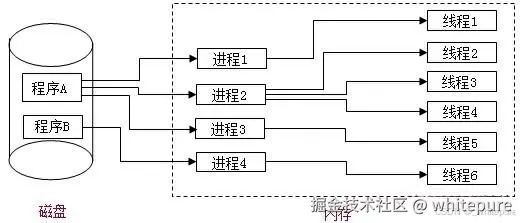
线程与进程
- 进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。一个正在运行的程序的实例就是一个进程。
- 线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际执行单位。一个进程可以包含多个线程,这些线程共享进程的内存空间和资源,但有自己的栈和程序计数器。
进程是操作系统资源分配的基本单位,而线程是处理器任务调度和执行的基本单位。一条线程指的是进程中的一个单一顺序的控制流,一个进程至少有一个线程,一个进程中可以并发多个线程,多个线程可共享数据,每条线程并行执行不同的任务。
Java程序是多线程程序,每启动一个Java程序,至少我们知道的都会包含一个主线程和一个垃圾回收线程。而且启动的时候,每条线程可以并行执行不同的任务。
线程的并行、串行、并发
- 并行:前提是在多核CPU,多个线程同时被多个CPU执行,同时执行的线程并不会抢占CPU资源。
- 串行:前提是在单核CPU条件下,单线程程序执行,不能同时执行,也不能去切换执行,也就是在同一时间段只能做一件事,如果需要做多件事情需要排队执行。
- 并发:前提是多线程条件下,多个线程抢占一个CPU资源,多个线程被交替执行。因为CPU运算速度很快,所以用户感觉不到线程切换的卡顿。
| 单线程 | 多线程 | |
|---|---|---|
| 单CPU | 串行 | 并发 |
| 多CPU | 串行 | 并行 |
无论并行、并发,都可以有多个线程执行,如果是多个线程抢占一个CPU,交替执行,并且CPU通过时间片轮转等机制切换执行线程,这种情况下称为并发执行。多个线程同时被多个CPU执行,并且各个线程之间不会互相抢占CPU资源,这种情况下称为并行执行。每个线程都在自己的CPU核心上独立执行,互不干扰。
对于单CPU的计算机来说,同一时间是只能干一件事儿的,如果是单线程就是串行,如果是多个线程就是并发。而对于多CPU的计算机说,同一时间能干多个事,如果多个CPU同时执行多个线程就是并行,如果一个CPU同时执行多个线程就是并行。
并行与并发区别图解 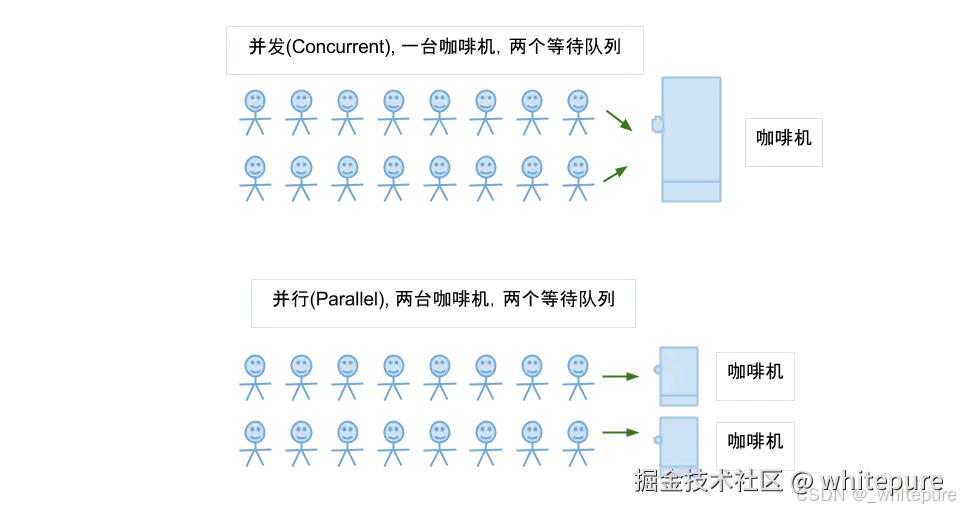
并发是两个队列交替使用一台咖啡机,并行是两个队列同时使用两台咖啡机;如果串行,一个队列使用一台咖啡机,那么哪怕前面那个人便秘了去厕所呆半天,后面的人也只能死等着他回来才能去接咖啡,这种效率无疑是最低的。
线程的同步、异步
- 同步指的是按顺序执行任务,一个任务的执行必须等待前一个任务完成后才能继续。在同步模式下,任务按照严格的顺序依次执行,每个任务执行完毕后才能进行下一个任务。例如,使用关键字
synchronized或Lock接口可以实现多线程的同步,确保多个线程按照特定的顺序或条件执行。 - 异步指的是任务的执行不依赖于主线程或当前线程,可以通过回调、事件驱动等方式实现任务的并行执行或后台执行。 异步任务可以在任务执行过程中继续执行其他任务,不需要等待当前任务完成。异步在Java中通常通过多线程、回调函数或
Future、CompletableFuture等方式实现。
线程与同步异步关系:
- 单线程环境下,所有任务按顺序同步执行。如果某个任务阻塞或者等待,整个程序会停止执行直到该任务完成。
- 多线程环境下,同步任务可以通过加锁等机制实现对共享资源的安全访问,保证数据的一致性。多线程中的同步操作可以确保多个线程协调执行,避免数据竞争和不一致问题。
- 单线程环境中,异步模式通过事件驱动或者非阻塞IO方式实现,可以模拟多任务并发执行的效果。虽然不能真正并行执行多个任务,但可以利用非阻塞方式处理IO或事件,提高响应速度。
- 多线程环境中,异步操作通常通过新线程或线程池执行,实现任务的并行处理。多线程中的异步操作可以提高系统的吞吐量和响应能力,充分利用多核处理器的优势。
| 单线程 | 多线程 | |
|---|---|---|
| 同步 | 只能同步执行,按照顺序执行任务 | 可以同步执行,多个线程按顺序执行任务 |
| 异步 | 不能直接异步执行,但可以通过事件循环或非阻塞IO模型实现类似异步效果 | 可以异步执行,通过多线程或者线程池来实现并行处理 |
守护线程
守护线程是指为其他线程服务的线程。守护线程也称"服务线程",在没有用户线程可服务时会自动离开。因为作用是服务其他线程,所以在程序中的优先级比较低。在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。
举例,垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的线程,程序就不会再产生垃圾,垃圾回收器也就无事可做。所以当垃圾回收线程是JVM上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。守护线程在程序中的操作演示:
java
public class MainTest {
public static void main(String[] args) {
int i = 0;
while (true) {
Thread daemon = new Thread(() -> {
System.out.println("启动线程--->" + Thread.currentThread().getName());
});
daemon.setDaemon(i==3);
daemon.start();
boolean isDaemon = daemon.isDaemon();
System.out.println("当前线程是否是守护线程:" + isDaemon);
if (isDaemon) {
break;
}
i++;
}
}
}线程安全
线程安全是指在多线程环境下,一个类、方法或代码块能够被多个线程安全地访问和修改,不会导致数据不一致性或产生不可预测的行为。线程安全通常通过同步机制实现,来确保多个线程不会同时访问或修改共享资源。
在多线程并发环境中,多个线程共同操作同一个数据,如果最终数据的值与预期不一致,就会出现线程不安全问题。为了解决这个问题,Java中最常用的方法是加锁。当一个线程修改某个数据时,其他线程不能访问该数据,直到该线程操作结束并释放锁,其他线程才能继续操作该数据。
线程安全问题的根本原因:
-
CPU切换线程执导致的原子性问题。当CPU在执行线程时进行上下文切换,一个线程的操作可能在执行一半时被中断,导致另一个线程看到不完整的操作结果,从而出现数据不一致。
javapublic class Counter { private int count = 0; public void increment() { count++; // 这个操作实际上分为三步:读取count值、增加1、写回count值 } } -
缓存可见性问题。由于CPU、内存、IO设备读写速度差异巨大,为了减少CPU等待IO的时间,在CPU和内存之间引入了高速缓存。多核CPU的情况下,每个核心有自己的缓存,这会导致高速缓存与主内存之间的数据不一致,即一个核心对变量的修改,另一个核心可能看不到。
javapublic class SharedData { private boolean flag = false; public void setFlag(boolean value) { flag = value; } public boolean getFlag() { return flag; } } -
指令优化重排序问题。编译器和处理器为了优化性能,可能会对指令进行重排序,这不会影响单线程环境下的执行结果,但在多线程环境下,可能导致程序行为不可预测。
javapublic class Example { private int a = 0; private boolean flag = false; public void write() { a = 1; // 1 flag = true; // 2 } public void read() { if (flag) { // 3 System.out.println(a); // 4 } } }
线程的状态
线程状态共包含6种,通过Thread.State枚举类表示的。6种状态又可以互相的转换,线程状态转换关系:
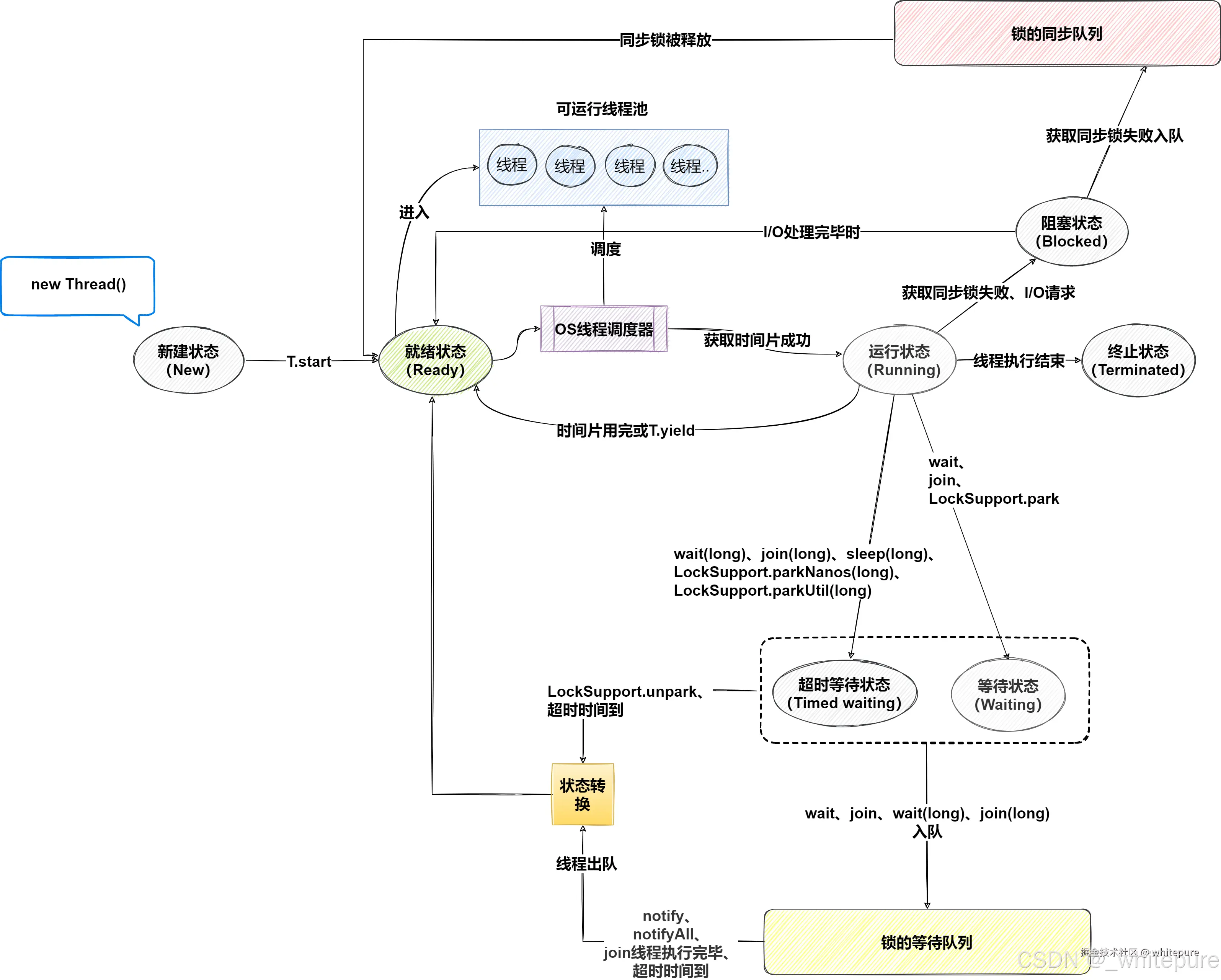
- 新建状态(New): 线程被创建但尚未启动。例如,
Thread t = new Thread();状态为NEW;调用线程对象的start()方法会使线程从NEW状态转变为RUNNABLE状态。 - 可运行状态(Runnable): 线程在Java虚拟机中执行中。这包括运行状态和就绪状态,线程可能正在运行,也可能等待操作系统为其分配CPU时间。
- 就绪(Ready):线程已经被创建,等待被调度执行。此时可能有多个线程处于就绪状态,但只有一个线程能够获取CPU时间片执行。
- 运行中(Running):就绪的线程获得了CPU时间片,开始执行程序代码。
- 阻塞状态(Blocked): 当一个线程试图进入一个同步代码块或方法,但该同步块已经被其他线程持有时,线程将进入阻塞状态。阻塞状态的线程将等待获取同步锁,一旦获取到锁就可以转变为RUNNABLE状态。
- 无限期等待(Waiting): 当线程调用
Object.wait()、Thread.join()或LockSupport.park()方法时,它会进入WAITING状态,直到被其他线程显式唤醒。线程被唤醒后可以转变为RUNNABLE状态。 - 限期等待(Timed Waiting): 当线程调用带有超时参数的等待方法,如
sleep()、wait(timeout)、join(timeout)、LockSupport.parkNanos()或LockSupport.parkUntil()时,它会进入TIMED_WAITING状态,直到超时时间到达或被其他线程唤醒。超时时间到达或被唤醒后可以转变为RUNNABLE状态。 - 死亡(Terminated): 线程完成
run()方法的执行或者因异常而终止时,会进入TERMINATED状态。一旦线程的run()方法执行完成或抛出未捕获的异常,线程将进入终止状态。
阻塞和等待的区别在于,阻塞是被动的,它是在等待获取一个排它锁。而等待是主动的,通过调用Thread.sleep()和Object.wait()等方法进入等待。
线程相关方法
-
start():启动一个新线程,调用线程的run()方法。textThread t = new Thread(() -> { System.out.println("Thread is running"); }); t.start(); -
run():运行线程中的代码。可以通过继承Thread类并重写run()方法,或通过实现Runnable接口并传递给Thread类的构造函数。textpublic class MyThread extends Thread { public void run() { System.out.println("Thread is running"); } } MyThread t = new MyThread(); t.start(); -
sleep(long millis):让当前线程休眠指定的毫秒数。texttry { Thread.sleep(1000); // 休眠1秒 } catch (InterruptedException e) { e.printStackTrace(); } -
join():当有新的线程加入时,主线程会进入等待状态,一直到调用join()方法的线程执行结束为止。join()方法的实现依赖于对象的wait()方法。textThread t = new Thread(() -> { try { Thread.sleep(2000); } catch (InterruptedException e) { e.printStackTrace(); } }); t.start(); try { t.join(); } catch (InterruptedException e) { e.printStackTrace(); } -
yield():用于让当前正在执行的线程暂时让出CPU的执行权,使其他线程有机会运行。它不会使线程进入阻塞或等待状态,只是让出当前的CPU时间片,让同等优先权的线程运行。如果没有同等优先权的线程,那么yield()方法将不会起作用。textpublic void run() { for (int i = 0; i < 5; i++) { System.out.println(threadName + " is running, iteration: " + i); // 暂时让出CPU执行权,给其他线程机会 Thread.yield(); } System.out.println(threadName + " has finished execution."); } public static void main(String[] args) { Thread thread1 = new Thread(new YieldExample("Thread 1")); Thread thread2 = new Thread(new YieldExample("Thread 2")); thread1.start(); thread2.start(); } -
wait():使当前线程等待,直到另一个线程调用该对象的notify()或notifyAll()方法。wait()必须在同步synchronized块里使用。textsynchronized (lock) { lock.wait(); } -
notify():唤醒一个正在等待该对象的wait()方法的线程。如果多个线程都在该对象的监视器上等待,则任意选择一个线程被唤醒。notify()方法必须与wait()方法一起使用,否则会抛出IllegalMonitorStateException异常。notify()方法必须在同步代码块或同步方法中调用,因为它依赖于对象的监视器锁。javapublic synchronized void doWaitNotify() { Thread waitingThread = new Thread(() -> { try { System.out.println("Thread is waiting..."); wait(); // 进入等待状态 System.out.println("Thread is notified and resumed."); } catch (InterruptedException e) { e.printStackTrace(); } }); waitingThread.start(); try { Thread.sleep(1000); // 模拟一些操作延迟 } catch (InterruptedException e) { e.printStackTrace(); } synchronized (this) { System.out.println("Notifying waiting thread..."); notify(); // 唤醒等待的线程 } }
需要注意区分wait方法与sleep方法,很多人分不清。sleep和wait方法异同点:
sleep()属于Thread类,wait()属于Object类;sleep()和wait()都会抛出InterruptedException异常,这个异常属于checkedException是不可避免;- 两者比较的共同之处是,都是使程序等待多长时间。不同的是调用
sleep()不会释放锁,会使线程堵塞,而调用wait()会释放锁,让线程进入等待状态,用notify()、notifyall()可以唤醒,或者等待时间到了;这是因为,如果没有释放锁,那么其它线程就无法进入对象的同步方法或者同步控制块中,那么就无法执行notify()或者notifyAll()来唤醒挂起的线程,造成死锁。 wait()必须在同步synchronized块里使用,sleep()可以在任意地方使用;
其中"wait()必须在同步synchronized块里使用",不止wait方法,notify、notifyAll也和wait方法一样,必须在synchronized块里使用,为什么呢?
是为了避免丢失唤醒问题。假设没有synchronized修饰,使用了wait方法而没有设置等待时间,也没有调用唤醒方法或者唤醒方法调用的时机不对,这个线程将会永远的堵塞下去。wait、notify、notifyAll方法调用的时候要释放锁,你都没给它加锁,他怎么释放锁。所以如果没在synchronized块中调用wait()、notify、notifyAll方法是肯定抛异常的。
创建线程
在Java中创建一个线程,有且仅有一种方式,创建一个Thread类实例,并调用它的start方法。
Thread
最经典也是最常见的方式是通过继承Thread类,重写run()方法来创建线程。适用于需要直接控制线程生命周期的情况。
java
public class MainTest {
public static void main(String[] args) {
ThreadDemo thread1 = new ThreadDemo();
thread1.start();
}
}
class ThreadDemo extends Thread {
@Override
public void run() {
System.out.printf("通过继承Thread类的方式创建线程,线程 %s 启动",Thread.currentThread().getName());
}
}Runnable
实现Runnale接口,将它作为target参数传递给Thread类构造函数的方式创建线程。
java
public class MainTest {
public static void main(String[] args) {
new Thread(() -> {
System.out.printf("通过实现Runnable接口的方式,重写run方法创建线程;线程 %s 启动",Thread.currentThread().getName());
}).start();
}
}Callable
Callable接口与Runnable类似,但它可以返回结果,并且可以抛出异常,需要配合Future接口使用。通过实现Callable接口,来创建一个带有返回值的线程。在Callable执行完之前的这段时间,主线程可以先去做一些其他的事情,事情都做完之后,再获取Callable的返回结果。可以通过isDone()来判断子线程是否执行完。
java
public class MainTest {
public static void main(String[] args) throws ExecutionException, InterruptedException {
FutureTask<String> futureTask = new FutureTask<>(() -> {
System.out.printf("通过实现Callable接口的方式,重写call方法创建线程;线程 %s 启动", Thread.currentThread().getName());
System.out.println();
Thread.sleep(10000);
return "我是call方法返回值";
});
new Thread(futureTask).start();
System.out.println("主线程工作中 ...");
String callRet = null;
while (callRet == null){
if(futureTask.isDone()){
callRet = futureTask.get();
}
System.out.println("主线程继续工作 ...");
}
System.out.println("获取call方法返回值:"+ callRet);
}
}在实际开发中,通常使用异步编程工具,如CompletableFuture。CompletableFuture是JDK8的新特性。CompletableFuture实现了CompletionStage接口和Future接口,前者是对后者的一个扩展,增加了异步会点、流式处理、多个Future组合处理的能力,使Java在处理多任务的协同工作时更加顺畅便利。
java
public class CompletableFutureRunAsyncExample {
public static void main(String[] args) {
CompletableFuture<Void> future = CompletableFuture.runAsync(() -> {
// 异步执行的任务,没有返回值
System.out.println("Running asynchronously");
});
future.thenRun(() -> {
System.out.println("After running asynchronously");
});
future.join(); // 等待任务完成
CompletableFuture<String> future = CompletableFuture.supplyAsync(() -> "Hello")
.thenApply(result -> result + " CompletableFuture!");
}
}线程池
线程池做的工作主要是控制运行的线程的数量,处理过程中将任务放入队列,然后在线程创建后启动这些任务。如果线程数量超过了最大数量超出数量的线程排队等候,等其它线程执行完毕,再从队列中取出任务来执行。线程池是一种用于管理和复用线程的机制,可以有效地提高应用程序的性能和资源利用率。它的主要特点为:线程复用,提高响应速度,管理线程。
- 降低资源消耗,通过重复利用己创建的线程降低线程创建和销毁造成的消耗。
- 提高响应速度,当任务到达时,任务可以不需要的等到线程创建就能立即执行。
- 提高线程的管理性,线程是稀缺资源,如果无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,使用线程池可以进行统一的分配,调优和监控。
创建方式
在Java中,使用java.util.concurrent包中的Executor来创建和管理线程池。几种常见的线程池创建方式:
Executors.newSingleThreadExecutor():创建只有一个线程的线程池。Executors.newFixedThreadPool(int):创建固定线程的线程池。Executors.newCachedThreadPool():创建一个可缓存的线程池,线程数量随着处理业务数量变化。
这三种常用创建线程池的方式,底层代码都是用ThreadPoolExecutor创建的。
-
使用
Executors.newSingleThreadExecutor()创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序执行。newSingleThreadExecutor将corePoolSize和maximumPoolSize都设置为1,它使用的LinkedBlockingQueue。javapublic static ExecutorService newSingleThreadExecutor() { return new FinalizableDelegatedExecutorService (new ThreadPoolExecutor(1, 1, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>())); }javapublic class MainTest { public static void main(String[] args) { ExecutorService executor1 = null; try { executor1 = Executors.newSingleThreadExecutor(); for (int i = 1; i <= 10; i++) { executor1.execute(() -> { System.out.println(Thread.currentThread().getName() + "执行了"); }); } } finally { executor1.shutdown(); } } } -
使用
Executors.newFixedThreadPool(int)创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。newFixedThreadPool创建的线程池corePoolSize和maximumPoolSize值是相等的,它使用的LinkedBlockingQueue。javapublic static ExecutorService newFixedThreadPool(int nThreads) { return new ThreadPoolExecutor(nThreads, nThreads, 0L, TimeUnit.MILLISECONDS, new LinkedBlockingQueue<Runnable>()); }javapublic class MainTest { public static void main(String[] args) { ExecutorService executor1 = null; try { executor1 = Executors.newFixedThreadPool(10); for (int i = 1; i <= 10; i++) { executor1.execute(() -> { System.out.println(Thread.currentThread().getName() + "执行了"); }); } } finally { executor1.shutdown(); } } } -
使用
Executors.newCachedThreadPool()创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收则新建线程。newCachedThreadPool将corePoolSize设置为0,将maximumPoolSize设置为Integer.MAX_VALUE,使用的SynchronousQueue,也就是说来了任务就创建线程运行,当线程空闲超过60秒,就销毁线程。javapublic static ExecutorService newCachedThreadPool() { return new ThreadPoolExecutor(0, Integer.MAX_VALUE, 60L, TimeUnit.SECONDS, new SynchronousQueue<Runnable>()); }javapublic class MainTest { public static void main(String[] args) { ExecutorService executor1 = null; try { executor1 = Executors.newCachedThreadPool(); for (int i = 1; i <= 10; i++) { executor1.execute(() -> { System.out.println(Thread.currentThread().getName() + "执行了"); }); } } finally { executor1.shutdown(); } } }
自定义线程池
在实际开发中用哪个线程池?上面的三种一个都不用,我们生产上只能使用自定义的。Executors类中已经给你提供了,为什么不用?
摘自《阿里巴巴开发手册》 【强制】线程资源必须通过线程池提供,不允许在应用中自行显式创建线程。 说明:线程池的好处是减少在创建和销毁线程上所消耗的时间以及系统资源的开销,解决资源不足的问题。 如果不使用线程池,有可能造成系统创建大量同类线程而导致消耗完内存或者"过度切换"的问题。
【强制】线程池不允许使用
Executors去创建,而是通过ThreadPoolExecutor的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。 说明:Executors返回的线程池对象的弊端如下: 1)FixedThreadPool和SingleThreadPool: 允许的请求队列长度为Integer.MAX_VALUE,可能会堆积大量的请求,从而导致OOM。 2)CachedThreadPool: 允许的创建线程数量为Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
自定义线程池代码演示:
java
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
executor1 = new ThreadPoolExecutor(
2,
5,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i <= 20; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}SpringBoot异步配置,自定义线程池代码演示:
java
@EnableAsync
@Configuration
public class AsyncConfig {
/**
* 线程空闲存活的时间 单位: TimeUnit.SECONDS
*/
public static final int KEEP_ALIVE_TIME = 60 * 60;
/**
* CPU 核心数量
*/
private static final int CPU_COUNT = Runtime.getRuntime().availableProcessors();
/**
* 核心线程数量
*/
public static final int CORE_POOL_SIZE = Math.max(2, Math.min(CPU_COUNT - 1, 4));
/**
* 线程池最大容纳线程数量
* IO密集型:即存在大量堵塞; 公式: CPU核心数量 / 1- 阻塞系数 (阻塞系统在 0.8~0.9 之间)
* CPU密集型: 需要大量运算,没有堵塞或很少有; 公式:CPU核心数量 + 1
*/
public static final int IO_MAXIMUM_POOL_SIZE = (int) (CPU_COUNT / (1 - 0.9));
public static final int CPU_MAXIMUM_POOL_SIZE = CPU_COUNT + 2;
/**
* 执行写入请求时的线程池
*
* @return 线程池
*/
@Bean(name = "iSaveTaskThreadPool")
public Executor iSaveTaskThreadPool() {
return getThreadPoolTaskExecutor("iSaveTaskThreadPool-",IO_MAXIMUM_POOL_SIZE,100000,new ThreadPoolExecutor.CallerRunsPolicy());
}
/**
* 执行读请求时的线程池
*
* @return 线程池
*/
@Bean(name = "iQueryThreadPool")
public Executor iQueryThreadPool() {
return getThreadPoolTaskExecutor("iQueryThreadPool-",CPU_MAXIMUM_POOL_SIZE,10000,new ThreadPoolExecutor.CallerRunsPolicy());
}
/**
* 创建一个线程池对象
* @param threadNamePrefix 线程名称
* @param queueCapacity 堵塞队列长度
* @param refusePolicy 拒绝策略
*/
private ThreadPoolTaskExecutor getThreadPoolTaskExecutor(String threadNamePrefix,int maxPoolSize,int queueCapacity,ThreadPoolExecutor.CallerRunsPolicy refusePolicy) {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(CORE_POOL_SIZE);
taskExecutor.setMaxPoolSize(maxPoolSize);
taskExecutor.setKeepAliveSeconds(KEEP_ALIVE_TIME);
taskExecutor.setThreadNamePrefix(threadNamePrefix);
// 拒绝策略; 既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量
taskExecutor.setRejectedExecutionHandler(refusePolicy);
// 阻塞队列 长度
taskExecutor.setQueueCapacity(queueCapacity);
taskExecutor.setWaitForTasksToCompleteOnShutdown(true);
taskExecutor.setAwaitTerminationSeconds(60);
taskExecutor.initialize();
return taskExecutor;
}
}线程池工作原理
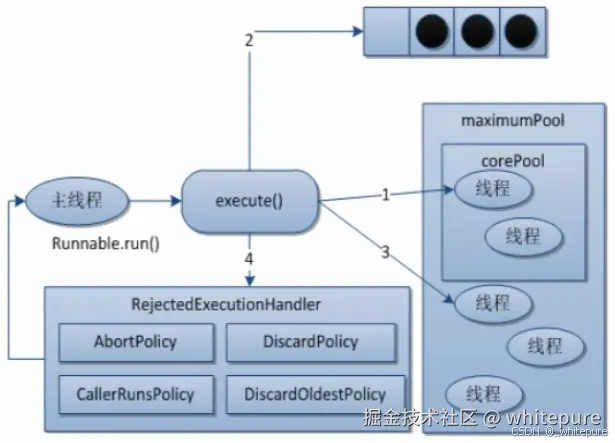
在创建了线程池后,等待提交过来的任务请求,当调用execute方法添加一个请求任务时,线程池会做如下判断:
- 如果当前运行的线程数小于
corePoolSize,那么马上创建线程运行该任务。 - 如果当前运行的线程数大于等于
corePoolSize,那么该任务会被放入任务队列。 - 如果这时候任务队列满了且正在运行的线程数还小于
maximumPoolSize,那么要创建非核心线程立刻运行这个任务扩容。 - 如果任务队列满了且正在运行的线程数等于
maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。 - 随着时间的推移,业务量越来越少,线程池中出现了空闲线程。当一个线程无事可做超过一定的时间时,线程池会进行判断,如果当前运行的线程数大于
corePoolSize,那么这个线程就被停掉,所以线程池的所有任务完成后它最终会收缩到corePoolSize的大小。
阻塞队列
阻塞队列,顾名思义,首先它是一个队列,一个阻塞队列在数据结构中所起的作用:
- 当阻塞队列是空时,从队列中获取元素的操作将会被阻塞。
- 当阻塞队列是满时,往队列里添加元素的操作将会被阻塞。
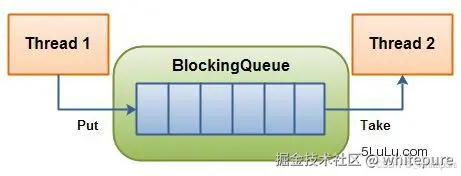
在多线程编程中,阻塞队列扮演着重要角色,特别适用于生产者-消费者模式,确保线程之间的同步和有序执行。阻塞队列的本质是一种数据结构,用于存储待执行的任务。当任务提交给线程池时,如果核心线程已满或任务队列达到容量上限,新任务将被放入阻塞队列中,等待执行条件的满足。
阻塞在多线程领域指的是线程因某些条件而暂停执行,一旦条件满足,线程会被自动唤醒继续执行。这种机制保证了线程池的任务按照预期顺序执行,有效地管理并发任务的执行流程。
在Java中,常见的线程池阻塞队列包括:
ArrayBlockingQueue: 由数组结构组成的有界阻塞队列。它按照 FIFO(先进先出)的顺序对元素进行排序。LinkedBlockingQueue: 由链表结构组成的有界(默认大小为Integer.MAX_VALUE,大约21亿)阻塞队列。同样按照 FIFO 的顺序对元素进行排序。PriorityBlockingQueue: 支持优先级排序的无界阻塞队列。元素按照它们的优先级顺序被处理,具有最高优先级的元素总是被队列中的下一个要处理的元素。DelayQueue: 使用优先级队列实现的延迟无界阻塞队列。队列中的元素只有在其指定的延迟时间到达时才能被取出。SynchronousQueue: 不存储元素的阻塞队列,每个插入操作必须等待一个对应的移除操作。用于直接传递任务的场景。LinkedTransferQueue: 由链表结构组成的无界阻塞队列,支持生产者-消费者的传输机制。与其他队列不同,它支持优先级传输。LinkedBlockingDeque: 由链表结构组成的双向阻塞队列。它支持在队列的两端进行插入和移除操作,是一种双端队列。
当你自定义线程池时,选择合适的阻塞队列是非常重要的。阻塞队列就像一个存放任务的"箱子",线程池中的任务先放到这里,然后线程池的线程再从这里取出来执行。如果你的系统可能会有很多任务一起提交,可以考虑用能存很多任务的队列,比如LinkedBlockingQueue。这样即使任务多了,也不会丢失。如果你的任务有优先级,比如有些任务比其他的更重要,那就选PriorityBlockingQueue。它会按照任务的优先级来决定哪个任务先执行。如果应用程序需要限制内存使用,并希望在达到容量限制时阻塞新任务提交,可以选择ArrayBlockingQueue。
线程池参数
在Java中,线程池的创建和管理通过java.util.concurrent.ThreadPoolExecutor类完成。理解这个类构造函数的参数可以帮助我们更好地配置和优化线程池的运行效果。
java
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
// ...
}corePoolSize: 核心线程数。当提交一个新任务时,如果当前运行的线程少于corePoolSize,则即使有空闲的工作线程,也会创建一个新线程来执行任务。核心线程在ThreadPoolExecutor的生命周期内始终存活,除非设置了allowCoreThreadTimeOut。maximumPoolSize:线程池能够容纳同时执行的最大线程数,此值必须大于等于1。当任务队列满时,如果当前运行的线程数少于maximumPoolSize,则会创建新的线程来执行任务。threadFactory:线程工厂,一般用默认的即可。用于创建新线程,通常用来给线程设置名称、设置为守护线程等。workQueue:任务队列,用于保存等待执行任务的队列。随着业务量的增多,线程开始慢慢处理不过来,这时候需要放到任务队列中去等待线程处理。rejectedExecutionHandler:拒绝策略。如果业务越来越多,线程池首先会扩容,扩容后发现还是处理不过来,任务队列已经满了,处理被拒绝任务的策略。AbortPolicy: 默认拒绝策略;直接抛出java.util.concurrent.RejectedExecutionException异常,阻止系统的正常运行;CallerRunsPolicy:调用这运行,一种调节机制,该策略既不会抛弃任务,也不会抛出异常,而是将某些任务回退到调用者,从而降低新任务的流量;DiscardOldestPolicy:抛弃队列中等待最久的任务,然后把当前任务加入到队列中;DiscardPolicy:直接丢弃任务,不给予任何处理也不会抛出异常;如果允许任务丢失,这是一种最好的解决方案;
keepAliveTime:多余的空闲线程的存活时间。如果线程池扩容后,能处理过来,而且数据量并没有那么大,用最初的线程数量就能处理过来,剩下的线程被叫做空闲线程。keepAliveTime指的是当线程数超过corePoolSize时,多余的空闲线程在等待新任务到来之前可以存活的最长时间。如果设置为0,则超出核心线程数的空闲线程会立即终止。unit:keepAliveTime参数的时间单位,可以是TimeUnit.SECONDS、TimeUnit.MILLISECONDS等。
合理配置线程池参数
合理配置线程池参数,可以分为以下两种情况:
- CPU密集型:CPU密集的意思是该任务需要大量的运算,而没有阻塞,CPU一直全速运行;CPU密集型任务配置尽可能少的线程数量:
参考公式:(CPU核数+1) - IO密集型:即该任务需要大量的IO,即大量的阻塞;在IO密集型任务中使用多线程可以大大的加速程序运行,故需要多配置线程数:参考公式:
CPU核数/ (1-阻塞系数) 阻塞系数在0.8~0.9之间
java
public class MainTest {
public static void main(String[] args) {
ExecutorService executor1 = null;
try {
// 获取CPU核心数
int coreNum = Runtime.getRuntime().availableProcessors();
/*
* 1. IO密集型: CPU核数/ (1-阻塞系数) 阻塞系数在0.8~0.9之间
* 2. CPU密集型: CPU核数+1
*/
// int maximumPoolSize = coreNum + 1;
int maximumPoolSize = (int) (coreNum / (1 - 0.9));
System.out.println("当前线程池最大允许存放:" + maximumPoolSize + "个线程");
executor1 = new ThreadPoolExecutor(
2,
maximumPoolSize,
1L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.CallerRunsPolicy());
for (int i = 1; i <= 20; i++) {
executor1.execute(() -> {
System.out.println(Thread.currentThread().getName() + "执行了");
});
}
} finally {
executor1.shutdown();
}
}
}锁
在Java中根据锁的特性来划分可以分为很多,锁的主要作用是确保多线程环境下的数据安全,从而保证程序的正确执行。在Java中具体"锁"的实现,通常可以归纳为三种,使用synchronized关键字、调用juc.locks包下相关接口、使用CAS思想。
| 锁的类型与概念 | 描述 |
|---|---|
| 公平锁 | 线程按照请求的顺序获取锁。 |
| 非公平锁 | 线程获取锁的顺序不受控制,有可能插队。 |
| 可重入锁 | 允许同一个线程多次获取同一把锁,避免死锁。 |
| 不可重入锁 | 不允许同一个线程多次获取同一把锁。 |
| 共享锁 | 多个线程可以同时获取同一把锁。 |
| 独占锁 | 同一时间只允许一个线程获取该锁。 |
| 悲观锁 | 假设会有并发冲突,每次操作时都加锁。 |
| 乐观锁 | 假设不会有并发冲突,操作时不加锁,提交时检查是否冲突。 |
| 偏向锁 | 当只有一个线程访问同步块时,为该线程加锁,减少获取锁的操作成本。 |
| 轻量级锁 | 针对竞争不激烈的情况下进行优化,通过CAS操作来避免互斥。 |
| 重量级锁 | 竞争激烈时,锁的持有和释放会导致线程阻塞和唤醒。 |
| 可中断锁 | 允许在等待锁的过程中可以响应中断信号。 |
| 互斥锁 | 控制对共享资源的访问,同一时间只有一个线程可以获取锁。 |
| 死锁 | 几个线程因互相持有对方所需的资源而无法继续执行的状态。 |
公平锁与非公平锁
根据线程获取锁的顺序来划分可分为公平锁和非公平锁。
-
公平锁:公平锁是指多个线程按照申请锁的顺序来获取锁。即先到先得的原则,先请求锁的线程会先获取到锁,后到的线程会排队等待。优点是等待锁的线程不会饿死。缺点是整体吞吐效率相对非公平锁要低,等待队列中除第一个线程以外的所有线程都会阻塞,CPU唤醒阻塞线程的开销比非公平锁大。
javaReentrantLock fairLock = new ReentrantLock(true); // true 表示使用公平锁 -
非公平锁:非公平锁是指多个线程获取锁的顺序是不确定的,是随机竞争的。即线程获取锁的顺序是不固定的,有可能新来的线程比等待时间长的线程先获取到锁。优点是可以通过减少线程切换的开销来提高并发性能,整体的吞吐效率高。缺点是处于等待队列中的线程可能会饿死,或者等很久才会获得锁。
javaReentrantLock nonfairLock = new ReentrantLock(false); // false 表示使用非公平锁(默认)
通常情况下,如果不特别需要公平性,非公平锁能够提供更高的性能。但是在某些需要严格控制线程执行顺序的场景下,公平锁可能更为适合。在Java中公平锁和非公平锁的实现为ReentrantLock、synchronized。其中synchronized是非公平锁,ReentrantLock默认是非公平锁,但是可以指定ReentrantLock的构造函数创建公平锁。
java
/**
* Creates an instance of {@code ReentrantLock}.
* This is equivalent to using {@code ReentrantLock(false)}.
*/
public ReentrantLock() {
sync = new NonfairSync();
}
/**
* Creates an instance of {@code ReentrantLock} with the
* given fairness policy.
*
* @param fair {@code true} if this lock should use a fair ordering policy
*/
public ReentrantLock(boolean fair) {
sync = fair ? new FairSync() : new NonfairSync();
}可重入锁与不可重入锁
根据一个线程是否可以多次获得同一把锁来划分,可分为可重入锁和不可重入锁。
- 可重入锁:可重入锁是指同一个线程在外层方法获取锁之后,在内层方法仍然能够获取该锁的锁。即同一个线程可以多次获得同一把锁,可重入锁最大的作用就是避免死锁。所以可重入锁又叫做递归锁。
- 不可重入锁:所谓不可重入锁,就是与可冲入锁作用相悖;不可重入锁是指一个线程在持有锁的情况下再次请求锁时,会被阻塞或导致死锁。即同一个线程不能多次获得同一把锁。
举个例子,当你进入你家时门外会有锁,进入房间后厨房卫生间都可以随便进出,这个叫可重入锁。当你进入房间时,发现厨房、卫生间都上锁而且你拿不到钥匙,这个叫不可重入锁。在Java中ReentrantLock和synchronized都是可重入锁。
java
public class ReentrantExample {
public synchronized void outerMethod() {
System.out.println("Outer method");
innerMethod();
}
public synchronized void innerMethod() {
System.out.println("Inner method");
}
public static void main(String[] args) {
ReentrantExample example = new ReentrantExample();
example.outerMethod();
}
}
java
public class ReentrantLockExample {
private final ReentrantLock lock = new ReentrantLock();
public void outerMethod() {
lock.lock();
try {
System.out.println("Outer method");
innerMethod();
} finally {
lock.unlock();
}
}
public void innerMethod() {
lock.lock();
try {
System.out.println("Inner method");
} finally {
lock.unlock();
}
}
public static void main(String[] args) {
ReentrantLockExample example = new ReentrantLockExample();
example.outerMethod();
}
}共享锁与独占锁
根据锁的访问权限可划分为共享锁和独占锁。
- 独占锁:独占锁又称排它锁,指一次只能有一个线程获得锁,其他所有尝试获取锁的线程都会被阻塞,直到持有锁的线程释放锁。只有一个线程能访问受保护的资源,从而确保资源的独占访问,适用于写操作等需要完全独占资源的场景。
- 共享锁:共享锁允许多个线程同时获得锁,多个线程可以并发地访问受保护的资源。适用于读操作等可以并发访问的场景。多个线程可以同时持有锁,但如果某个线程需要进行写操作,则必须等到所有持有共享锁的线程释放锁。
在Java中,对于ReentrantLock和synchronized都是独占锁。对于ReentrantReadWriteLock其读锁是共享锁而写锁是独占锁,读锁的共享可保证并发读是非常高效的。
java
public class SharedLockExample {
private final ReentrantReadWriteLock rwLock = new ReentrantReadWriteLock();
private final ReentrantReadWriteLock.ReadLock readLock = rwLock.readLock();
private final ReentrantReadWriteLock.WriteLock writeLock = rwLock.writeLock();
public void readMethod() {
readLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the read lock");
// Read-only critical section
} finally {
readLock.unlock();
System.out.println(Thread.currentThread().getName() + " released the read lock");
}
}
public void writeMethod() {
writeLock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the write lock");
// Write critical section
} finally {
writeLock.unlock();
System.out.println(Thread.currentThread().getName() + " released the write lock");
}
}
public static void main(String[] args) {
SharedLockExample example = new SharedLockExample();
Runnable readTask = () -> {
for (int i = 0; i < 3; i++) {
example.readMethod();
}
};
Runnable writeTask = () -> {
for (int i = 0; i < 3; i++) {
example.writeMethod();
}
};
Thread t1 = new Thread(readTask);
Thread t2 = new Thread(readTask);
Thread t3 = new Thread(writeTask);
t1.start();
t2.start();
t3.start();
}
}悲观锁与乐观锁
根据对数据并发访问来划分,可分为悲观锁和乐观锁。乐观锁与悲观锁是一种广义上的概念,可以理解为一种标准类似于Java中的接口。
- 对于多线程并发操作,加了悲观锁的线程认为每一次修改数据时都会有其他线程来跟它一起修改数据,所以在修改数据之前先会加锁,确保其他线程不会修改该数据。由于悲观锁在修改数据前先加锁的特性,能保证写操作时数据正确,所以悲观锁更适合写多读少的场景。
- 乐观锁则与悲观锁相反,每一次修改数据时,都认为没有其他线程来跟它一起修改,所以在修改数据之前不会去添加锁,如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作。由于乐观锁是一种无锁操作,所以在使用乐观锁的场景中读的性能会大幅度提升,适合读多写少。
在Java中悲观锁的实现有,synchronized、Lock实现类,乐观锁的实现有CAS。
java
public class SynchronizedExample {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
public static void main(String[] args) {
SynchronizedExample example = new SynchronizedExample();
example.increment();
System.out.println("Count: " + example.getCount());
}
}
java
public class CASExample {
private final AtomicInteger count = new AtomicInteger(0);
public void increment() {
while (true) {
int existingValue = count.get();
int newValue = existingValue + 1;
if (count.compareAndSet(existingValue, newValue)) {
break;
}
}
}
public int getCount() {
return count.get();
}
public static void main(String[] args) {
CASExample example = new CASExample();
example.increment();
System.out.println("Count: " + example.getCount());
}
}自旋锁与适应性自旋锁
自旋锁是一种特殊的锁,它不会让线程立即阻塞。当一个线程尝试获取某个锁时,如果该锁已被其他线程占用,就一直循环检测锁是否被释放,而不是进入线程挂起或睡眠状态,直到获取到某个锁超过一定的自旋次数后才会阻塞线程。自旋锁本身是有缺点的,它不能代替阻塞。如果锁被占用的时间很长,那么自旋的线程只会白白浪费处理器资源,带来性能上的浪费,所以使用自旋锁时需要根据具体的应用场景来权衡其利弊。
在Java中,可以使用java.util.concurrent.atomic包下的原子类来实现自旋锁,其中AtomicInteger常被用来实现简单的自旋锁。
java
public class SpinLock {
private volatile boolean locked = false;
public void lock() {
// 自旋等待获取锁
while (locked);
// 获取到锁后,将 locked 设置为 true
locked = true;
}
public void unlock() {
// 释放锁
locked = false;
}
public static void main(String[] args) {
SpinLock spinLock = new SpinLock();
// 线程1
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 1 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
// 线程2
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 2 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
}
}为什么要使用自旋锁?在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。简单来说就是,避免切换线程带来的开销。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是10次,可以使用-XX:PreBlockSpin来更改)没有成功获得锁,就应当挂起线程。
自旋锁在JDK 1.4中引入,默认关闭,但是可以使用
-XX:+UseSpinning开启。在JDK1.6中默认开启,同时自旋的默认次数为10次,可以通过参数-XX:PreBlockSpin来调整。
如果通过参数-XX:PreBlockSpin来调整自旋锁的自旋次数会带来诸多不便。假如将参数调整为10,但是系统很多线程都是等你刚刚退出的时候就释放了锁,假如多自旋一两次就可以获取锁。于是JDK1.6引入适应性自旋锁。
适应性自旋锁是对自旋的升级、优化,自旋的时间不再固定,它根据当前锁的使用情况动态调整自旋等待时间。如果在同一个锁对象上,自旋等待刚刚成功获得过锁,并且持有锁的线程正在运行中,那么虚拟机就会认为这次自旋也是很有可能再次成功,进而它将允许自旋等待持续相对更长的时间。如果对于某个锁,自旋很少成功获得过,那在以后尝试获取这个锁时将可能省略掉自旋过程,直接阻塞线程,避免浪费处理器资源。
java
public class AdaptiveSpinLock {
private static final int MIN_SPIN_COUNT = 10;
private static final int MAX_SPIN_COUNT = 1000;
private AtomicBoolean locked = new AtomicBoolean(false);
private int spinCount = MIN_SPIN_COUNT; // 初始自旋等待次数设定为最小值
public void lock() {
int spins = spinCount; // 获取当前自旋次数
while (!locked.compareAndSet(false, true)) {
if (spins < MAX_SPIN_COUNT) {
spins++; // 自旋次数递增
}
// 在真实场景中,可能需要添加短暂的延时,避免过多占用CPU资源
for (int i = 0; i < spins; i++) {
Thread.onSpinWait(); // 在Java 9及以上版本中,可以使用Thread.onSpinWait()来优化自旋等待
}
}
spinCount = spins; // 更新自旋次数
}
public void unlock() {
locked.set(false);
}
public static void main(String[] args) {
AdaptiveSpinLock spinLock = new AdaptiveSpinLock();
// 线程1
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 1 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
// 线程2
new Thread(() -> {
spinLock.lock();
try {
System.out.println("Thread 2 in critical section");
Thread.sleep(1000); // 模拟临界区代码执行
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
spinLock.unlock();
}
}).start();
}
}偏向锁
偏向锁是Java中针对加锁操作进行的一种优化机制,主要针对只有一个线程访问同步块的场景。它的设计初衷是在无竞争的情况下,减少不必要的同步原语的性能消耗。
《深入理解Java虚拟机》对偏向锁的解释:
Hotspot的作者经过以往的研究发现大多数情况下锁不仅不存在多线程竞争,而且总是由同一线程多次获得,为了让线程获得锁的代价更低而引入了偏向锁。 当一个线程访问同步块并获取锁时,会在对象头和栈帧中的锁记录里存储锁偏向的线程 ID,以后该线程在进入和退出同步块时不需要花费CAS操作来加锁和解锁,而只需简单的测试一下对象头的MarkWord里是否存储着指向当前线程的偏向锁,如果测试成功,表示线程已经获得了锁,如果测试失败,则需要再测试下MarkWord中偏向锁的标识是否设置成 1(表示当前是偏向锁),如果没有设置,则使用 CAS 竞争锁,如果设置了,则尝试使用CAS将对象头的偏向锁指向当前线程。
之所以叫偏向锁是因为偏向于第一个获取到他的线程,如果在程序执行中该锁没有被其他的线程获取,则持有偏向锁的线程将永远不需要再进行同步。但是如果线程间存在锁竞争,偏向锁会失效,此时会涉及到锁的撤销,将锁状态升级为适合多线程竞争的轻量级锁或者重量级锁,这个过程可能会引入额外的开销,影响性能。
当一个线程访问同步块时,首先会尝试获取偏向锁。如果同步块之前没有被其他线程锁定,当前线程会尝试获取偏向锁,并将对象头的标记位设置为偏向锁。如果其他线程尝试访问该同步块,会检测到该同步块已经被偏向锁定,会尝试撤销偏向锁,升级为轻量级锁或者重量级锁。如果偏向线程已经不再访问该同步块,那么该对象头的标记位会被设置成无锁状态,接着是无锁状态。
轻量级锁与重量级锁
根据锁的竞争情况来划分可以分为重量级锁和轻量级锁。
- 重量级锁:重量级锁适用于多线程竞争激烈的情况下,它的实现通常依赖于操作系统的底层特性,重量级锁会导致线程堵塞。传统的重量级锁,使用的是系统互斥量实现的。
- 轻量级锁:相对于重量级锁而言的。轻量级锁适用于多线程竞争不激烈的情况下,它的设计目标是在减少传统重量级锁在竞争时带来的性能损耗。
在Java中轻量级锁的经典实现是CAS中的自旋锁。优点是竞争的线程不会阻塞,提高了程序的响应速度;缺点是如果始终得不到锁竞争的线程,使用自旋会消耗CPU。所以轻量级锁适合,追求响应时间,同步块执行速度非常快的场景。重量级锁依赖于操作系统提供的底层同步机制。优点是线程竞争不使用自旋,不会消耗CPU;缺点是当多个线程竞争同一个锁时,会直接阻塞等待,直到获取到锁的线程释放锁资源。适合追求吞吐量、同步块执行时间较长也就是线程竞争激烈的场景。
轻量级锁不是在任何情况下都比重量级锁快的,要看同步块执行期间有没有多个线程抢占资源的情况。如果有,那么轻量级线程要承担CAS+互斥锁的性能消耗,就会比重量锁执行的更慢。
可中断锁
可中断锁顾名思义,就是可以中断的锁。如果某一线程A正在执行锁中的代码,另一线程B正在等待获取该锁,可能由于等待时间过长,线程B不想等待了,想先处理其他事情,我们可以让它中断自己或者在别的线程中中断它,这种就是可中断锁。
在Java中synchronized就是不可中断锁,Lock是可中断锁。
java
public class SynchronizedExample {
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
try {
Thread.sleep(5000); // 模拟线程持有锁的操作
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}, "Thread-1");
Thread thread2 = new Thread(() -> {
synchronized (lock) {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
}
}, "Thread-2");
thread1.start();
Thread.sleep(1000); // 让Thread-1先获取锁
thread2.start();
// 等待线程执行完成
thread1.join();
thread2.join();
}
}
java
public class LockExample {
private static final Lock lock = new ReentrantLock();
public static void main(String[] args) throws InterruptedException {
Thread thread1 = new Thread(() -> {
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
Thread.sleep(5000); // 模拟线程持有锁的操作
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}, "Thread-1");
Thread thread2 = new Thread(() -> {
try {
if (lock.tryLock()) { // 可中断地尝试获取锁
try {
System.out.println(Thread.currentThread().getName() + " acquired the lock");
} finally {
lock.unlock();
}
} else {
System.out.println(Thread.currentThread().getName() + " unable to acquire the lock");
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}, "Thread-2");
thread1.start();
Thread.sleep(1000); // 让Thread-1先获取锁
thread2.start();
// 等待线程执行完成
thread1.join();
thread2.join();
}
}互斥锁
互斥锁是一种用于多线程编程中的同步原语,用于确保在任何时刻,只有一个线程可以访问共享资源,从而避免数据竞争和并发访问的冲突。在编程中,引入了对象互斥锁的概念,来保证共享数据操作的完整性。每个对象都对应于一个可称为"互斥锁"的标记,这个标记用来保证在任一时刻,只能有一个线程访问该对象。
互斥锁在访问共享资源之前对对象进行加锁操作,在访问完成之后进行解锁操作。加锁后,任何其他试图再次加锁的线程会被阻塞,直到当前线程解锁其他线程才能访问公共资源。如果在解锁时有多个线程在等待获取锁,一旦锁被释放,它们将竞争重新获取锁。只有第一个竞争到锁的线程会变为就绪状态并开始执行,其他线程将继续等待。
在Java里最基本的互斥手段就是使用synchronized关键字、ReentrantLock。
java
public class SynchronizedMutexExample {
private static int counter = 0;
private static final Object lock = new Object();
public static void main(String[] args) throws InterruptedException {
Runnable task = () -> {
synchronized (lock) {
for (int i = 0; i < 10000; i++) {
counter++;
}
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Counter: " + counter);
}
}死锁
死锁并不是Java程序中通俗意义上的"锁",而是程序中出现的一种问题。之所以放到"锁"这个标题下是为了方便类比,就类似谐音梗吧。
死锁是指两个或多个线程在执行过程中,由于竞争资源或者互相等待释放资源而造成的一种僵局,使得所有参与的线程无法继续执行。举个例子,当线程A持有锁a并尝试获取锁b,线程B持有锁b并尝试获取锁a时,就会出现死锁。简单来说,死锁问题的产生是由两个或者以上线程并行执行的时候,争夺资源而互相等待造成的。
java
public class MainTest {
public static void main(String[] args) {
String lockA = "lockA";
String lockB = "lockB";
new Thread(new ThreadHolderLock(lockA,lockB),"线程AAA").start();
new Thread(new ThreadHolderLock(lockB,lockA),"线程BBB").start();
}
}
class ThreadHolderLock implements Runnable{
private String lockA;
private String lockB;
public ThreadHolderLock(String lockA, String lockB){
this.lockA = lockA;
this.lockB = lockB;
}
@Override
public void run() {
synchronized (lockA){
System.out.println(Thread.currentThread().getName() + "\t 持有锁 "+ lockA+", 尝试获得"+ lockB);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (lockB){
System.out.println(Thread.currentThread().getName() + "\t 持有锁 "+ lockB+", 尝试获得"+ lockA);
}
}
}
}使用资源有序分配法避免死锁
想要如何避免死锁,就要弄清楚死锁出现的原因,造成死锁必须达成的4个条件:
- 互斥条件:一个资源每次只能被一个线程使用。例如,如果线程 A 已经持有的资源,不能再同时被线程 B 持有,如果线程 B 请求获取线程 A 已经占用的资源,那线程 B 只能等待,直到线程 A 释放了资源。
- 请求与保持条件:一个线程因请求资源而阻塞时,对已获得的资源保持不放。例如,当线程 A 已经持有了资源 1,又想申请资源 2,而资源 2 已经被线程 C 持有了,所以线程 A 就会处于等待状态,但是线程 A 在等待资源 2 的同时并不会释放自己已经持有的资源 1。
- 不剥夺条件:线程已获得的资源,在未使用完之前,不能强行剥夺。例如,当线程A已经持有了资源 ,在自己使用完之前不能被其他线程获取,线程 B 如果也想使用此资源,则只能在线程 A 使用完并释放后才能获取。
- 循环等待条件:若干线程之间形成一种头尾相接的循环等待资源关系。比如,线程 A 已经持有资源 2,而想请求资源 1, 线程 B 已经获取了资源 1,而想请求资源 2,这就形成资源请求等待的环。
避免死锁的产生就只需要破环其中一个条件就可以,最常见的并且可行的就是使用资源有序分配法,来破循环等待条件。资源有序分配法指的是,线程 A 和 线程 B 获取资源的顺序要一样,当线程 A 先尝试获取资源 A,然后尝试获取资源 B 的时候,线程 B 同样也是先尝试获取资源 A,然后尝试获取资源 B。也就是说,线程 A 和 线程 B 总是以相同的顺序申请自己想要的资源。给资源分配一个全局的唯一编号,进程必须按资源编号的顺序请求资源。这种方法可以避免循环等待,从而防止死锁。
java
class Resource {
private final int id;
public Resource(int id) {
this.id = id;
}
public int getId() {
return id;
}
}
class Process extends Thread {
private final int id;
private final Resource[] resources;
public Process(int id, Resource[] resources) {
this.id = id;
this.resources = resources;
}
@Override
public void run() {
try {
acquireResources();
// 模拟处理
Thread.sleep((int) (Math.random() * 1000));
releaseResources();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void acquireResources() throws InterruptedException {
for (Resource resource : resources) {
synchronized (resource) {
System.out.println("Process " + id + " acquired Resource " + resource.getId());
}
}
}
private void releaseResources() {
for (Resource resource : resources) {
synchronized (resource) {
System.out.println("Process " + id + " released Resource " + resource.getId());
}
}
}
}
public class ResourceOrderingExample {
public static void main(String[] args) {
Resource resource1 = new Resource(1);
Resource resource2 = new Resource(2);
Resource resource3 = new Resource(3);
Process process1 = new Process(1, new Resource[]{resource1, resource2});
Process process2 = new Process(2, new Resource[]{resource2, resource3});
Process process3 = new Process(3, new Resource[]{resource3, resource1});
process1.start();
process2.start();
process3.start();
}
}使用银行家算法避免死锁
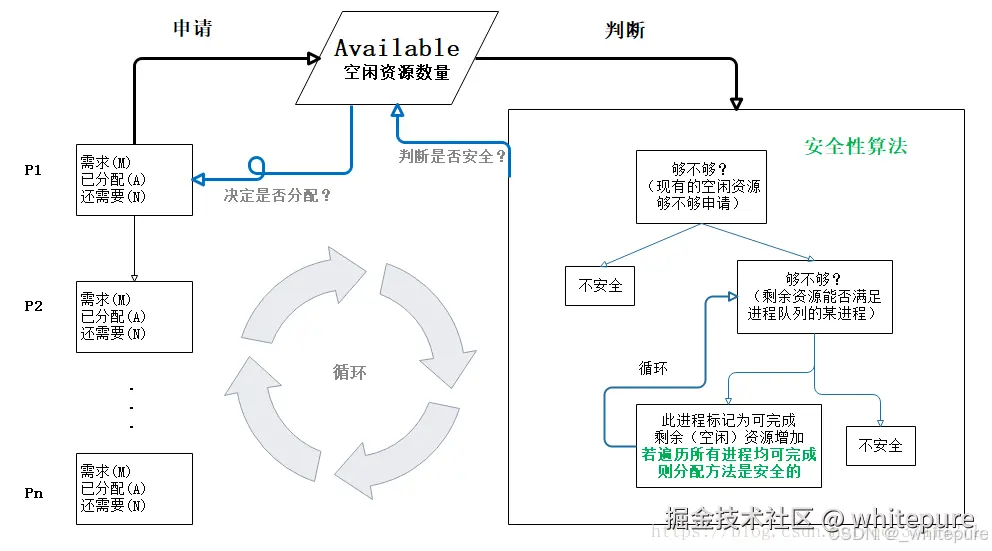
银行家算法:一个避免死锁的著名算法,是由艾兹格·迪杰斯特拉在1965年为T.H.E系统设计的一种避免死锁产生的算法。它以银行借贷系统的分配策略为基础,判断并保证系统的安全运行。
在银行中,客户申请贷款的数量是有限的,每个客户在第一次申请贷款时要声明完成该项目所需的最大资金量,在满足所有贷款要求时,客户应及时归还。银行家在客户申请的贷款数量不超过自己拥有的最大值时,都应尽量满足客户的需要。通过判断借贷是否安全,然后决定借不借。举例,现有公司B、公司A、公司T,想要从银行分别贷款70亿、40亿、50亿,假设银行只有100亿供放贷,如果借不到企业最大需求的钱,钱将不会归还,怎么才能合理的放贷?
| 公司 | 最大需求 | 已借走 | 最多还借 |
|---|---|---|---|
| B | 70 | 20 | 50 |
| A | 40 | 10 | 30 |
| T | 50 | 30 | 20 |
此时公司B、A、T已经从银行借走60亿,银行还剩40亿。此时银行可放贷金额组合:
- 借给公司B10亿、公司A10亿、公司T20亿,等待公司T还钱再将10亿借给公司A,等待公司A还钱,再将钱借给公司B;
- 借给公司T20亿,等公司T还钱再将钱借给公司A,等待公司A还钱再将钱借给公司B;
- 借给公司A10亿,等待公司A还钱再将钱借给公司T,公司T还钱再将钱借给公司B;
java
class Banker {
private int[] available; // 系统可用资源
private int[][] maximum; // 每个进程的最大资源需求
private int[][] allocation; // 每个进程当前已分配的资源
private int[][] need; // 每个进程剩余的资源需求
public Banker(int[] available, int[][] maximum) {
this.available = available;
this.maximum = maximum;
int numProcesses = maximum.length;
int numResources = available.length;
allocation = new int[numProcesses][numResources];
need = new int[numProcesses][numResources];
for (int i = 0; i < numProcesses; i++) {
for (int j = 0; j < numResources; j++) {
need[i][j] = maximum[i][j]; // 初始时,Need等于Maximum
}
}
}
// 请求资源的方法
public synchronized boolean requestResources(int processId, int[] request) {
if (!isRequestValid(processId, request)) {
return false; // 请求不合法,拒绝请求
}
// 试探性分配
for (int i = 0; i < available.length; i++) {
available[i] -= request[i];
allocation[processId][i] += request[i];
need[processId][i] -= request[i];
}
// 安全性检查
boolean safe = isSafeState();
if (!safe) {
// 如果不安全,恢复试探性分配前的状态
for (int i = 0; i < available.length; i++) {
available[i] += request[i];
allocation[processId][i] -= request[i];
need[processId][i] += request[i];
}
}
return safe;
}
private boolean isRequestValid(int processId, int[] request) {
for (int i = 0; i < request.length; i++) {
if (request[i] > need[processId][i] || request[i] > available[i]) {
return false; // 请求超出需求或可用资源
}
}
return true;
}
private boolean isSafeState() {
int[] work = available.clone();
boolean[] finish = new boolean[allocation.length];
while (true) {
boolean found = false;
for (int i = 0; i < allocation.length; i++) {
if (!finish[i]) {
boolean canProceed = true;
for (int j = 0; j < work.length; j++) {
if (need[i][j] > work[j]) {
canProceed = false;
break;
}
}
if (canProceed) {
for (int j = 0; j < work.length; j++) {
work[j] += allocation[i][j];
}
finish[i] = true;
found = true;
}
}
}
if (!found) {
break;
}
}
for (boolean f : finish) {
if (!f) {
return false; // 存在未完成的进程,系统不安全
}
}
return true; // 所有进程都完成,系统安全
}
}
java
public class BankerExample {
public static void main(String[] args) {
int[] available = {3, 3, 2};
int[][] maximum = {
{7, 5, 3},
{3, 2, 2},
{9, 0, 2},
{2, 2, 2},
{4, 3, 3}
};
Banker banker = new Banker(available, maximum);
int[] request1 = {1, 0, 2};
boolean granted1 = banker.requestResources(1, request1);
System.out.println("Request 1 granted: " + granted1);
int[] request2 = {3, 3, 0};
boolean granted2 = banker.requestResources(4, request2);
System.out.println("Request 2 granted: " + granted2);
int[] request3 = {2, 0, 0};
boolean granted3 = banker.requestResources(0, request3);
System.out.println("Request 3 granted: " + granted3);
}
}使用tryLock进行超时锁定
使用 java.util.concurrent.locks.ReentrantLock 的 tryLock方法可以尝试获取锁,并设置超时时间,避免长时间等待造成的死锁。
java
class Process extends Thread {
private final int id;
private final Lock lock1;
private final Lock lock2;
public Process(int id, Lock lock1, Lock lock2) {
this.id = id;
this.lock1 = lock1;
this.lock2 = lock2;
}
@Override
public void run() {
try {
while (true) {
if (lock1.tryLock(50, TimeUnit.MILLISECONDS)) {
try {
if (lock2.tryLock(50, TimeUnit.MILLISECONDS)) {
try {
System.out.println("Process " + id + " acquired both locks");
// 模拟处理
Thread.sleep((int) (Math.random() * 1000));
return;
} finally {
lock2.unlock();
}
}
} finally {
lock1.unlock();
}
}
// 等待一段时间再重试
Thread.sleep((int) (Math.random() * 50));
}
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public class TryLockExample {
public static void main(String[] args) {
Lock lock1 = new ReentrantLock();
Lock lock2 = new ReentrantLock();
Process process1 = new Process(1, lock1, lock2);
Process process2 = new Process(2, lock2, lock1);
process1.start();
process2.start();
}
}