RAG医疗问答系统_项目概述与背景
在当今科技飞速发展的时代,人工智能(AI)已经成为各行各业不可或缺的一部分。特别是在文档处理和数据分析领域,AI的应用更是无处不在。今天,我要向大家介绍一个开源的AI框架引擎------RAGflow。它能够在深度文档理解方面执行检索增强生成(Retrieval-Augmented Generation,简称RAG),并且被认为是目前最优秀的RAG框架之一。本文将详细探讨RAGflow的创新功能、技术特点以及如何在实际应用中发挥其最大潜力。
RAG医疗问答系统_项目搭建与环境配置
引入依赖
XML
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-open-ai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>1.5.8</version>
</dependency>
<!-- 向量数据库qdrant依赖包 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-qdrant</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-zhipu-ai</artifactId>
<version>0.35.0</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-all</artifactId>
<version>5.8.26</version>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-searchapi</artifactId>
</dependency>
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-jina</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-spring-boot3-starter</artifactId>
<version>3.5.9</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>
</dependencies>编写主启动类
java
/**
* 主启动类
*/
@Slf4j
@SpringBootApplication
public class MedicalApplication
{
public static void main( String[] args )
{
SpringApplication.run(MedicalApplication.class,args);
log.info("************* ChatApplication success ***********");
}
}RAG医疗问答系统_数据准备与知识库构建
https://huggingface.co/datasets/InfiniFlow/medical_QA/tree/main
HuggingFace简介
和 Github 类似,都是Hub(社区)。Hugging Face可以说的上是机器学习界的Github。
Hugging Face主要功能
- Git仓库可以让你管理代码版本、开源代码。
- Hugging Face上有许多公开数据集。
- Transformers: Transformers提供了上千个预训练好的模型可以用于不同的任务,例如文本领域、音频领域和CV领域。
- Datasets: 一个轻量级的数据集框架,主要有两个功能:①一行代码下载和预处理常用的公开数据集; ② 快速、易用的数据预处理类库。
- Space():Space提供了许多好玩的深度学习应用,可以尝试玩一下。
搜索数据集
数据介绍
- 医疗咨询
ChatMed_Consult-v0.3.CSV - 内科
Internal medicine_QA_all.csv - 医学肿瘤学
Medical Oncology_QA_all.csv - 妇产科
OB GYN_QA_all.csv - 儿科
Pediatrics_QA_all.csv - 男科
Andrology QA.CSV - 外科
urgical_QA_all.csv
RAG医疗问答系统_数据库设计

创建数据库
sql
CREATE TABLE `file_info` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`file_name` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '文件名字',
`file_size` bigint(20) DEFAULT NULL COMMENT '文件大小',
`char_count` int(11) DEFAULT NULL COMMENT '文件字符',
`segments` int(11) DEFAULT NULL COMMENT '文件分段',
`status` varchar(222) COLLATE utf8mb4_bin DEFAULT '待处理' COMMENT '文件状态',
`upload_time` timestamp NULL DEFAULT CURRENT_TIMESTAMP COMMENT '上传时间',
`file_path` varchar(255) COLLATE utf8mb4_bin DEFAULT NULL COMMENT '文件路径',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin;使用idea连接数据库
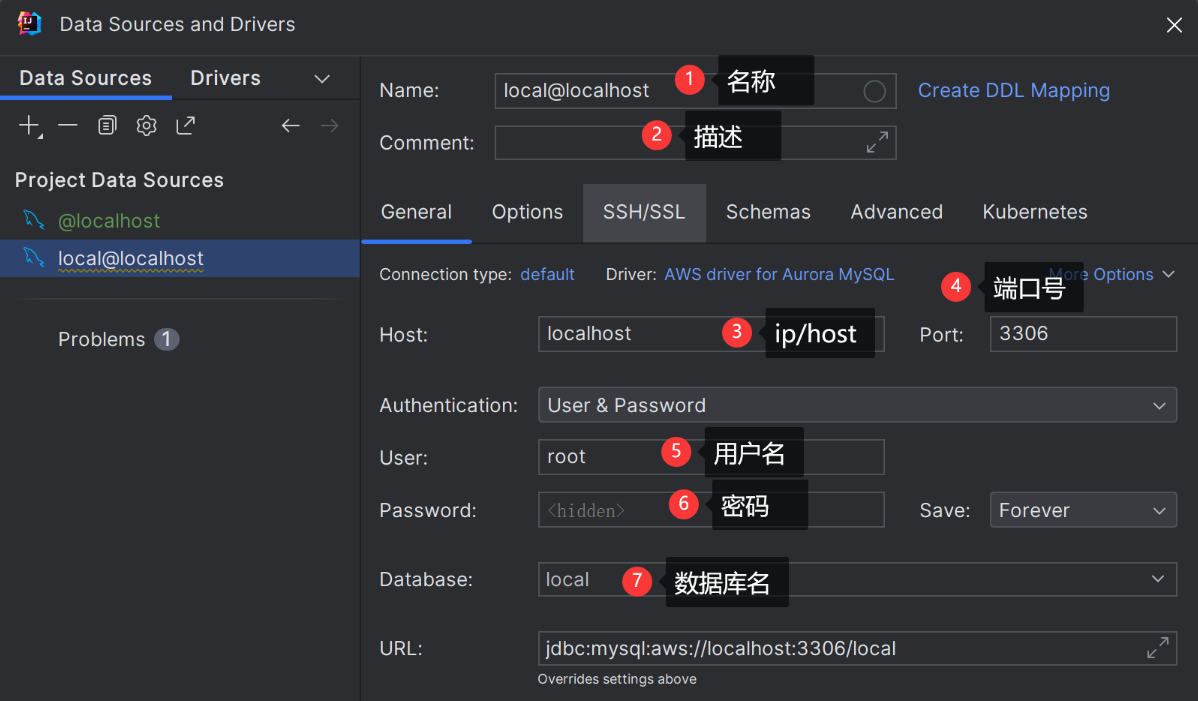
如果下载有问题,在这边可以配置驱动,根据自己的mysql版本来配置
Mybatis-X插件自动生成代码
第一步
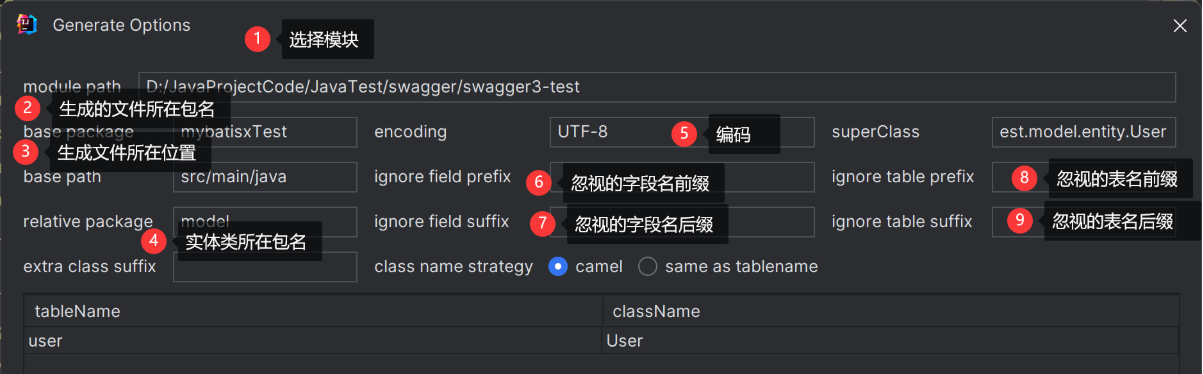
第二步
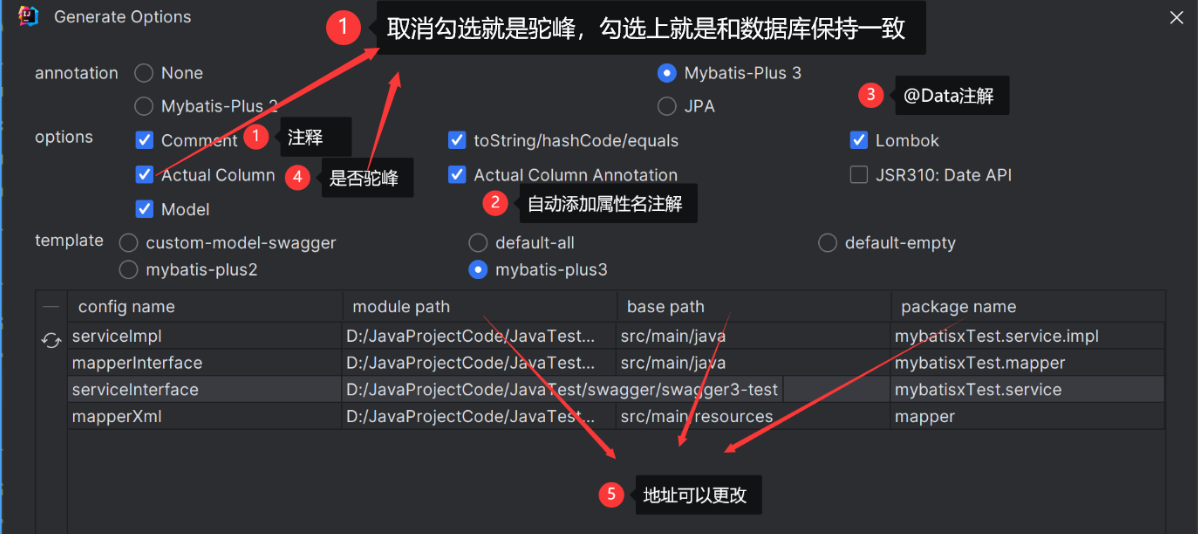
参数:
- custom-model-swagger:生成实体文件,属性上会自动增加swagger的相关注解。
- default-all:生成实体文件、xml文件和dao层接口文件,默认会生成常用的增删改查到的方法
- mybatis-plus3:生成实体文件、xml文件、dao层接口文件、service层接口文件和service层接口实现文件
编写核心配置文件
在resource文件夹下面创建application.yml文件
sql
logging:
pattern:
console: logging.pattern.console=%d{MM/dd HH:mm:ss.SSS} %clr(%-5level) --- [%-15thread] %cyan(%-50logger{50}):%msg%n
level:
dev:
langchain4j: debug
ai4j:
openai4j: debug
spring:
servlet:
multipart:
max-file-size: 500MB
max-request-size: 500MB
datasource:
driver-class-name: com.mysql.jdbc.Driver
username: root
password: 123456
url: jdbc:mysql://localhost:3306/rag?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false
file:
path: D:\filedata\RAG医疗问答系统_集成Thymeleaf构建知识库页面

导入依赖
<!-- SpringBoot框架集成Thymeleaf的起步依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
配置文件
配置application.yml
spring:
thymeleaf:
cache: false #关闭模板缓存,方便测试
suffix: .html
prefix: classpath:/templates/
创建controller
创建IndexController类,向Map中添加name,最后返回模板文件
//@PathVariable("page")括号里必须要指定参数,否则会报错 不能跳转到index页面
java
@Controller
public class IndexController {
//@PathVariable("page")括号里必须要指定参数
@GetMapping("/{page}")
public String page(@PathVariable("page") String page){
return page;
}
}编写知识库页面
在resource下面创建templates文件夹,创建index.html
html
<!DOCTYPE html>
<html lang="zh" xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<link rel="shortcut icon" href="../resources/favicon.ico" th:href="@{/static/favicon.ico}"/>
<link rel="stylesheet" type="text/css" href="../static/css/index.css" th:href="@{/css/index.css}">
<title>医疗智能体</title>
</head>
<body>
<!-- 头部用户信息 -->
<div class="header">
<div class="user-info">
<img src="https://www.w3schools.com/w3images/avatar2.png" alt="User Avatar">
<span>用户名: 小王</span>
</div>
</div>
<!-- 侧边栏导航 -->
<div class="sidebar">
<div class="tab active-tab" onclick="switchTab(0)">知识库上传</div>
<div class="tab" onclick="switchTab(1)">医疗智能</div>
</div>
<!-- 主内容区 -->
<div class="main-content">
<div class="tab-content active-content" id="uploadTab">
<h2>文件上传</h2>
<div class="upload-container">
<input type="file" id="fileInput">
<button onclick="uploadFile()">上传文件</button>
</div>
<!-- 文件列表显示 -->
<div class="file-list">
<h2>已上传文件</h2>
<table>
<thead>
<tr>
<th>文件名</th>
<th>文件大小</th>
<th>字符数量</th>
<th>分段</th>
<th>文件状态</th>
<th>操作</th>
</tr>
</thead>
<tbody id="fileListBody">
<!-- 动态填充文件列表 -->
</tbody>
</table>
</div>
</div>
<div class="tab-content" id="chatTab">
<h2>医疗智能体Agent</h2>
<p>医疗问答智能体是一种基于人工智能的系统,利用自然语言处理技术,能够理解和解答用
户的健康相关问题。通过接入医学知识库和专家系统,智能体可以提供准确的医学建议、疾
病解答和健康咨询服务,帮助用户快速获取相关医疗信息,提升用户的就医体验。</p>
<div class="chat-box" id="chatBox">
</div>
<div class="input-area">
<textarea id="userInput" rows="3" placeholder="请输入消息..."></textarea>
<button onclick="sendMessage()">发送</button>
</div>
</div>
</div>
<!-- 版权信息 -->
<div class="footer">
<p>百战程序员 版权所有</p>
</div>
<script>
// 切换标签
function switchTab(index) {
const tabs = document.querySelectorAll('.sidebar .tab');
const contents = document.querySelectorAll('.tab-content');
// 重置所有标签和内容
tabs.forEach(tab => tab.classList.remove('active-tab'));
contents.forEach(content => content.classList.remove('active-content'));
// 激活选中的标签和内容
tabs[index].classList.add('active-tab');
contents[index].classList.add('active-content');
}
// 文件上传模拟
function uploadFile() {
const formData = new FormData();
const fileInput = document.getElementById('fileInput');
const file = fileInput.files[0];
if (file) {
formData.append('file', file);
fetch('/upload', {
method: 'POST',
body: formData
})
.then(response => response.json())
.then(data => alert('文件上传成功'))
.catch(error => alert('文件上传失败'));
} else {
alert('请选择一个文件上传');
}
}
function displayMessage(message, isUser = true,id) {
const chatBox = document.getElementById('chatBox');
const messageElement = document.createElement('div');
messageElement.classList.add('message');
// 用户消息
if (isUser) {
messageElement.classList.add('user-message');
messageElement.textContent = message;
chatBox.appendChild(messageElement);
} else {
// GPT 消息
messageElement.classList.add('gpt-message', `gpt-message-${id}`);
messageElement.textContent = message;
// 查找并替换最新的 GPT 消息
const existingMessages = chatBox.getElementsByClassName('gpt-message-'+id);
if (existingMessages.length > 0) {
// 如果有旧的 GPT 消息,则移除旧的并替换
chatBox.removeChild(existingMessages[0]);
}
chatBox.appendChild(messageElement);
}
// 滚动到最新消息
chatBox.scrollTop = chatBox.scrollHeight;
}
// 发送消息函数
function sendMessage() {
const userInput = document.getElementById('userInput');
const message = userInput.value.trim();
const id = Math.floor(10000 + Math.random() * 90000)
if (message) {
displayMessage(message, true,id); // 显示用户消息
userInput.value = ''; // 清空输入框
// 向后端发送GET请求,传递消息作为查询参数
fetch(`/chat?message=${encodeURIComponent(message)}`, {
method: 'GET',
}).then(response => {
// 确保响应成功且返回流
if (response.ok && response.body) {
const reader = response.body.getReader();
const decoder = new TextDecoder();
let messageBuffer = '';
// 读取流的每一块
function readStream() {
reader.read().then(({value, done}) => {
if (done) {
// 流结束时,将整个消息显示
displayMessage(messageBuffer, false,id);
} else {
// 拼接接收到的流数据
messageBuffer += decoder.decode(value, {stream: true});
// 实时更新显示
displayMessage(messageBuffer, false,id);
// 继续读取下一个数据块
readStream();
}
});
}
// 开始读取流
readStream();
}
})
.catch(error => {
console.error('发送消息失败:', error);
displayMessage('发送消息失败,请稍后再试。', false);
});
}
}
// 获取知识体列表信息
function loadFilelist() {
// 向后端发送get请求,获取文件列表
fetch('/getList')
.then(response => response.json()) // 解析返回的json数据
.then(data => {
// fileListBody 获取表格tbody部分
const filelistBody = document.getElementById('fileListBody')
// 使用map生成HTML表格行,并通过join拼接成一个完整的字符串
filelistBody.innerHTML = data.map(file =>
`
<td>${file.fileName}</td>
<td>${file.fileSize}</td>
<td>${file.charCount}</td>
<td>${file.segments}</td>
<td>${file.status}</td>
<td>删除</td>
`).join('')// 合并所有行放到表格中
})
.catch(error => console.log("获取文件列表出错了。。。"))
}
// 页面加载就调用
window.onload = loadFilelist()
</script>
</body>
</html>编写知识库CSS
在resource下创建static文件夹,css - > index.css
css
/* 页面整体样式 */
body {
font-family: Arial, sans-serif;
margin: 0;
padding: 0;
display: flex;
flex-direction: column;
min-height: 100vh;
background-color: #f4f4f9;
}
/* 头部用户信息栏样式 */
.header {
display: flex;
justify-content: flex-end;
align-items: center;
padding: 15px;
background-color: #333;
color: white;
position: relative;
}
.user-info {
display: flex;
align-items: center;
margin-left: 20px;
}
.user-info img {
width: 40px;
height: 40px;
border-radius: 50%;
margin-right: 10px;
}
.user-info span {
font-size: 16px;
}
/* 侧边栏样式 */
.sidebar {
width: 250px;
background-color: #333;
color: white;
padding-top: 20px;
position: fixed;
height: 100%;
left: 0;
top: 0;
border-radius: 10px 0 0 10px;
box-shadow: 2px 0 10px rgba(0, 0, 0, 0.1);
}
.sidebar .tab {
padding: 15px;
cursor: pointer;
text-align: center;
background-color: #444;
margin: 10px;
border-radius: 8px;
transition: background-color 0.3s;
}
.sidebar .tab:hover {
background-color: #555;
}
.sidebar .active-tab {
background-color: #4CAF50;
font-weight: bold;
}
/* 主容器 */
.main-content {
margin-left: 270px;
padding: 20px;
width: 100%;
max-width: 1000px;
flex-grow: 1;
}
/* 标签内容区样式 */
.tab-content {
display: none;
padding: 20px;
background-color: #fff;
border-radius: 10px;
box-shadow: 0 0 15px rgba(0, 0, 0, 0.1);
}
.active-content {
display: block;
}
/* 文件上传页面样式 */
.upload-container {
text-align: center;
}
/* ChatGPT 对话页面样式 */
.chat-box {
margin-top: 20px;
max-height: 400px;
overflow-y: auto;
border: 1px solid #ddd;
padding: 10px;
border-radius: 8px;
background-color: #f9f9f9;
}
.message {
padding: 8px 12px;
margin: 5px 0;
border-radius: 8px;
max-width: 80%;
}
.user-message {
background-color: #d1f7c4;
margin-left: auto;
text-align: right;
}
.gpt-message {
background-color: #e9ecef;
margin-right: auto;
text-align: left;
}
.input-area {
display: flex;
margin-top: 20px;
align-items: center;
}
.input-area textarea {
width: 100%;
padding: 10px;
border: 1px solid #ddd;
border-radius: 8px;
font-size: 16px;
resize: none;
}
.input-area button {
background-color: #4CAF50;
color: white;
padding: 12px;
border: none;
border-radius: 8px;
cursor: pointer;
margin-left: 10px;
}
.input-area button:hover {
background-color: #45a049;
}
/* 版权信息样式 */
.footer {
background-color: #333;
color: white;
text-align: center;
padding: 10px;
margin-top: 20px;
}
.file-list {
margin-top: 30px;
}
.file-list table {
width: 100%;
border-collapse: collapse;
margin-top: 20px;
}
.file-list th, .file-list td {
border: 1px solid #ddd;
padding: 8px;
text-align: left;
}
.file-list th {
background-color: #f2f2f2;
}
.file-list td button {
background-color: #f44336;
color: white;
border: none;
padding: 5px 10px;
cursor: pointer;
}
.file-list td button:hover {
background-color: #e53935;
}RAG医疗问答系统_知识库文件上传
创建统一结果返回集
java
package com.haoo.common;
public class ResponseResult<T> {
private int code; // 状态码
private String message; // 消息
private T data; // 返回数据
// 构造函数
public ResponseResult(int code, String message, T data) {
this.code = code;
this.message = message;
this.data = data;
}
// 默认成功响应
public static <T> ResponseResult<T> success(T data) {
return new ResponseResult<>(200, "操作成功", data);
}
// 默认失败响应
public static <T> ResponseResult<T> fail(String message) {
return new ResponseResult<>(500, message, null);
}
// 其他自定义返回状态码和消息
public static <T> ResponseResult<T> of(int code, String message, T data) {
return new ResponseResult<>(code, message, data);
}
// Getter 和 Setter
public int getCode() {
return code;
}
public void setCode(int code) {
this.code = code;
}
public String getMessage() {
return message;
}
public void setMessage(String message) {
this.message = message;
}
public T getData() {
return data;
}
public void setData(T data) {
this.data = data;
}
}创建枚举
java
package com.haoo.domain;
import lombok.Getter;
import lombok.Setter;
@Getter
public enum FileStatus {
PEENDING("待处理"),
PROCESSING("处理中"),
COMPLETED("已完成"),
FAILED("失败");
private String status;
FileStatus(String status) {
this.status = status;
}
}文件上传接口实现
java
package com.haoo.controller;
import com.haoo.common.ResponseResult;
import com.haoo.domain.FileInfo;
import com.haoo.domain.FileStatus;
import com.haoo.service.FileInfoService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RestController;
import org.springframework.web.multipart.MultipartFile;
import java.io.File;
import java.io.IOException;
@RestController
public class FileController {
/**
* 从配置文件中取到filePath
*/
@Value("${file.path}")
private String filePath;
@Autowired
private FileInfoService fileInfoService;
/**
* 文件上传接口
* @param file
* @return
*/
@PostMapping("/upload")
public ResponseResult<Boolean> upload(MultipartFile file) throws IOException {
// 获取文件信息
String fileName = file.getOriginalFilename();
long fileSize = file.getSize();
int charCount = getCharCount(file);
int segments = calculateSegments(fileSize);
// 创建 FileInfo 实体并保存到数据库
FileInfo fileInfo = new FileInfo();
fileInfo.setFileName(fileName);
fileInfo.setFileSize(fileSize);
fileInfo.setCharCount(charCount);
fileInfo.setSegments(segments);
fileInfo.setStatus(FileStatus.PROCESSING.getStatus());
// 设置保存文件的路径
File dest = new File(filePath + fileName);
// 确保目标文件目录存在
dest.getParentFile().mkdirs();
// 将文件保存到目标目录
file.transferTo(dest);
fileInfo.setFilePath(filePath + fileName);
// 保存文件信息到数据库
boolean save = fileInfoService.save(fileInfo);
if (save){
return ResponseResult.success(true);
}else {
return ResponseResult.fail("系统异常");
}
}
/**
* 获取文件字符数
* @param file
* @return
* @throws IOException
*/
private int getCharCount(MultipartFile file) throws IOException {
return new String(file.getBytes()).length();
}
/**
* 计算分片数量
* @param fileSize
* @return
*/
private int calculateSegments(long fileSize) {
final long segmentSize = 5 * 1024 * 1024; // 5 MB
return (int) Math.ceil((double) fileSize / segmentSize);
}
}RAG医疗问答系统_知识库列表实现
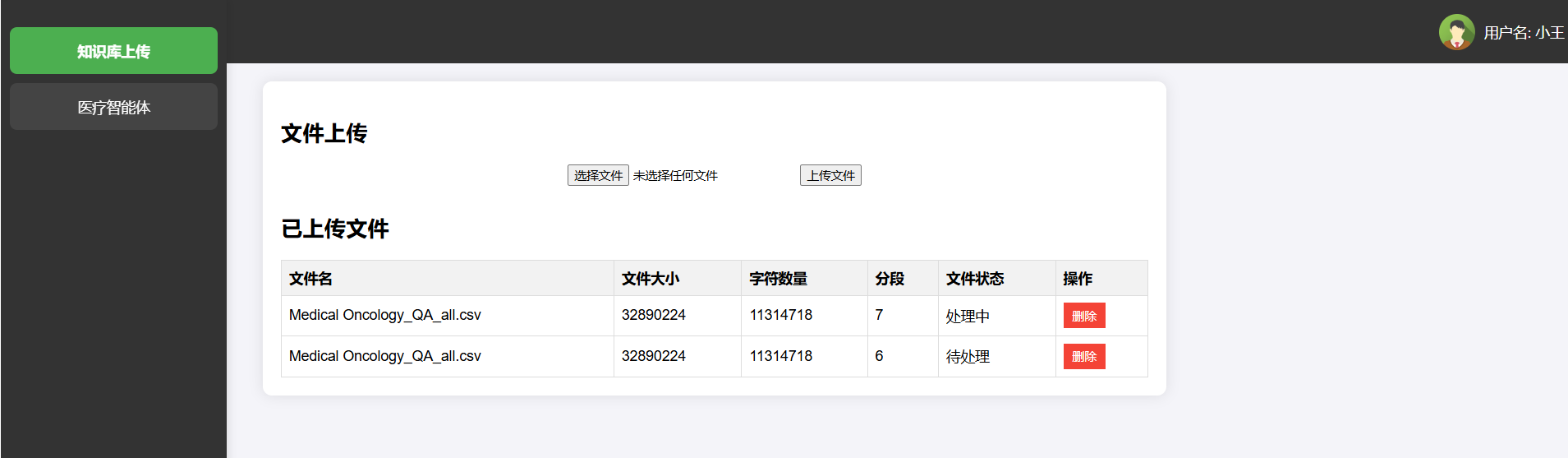
获取文件列表
java
/**
* 获取文件列表
* @return
*/
@GetMapping("/getList")
public List<FileInfo> select() {
return fileInfoService.list();
}前端显示知识库列表
RAG医疗问答系统_定时任务在知识库中的应用
基于注解@Scheduled默认为单线程,开启多个任务时,任务的执行时机会受上一个任务执行时间的影响
创建定时器
使用SpringBoot基于注解Scheduled来创建定时任务。
java
package com.haoo.scheduling;
import cn.hutool.core.io.FileUtil;
import com.haoo.domain.FileInfo;
import com.haoo.domain.FileStatus;
import com.haoo.service.FileInfoService;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import kotlin.time.TestTimeSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import java.io.File;
import java.util.List;
@Component
public class MedicalFileScheduling {
@Autowired
private FileInfoService fileInfoService;
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore<TextSegment> textSegmentEmbeddingStore;
@Scheduled(fixedRate = 5000)
public void data(){
System.out.println("轮询任务执行中...");
//查询所有知识体
List<FileInfo> list = fileInfoService.list();
if(!list.isEmpty()){
for(FileInfo fileInfo : list){
if(fileInfo.getStatus().equals(FileStatus.PEENDING.getStatus())){
//更新
fileInfo.setStatus(FileStatus.PROCESSING.getStatus());
fileInfoService.updateById(fileInfo);
//处理数据 数据通过向量模型 -》向量 -》向量数据库
File file = new File(fileInfo.getFilePath());
//获取文件数据
List<String> medicalMessage = FileUtil.readLines(file, "utf-8");
for(String s : medicalMessage){
TextSegment from = TextSegment.from(s);//文本片段
Embedding content = embeddingModel.embed(from).content();//向量化
textSegmentEmbeddingStore.add(content);//存储到向量数据库
}
//更新状态
fileInfo.setStatus(FileStatus.COMPLETED.getStatus());
fileInfoService.updateById(fileInfo);
}
}
}
}
}RAG医疗问答系统_知识库性能优化之异步处理提升文件读取与嵌入计算性能
什么是异步处理
异步处理是一种执行任务的方式,在执行某些耗时操作时,任务不会阻塞当前线程,而是通过创建新的线程或者使用线程池,执行耗时操作后再通知主线程或回调结果。
- 同步: 主线程等待耗时操作完成后再继续执行。
- 异步: 主线程在等待耗时操作时,不会被阻塞,可以继续执行其他任务。
为什么需要异步处理文件读取和嵌入计算
在当前代码中,每个文件的读取和嵌入计算是同步执行的。
- 每次读取一个文件内容都要等待,直到文件读取完毕才能进行下一步处理。
- 嵌入计算也是逐行处理的,这会让计算过程变得非常耗时,尤其是文件较大时。
如何实现异步处理
启用异步支持
首先,在 Spring Boot 应用程序中启用异步支持。在配置类上添加 **@EnableAsync**注解。
@Configuration
@EnableAsync // 启用异步支持
public class AsyncConfig {
// 这里可以进一步配置异步任务执行的线程池
}
线程池配置
默认情况下,@Async 使用 Spring 的默认线程池。如果你需要更精细的控制,可以自定义线程池,例如设置线程池大小、队列容量等。
java
@Configuration
@EnableAsync // 启用异步支持
public class AsyncConfig {
@Bean
public Executor asyncExecutor() {
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(10); // 核心线程数
executor.setMaxPoolSize(20); // 最大线程数
executor.setQueueCapacity(50); // 队列容量
executor.setThreadNamePrefix("Async-"); // 线程名称前缀
executor.initialize();
return executor;
}
}在主轮询任务中调用异步方法:
java
@Scheduled(fixedRate = 5000)
public void data(){
System.out.println("轮询任务执行中...");
//查询所有知识体
List<FileInfo> list = fileInfoService.list();
if(!list.isEmpty()){
for(FileInfo fileInfo : list){
if(fileInfo.getStatus().equals(FileStatus.PEENDING.getStatus())){
//更新
fileInfo.setStatus(FileStatus.PROCESSING.getStatus());
fileInfoService.updateById(fileInfo);
//处理数据 数据通过向量模型 -》向量 -》向量数据库
File file = new File(fileInfo.getFilePath());
//获取文件数据
processFileData(file);
//更新状态
fileInfo.setStatus(FileStatus.COMPLETED.getStatus());
fileInfoService.updateById(fileInfo);
}
}
}
}监控和回调
如果你希望在异步任务完成后执行一些后续操作(比如更新文件处理状态),可以使用 CompletableFuture 的回调功能。你可以在任务完成时,通过 thenAccept 或 thenRun 方法来执行后续操作。
java
@Async
public CompletableFuture<Void> processFileData(File file){
List<String> medicalMessage = FileUtil.readLines(file, "utf-8");
medicalMessage.parallelStream().forEach(data -> {
TextSegment from = TextSegment.from(data);//文本片段
Embedding content = embeddingModel.embed(from).content();//向量化
textSegmentEmbeddingStore.add(content);//存储到向量数据库
});
return CompletableFuture.completedFuture(null).thenRun(() -> {
updateFileStatus(file);
});
}
private void updateFileStatus(File file) {
System.out.println("文件: " + file.getName() + "文件处理完成");
}RAG医疗问答系统_知识库性能优化之提升文件读取性能

使用缓冲流(Buffered Streams)
在 Java 中,读取文件时,使用缓冲流(BufferedReader 或 BufferedInputStream)可以显著提高性能。默认的 FileReader 或 FileInputStream 是非缓冲的,每次读取一个字符或字节时都会与磁盘进行一次交互,而缓冲流则通过内部缓存机制减少与磁盘的交互次数。
使用 BufferedReader 读取文本文件
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public void readFileWithBuffer(String filePath) throws IOException {
BufferedReader reader = new BufferedReader(new FileReader(filePath));
String line;
while ((line = reader.readLine()) != null) {
// 处理每一行数据
}
reader.close();
}
缓冲流优化的原理:
- 缓存读取 :
BufferedReader会预先将一定数量的数据加载到内存中,这样就能避免每次读取时都与磁盘进行交互。- 提高读取效率:通常情况下,内存读取的速度远高于直接从磁盘读取,因此可以显著提高性能。
逐块读取文件(Batch Reading)
如果文件非常大,一次性读取整个文件可能会导致内存溢出或者降低处理速度。逐块读取文件的方式可以在读取大文件时提高效率。你可以通过设置一个合适的块大小来逐步读取文件的一部分。
逐块读取的优势:
- 减少内存消耗:通过分块读取,可以避免一次性读取大文件时占用过多内存。
- 提高处理效率:逐块处理每个数据块后,可以实时处理数据,避免文件读取操作和数据处理操作的阻塞。
java
package com.haoo.scheduling;
import cn.hutool.core.io.FileUtil;
import com.haoo.domain.FileInfo;
import com.haoo.domain.FileStatus;
import com.haoo.service.FileInfoService;
import dev.langchain4j.data.embedding.Embedding;
import dev.langchain4j.data.segment.TextSegment;
import dev.langchain4j.model.embedding.EmbeddingModel;
import dev.langchain4j.store.embedding.EmbeddingStore;
import kotlin.time.TestTimeSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.scheduling.annotation.Async;
import org.springframework.scheduling.annotation.Scheduled;
import org.springframework.stereotype.Component;
import org.springframework.util.CollectionUtils;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.CompletableFuture;
@Component
public class MedicalFileScheduling {
@Autowired
private FileInfoService fileInfoService;
@Autowired
private EmbeddingModel embeddingModel;
@Autowired
private EmbeddingStore<TextSegment> textSegmentEmbeddingStore;
@Scheduled(fixedRate = 5000)
public void data() throws IOException {
System.out.println("轮询任务执行中...");
//查询所有知识体
List<FileInfo> list = fileInfoService.list();
if(!list.isEmpty()){
for(FileInfo fileInfo : list){
if(fileInfo.getStatus().equals(FileStatus.PEENDING.getStatus())){
//更新
fileInfo.setStatus(FileStatus.PROCESSING.getStatus());
fileInfoService.updateById(fileInfo);
//处理数据 数据通过向量模型 -》向量 -》向量数据库
//获取文件数据
//更新状态
processFileData(fileInfo);
}
}
}
}
@Async
public CompletableFuture<Void> processFileData(FileInfo file) throws IOException {
BufferedReader bufferedReader = new BufferedReader(new FileReader(file.getFilePath()));
String line = null;
List<String> chunk = new ArrayList<>();
while((line = bufferedReader.readLine()) != null){
chunk.add(line);
if(chunk.size() >= 10){
processChunk(chunk);
chunk.clear();
}
}
if(!CollectionUtils.isEmpty(chunk)){
processChunk(chunk);
}
bufferedReader.close();
return CompletableFuture.completedFuture(null).thenRun(() -> {
updateFileStatus(file);
});
}
private void processChunk(List<String> chunk){
// parallelStream 方法会异步执行。 文件内容的读取和每行数据的嵌入计算都会在后台线程中执行
// 而且每行数据都会由不同的线程进行处理。能够加速计算过程
chunk.parallelStream().forEach(data -> {
TextSegment from = TextSegment.from(data);
// 文本转换为向量
Embedding content = embeddingModel.embed(from).content();
// 保存到向量数据库
textSegmentEmbeddingStore.add(content, from);
});
}
private void updateFileStatus(FileInfo file) {
file.setStatus(FileStatus.COMPLETED.getStatus());
fileInfoService.updateById(file);
}
}RAG医疗问答系统_构建检索增强器
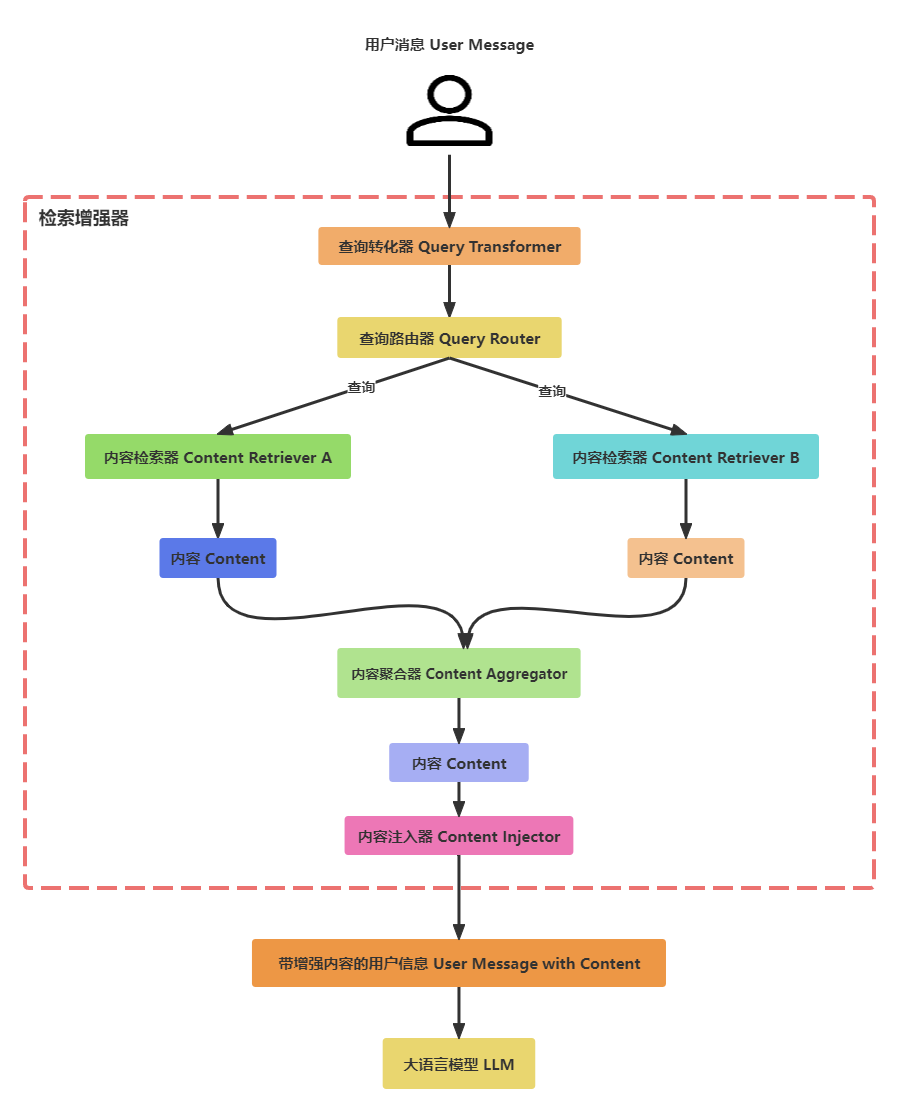
什么是检索增强器
RetrievalAugmentor 是 RAG 管道的入口点。它负责使用从各种来源检索的相关 Content 来扩充 ChatMessage 。
默认检索增强器
LangChain4j 提供了开箱即用的 RetrievalAugmentor 实现:DefaultRetrievalAugmentor。它适用于大多数的 RAG 场景。
内容检索器(Content Retriever)
ContentRetriever根据用户的查询从底层数据源中获取内容,数据源可以是:
- 嵌入向量存储
- 全文搜索引擎
- 向量与全文检索结合
- 网络搜索引擎
- SQL数据库
- 知识图谱等
引入依赖
<dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-reactor</artifactId> <version>0.35.0</version> </dependency>
提供模型元信息
java
/**
* 提供模型元信息
*
* @return
*/
@Bean
public StreamingChatLanguageModel streamingChatLanguageModel() {
return OpenAiStreamingChatModel.builder()
.apiKey("")
.modelName("qwen-max")
.logRequests(true)
.logResponses(true)
.baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1")
.build();
}编写Assistant
java
public interface Assistant {
/**
* 聊天
* @param message 信息
* @return
*/
Flux<String> chat(String message);
}配置检索增强器
java
@Bean
public Assistant assistant() {
ContentRetriever contentRetriever1 = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore())
.embeddingModel(embeddingModel())
.maxResults(3) // 返回最多3条结果
.dynamicMaxResults(query -> 3) // 根据查询动态指定maxResults
.minScore(0.75) // 过滤分数低于0.75的内容
.dynamicMinScore(query -> 0.75) // 根据查询动态指定minScore
.build();
// 创建检索增强器
RetrievalAugmentor retrievalAugmentor = DefaultRetrievalAugmentor.builder()
.contentRetriever(contentRetriever1)
.build();
// 构建AI服务
Assistant assistant = AiServices.builder(Assistant.class)
.streamingChatLanguageModel(streamingChatLanguageModel())
.retrievalAugmentor(retrievalAugmentor)
.build();
return assistant;
}编写对话controller
java
@RestController
public class ChatController {
@Autowired
Assistant assistant;
@GetMapping("/chat")
public Flux<String> chat2(String message){
return assistant.chat(message);
}
}RAG医疗问答系统_网络搜索内容检索器Tavily

Tavily是什么
Tavily是一个为大型语言模型(LLMs)和检索增强生成(RAG)优化的搜索引擎,旨在提供高效、快速且持久的搜索结果。
Tavily的主要功能和特点
- 深度研究:通过单一的API调用,简化数据收集,提供来自可信来源的聚合和精选结果。
- 智能查询建议和答案:装备AI以自动化的方式深化知识,通过细微的答案和后续查询。
- 多源优化:与Bing、Google和SerpAPI等其他API相比,Tavily Search API会审查多个来源,从每个来源中找到最相关的内容,以优化LLM上下文。
- 灵活性和成本效益:Tavily Search API提供更灵活的定价计划和更实惠的成本。
引入依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-web-search-engine-tavily</artifactId>
</dependency>
获取APi-key
从互联网检索相关内容
java
WebSearchEngine webSearchEngine = TavilyWebSearchEngine.builder()
.apiKey("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") // get a free key: https://app.tavily.com/sign-in
.build();
ContentRetriever webSearchContentRetriever = WebSearchContentRetriever.builder()
.webSearchEngine(webSearchEngine)
.maxResults(3)
.build();RAG医疗问答系统_Scoring (re-ranking) Models重排序

Rerank(重排序)
重排序,顾名思义,就是将检索召回的结果,按照一定的规则或逻辑重新排序,从而将相关性或准确度更高的结果排在前面,提升检索质量。
示例:
假设你在网上搜索头痛的治疗方法,你可能会得到很多相关的搜索结果。但是这些结果的顺序可能并不完全符合你的需求。结果重排技术的作用就是根据你真正的需求对这些结果进行调整,确保最相关的内容排在最前面。
重排序主要有两种类型
- 统计打分的重排序
- 基于深度学习的重排序
理解RRF(统计打分的重排序)
假设你和三个朋友在寻找一本丢失的书,每个人列出了最有可能找到书的地点,并按从高到低的顺序进行排序。RRF 就是结合这些排序结果,帮助找到最有可能的地点。

排序结果
最终,我们依据各个地点的融合分数进行排序:
- 书架: 2
- 桌子: 1.83
- 床下: 1.66
因此,书架是最有可能藏书的地方。
Maven 依赖
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-jina</artifactId>
<version>0.36.2</version>
</dependency>