大家好,我是程序员鱼皮。之前已经带大家完成了 AI 零代码应用生成平台 的核心功能,能够一句话生成复杂网站,并支持实时浏览和可视化修改。
但是作为一个对标大厂的项目,光实现功能怎么足够呢?
我们还要为项目添加全面的 可观测性 能力,让系统运行状态变得透明可见,为用户提供可靠稳定的服务。
说直白一点,这也是玩具项目和企业级项目的重要区别。我相信很多朋友的项目应该是做完了就扔那了,压根儿没想到要去监控它的运行状态吧。

下面就来带大家学习可观测性相关的技术,依然是保姆级教程:
- 可观测性介绍
- ARMS 系统监控
- Prometheus + Grafana 业务监控
⭐️ 推荐观看视频版:bilibili.com/video/BV1QP...
本项目代码开源:github.com/liyupi/yu-a...
编程导航的朋友们可以看到完整的项目教程:
一、可观测性介绍
可观测性(Observability)指通过系统的外部输出推断其内部状态的能力。在软件开发中,可观测性是指通过日志、指标和追踪等数据,全面了解系统的运行状况,以便及时发现和解决问题。
你可以简单将其理解为 "监控",但它又比监控的概念更广更深。
相关概念
接下来,我们了解一些和可观测性有关的概念。
维度和指标
维度是用来描述和分类数据的标签属性,比如用户 ID、应用 ID、模型名称等,关注 "是什么"。
指标是用来量化的数值数据,比如请求次数、响应时间、Token 消耗量等,关注 "有多少"。
简单来说,维度是可以用来筛选的标签,指标是用来计算的数值。
举个例子:
- 维度:user_id=12345, app_id=67890, model_name=deepseek-chat
- 指标:requests_total=100, response_time=1.5s, tokens_used=2000
监控的数据分类
在实现可观测性时,我们需要关注多种不同类型的数据:
1)系统指标:包括 CPU 使用率、内存占用、磁盘 I/O、网络流量等基础设施层面的监控数据。
2)应用指标:涵盖接口响应时间、QPS(每秒查询率)、错误率、JVM 状态等应用层面的性能数据。
3)业务指标:针对我们平台的特定业务逻辑,比如 AI 模型调用次数、Token 消耗量、用户活跃度等。
4)调用链:在分布式系统中,一个请求可能经过多个服务组件。Trace 表示一个完整请求的调用链路,而 Span 则代表调用链中的一个操作单元。通过分析 Trace 和 Span,我们可以清晰地看到请求在系统中的流转过程,快速定位性能瓶颈。

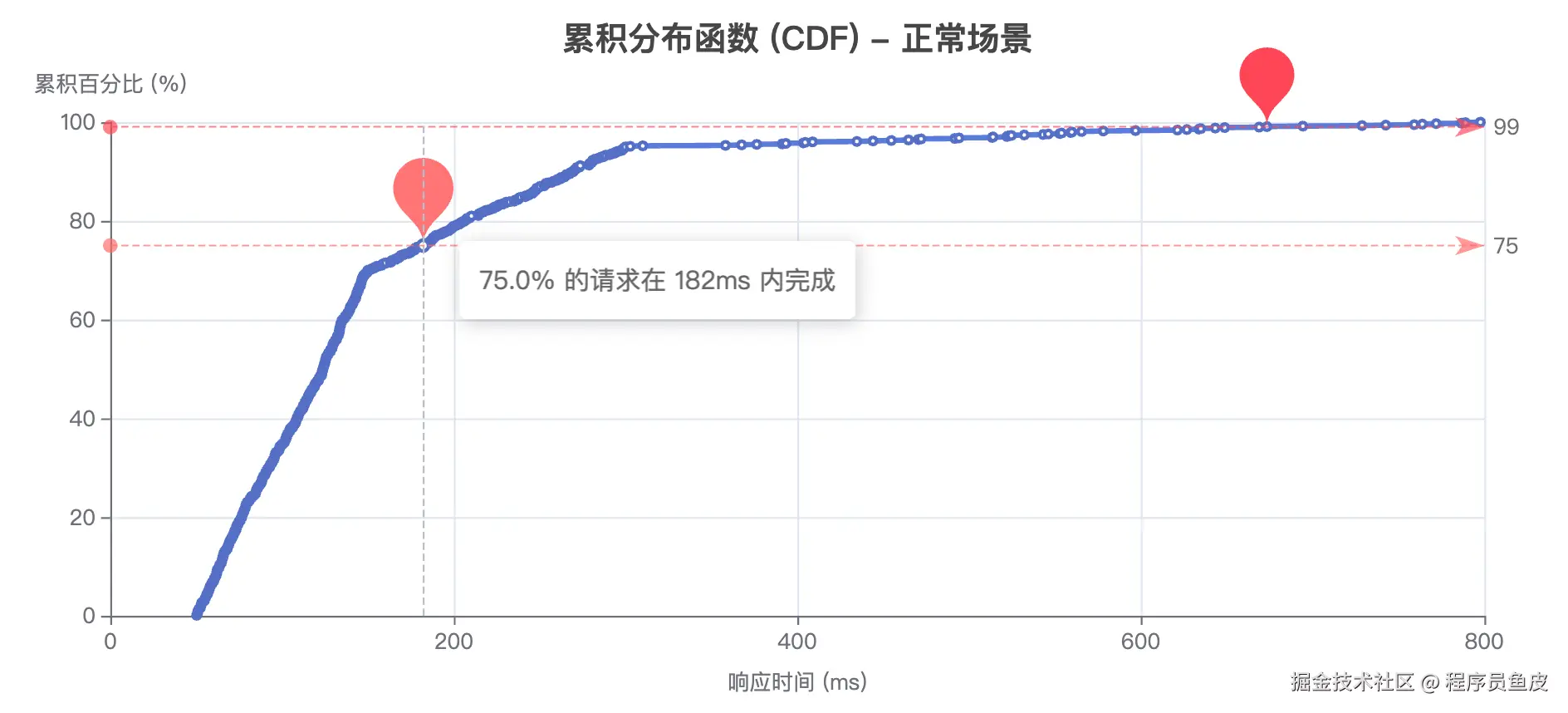
百分位数
在性能监控中,我们经常会看到 P50、P75、P90、P99 这些指标,它们被称为 百分位数。
- P50:中位数,表示 50% 的请求响应时间都在这个值以下
- P75:75% 的请求响应时间都在这个值以下
- P90:90% 的请求响应时间都在这个值以下
- P99:99% 的请求响应时间都在这个值以下
举个例子,如果一个接口的 P99 响应时间是 500ms,这意味着 99% 的请求都能在 500ms 内完成,只有 1% 的请求可能超过这个时间。P99 指标对于发现系统中的异常情况特别有用,因为它能反映出那些偶发的长尾延迟问题。
💡 注意,别把这玩意跟优先级 P0、P1、P2 搞混了。
怎么实现?
要构建完善的可观测性体系,我们需要解决几个核心问题:
1)统计什么?
需要根据业务特点确定关键指标,既要覆盖 系统层面 的通用指标,也要包含 业务特有 的监控维度。
2)如何收集?
数据收集是可观测性的基础,可以通过代码埋点、探针技术、日志分析等多种方式实现。
3)如何存储?
监控数据通常量大且连续,需要选择合适的存储方案,比如时序数据库或专门的监控系统。
4)如何展示?
最终需要通过直观的图表和仪表板将数据呈现给用户,一般会实时监控(页面自动刷新)。
接下来,在本项目中,我会带大家实战下面 2 种主流的可观测性实现方式:
1)利用 ARMS 平台进行系统指标监控:这是一种开箱即用的方案,通过集成阿里云 ARMS 等监控平台,可以快速获得系统层面的全面监控能力。
2)利用 Prometheus + Grafana 自定义业务指标监控:这是目前最主流的开源监控方案,提供了强大的自定义能力和丰富的生态支持。
二、ARMS 系统监控
什么是 ARMS?
ARMS 是阿里云提供的应用实时监控服务,采用了探针技术,能够在不修改应用代码的情况下,自动收集和分析应用性能数据,快速构建实时的监控能力。
还记得我们刚刚讲的 "怎么实现可观测性" 的 4 个核心问题么?ARMS 给出了这样的答案:
1)统计什么?
ARMS 能够监控 Java 应用性能(CPU、内存、线程、GC 等)、应用调用链追踪、异常分析诊断、请求数、错误数、平均耗时、连接池/线程池监控等全方位指标。
2)如何收集?
通过 Java Agent 技术,在 JVM 启动时加载监控代理,实现无侵入式的数据收集。
3)如何存储?
数据存储在阿里云的分布式存储系统中,用户无需关心存储细节。
4)如何展示?
ARMS 提供了丰富的 Web 控制台,支持多维度的数据分析和可视化展示。
接入 ARMS
在使用任何云产品之前,我们都需要先了解其 计费规则,保护好自己的 money。
好在 ARMS 提供的免费资源,一般足够个人测试使用:

下面我们来接入 ARMS,首先访问 ARMS 控制台,第一次使用需要开通服务。
进入接入中心,选择 Java 应用监控:
选择手动安装 Agent:
按照指引下载 Agent 包:
下载完成后解压到合适的位置。
复制启动命令,注意替换目录路径和应用名称。你也可以选择开启应用安全功能,它能够提供 应用层面的安全监控能力,帮你抵御一些漏洞攻击。
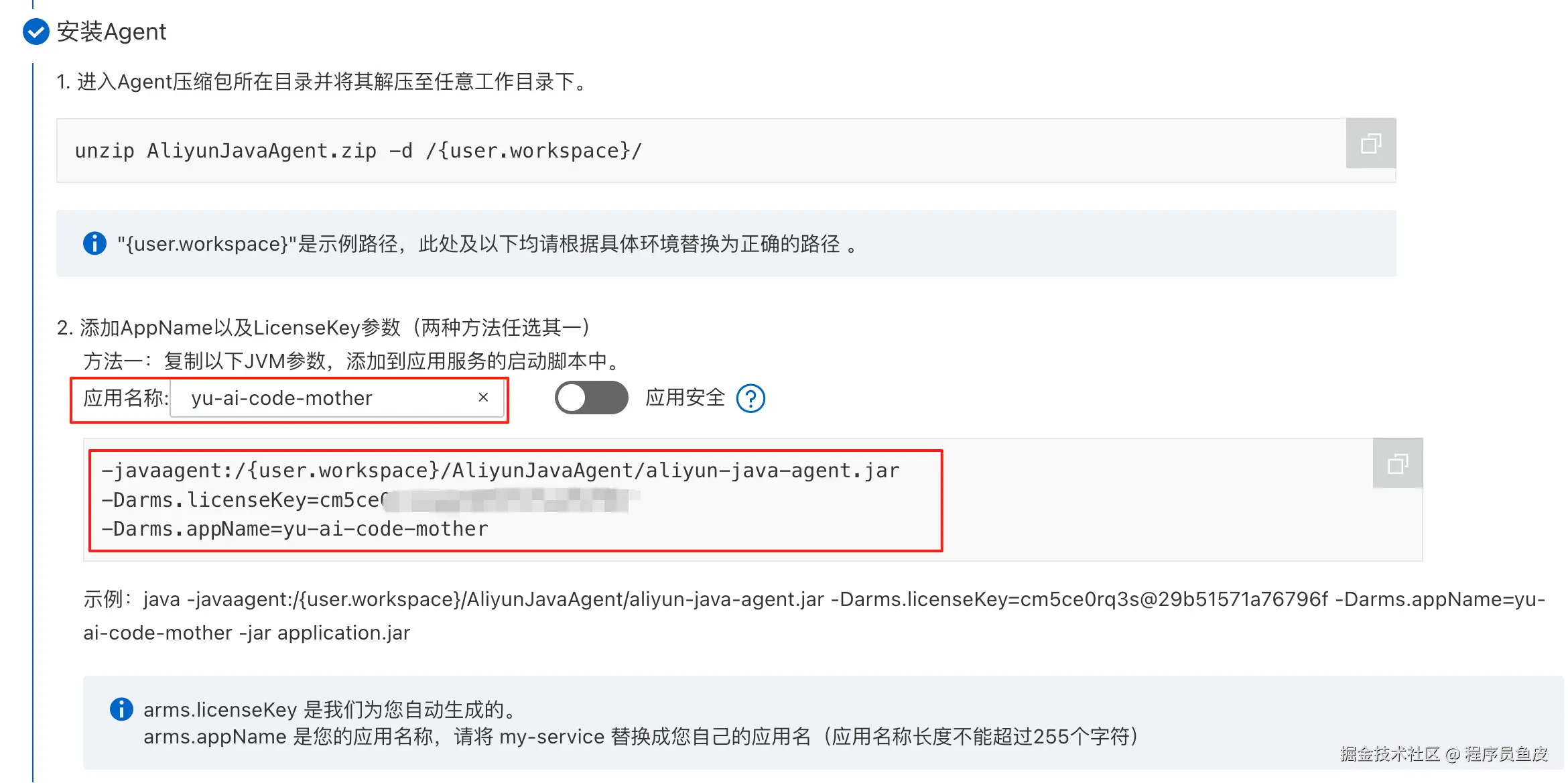
在 IDE 中编辑项目的启动配置,将复制的命令参数添加到 VM options 中:
ini
-javaagent:/Users/yupi/Tools/AliyunJavaAgent/aliyun-java-agent.jar
-Darms.licenseKey=xxx
-Darms.appName=yu-ai-code-mother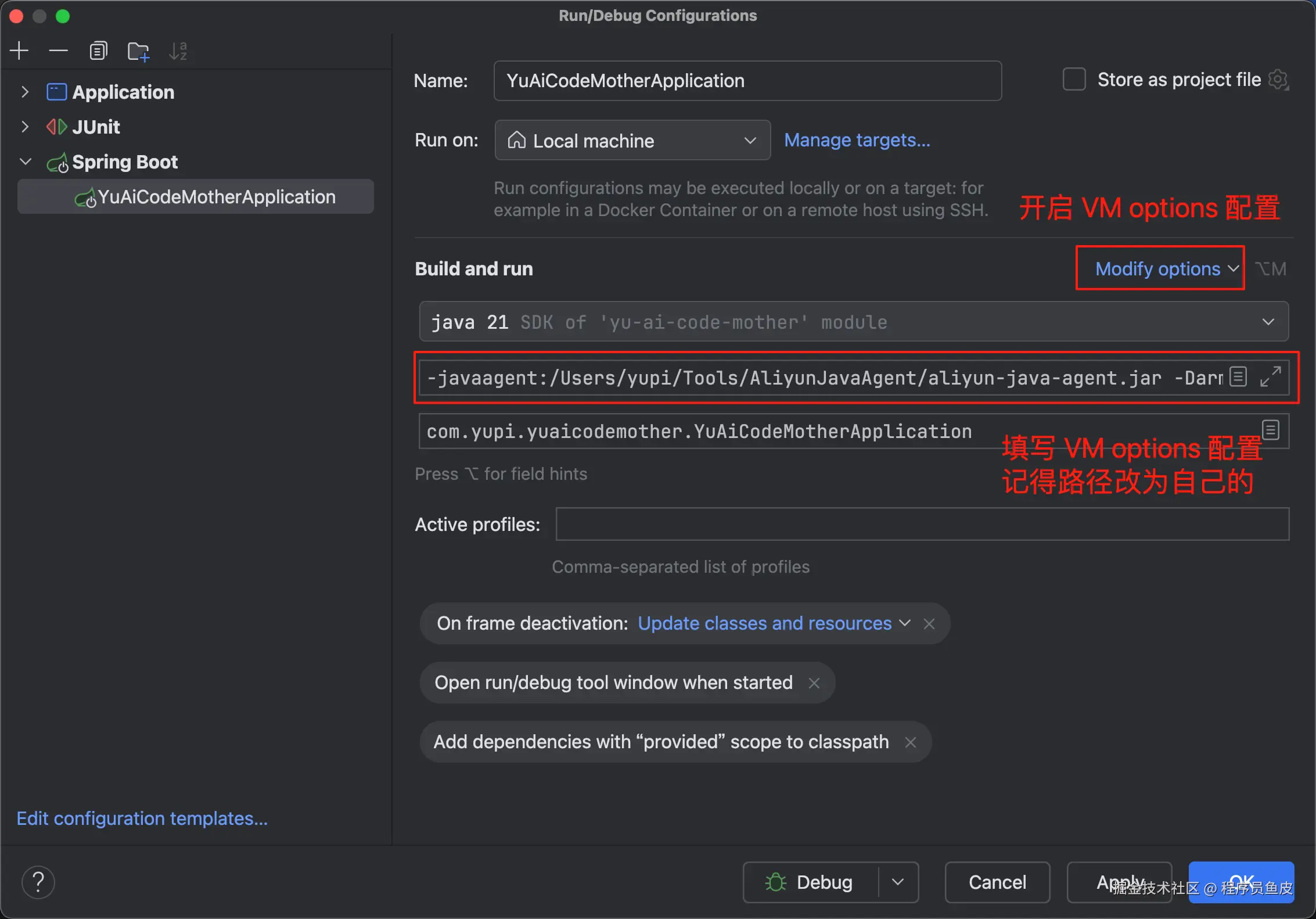
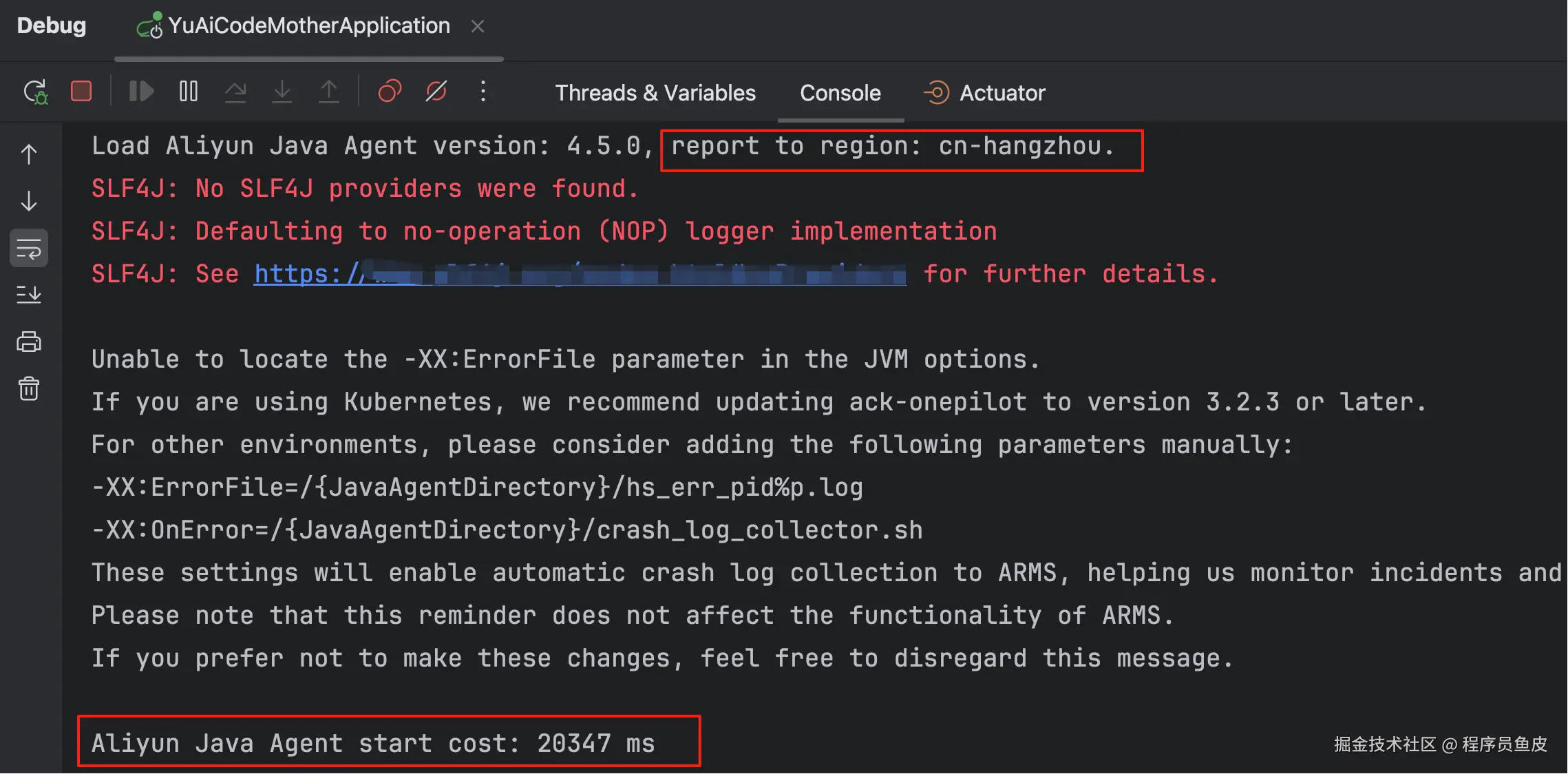
接下来启动项目。启动会比平时慢一些,这是正常的,因为引入 Agent 会拖慢启动速度。
看到下图信息就表示启动成功了,默认数据会上报到杭州区域:
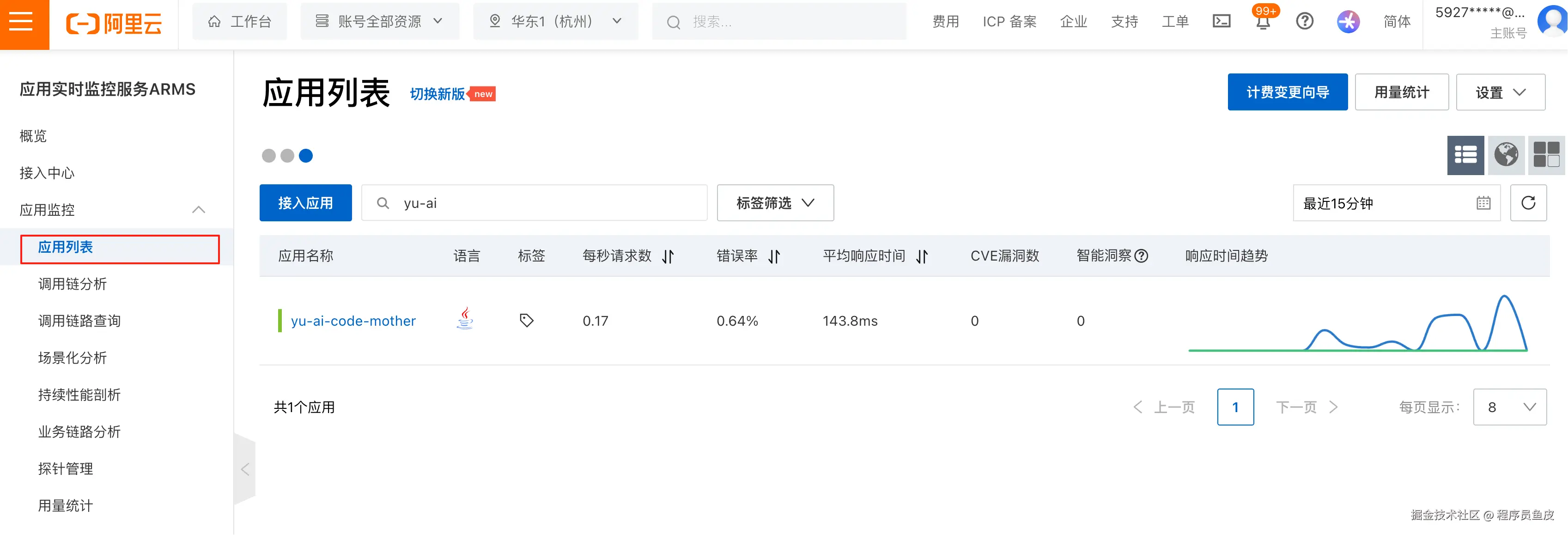
最后,回到 ARMS 控制台的应用列表页面,就能看到刚刚接入的应用了:
指标监控
下面我们来看看 ARMS 都提供了哪些指标的监控,有个印象就好。
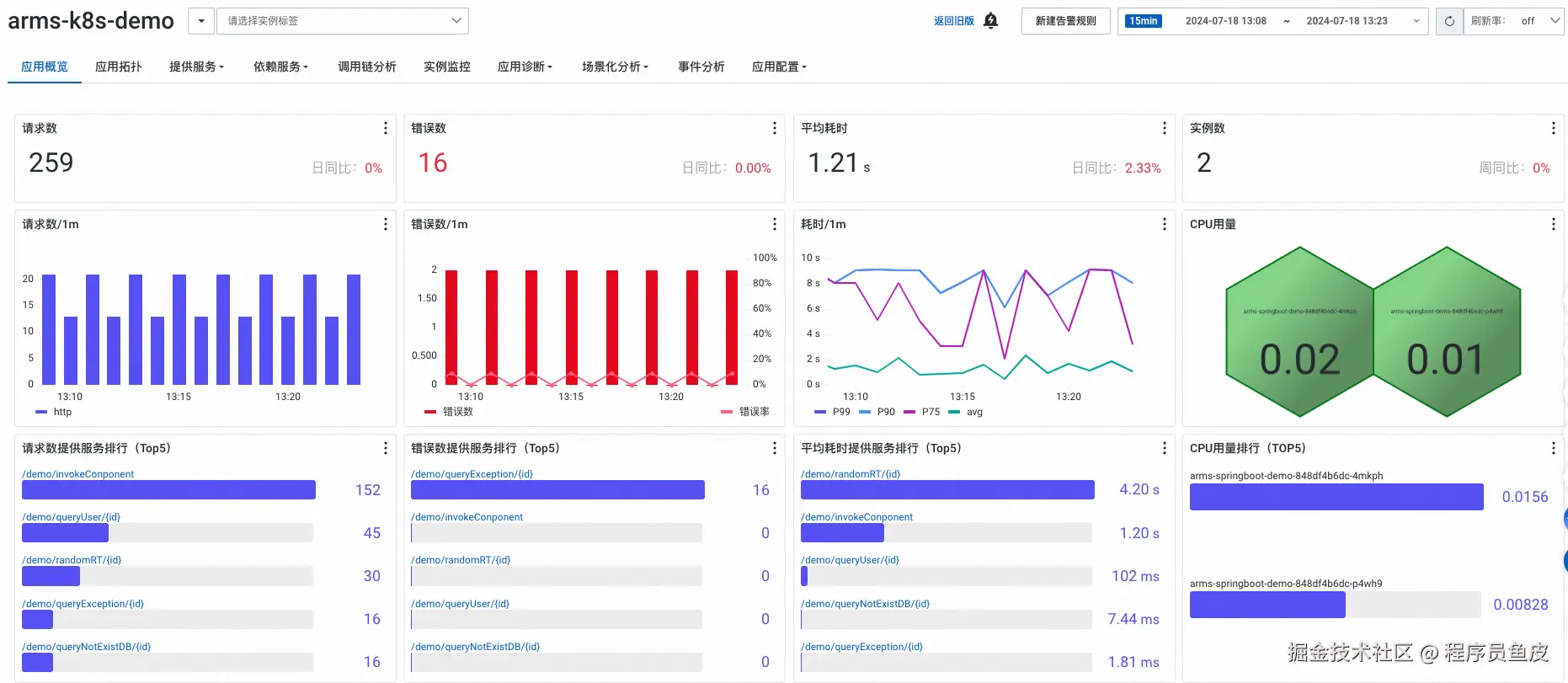
应用概览
点击进入应用详情页,首先看到的是应用概览 Tab。建议切换到新版视图,豁然开朗。
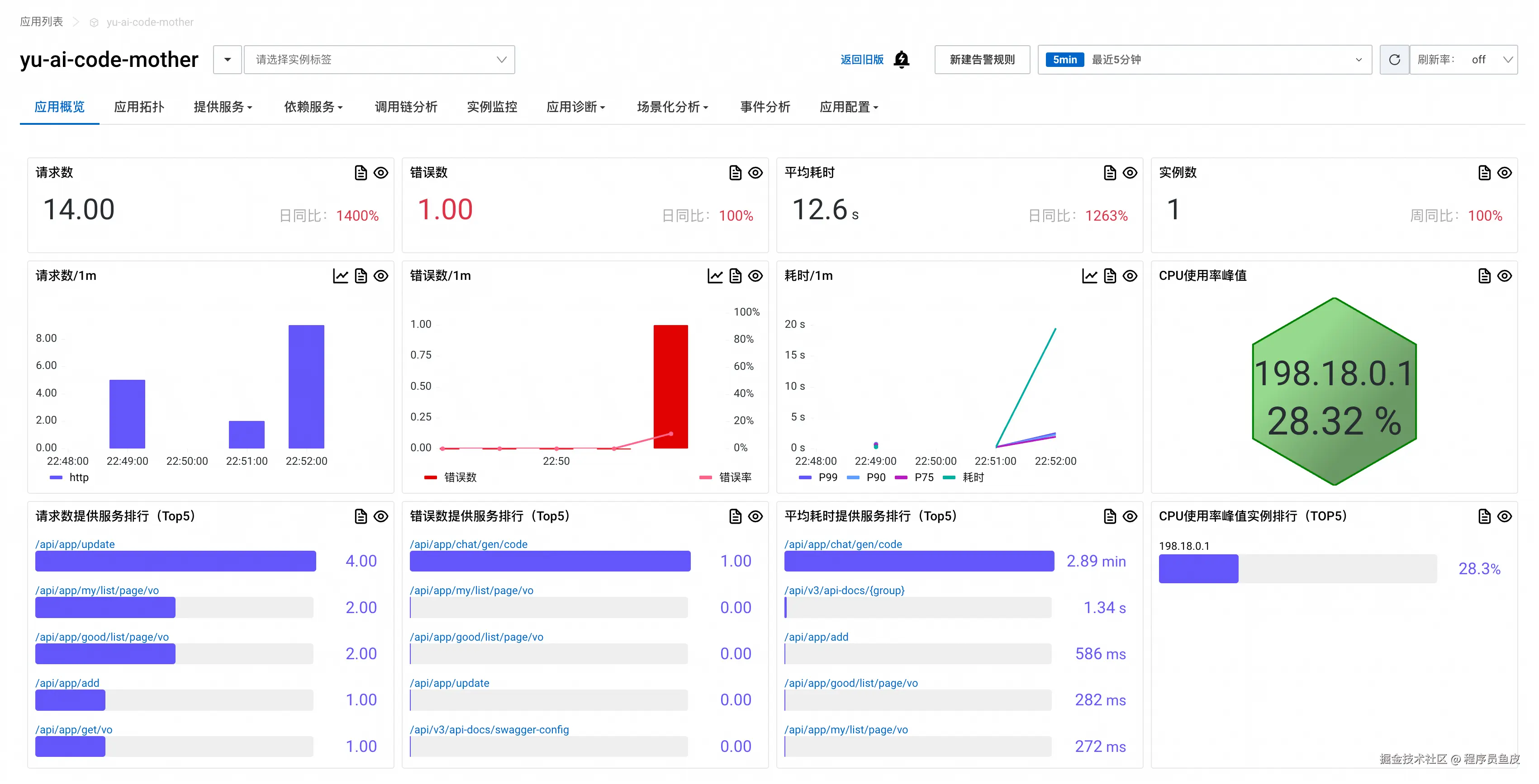
在这个页面可以看到应用的核心性能指标,包括请求数、响应时间、错误数等关键数据。
应用拓扑
应用拓扑页面展示了项目的依赖关系图,可以清晰地看到应用和各种中间件的连接情况:
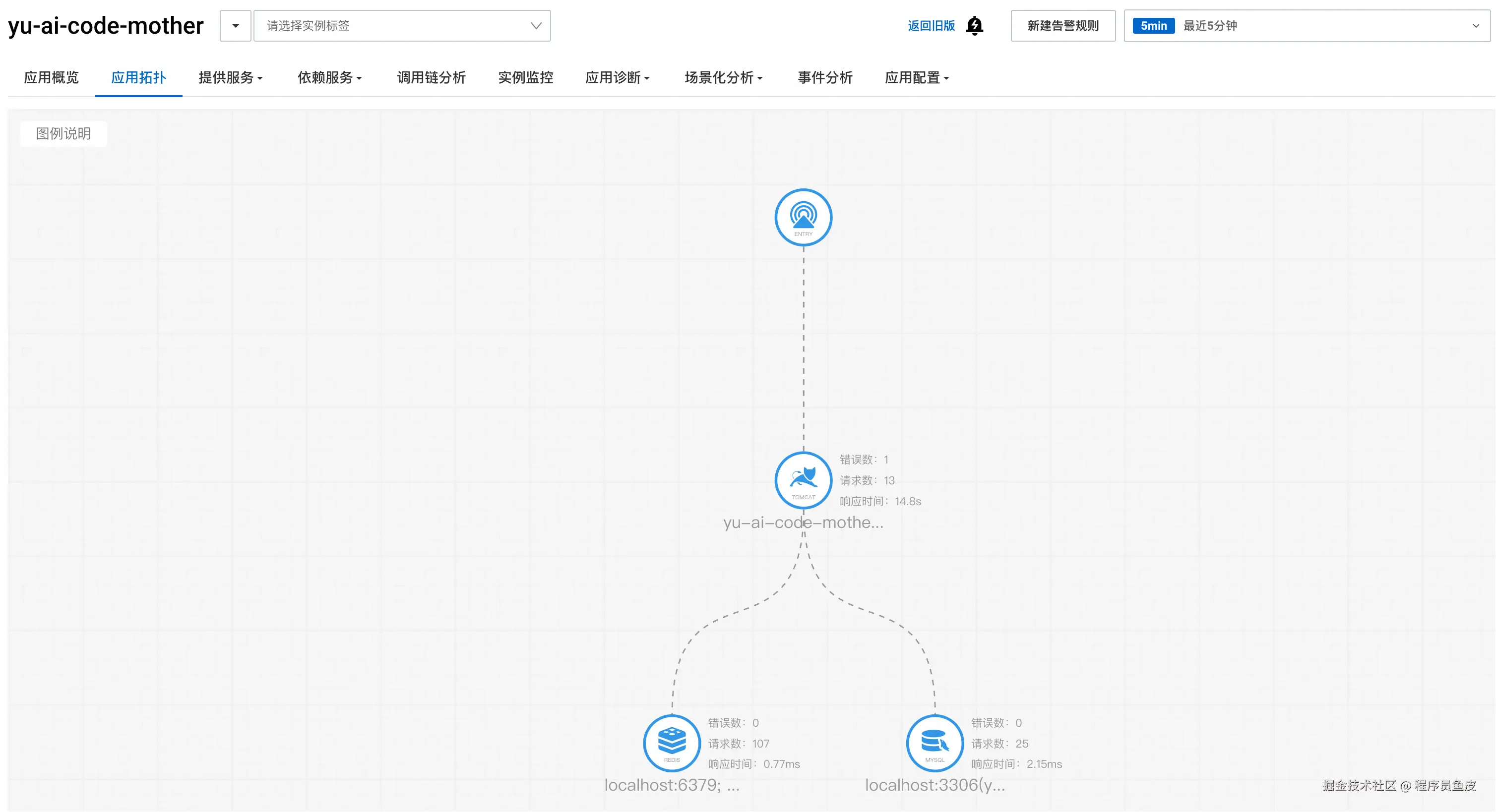
这个视图对于理解系统架构和排查依赖问题有用。
提供服务
提供服务页面能够统一展示所有接口的调用情况,包括请求量、错误数、平均耗时等核心指标:
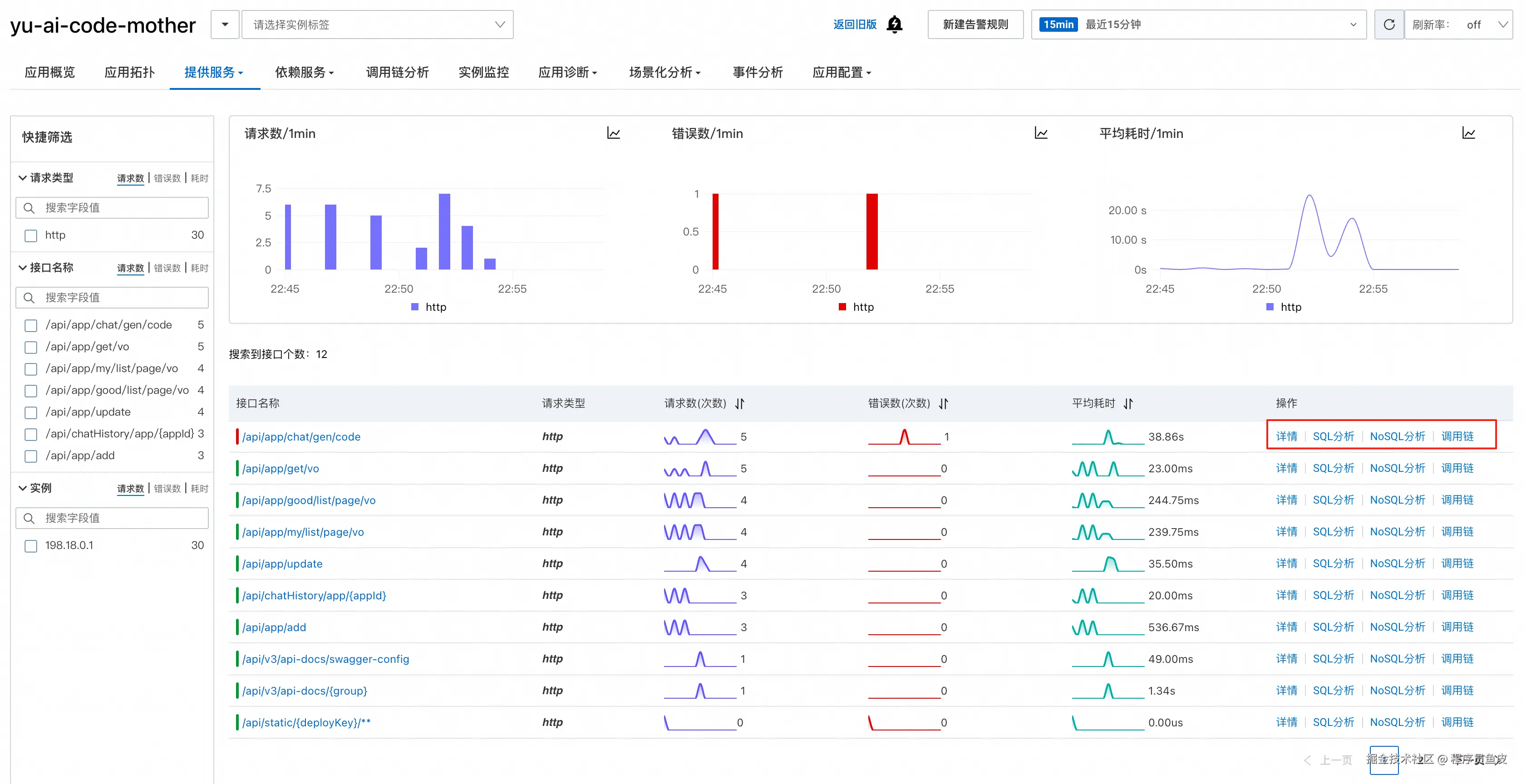
点击具体接口还可以深入分析该接口的详细数据(这就是所谓的 "下钻分析"):
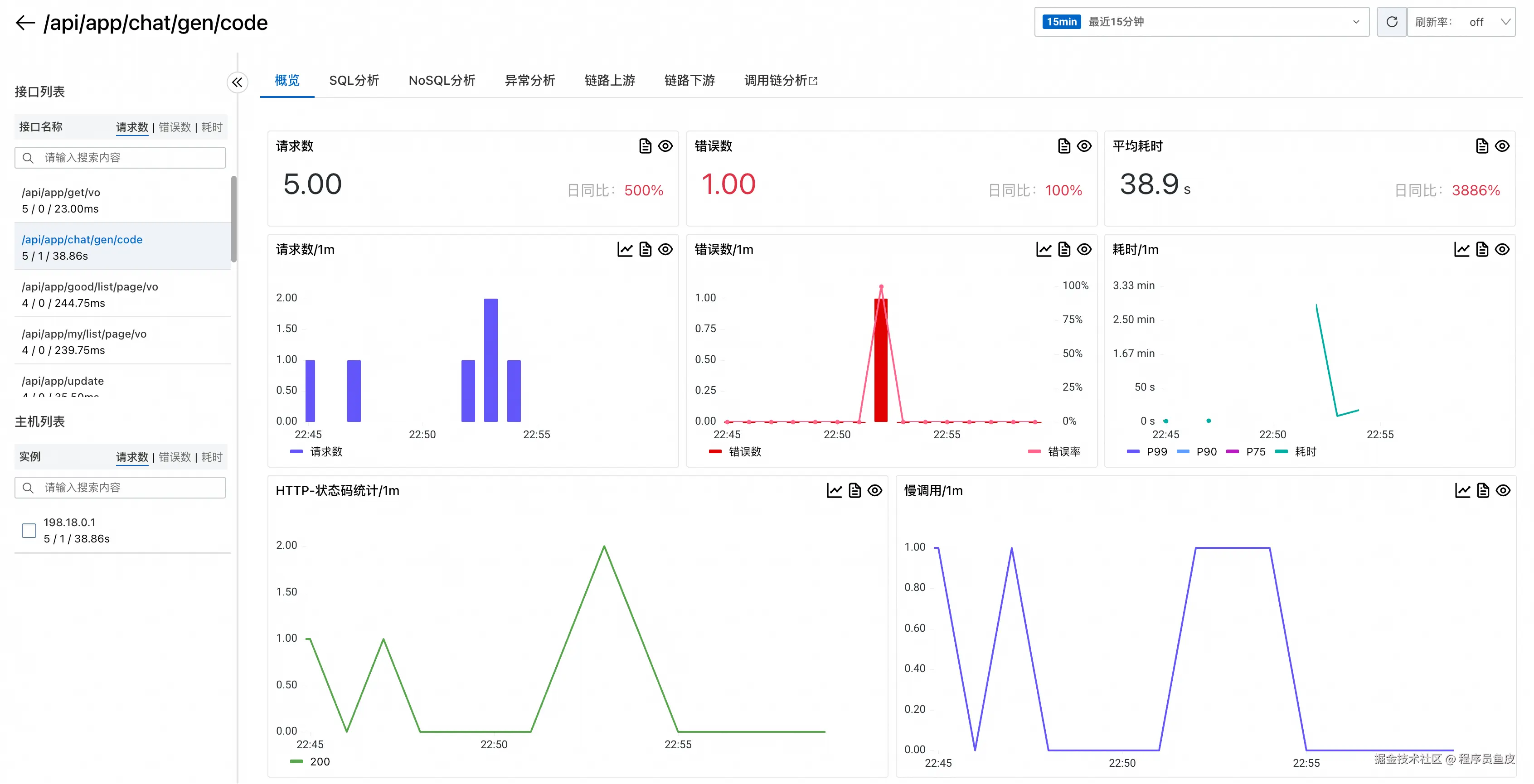
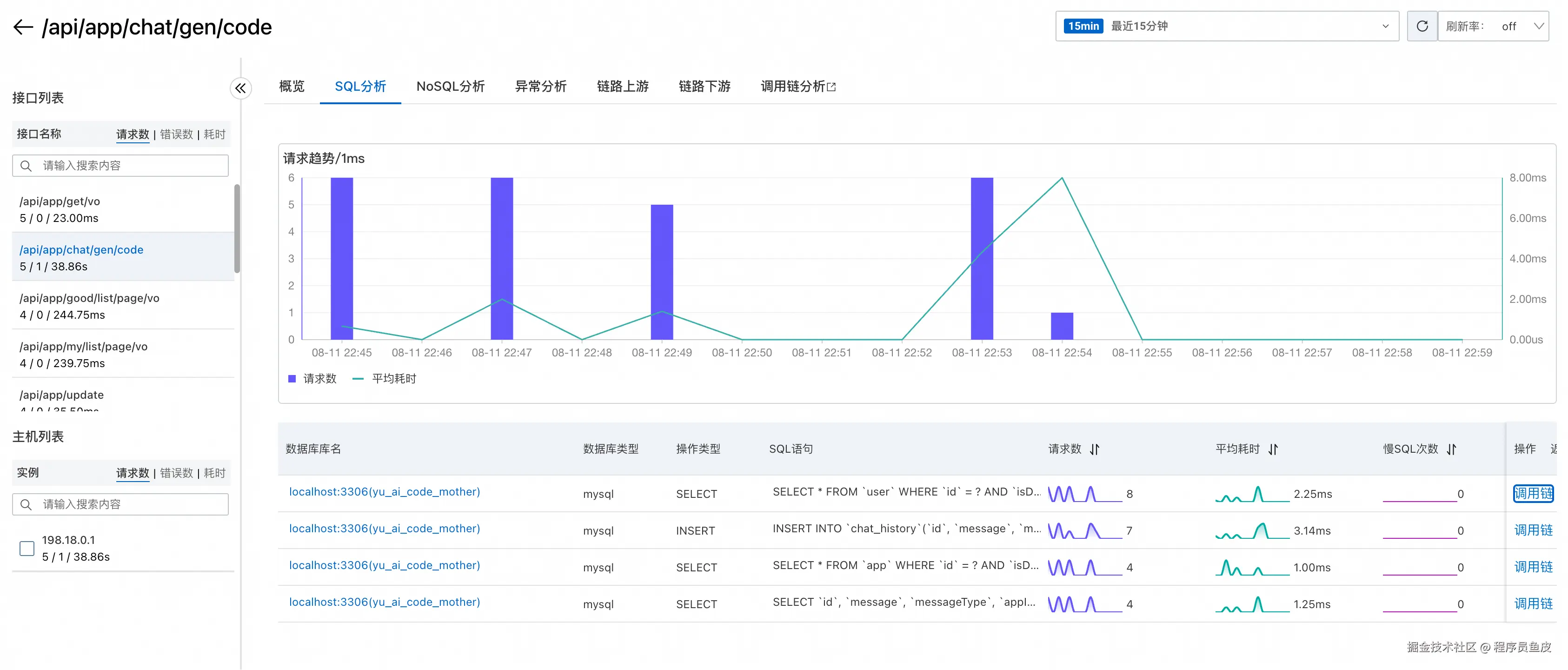
ARMS 还提供了 SQL 调用分析功能,能够监控数据库操作的性能:
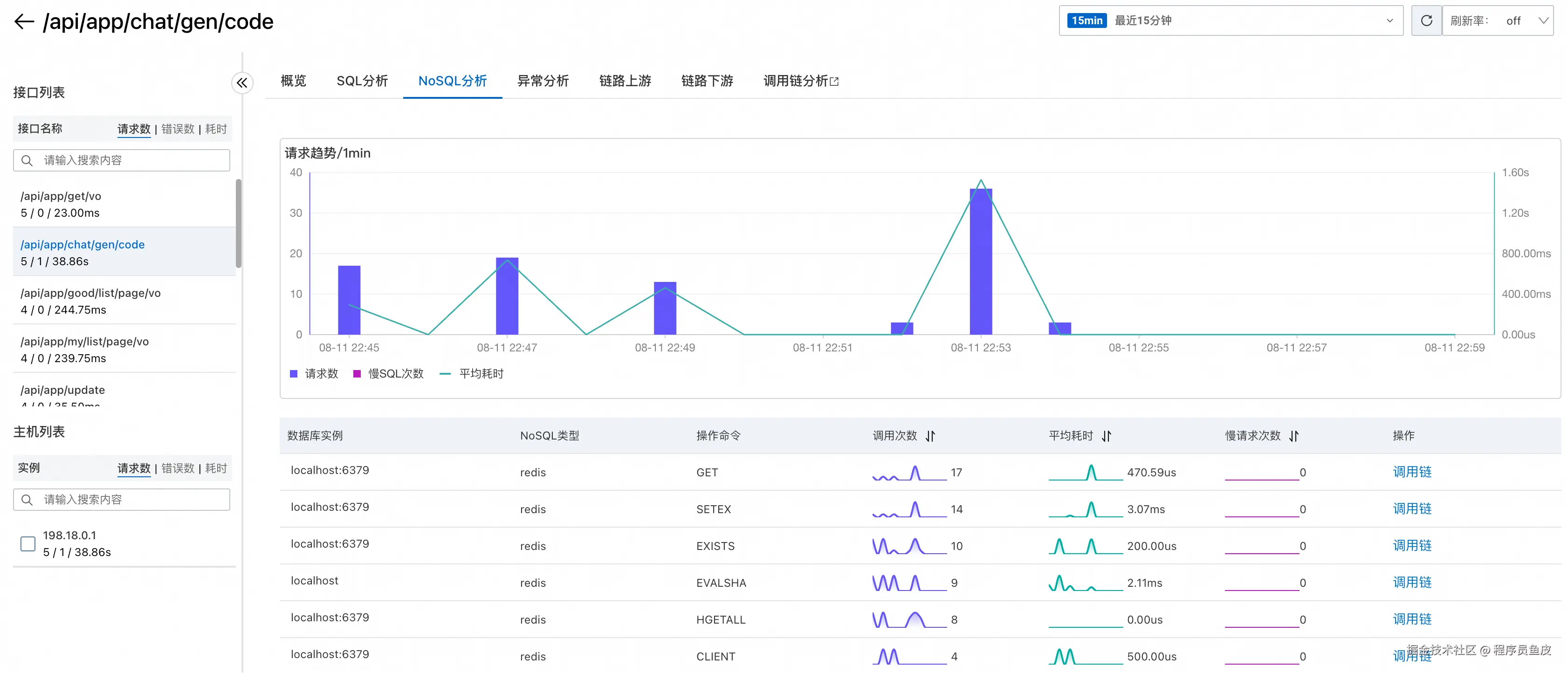
以及 NoSQL(如 Redis)的调用分析:
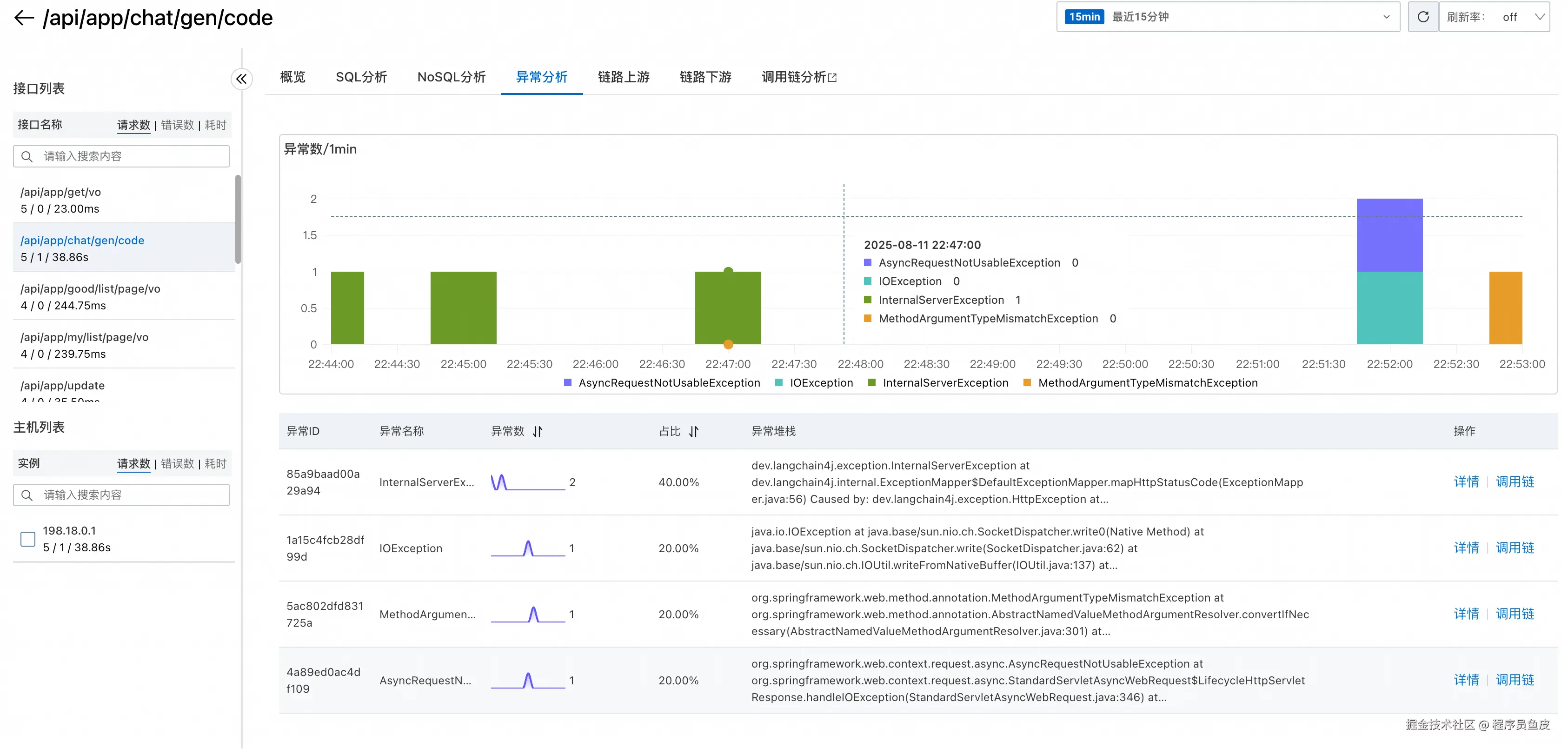
还提供了异常分析功能,可以帮助快速定位和解决应用中的异常问题:
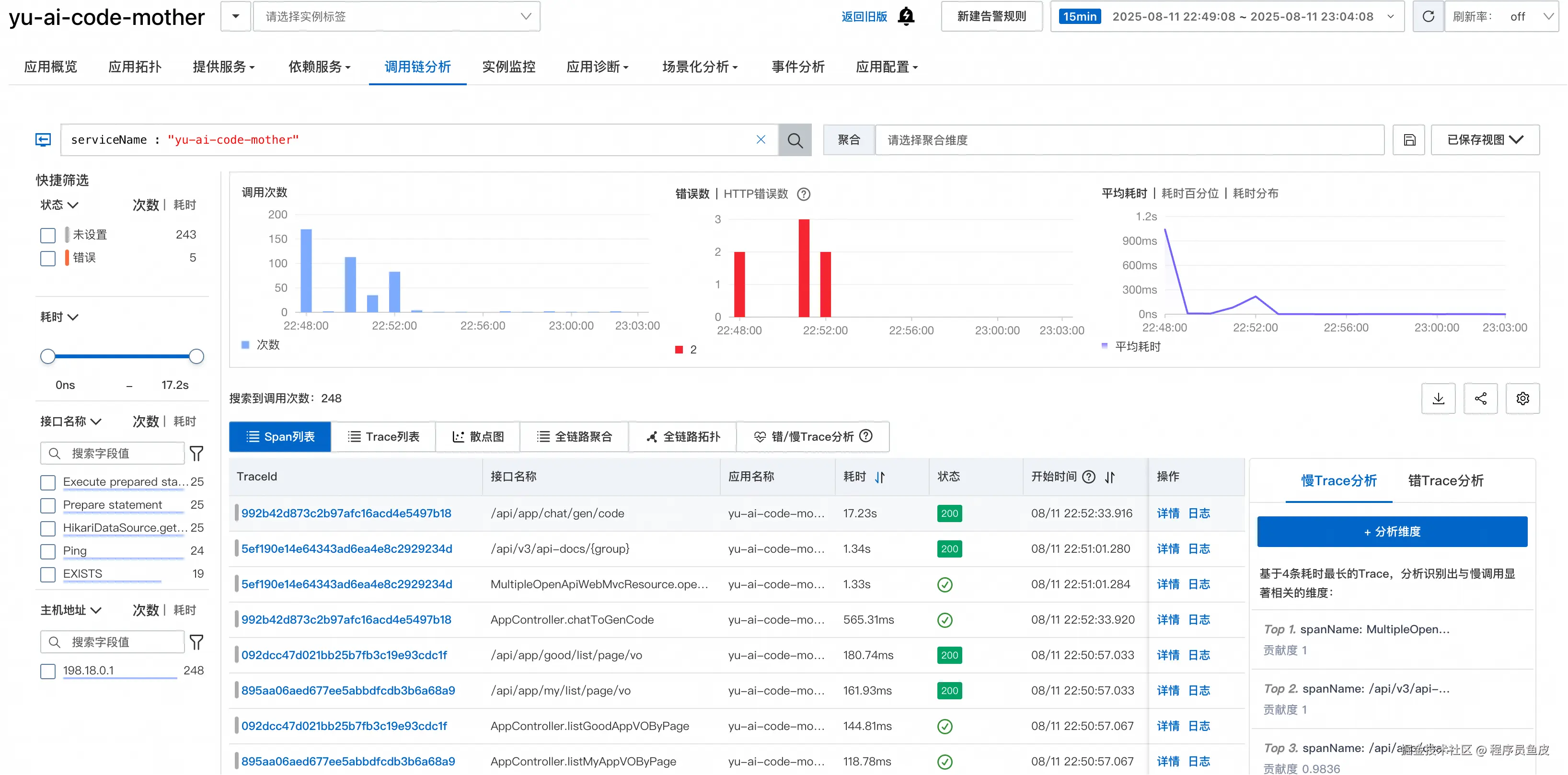
调用链分析
调用链分析是 ARMS 的核心功能之一,可以深度分析单次请求的完整调用路径,快速定位瓶颈点:
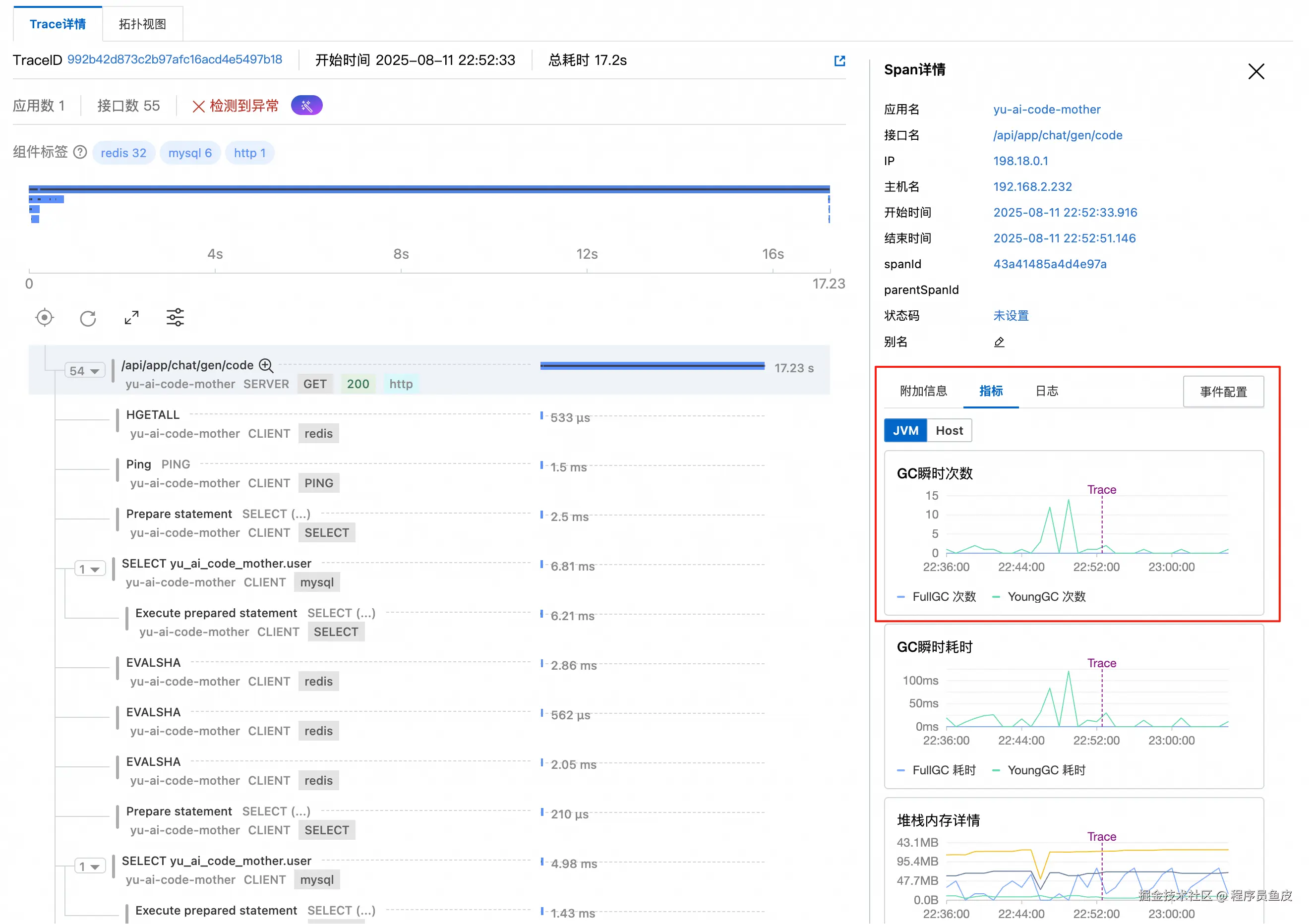
点击具体的调用记录,在 Trace 详情页面可以看到请求经过的每个环节和对应的耗时,右侧还能显示当时的 JVM 状态:
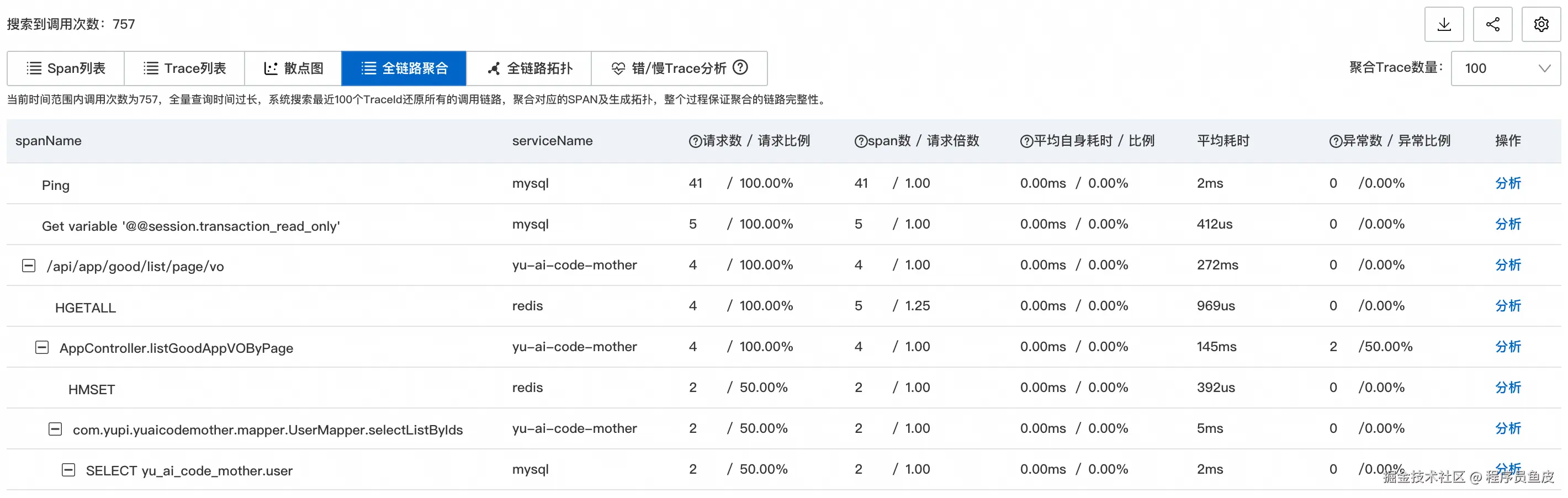
在全链路聚合页面可以清晰地看到树形的调用结构:
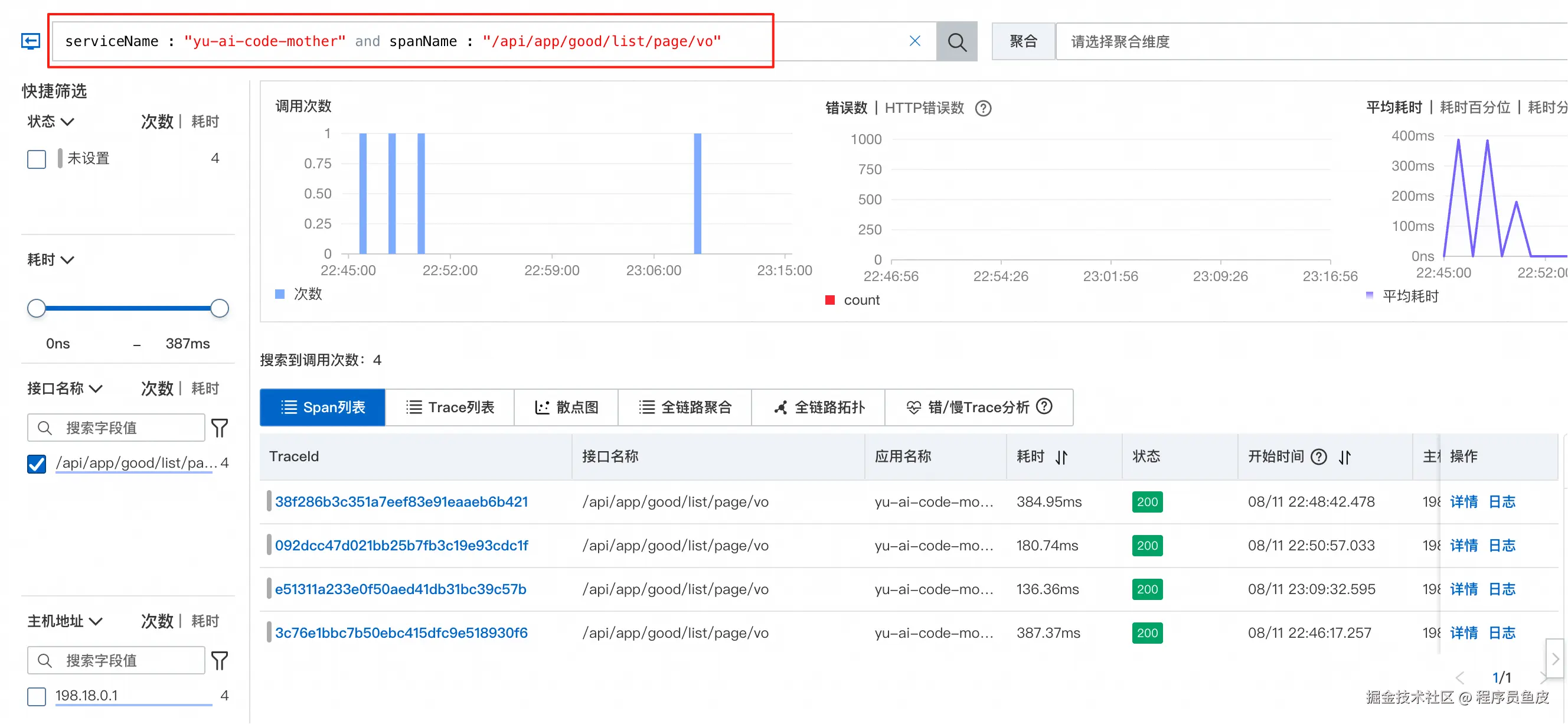
点击分析后,会根据特定的 serviceName 和 span 进行过滤分析:
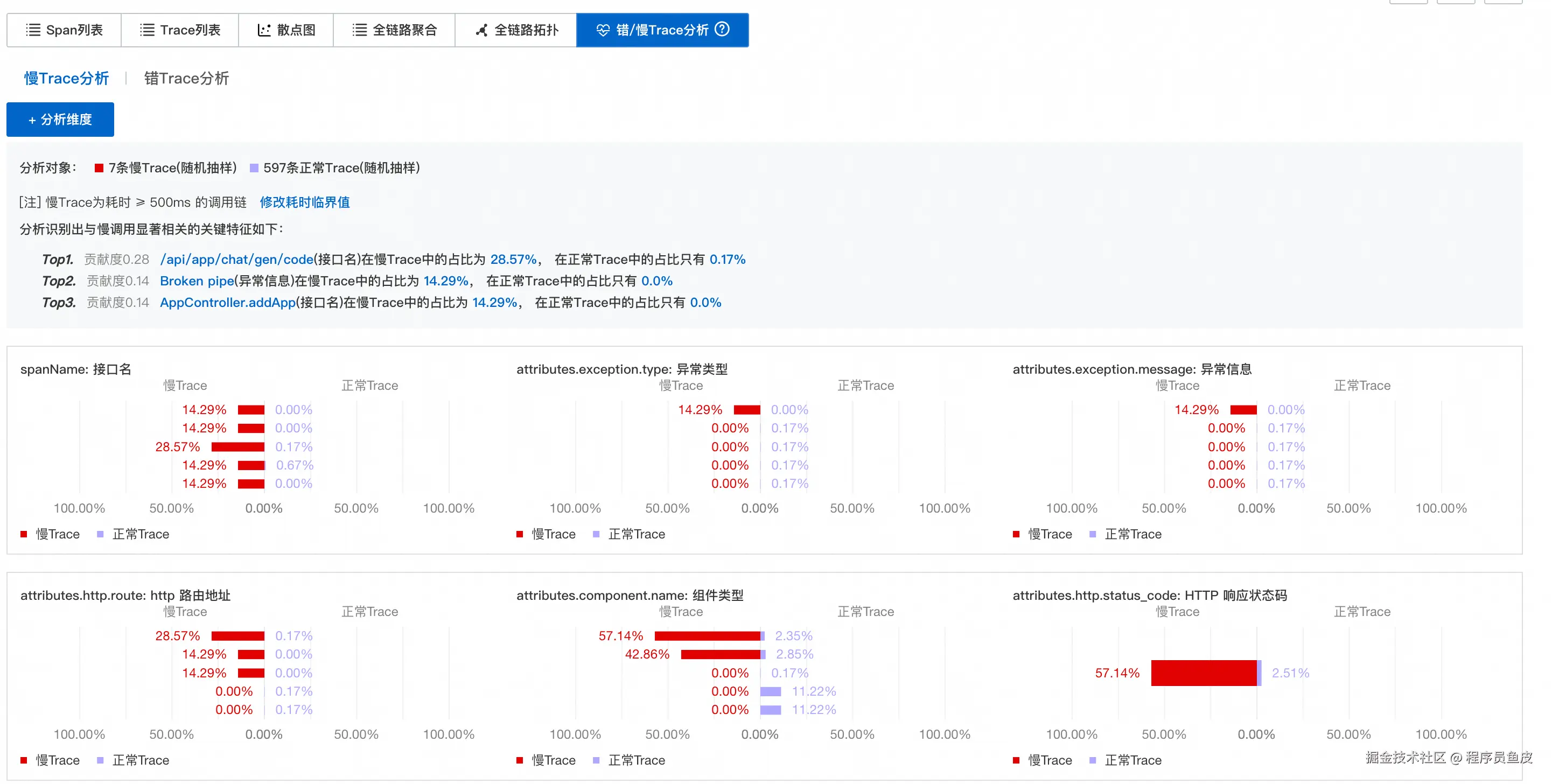
其中,错误 / 慢 Trace 分析功能特别实用,能够一秒定位到性能瓶颈:
依赖服务
依赖服务页面专门监控应用对外部服务的调用情况,比如数据库、缓存等:
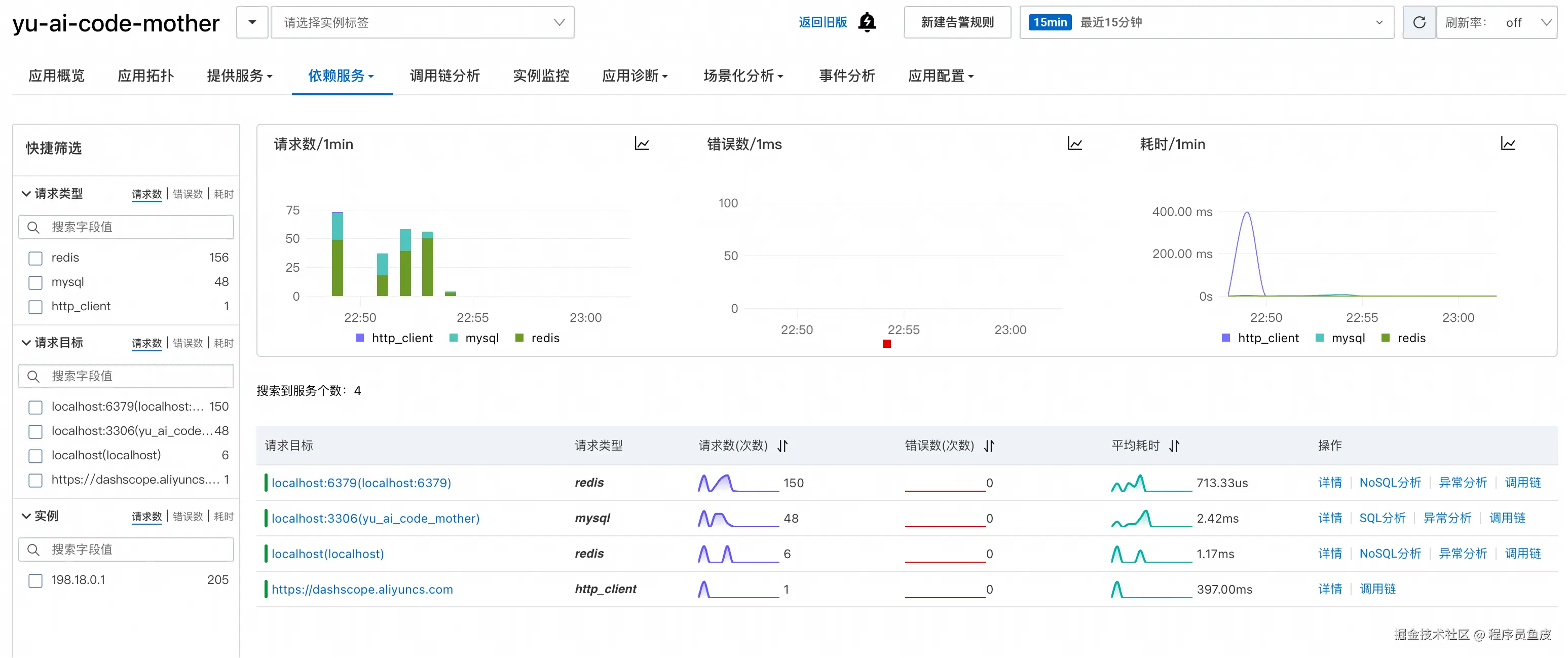
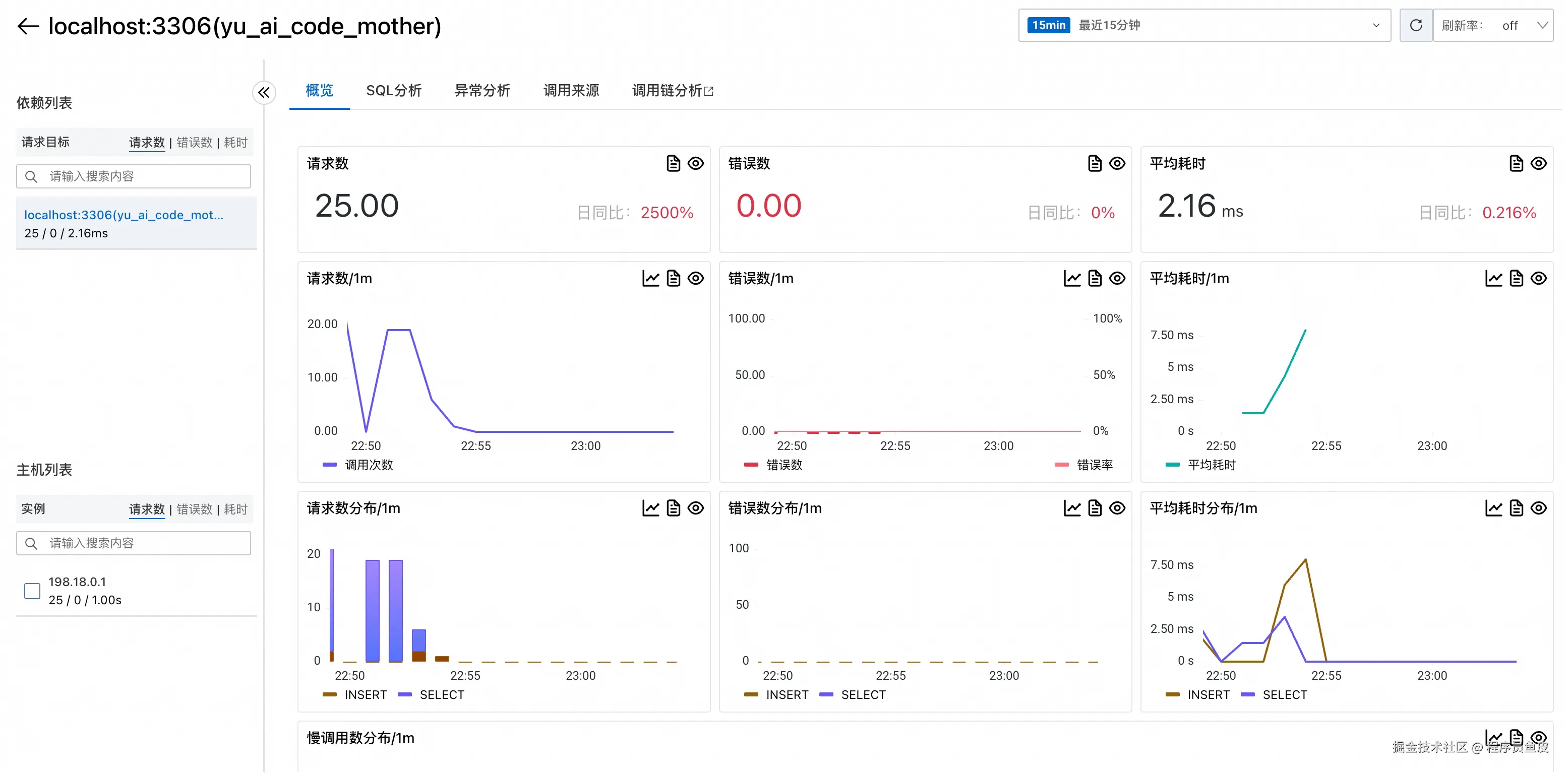
可以深入到具体依赖的详情页面,比如数据库详情:
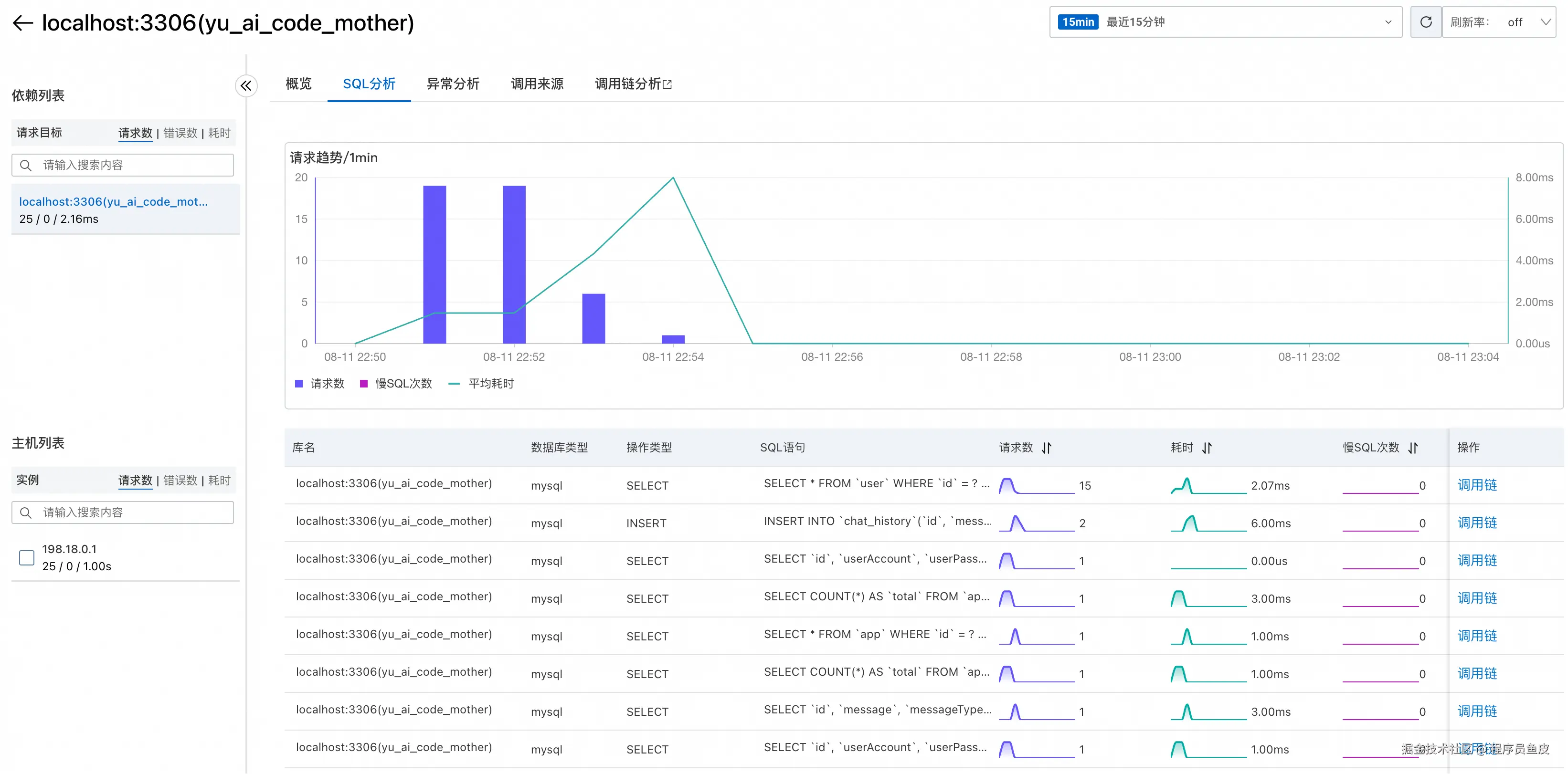
这里能够看到执行的具体 SQL 语句和慢 SQL,一目了然!
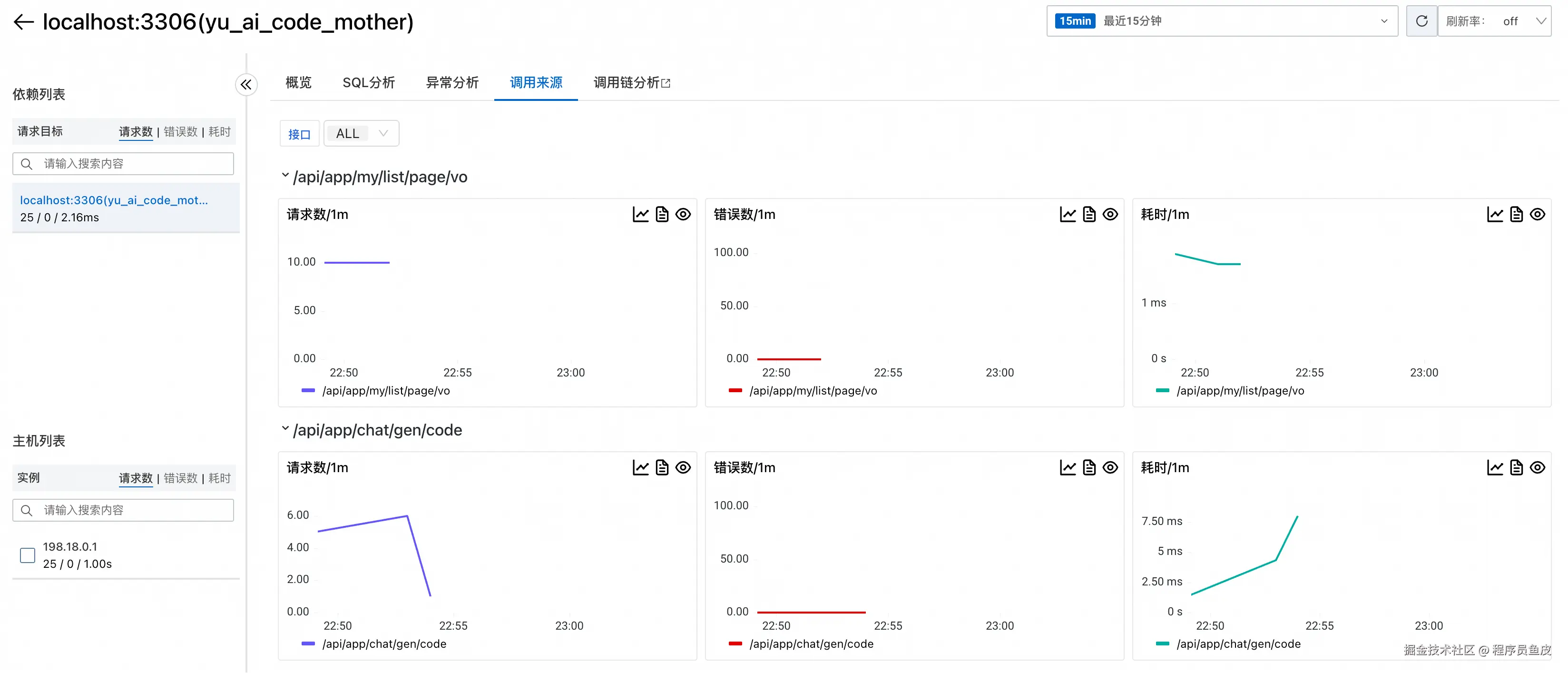
还能分析哪些请求对数据库的消耗最大:
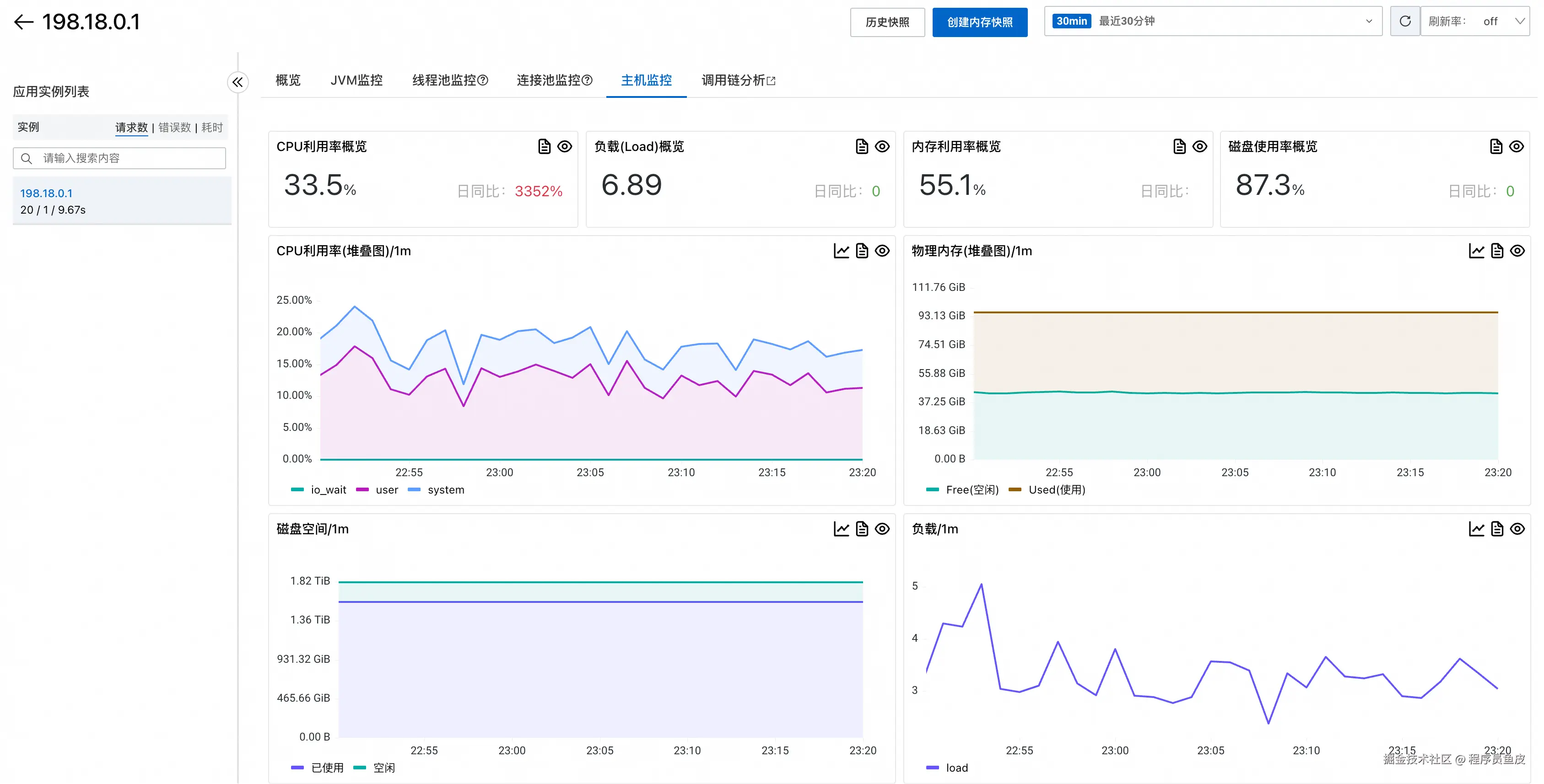
实例监控
实例监控页面展示服务器本身的运行状态:
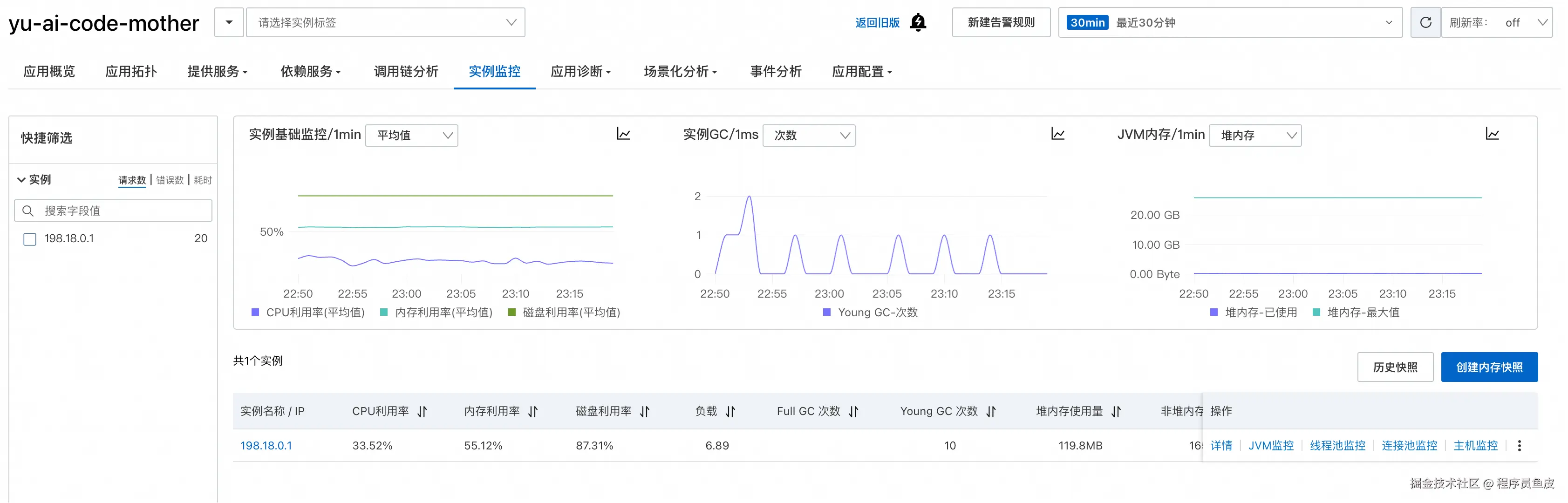
可以深入查看某个实例的详细信息:
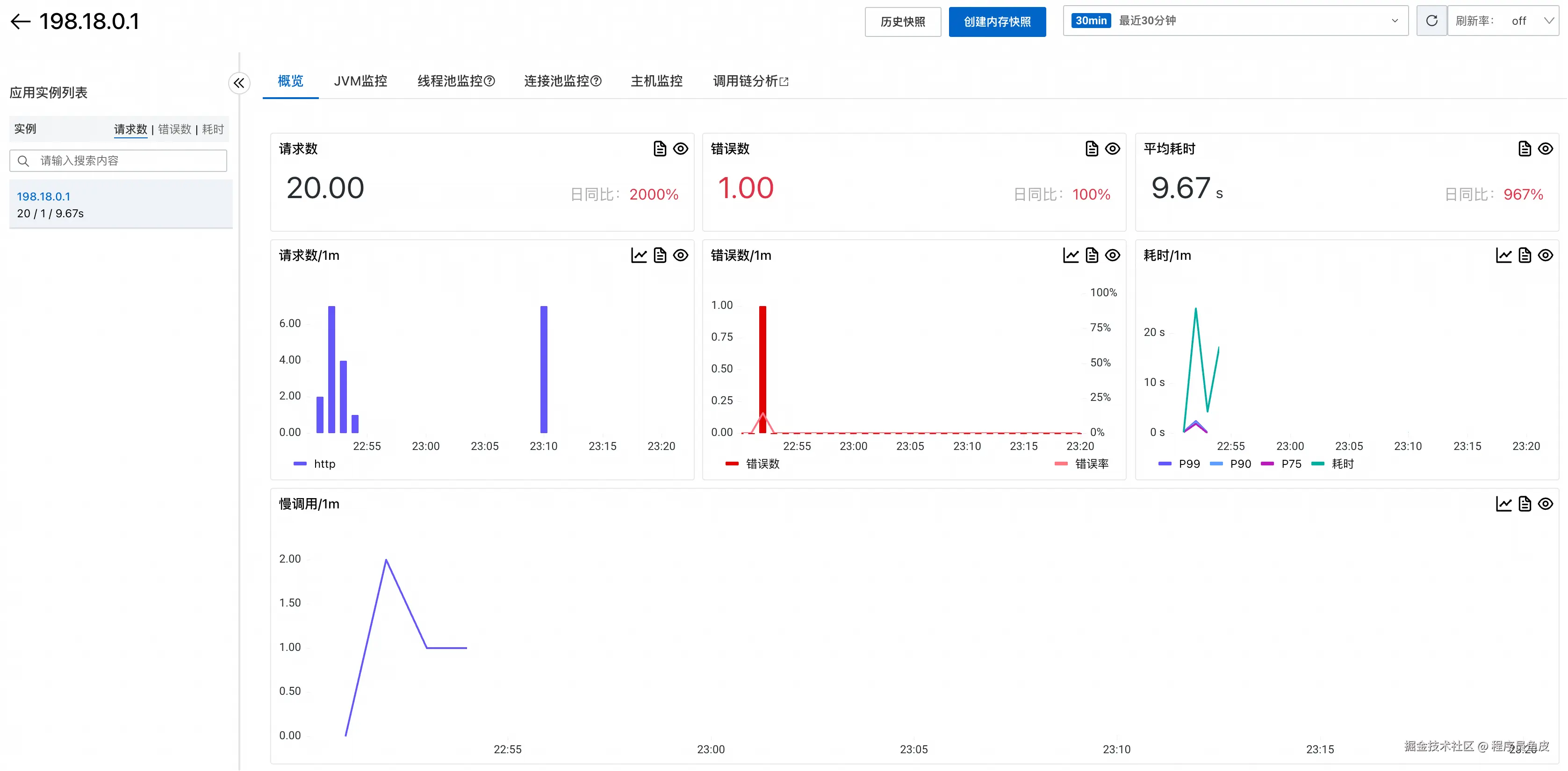
JVM 监控提供了堆内存、垃圾回收等关键指标:
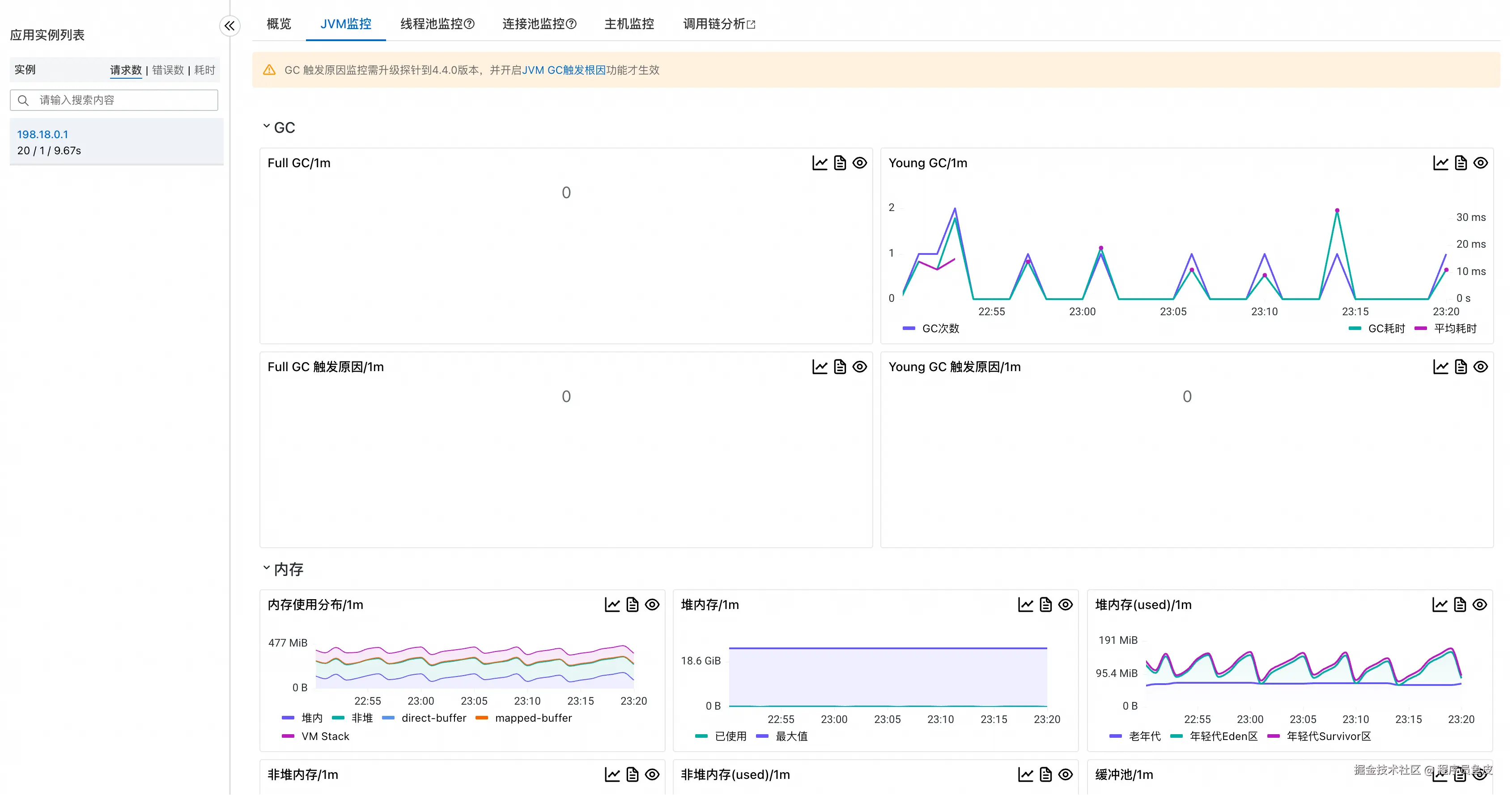
线程池监控帮助了解线程的使用情况:
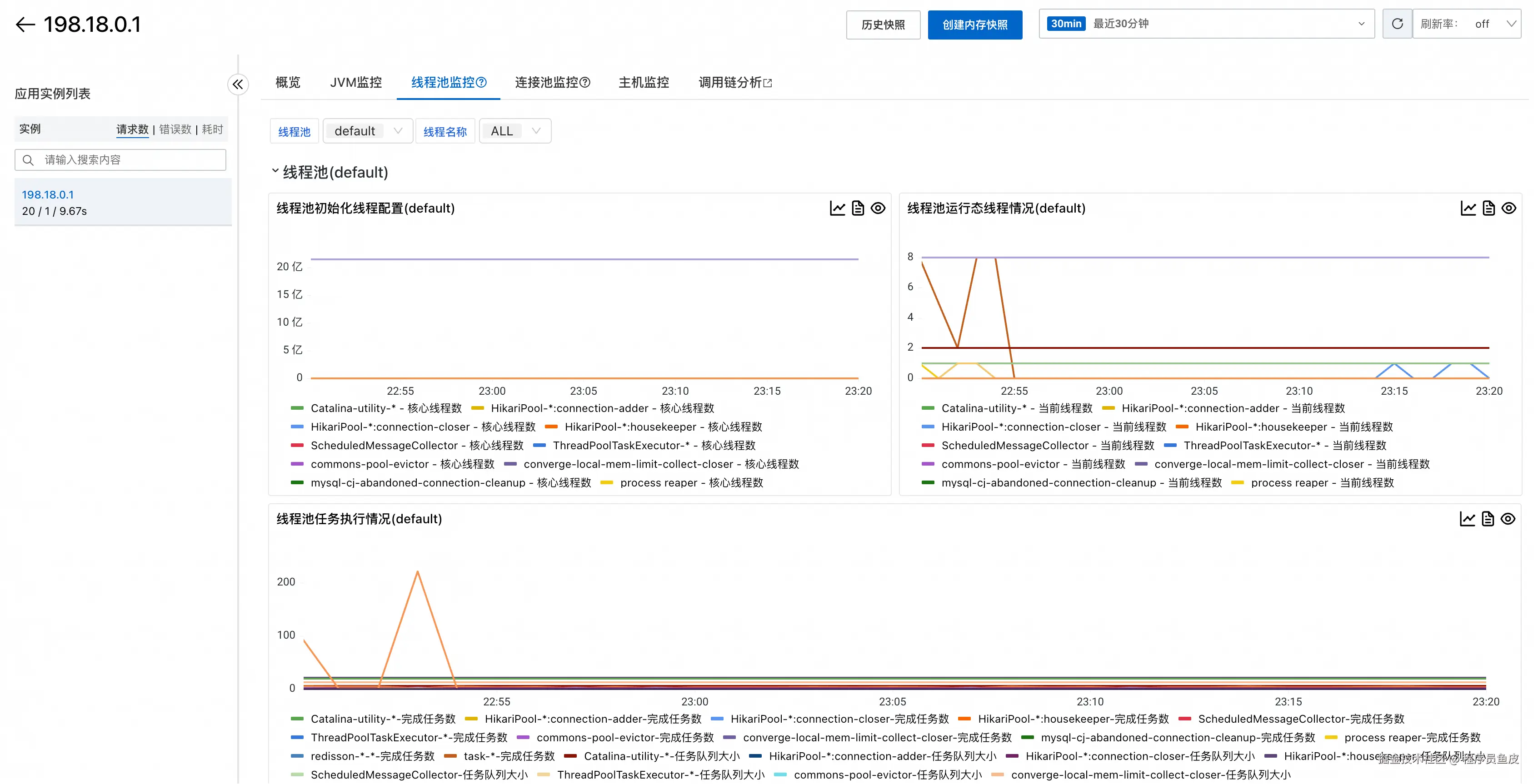
甚至还有连接池监控,比如数据库连接池:
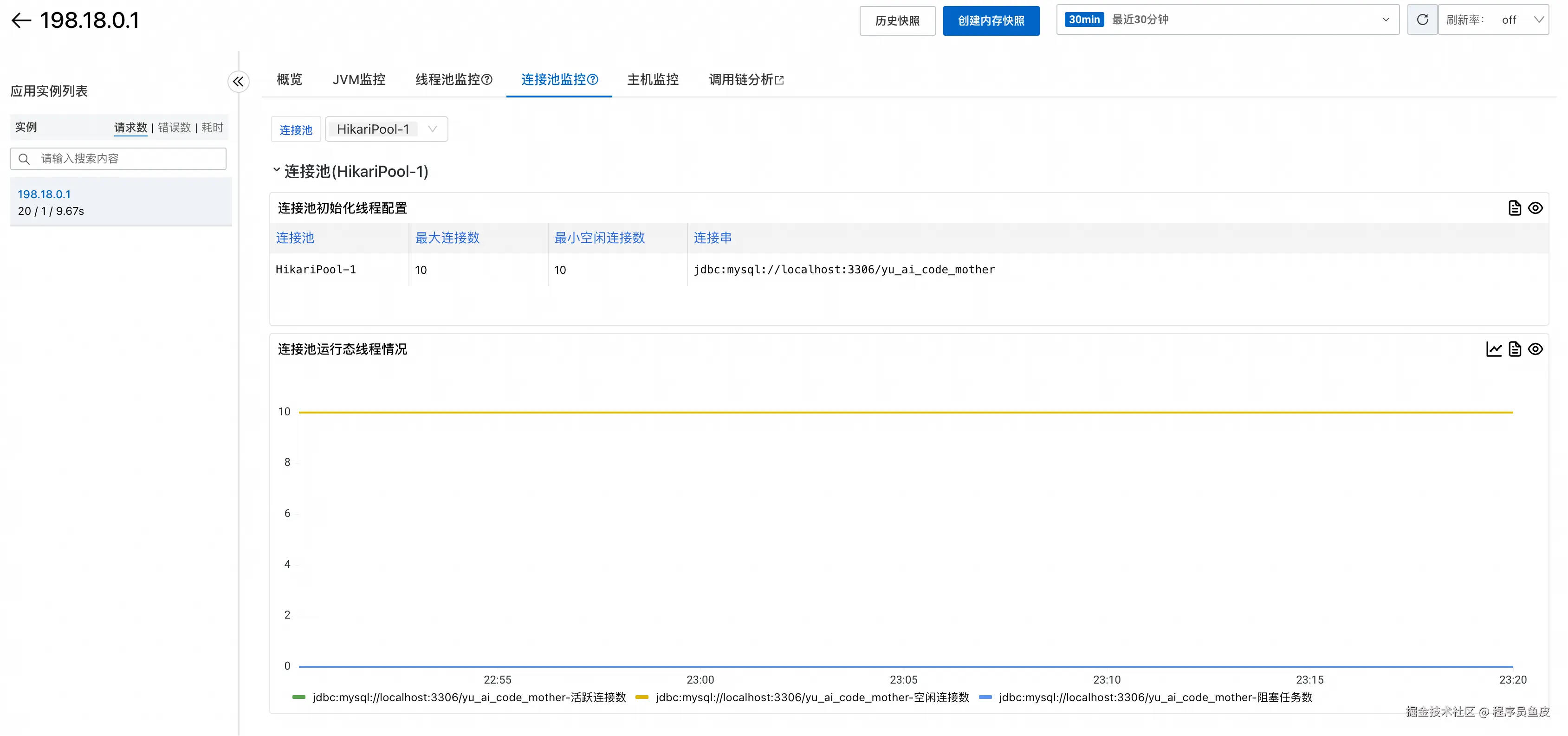
机器负载监控显示了系统层面的资源使用情况,比如 CPU、内存利用率,如果发现利用率较高,可能要考虑升配;较低则表示可能存在浪费。
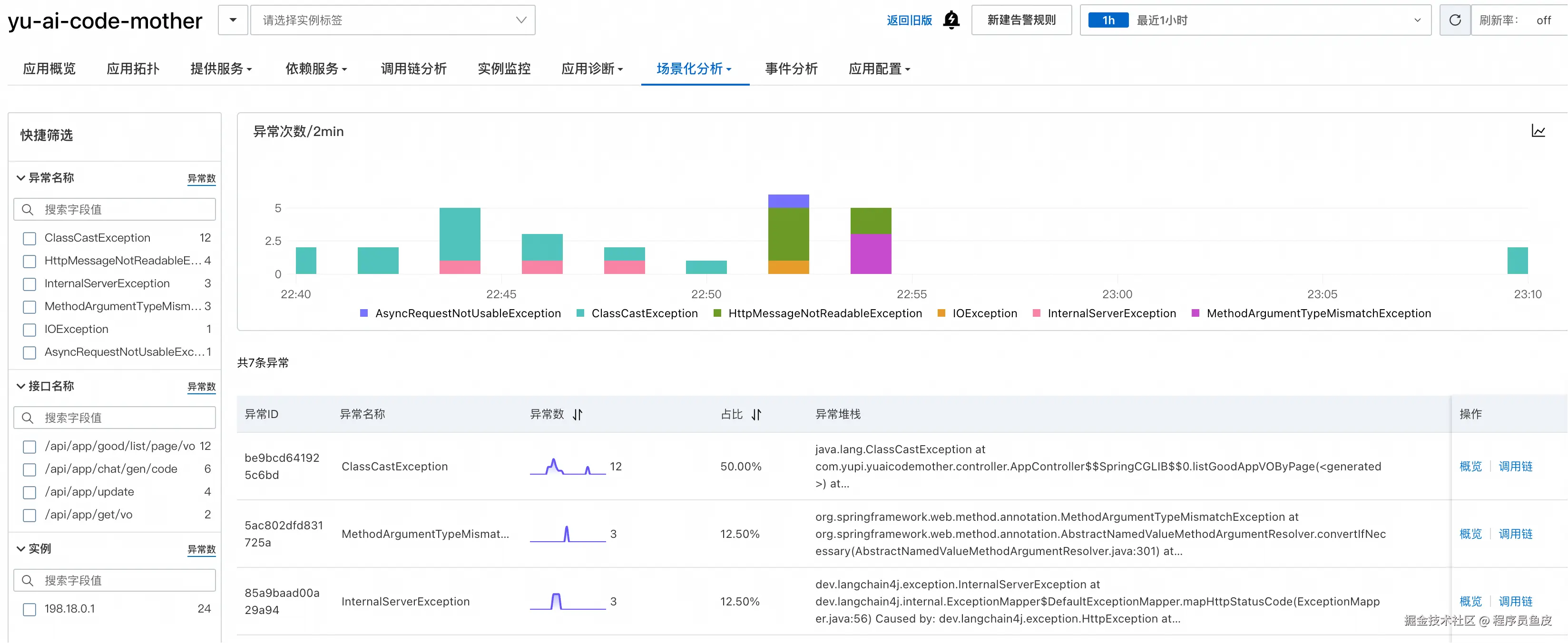
场景化分析
ARMS 还提供了 5 大场景化分析功能:
- 异常分析
- 日志分析
- 数据库分析
- 调用链分布
- 上下游分析
我感觉异常分析比较实用,能够按照异常名称进行分类展示,可以快速查看某类异常的出现情况,以及查看异常堆栈信息,从而快速定位错误:
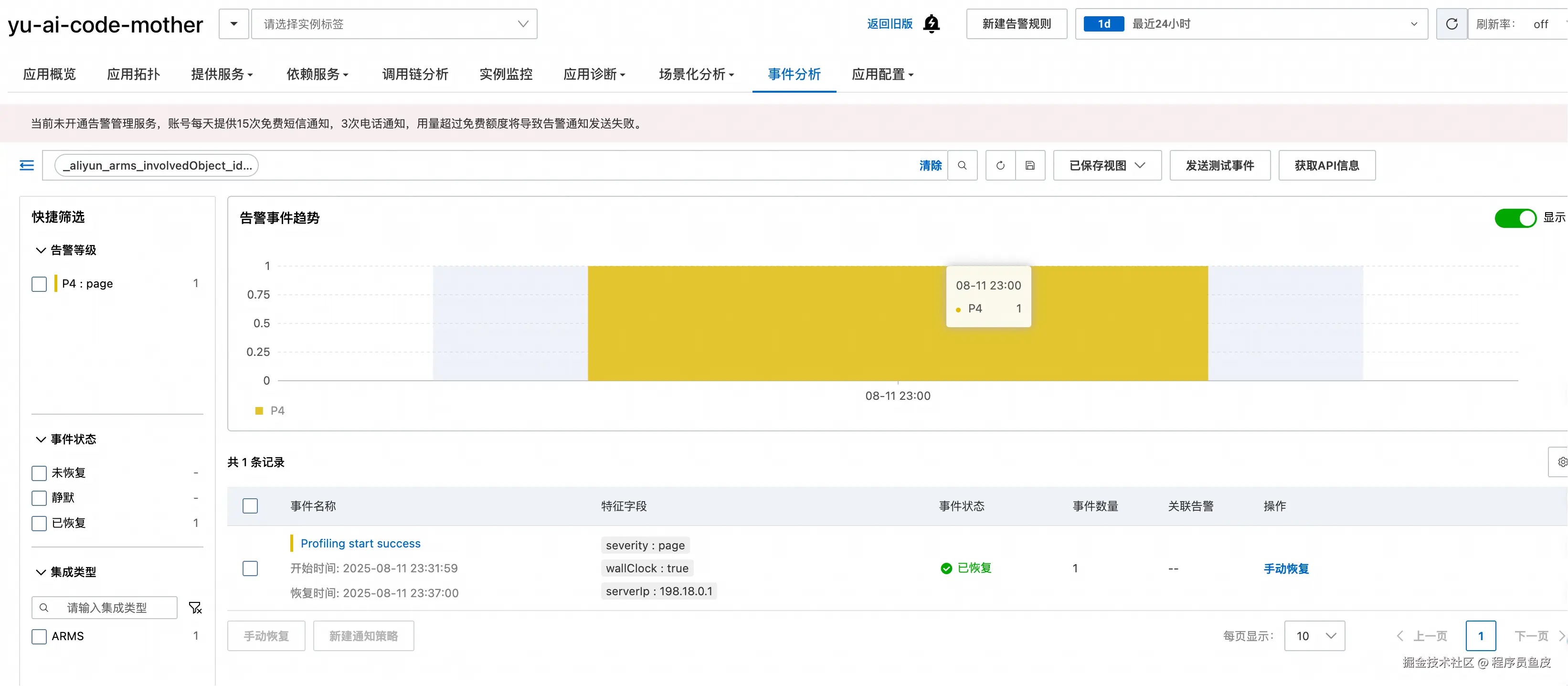
事件分析
事件分析页面用于管理各种告警事件:
应用配置
在应用配置页面可以设置数据采样率、自定义探针收集的指标:
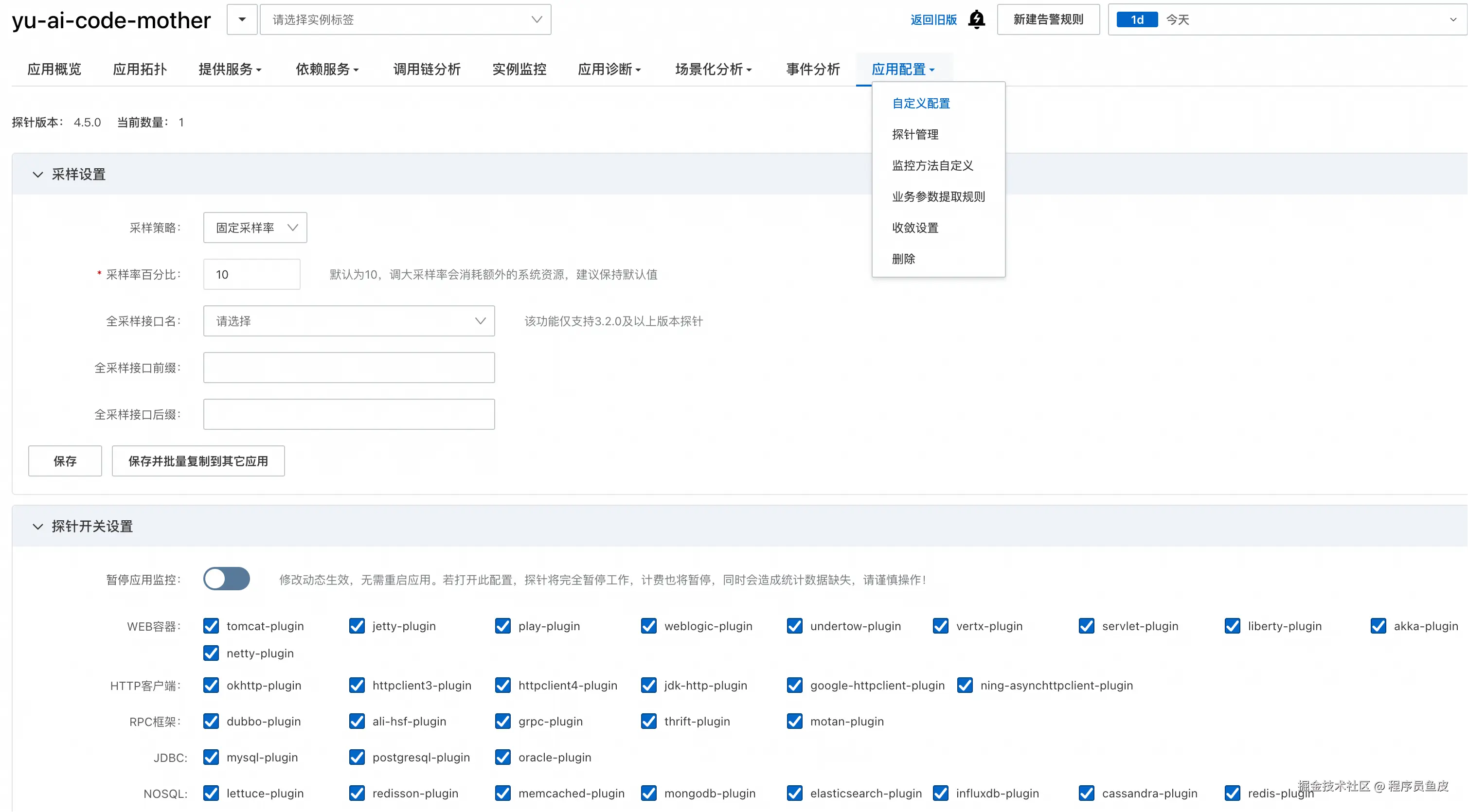
还可以开启一些高级功能,比如 Arthas 监控、持续性能剖析等:
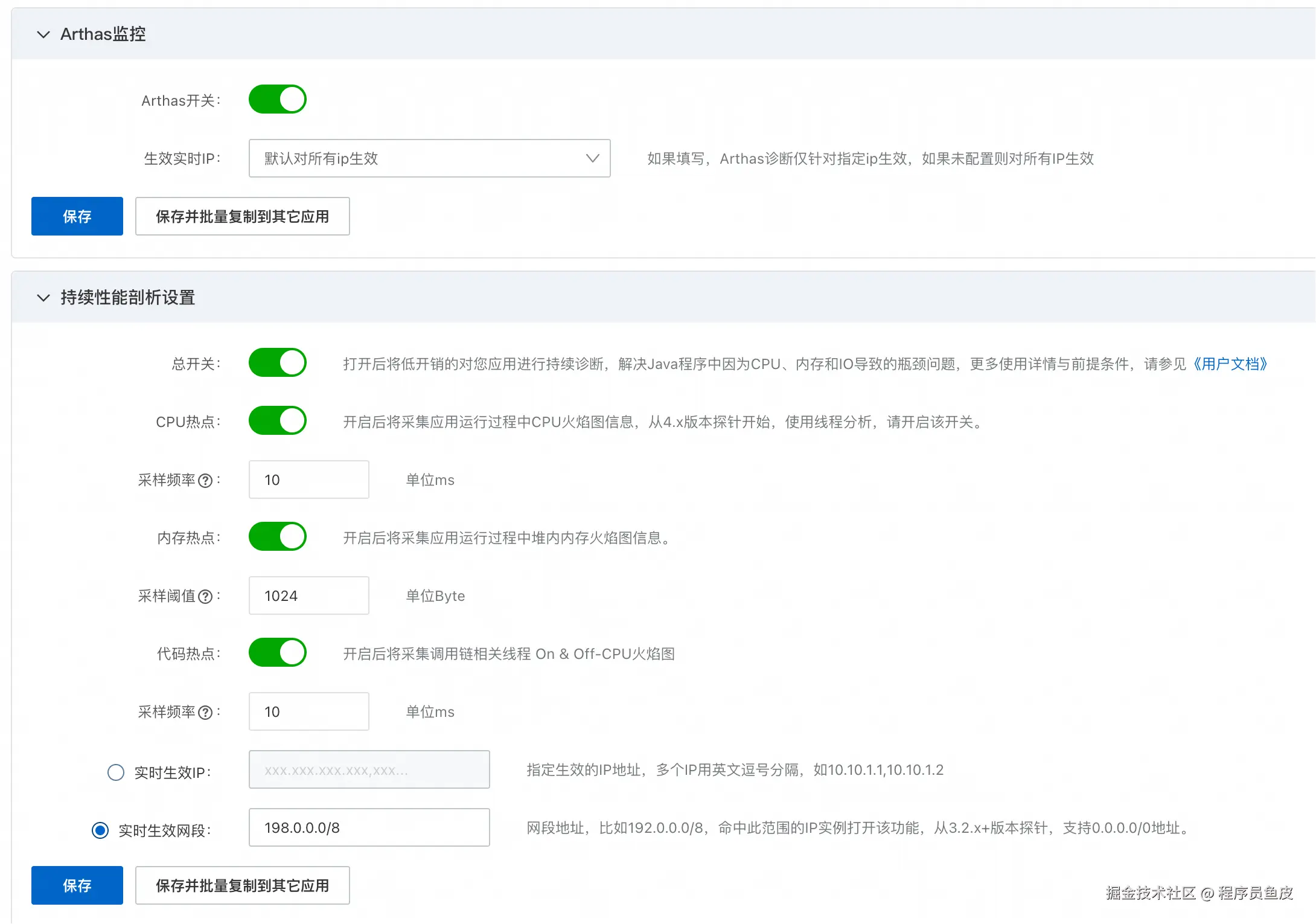
💡 不过需要注意的是,收集的数据越多,费用也会相应增加,请按需开启。测试完成后记得关闭不必要的监控功能,避免产生不必要的费用。
告警能力
监控和告警天生一对,通常是配套使用的,告警机制能够在问题发生时及时通知相关人员。
创建告警规则的流程很简单:
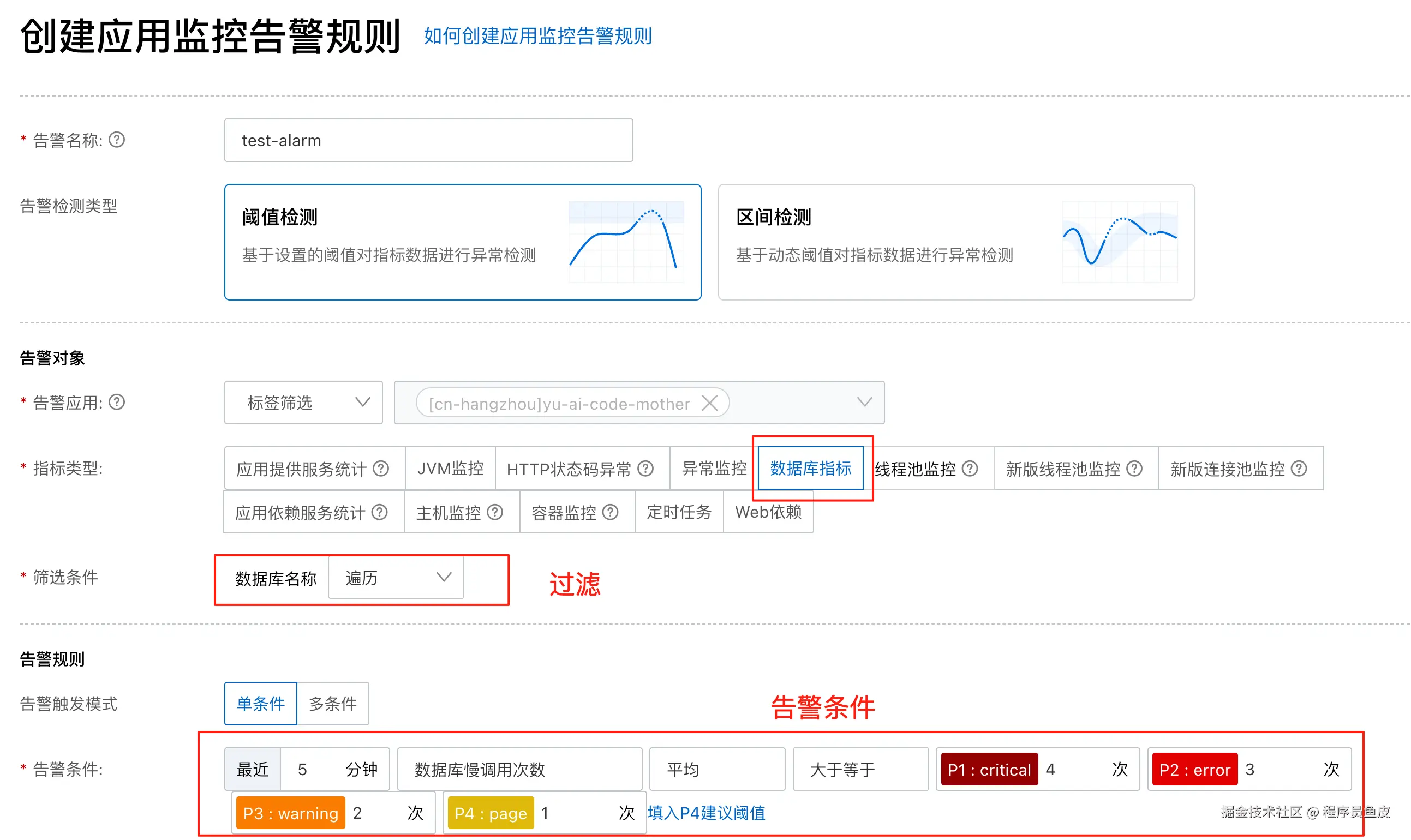
ARMS 支持阈值检测和区间检测两种模式。以监控慢 SQL 次数为例:
可以配置告警通知方式、时间段、重复策略等:
创建完成后,可以在告警规则列表中看到,并且支持测试功能:
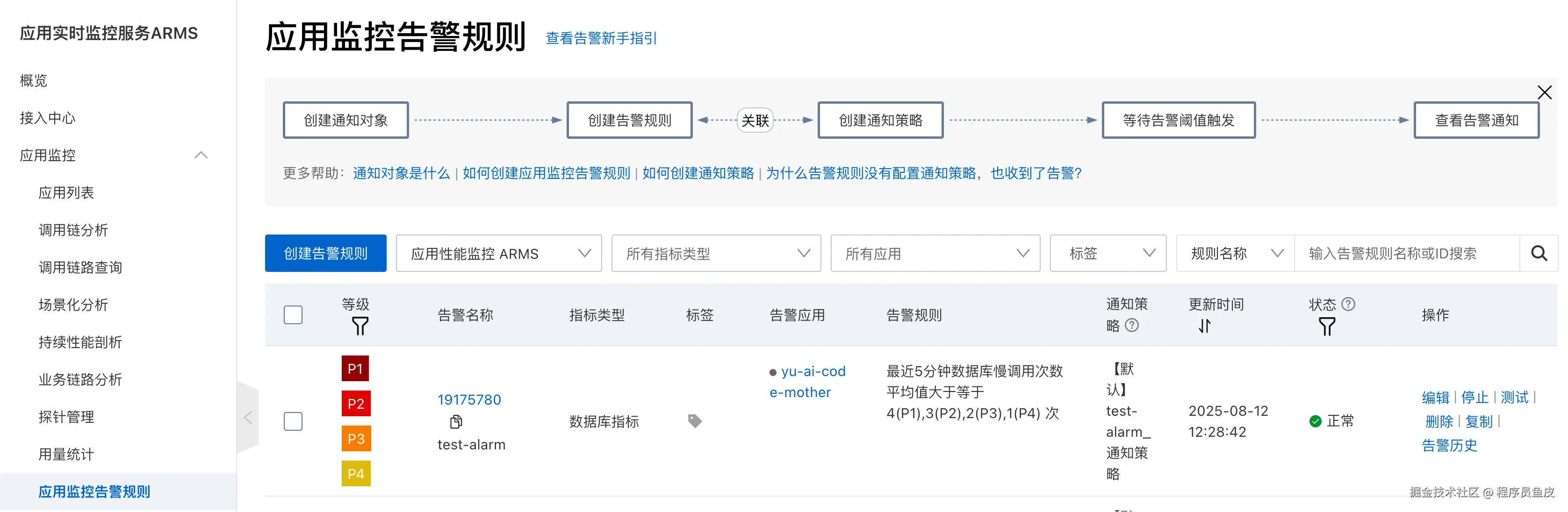
还有一些常见的告警配置,比如应用响应时间超过阈值、错误率超过阈值、数据库连接数过高、JVM 内存使用率过高等。
💡 不过要注意合理配置告警,而且要配置分级告警,否则可能就会出现大家对告警已经麻了,有告警也不处理的情况。
扩展知识 - 怎么自己实现监控平台?
可能有同学好奇,为什么 ARMS 只是在启动命令中加了几个参数,就能实现这么全面的监控功能?而且能够支持那么灵活的筛选?这背后的技术原理是什么?
探针技术
首先,数据是通过探针技术 Java Agent 收集的。Java Agent 是 JVM 提供的机制,允许在 Java 应用启动时或运行时动态修改字节码,从而实现无侵入式的监控。
利用探针进行监控的原理如下:
- 字节码增强:Java Agent 通过 Java Instrumentation API 在类加载时拦截字节码,动态插入监控代码。
- 方法织入:在关键方法(如 HTTP 请求处理、数据库调用等)的入口和出口处织入监控逻辑,记录执行时间、参数、返回值等信息。
- 数据收集:织入的监控代码会收集各种性能数据,并通过网络传输到监控平台。
- 链路追踪:通过在请求上下文中传递唯一标识,将分布式调用链串联起来,形成完整的 Trace。
这种方式的优势在于完全不需要修改业务代码,只需要在 JVM 启动时指定 Agent,就能获得全面的监控能力。

数据的维度划分
监控平台之所以能提供如此灵活的筛选和分析能力,关键在于合理的数据维度设计。
以一个 HTTP 请求为例,监控系统会记录 最细粒度 的维度信息:
| 维度 | 示例值 | 说明 |
|---|---|---|
| 时间戳 | 2025-08-14 19:30:10 | 请求发生的精确时间 |
| 应用名 | yu-ai-code-mother | 应用标识 |
| 接口路径 | /api/app/generate | 具体的接口 |
| HTTP 方法 | POST | 请求方法 |
| 响应状态码 | 200 | 请求结果 |
| 响应时间 | 150ms | 接口耗时 |
| 客户端 IP | 127.0.0.1 | 请求来源 |
| 用户 ID | 12345 | 业务维度 |
基于这些最细粒度的数据,监控平台就可以进行各种维度的聚合分析,比如:
- 按时间聚合:统计每分钟/小时/天的请求量
- 按接口聚合:分析各接口的性能表现
- 按状态码聚合:计算成功率和错误率
- 按用户聚合:分析用户行为模式
三、Prometheus + Grafana 业务监控
前面我们通过 ARMS 实现了系统级的监控,这种方式简单高效,适合快速获得全面的监控能力。但 ARMS 主要关注通用的系统指标,如果我们想监控业务特有的指标,比如大模型的 Token 使用量、用户的活跃度等,就需要自定义的监控方案。
回到最初的几个核心问题,都需要我们自己来考虑了:
- 统计什么?监控 AI 模型调用相关的业务指标
- 如何收集?通过在代码中埋点的方式主动收集数据。
- 如何存储?使用 Prometheus 时序数据库存储指标数据。
- 如何展示?通过 Grafana 构建可视化监控仪表板。
下面我们进入方案设计阶段,依次对这几个问题进行展开。
监控指标设计
首先我们需要明确要监控哪些维度和业务指标。根据 LangChain4j 可观测性文档,我们可以获取到以下数据:
维度
- 用户 ID
- 应用 ID
- 模型名称
- 最大输出 Token 数(maxOutputTokens)
- AI 回复消息内容
- 模型生成停止的原因(Finish Reason)
- 调用状态(成功或失败)
- 请求时间
- 调用失败时的错误信息
指标
- 输入 Token 数量
- 输出 Token 数量
- 总消耗 Token 数量
- 响应时长
分析能力
有了上面这些数据,我们能够进行很多分析:
- 模型调用分析:统计不同时间窗口(分钟/小时/天)内各模型、用户、应用的调用次数趋势
- 模型性能分析:分析各模型的平均响应时间,以及响应时间分布的 P50/P90/P95/P99 百分位数
- Token 消耗分析:监控不同时间窗口(分钟/小时/天)内输入 Token、输出 Token、总 Token 的消耗
- 热门应用排行:按调用次数对应用进行排序,识别调用 AI 最频繁的应用
- 用户活跃排行:按调用次数对用户进行排序,识别调用 AI 最频繁的用户
- 应用 Token 消耗排行:按 Token 消耗量对应用进行排序,识别消耗最高的应用
- 用户 Token 消耗排行:按 Token 消耗量用户进行排序,识别消耗最高的用户
- 错误分析:统计各模型的失败次数,以及不同错误类型的分布占比
数据收集方式
在业务监控中,数据收集需要开发者手动埋点,因为只有业务开发者才知道要收集什么信息、从哪里收集、什么时候收集。
跟业界主流的可观测性实现方案一样,我们的策略是在业务层收集 最原始、最细粒度 的数据,这样在查询层就能进行灵活的聚合分析。
怎么获取原始数据呢?
LangChain4j 提供了 可观测性支持,通过定义 Listener 来获取大模型的调用信息。

数据存储方案 - Prometheus
即使没有学过 Prometheus,也应该知道可以通过数据库存储的方式实现监控统计。
比如将监控数据存储到 MySQL 等关系型数据库中(或者 Elasticsearch),之后从数据库中读取。适合需要持久化保存详细数据的场景,而且比较灵活,可以自己写 SQL 实现复杂的查询和关联分析。
但缺点是收集监控数据可能会比较频繁,需要频繁写入数据库,容易对应用性能产生影响。
因此,专业的事情交给专业的中间件来做吧!
什么是 Prometheus?
Prometheus 是一个开源的监控系统,专门为时序数据的收集、存储和查询而设计。
Prometheus 的核心理念是将所有监控数据以 时间序列 的形式存储。根据它的 数据模型,每个时间序列都由指标名称和一组标签唯一标识。比如 http_requests_total{method="POST", handler="/api/yupi"} 就表示一个记录 POST 请求接口总数的时间序列。
这样一来,Prometheus 能够高效地处理监控场景中的时间范围查询,比如过去一小时内各个接口的平均响应时间、CPU 使用率超过 80% 的服务器列表等。
核心组件架构
Prometheus 包含几个关键组件,职责明确:
1)Prometheus Server:整个系统的核心,负责数据收集、存储和查询。它定期从配置的目标 拉取 指标数据,将数据存储在本地的时序数据库中,并提供 PromQL 查询语言来支持复杂的数据分析。
2)Exporter:翻译器,将第三方系统(如数据库、操作系统、消息队列等)的指标转换为 Prometheus 格式。比如 Node Exporter 可以收集 Linux 系统的 CPU、内存、磁盘等指标,MySQL Exporter 可以收集数据库的性能指标。
3)Alertmanager:处理告警规则和通知分发。当指标触发预设的告警条件时,它负责将告警信息发送给相应的人员或系统,支持邮件等多种通知方式。
4)客户端库:提供各种编程语言的 SDK,方便开发者在应用代码中埋点收集自定义指标。这些库封装了指标类型的创建和管理,让开发者能够专注于业务逻辑。
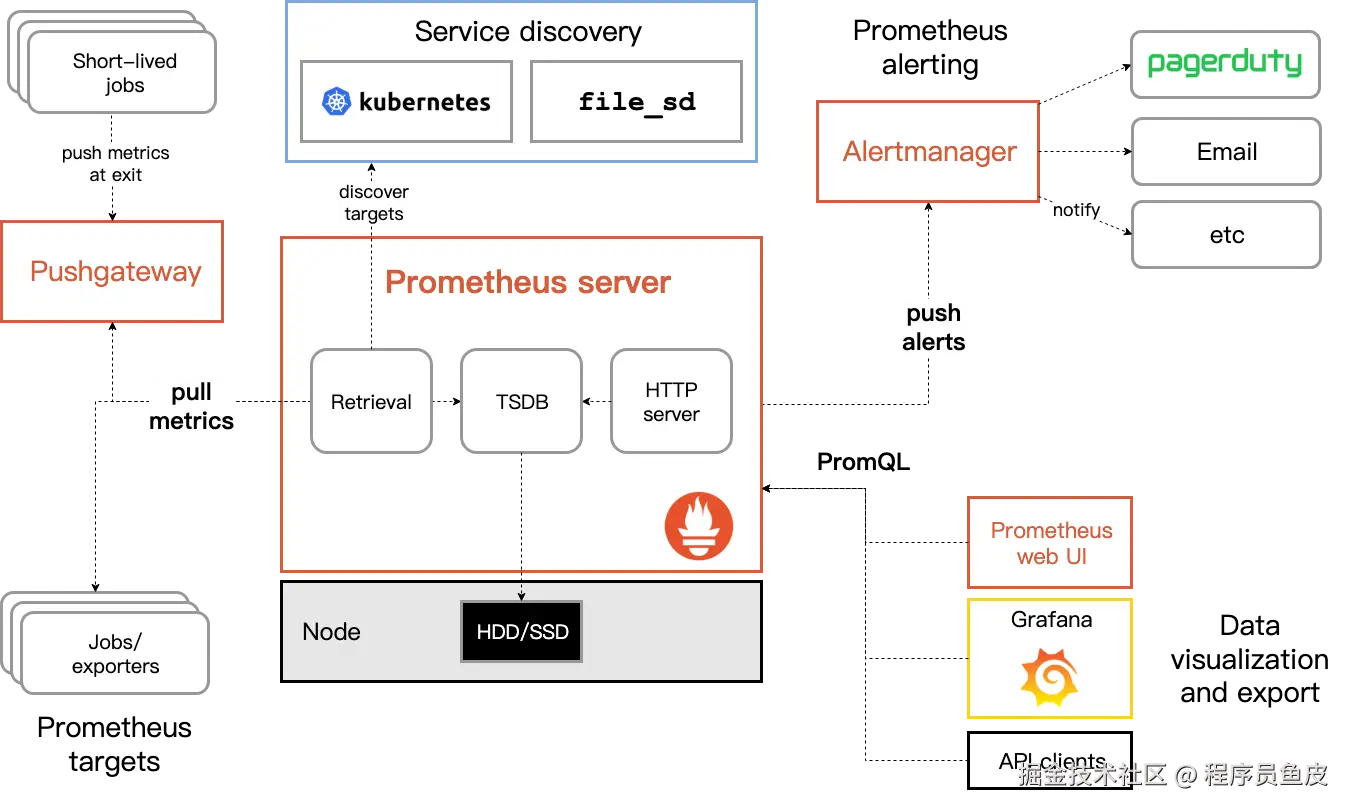
数据收集原理
Prometheus 采用 拉取模式 来收集指标数据,而不是由项目主动推送数据,这是它的核心特征。
它会定期向配置的目标发起 HTTP 请求,从 /metrics 端点获取指标数据。
拉模式的好处是:
- 简单可靠:基于标准 HTTP 协议,无需复杂的消息队列或特殊的网络配置
- 监控目标的发现和管理更加灵活:Prometheus 可以通过服务发现机制自动发现新的监控目标。而且将监控的控制权交给 Prometheus,可以避免目标服务的监控数据推送失败影响业务逻辑。
我们可以通过 Jobs 和 Instances 配置需要拉取的数据任务和服务实例,当 Prometheus 抓取目标时,会自动为每个时间序列添加 job 和 instance 标签来标识数据来源。同时还会生成一些元指标,比如 up 指标表示目标是否可达,scrape_duration_seconds 记录抓取耗时,这些信息对于监控系统自身的健康检查非常有用。
指标类型
如果想在项目中自定义指标收集,需要先了解 Prometheus 的 4 种核心 指标类型,每种类型都针对不同的监控场景进行了优化。
1)Counter:累积计数器,只能增加或重置为零,适合统计请求总数、错误次数等单调递增的指标。在我们的 AI 监控场景中,ai_model_requests_total 大模型请求总数就是一个典型的 Counter 指标。
2)Gauge:仪表盘类型,数值可以任意上下波动,适合记录当前状态值,比如内存使用量、当前在线用户数、队列长度等。
3)Histogram:直方图类型,用于观察数据分布情况,比如请求响应时间的分布。它会自动生成多个时间序列,包括各个桶的计数、总和以及总数,可以用来计算百分位数等统计指标。
4)Summary:和 Histogram 类似,但它在客户端预先计算百分位数,适合需要精确百分位数计算但对网络传输有要求的场景。
通过合理选择指标类型,我们可以用最小的存储开销获得最大的监控价值。
存储机制
提到拉模式,可能会有朋友误以为 Prometheus 不存储数据,实际上它拥有自己的高性能时间序列数据库 TSDB,单节点就能处理数百万个时间序列,满足大部分企业的监控需求。
新写入的数据首先存储在内存中,达到时间阈值(每 2 小时一个数据块)后批量写入磁盘,这种设计在保证查询性能的同时也提供了良好的写入吞吐量。预写日志 WAL 机制确保了数据的可靠性,即使系统崩溃也不会丢失数据。
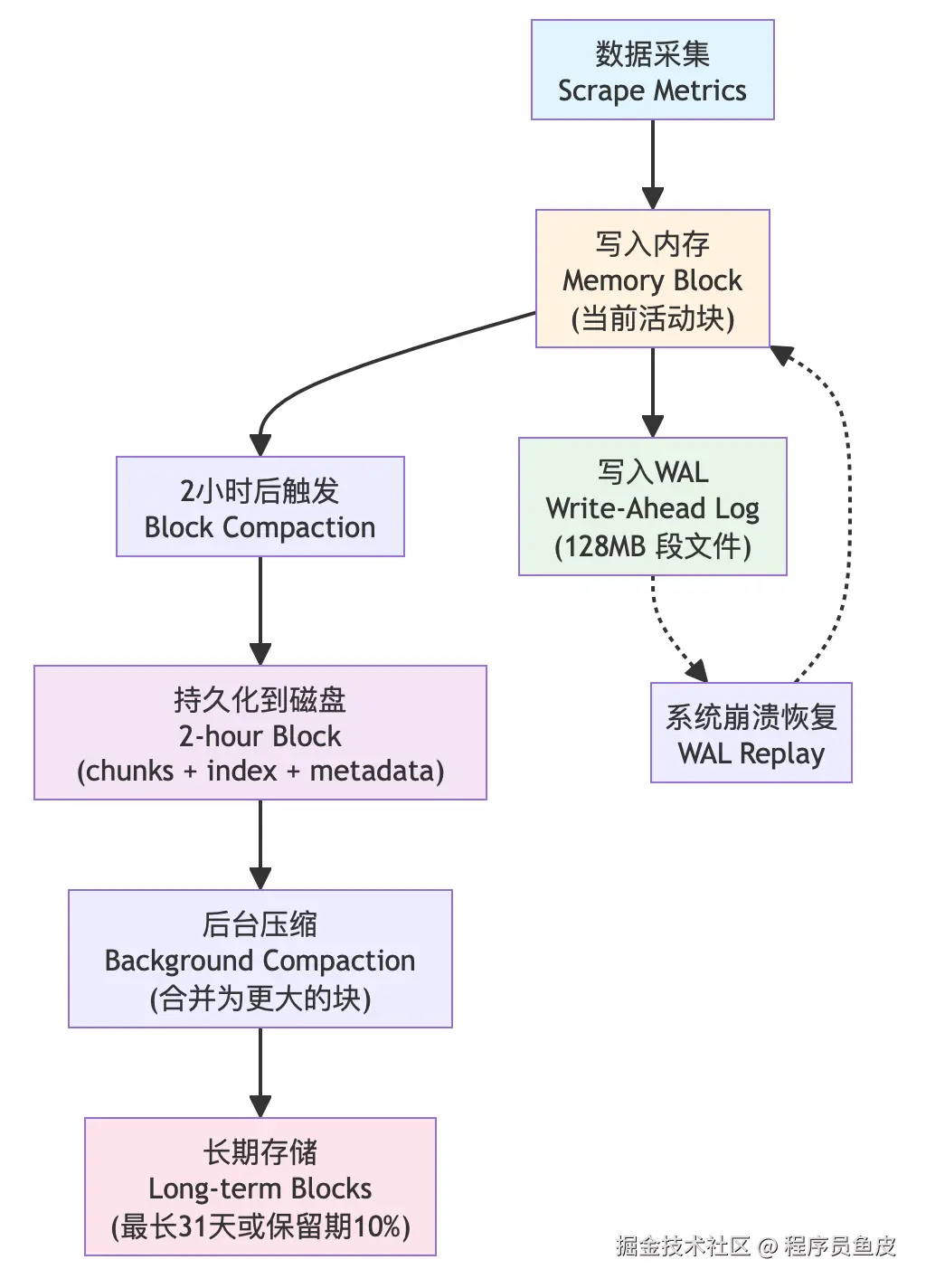
什么是 Grafana?
Grafana 是一个开源的数据可视化平台,专门用于创建监控看板。它可以连接多种数据源(包括 Prometheus、MySQL、PostgreSQL、Elasticsearch 等),并提供丰富的图表类型和可视化选项。
虽然 Grafana 是一个功能非常丰富的企业级产品,拥有告警管理、用户权限控制、插件生态、云服务集成等高级特性,但对于我们目前的需求来说,将它当作一个看板工具来使用,知道怎么创建看板和接入数据进行展示就足够了。
环境准备
接下来我们先开始搭建 Prometheus + Grafana 监控环境。
为了照顾不便安装 Docker 或不熟悉 Docker 的同学,我这里使用普通的安装方式,会 Docker 的同学用 Docker 启动更方便。
Prometheus 安装
1)访问 Prometheus 下载页面,选择对应的操作系统和架构。
2)下载并解压到不包含中文路径的目录。
3)查看默认配置文件 prometheus.yml,关键配置如下:
makefile
# 抓取配置
scrape_configs:
# Prometheus 自身监控
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"]
labels:
app: "prometheus"默认配置会监控 Prometheus 自己,这样我们可以先测试环境是否正常。
4)启动 Prometheus:
ini
./prometheus --config.file=prometheus.yml启动成功后会在 9090 端口提供服务。
5)访问 http://localhost:9090 进入管理界面,建议开启本地时间(不然时间可能少 8 个小时):
访问 http://localhost:9090/metrics 可以看到 Prometheus 自身暴露的指标数据:
这就是 Prometheus 期望的指标数据格式,每个应用都需要在 /metrics 端点暴露类似的数据。
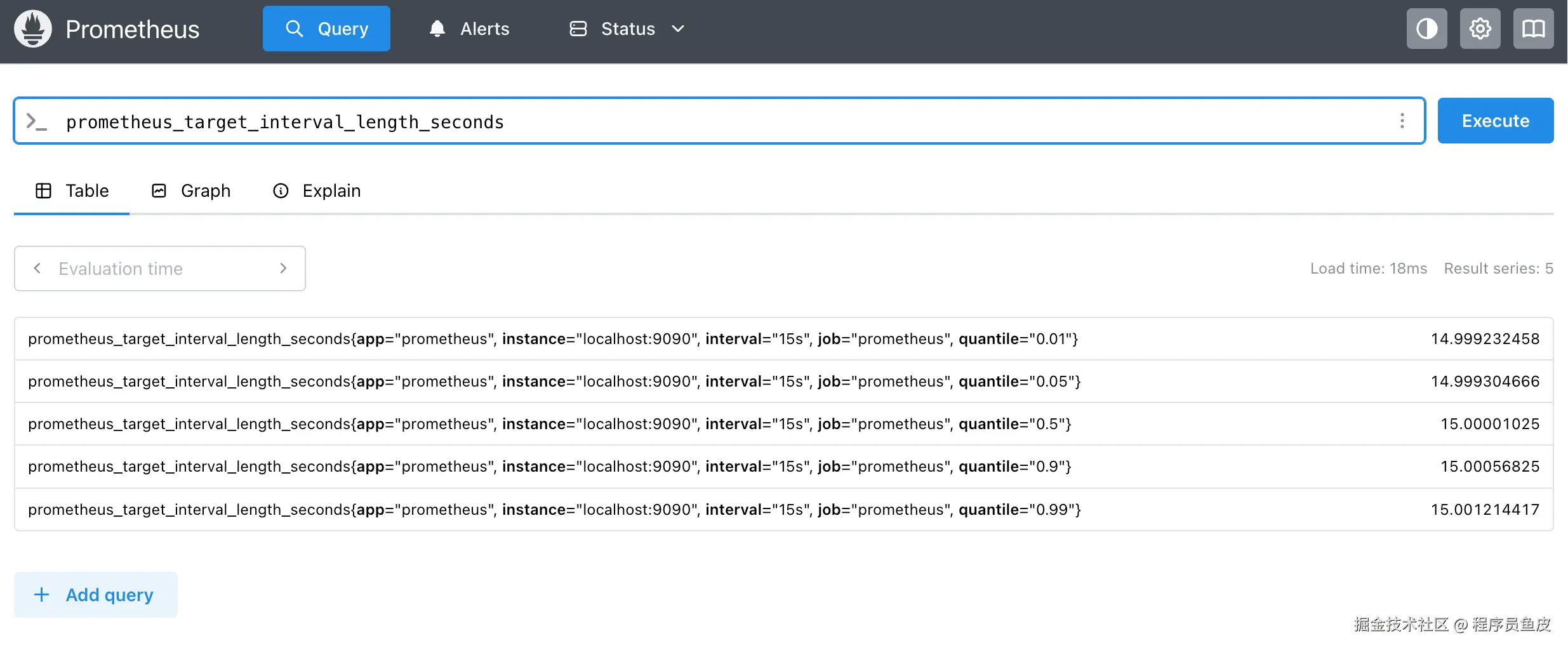
6)在 Prometheus 查询界面可以输入 PromQL 表达式 查看指标:
prometheus_target_interval_length_seconds这个指标记录了 Prometheus 抓取目标之间的实际时间间隔,比如你配置每 15 秒抓取一次,但实际可能是 14.8 秒或 15.2 秒,这个指标就记录这些实际值。
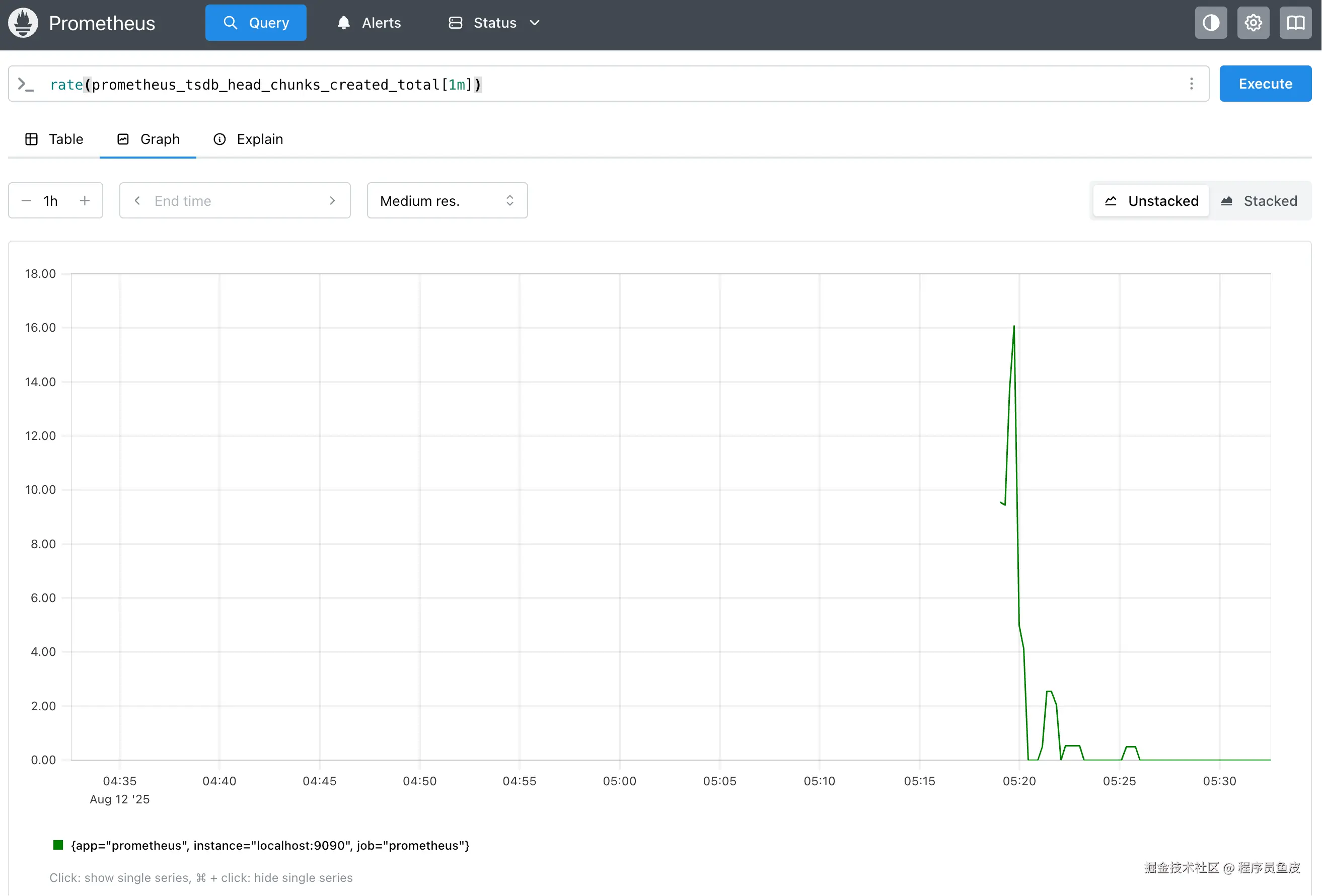
7)在 Graph 页签可以查看可视化图表,比如计算过去 1 分钟内 Prometheus 每秒平均创建的内存数据块数:
scss
rate(prometheus_tsdb_head_chunks_created_total[1m])如图:
Grafana 安装
1)访问 Grafana 下载页面,根据操作系统选择对应的安装包。
2)按照对应系统的 安装文档 进行安装。比如 Windows 系统直接执行 grafana-server.exe,Mac 系统执行下列命令:
bash
./bin/grafana server3)访问 http://localhost:3000 查看看板,默认登录账号密码都是 admin:
Grafana 整合 Prometheus
Grafana 与 Prometheus 打配合的 工作原理 很简单:Grafana 通过 HTTP API 从 Prometheus 查询数据,然后以图表形式展示。用户可以编写 PromQL 表达式来实现灵活的数据分析。
下面我们先来跑通一下整合流程。
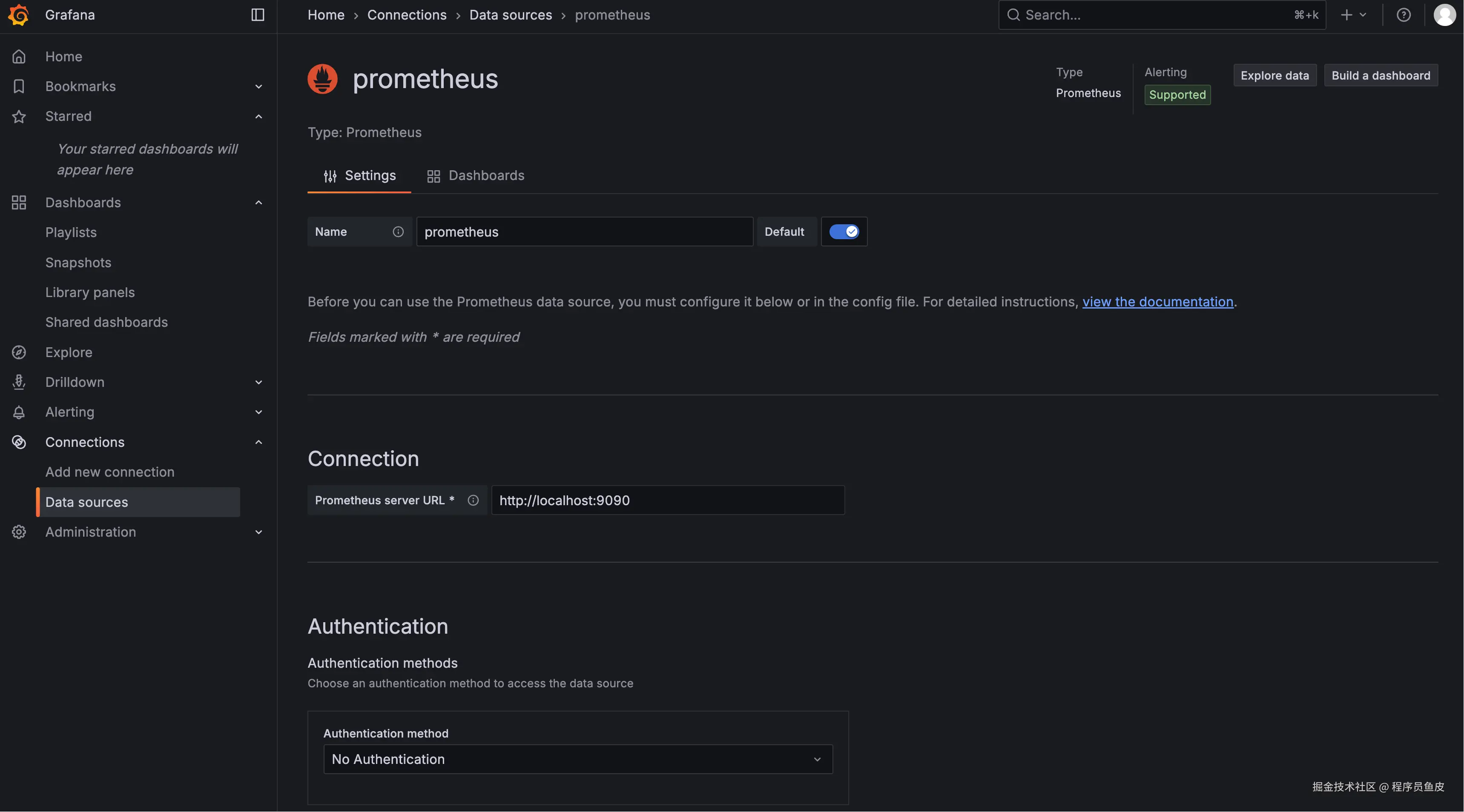
1)参考 官方文档,登录 Grafana 后,需要先添加 Prometheus 作为数据源:
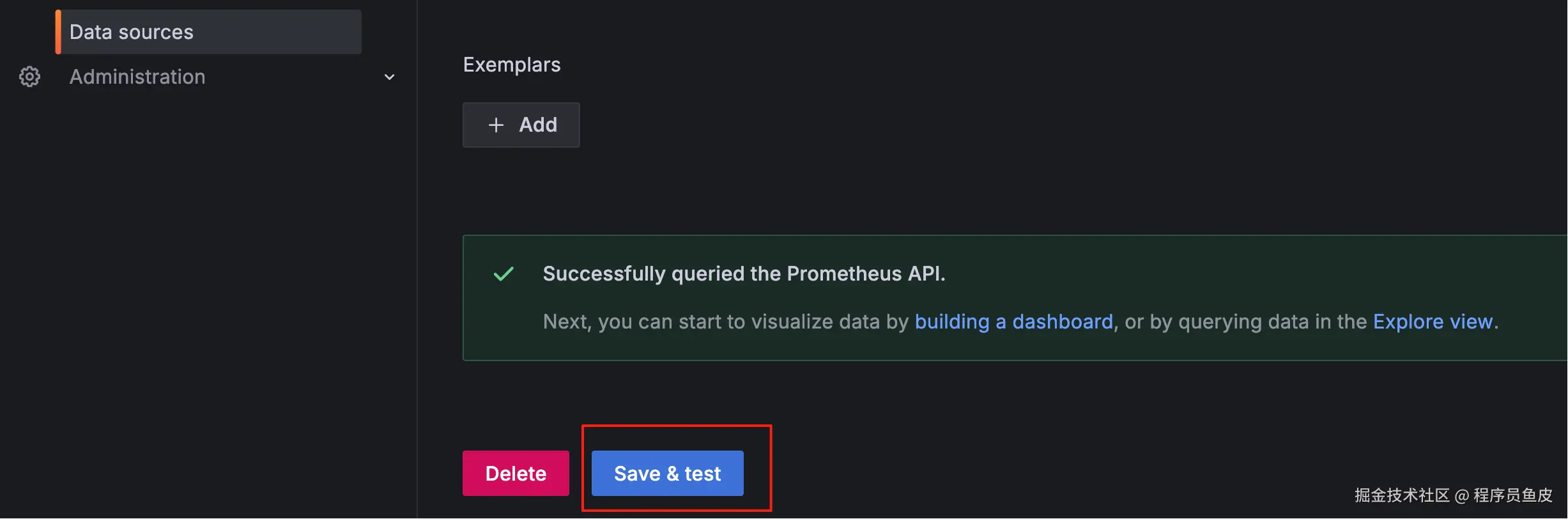
配置 Prometheus 服务器地址,然后测试连接:
2)快速导入现成的仪表板模板:
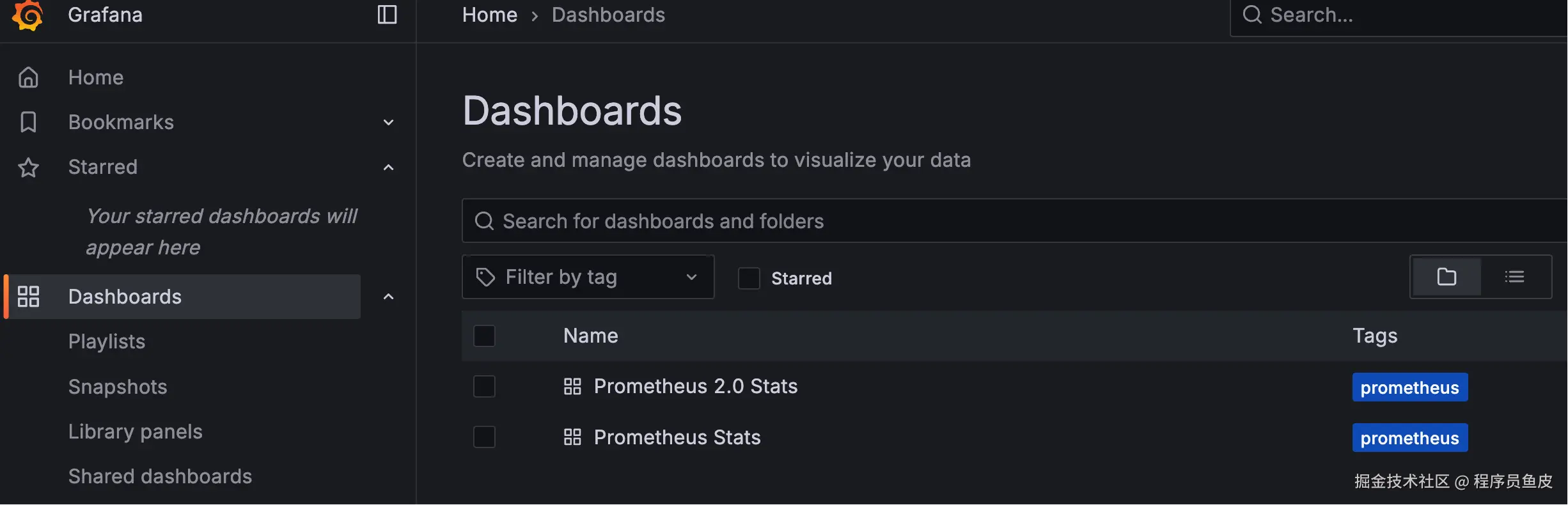
3)进入看板页面,查看导入的看板:
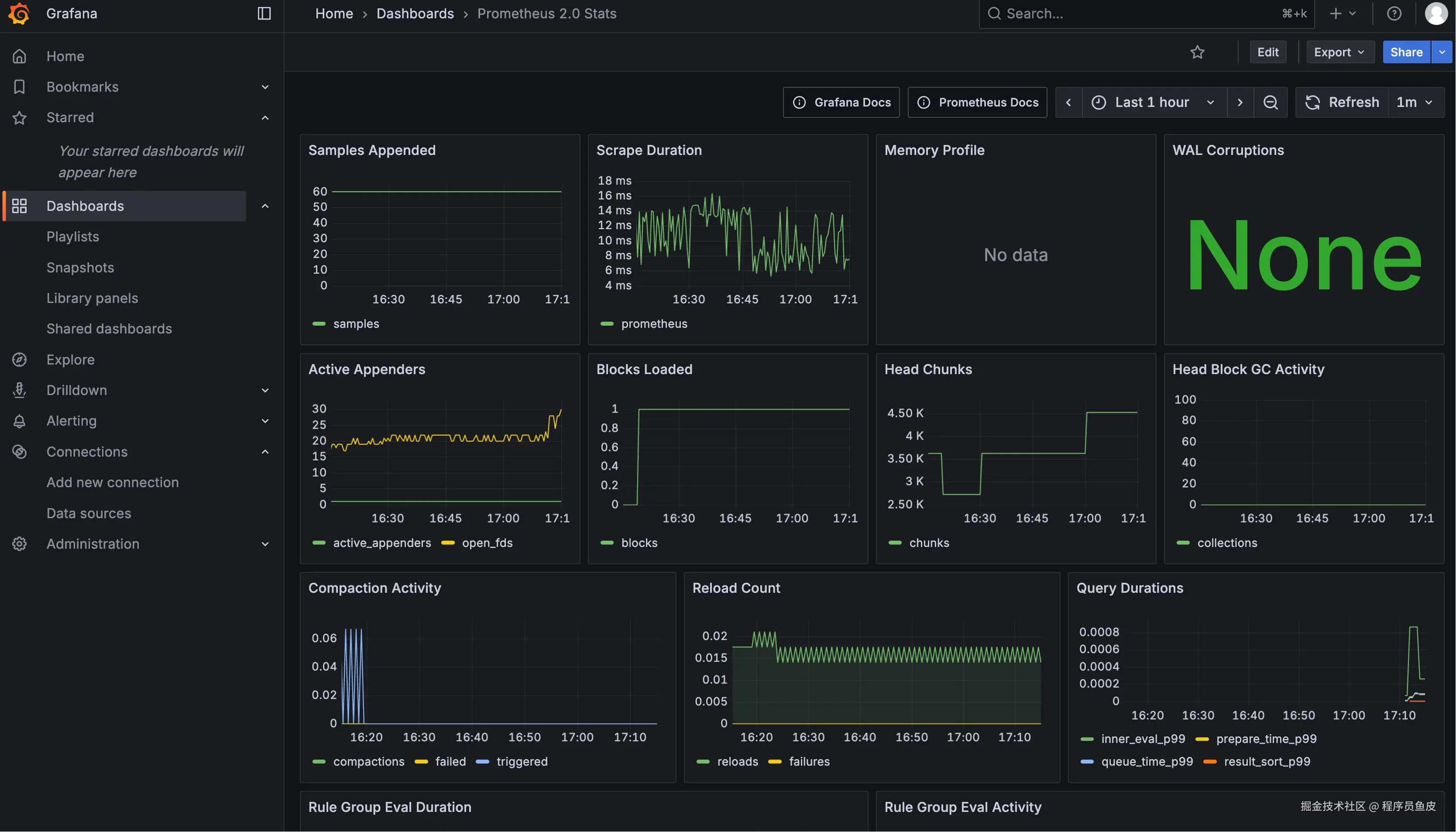
4)查看看板详情,一个仪表板可以包含多个 Panel(图表面板):
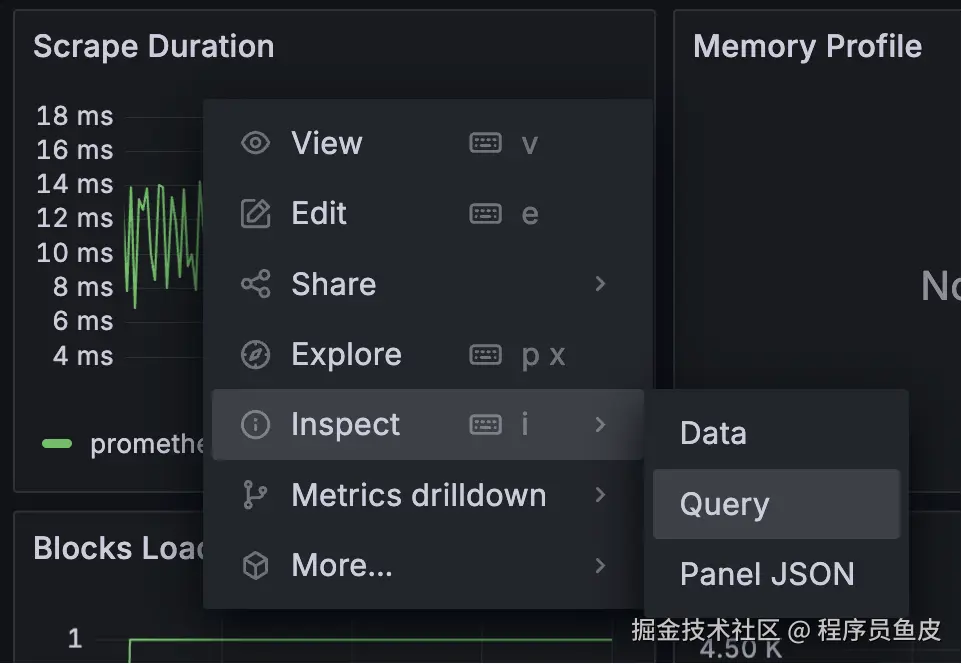
每个 Panel 都可以查看具体的数据、状态和查询语句:
开发实现
环境准备就绪后,接下来在我们的 AI 零代码应用生成平台中实现业务监控功能。
1、引入依赖
在 pom.xml 中添加必要的依赖:
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-registry-prometheus</artifactId>
</dependency>建议大家理解每个依赖的作用:
1)spring-boot-starter-actuator:Actuator 提供生产就绪的监控基础设施,暴露各种管理和监控端点。它是应用与外部监控系统交互的窗口,但本身不负责指标数据的收集。
2)micrometer-core:Micrometer 是真正的指标收集引擎,负责收集 JVM、HTTP、数据库等各种指标数据。它提供统一的 API 让开发者可以创建自定义指标(类似于一个门面),是整个监控体系的数据生产者。
3)micrometer-registry-prometheus:Prometheus Registry 专门负责将 Micrometer 收集的指标数据转换为 Prometheus 格式。它创建 /actuator/prometheus 端点,让 Prometheus 服务器可以直接拉取标准格式的监控数据。
Prometheus 可以定期访问 /actuator/prometheus 端点拉取指标数据,实现对 Spring Boot 应用的持续监控和告警。
2、编写配置
在 application.yml 中添加 Actuator 配置,暴露监控端点:
yaml
management:
endpoints:
web:
exposure:
include: health,info,prometheus
endpoint:
health:
show-details: always重启项目后,可以访问端点验证配置。比如 Prometheus 指标端点:http://localhost:8123/api/actuator/prometheus,可以看到 Spring Boot 默认提供的各种系统指标。
3、监控上下文
由于需要在监听器中获取业务维度信息(比如 appId、userId),我们可以通过 ThreadLocal 来传递这些参数。
1)在 monitor 包下定义上下文类 MonitorContext:
less
@Data
@Builder
@NoArgsConstructor
@AllArgsConstructor
public class MonitorContext implements Serializable {
private String userId;
private String appId;
@Serial
private static final long serialVersionUID = 1L;
}还可以按需添加 requestId、chatHistoryId 等字段。
2)定义上下文持有者 MonitorContextHolder,提供 ThreadLocal 的读、写、清除方法:
csharp
@Slf4j
public class MonitorContextHolder {
private static final ThreadLocal<MonitorContext> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 设置监控上下文
*/
public static void setContext(MonitorContext context) {
CONTEXT_HOLDER.set(context);
}
/**
* 获取当前监控上下文
*/
public static MonitorContext getContext() {
return CONTEXT_HOLDER.get();
}
/**
* 清除监控上下文
*/
public static void clearContext() {
CONTEXT_HOLDER.remove();
}
}3)在 AppServiceImpl 的 chatToGenCode 方法中设置上下文,并在 AI 调用流结束时清理:
less
// 5. 通过校验后,添加用户消息到对话历史
chatHistoryService.addChatMessage(appId, message, ChatHistoryMessageTypeEnum.USER.getValue(), loginUser.getId());
// 6. 设置监控上下文
MonitorContextHolder.setContext(
MonitorContext.builder()
.userId(loginUser.getId().toString())
.appId(appId.toString())
.build()
);
// 7. 调用 AI 生成代码(流式)
Flux<String> codeStream = aiCodeGeneratorFacade.generateAndSaveCodeStream(message, codeGenTypeEnum, appId);
// 8. 收集 AI 响应内容并在完成后记录到对话历史
return streamHandlerExecutor.doExecute(codeStream, chatHistoryService, appId, loginUser, codeGenTypeEnum)
.doFinally(signalType -> {
// 流结束时清理(无论成功/失败/取消)
MonitorContextHolder.clearContext();
});注意清理时机应该是在流结束时,而不是方法返回值之前,这样能确保整个请求周期内都能获取到上下文信息。
4、指标收集器
编写指标收集器,负责收集业务数据并转换为 Prometheus 指标。
这一步不用想太多,尽量把 最细粒度的数据 按照维度分类统计就好。
指标收集器需要提供几个方法,分别统计请求信息、错误信息、Token 消耗、响应时间,下面仅列举部分代码:
less
@Component
@Slf4j
public class AiModelMetricsCollector {
@Resource
private MeterRegistry meterRegistry;
// 缓存已创建的指标,避免重复创建(按指标类型分离缓存)
private final ConcurrentMap<String, Counter> requestCountersCache = new ConcurrentHashMap<>();
private final ConcurrentMap<String, Timer> responseTimersCache = new ConcurrentHashMap<>();
/**
* 记录请求次数
*/
public void recordRequest(String userId, String appId, String modelName, String status) {
String key = String.format("%s_%s_%s_%s", userId, appId, modelName, status);
Counter counter = requestCountersCache.computeIfAbsent(key, k ->
Counter.builder("ai_model_requests_total")
.description("AI模型总请求次数")
.tag("user_id", userId)
.tag("app_id", appId)
.tag("model_name", modelName)
.tag("status", status)
.register(meterRegistry)
);
counter.increment();
}
// 省略记录错误和记录 Token 消耗的代码
/**
* 记录响应时间
*/
public void recordResponseTime(String userId, String appId, String modelName, Duration duration) {
String key = String.format("%s_%s_%s", userId, appId, modelName);
Timer timer = responseTimersCache.computeIfAbsent(key, k ->
Timer.builder("ai_model_response_duration_seconds")
.description("AI模型响应时间")
.tag("user_id", userId)
.tag("app_id", appId)
.tag("model_name", modelName)
.register(meterRegistry)
);
timer.record(duration);
}
}这里的几个关键点:
- 选择合适的指标类型:Counter 用于计数(请求次数、错误次数、Token 数量);Timer 用于时间测量(AI 模型响应时间)
- 使用缓存避免统计对象重复注册:Micrometer 会为相同的维度组合创建唯一的指标,通过缓存可以重用同一个 Counter / Timer 对象,避免每次调用都执行
Counter.builder()...register()操作。
5、AI 调用监听器
编写 LangChain4j 监听器来触发指标收集,这是整个监控体系的核心。下面列举监听 AI 请求和响应的代码:
scss
@Component
@Slf4j
public class AiModelMonitorListener implements ChatModelListener {
// 用于存储请求开始时间的键
private static final String REQUEST_START_TIME_KEY = "request_start_time";
// 用于监控上下文传递(因为请求和响应事件的触发不是同一个线程)
private static final String MONITOR_CONTEXT_KEY = "monitor_context";
@Resource
private AiModelMetricsCollector aiModelMetricsCollector;
@Override
public void onRequest(ChatModelRequestContext requestContext) {
// 记录请求开始时间
requestContext.attributes().put(REQUEST_START_TIME_KEY, Instant.now());
// 从监控上下文中获取信息
MonitorContext context = MonitorContextHolder.getContext();
String userId = context.getUserId();
String appId = context.getAppId();
requestContext.attributes().put(MONITOR_CONTEXT_KEY, context);
// 获取模型名称
String modelName = requestContext.chatRequest().modelName();
// 记录请求指标
aiModelMetricsCollector.recordRequest(userId, appId, modelName, "started");
}
@Override
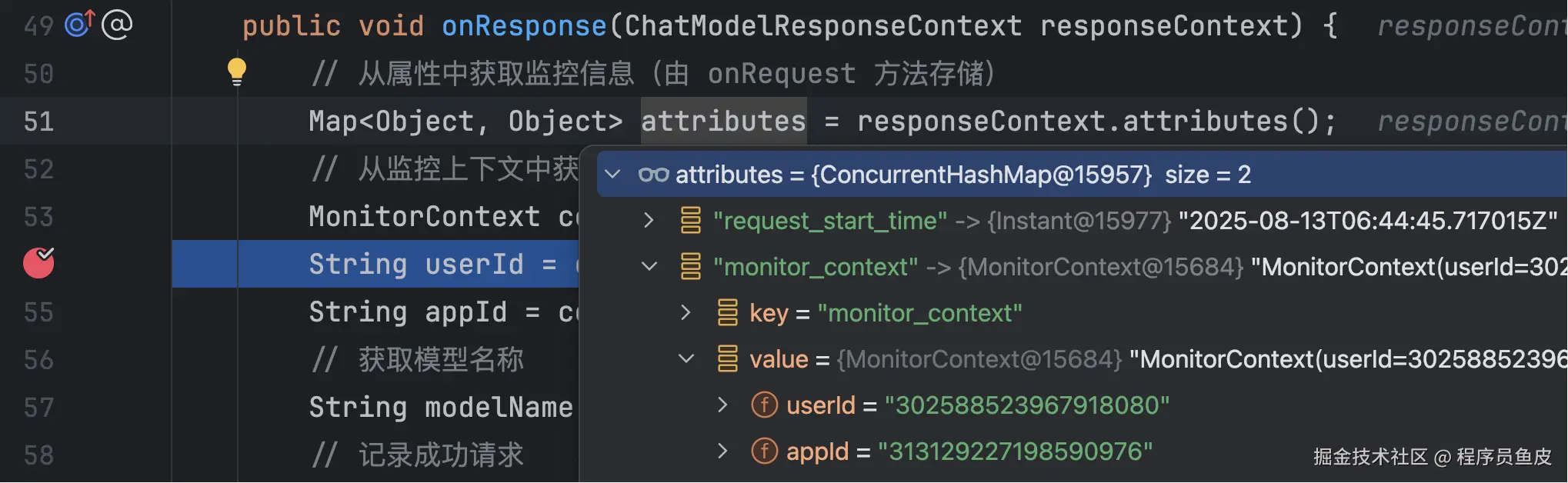
public void onResponse(ChatModelResponseContext responseContext) {
// 从属性中获取监控信息(由 onRequest 方法存储)
Map<Object, Object> attributes = responseContext.attributes();
// 从监控上下文中获取信息
MonitorContext context = (MonitorContext) attributes.get(MONITOR_CONTEXT_KEY);
String userId = context.getUserId();
String appId = context.getAppId();
// 获取模型名称
String modelName = responseContext.chatResponse().modelName();
// 记录成功请求
aiModelMetricsCollector.recordRequest(userId, appId, modelName, "success");
// 记录响应时间
recordResponseTime(attributes, userId, appId, modelName);
// 记录 Token 使用情况
recordTokenUsage(responseContext, userId, appId, modelName);
}
// 省略监听错误的代码
/**
* 记录响应时间
*/
private void recordResponseTime(Map<Object, Object> attributes, String userId, String appId, String modelName) {
Instant startTime = (Instant) attributes.get(REQUEST_START_TIME_KEY);
Duration responseTime = Duration.between(startTime, Instant.now());
aiModelMetricsCollector.recordResponseTime(userId, appId, modelName, responseTime);
}
/**
* 记录Token使用情况
*/
private void recordTokenUsage(ChatModelResponseContext responseContext, String userId, String appId, String modelName) {
TokenUsage tokenUsage = responseContext.chatResponse().metadata().tokenUsage();
if (tokenUsage != null) {
aiModelMetricsCollector.recordTokenUsage(userId, appId, modelName, "input", tokenUsage.inputTokenCount());
aiModelMetricsCollector.recordTokenUsage(userId, appId, modelName, "output", tokenUsage.outputTokenCount());
aiModelMetricsCollector.recordTokenUsage(userId, appId, modelName, "total", tokenUsage.totalTokenCount());
}
}
}有几个重要细节需要注意:
- 线程切换问题:请求监听在主线程,但响应监听可能在另一个线程,所以要通过 AI context 的 attributes 传递参数。
- 时间计算:在请求开始时记录时间戳,在响应完成时计算耗时。
然后需要将监听器注册到 AI 模型配置中。修改 ReasoningStreamingChatModelConfig 和 StreamingChatModelConfig:
less
@Resource
private AiModelMonitorListener aiModelMonitorListener;
@Bean
@Scope("prototype")
public StreamingChatModel streamingChatModelPrototype() {
return OpenAiStreamingChatModel.builder()
// ... 省略其他配置
.listeners(List.of(aiModelMonitorListener))
.build();
}6、测试验证
通过前端发起一次 AI 对话请求(需要调用 chatToGenCode 方法),看看会不会触发监听器的方法。
成功触发请求监听,能够获取到上下文信息:

触发响应监听,能够获取到请求时间和上下文信息:
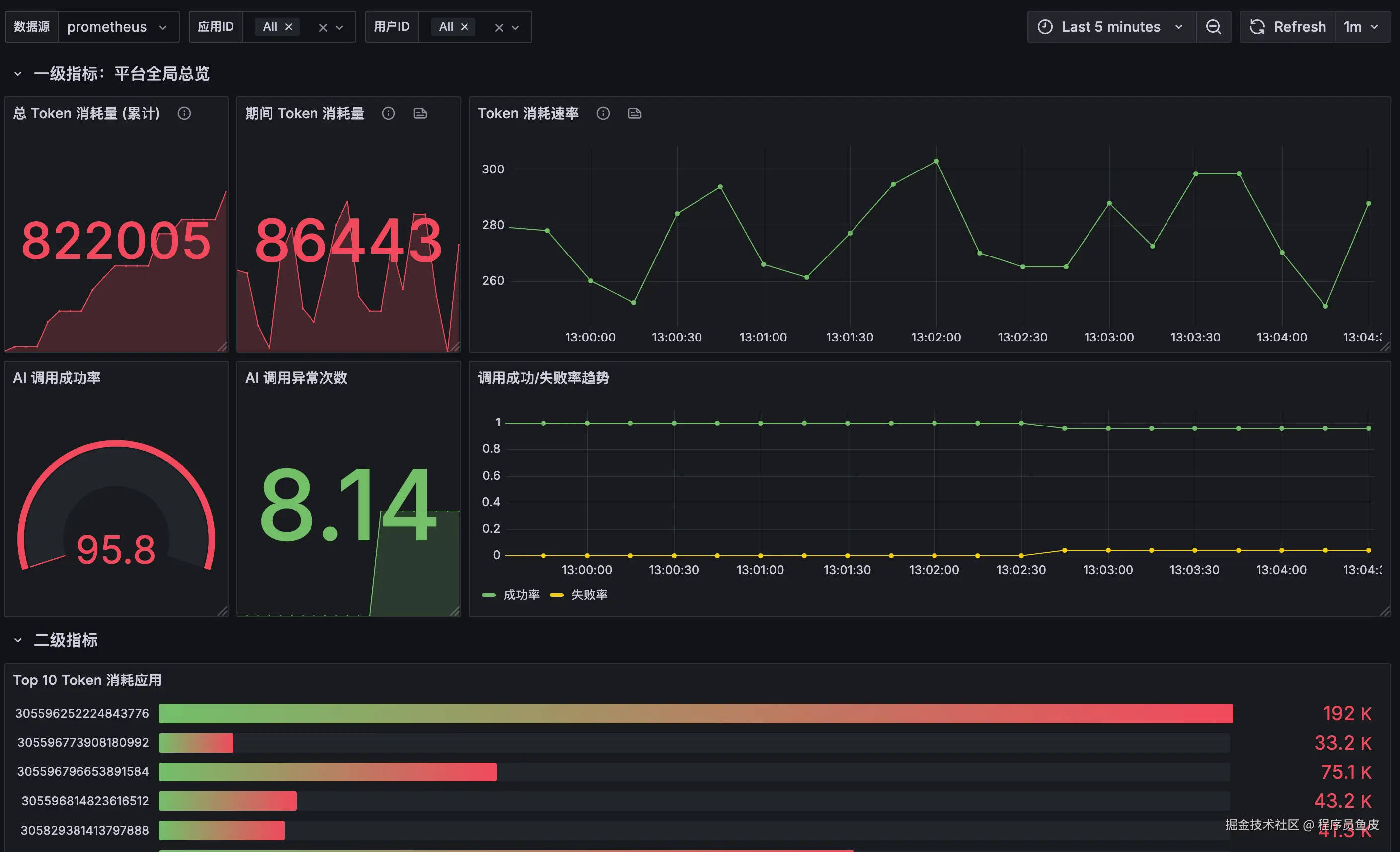
查看指标数据:
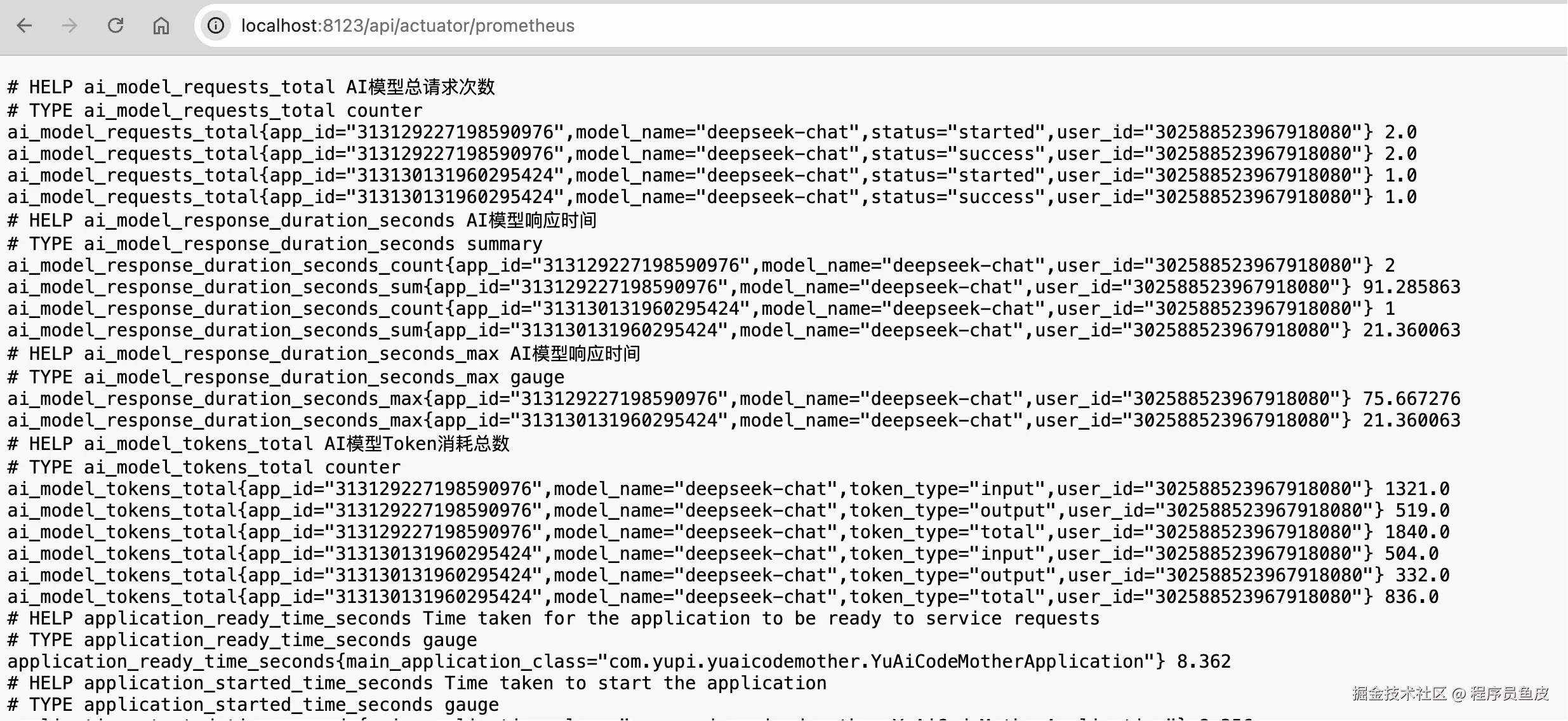
可以看到相同维度的指标自动进行了聚合,确认各个指标统计正确。
7、Prometheus 配置
现在需要配置 Prometheus 定期从我们的应用拉取监控数据,增加一个抓取任务:
bash
# 抓取配置
scrape_configs:
# Prometheus 自身监控
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# Spring Boot 应用监控
- job_name: 'yu-ai-code-mother'
metrics_path: '/api/actuator/prometheus' # Spring Boot Actuator 端点
static_configs:
- targets: ['localhost:8123'] # 应用服务器地址
scrape_interval: 10s # 每 10 秒抓取一次
scrape_timeout: 10s # 抓取超时时间然后使用新配置启动 Prometheus:
ini
./prometheus --config.file=<配置文件路径>测试查询我们自定义的指标:
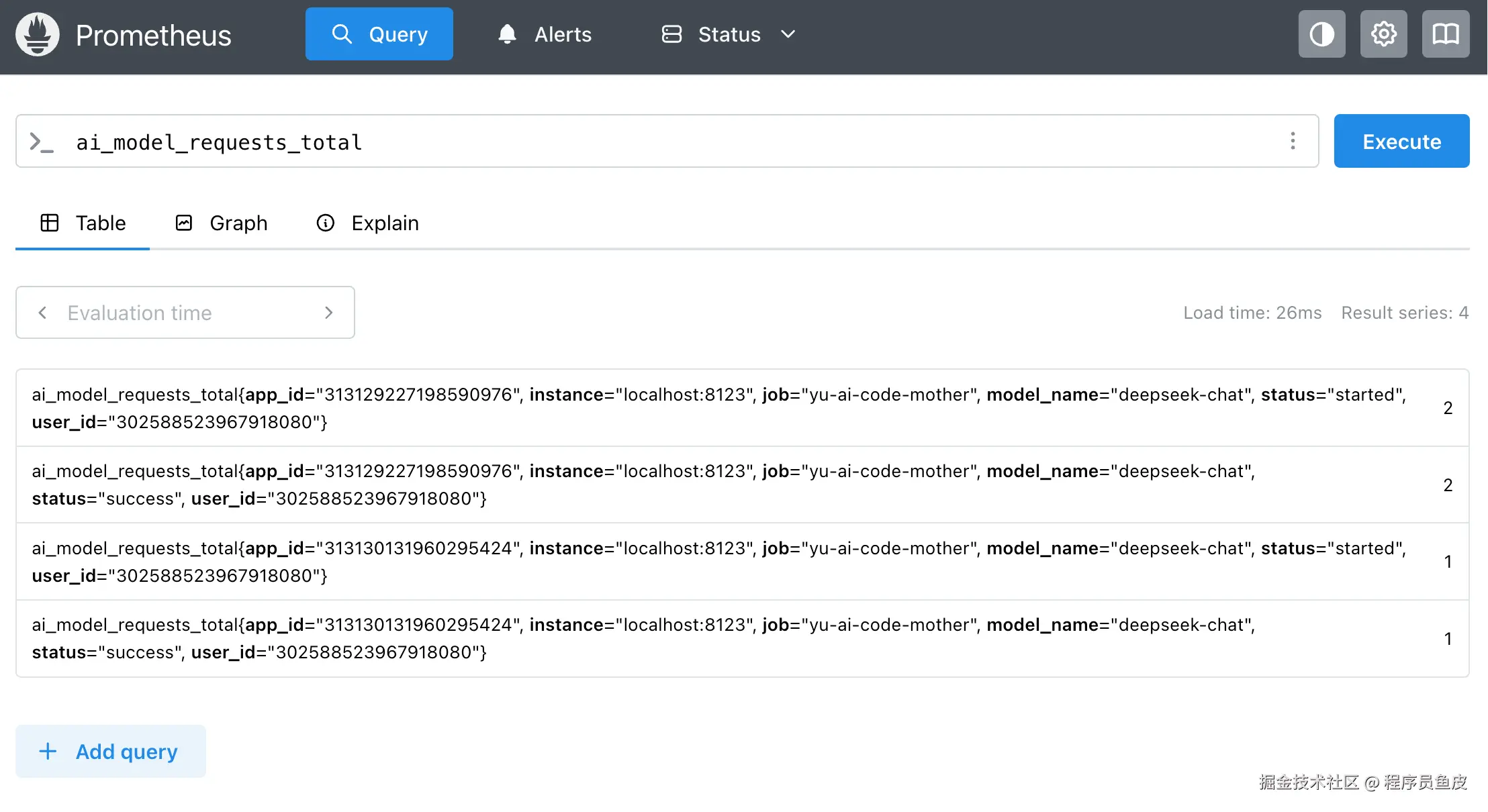
8、Grafana 可视化监控配置
有了数据后,接下来在 Grafana 中创建可视化看板。
一个个手动创建图表会比较麻烦,更高效的方式是让 AI 帮我们生成完整的看板 JSON 配置。需要给 AI 提供需求说明、数据样例和 Grafana 规范。
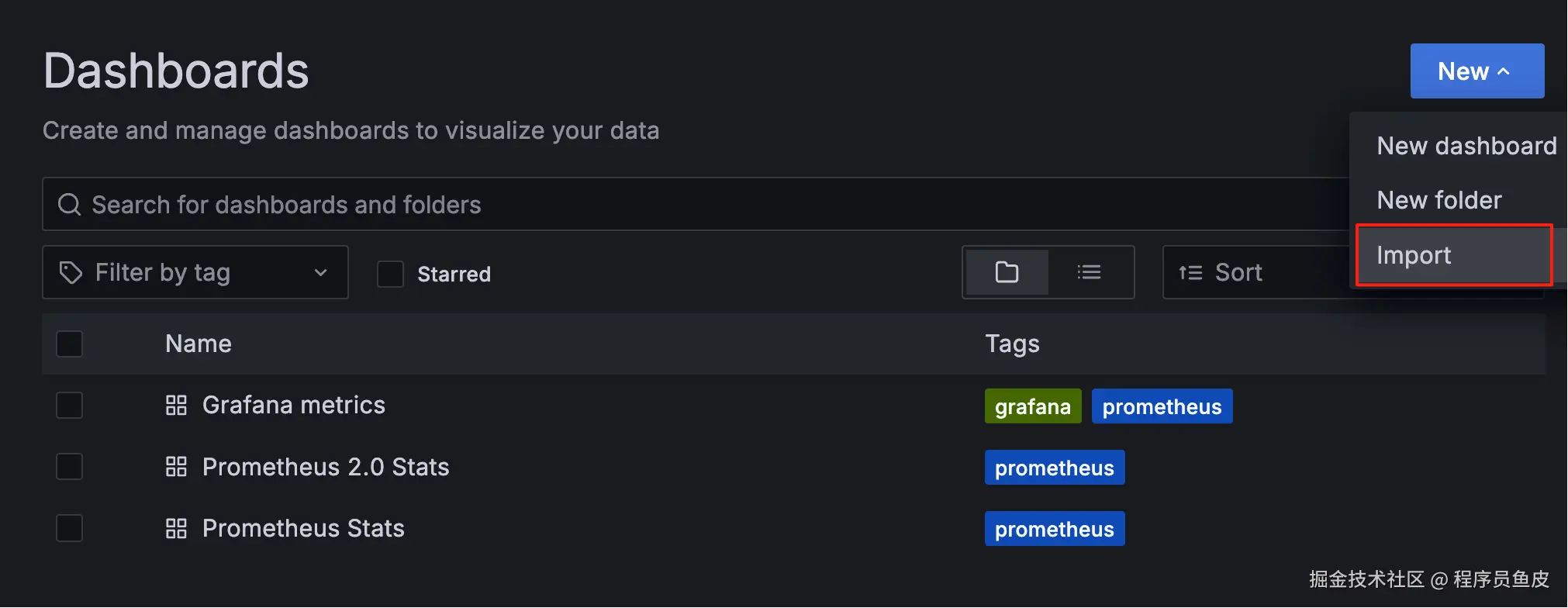
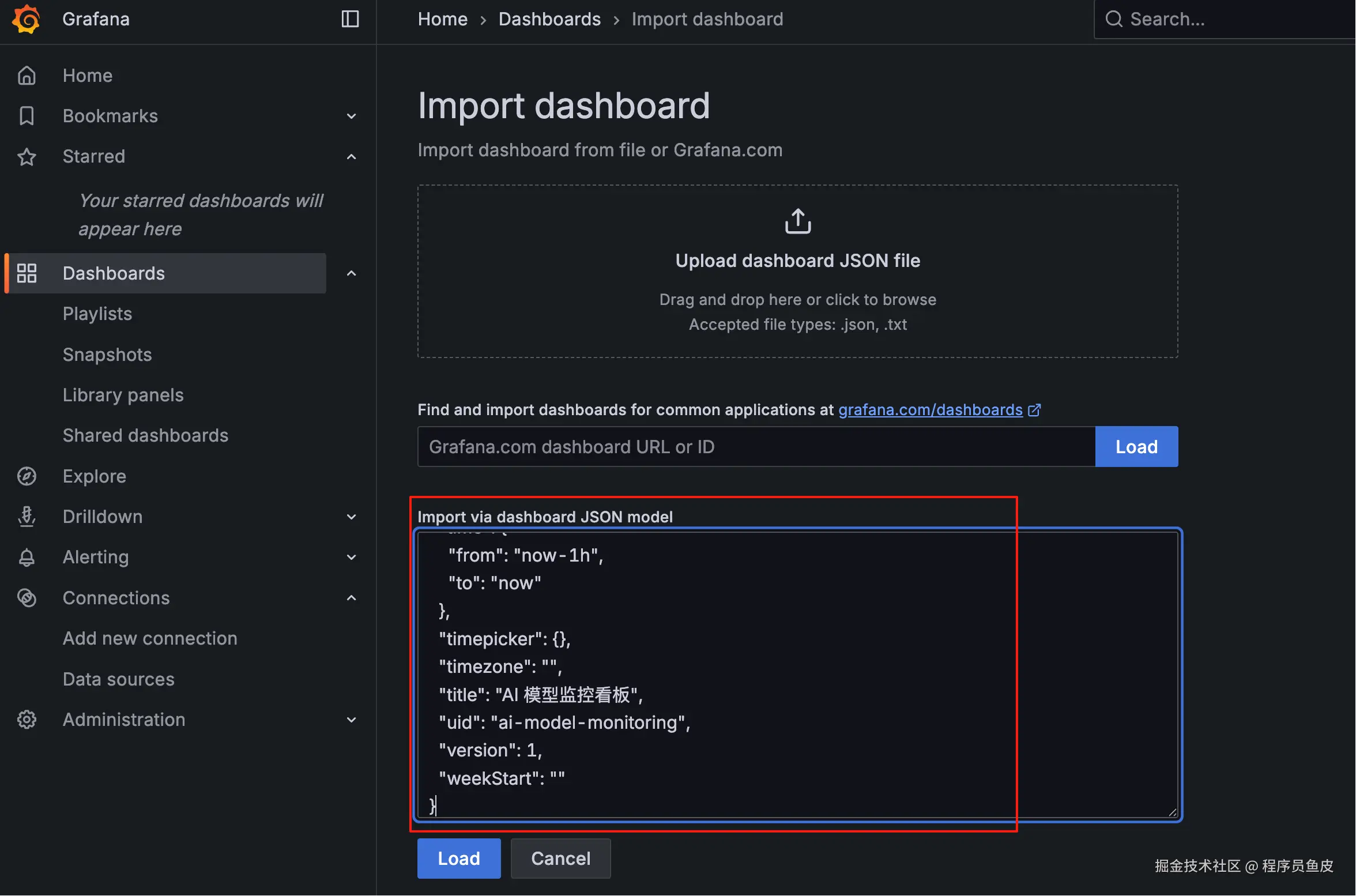
可以通过导入生成的 JSON 配置快速创建完整的看板:
看板代码可以在源码仓库获取:github.com/liyupi/yu-a...(记得点个 star 再走哦,感谢支持!)
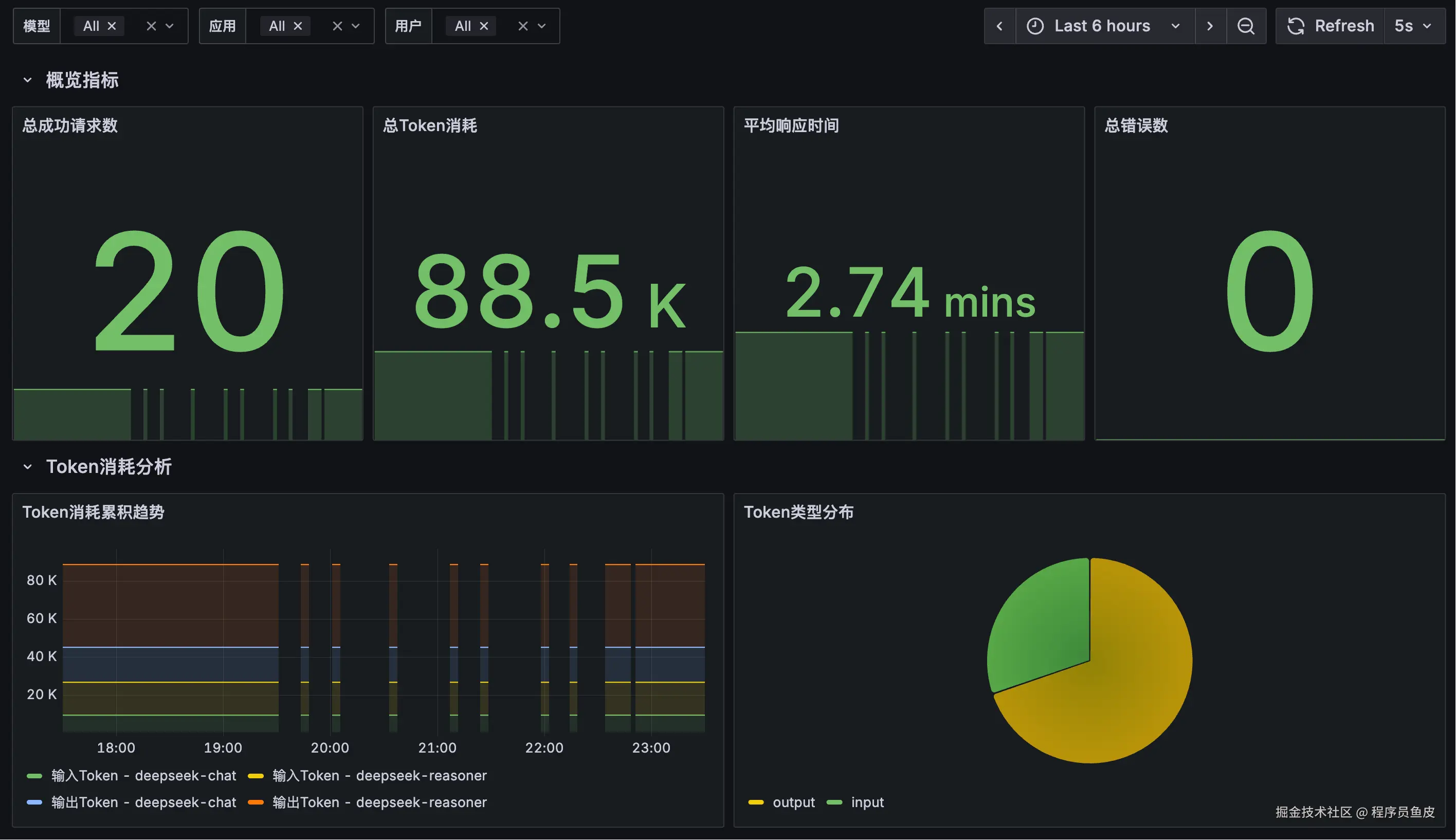
效果如图:
OK,就分享到这里。希望大家掌握这些技术、以及实现可观测性的套路,能够为项目搭建合理的监控分析系统,构建更可靠的 AI 应用。