引言
在日常数据库管理中,数据归档是必不可少的重要环节。随着业务数据的不断增长,将历史数据从生产数据库迁移到更经济的存储方案中,不仅可以降低存储成本,还能提升数据库性能。阿里云提供了丰富的数据归档解决方案,本文将深入探讨RDS MySQL数据归档的各种方案及其适用场景。
一、数据归档方案概览
阿里云为RDS MySQL提供了多种数据归档路径,主要包括:
-
Lindorm - 面向海量数据的高性能低成本存储
-
AnalyticDB for MySQL 3.0 - 实时分析型数据仓库
-
AnalyticDB for PostgreSQL - 分析型PostgreSQL数据仓库
-
RDS MySQL - 归档到另一RDS MySQL实例
-
PolarDB MySQL版 - 阿里云自研云原生数据库
-
DBS内置OSS - 通过DBS备份到对象存储
-
用户OSS - 直接归档到用户自己的对象存储
-
专属存储 - 专属集群存储方案
-
同数据库归档 - 在同一数据库内进行数据归档
二、主流归档方案详解
1. 归档至AnalyticDB for MySQL 3.0
适用场景:需要对接实时分析业务的历史数据查询
优势:
-
支持PB级数据存储和分析
-
与RDS MySQL无缝对接
-
提供高性能复杂查询能力
2. 归档至用户OSS
适用场景:低成本长期存储,偶尔需要查询历史数据
优势:
-
存储成本极低
-
数据持久性高(99.9999999999%)
-
可与多种阿里云服务集成
3. 同数据库归档
适用场景:数据量不大,需要频繁查询归档数据
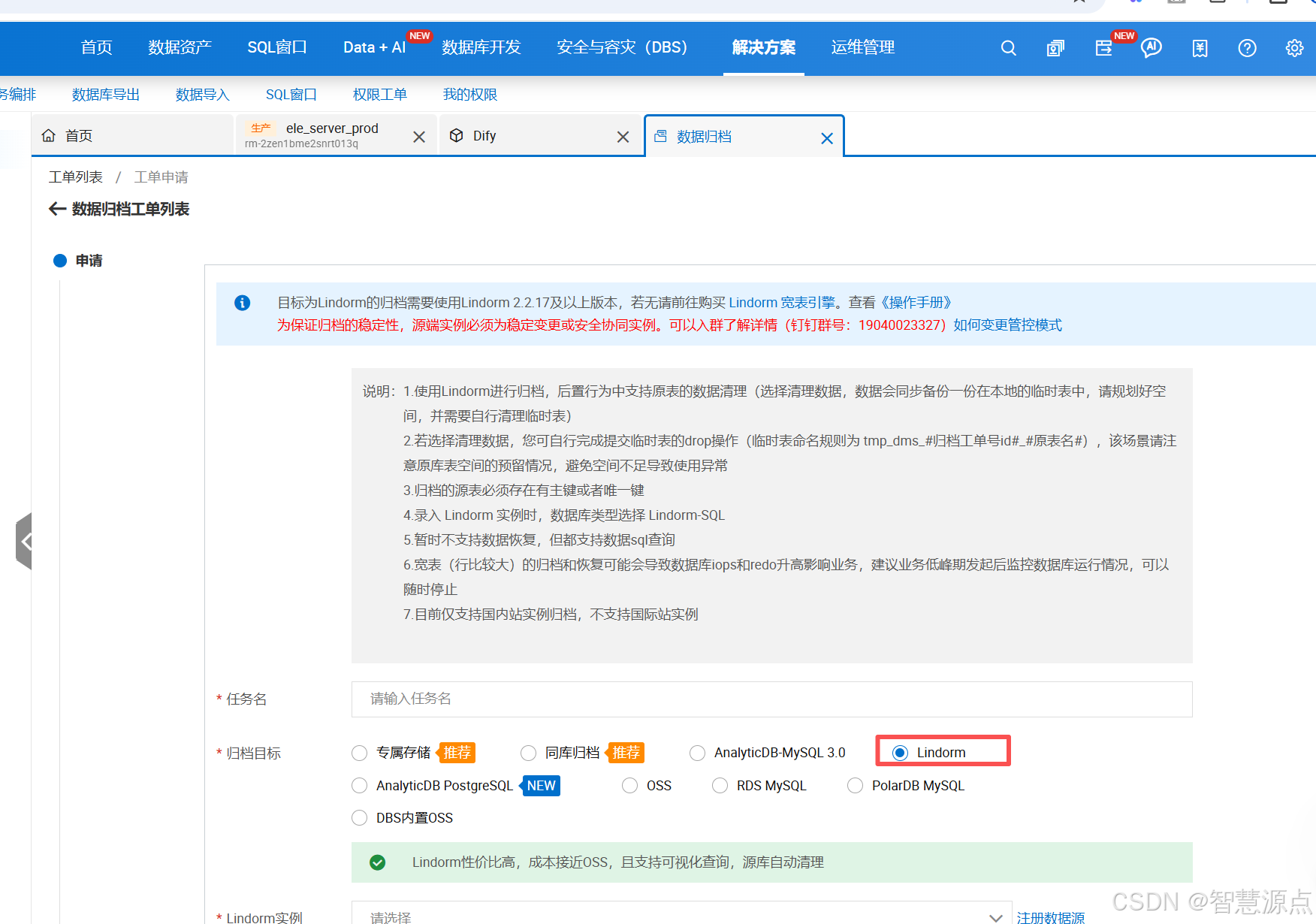
4.归档至Lindorm
适用场景
-
海量数据存储(PB级别)
-
需要高性能时序数据查询
-
低成本长期数据保留
-
复杂分析查询需求
三、数据归档最佳实践
1. 归档策略设计
-
按时间分区归档:根据业务时间字段进行数据切片
-
按业务维度归档:根据业务单元或类型进行分类归档
-
分级存储策略:热数据、温数据、冷数据分别存储
2. 归档过程注意事项
-
业务影响:选择业务低峰期执行归档操作
-
数据一致性:确保归档过程中数据的一致性
-
归档验证:归档完成后进行数据校验
-
索引优化:为归档表设计合适的索引策略
四、业务场景与需求分析
某健康科技公司的穿戴设备每日产生:
-
实时数据:每秒心率、步频、GPS定位(日均10亿+记录)
-
健康指标:每分钟血氧、睡眠质量、卡路里消耗
-
用户数据:5000万+活跃用户,设备生命周期3-5年
核心需求:
-
将30天前的数据自动归档,降低主库存储压力
-
支持历史数据快速查询和分析
-
保证归档过程不影响实时业务
-
成本可控,具备弹性扩展能力
方案架构设计
数据流向:
穿戴设备 → RDS MySQL(热数据) → DMS数据归档 → Lindorm(冷数据/分析)
↘
RDS MySQL(历史查询)方案一:DMS归档至MySQL历史库
DMS任务配置步骤
-
创建归档任务
-
任务类型:数据归档
-
源实例:RDS MySQL生产库
-
目标实例:RDS MySQL归档库
-
调度周期:每天02:00执行
-
方案二:DMS归档至Lindorm
Lindorm表设计
-- 创建Lindorm宽表(通过Lindorm控制台)
CREATE TABLE device_archive_lindorm (
row_key VARCHAR(64), -- device_id + timestamp
cf:device_id VARCHAR(32),
cf:user_id VARCHAR(32),
cf:heart_rate INT,
cf:steps BIGINT,
cf:blood_oxygen DECIMAL(4,1),
cf:gps LONG VARCHAR, -- JSON格式位置数据
cf:timestamp BIGINT,
cf:data_type VARCHAR(20),
PRIMARY KEY (row_key)
) WITH (
compression = 'ZSTD',
ttl = '3650 days'
);
-- 创建二级索引
CREATE INDEX idx_user_time ON device_archive_lindorm (cf:user_id, cf:timestamp);
CREATE INDEX idx_device_type ON device_archive_lindorm (cf:device_id, cf:data_type);