前言
领域驱动设计(DDD,Domain-Driven Design)是一套以业务领域知识为中心、以统一语言和模型为驱动的复杂软件系统设计方法学。
它的核心思想是:把技术实现与业务知识深度融合,让代码成为业务概念的忠实映射,从而持续交付真正解决业务问题的软件。
领域驱动设计相关概念
领域模型
领域模型是业务概念在程序中的一种表达方式。
领域模型可以用来设计和理解整个软件结构。面向对象设计中的类概念是领域模型的一种表达方式。与此类似,UML的建模方法也可以应用在对领域模型的表达上。
但是要区分的一点就是,领域模型≠数据模型。
领域模型的组成元素:实体、值对象、聚合、领域服务、领域事件
实体(Entity)
实体通常指具有唯一标识的具体对象或事物。
实体通常具有自己的生命周期,可以被创建、修改和删除。
在数据库中,实体通常对应着数据库表的一行记录,每个实体具有唯一的标识符(通常是主键)。
在代码模型中,实体的表现形式是实体类,这个类包含了实体的属性和方法,通过这些方法实现实体自身的业务逻辑。
值对象(Value Object)
值对象(Value Object)是通过对象属性值来识别的对象,它将多个相关属性组合为一个概念整体。
实体可以使用 ID 标识,但是值对象是用属性标识,值对象通常不可变,一旦创建就不能修改,只能通过创建新的值对象来替换原来的值对象。
在数据库中,值对象通常对应着数据库表的一组字段,每个值对象不具有唯一的标识符而是通过一组字段来描述其属性。
值对象在代码中有这样两种形态。
- 如果值对象是单一属性,则直接定义为实体类的属性;
- 如果值对象是属性集合,则把它设计为 Class 类,Class 将具有整体概念的多个属性归集到属性集合,这样的值对象没有 ID,会被实体整体引用。
聚合
聚合(Aggregate)是由一个或多个强关联的实体和值对象组成的集合。
领域模型内的实体和值对象就好比个体,而能让实体和值对象协同工作的组织就是聚合,它用来确保这些领域对象在实现共同的业务逻辑时,能保证数据的一致性。
聚合有一个聚合根和上下文边界,这个边界根据业务单一职责和高内聚原则,定义了聚合内部应该包含哪些实体和值对象,而聚合之间的边界是松耦合的。按照这种方式设计出来的微服务很自然就是"高内聚、低耦合"的
聚合根
聚合根(Aggregate Root)是聚合的根实体,它不仅是实体,也是聚合的管理者,管理着聚合内其他对象的生命周期和完整性。
聚合根是聚合中的唯一标识符,是整个聚合的唯一入口点,所有的操作都是通过聚合根来进行的。
领域服务
领域服务(Domain Service)主要用于处理那些不适合放在实体(Entity)或值对象(Value Object)中的业务逻辑。
领域服务具有以下特点:
- 领域逻辑的封装 :领域服务封装了领域特定的业务逻辑,这些逻辑通常涉及多个领域对象的交互,这种封装有助于保持实体和值对象的职责单一和清晰
- 无状态:领域服务通常是无状态的,它们不保存任何业务数据,而是操作领域对象来完成业务逻辑。这有助于保持服务的可重用性和可测试性。
- 独立性:领域服务通常与特定的实体或值对象无关,它们提供了一种独立于领域模型的其他部分的方式来实现业务规则
- 重用性:领域服务可以被不同的应用请求重用,例如不同的应用服务编排或领域事件处理器
- 接口清晰:领域服务的接口应该清晰的反映其提供的业务能力,参数的返回值应该是领域对象或基本数据类型
领域事件
领域事件(Domain Event)代表领域中的发生的重要事件,可以用于通知其他领域对象或跨限界上下文进行解耦和协作。
这些事件通常是由领域实体或聚合根的状态变化触发的。领域事件不仅仅是数据的变化,它们还承载了业务上下文和业务意图。
领域事件具有以下特点:
- 意义明确:领域事件通常具有明确的业务含义,例如"用户已下单"、"商品已支付"等。
- 不可变性:一旦领域事件被创建,它的状态就不应该被改变。这有助与确保事件的一致性和可靠性。
- 时间相关性:领域事件通常包括事件发生的时间戳,这有助于追踪事件的顺序和时间线
- 关联性:领域事件可能被特定的领域实体和聚合根相关联,者有助于完成事件上下文
- 可观察性:领域事件可以被其他部分的系统监听和响应,有助于实现系统间解耦
领域事件和我们常听说的MQ中的事件不一样,一般不会在分布式系统之间传递,只会在单个微服务内部传递。
它起到最大的好处和MQ一样,就是解耦,通过事件的方式来解除领域之间的耦合,通过发布事件的方式进行一种松耦合的通信,而不用依赖具体的实现细节。
领域模型分层架构
DDD的分层架构是一个四层架构,从上到下依次是:用户接口层、应用层、领域层和基础层。
分层架构可以简单分为两种,即严格分层架构和松散分层架构。在严格分层架构中,某层只能与位于其直接下方的层发生耦合,而在松散分层架构中,则允许某层与它的任意下方层发生耦合。
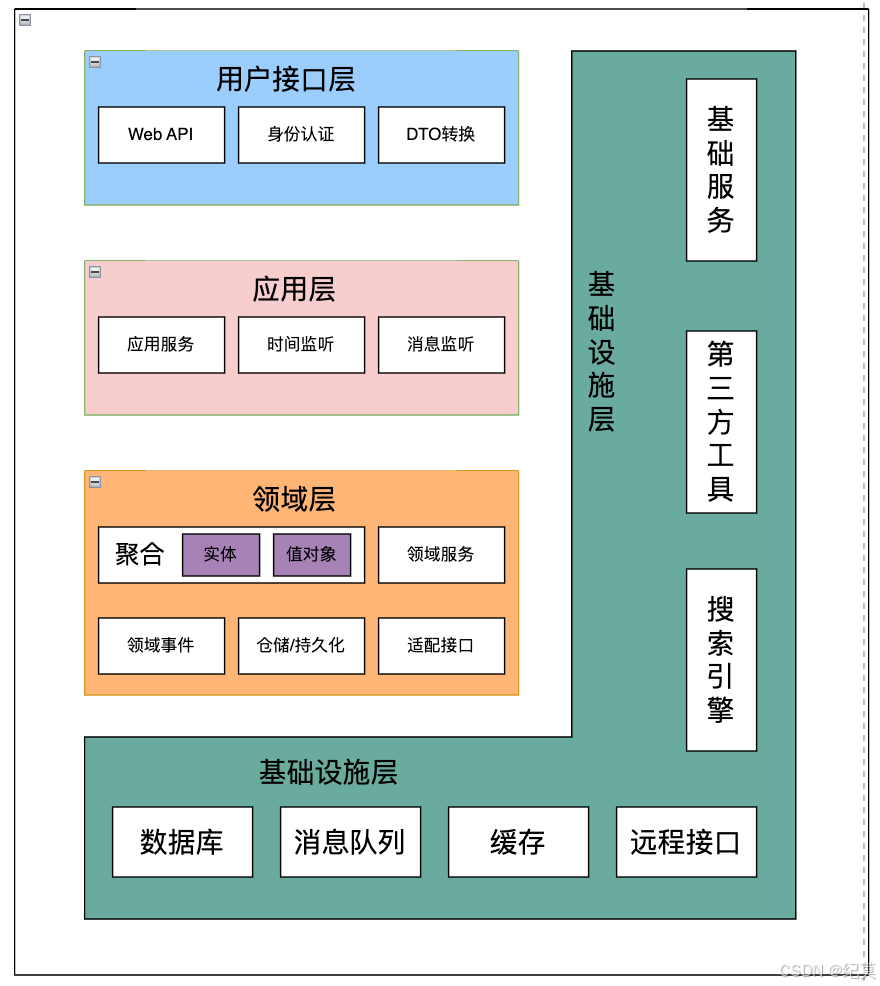
这种分层的结构的优点有:
- 开发人员可以只关注整个结构中的某一层。
- 可以很容易的用新的实现来替换原有层次的实现。
- 可以降低层与层之间的依赖。
- 有利于标准化。
- 利于各层逻辑的复用。
当然也有一定的弊端:
- 降低了系统的性能。这是显然的,因为增加了中间层,不过可以通过缓存机制来改善。
- 可能会导致级联的修改。这种修改尤其体现在自上而下的方向,不过可以通过依赖倒置来改善。
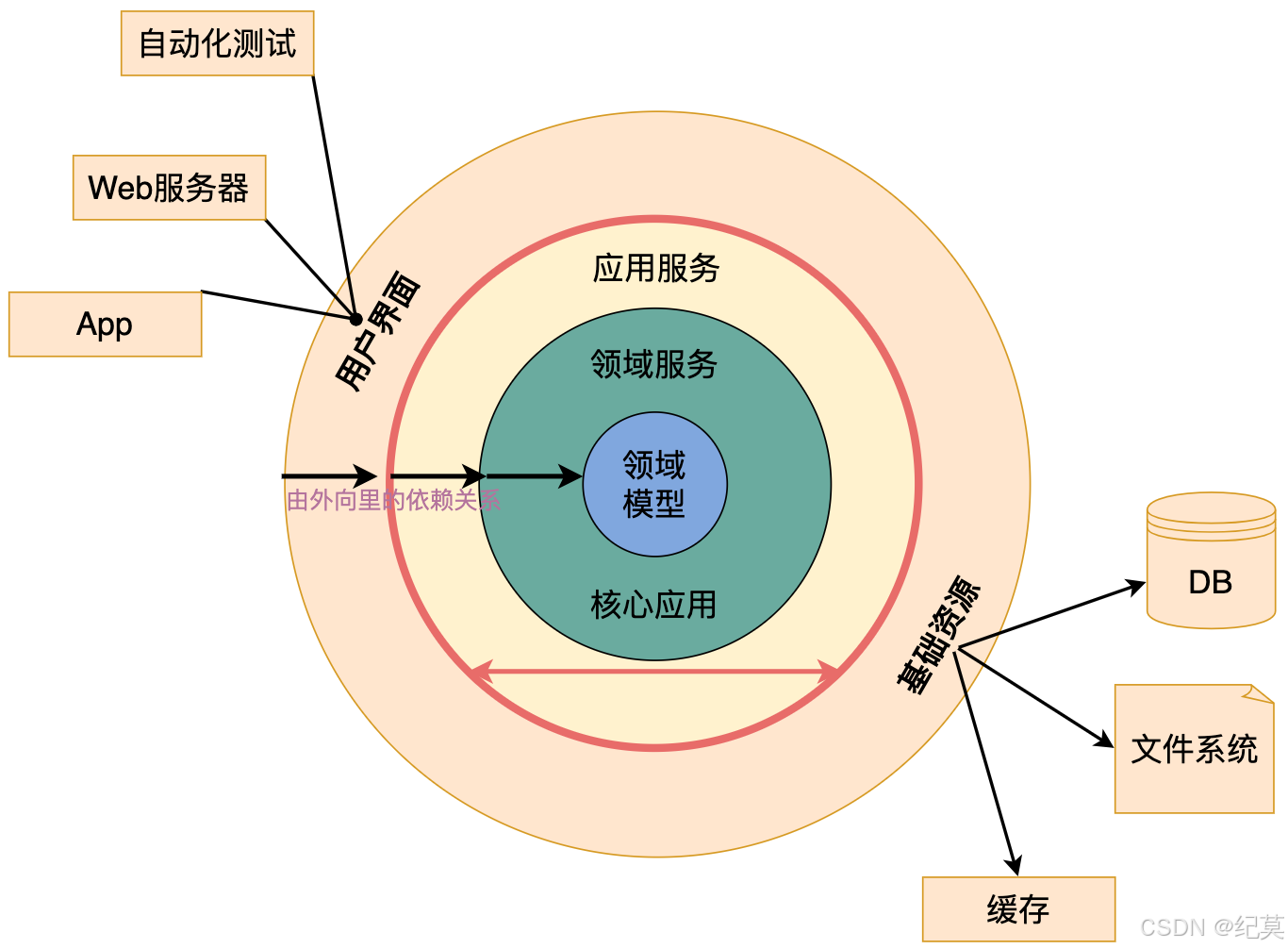
洋葱分层架构
洋葱架构,就是像洋葱一样的一层一层,从外到内的架构形式,如下图
六边形分层架构
六边形架构是 Alistair Cockburn 在2005年提出,解决了传统的分层架构所带来的问题,实际上它也是一种分层架构,只不过不是上下或左右,而是变成了内部和外部。六边形架构又名"端口-适配器架构":
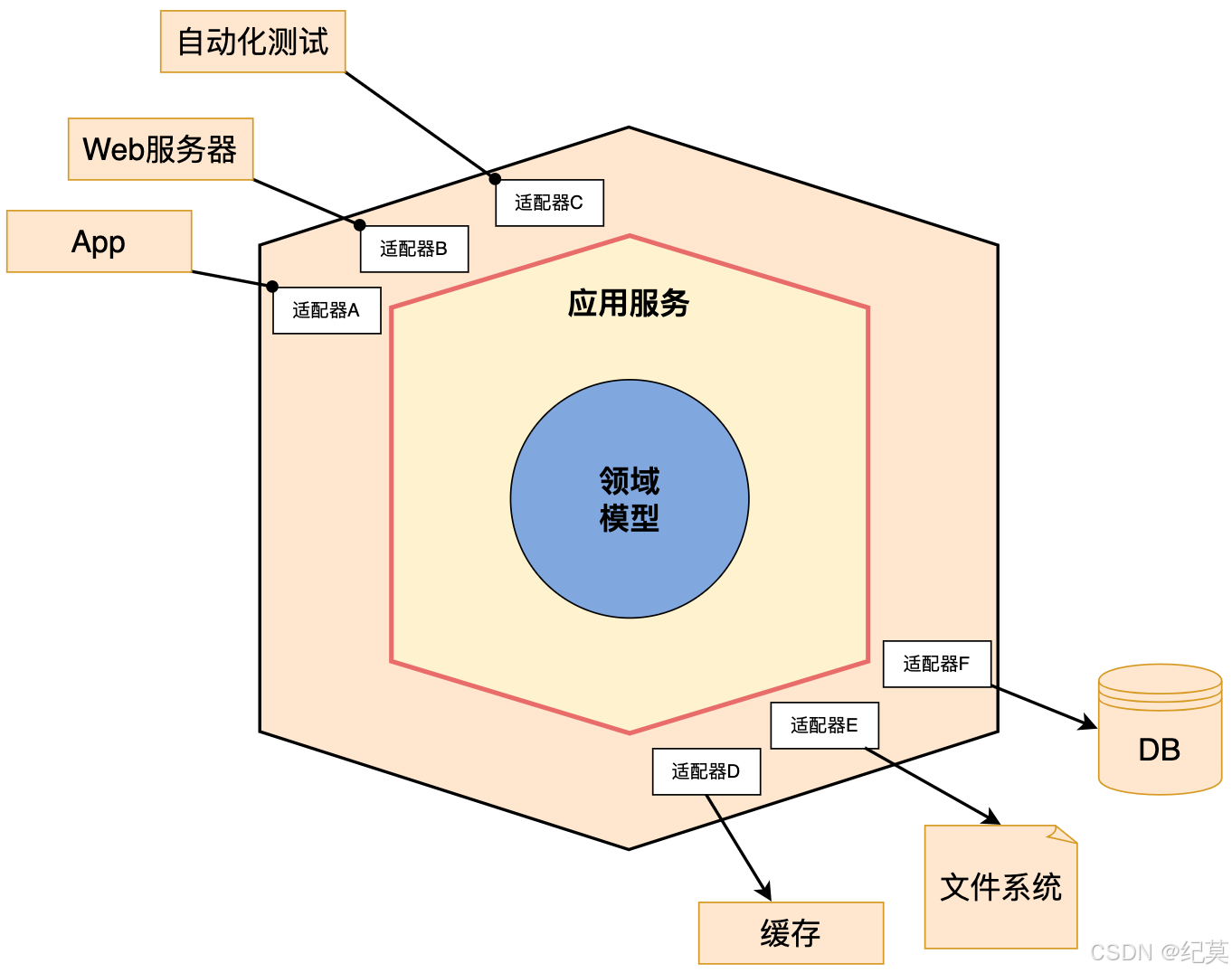
虽然 DDD 分层架构、洋葱架构(整洁架构)、六边形架构的架构模型表现形式不一样,但是这三种架构模型的设计思想都是微服务架构高内聚低耦合原则的完美体现,都是以领域模型为中心的设计思想。
领域模型设计相关
仓储
仓储(Repository)是用于管理领域对象的创建、更新和持久化的接口。
仓储充当领域模型和数据存储之间的中介,隐藏了底层的数据访问细节,提供了一致的接口和抽象,使得领域对象的访问和持久化变得简单和统一。
工厂
工厂(Factory)是以构建领域模型(实体或值对象)为职责的类或方法。
工厂可以利用不同的业务参数构建不同的领域模型。
对于简单的业务逻辑实现可以不使用工厂。工厂的实现不一定是类的形式,也可以是具备工厂功能的方法。
贫血模型
贫血模型(Anemic Domain Model)则是一种将数据与行为分离的模型,其中数据由对象持有,而行为则由外部服务提供。
它的主要特征是领域对象缺乏行为,通常只包含数据属性和简单的 getter 和 setter 方法,而业务逻辑则被放置在服务层中。
例如下面商品
java
/**
* 商品类
*/
public class Goods {
private String name;
private BigDecimal price;
private int count;
public Goods(String name, BigDecimal price, int count) {
this.name = name;
this.price = price;
this.count = count;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public BigDecimal getPrice() {
return price;
}
public void setPrice(BigDecimal price) {
this.price = price;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
}商品行为
java
public class GoodsService {
public void updatePrice(Goods goods, BigDecimal price){
if(Objects.isNull(price) || BigDecimal.ZERO.compareTo(price) > 0){
throw new RuntimeException("价格不能小于0");
}
goods.setPrice(price);
}
}充血模型
在领域驱动设计中,充血模型是一种设计模式,它强调在领域对象中封装数据和业务逻辑。
与贫血模型相对,充血模型将数据与行为结合在一起,使领域对象不仅仅是数据的容器,还能够包含与其状态相关的业务逻辑。
java
/**
* 商品类
*/
public class Goods {
private String name;
private BigDecimal price;
private int count;
public Goods(String name, BigDecimal price, int count) {
this.name = name;
this.price = price;
this.count = count;
}
public void updatePrice(Goods goods, BigDecimal price){
if(Objects.isNull(price) || BigDecimal.ZERO.compareTo(price) > 0){
throw new RuntimeException("价格不能小于0");
}
goods.setPrice(price);
}
}优缺点与使用场景
贫血模型的优点
- 数据与行为分离,降低了对象的复杂度。
- 可以提高代码的重用性和可测试性。
- 可以更好地利用现有的服务和框架。
贫血模型的缺点
- 对象缺乏封装性,易于出现耦合性和脆弱性。
- 业务逻辑被分散在多个类中,难以维护和理解。
- 过度依赖外部服务,可能导致系统的不稳定性。
充血模型的优点
- 面向对象设计,具有良好的封装性和可维护性。
- 领域对象自包含业务逻辑,易于理解和扩展。
- 可以避免过度依赖外部服务,提高系统的稳定性。
充血模型的缺点
- 需要对模型的理解才能更好的开发,上手成本高
- 对象间的协作可能增加,导致设计变得复杂。
- 对象的状态可能会变得不一致,需要特别注意。
一般来说,对于较小的应用系统或者简单的业务流程,可以使用贫血模型;对于较大的应用系统或者复杂的业务流程,建议使用充血模型。
防腐层
防腐层,用于保护系统的内部模型和业务逻辑不受外部系统或服务的影响。
它的主要目的是提供一个清晰的界面,隔离外部系统的变化,以防止它们对内部领域模型产生腐蚀或负面影响。
例如:当某个业务模块需要依赖第三方系统提供的数据或者功能时,我们常用的策略就是直接使用外部系统的API、数据结构。
这样存在的问题就是,因使用外部系统,而被外部系统的质量问题影响,从而"腐化"本身设计的问题。
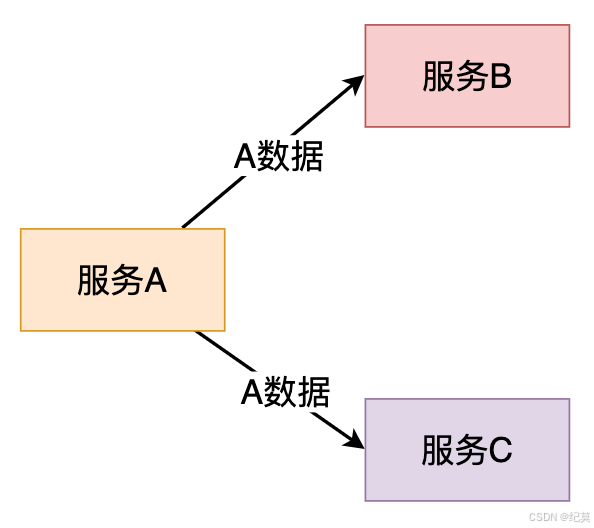
因此解决方案就是在两个系统之间加入一个中间层,隔离第三方系统的依赖,对第三方系统进行通讯转换和语义隔离,这个中间层,我们叫它防腐层。
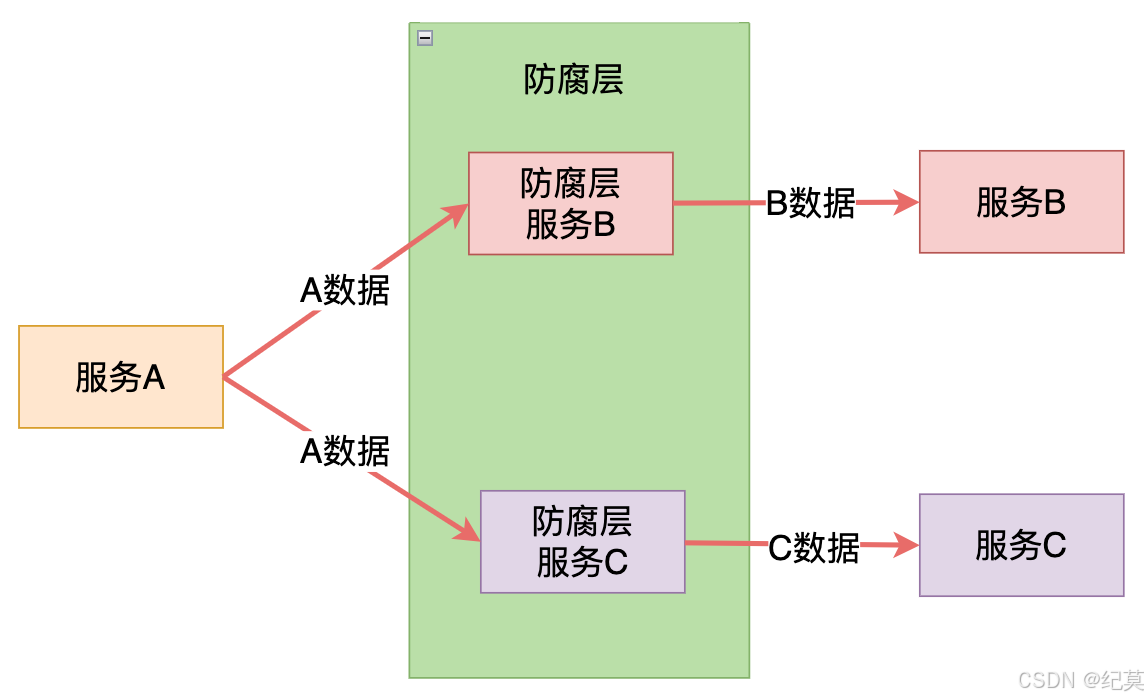
两个系统之间加了中间层,中间层类似适配器模式,解决接口差异的对接,接口转换是单向的(即从调用方向被调用方进行接口转换);防腐层强调两个子系统语义解耦,接口转换是双向的。
防腐层作用:
- 使两方的系统解耦,隔离双方变更的影响,允许双方独立演进。
- 防腐层允许其它的外部系统能够在不改变现有系统的领域层的前提下,与该系统实现无缝集成,从而降低系统集成的开发工作量。