Kubernetes 简介及部署方法
应用部署方式演变
在部署应用程序的方式上,主要经历了三个阶段
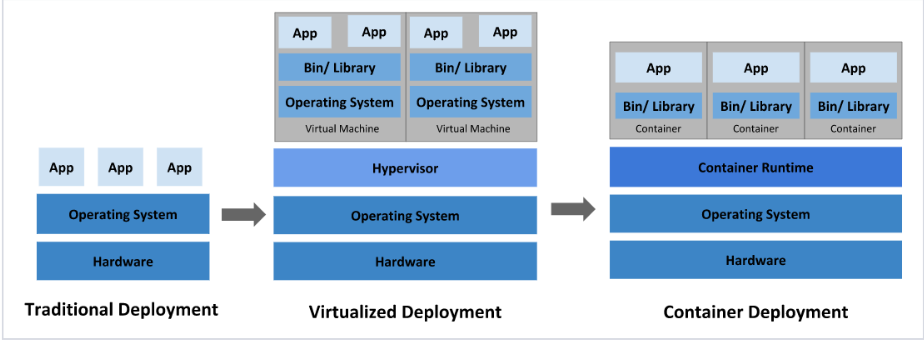
传统部署:互联网早期,会直接将应用程序部署在物理机上
-
优点:简单,不需要其它技术的参与
-
缺点:不能为应用程序定义资源使用边界,很难合理地分配计算资源,而且程序之间容易产生影响
虚拟化部署:可以在一台物理机上运行多个虚拟机,每个虚拟机都是独立的一个环境
-
优点:程序环境不会相互产生影响,提供了一定程度的安全性
-
缺点:增加了操作系统,浪费了部分资源
容器化部署:与虚拟化类似,但是共享了操作系统
!NOTE
容器化部署方式给带来很多的便利,但是也会出现一些问题,比如说:
一个容器故障停机了,怎么样让另外一个容器立刻启动去替补停机的容器
当并发访问量变大的时候,怎么样做到横向扩展容器数量
容器编排应用
为了解决这些容器编排问题,就产生了一些容器编排的软件:
-
Swarm:Docker自己的容器编排工具
-
Mesos:Apache的一个资源统一管控的工具,需要和Marathon结合使用
-
Kubernetes:Google开源的的容器编排工
kubernetes 简介

-
在Docker 作为高级容器引擎快速发展的同时,在Google内部,容器技术已经应用了很多年
-
Borg系统运行管理着成千上万的容器应用。
-
Kubernetes项目来源于Borg,可以说是集结了Borg设计思想的精华,并且吸收了Borg系统中的经验和教训。
-
Kubernetes对计算资源进行了更高层次的抽象,通过将容器进行细致的组合,将最终的应用服务交给用户
kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
-
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
-
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
-
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
-
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
-
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
-
存储编排:可以根据容器自身的需求自动创建存储卷
K8S的设计架构
K8S各个组件用途
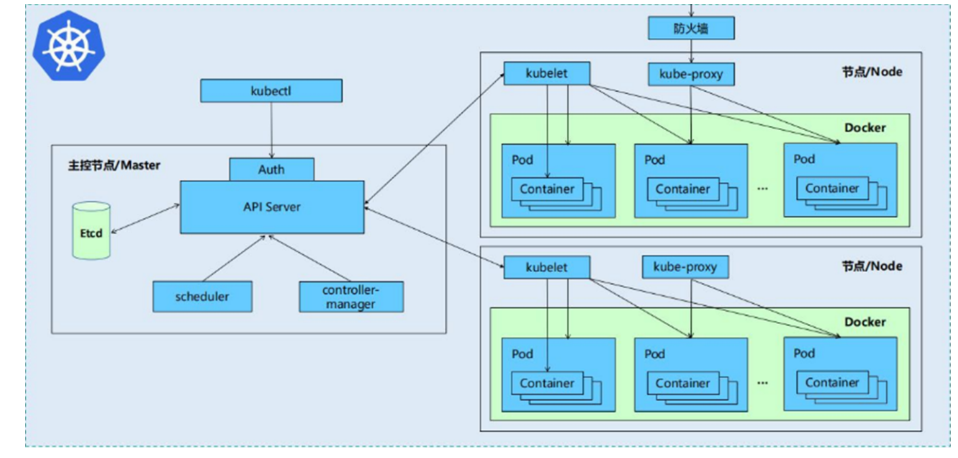
一个kubernetes集群主要是由控制节点(master) 、**工作节点(node)**构成,每个节点上都会安装不同的组件
1 master:集群的控制平面,负责集群的决策
-
ApiServer : 资源操作的唯一入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制
-
Scheduler : 负责集群资源调度,按照预定的调度策略将Pod调度到相应的node节点上
-
ControllerManager : 负责维护集群的状态,比如程序部署安排、故障检测、自动扩展、滚动更新等
-
Etcd :负责存储集群中各种资源对象的信息
2 node:集群的数据平面,负责为容器提供运行环境
-
kubelet:负责维护容器的生命周期,同时也负责Volume(CVI)和网络(CNI)的管理
-
Container runtime:负责镜像管理以及Pod和容器的真正运行(CRI)
-
kube-proxy:负责为Service提供cluster内部的服务发现和负载均衡
K8S 各组件之间的调用关系
当我们要运行一个web服务时
-
kubernetes环境启动之后,master和node都会将自身的信息存储到etcd数据库中
-
web服务的安装请求会首先被发送到master节点的apiServer组件
-
apiServer组件会调用scheduler组件来决定到底应该把这个服务安装到哪个node节点上
在此时,它会从etcd中读取各个node节点的信息,然后按照一定的算法进行选择,并将结果告知apiServer
-
apiServer调用controller-manager去调度Node节点安装web服务
-
kubelet接收到指令后,会通知docker,然后由docker来启动一个web服务的pod
-
如果需要访问web服务,就需要通过kube-proxy来对pod产生访问的代理
K8S 的 常用名词概念
-
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
-
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
-
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
-
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
-
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
-
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
-
NameSpace:命名空间,用来隔离pod的运行环境
k8S的分层架构
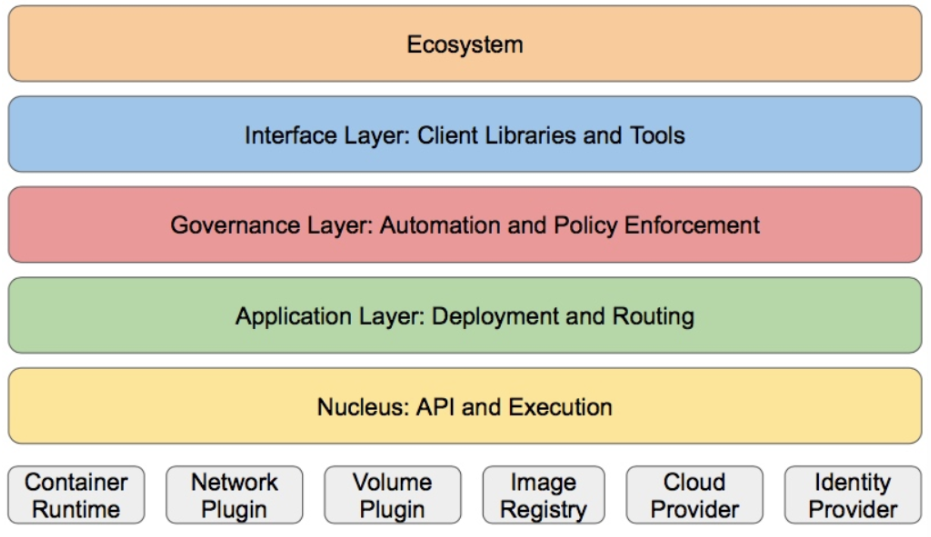
-
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
-
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
-
接口层:kubectl命令行工具、客户端SDK以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
-
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
-
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
K8S集群环境搭建
k8s中容器的管理方式
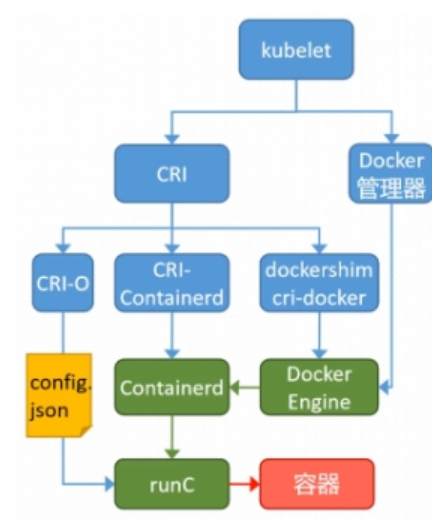
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建。
集群部署
k8s 环境部署说明
K8S中文官网:Kubernetes
|-----------------|--------------------|----------------------|
| 主机名 | ip | 角色 |
| reg.jxw.org | 172.25.254.200 | harbor仓库 |
| master | 172.25.254.100 | master,k8s集群控制节点 |
| node1 | 172.25.254.10 | worker,k8s集群工作节点 |
| node2 | 172.25.254.20 | worker,k8s集群工作节点 |
-
所有节点禁用selinux和防火墙
-
所有节点同步时间和解析
-
所有节点安装docker-ce
-
所有节点禁用swap,注意注释掉/etc/fstab文件中的定义
集群环境初始化
搭建harbor仓库
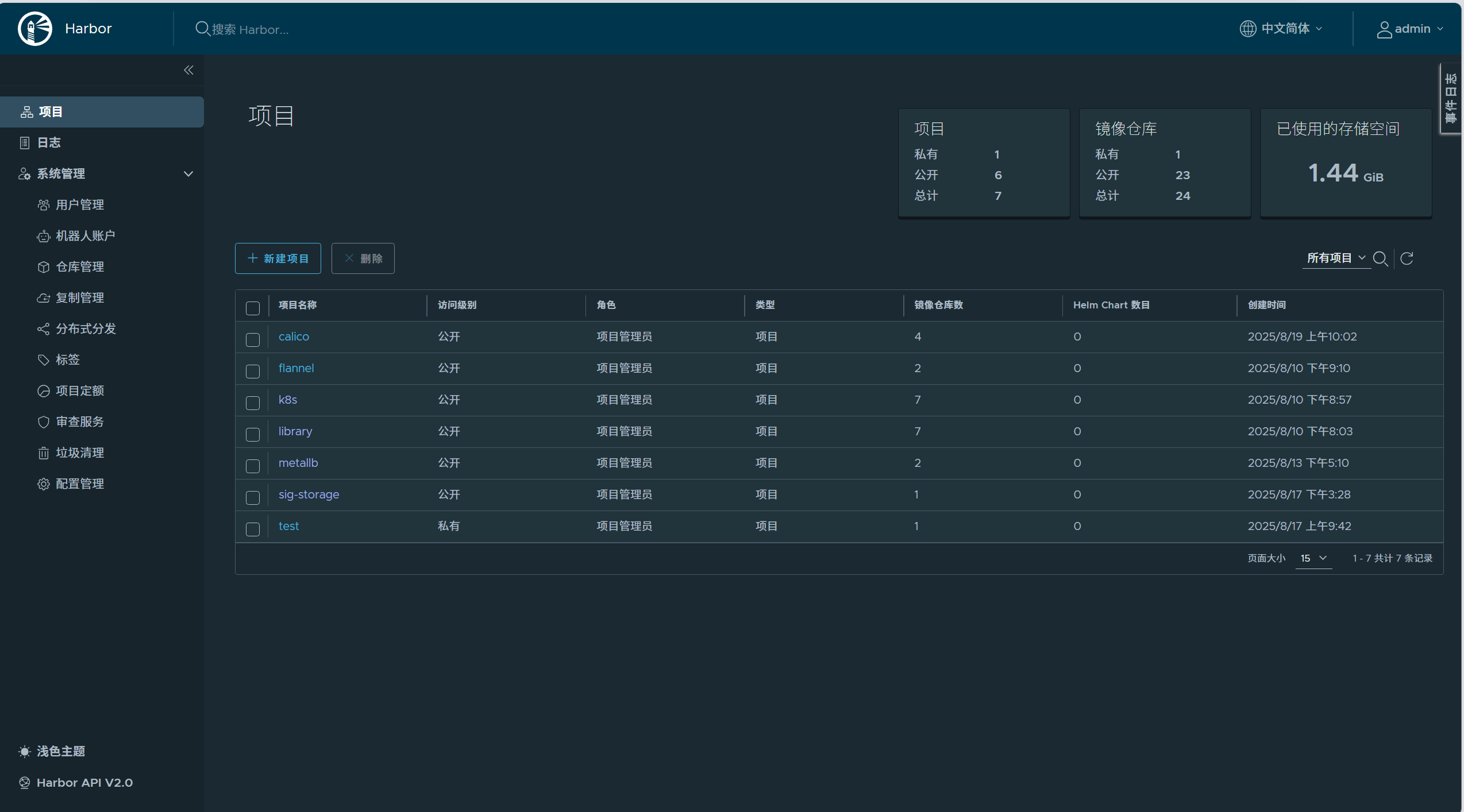
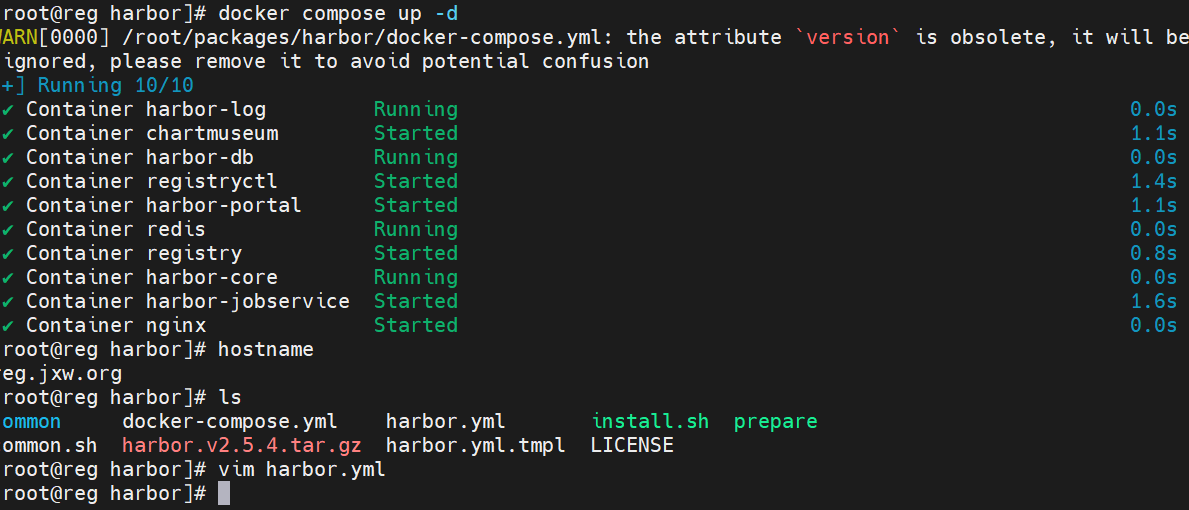
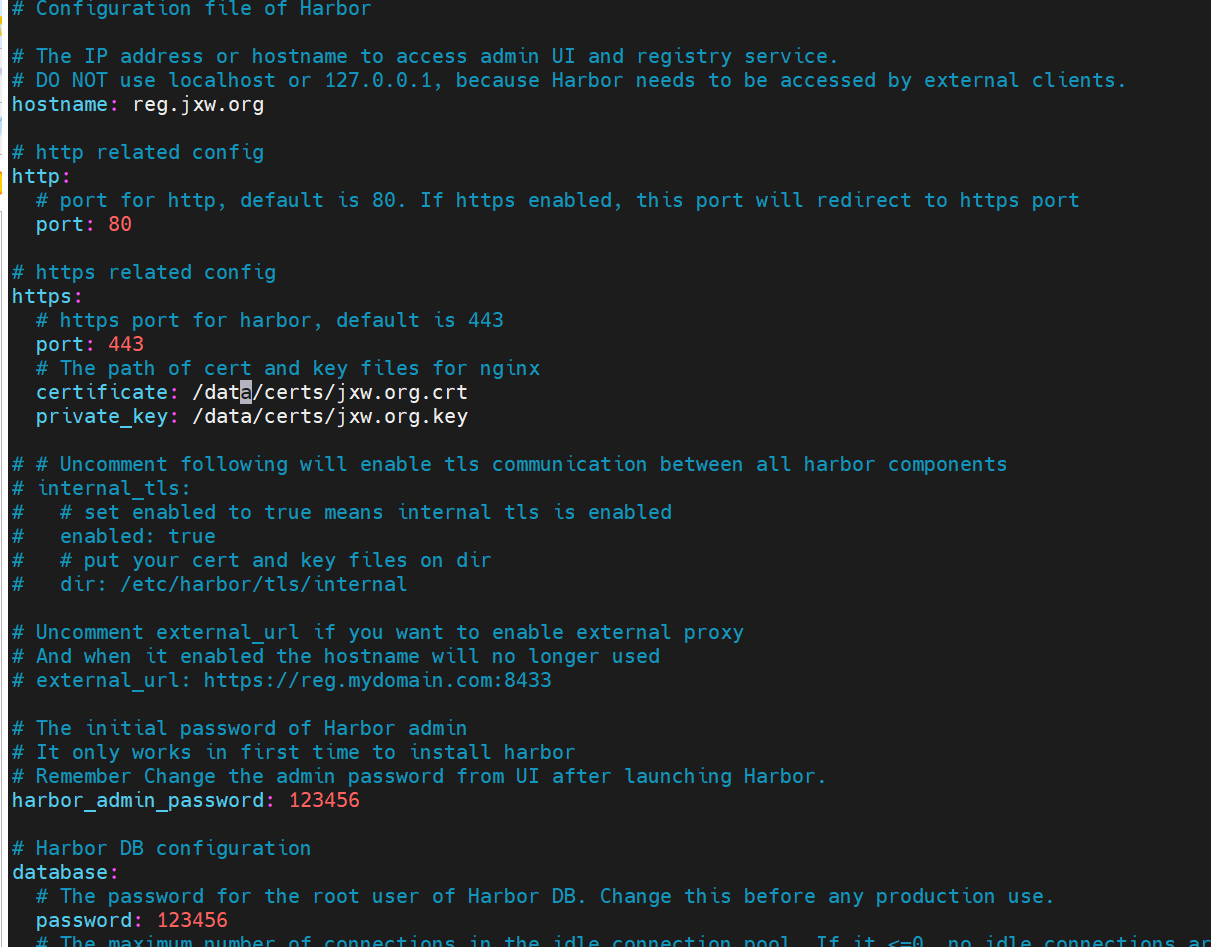
所有节点禁用swap
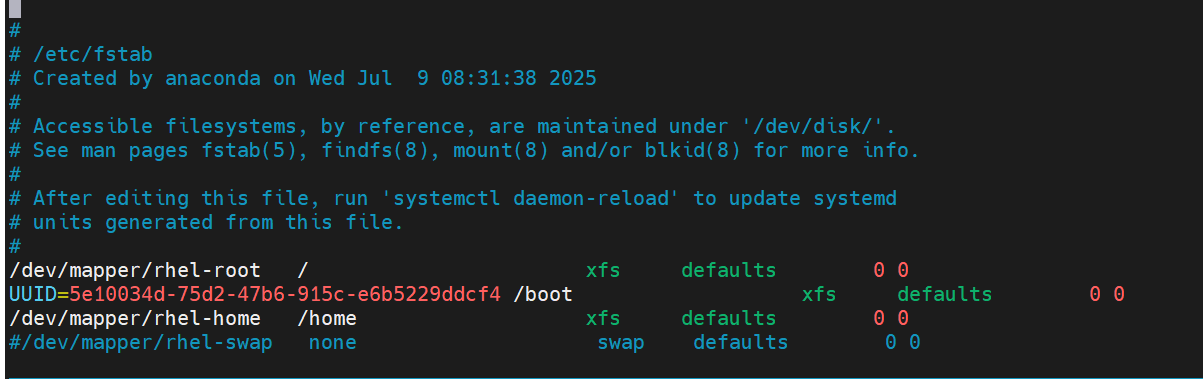
]# swapoff -a
]# vim /etc/fstab
所有节点做hosts本地解析
vim /etc/hosts

所有节点安装docker
#这里可以直接使用本地仓库安装docker-ce也可官网下载tar包
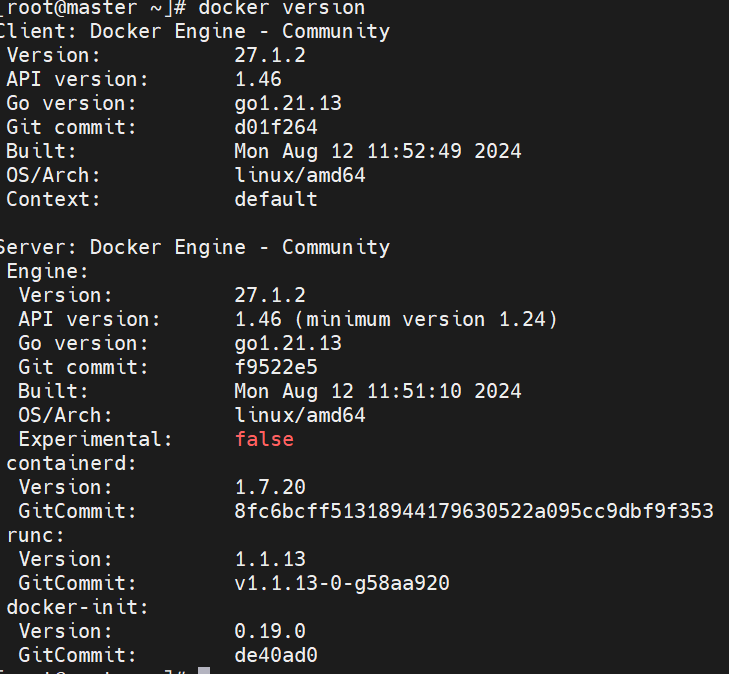
root@master \~# vim /etc/docker/daemon.json

#设置本地镜像拉取harbor仓库地址,方便之后镜像的拉取与使用

#所有节点复制harbor仓库中的证书并启动docker
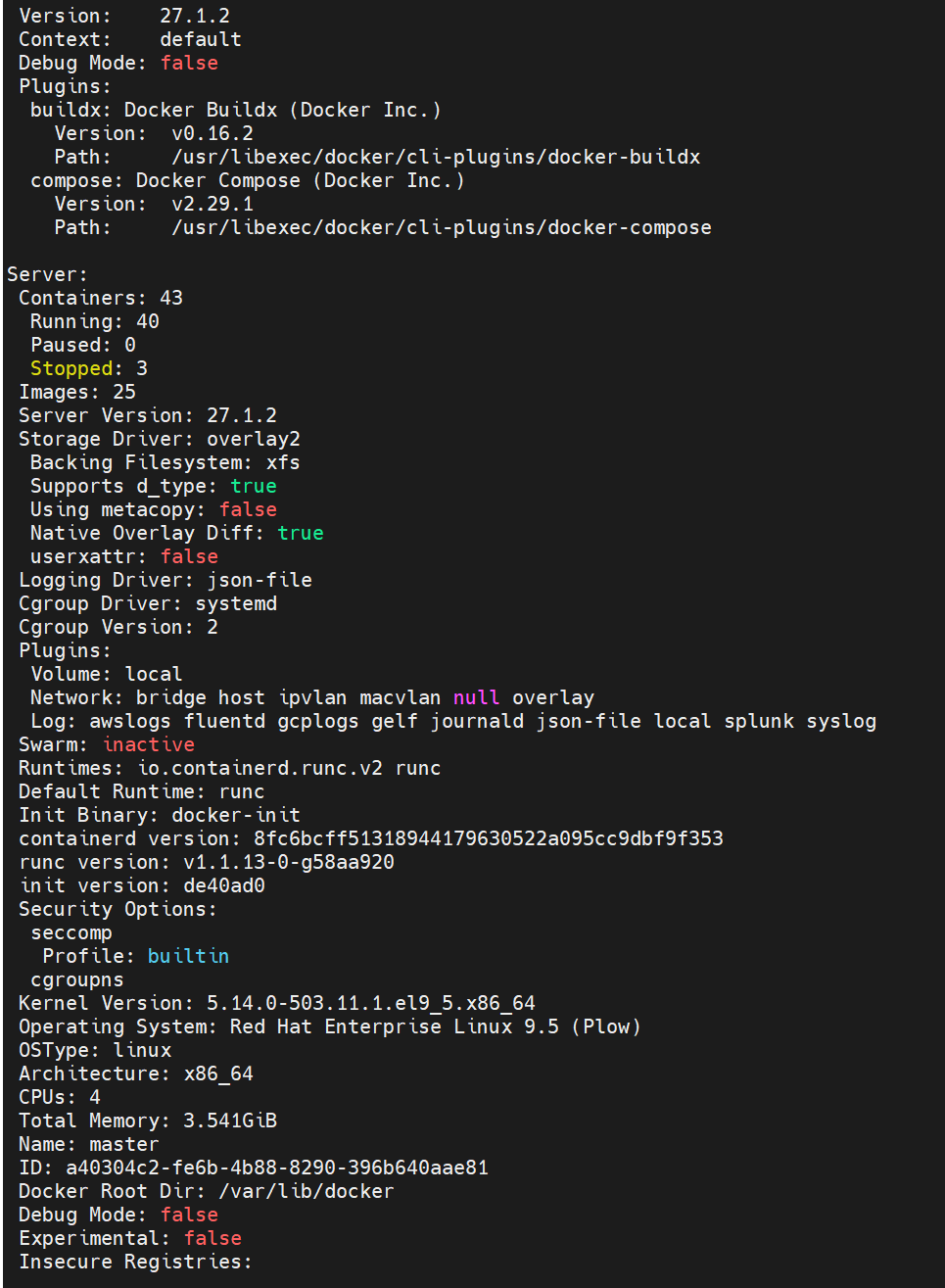
#docker info 确定docker信息
安装K8S部署工具,设置kubectl命令补齐功能
#这里个人使用软件包,也可配置软件仓库安装
#部署软件仓库,添加K8S源
root@master \~# vim /etc/yum.repos.d/k8s.repo
k8s
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0
#安装软件
root@k8s-master \~# dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -y
root@k8s-master \~# dnf install bash-completion -y
设置命令补全功能
root@master \~# echo "source <(kubectl completion bash)" >> ~/.bashrc
root@master \~# source ~/.bashrc
在所节点安装cri-docker
k8s从1.24版本开始移除了dockershim,所以需要安装cri-docker插件才能使用docker
软件下载:https://github.com/Mirantis/cri-dockerd
#dnf install libcgroup-0.41-19.el8.x86_64.rpm \
> cri-dockerd-0.3.14-3.el8.x86_64.rpm -y
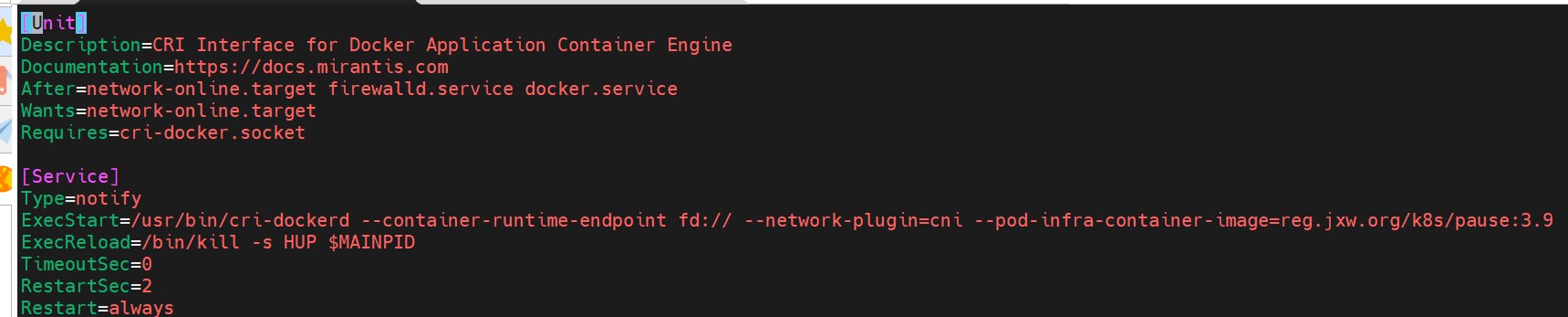
#vim /lib/systemd/system/cri-docker.service
编辑配置文件指定网络插件名称及基础容器镜像
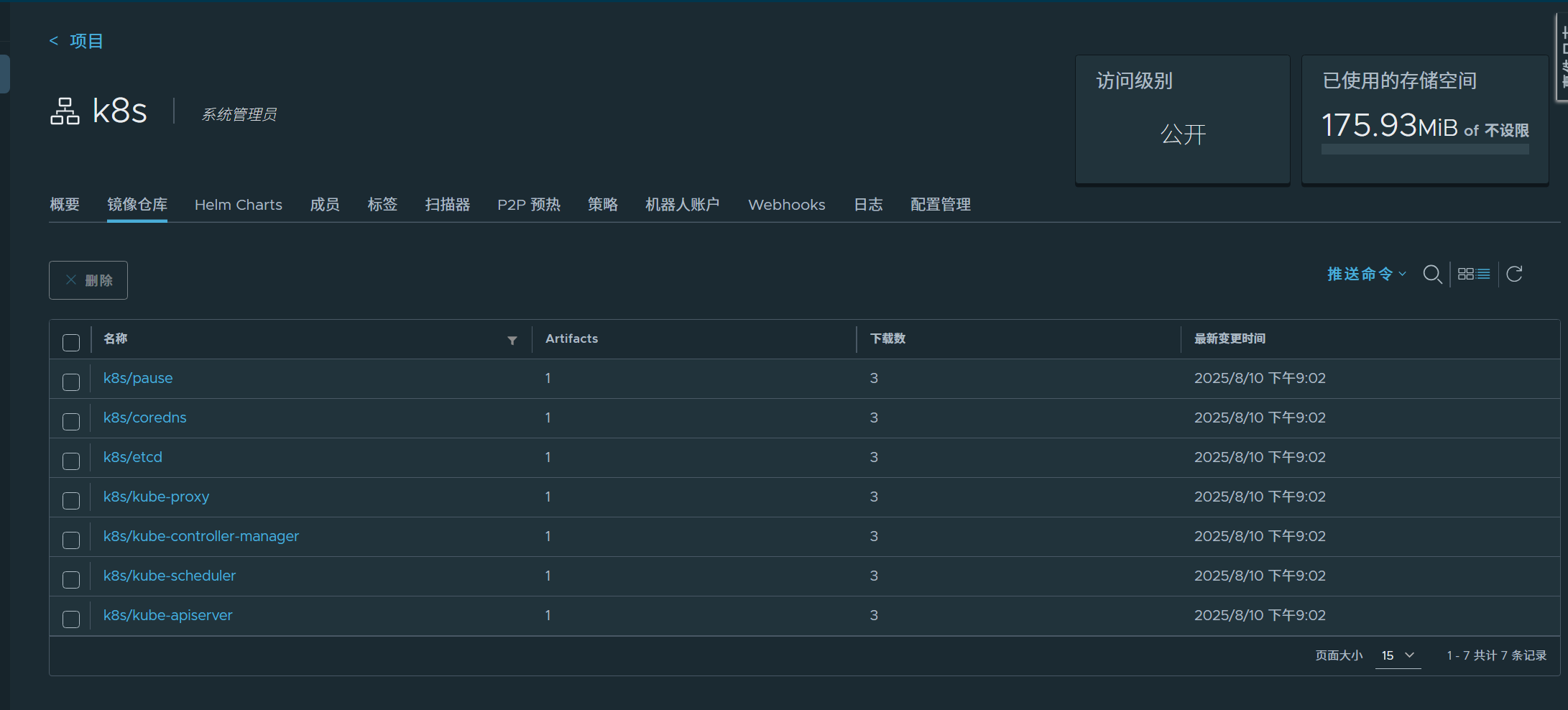
在master节点拉取K8S所需镜像
#这里我们在本地仓库建立k8s公开项目并推送(docker push)镜像到本地仓库,本地拉取不了的镜像我们可以下载(docker load -i)镜像到主机中并推送
集群初始化
#启动kubelet服务
root@master \~# systemctl status kubelet.service
#执行初始化命令
root@master \~# kubeadm init --pod-network-cidr=10.244.0.0/16 \
--image-repository reg.timinglee.org/k8s \
--kubernetes-version v1.30.0 \
--cri-socket=unix:///var/run/cri-dockerd.sock
#指定集群配置文件变量
root@master \~# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
#当前节点没有就绪,是因为还没有安装网络插件,容器没有运行
安装flannel网络插件
wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
#推送镜像到harbor仓库中
docker tag flannel/flannel:v0.25.5 reg.jxw.org/flannel/flannel:v0.25.5
docker push reg.jxw.org/flannel/flannel:v0.25.5
ocker tag flannel/flannel-cni-plugin:v1.5.1-flannel1
\reg.jxw.org/flannel/flannel-cni-plugin:v1.5.1-flannel
ocker push reg.jxw.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
#编辑kube-flannel.yml 修改镜像下载位置
root@master \~# vim kube-flannel.yml
#需要修改以下几行
root@k8s-master \~# grep -n image kube-flannel.yml
146: image: /flannel/flannel:v0.25.5
173: image: /flannel/flannel-cni-plugin:v1.5.1-flannel1
184: image: /flannel/flannel:v0.25.5
#安装flannel网络插件
root@k8s-master \~# kubectl apply -f kube-flannel.yml
节点扩容
在所有的worker节点中
1 确认部署好以下内容
2 禁用swap
3 安装:
-
kubelet-1.30.0
-
kubeadm-1.30.0
-
kubectl-1.30.0
-
docker-ce
-
cri-dockerd
4 修改cri-dockerd启动文件添加
-
--network-plugin=cni
-
--pod-infra-container-image=reg.jxw.org/k8s/pause:3.9
5 启动服务
-
kubelet.service
-
cri-docker.service
以上信息确认完毕后即可加入集群
#使用kubeadm join +集群token 命令在各node节点上使用
!NOTE
这里的token若找不到可以使用kubeadm token create --print-join-command来查看
若加入节点内容编写错误可以使用 kubeadm reset --discovery-token-ca-cert-hash来重置集群设置
查看集群状态
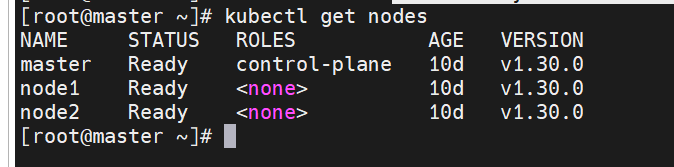
#这里如果显示all ready这里k8s集群就部署完成了
kubernetes 中的资源
资源管理介绍
-
在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes。
-
kubernetes的本质上就是一个集群系统,用户可以在集群中部署各种服务
-
所谓的部署服务,其实就是在kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
-
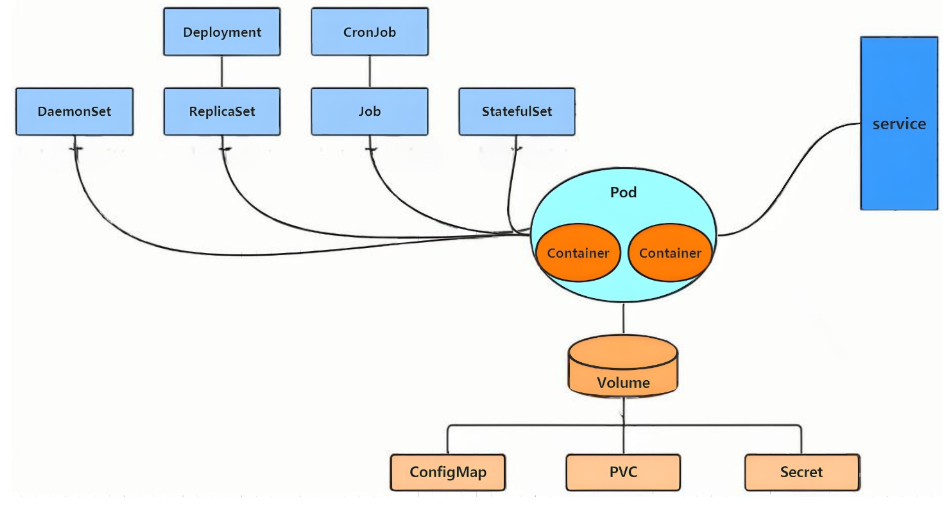
kubernetes的最小管理单元是pod而不是容器,只能将容器放在
Pod中, -
kubernetes一般也不会直接管理Pod,而是通过
Pod控制器来管理Pod的。 -
Pod中服务的访问是由kubernetes提供的
Service资源来实现。 -
Pod中程序的数据需要持久化是由kubernetes提供的各种存储系统来实现
资源管理方式
-
命令式对象管理:直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:latest --port=80 -
命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubectl create/patch -f nginx-pod.yaml -
声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml
命令式对象管理
kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl命令的语法如下:
kubectl command type name flags
comand:指定要对资源执行的操作,例如create、get、delete
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
查看所有pod
kubectl get pods
查看某个pod
kubectl get pods pod_name
查看某个pod,以yaml格式展示结果
kubectl get pod pod_name -o yaml
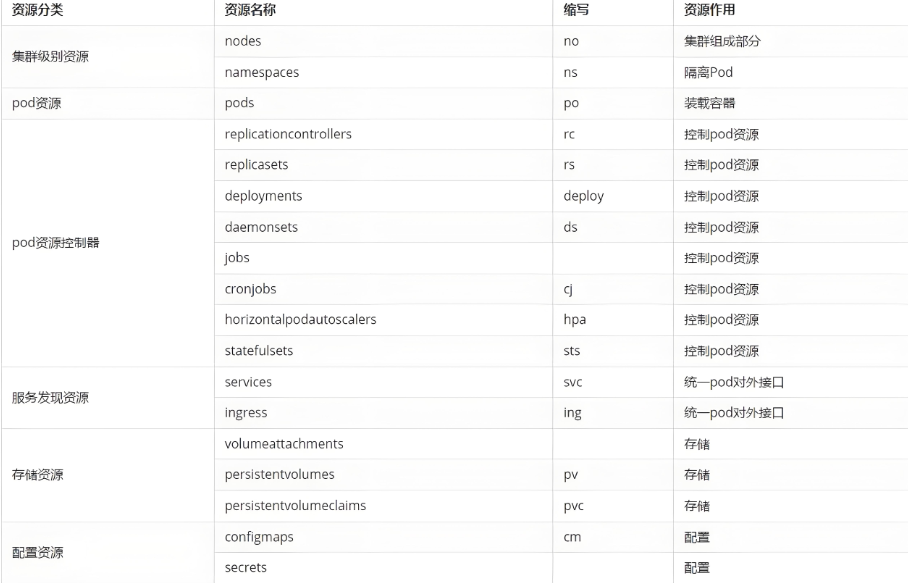
资源类型
kubernetes中所有的内容都抽象为资源
kubectl api-resources
常用资源类型
kubect 常见命令操作
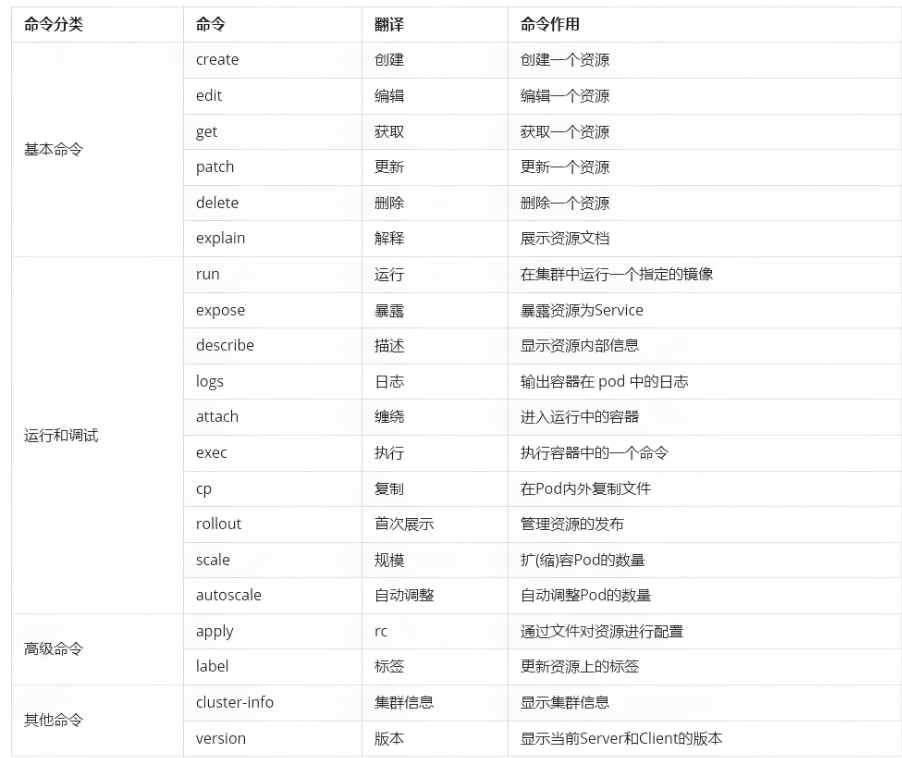
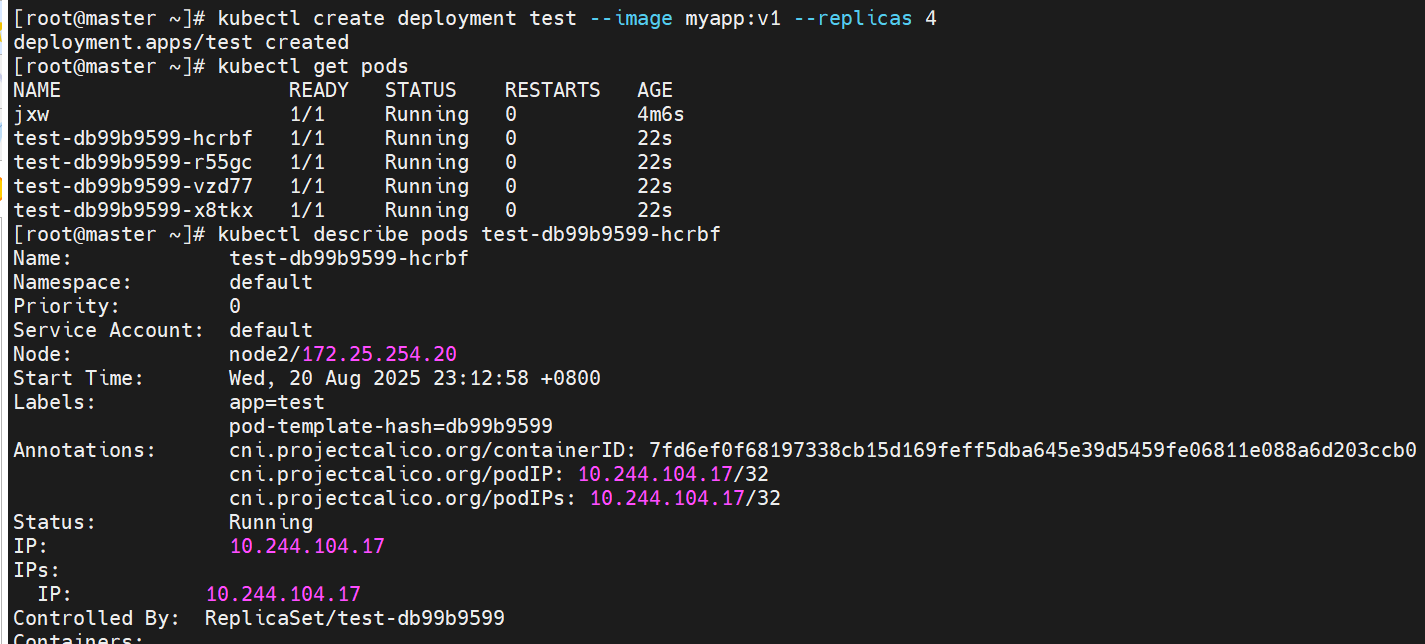
什么是pod
-
Pod是可以创建和管理Kubernetes计算的最小可部署单元
-
一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
-
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
-
多个容器间共享IPC、Network和UTC namespace。
创建自主式pod (生产不推荐)
优点:
灵活性高:
- 可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
- 对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
- 在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
- 如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
- 无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
- 手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。

利用控制器管理pod(推荐)
高可用性和可靠性:
-
自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
-
健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
-
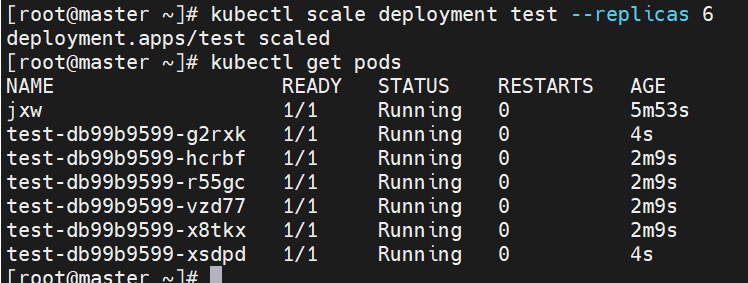
轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
-
水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
-
滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
-
回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
-
简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
-
期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
-
自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
-
流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
版本更新与回滚
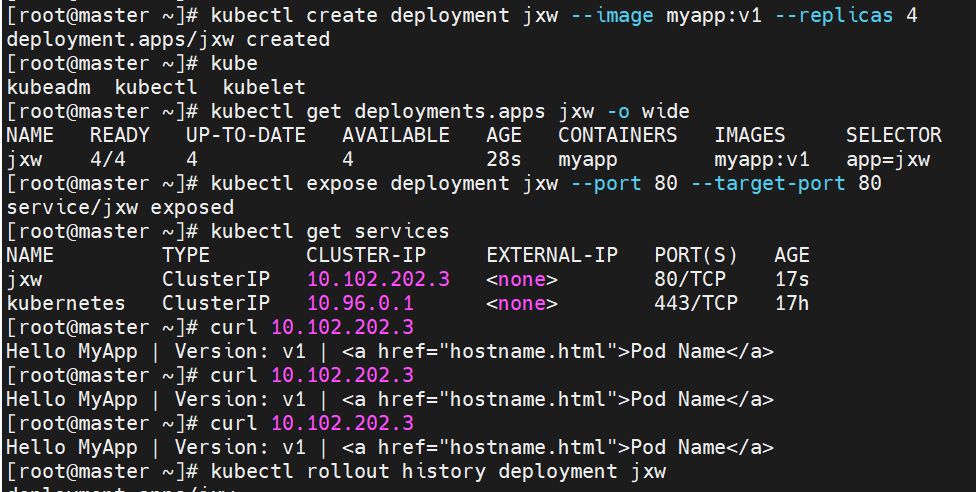
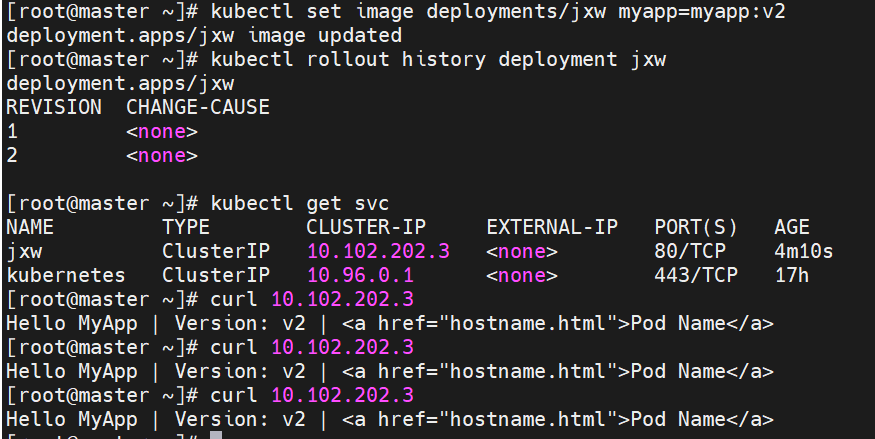
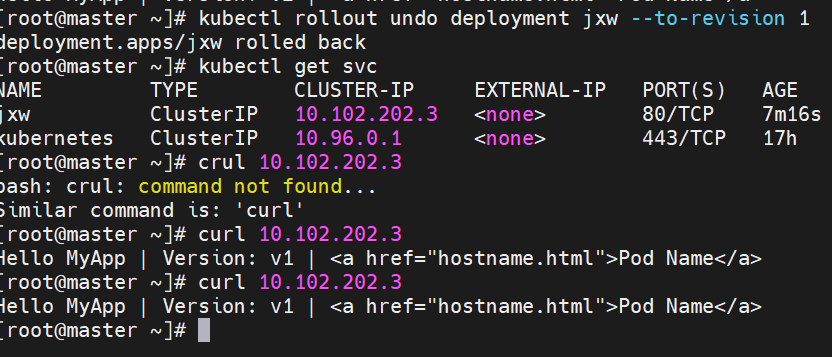
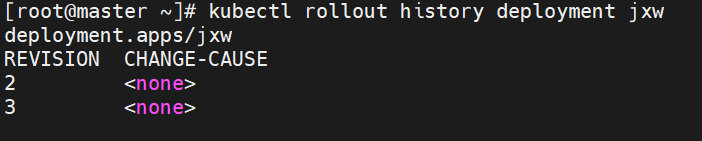
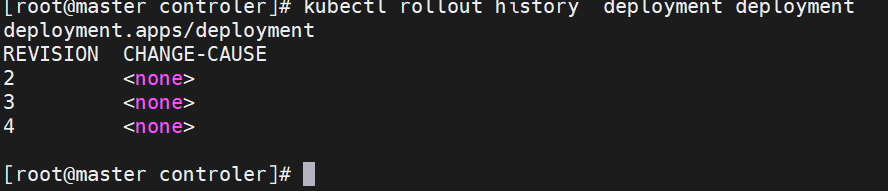
#这里版本v1---->revison1在回滚之后变为了版本revison3,在版本更新时deployment断开了与旧版本replicas的连接并新创了一个新版本replicas
利用yaml文件部署应用
用yaml文件部署应用有以下优点
声明式配置:
-
清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
-
可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
-
团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
-
丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
-
组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
-
与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
-
命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
编写示例
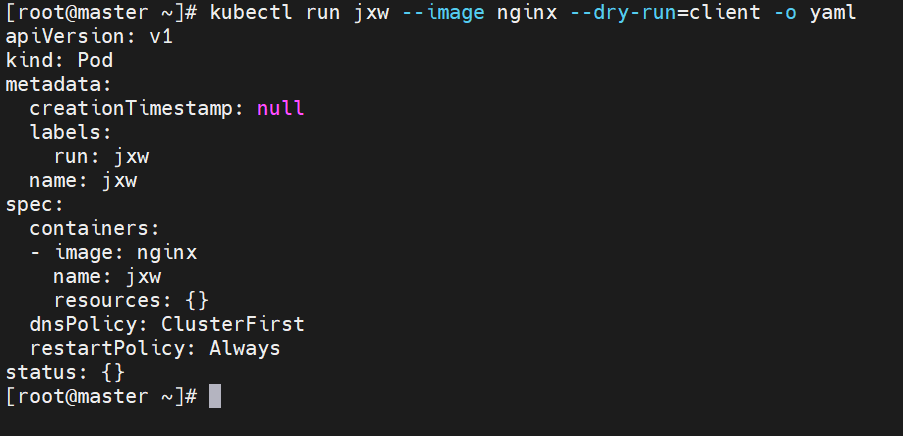
示例1:运行简单的单个容器pod
示例2:运行多个容器pod
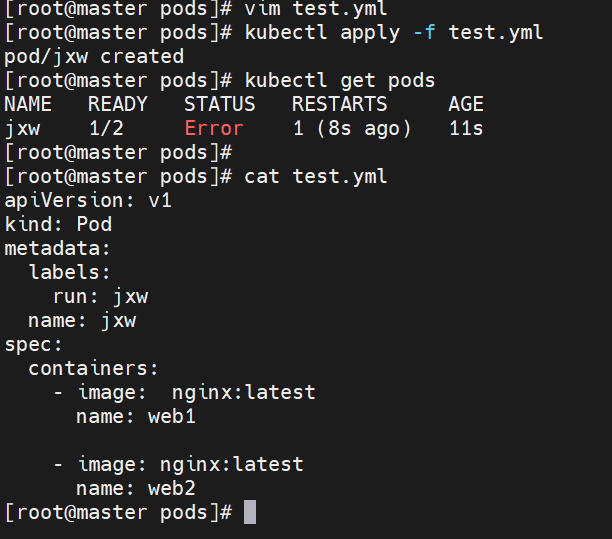
#注意如果多个容器运行在一个pod中,资源共享的同时在使用相同资源时也会干扰,比如端口
在一个pod中开启多个容器时一定要确保容器彼此不能互相干扰
示例3:理解pod间的网络整合
同在一个pod中的容器公用一个网络
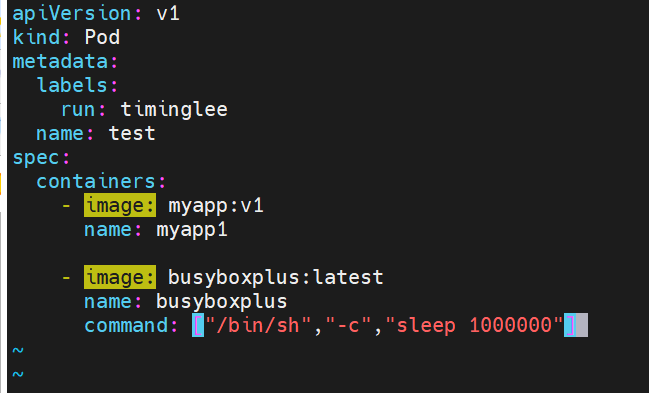

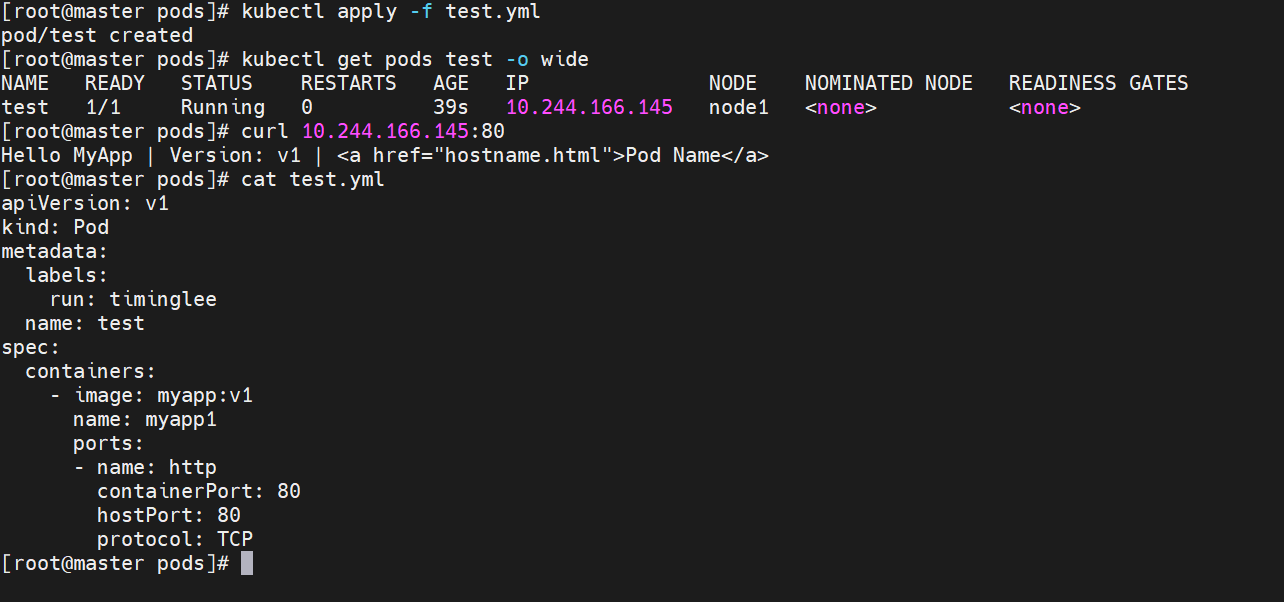
示例4:端口映射
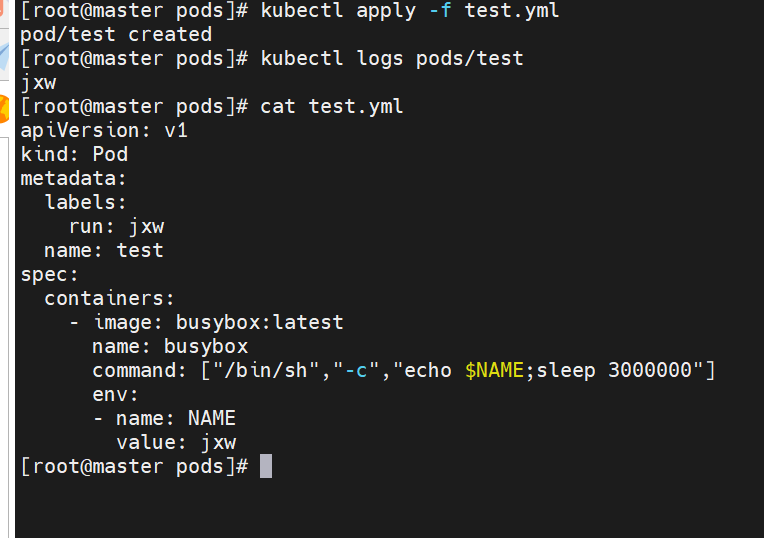
示例5:如何设定环境变量
示例6:资源限制
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
QoS(Quality of Service)即服务质量
|-----------------|------------|
| 资源设定 | 优先级类型 |
| 资源限定未设定 | BestEffort |
| 资源限定设定且最大和最小不一致 | Burstable |
| 资源限定设定且最大和最小一致 | Guaranteed |
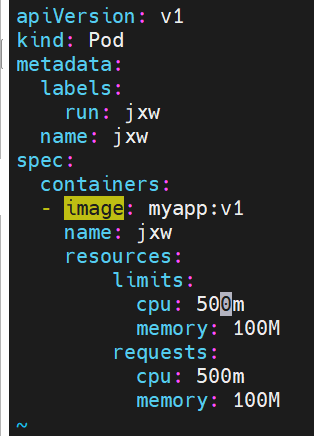
#这里设置的资源的期望使用资源量=最高限制,为最高优先类级别Guaranteed
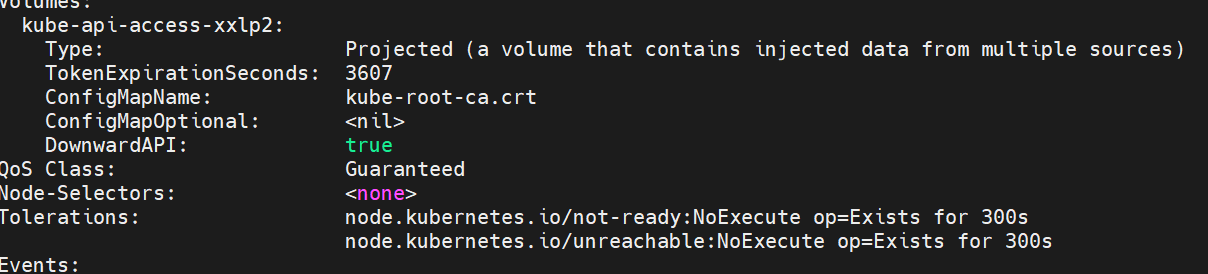
示例7 容器启动管理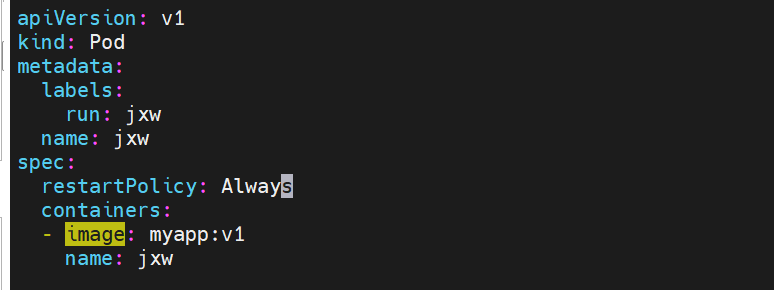

#在宿主机容器删除之后pod会立即重启动容器
示例8 选择运行节点
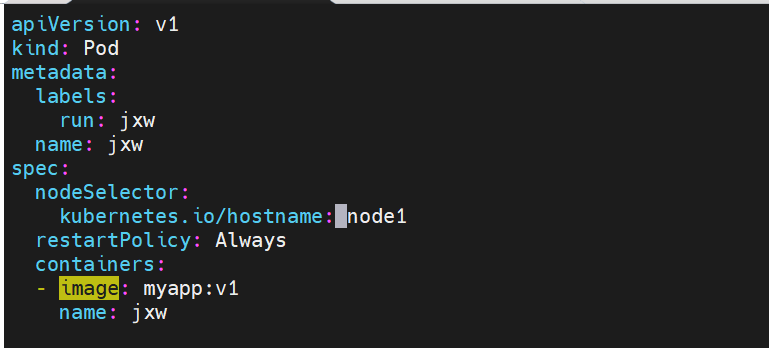
#无论是否识别到容器机上的镜像都会在node1上开启容器
示例9 共享宿主机网络
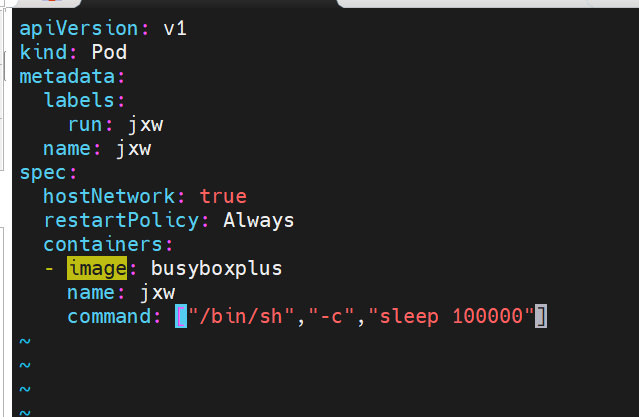
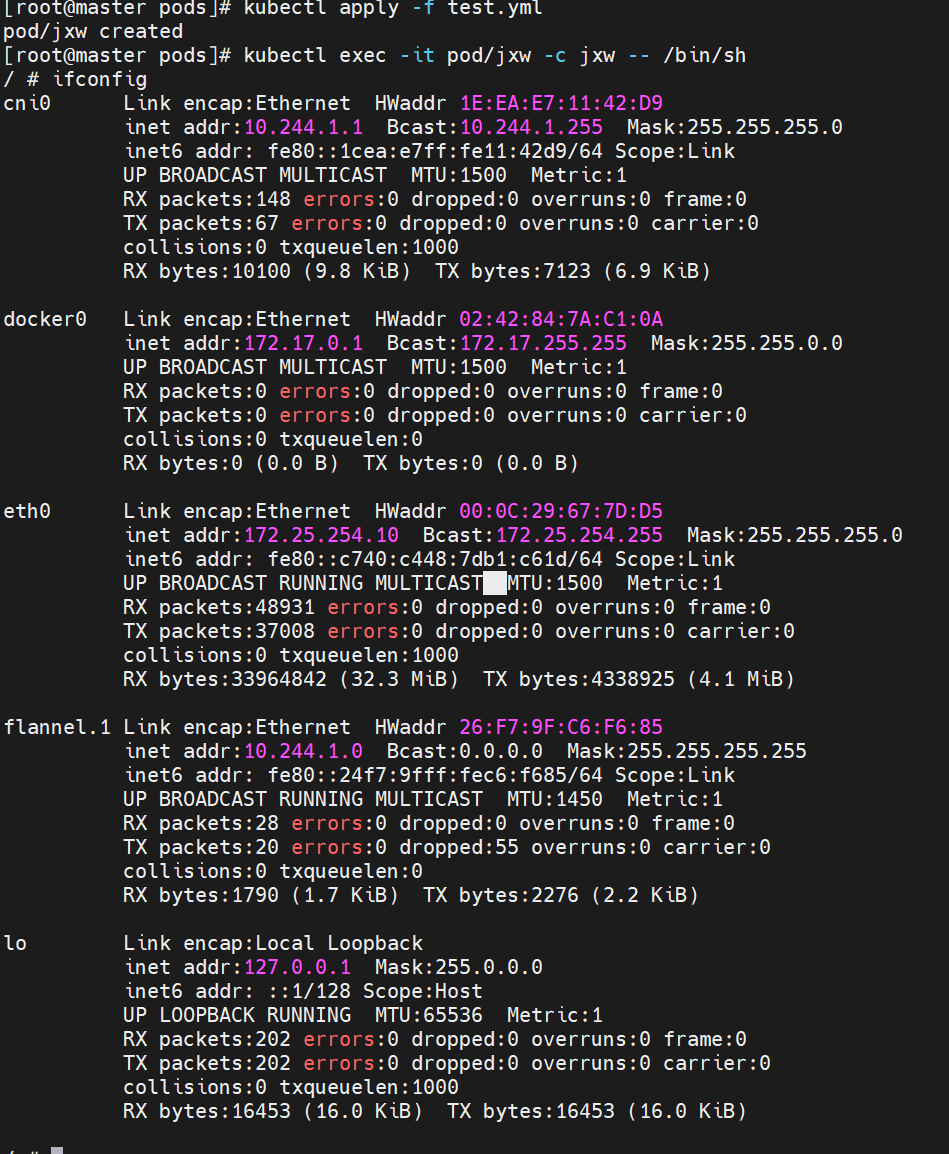

#设置ip与宿主机一致
pod的生命周期
INIT 容器
官方文档:Pod | Kubernetes
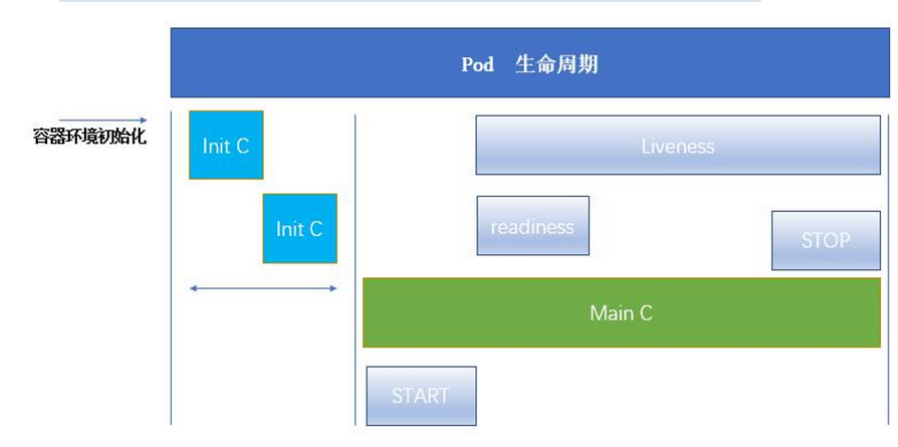
-
Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
-
Init 容器与普通的容器非常像,除了如下两点:
-
它们总是运行到完成
-
init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每个 Init 容器必须运行成功,下一个才能够运行。
-
-
如果Pod的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。但是,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动
INIT 容器的功能
-
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
-
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
-
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
-
Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
-
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
探针
探针是由 kubelet 对容器执行的定期诊断:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
成功:容器通过了诊断。
-
失败:容器未通过诊断。
-
未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
-
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
-
readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
-
ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
-
LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
-
如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
-
另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
探针实例
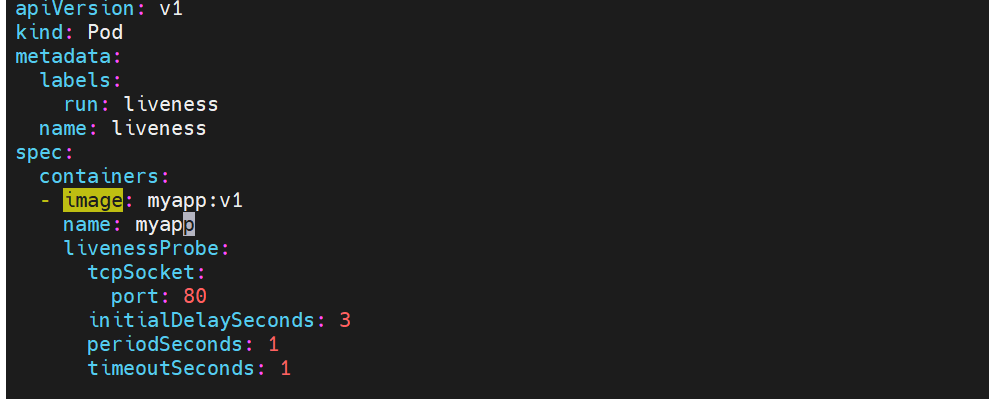
存活探针示例: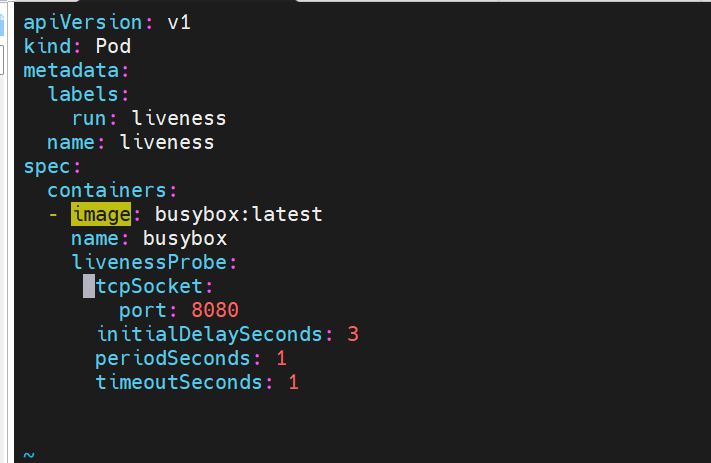

#没有暴漏端口,就绪探针探测不满足暴漏条件

就绪探针示例:
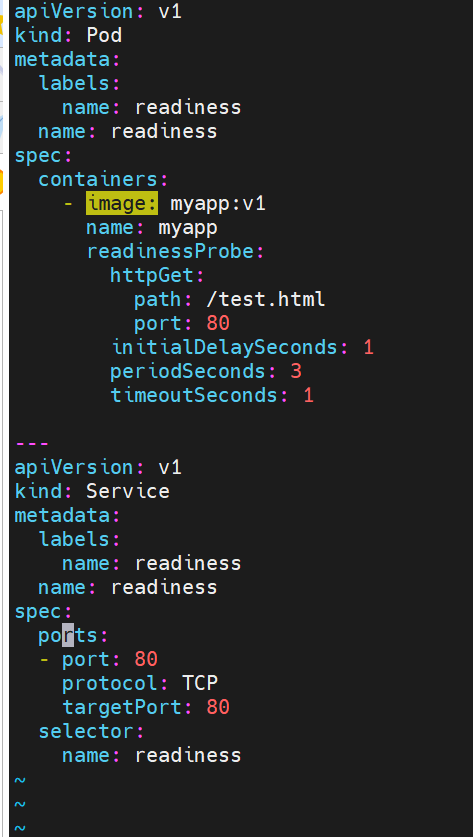

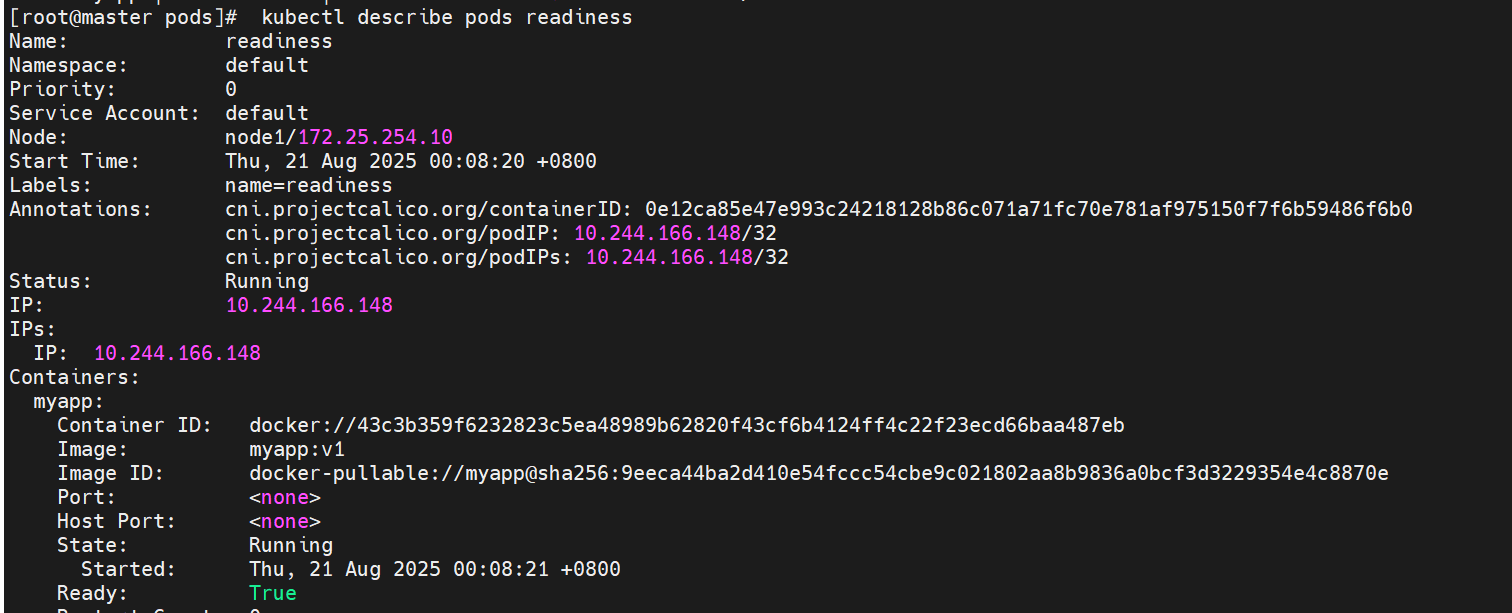
#服务没有就绪这里的就绪探针探测不满足暴漏条件,与存活检测端口暴露不同,就绪探针还要检测服务是否准备就绪

#将服务准备就绪后,pod成功启动
什么是控制器
控制器也是管理pod的一种手段
-
自主式pod:pod退出或意外关闭后不会被重新创建
-
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
控制器常用类型
|--------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 控制器名称 | 控制器用途 |
| Replication Controller | 比较原始的pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
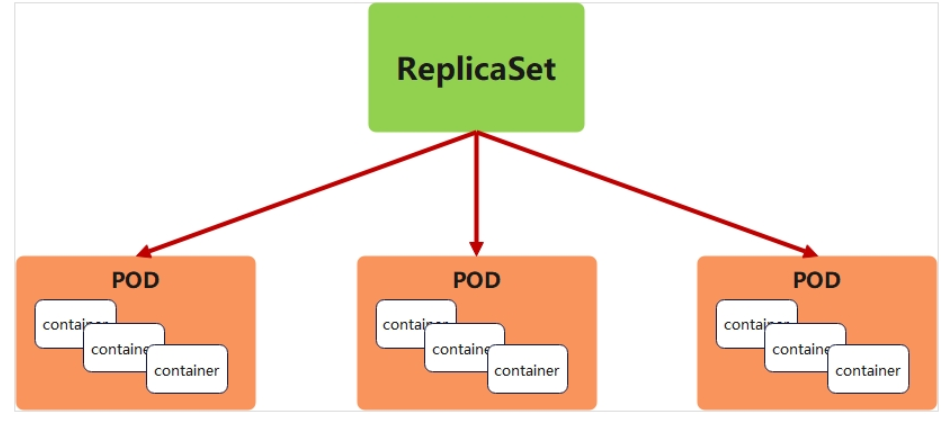
replicaset控制器
-
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
-
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
-
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
-
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
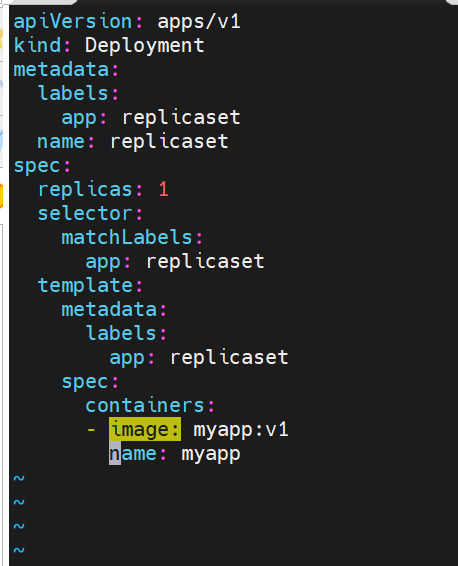
bash
[root@master ~]# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:
replicas: 2 #指定维护pod数量为2
selector: #指定检测匹配方式
matchLabels: #指定匹配方式为匹配标签
app: myapp #指定匹配的标签为app=myapp
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp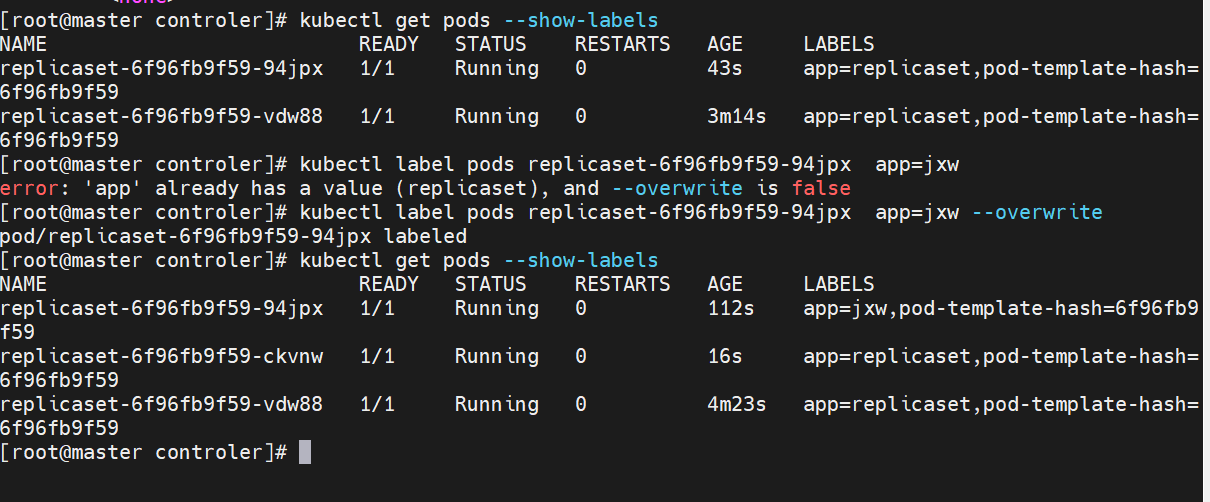
#replicaset是通过标签匹配pod,改变原有标签后replicaset会开启新的pod
deployment 控制器
deployment控制器的功能
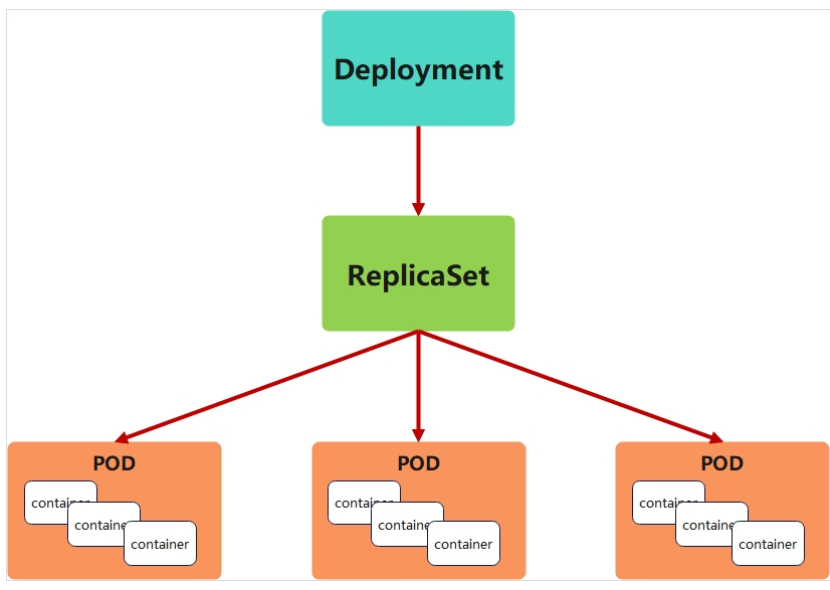
-
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。
-
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
-
Deployment管理ReplicaSet,ReplicaSet管理Pod
-
Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
-
在Deployment中ReplicaSet相当于一个版本
典型的应用场景:
-
用来创建Pod和ReplicaSet
-
滚动更新和回滚
-
扩容和缩容
-
暂停与恢复
deployment控制器示例
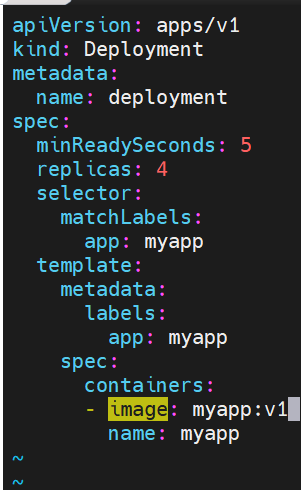
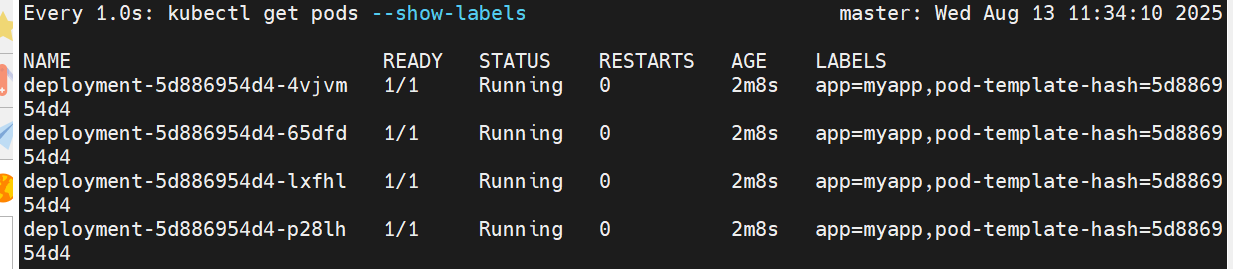
版本迭代
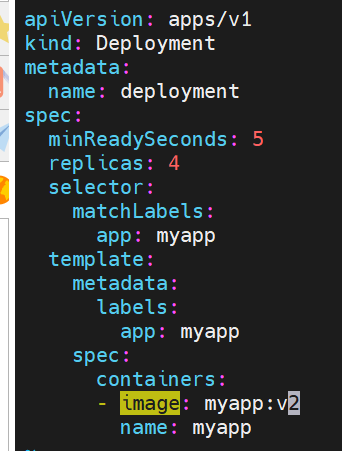

版本回滚
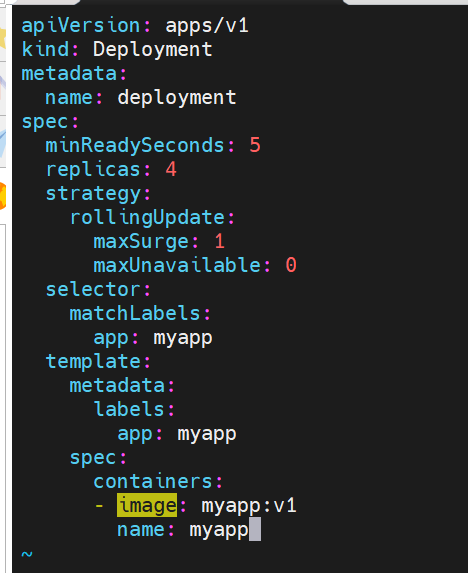
暂停及恢复
在实际生产环境中我们做的变更可能不止一处,当修改了一处后,如果执行变更就直接触发了
我们期望的触发时当我们把所有修改都搞定后一次触发暂停,避免触发不必要的线上更新
这里我们暂停管理器并进行副本的调整

将副本数设为6,以及对镜像进行更新
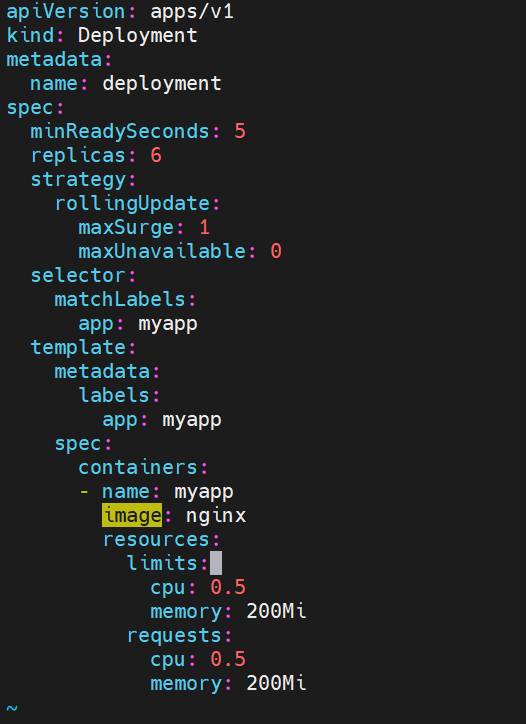
这里副本数量变化不受影响但是镜像和资源并没有更新
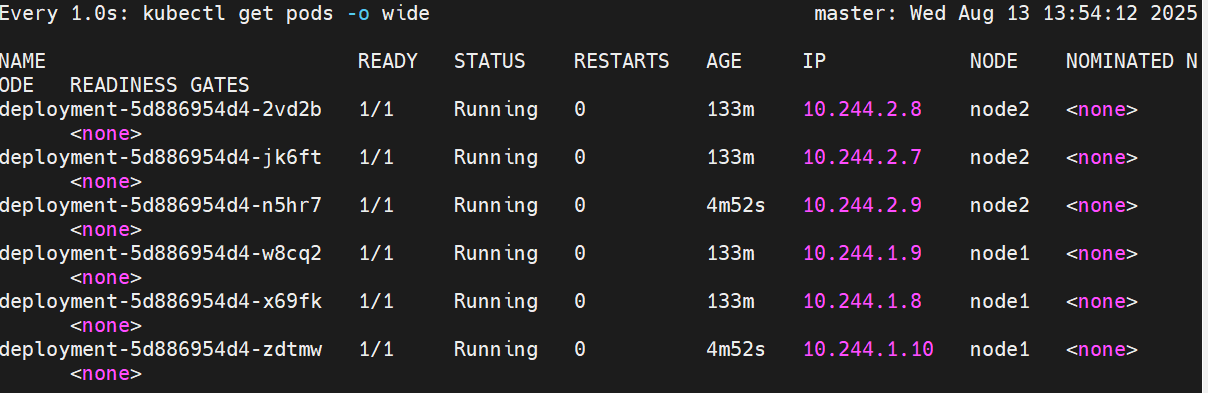
恢复暂停

触发了版本的更新
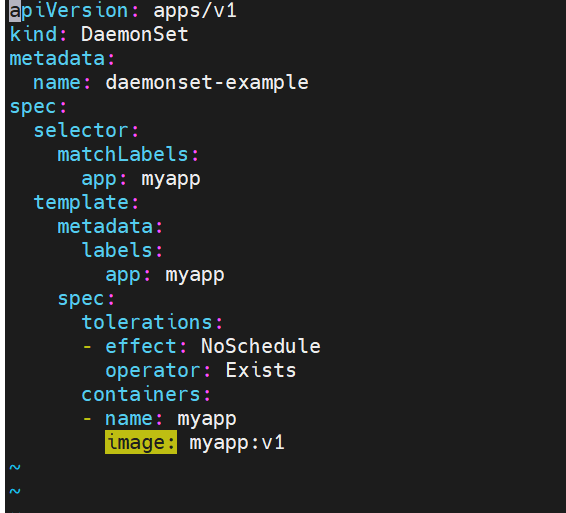
daemonset控制器
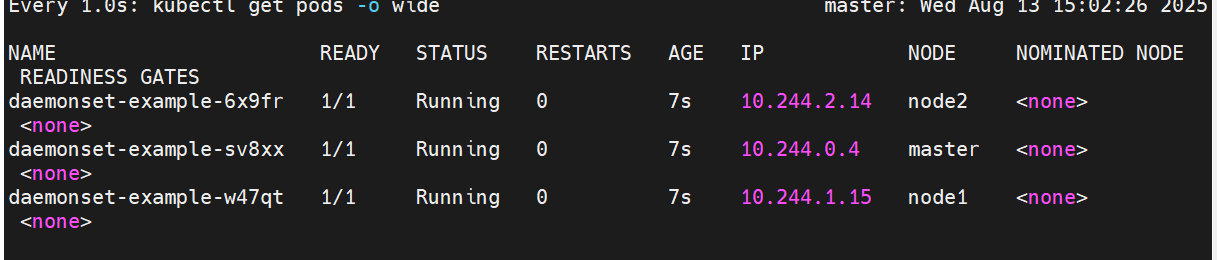
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
DaemonSet 的典型用法:
-
在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
-
在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
-
在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
-
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
-
一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
daemonset 示例
job 控制器
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
-
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
-
当成功结束的pod达到指定的数量时,Job将完成执行
job 控制器示例:
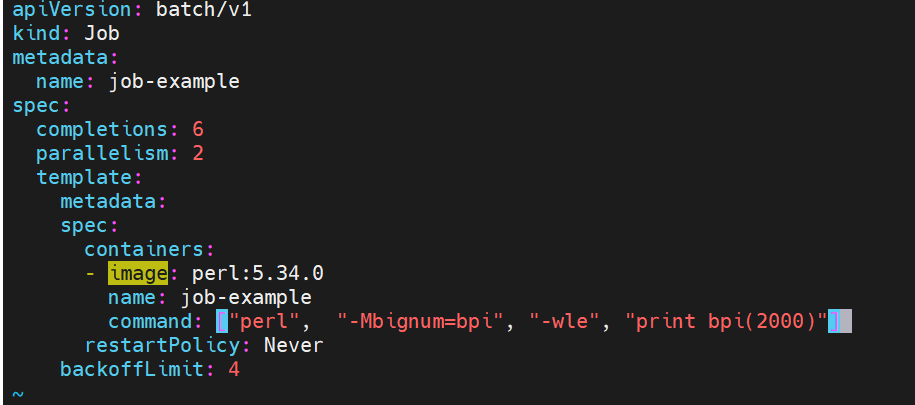
关于重启策略设置的说明:
如果指定为OnFailure,则job会在pod出现故障时重启容器
而不是创建pod,failed次数不变
如果指定为Never,则job会在pod出现故障时创建新的pod
并且故障pod不会消失,也不会重启,failed次数加1
如果指定为Always的话,就意味着一直重启,意味着job任务会重复去执行了
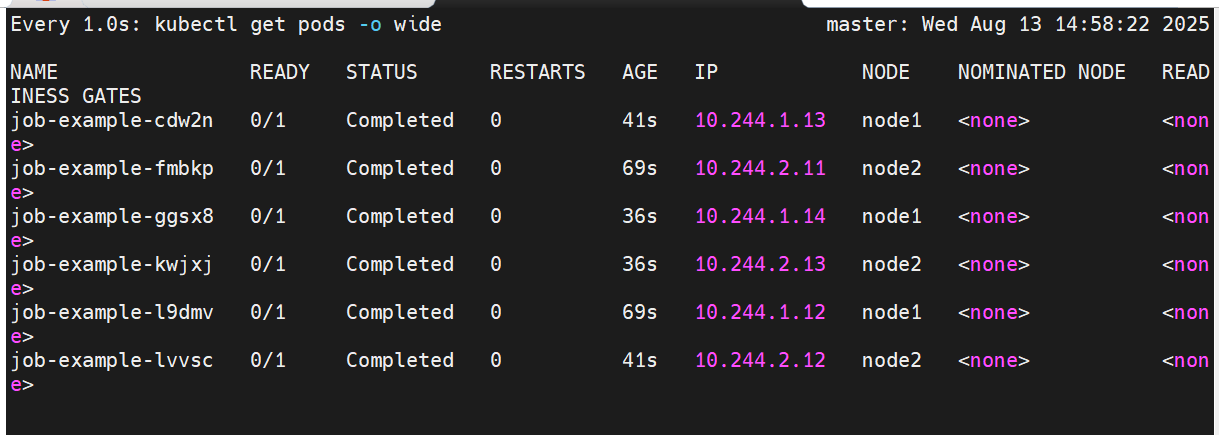
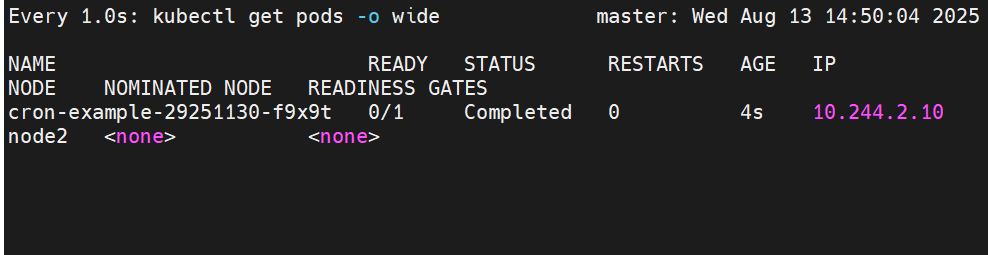
#查看job运行效果

cronjob 控制器
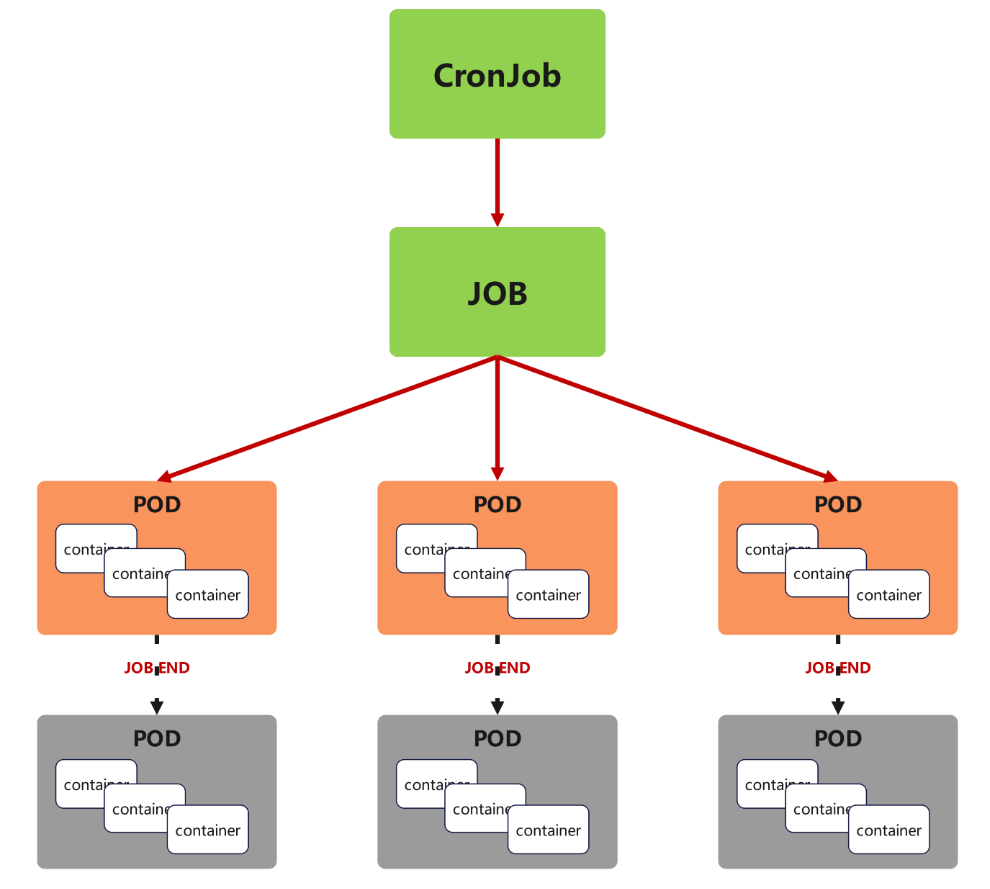
-
Cron Job 创建基于时间调度的 Jobs。
-
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,
-
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
-
CronJob可以在特定的时间点(反复的)去运行job任务。
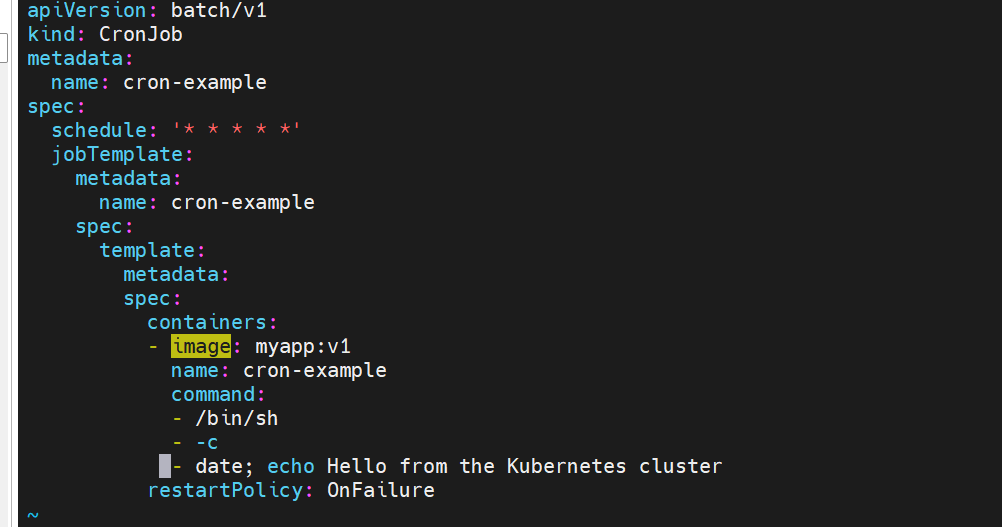
cronjob 控制器 示例
#这里指定每分钟打印
什么是微服务
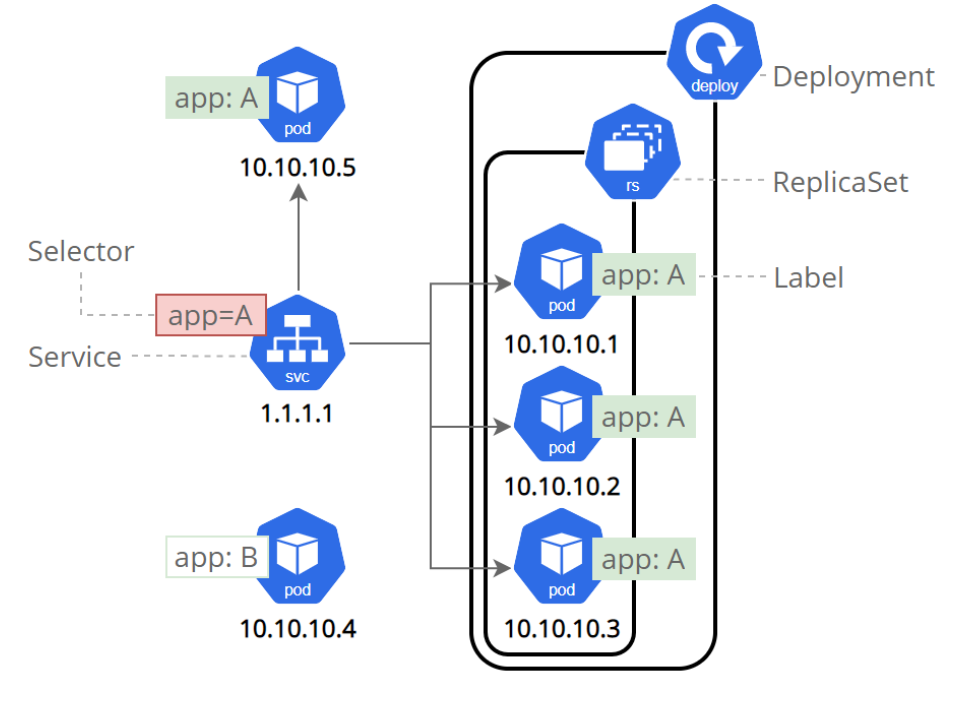
用控制器来完成集群的工作负载,那么应用如何暴漏出去?需要通过微服务暴漏出去后才能被访问
-
Service是一组提供相同服务的Pod对外开放的接口。
-
借助Service,应用可以实现服务发现和负载均衡。
-
service默认只支持4层负载均衡能力,没有7层功能。(可以通过Ingress实现)
微服务的类型
|--------------|----------------------------------------------------------------------------------|
| 微服务类型 | 作用描述 |
| ClusterIP | 默认值,k8s系统给service自动分配的虚拟IP,只能在集群内部访问 |
| NodePort | 将Service通过指定的Node上的端口暴露给外部,访问任意一个NodeIP:nodePort都将路由到ClusterIP |
| LoadBalancer | 在NodePort的基础上,借助cloud provider创建一个外部的负载均衡器,并将请求转发到 NodeIP:NodePort,此模式只能在云服务器上使用 |
| ExternalName | 将服务通过 DNS CNAME 记录方式转发到指定的域名(通过 spec.externlName 设定 |
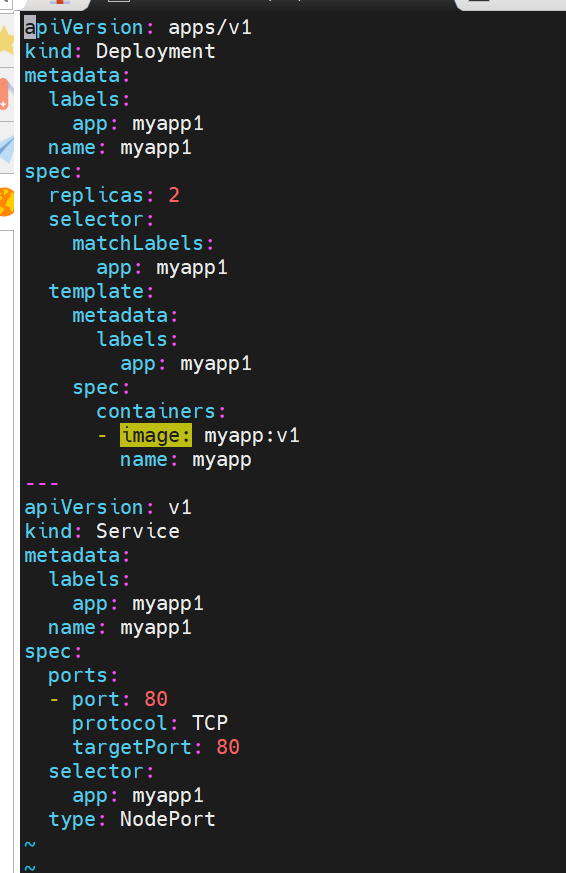
#生成控制器文件并建立控制器
root@master \~# kubectl create deployment timinglee --image myapp:v1 --replicas 2 --dry-run=client -o yaml > myapp1.yml
#生成微服务yaml追加到已有yaml中
root@master \~# kubectl expose deployment timinglee --port 80 --target-port 80 --dry-run=client -o yaml >> myapp1.yml

ipvs模式
-
Service 是由 kube-proxy 组件,加上 iptables 来共同实现的
-
kube-proxy 通过 iptables 处理 Service 的过程,需要在宿主机上设置相当多的 iptables 规则,如果宿主机有大量的Pod,不断刷新iptables规则,会消耗大量的CPU资源
-
IPVS模式的service,可以使K8s集群支持更多量级的Pod
ipvs模式配置方式
root@k8s-所有节点 podyum install ipvsadm --y
#设置kube-proxy使用ipvs模式kubectl -n kube-system edit cm kube-proxy
微服务类型详解
clusterip
clusterip模式只能在集群内访问,并对集群内的pod提供健康检测和自动发现功能
示例
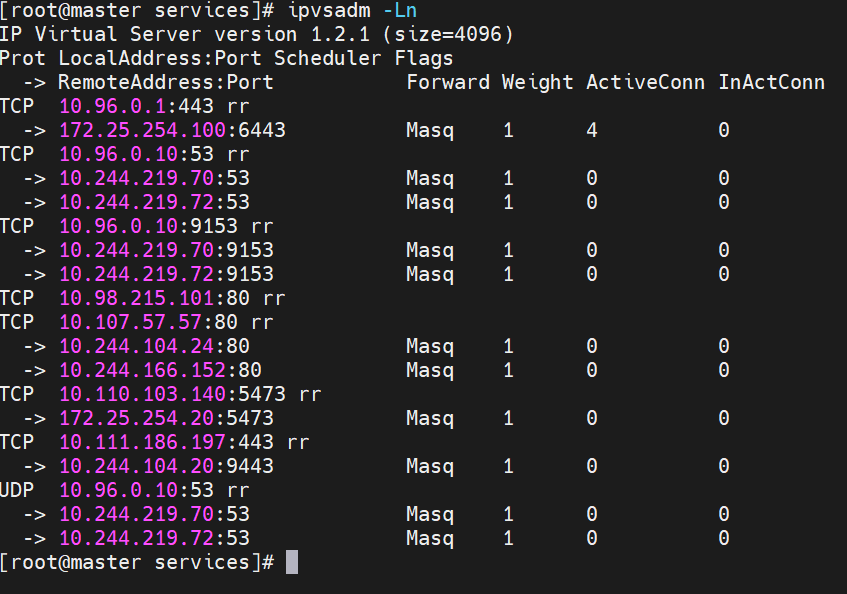
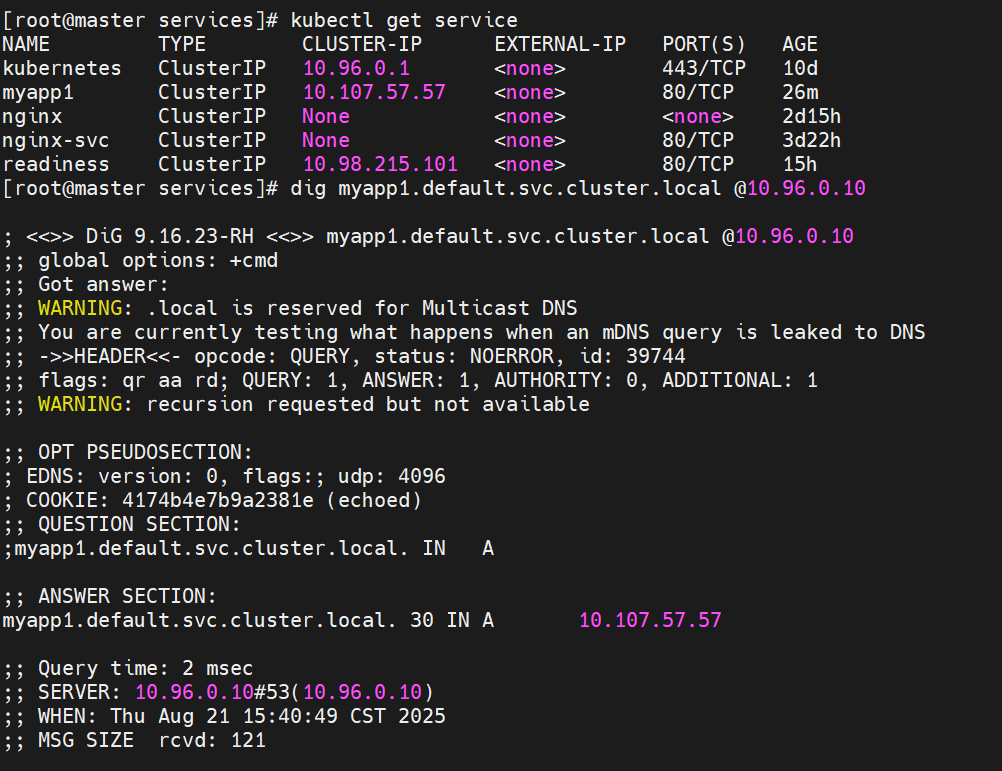
#service创建后集群DNS提供解析
ClusterIP中的特殊模式headless
headless(无头服务)
对于无头 `Services` 并不会分配 Cluster IP,kube-proxy不会处理它们, 而且平台也不会为它们进行负载均衡和路由,集群访问通过dns解析直接指向到业务pod上的IP,所有的调度有dns单独完成

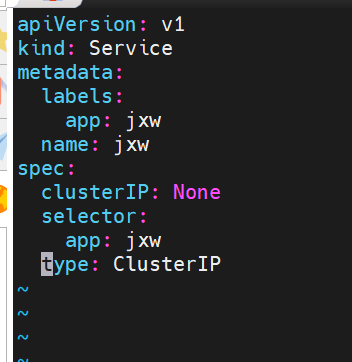
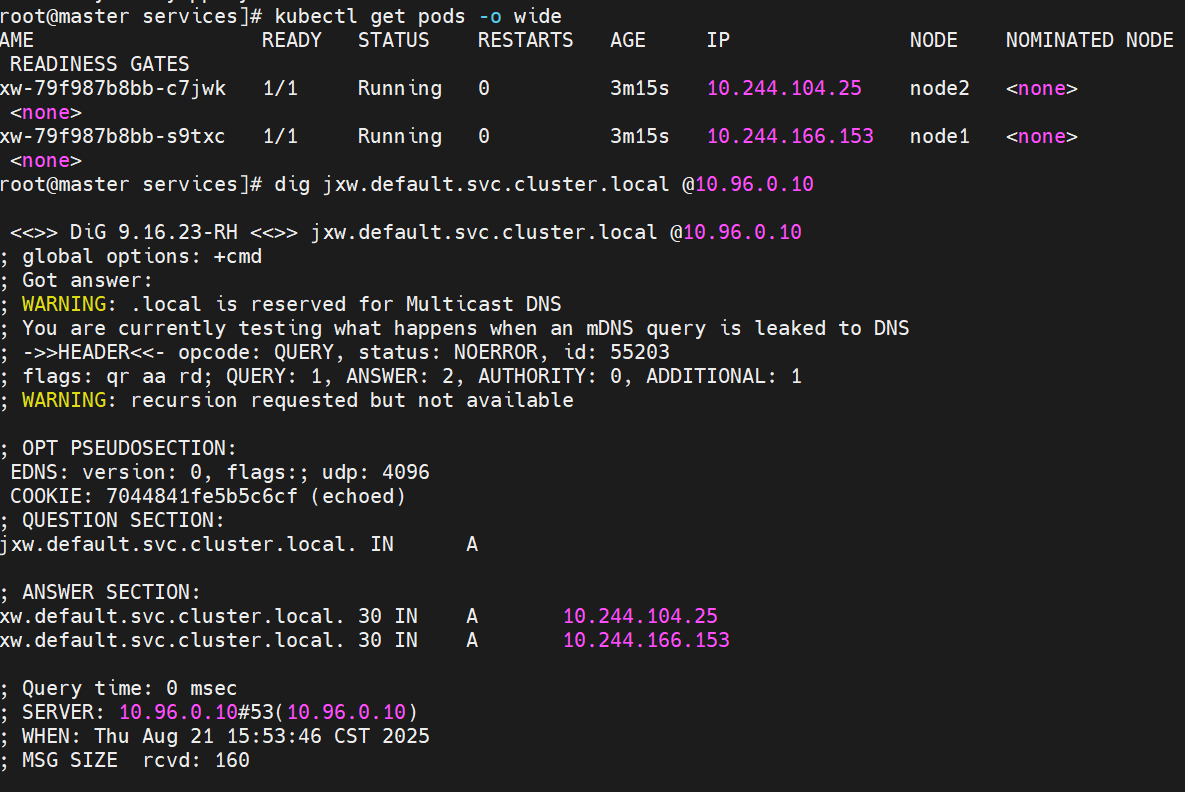
#直接解析到pod上
nodeport
通过ipvs暴漏端口从而使外部主机通过master节点的对外ip:<port>来访问pod业务
其访问过程为:

示例
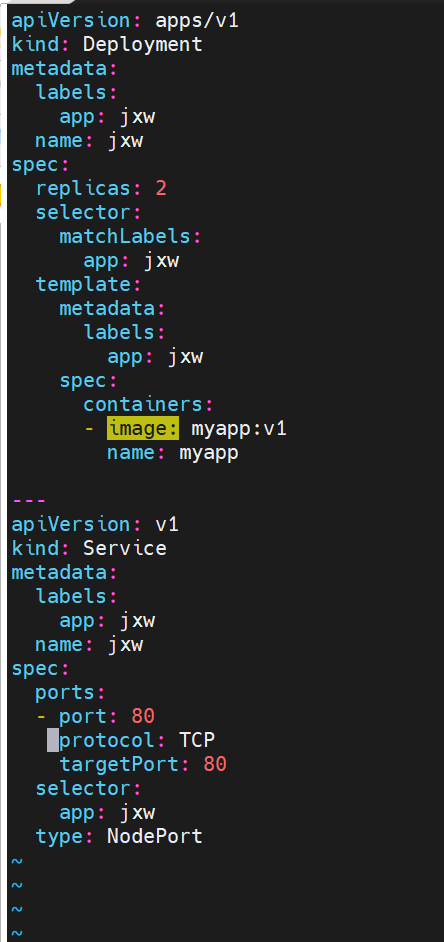
#nodeport在集群节点上绑定端口,一个端口对应一个服务
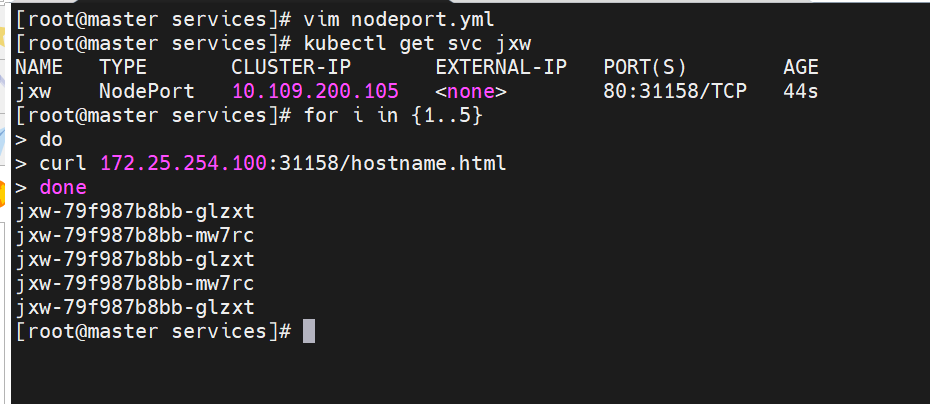
#这里也可以指定端口
nodeport默认端口
nodeport默认端口是30000-32767,超出会报错
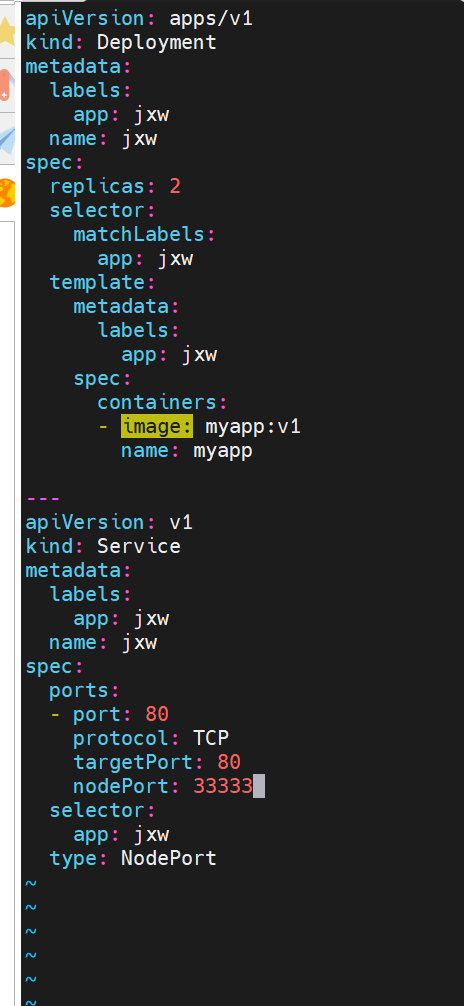

loadbalancer
云平台会为我们分配vip并实现访问,如果是裸金属主机那么需要metallb来实现ip的分配

示例
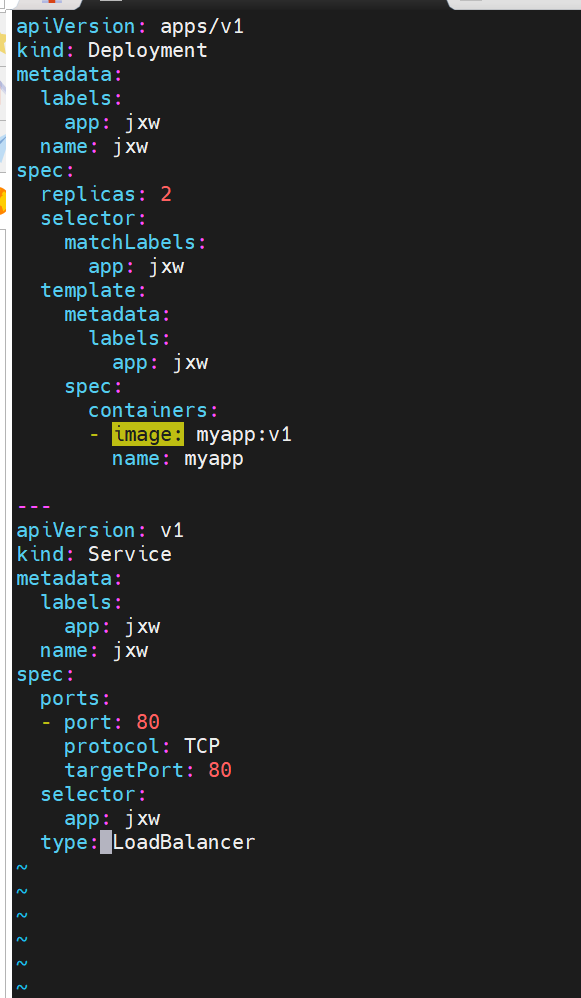
metalLB
官网:Installation :: MetalLB, bare metal load-balancer for Kubernetes
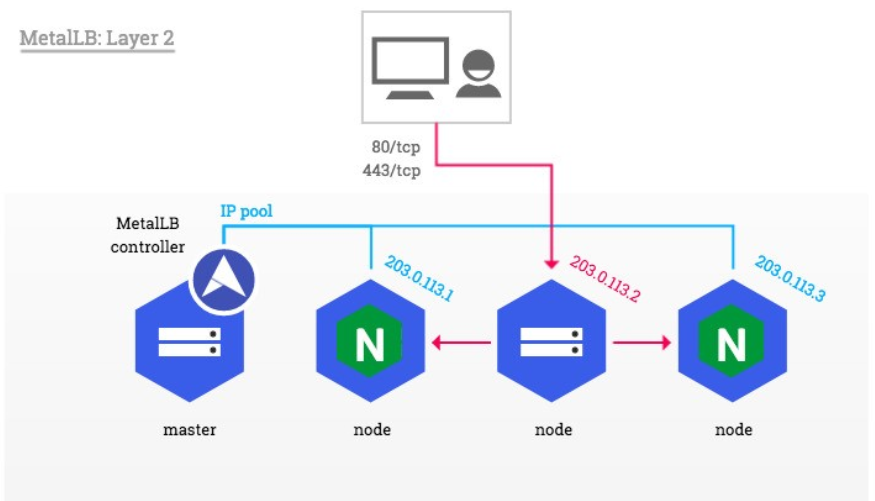
metalLB功能
为LoadBalancer分配vip
部署方式
#设置ipvs模式
kubectl edit cm -n kube-system kube-proxy
#下载部署文件
wget https://raw.githubusercontent.com/metallb/metallb/v0.13.12/config/manifests/metallb-native.yaml
#修改文件中镜像地址,与harbor仓库路径保持一致
vim metallb-native.yaml
...
image: metallb/controller:v0.14.8
image: metallb/speaker:v0.14.8
上传镜像到harbor
部署服务
kubectl apply -f metallb-native.yaml
kubectl -n metallb-system get pods
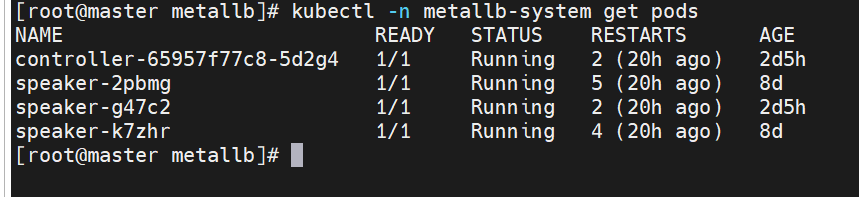
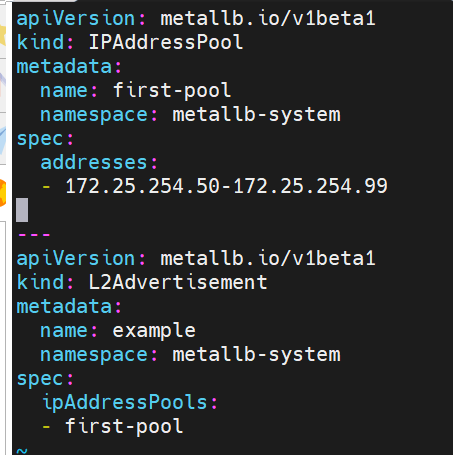
#配置分配地址段
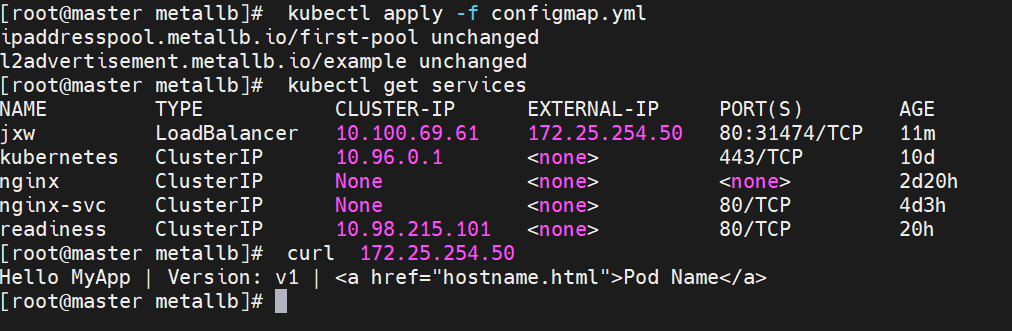
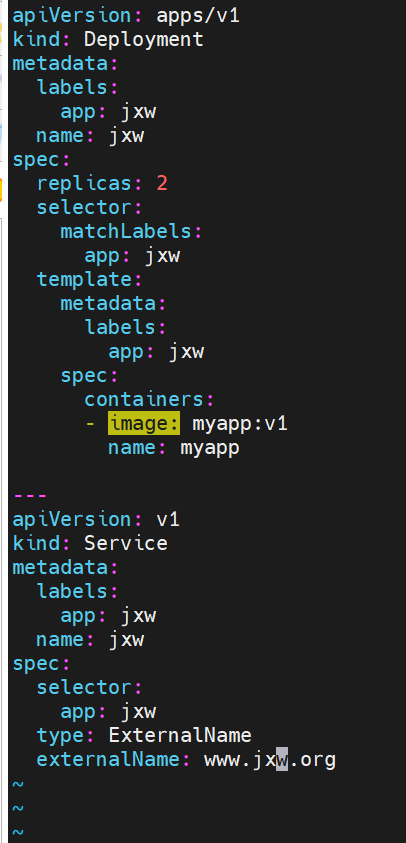
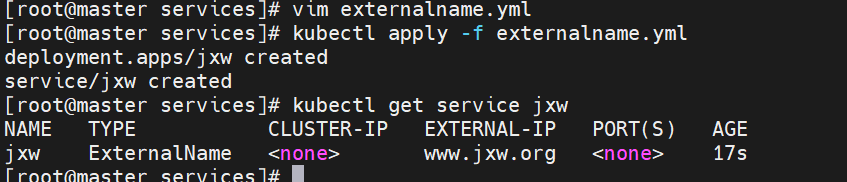
externalname
-
开启services后,不会被分配IP,而是用dns解析CNAME固定域名来解决ip变化问题
-
一般应用于外部业务和pod沟通或外部业务迁移到pod内时
-
在应用向集群迁移过程中,externalname在过度阶段就可以起作用了。
-
集群外的资源迁移到集群时,在迁移的过程中ip可能会变化,但是域名+dns解析能完美解决此问题
示例
Ingress-nginx
ingress-nginx功能
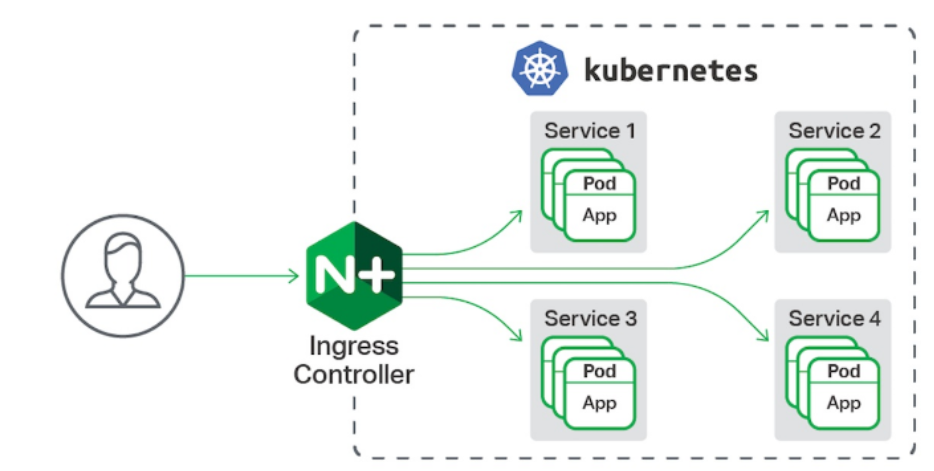
-
一种全局的、为了代理不同后端 Service 而设置的负载均衡服务,支持7层
-
Ingress由两部分组成:Ingress controller和Ingress服务
-
Ingress Controller 会根据你定义的 Ingress 对象,提供对应的代理能力。
-
业界常用的各种反向代理项目,比如 Nginx、HAProxy、Envoy、Traefik 等,都已经为Kubernetes 专门维护了对应的 Ingress Controller。
部署ingress
下载部署文件
上传ingress所需镜像到harbor
安装ingress
root@master \~# vim deploy.yaml
445 image: ingress-nginx/controller:v1.11.2
546 image: ingress-nginx/kube-webhook-certgen:v1.4.3
599 image: ingress-nginx/kube-webhook-certgen:v1.4.3
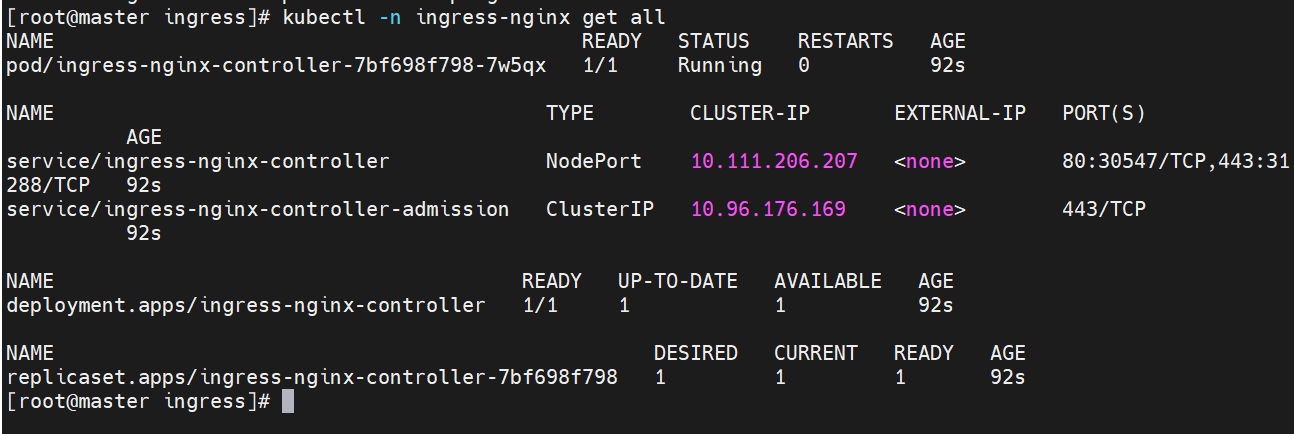
#这里默认svc类型为NodePort应改为LoadBalancer

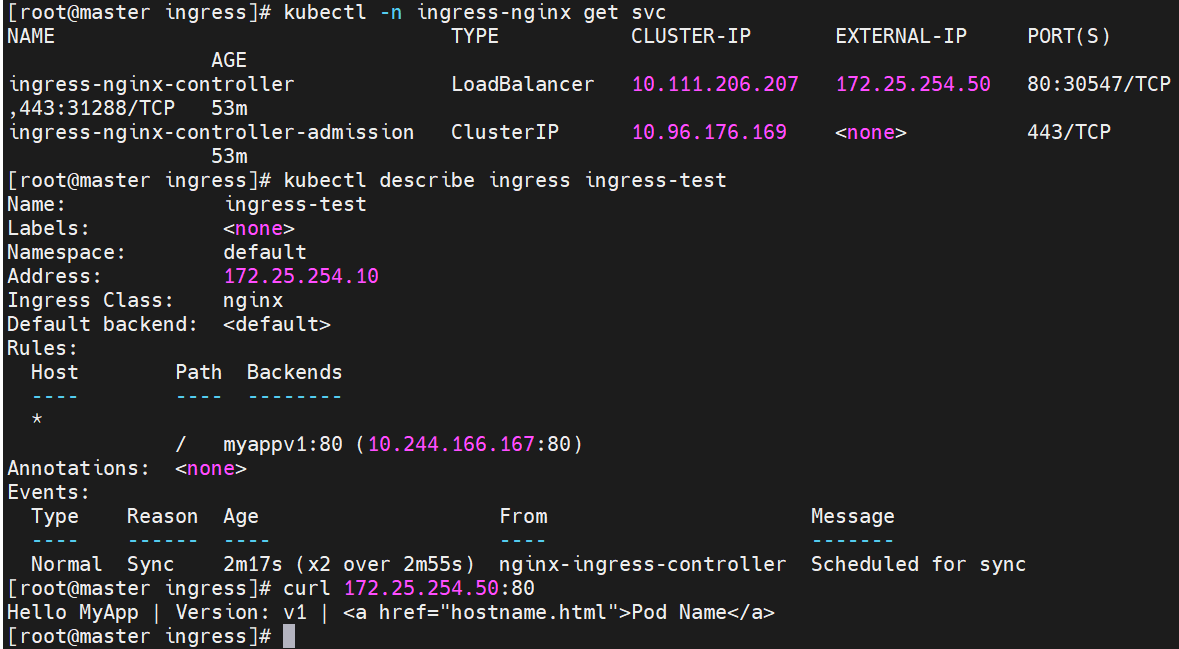
测试ingress
#Exact(精确匹配),ImplementationSpecific(特定实现),Prefix(前缀匹配),Regular expression(正则表达式匹配)

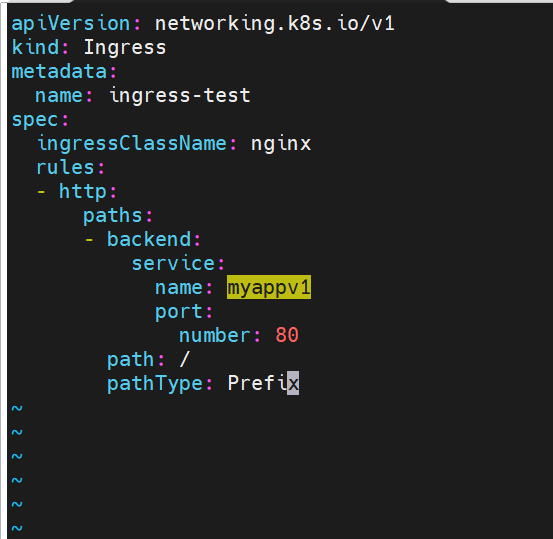
#创建两个测试web服务器
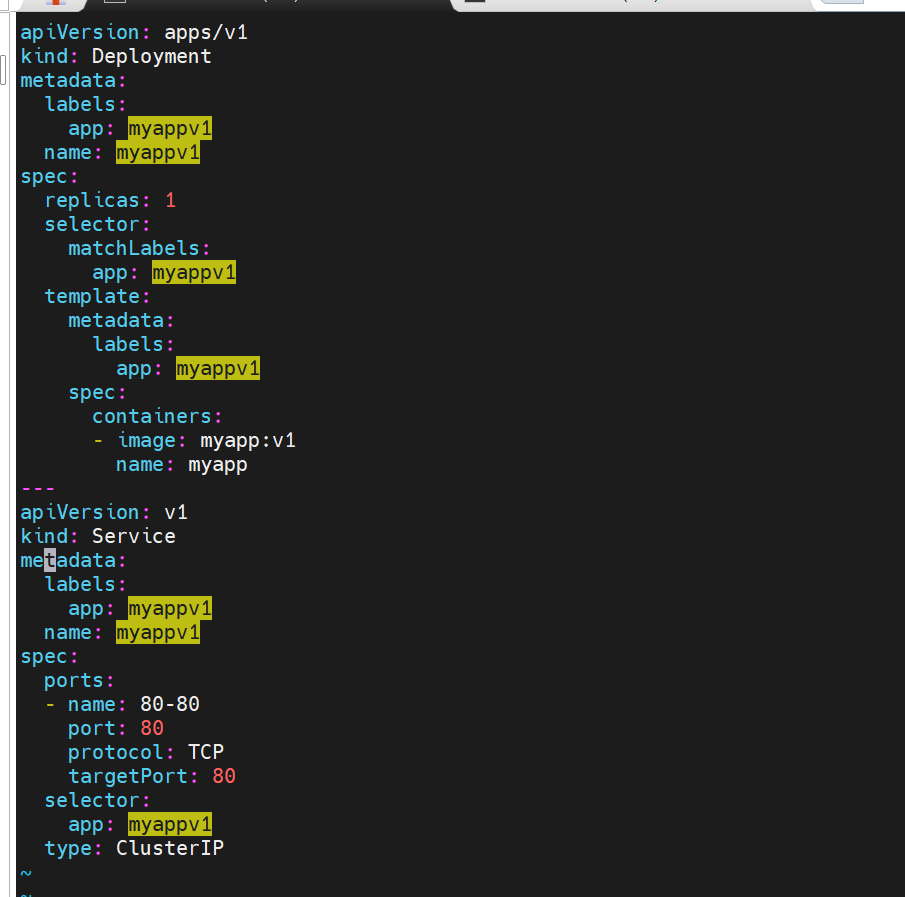
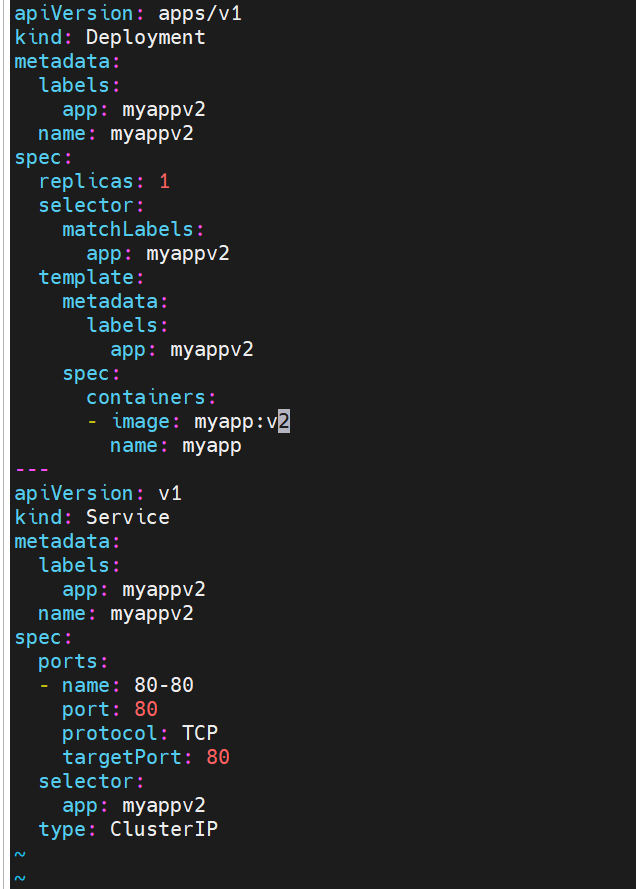
#这里访问代理服务器地址时会指向myappv1的内容
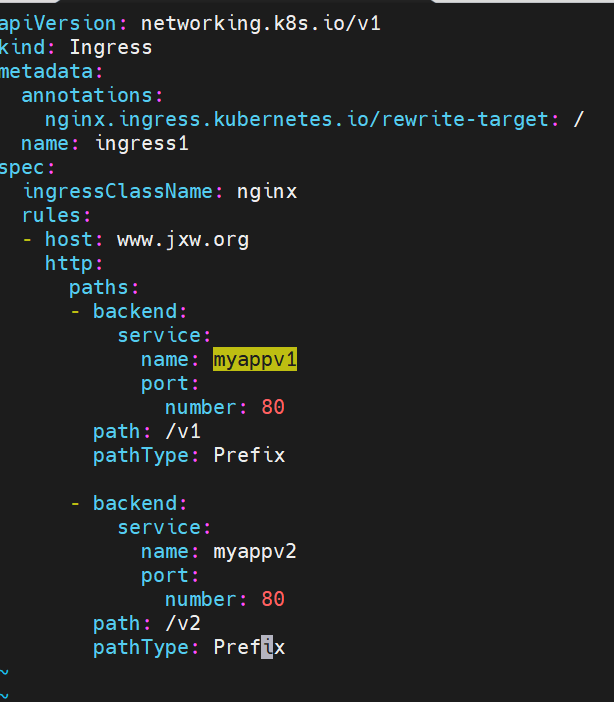
ingress 的高级用法
基于路径的访问
建立ingress的yaml
#访问路径后加任何内容都被定向到/
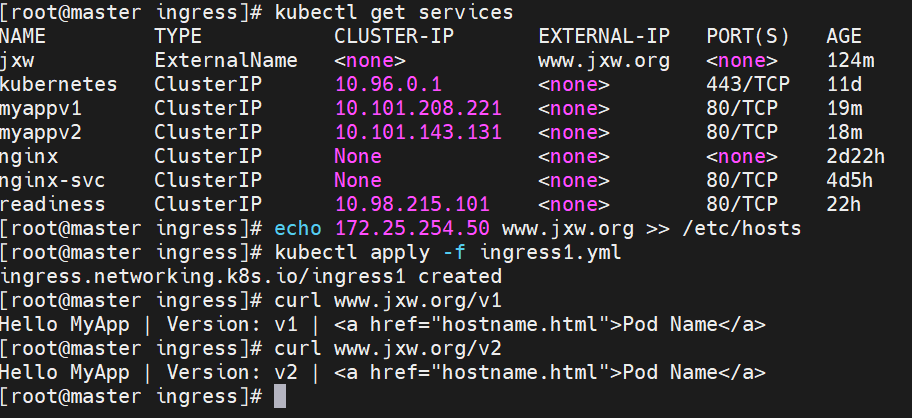
基于域名的访问
#在测试主机中设定解析

建立基于域名的yml文件
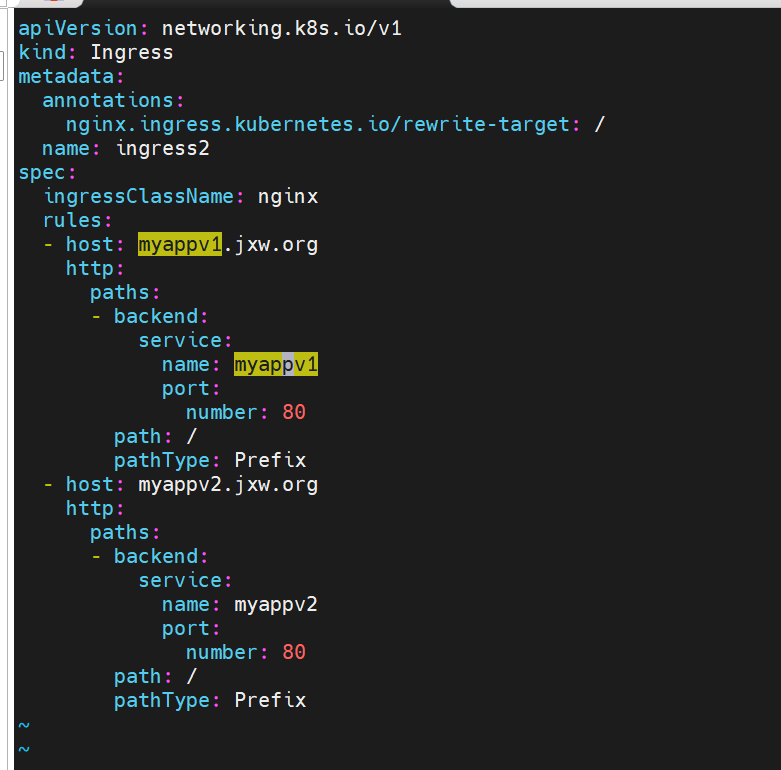
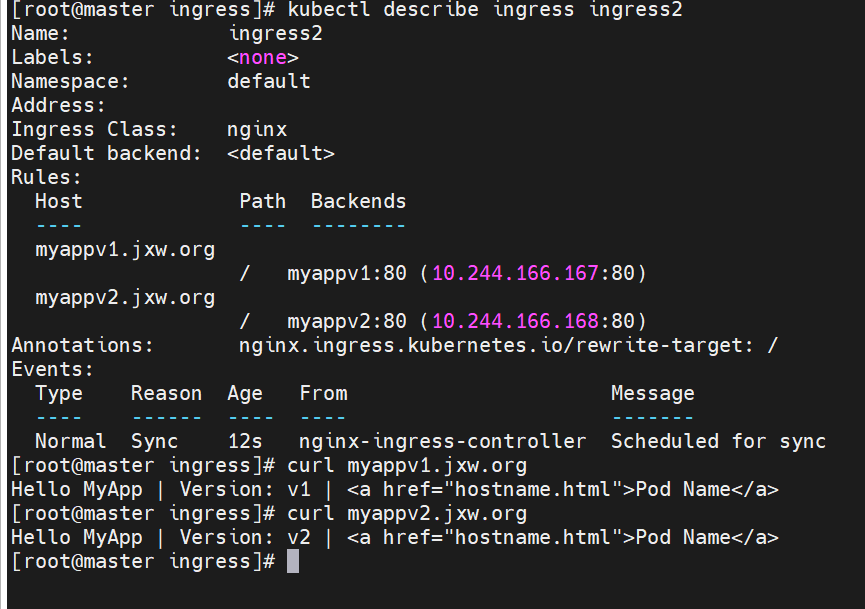
测试
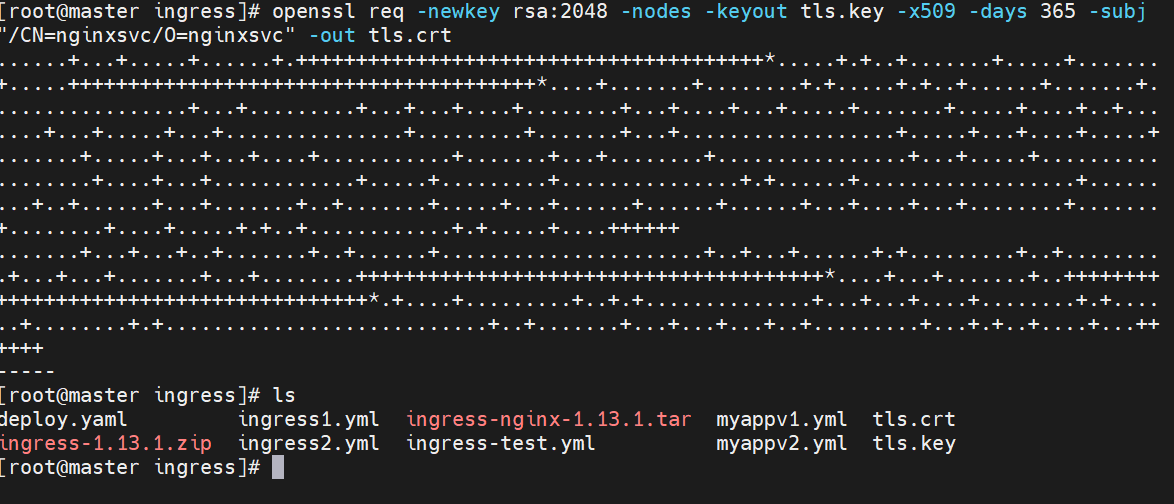
建立tls加密
#建立证书
#建立加密资源类型secret

#建立ingress3基于tls认证的yml文件
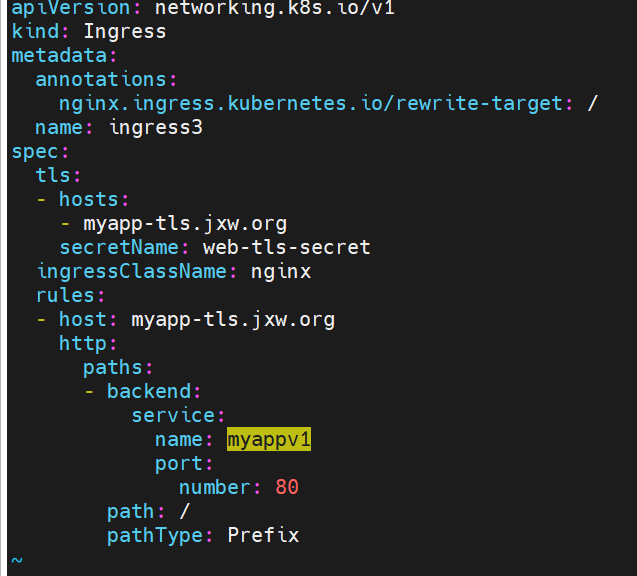
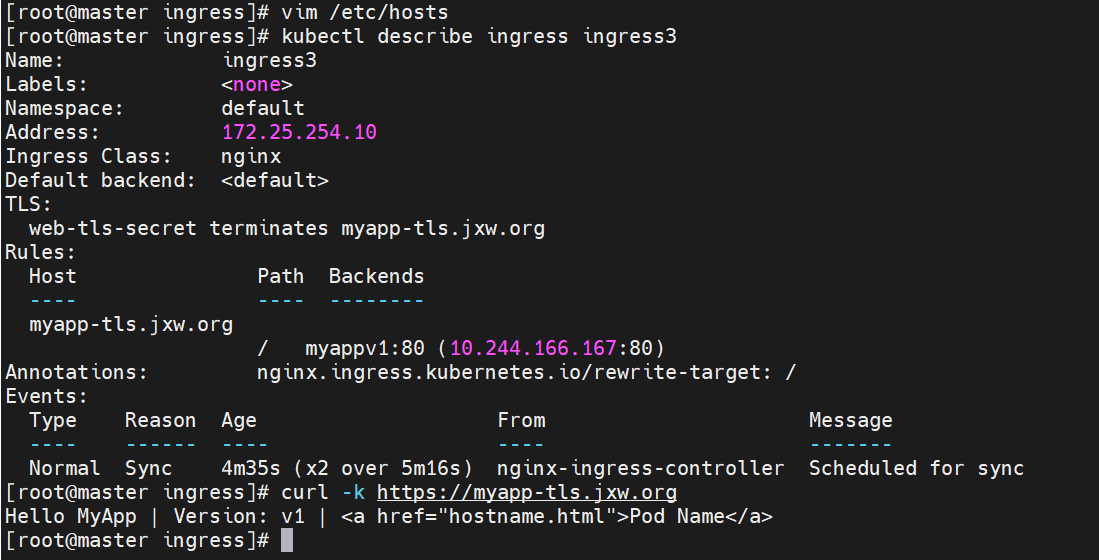
#做本地域名解析

测试
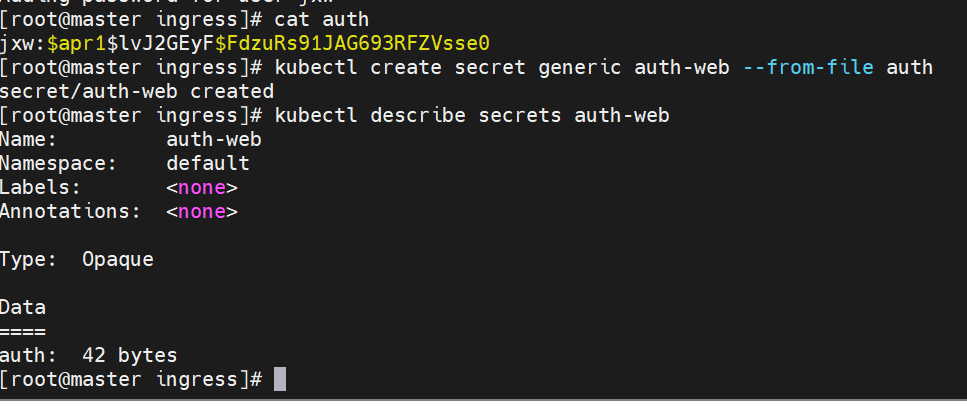
建立auth认证
建立认证文件
dnf install httpd-tools -y
htpasswd -cm auth jxw
New password:
Re-type new password:
Adding password for user jxw
建立auth认证
#建立ingress4基于用户认证的yaml文件
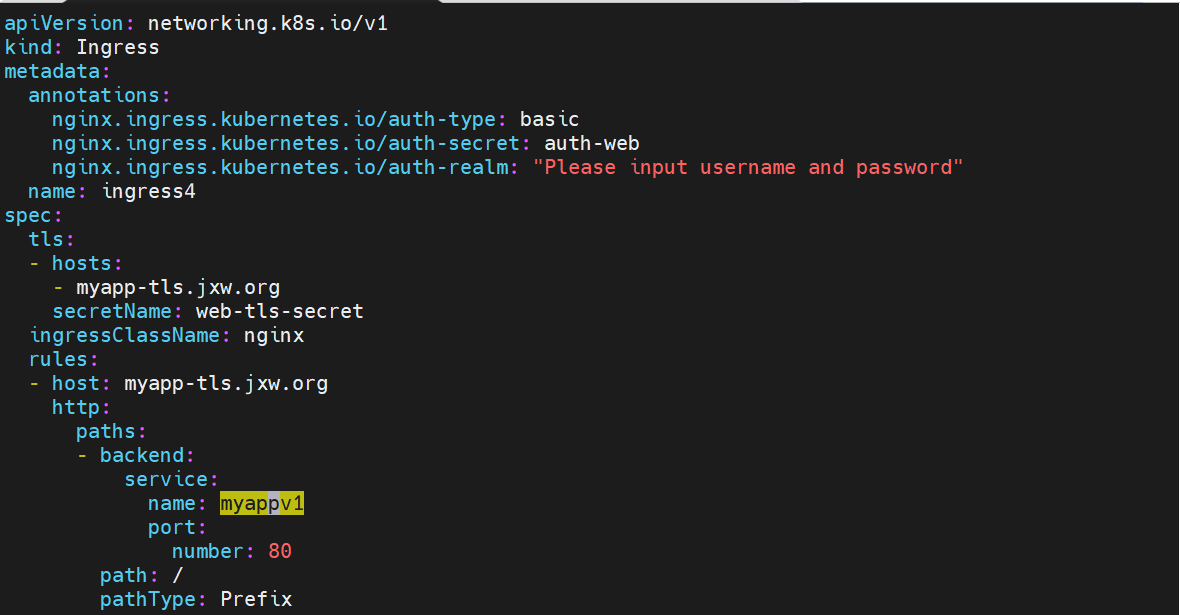
测试
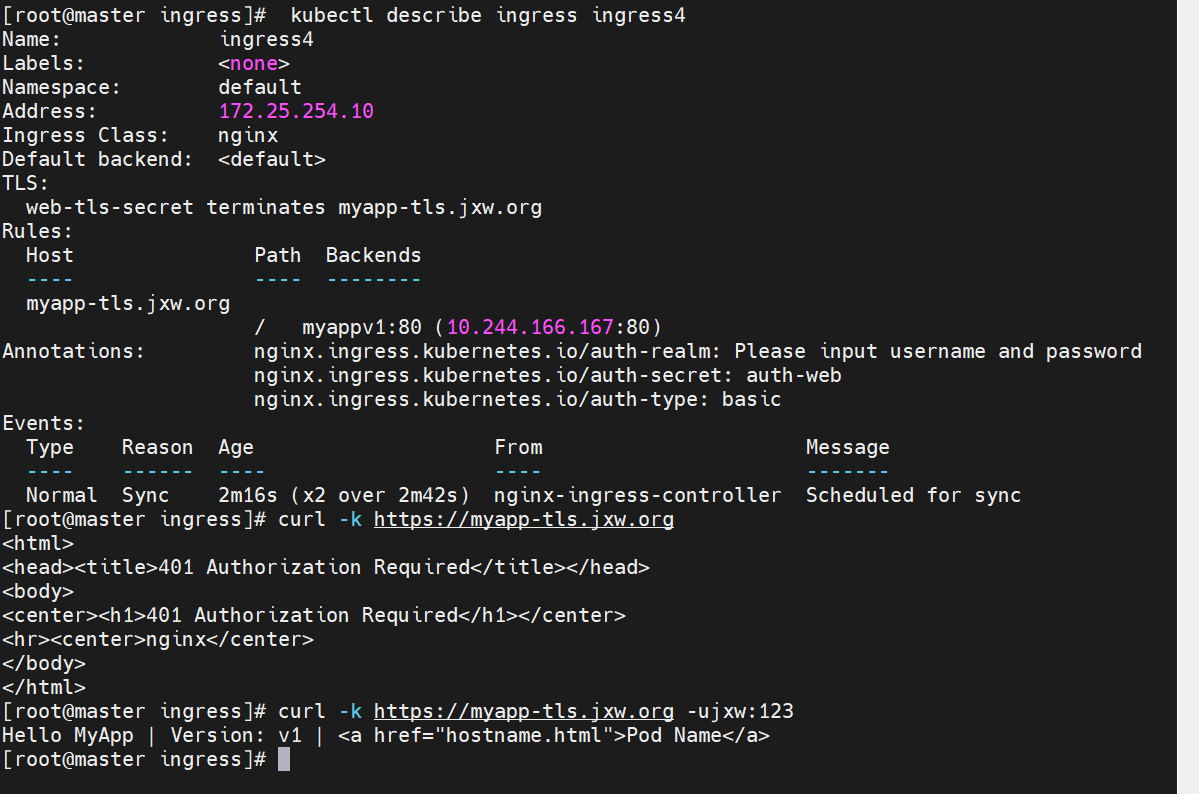
rewrite重定向
#指定默认访问的文件到hostname.html上
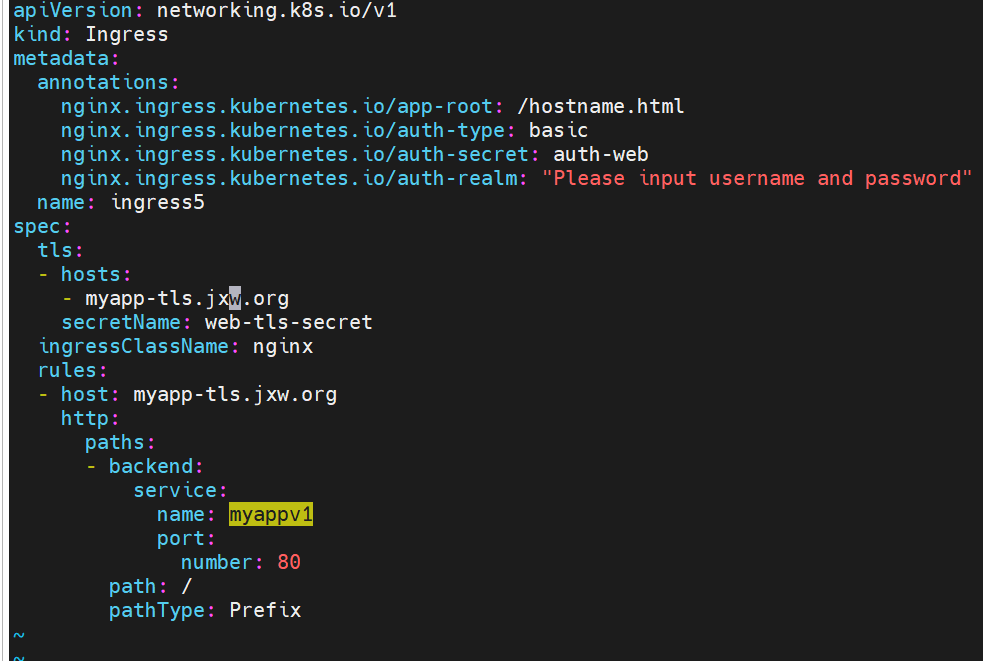
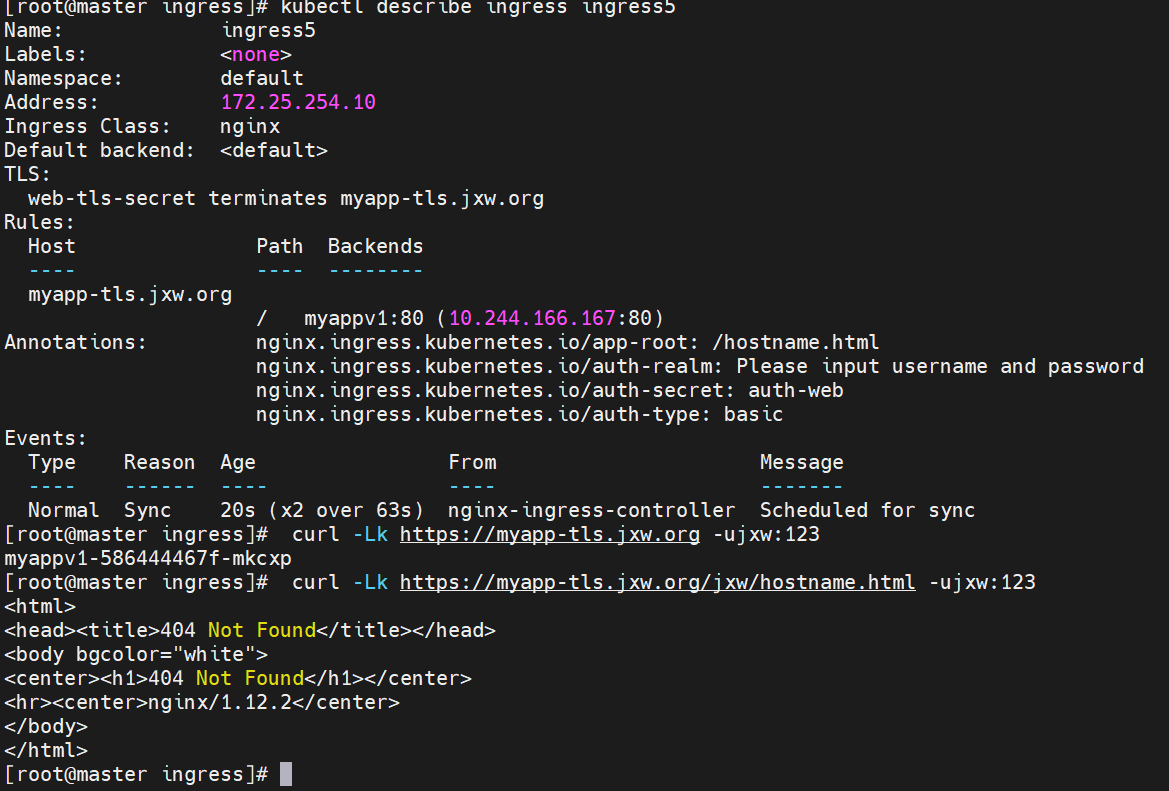
#解决重定向路径问题
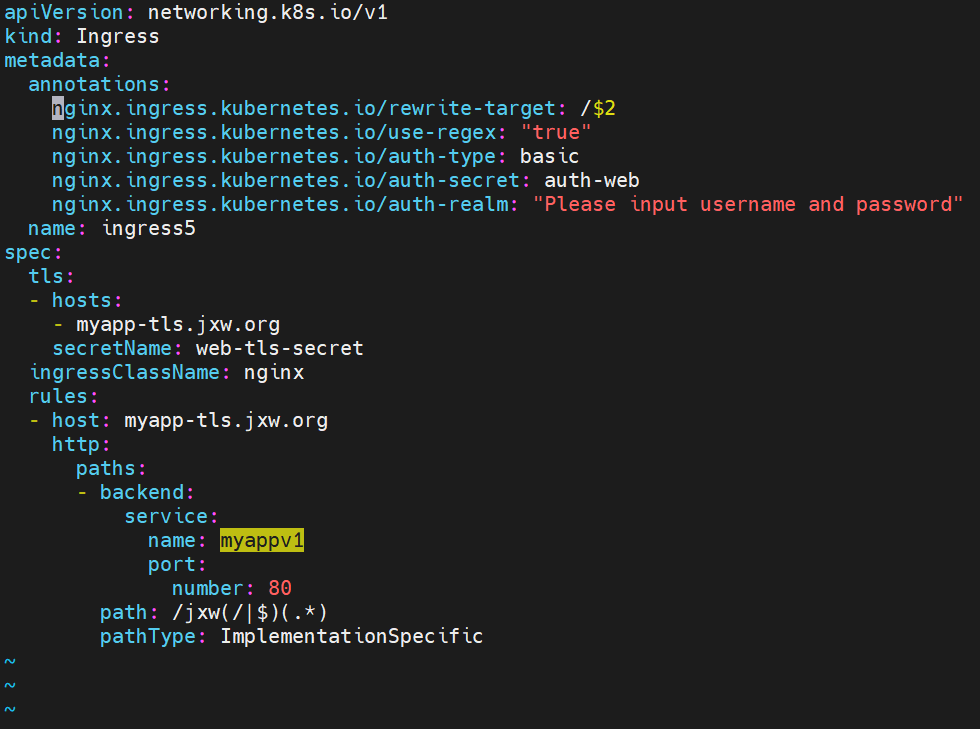
测试
Canary金丝雀发布
金丝雀发布(Canary Release)也称为灰度发布,是一种软件发布策略。
主要目的是在将新版本的软件全面推广到生产环境之前,先在一小部分用户或服务器上进行测试和验证,以降低因新版本引入重大问题而对整个系统造成的影响。
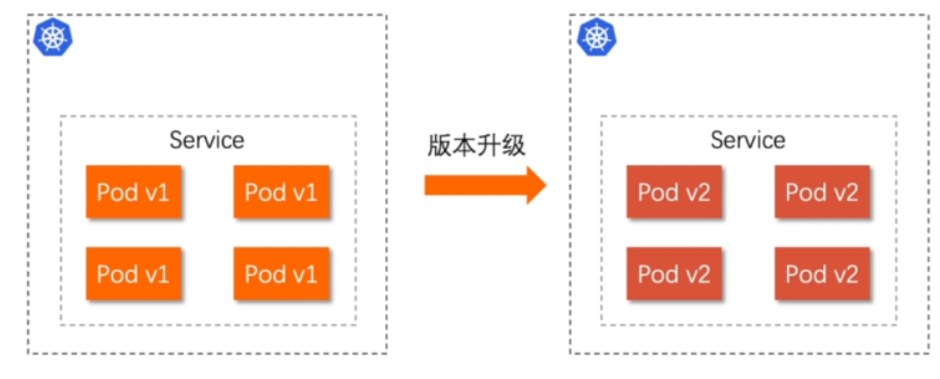
是一种Pod的发布方式。金丝雀发布采取先添加、再删除的方式,保证Pod的总量不低于期望值。并且在更新部分Pod后,暂停更新,当确认新Pod版本运行正常后再进行其他版本的Pod的更新。
Canary发布方式
其中header和weiht中的最多
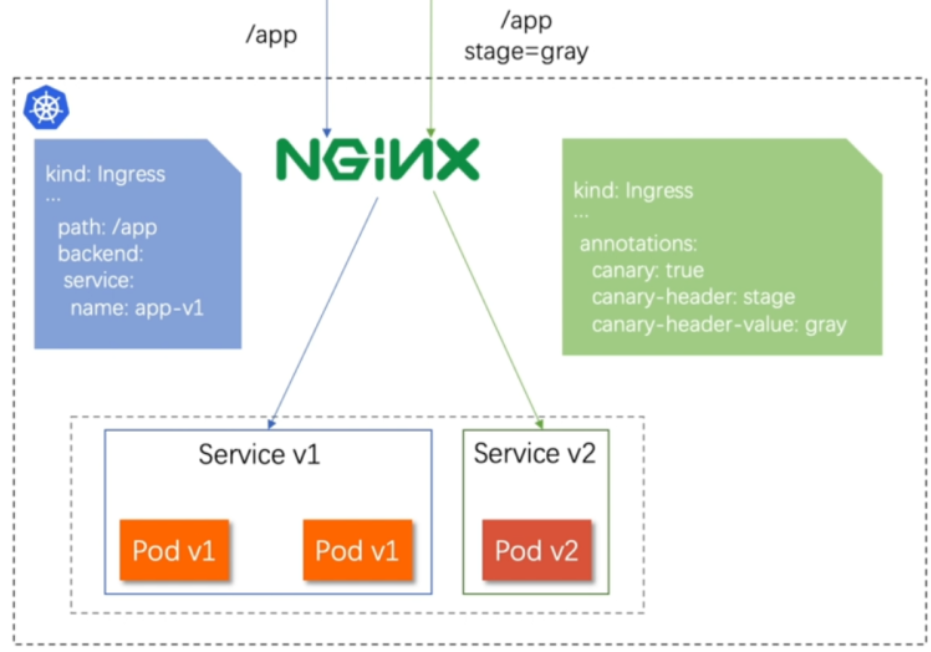
基于header(http包头)灰度
#在服务更新时新老服务交替混合,在新服务出现问题时用户刷新后进入老版本
-
通过Annotaion扩展
-
创建灰度ingress,配置灰度头部key以及value
-
灰度流量验证完毕后,切换正式ingress到新版本
-
之前我们在做升级时可以通过控制器做滚动更新,默认25%利用header可以使升级更为平滑,通过key 和vule 测试新的业务体系是否有问题。
#建立版本1的ingress-old
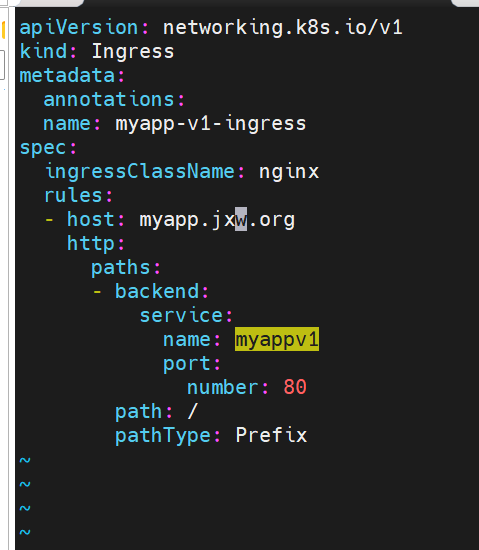
#建立基于header的ingress-new
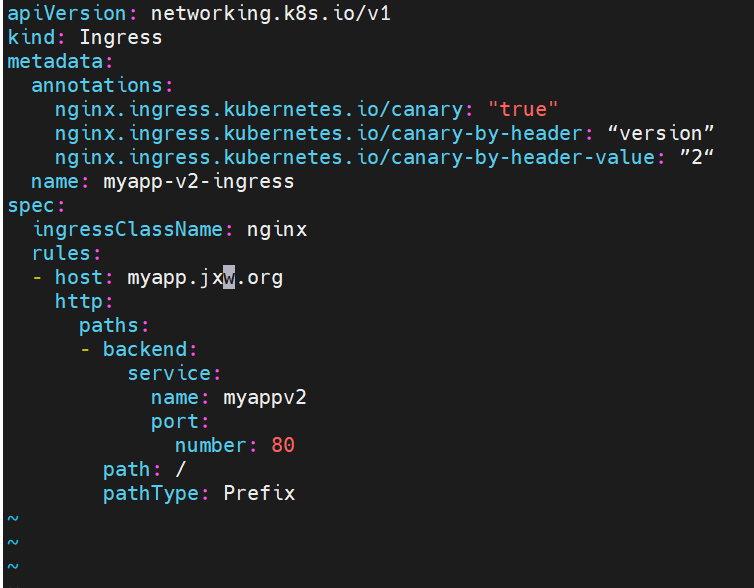
测试

基于权重的灰度发布
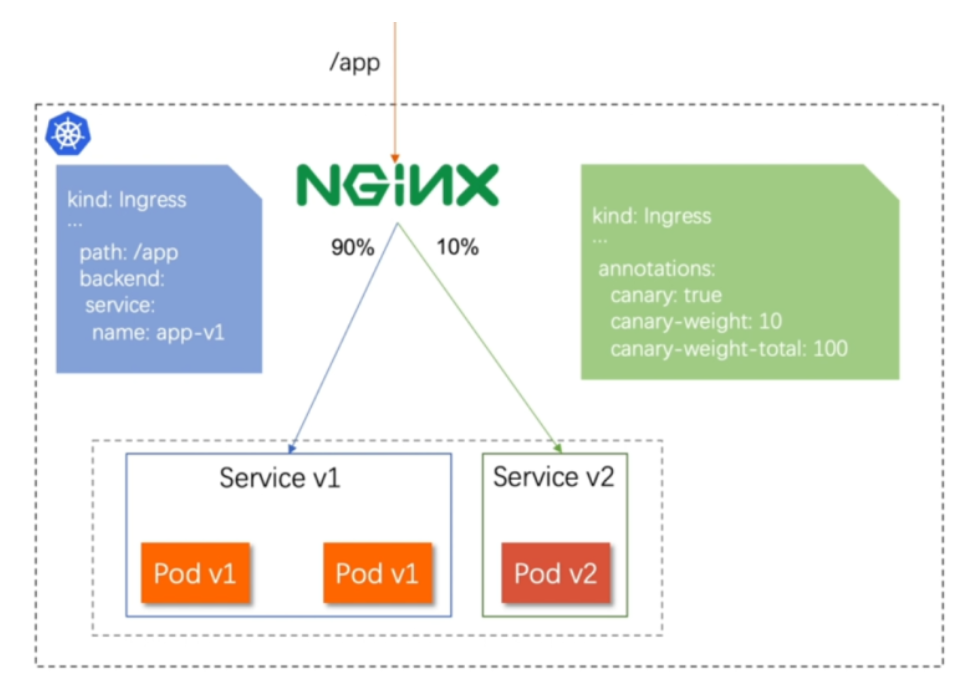
-
通过Annotaion拓展
-
创建灰度ingress,配置灰度权重以及总权重
-
灰度流量验证完毕后,切换正式ingress到新版本
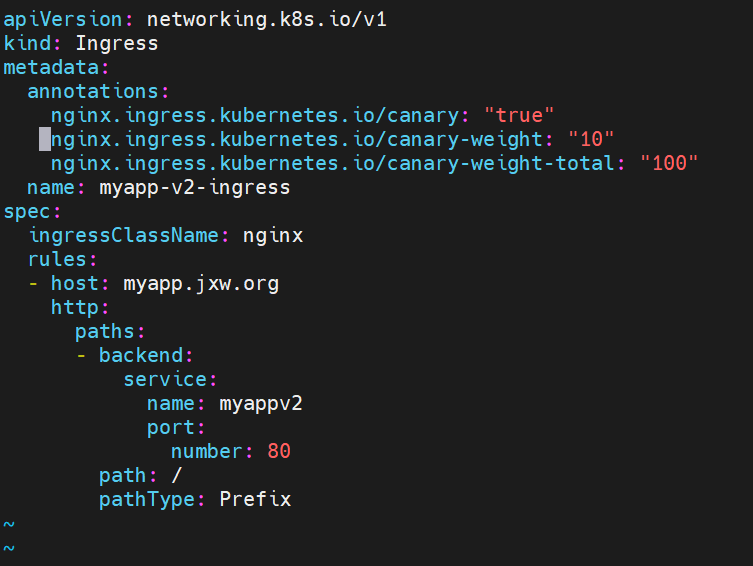
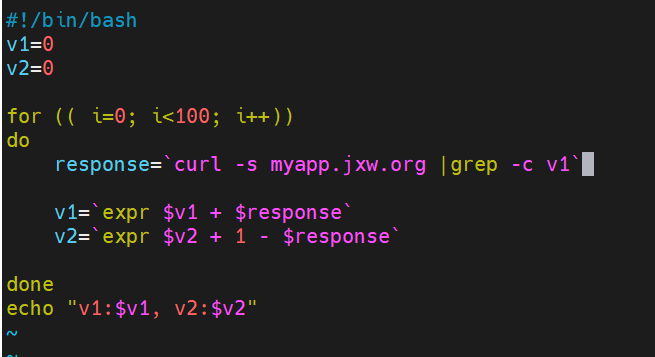
建立测试文件

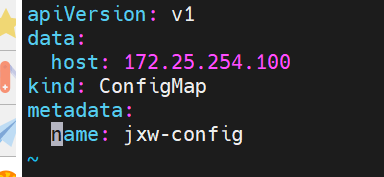
configmap
configmap的功能
-
configMap用于保存配置数据,以键值对形式存储。
-
configMap 资源提供了向 Pod 注入配置数据的方法。
-
镜像和配置文件解耦,以便实现镜像的可移植性和可复用性。
-
etcd限制了文件大小不能超过1M
configmap的使用场景
-
填充环境变量的值
-
设置容器内的命令行参数
-
填充卷的配置文件
configmap创建方式
字面值创建
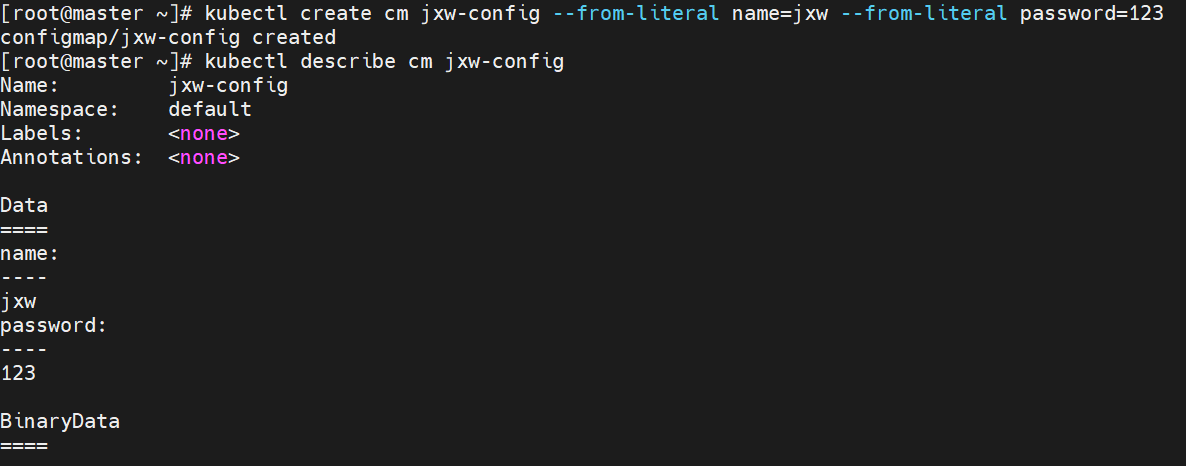
通过文件创建
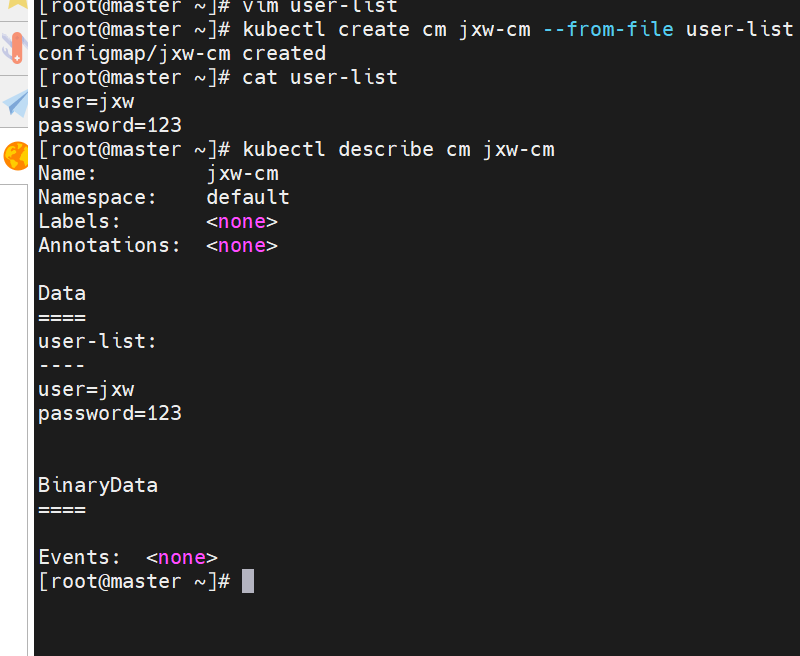
通过目录创建
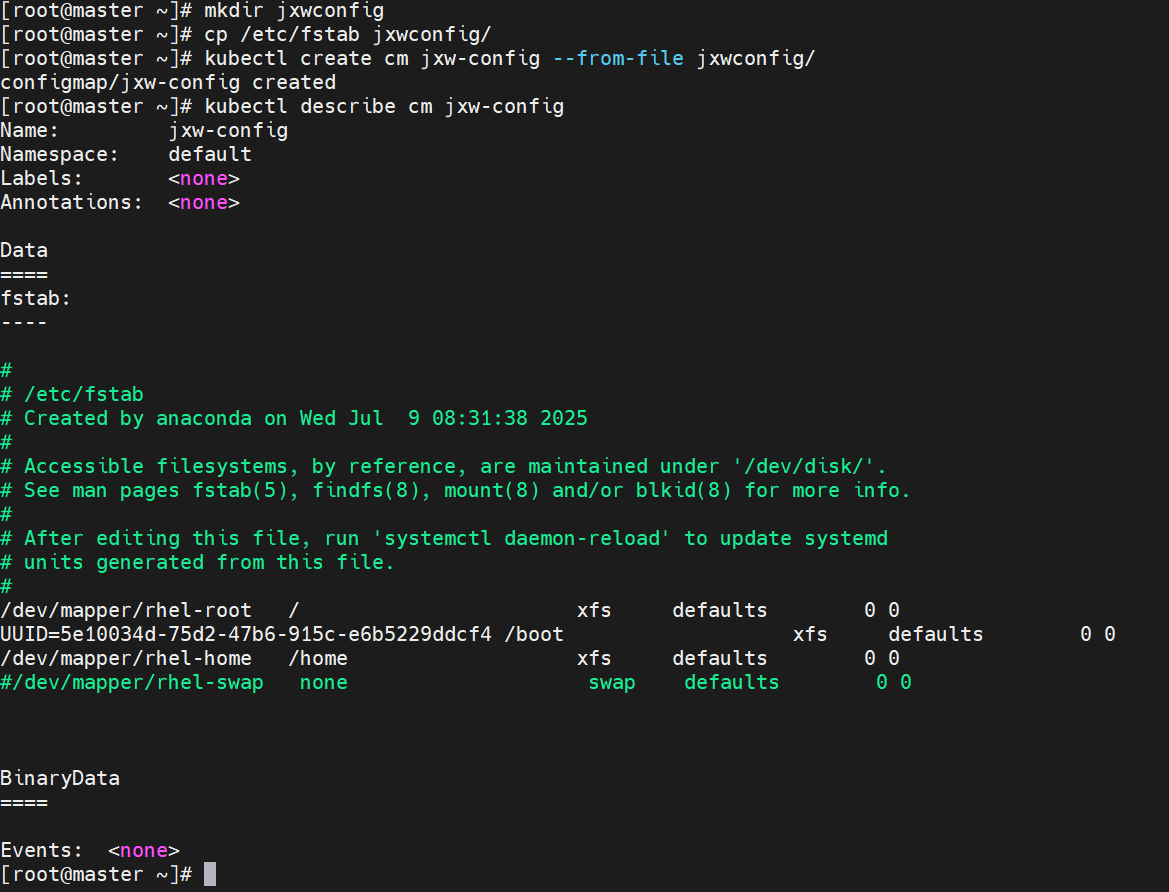
通过yaml文件创建
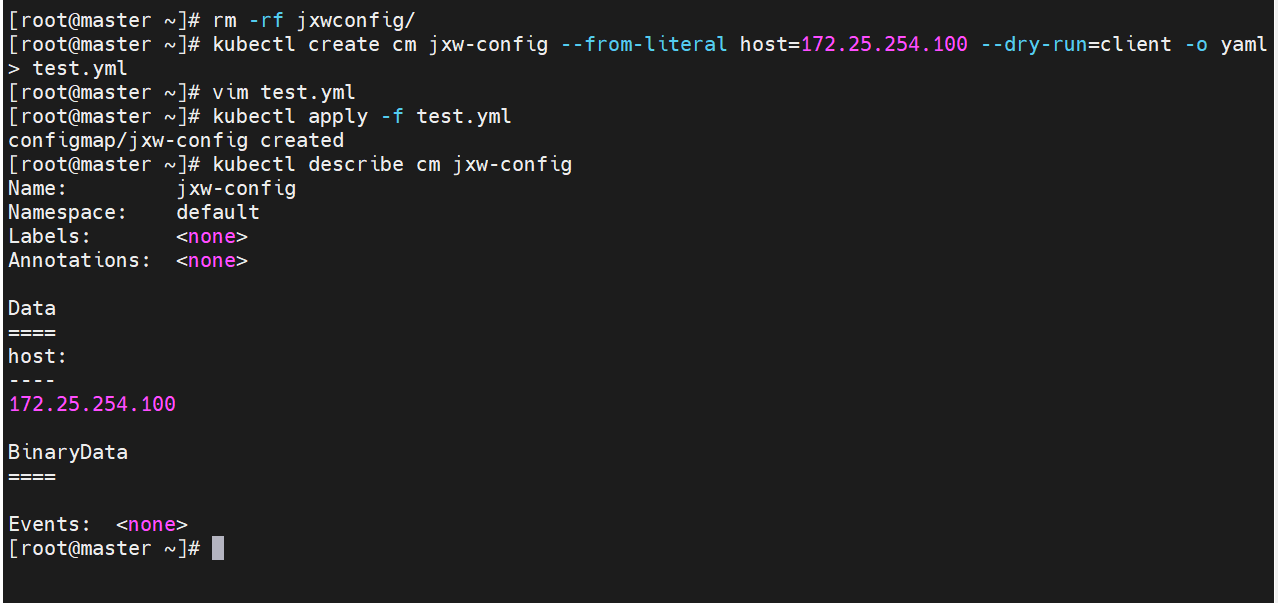
configmap的使用方式
-
通过环境变量的方式直接传递给pod
-
通过pod的 命令行运行方式
-
作为volume的方式挂载到pod内
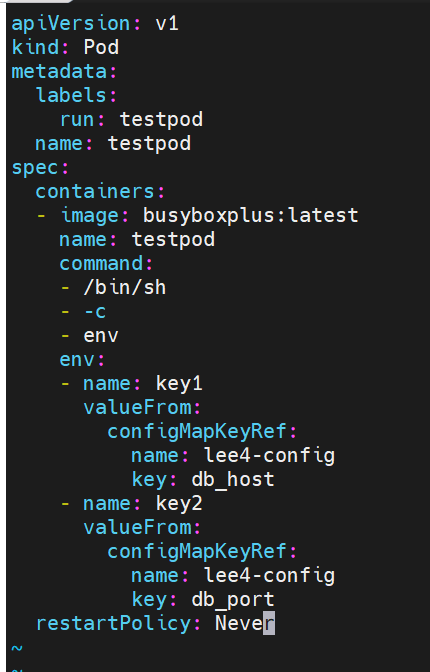
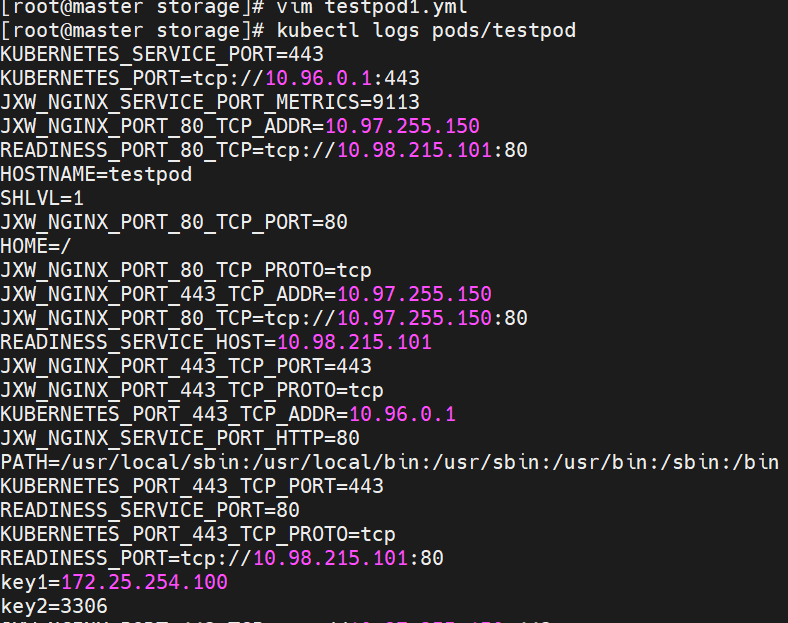
使用configmap填充环境变量
#讲cm中的内容映射为指定变量

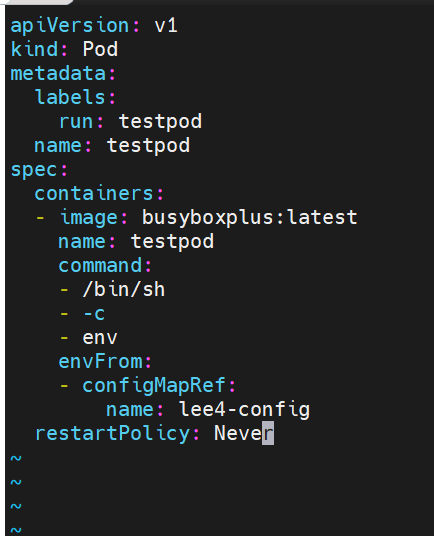
#把cm中的值直接映射为变量
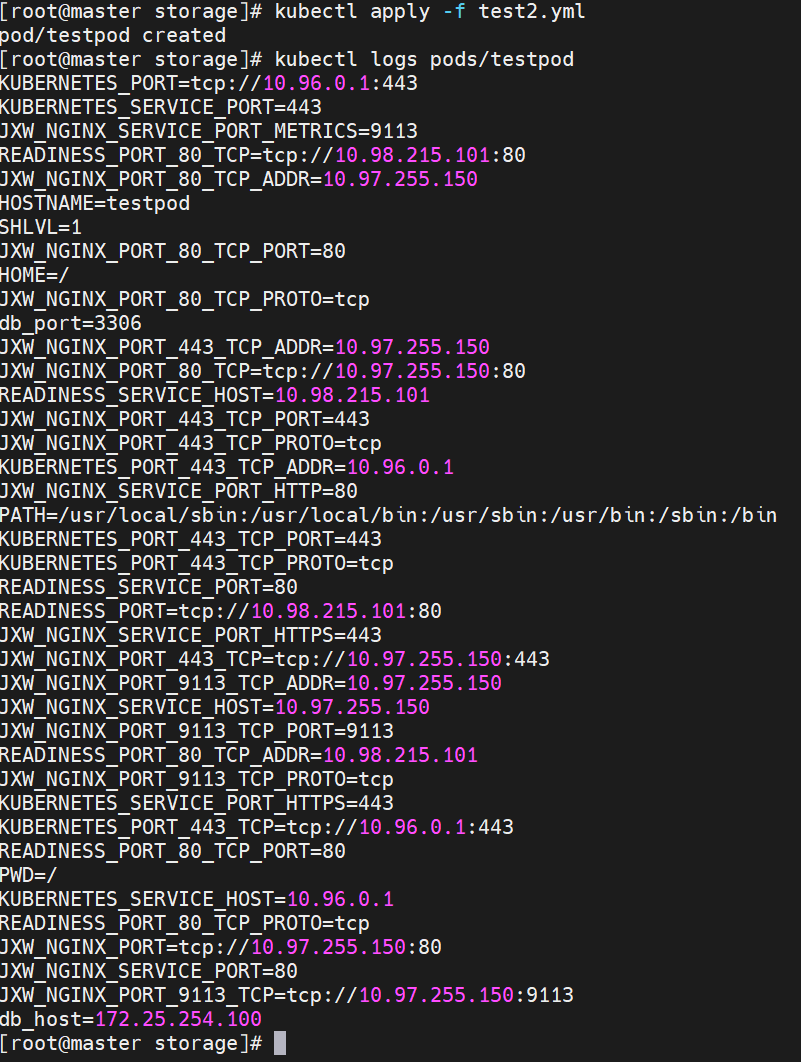
通过数据卷使用configmap
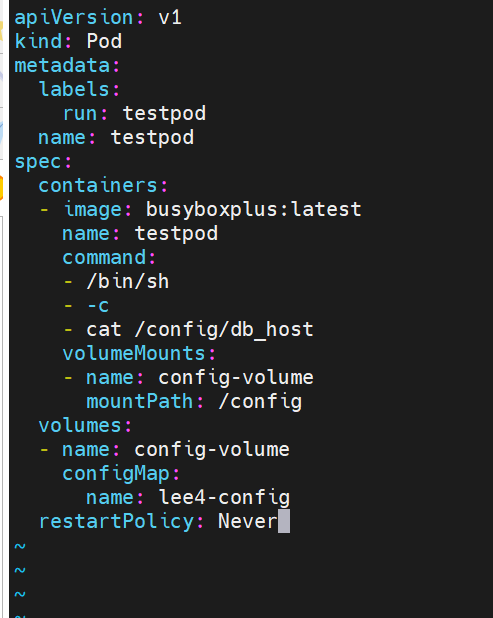
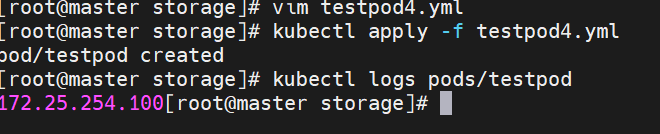
利用configMap填充pod的配置文件
#建立配置文件模板,利用模板生成cm
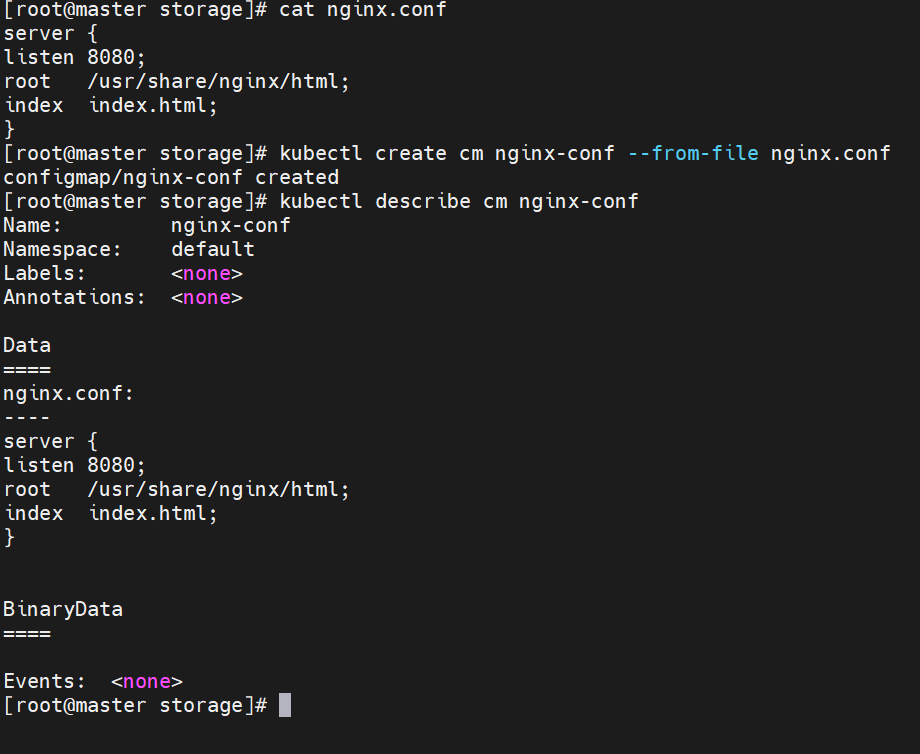
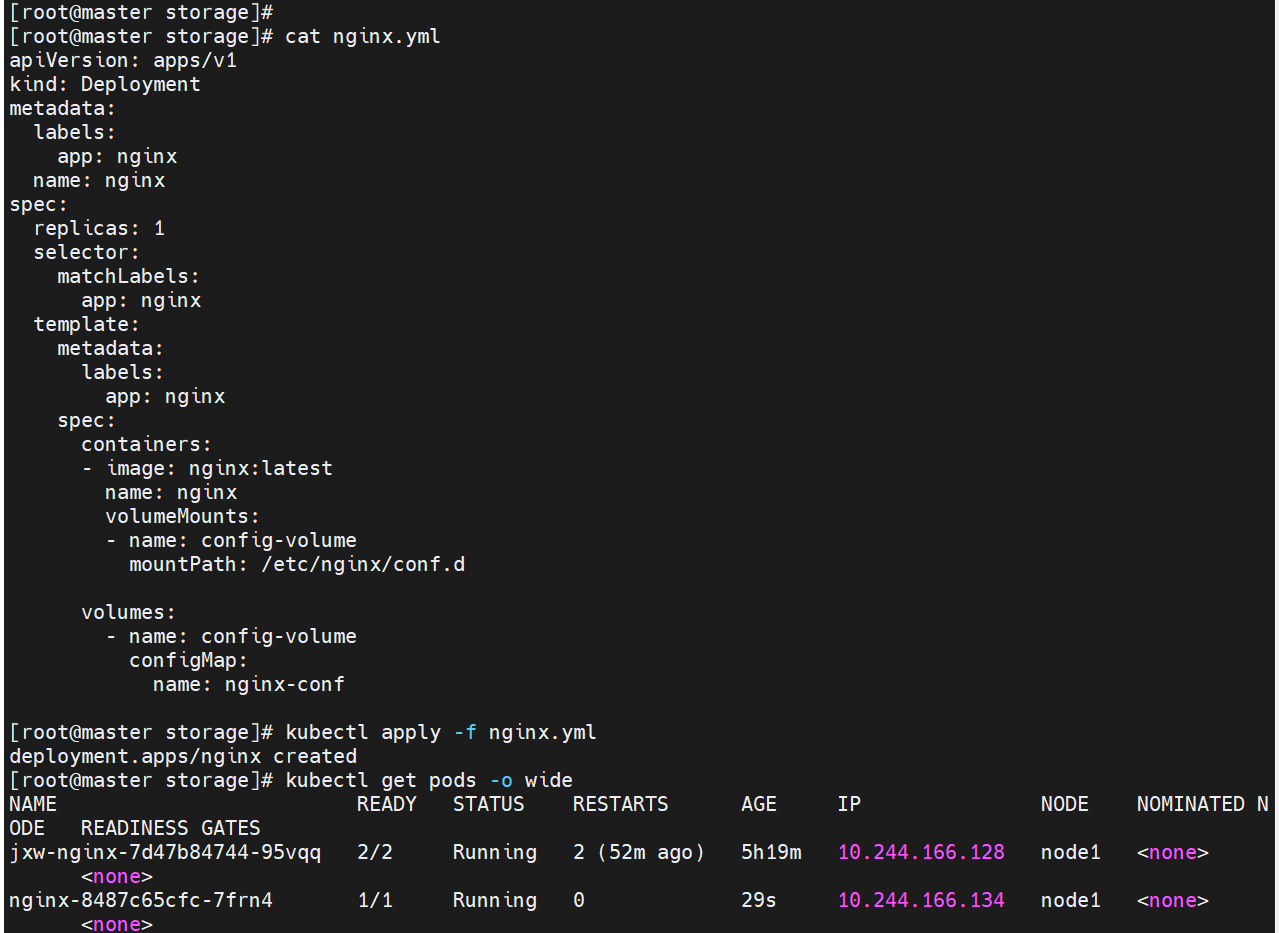
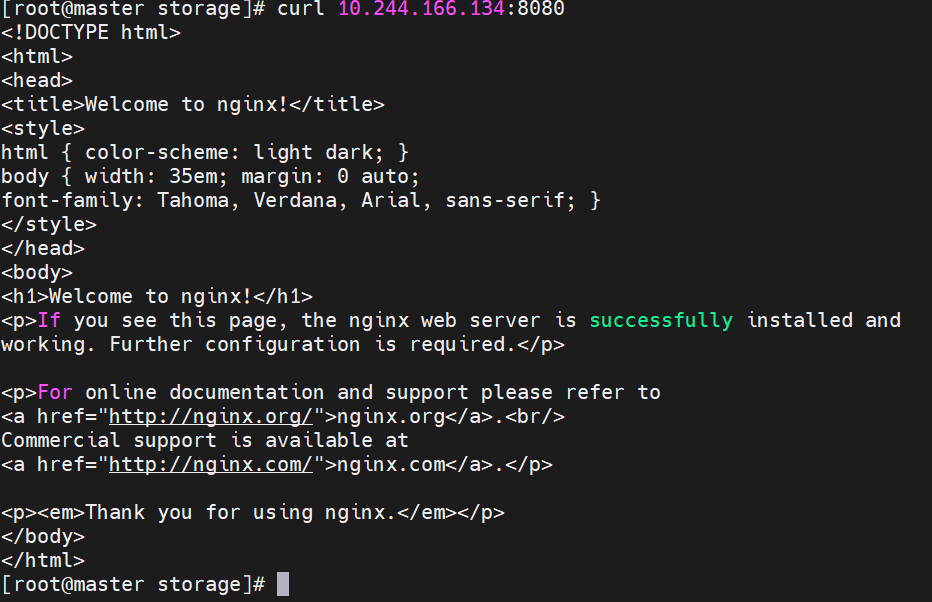
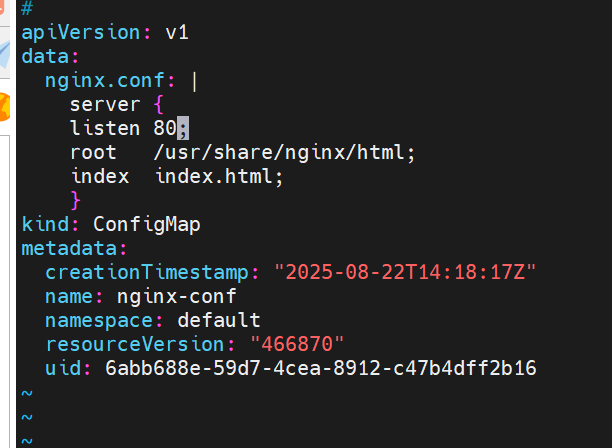
通过热更新cm修改配置


secrets配置管理
secrets的功能介绍
-
Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 ssh key。
-
敏感信息放在 secret 中比放在 Pod 的定义或者容器镜像中来说更加安全和灵活
-
Pod 可以用两种方式使用 secret:
-
作为 volume 中的文件被挂载到 pod 中的一个或者多个容器里。
-
当 kubelet 为 pod 拉取镜像时使用。
-
-
Secret的类型:
-
Service Account:Kubernetes 自动创建包含访问 API 凭据的 secret,并自动修改 pod 以使用此类型的 secret。
-
Opaque:使用base64编码存储信息,可以通过base64 --decode解码获得原始数据,因此安全性弱。
-
kubernetes.io/dockerconfigjson:用于存储docker registry的认证信息
-
secrets的创建
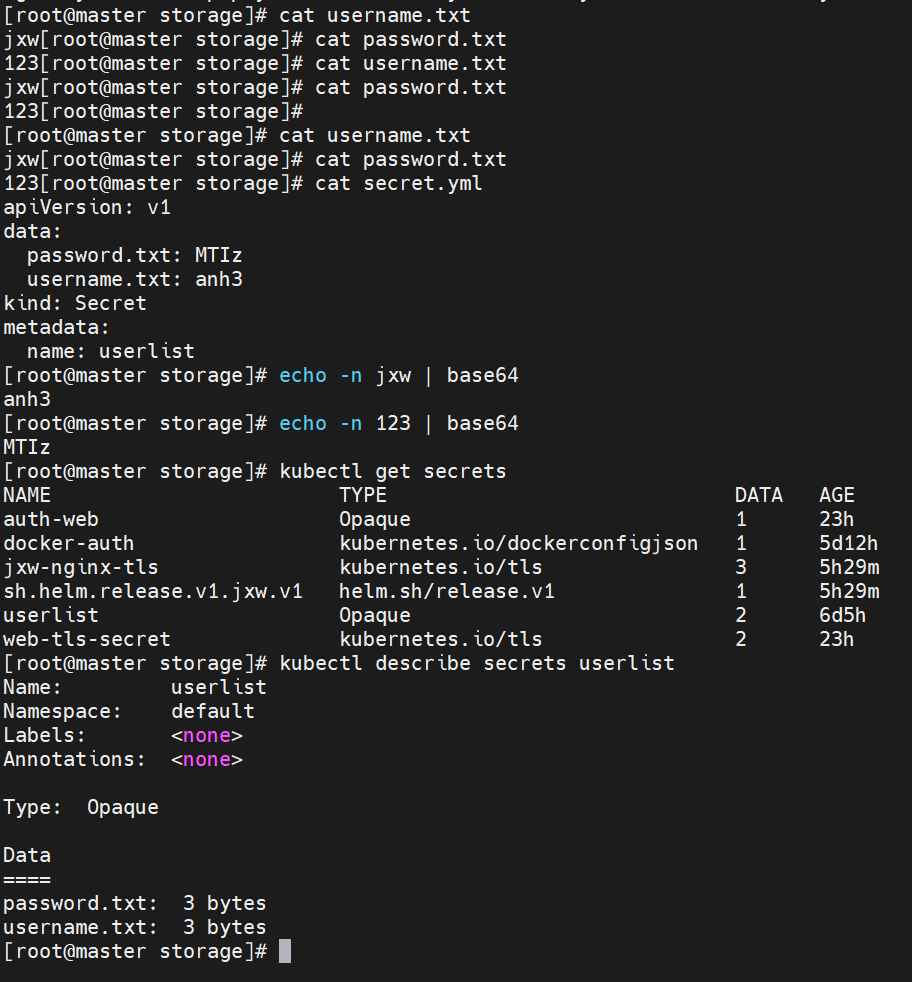
Secret的使用方法
将Secret挂载到Volume中
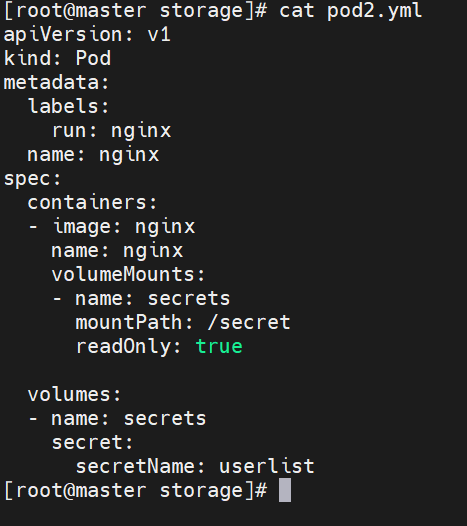
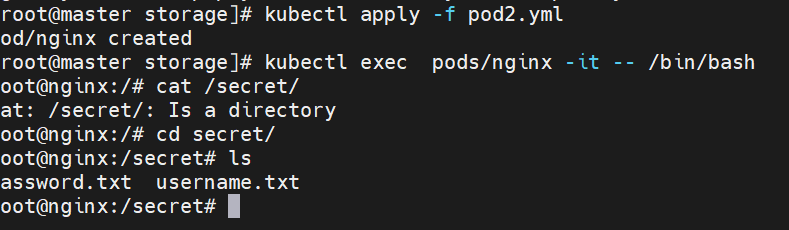
volumes配置管理
-
容器中文件在磁盘上是临时存放的,这给容器中运行的特殊应用程序带来一些问题
-
当容器崩溃时,kubelet将重新启动容器,容器中的文件将会丢失,因为容器会以干净的状态重建。
-
当在一个 Pod 中同时运行多个容器时,常常需要在这些容器之间共享文件。
-
Kubernetes 卷具有明确的生命周期与使用它的 Pod 相同
-
卷比 Pod 中运行的任何容器的存活期都长,在容器重新启动时数据也会得到保留
-
当一个 Pod 不再存在时,卷也将不再存在。
-
Kubernetes 可以支持许多类型的卷,Pod 也能同时使用任意数量的卷。
-
卷不能挂载到其他卷,也不能与其他卷有硬链接。 Pod 中的每个容器必须独立地指定每个卷的挂载位置。
kubernets支持的卷的类型
k8s支持的卷的类型如下:
-
awsElasticBlockStore 、azureDisk、azureFile、cephfs、cinder、configMap、csi
-
downwardAPI、emptyDir、fc (fibre channel)、flexVolume、flocker
-
gcePersistentDisk、gitRepo (deprecated)、glusterfs、hostPath、iscsi、local、
-
nfs、persistentVolumeClaim、projected、portworxVolume、quobyte、rbd
-
scaleIO、secret、storageos、vsphereVolume
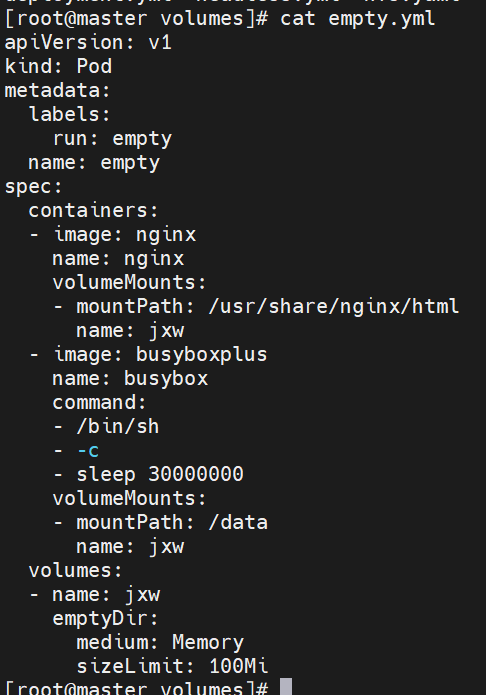
emptyDir卷
功能:
当Pod指定到某个节点上时,首先创建的是一个emptyDir卷,并且只要 Pod 在该节点上运行,卷就一直存在。卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但是这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会永久删除
emptyDir 的使用场景:
-
缓存空间,例如基于磁盘的归并排序。
-
耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
-
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
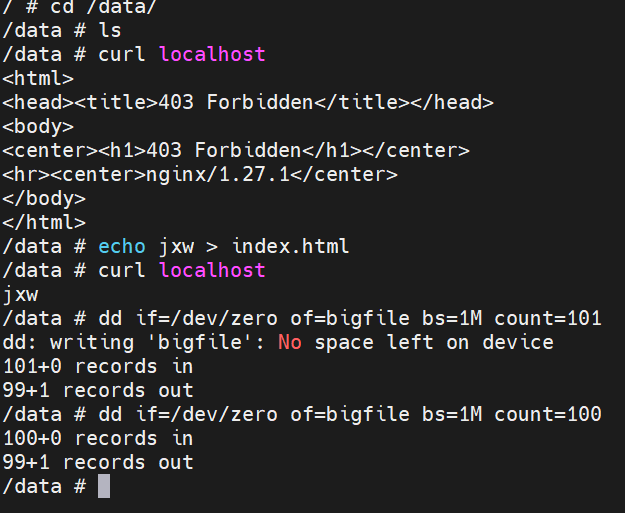
示例:
测试
hostpath卷
功能:
hostPath 卷能将主机节点文件系统上的文件或目录挂载到您的 Pod 中,不会因为pod关闭而被删除
hostPath 的一些用法
-
运行一个需要访问 Docker 引擎内部机制的容器,挂载 /var/lib/docker 路径。
-
在容器中运行 cAdvisor(监控) 时,以 hostPath 方式挂载 /sys。
-
允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在
hostPath的安全隐患
-
具有相同配置(例如从 podTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为。
-
当 Kubernetes 按照计划添加资源感知的调度时,这类调度机制将无法考虑由 hostPath 使用的资源。
-
基础主机上创建的文件或目录只能由 root 用户写入。您需要在 特权容器 中以 root 身份运行进程,或者修改主机上的文件权限以便容器能够写入 hostPath 卷。
示例
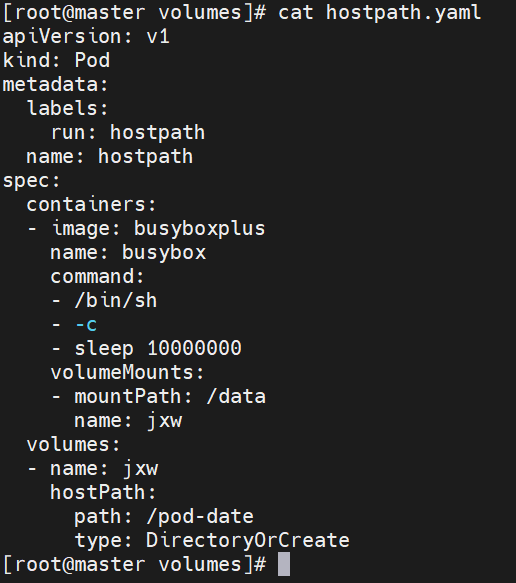
nfs卷
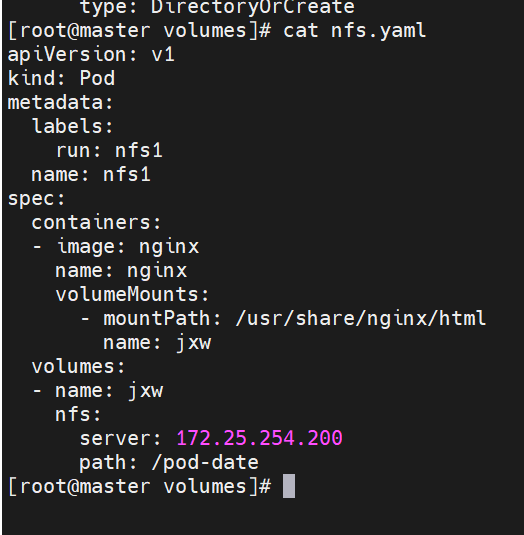
NFS 卷允许将一个现有的 NFS 服务器上的目录挂载到 Kubernetes 中的 Pod 中。这对于在多个 Pod 之间共享数据或持久化存储数据非常有用
例如,如果有多个容器需要访问相同的数据集,或者需要将容器中的数据持久保存到外部存储,NFS 卷可以提供一种方便的解决方案
部署一台nfs共享主机并在所有k8s节点中安装nfs-utils
#部署nfs主机
root@reg \~# dnf install nfs-utils -y
root@reg \~# systemctl enable --now nfs-server.service
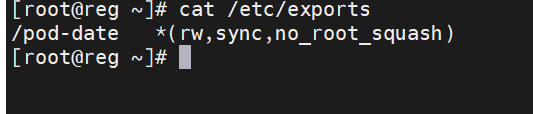
root@reg \~# exportfs -rv
exporting *:/nfsdata
root@reg \~# showmount -e
Export list for reg.timinglee.org:
/nfsdata *
#在k8s所有节点中安装nfs-utils
root@k8s-master \& node1 \& node2 \~# dnf install nfs-utils -y
部署nfs卷
PersistentVolume持久卷
静态持久卷pv与静态持久卷声明pvc
PersistentVolume(持久卷,简称PV)
-
pv是集群内由管理员提供的网络存储的一部分。
-
PV也是集群中的一种资源。是一种volume插件,
-
但是它的生命周期却是和使用它的Pod相互独立的。
-
PV这个API对象,捕获了诸如NFS、ISCSI、或其他云存储系统的实现细节
-
pv有两种提供方式:静态和动态
-
静态PV:集群管理员创建多个PV,它们携带着真实存储的详细信息,它们存在于Kubernetes API中,并可用于存储使用
-
动态PV:当管理员创建的静态PV都不匹配用户的PVC时,集群可能会尝试专门地供给volume给PVC。这种供给基于StorageClass
-
PersistentVolumeClaim(持久卷声明,简称PVC)
-
是用户的一种存储请求
-
它和Pod类似,Pod消耗Node资源,而PVC消耗PV资源
-
Pod能够请求特定的资源(如CPU和内存)。PVC能够请求指定的大小和访问的模式持久卷配置
-
PVC与PV的绑定是一对一的映射。没找到匹配的PV,那么PVC会无限期得处于unbound未绑定状态
volumes访问模式
-
ReadWriteOnce -- 该volume只能被单个节点以读写的方式映射
-
ReadOnlyMany -- 该volume可以被多个节点以只读方式映射
-
ReadWriteMany -- 该volume可以被多个节点以读写的方式映射
-
在命令行中,访问模式可以简写为:
- RWO - ReadWriteOnce
-
ROX - ReadOnlyMany
-
RWX -- ReadWriteMany
volumes回收策略
-
Retain:保留,需要手动回收
-
Recycle:回收,自动删除卷中数据(在当前版本中已经废弃)
-
Delete:删除,相关联的存储资产,如AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷都会被删除
注意:
!NOTE
只有NFS和HostPath支持回收利用
AWS EBS,GCE PD,Azure Disk,or OpenStack Cinder卷支持删除操作。
volumes状态说明
-
Available 卷是一个空闲资源,尚未绑定到任何申领
-
Bound 该卷已经绑定到某申领
-
Released 所绑定的申领已被删除,但是关联存储资源尚未被集群回收
-
Failed 卷的自动回收操作失败
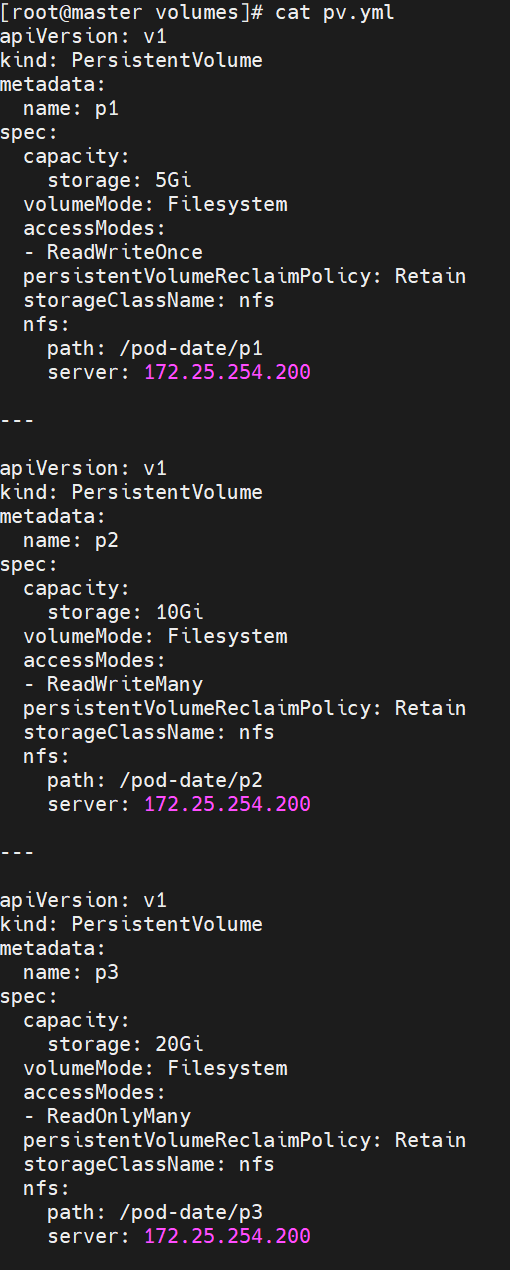
静态pv实例:
bash
[root@master pvc]# kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS VOLUMEATTRIBUTESCLASS REASON AGE
pv1 5Gi RWO Retain Available nfs <unset> 4m50s
pv2 15Gi RWX Retain Available nfs <unset> 4m50s
pv3 25Gi ROX Retain Available nfs <unset> 4m50s#建立pvc,pvc是pv使用的申请,需要保证和pod在一个namesapce中
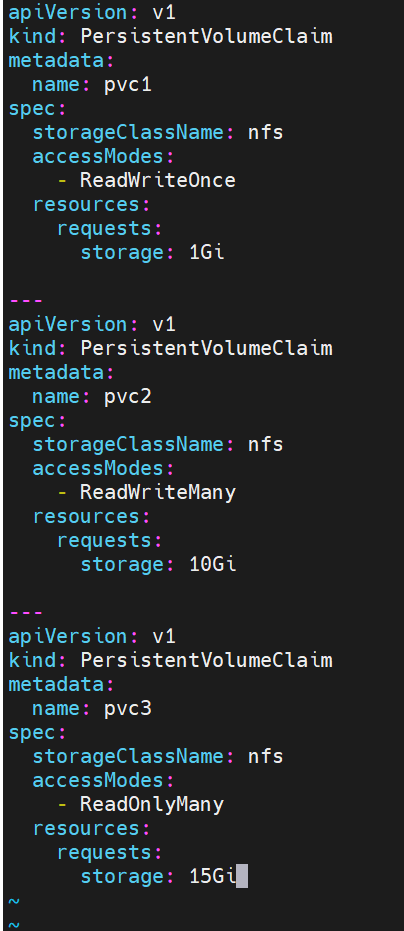
bash
[root@master pvc]# kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
pvc1 Bound pv1 5Gi RWO nfs <unset> 5s
pvc2 Bound pv2 15Gi RWX nfs <unset> 4s
pvc3 Bound pv3 25Gi ROX nfs <unset> 4s
#在其他namespace中无法应用
[root@k8s-master pvc]# kubectl -n kube-system get pvc
No resources found in kube-system namespace.存储类storageclass
官网: https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
StorageClass说明
-
StorageClass提供了一种描述存储类(class)的方法,不同的class可能会映射到不同的服务质量等级和备份策略或其他策略等。
-
每个 StorageClass 都包含 provisioner、parameters 和 reclaimPolicy 字段, 这些字段会在StorageClass需要动态分配 PersistentVolume 时会使用到
StorageClass的属性
属性说明:存储类 | Kubernetes
Provisioner(存储分配器):用来决定使用哪个卷插件分配 PV,该字段必须指定。可以指定内部分配器,也可以指定外部分配器。外部分配器的代码地址为: kubernetes-incubator/external-storage,其中包括NFS和Ceph等。
Reclaim Policy(回收策略):通过reclaimPolicy字段指定创建的Persistent Volume的回收策略,回收策略包括:Delete 或者 Retain,没有指定默认为Delete。
4.3 存储分配器NFS Client Provisioner
源码地址:https://github.com/kubernetes-sigs/nfs-subdir-external-provisioner
-
NFS Client Provisioner是一个automatic provisioner,使用NFS作为存储,自动创建PV和对应的PVC,本身不提供NFS存储,需要外部先有一套NFS存储服务。
-
PV以 {namespace}-{pvcName}-${pvName}的命名格式提供(在NFS服务器上)
-
PV回收的时候以 archieved-{namespace}-{pvcName}-${pvName} 的命名格式(在NFS服务器上)
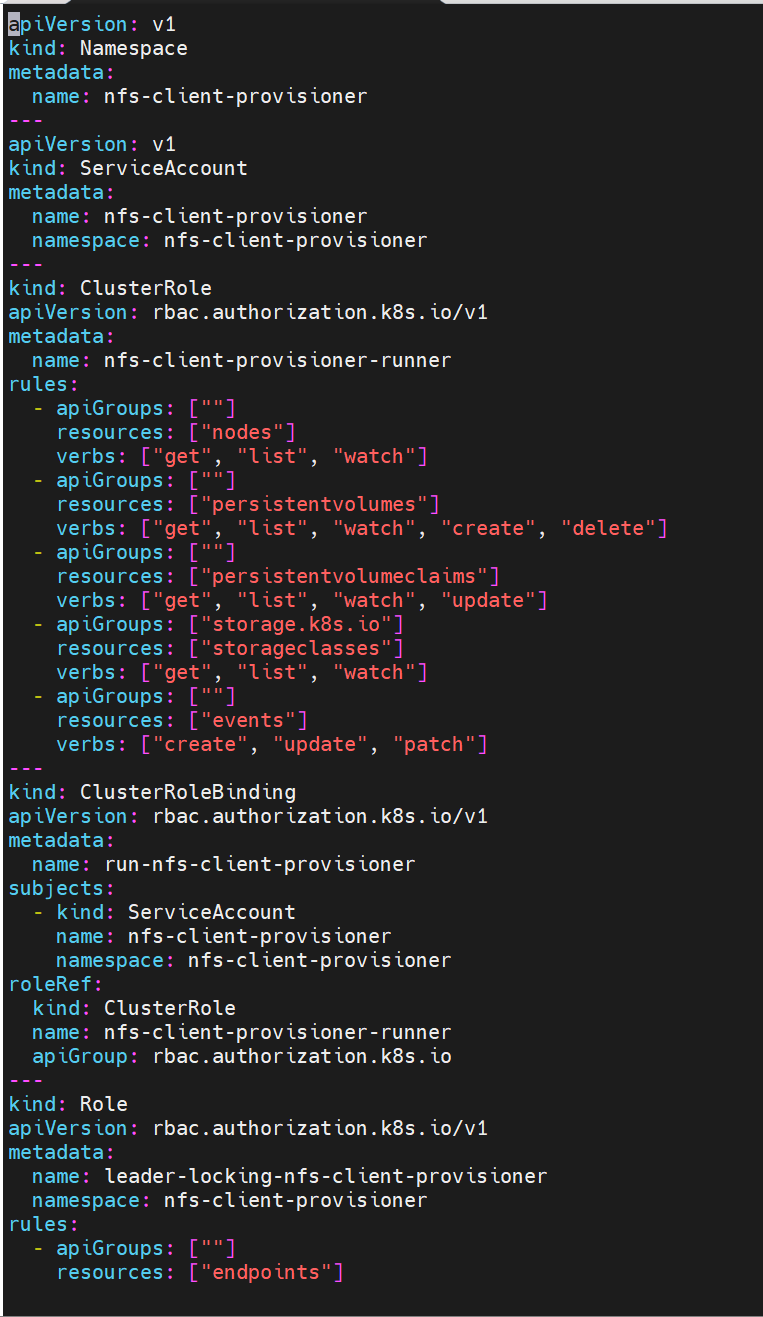
部署NFS Client Provisioner
创建sa并授权
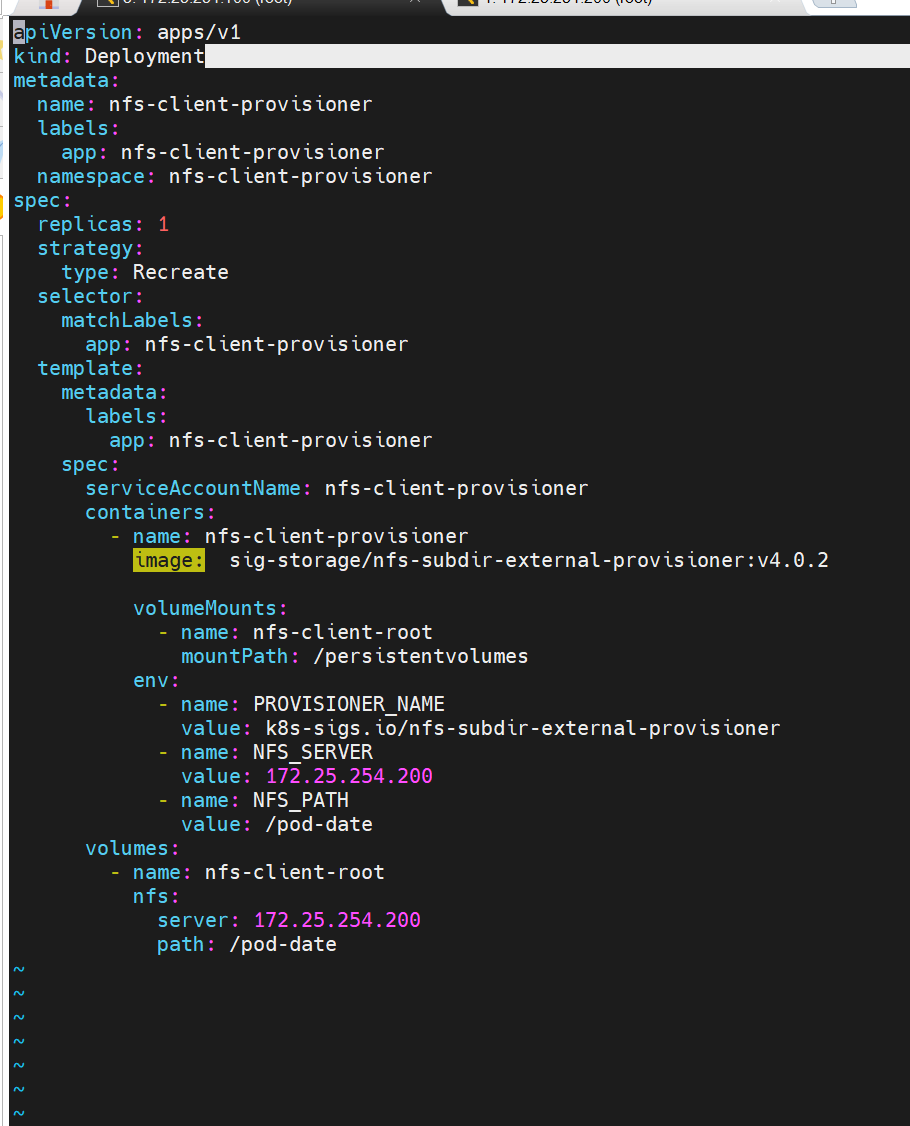
部署应用
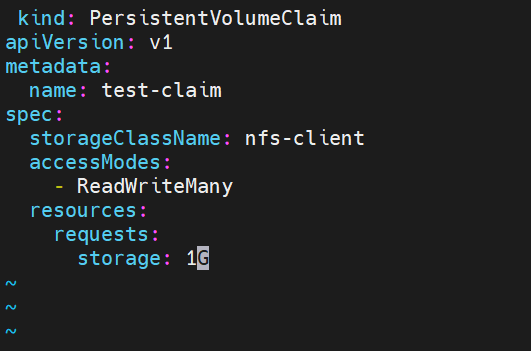
创建pvc
statefulset控制器
5.1 功能特性
-
Statefulset是为了管理有状态服务的问提设计的
-
StatefulSet将应用状态抽象成了两种情况:
-
拓扑状态:应用实例必须按照某种顺序启动。新创建的Pod必须和原来Pod的网络标识一样
-
存储状态:应用的多个实例分别绑定了不同存储数据。
-
StatefulSet给所有的Pod进行了编号,编号规则是:(statefulset名称)-(序号),从0开始。
-
Pod被删除后重建,重建Pod的网络标识也不会改变,Pod的拓扑状态按照Pod的"名字+编号"的方式固定下来,并且为每个Pod提供了一个固定且唯一的访问入口,Pod对应的DNS记录。
5.2 StatefulSet的组成部分
-
Headless Service:用来定义pod网络标识,生成可解析的DNS记录
-
volumeClaimTemplates:创建pvc,指定pvc名称大小,自动创建pvc且pvc由存储类供应。
-
StatefulSet:管理pod的
k8s网络通信
k8s通信整体架构
-
k8s通过CNI接口接入其他插件来实现网络通讯。目前比较流行的插件有flannel,calico等
-
CNI插件存放位置:# cat /etc/cni/net.d/10-flannel.conflist
-
插件使用的解决方案如下
-
虚拟网桥,虚拟网卡,多个容器共用一个虚拟网卡进行通信。
-
多路复用:MacVLAN,多个容器共用一个物理网卡进行通信。
-
硬件交换:SR-LOV,一个物理网卡可以虚拟出多个接口,这个性能最好。
-
-
容器间通信:
-
同一个pod内的多个容器间的通信,通过lo即可实现pod之间的通信
-
同一节点的pod之间通过cni网桥转发数据包。
-
不同节点的pod之间的通信需要网络插件支持
-
-
pod和service通信: 通过iptables或ipvs实现通信,ipvs取代不了iptables,因为ipvs只能做负载均衡,而做不了nat转换
-
pod和外网通信:iptables的MASQUERADE
-
Service与集群外部客户端的通信;(ingress、nodeport、loadbalancer)
flannel跨主机通信原理
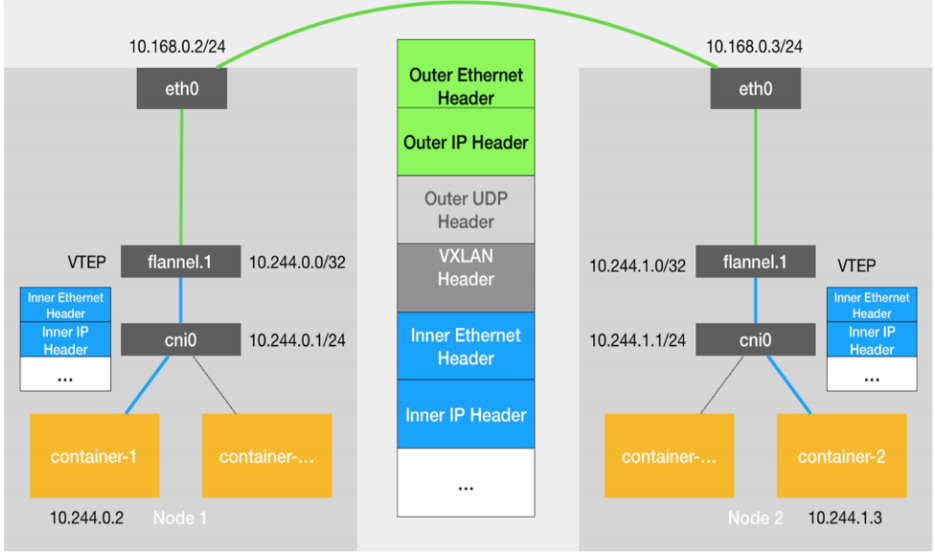
-
当容器发送IP包,通过veth pair 发往cni网桥,再路由到本机的flannel.1设备进行处理。
-
VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
-
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
-
Linux会在内部数据帧前面,加上一个VXLAN头,VXLAN头里有一个重要的标志叫VNI,它是VTEP识别某个数据桢是不是应该归自己处理的重要标识。
-
flannel.1设备只知道另一端flannel.1设备的MAC地址,却不知道对应的宿主机地址是什么。在linux内核里面,网络设备进行转发的依据,来自FDB的转发数据库,这个flannel.1网桥对应的FDB信息,是由flanneld进程维护的。
-
linux内核在IP包前面再加上二层数据帧头,把目标节点的MAC地址填进去,MAC地址从宿主机的ARP表获取。
-
此时flannel.1设备就可以把这个数据帧从eth0发出去,再经过宿主机网络来到目标节点的eth0设备。目标主机内核网络栈会发现这个数据帧有VXLAN Header,并且VNI为1,Linux内核会对它进行拆包,拿到内部数据帧,根据VNI的值,交给本机flannel.1设备处理,flannel.1拆包,根据路由表发往cni网桥,最后到达目标容器。
flannel支持的后端模式
更改flannel的默认模式
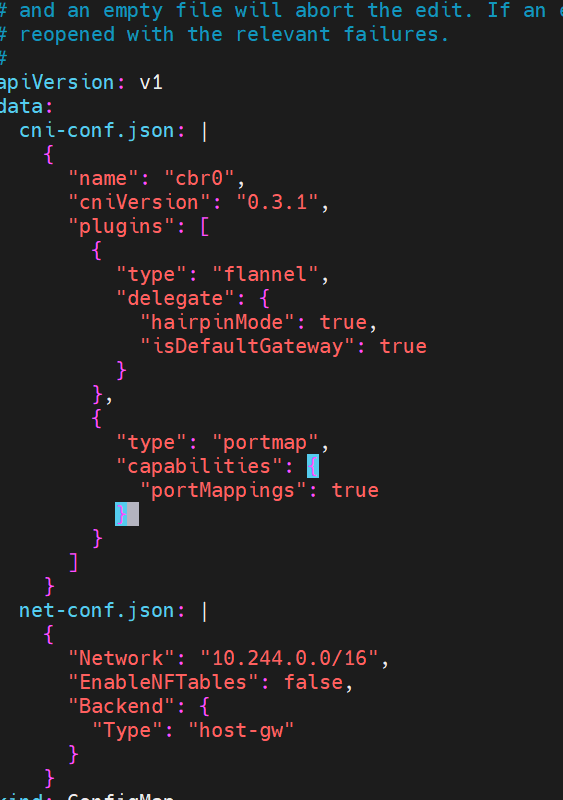
#重启pod
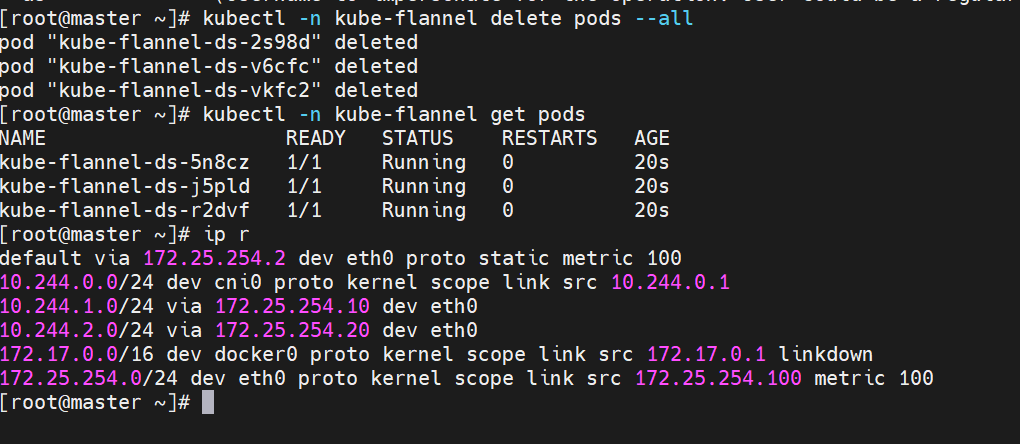
calico网络插件
官网:
Installing on on-premises deployments | Calico Documentation
calico简介:
-
纯三层的转发,中间没有任何的NAT和overlay,转发效率最好。
-
Calico 仅依赖三层路由可达。Calico 较少的依赖性使它能适配所有 VM、Container、白盒或者混合环境场景。
calico网络架构
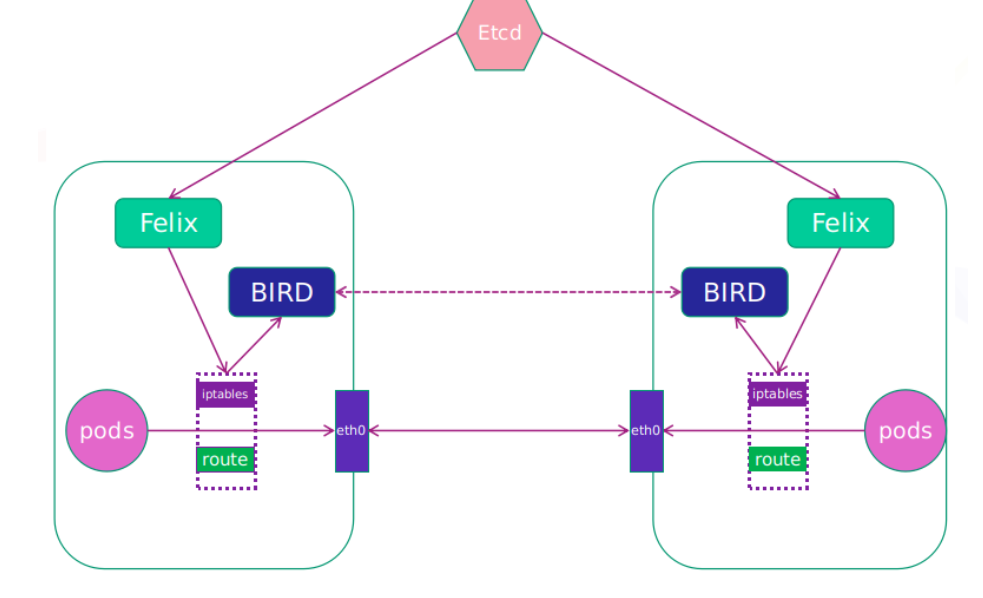
-
Felix:监听ECTD中心的存储获取事件,用户创建pod后,Felix负责将其网卡、IP、MAC都设置好,然后在内核的路由表里面写一条,注明这个IP应该到这张网卡。同样如果用户制定了隔离策略,Felix同样会将该策略创建到ACL中,以实现隔离。
-
BIRD:一个标准的路由程序,它会从内核里面获取哪一些IP的路由发生了变化,然后通过标准BGP的路由协议扩散到整个其他的宿主机上,让外界都知道这个IP在这里,路由的时候到这里
部署calico
删除flannel插件,删除所有节点上flannel配置文件,避免冲突,下载镜像上传至仓库:
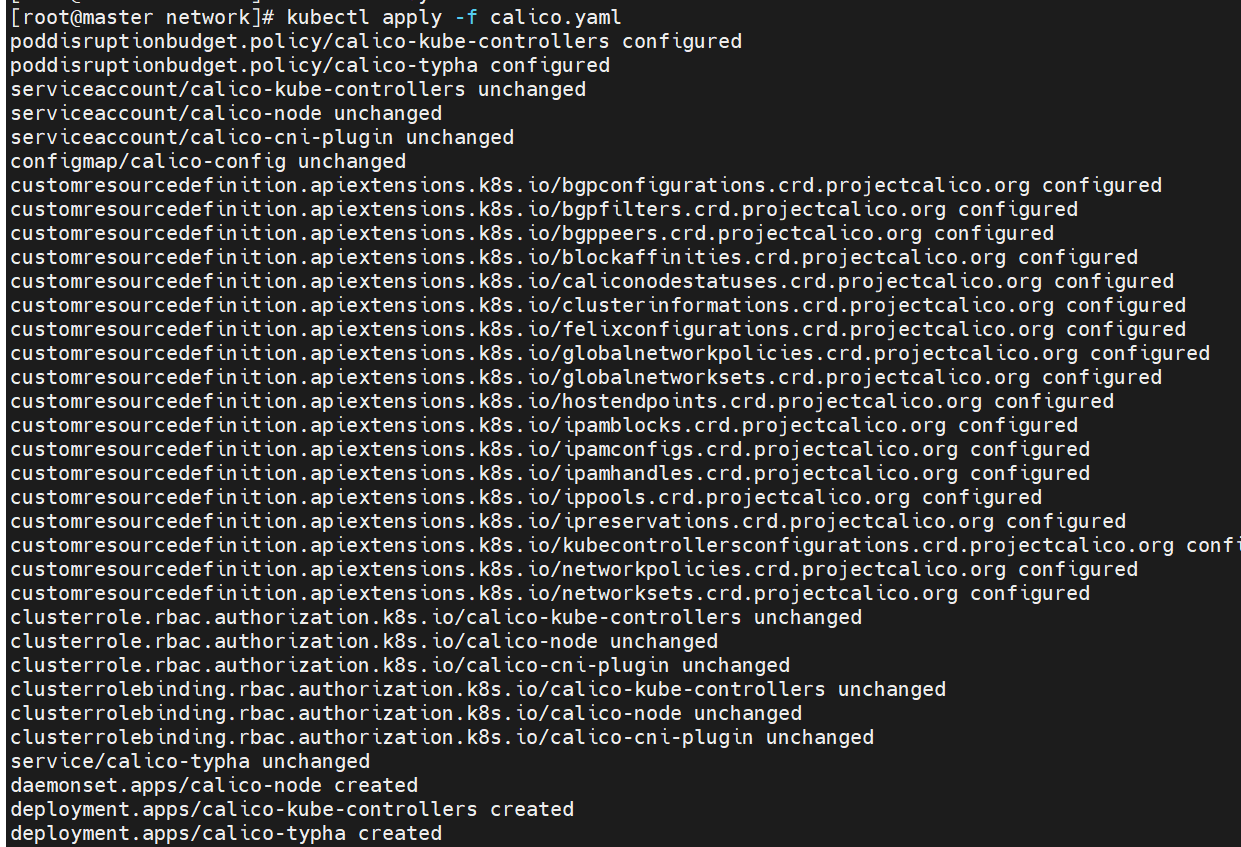
更改yml设置
bash
[root@k8s-master calico]# vim calico.yaml
4835 image: calico/cni:v3.28.1
4835 image: calico/cni:v3.28.1
4906 image: calico/node:v3.28.1
4932 image: calico/node:v3.28.1
5160 image: calico/kube-controllers:v3.28.1
5249 - image: calico/typha:v3.28.1
4970 - name: CALICO_IPV4POOL_IPIP
4971 value: "Never"
4999 - name: CALICO_IPV4POOL_CIDR
5000 value: "10.244.0.0/16"
5001 - name: CALICO_AUTODETECTION_METHOD
5002 value: "interface=eth0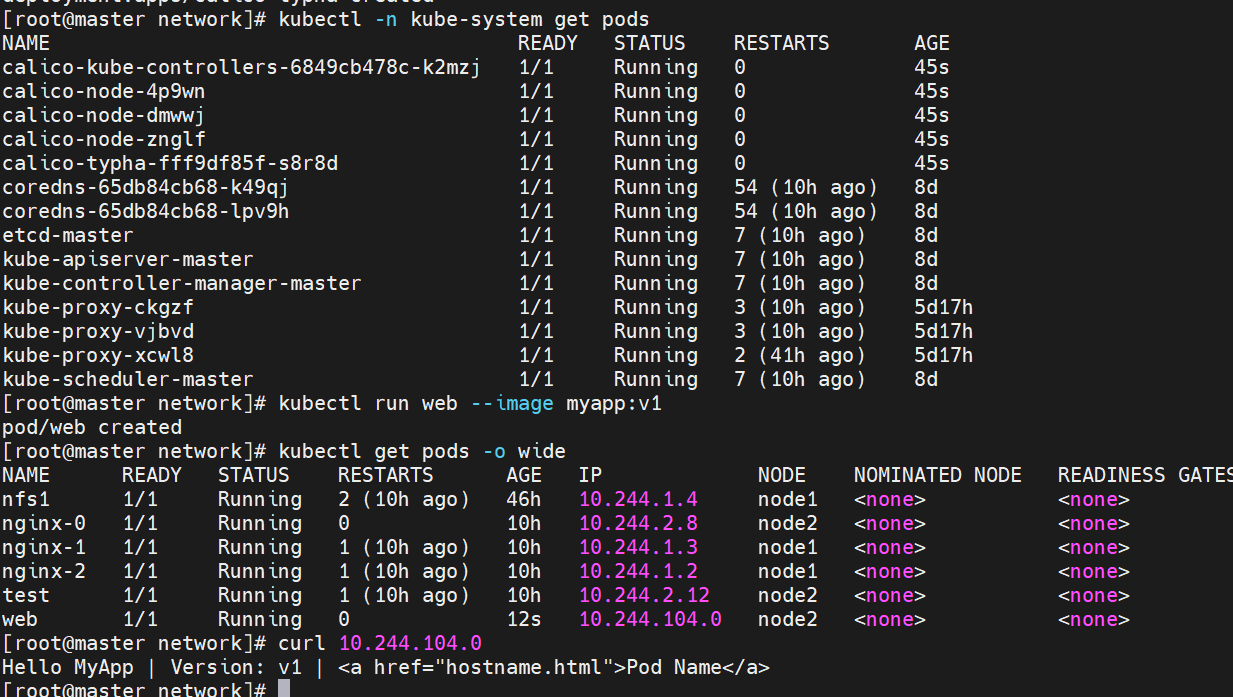
测试:

k8s调度(Scheduling)
调度在Kubernetes中的作用
-
调度是指将未调度的Pod自动分配到集群中的节点的过程
-
调度器通过 kubernetes 的 watch 机制来发现集群中新创建且尚未被调度到 Node 上的 Pod
-
调度器会将发现的每一个未调度的 Pod 调度到一个合适的 Node 上来运行
调度原理:
-
创建Pod
- 用户通过Kubernetes API创建Pod对象,并在其中指定Pod的资源需求、容器镜像等信息。
-
调度器监视Pod
- Kubernetes调度器监视集群中的未调度Pod对象,并为其选择最佳的节点。
-
选择节点
- 调度器通过算法选择最佳的节点,并将Pod绑定到该节点上。调度器选择节点的依据包括节点的资源使用情况、Pod的资源需求、亲和性和反亲和性等。
-
绑定Pod到节点
- 调度器将Pod和节点之间的绑定信息保存在etcd数据库中,以便节点可以获取Pod的调度信息。
-
节点启动Pod
- 节点定期检查etcd数据库中的Pod调度信息,并启动相应的Pod。如果节点故障或资源不足,调度器会重新调度Pod,并将其绑定到其他节点上运行。
调度器种类
-
默认调度器(Default Scheduler):
- 是Kubernetes中的默认调度器,负责对新创建的Pod进行调度,并将Pod调度到合适的节点上。
-
自定义调度器(Custom Scheduler):
- 是一种自定义的调度器实现,可以根据实际需求来定义调度策略和规则,以实现更灵活和多样化的调度功能。
-
扩展调度器(Extended Scheduler):
- 是一种支持调度器扩展器的调度器实现,可以通过调度器扩展器来添加自定义的调度规则和策略,以实现更灵活和多样化的调度功能。
-
kube-scheduler是kubernetes中的默认调度器,在kubernetes运行后会自动在控制节点运行
常用调度方法
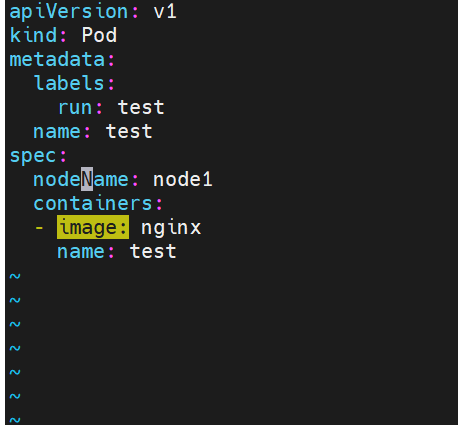
nodename
-
nodeName 是节点选择约束的最简单方法,但一般不推荐
-
如果 nodeName 在 PodSpec 中指定了,则它优先于其他的节点选择方法
-
使用 nodeName 来选择节点的一些限制
-
如果指定的节点不存在。
-
如果指定的节点没有资源来容纳 pod,则pod 调度失败。
-
云环境中的节点名称并非总是可预测或稳定的
-
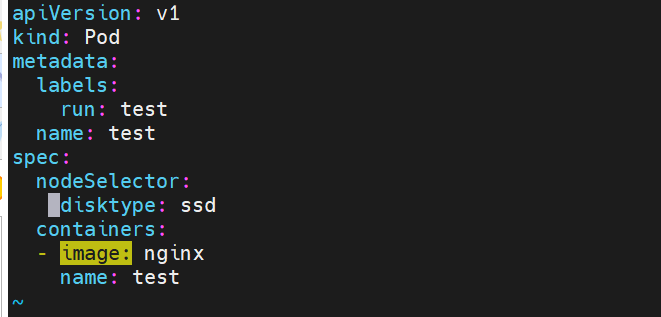
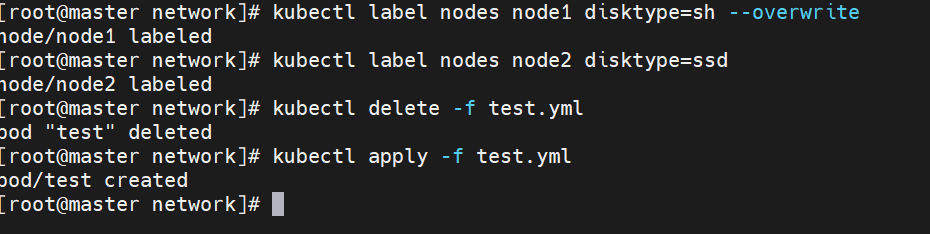
Nodeselector(通过标签控制节点)
-
nodeSelector 是节点选择约束的最简单推荐形式
-
给选择的节点添加标签:
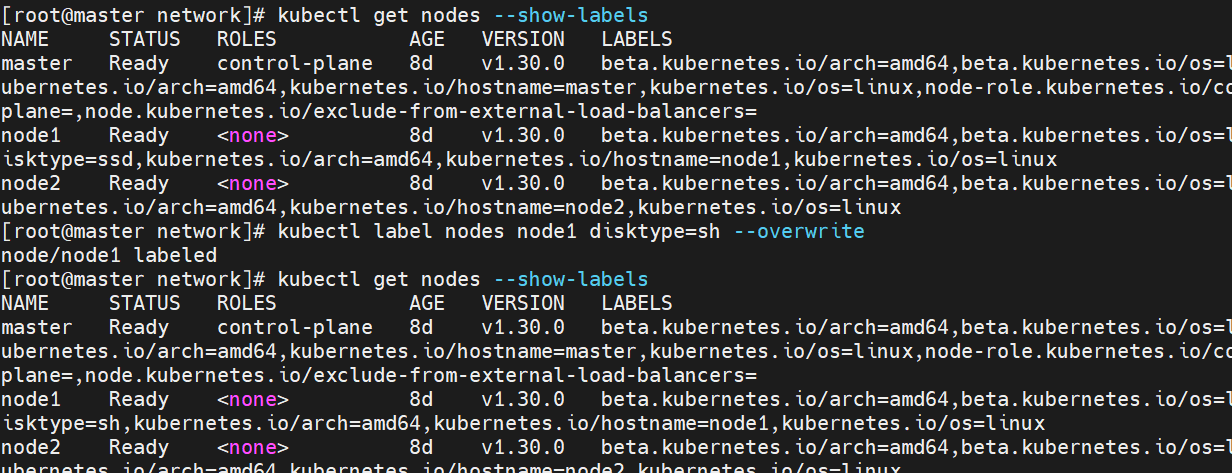
#调度设置



Taints(污点模式,禁止调度)
-
Taints(污点)是Node的一个属性,设置了Taints后,默认Kubernetes是不会将Pod调度到这个Node上
-
Kubernetes如果为Pod设置Tolerations(容忍),只要Pod能够容忍Node上的污点,那么Kubernetes就会忽略Node上的污点,就能够(不是必须)把Pod调度过去
-
可以使用命令 kubectl taint 给节点增加一个 taint:
Taints示例
#设定污点为NoSchedule
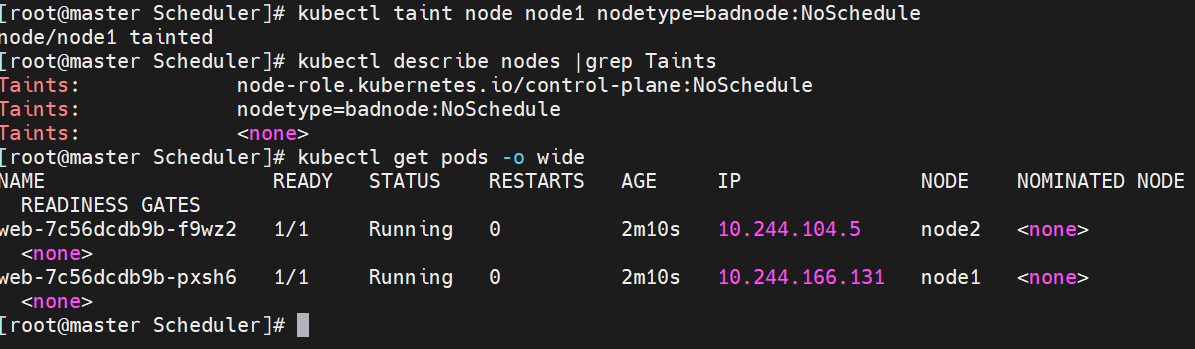

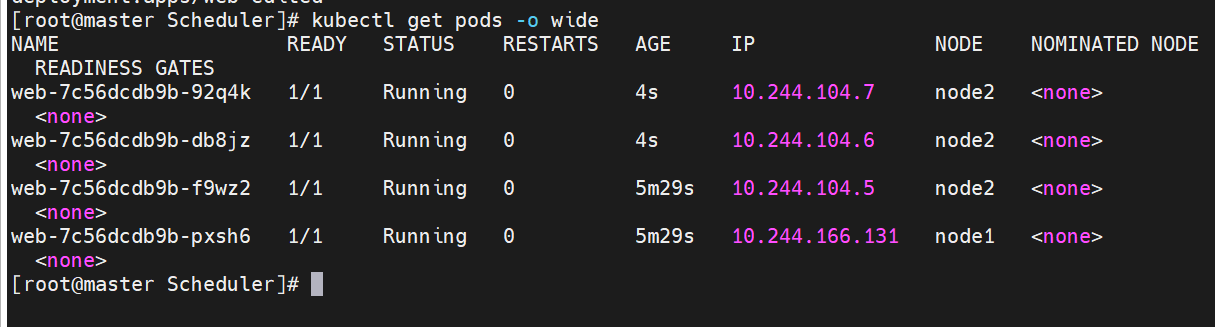
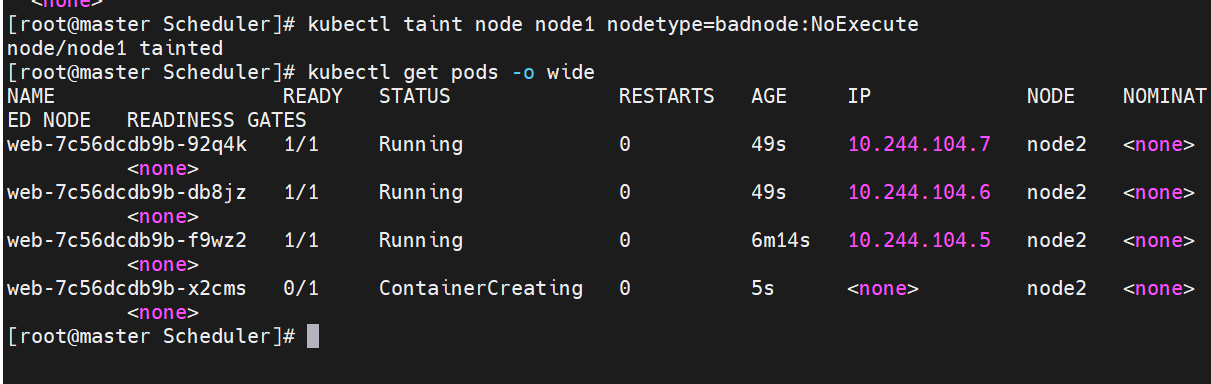
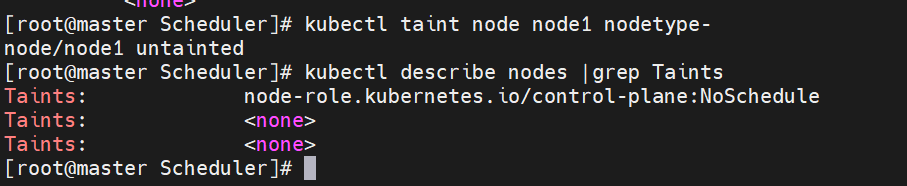
#设定污点为NoExecute
tolerations(污点容忍)
-
tolerations中定义的key、value、effect,要与node上设置的taint保持一直:
-
如果 operator 是 Equal ,则key与value之间的关系必须相等。
-
如果 operator 是 Exists ,value可以省略
-
如果不指定operator属性,则默认值为Equal。
-
-
还有两个特殊值:
-
当不指定key,再配合Exists 就能匹配所有的key与value ,可以容忍所有污点。
-
当不指定effect ,则匹配所有的effect
-
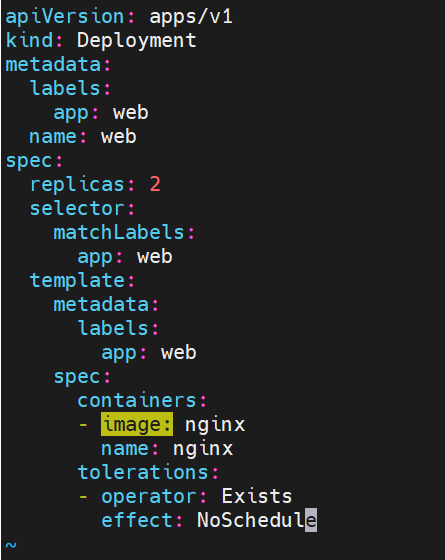
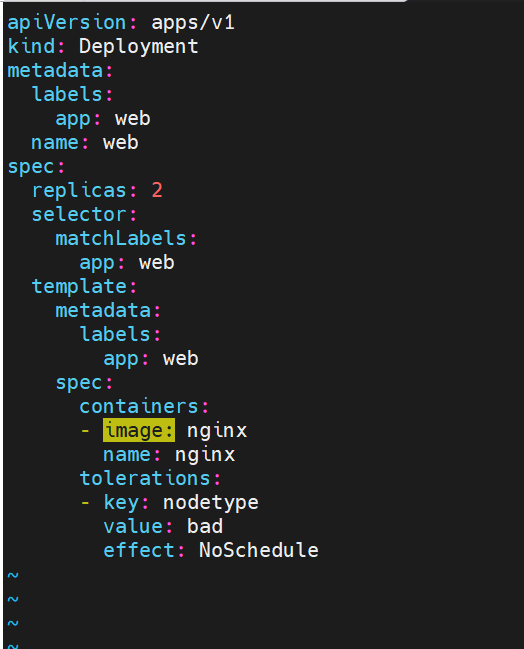
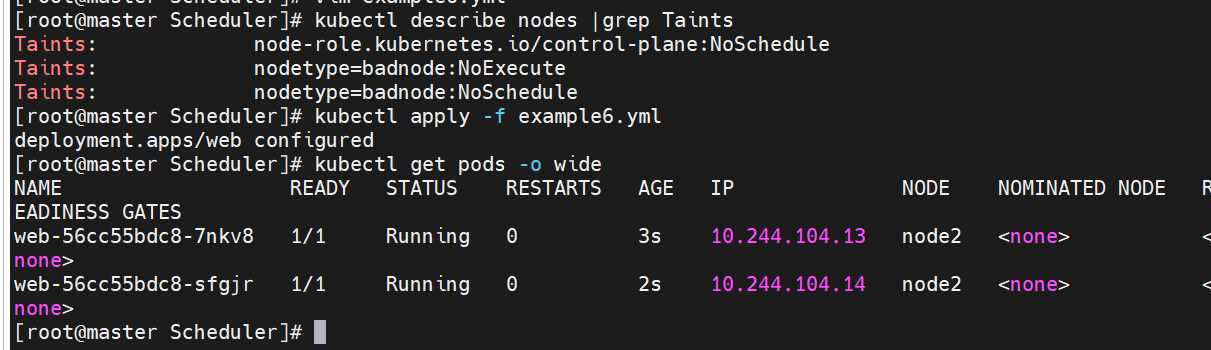
污点容忍示例:
容忍所有污点
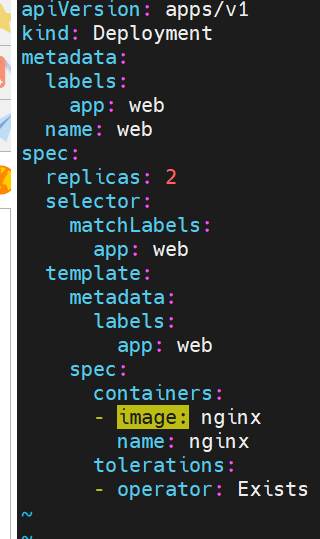

#容忍effect为Noschedule的污点

#容忍指定kv的NoSchedule污点
kubernetes API 访问控制
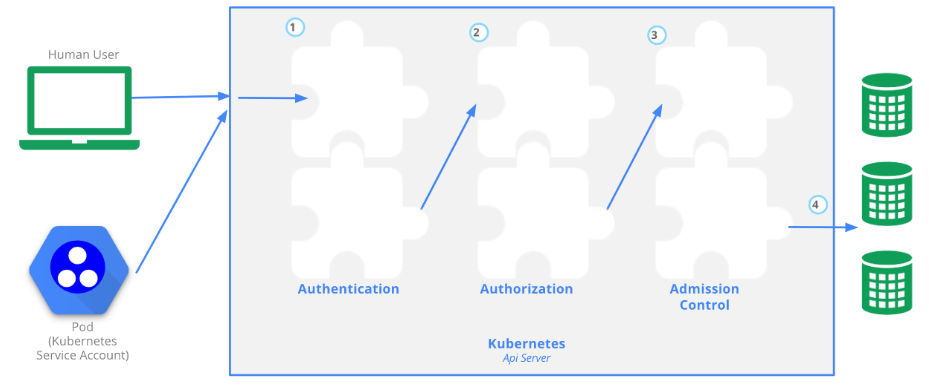
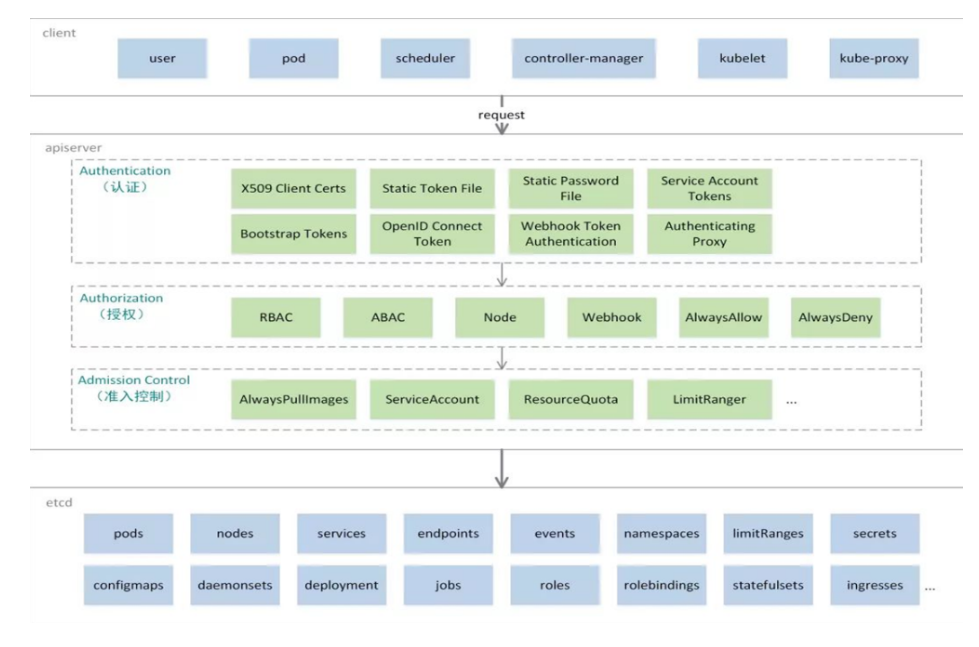
Authentication(认证)
-
认证方式现共有8种,可以启用一种或多种认证方式,只要有一种认证方式通过,就不再进行其它方式的认证。通常启用X509 Client Certs和Service Accout Tokens两种认证方式。
-
Kubernetes集群有两类用户:由Kubernetes管理的Service Accounts (服务账户)和(Users Accounts) 普通账户。k8s中账号的概念不是我们理解的账号,它并不真的存在,它只是形式上存在。
Authorization(授权)
- 必须经过认证阶段,才到授权请求,根据所有授权策略匹配请求资源属性,决定允许或拒绝请求。授权方式现共有6种,AlwaysDeny、AlwaysAllow、ABAC、RBAC、Webhook、Node。默认集群强制开启RBAC。
Admission Control(准入控制)
- 用于拦截请求的一种方式,运行在认证、授权之后,是权限认证链上的最后一环,对请求API资源对象进行修改和校验。
UserAccount与ServiceAccount
-
用户账户是针对人而言的。 服务账户是针对运行在 pod 中的进程而言的。
-
用户账户是全局性的。 其名称在集群各 namespace 中都是全局唯一的,未来的用户资源不会做 namespace 隔离, 服务账户是 namespace 隔离的。
-
集群的用户账户可能会从企业数据库进行同步,其创建需要特殊权限,并且涉及到复杂的业务流程。 服务账户创建的目的是为了更轻量,允许集群用户为了具体的任务创建服务账户 ( 即权限最小化原则 )。
1.1.1 ServiceAccount
-
服务账户控制器(Service account controller)
-
服务账户管理器管理各命名空间下的服务账户
-
每个活跃的命名空间下存在一个名为 "default" 的服务账户
-
-
服务账户准入控制器(Service account admission controller)
-
相似pod中 ServiceAccount默认设为 default。
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
-
如果pod不包含ImagePullSecrets设置那么ServiceAccount中的ImagePullSecrets 被添加到pod中
-
将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中
-
认证(在k8s中建立认证用户)
创建UserAccount
bash
[root@k8s-master auth]# cd /etc/kubernetes/pki/
[root@k8s-master pki]# openssl genrsa -out jxw.key 2048
[root@k8s-master pki]# openssl req -new -key jxw.key -out jxw.csr -subj "/CN=jxw"
[root@k8s-master pki]# openssl x509 -req -in jxw.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out jxw.crt -days 365
Certificate request self-signature ok
[root@k8s-master pki]# openssl x509 -in jxw.crt -text -noout
Certificate:
Data:
Version: 1 (0x0)
Serial Number:
76:06:6c:a7:36:53:b9:3f:5a:6a:93:3a:f2:e8:82:96:27:57:8e:58
Signature Algorithm: sha256WithRSAEncryption
Issuer: CN = kubernetes
Validity
Not Before: Sep 8 15:59:55 2024 GMT
Not After : Sep 8 15:59:55 2025 GMT
Subject: CN = timinglee
Subject Public Key Info:
Public Key Algorithm: rsaEncryption
Public-Key: (2048 bit)
Modulus:
00:a6:6d:be:5d:7f:4c:bf:36:96:dc:4e:1b:24:64:
f7:4b:57:d3:45:ad:e8:b5:07:e7:78:2b:9e:6e:53:
2f:16:ff:00:f4:c8:41:2c:89:3d:86:7c:1b:16:08:
2e:2c:bc:2c:1e:df:60:f0:80:60:f9:79:49:91:1d:
9f:47:16:9a:d1:86:c7:4f:02:55:27:12:93:b7:f4:
07:fe:13:64:fd:78:32:8d:12:d5:c2:0f:be:67:65:
f2:56:e4:d1:f6:fe:f6:d5:7c:2d:1d:c8:90:2a:ac:
3f:62:85:9f:4a:9d:85:73:33:26:5d:0f:4a:a9:14:
12:d4:fb:b3:b9:73:d0:a3:be:58:41:cb:a0:62:3e:
1b:44:ef:61:b5:7f:4a:92:5b:e3:71:77:99:b4:ea:
4d:27:80:14:e9:95:4c:d5:62:56:d6:54:7b:f7:c2:
ea:0e:47:b2:19:75:59:22:00:bd:ea:83:6b:cd:12:
46:7a:4a:79:83:ee:bc:59:6f:af:8e:1a:fd:aa:b4:
bd:84:4d:76:38:e3:1d:ea:56:b5:1e:07:f5:39:ef:
56:57:a2:3d:91:c0:3f:38:ce:36:5d:c7:fe:5e:0f:
53:75:5a:f0:6e:37:71:4b:90:03:2f:2e:11:bb:a1:
a1:5b:dc:89:b8:19:79:0a:ee:e9:b5:30:7d:16:44:
4a:53
Exponent: 65537 (0x10001)
Signature Algorithm: sha256WithRSAEncryption
Signature Value:
62:db:0b:58:a9:59:57:91:7e:de:9e:bb:20:2f:24:fe:b7:7f:
33:aa:d5:74:0e:f9:96:ce:1b:a9:65:08:7f:22:6b:45:ee:58:
68:d8:26:44:33:5e:45:e1:82:b2:5c:99:41:6b:1e:fa:e8:1a:
a2:f1:8f:44:22:e1:d6:58:5f:4c:28:3d:e0:78:21:ea:aa:85:
08:a5:c8:b3:34:19:d3:c7:e2:fe:a2:a4:f5:68:18:53:5f:ff:
7d:35:22:3c:97:3d:4e:ad:62:5f:bb:4d:88:fb:67:f4:d5:2d:
81:c8:2c:6c:5e:0e:e2:2c:f5:e9:07:34:16:01:e2:bf:1f:cd:
6a:66:db:b6:7b:92:df:13:a1:d0:58:d8:4d:68:96:66:e3:00:
6e:ce:11:99:36:9c:b3:b5:81:bf:d1:5b:d7:f2:08:5e:7d:ea:
97:fe:b3:80:d6:27:1c:89:e6:f2:f3:03:fc:dc:de:83:5e:24:
af:46:a6:2a:8e:b1:34:67:51:2b:19:eb:4c:78:12:ac:00:4e:
58:5e:fd:6b:4c:ce:73:dd:b3:91:73:4a:d6:6f:2c:86:25:f0:
6a:fb:96:66:b3:39:a4:b0:d9:46:c2:fc:6b:06:b2:90:9c:13:
e1:02:8b:6f:6e:ab:cf:e3:21:7e:a9:76:c1:38:15:eb:e6:2d:
a5:6f:e5:ab
bash
#建立k8s中的用户
[root@k8s-master pki]# kubectl config set-credentials jxw --client-certificate /etc/kubernetes/pki/jxw.crt --client-key /etc/kubernetes/pki/jxw.key --embed-certs=true
User "jxw" set.
[root@k8s-master pki]# kubectl config view
apiVersion: v1
clusters:
- cluster:
certificate-authority-data: DATA+OMITTED
server: https://172.25.254.100:6443
name: kubernetes
contexts:
- context:
cluster: kubernetes
user: kubernetes-admin
name: kubernetes-admin@kubernetes
current-context: kubernetes-admin@kubernetes
kind: Config
preferences: {}
users:
- name: kubernetes-admin
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
- name: jxw
user:
client-certificate-data: DATA+OMITTED
client-key-data: DATA+OMITTED
#为用户创建集群的安全上下文
root@k8s-master pki]# kubectl config set-context timinglee@kubernetes --cluster kubernetes --user jxw
Context "timinglee@kubernetes" created.
#切换用户,用户在集群中只有用户身份没有授权
[root@k8s-master ~]# kubectl config use-context timinglee@kubernetes
Switched to context "timinglee@kubernetes".
[root@k8s-master ~]# kubectl get pods
Error from server (Forbidden): pods is forbidden: User "timinglee" cannot list resource "pods" in API group "" in the namespace "default"
#切换会集群管理
[root@k8s-master ~]# kubectl config use-context kubernetes-admin@kubernetes
Switched to context "kubernetes-admin@kubernetes".
#如果需要删除用户
[root@k8s-master pki]# kubectl config delete-user timinglee
deleted user timinglee from /etc/kubernetes/admin.confRBAC(Role Based Access Control)
基于角色访问控制授权:
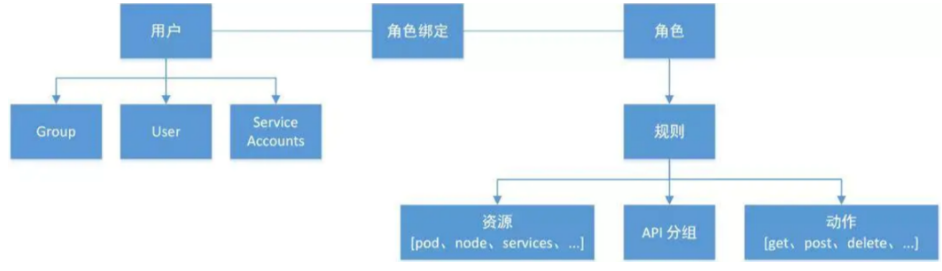
-
允许管理员通过Kubernetes API动态配置授权策略。RBAC就是用户通过角色与权限进行关联。
-
RBAC只有授权,没有拒绝授权,所以只需要定义允许该用户做什么即可
-
RBAC的三个基本概念
- Subject:被作用者,它表示k8s中的三类主体, user, group, serviceAccount
- Role:角色,它其实是一组规则,定义了一组对 Kubernetes API 对象的操作权限。
- RoleBinding:定义了"被作用者"和"角色"的绑定关系
-
RBAC包括四种类型:Role、ClusterRole、RoleBinding、ClusterRoleBinding
-
Role 和 ClusterRole
- Role是一系列的权限的集合,Role只能授予单个namespace 中资源的访问权限。
- ClusterRole 跟 Role 类似,但是可以在集群中全局使用。
- Kubernetes 还提供了四个预先定义好的 ClusterRole 来供用户直接使用
- cluster-amdin、admin、edit、view
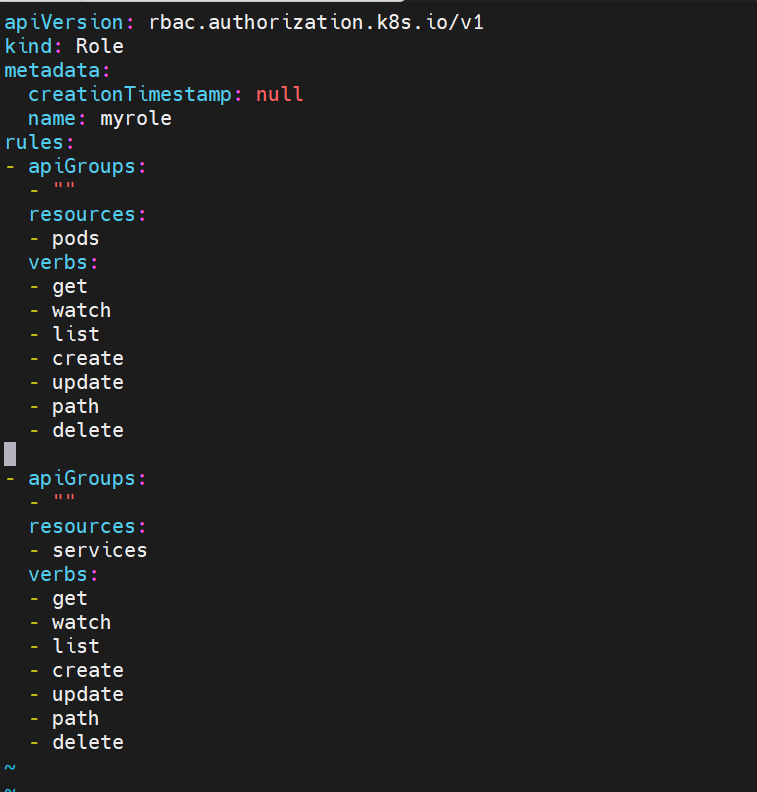
role授权实施
root@k8s-master rbac# kubectl create role myrole --dry-run=client --verb=get --resource pods -o yaml > myrole.yml
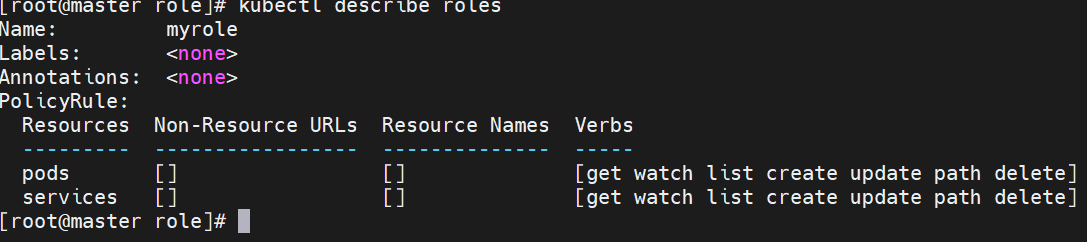
#建立角色绑定
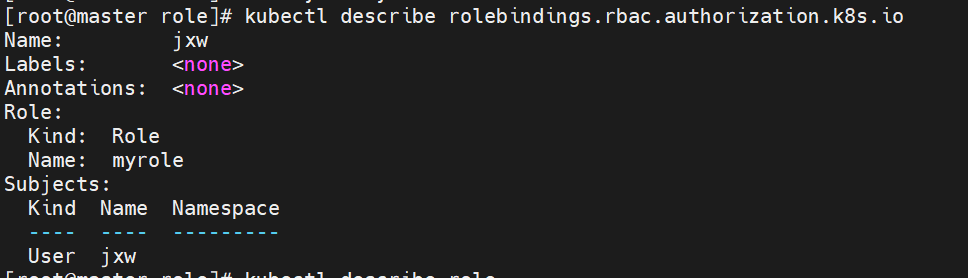
切换用户测试授权
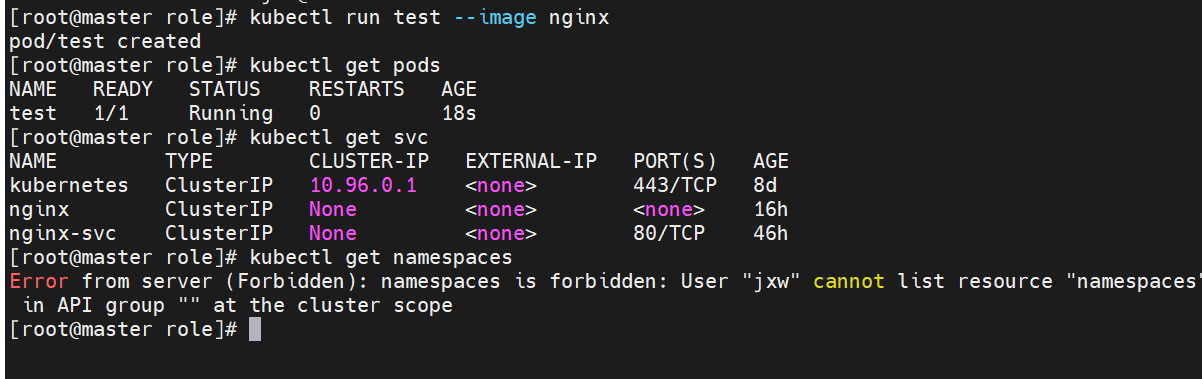
服务账户的自动化
服务账户准入控制器(Service account admission controller)
-
如果该 pod 没有 ServiceAccount 设置,将其 ServiceAccount 设为 default。
-
保证 pod 所关联的 ServiceAccount 存在,否则拒绝该 pod。
-
如果 pod 不包含 ImagePullSecrets 设置,那么 将 ServiceAccount 中的 ImagePullSecrets 信息添加到 pod 中。
-
将一个包含用于 API 访问的 token 的 volume 添加到 pod 中。
- 将挂载于 /var/run/secrets/kubernetes.io/serviceaccount 的 volumeSource 添加到 pod 下的每个容器中。
服务账户控制器(Service account controller)
服务账户管理器管理各命名空间下的服务账户,并且保证每个活跃的命名空间下存在一个名为 "default" 的服务账户