即MySQL 主从复制高可用架构 ,是一套优秀的MySQL 高可用解决方案 ,由日本 DeNA 公司 youshimaton 开发,主要用于保障 MySQL 数据库在主服务器出现故障时,能快速进行主从切换,减少数据库服务中断时间。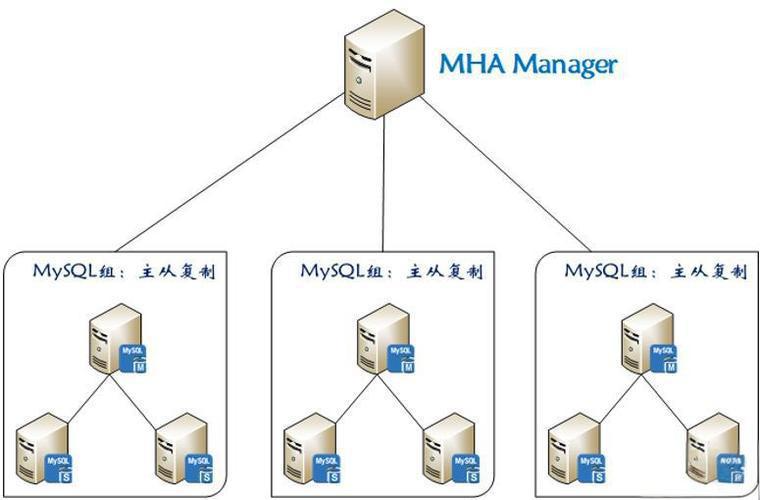
其核心特点包括:
-
自动故障检测与切换:通过定期监控主库状态,当主库出现故障(如宕机、网络中断等)时,能自动识别并在从库中选择最合适的节点提升为新主库,整个过程无需人工干预。
-
数据一致性保障:在切换过程中,会尽量复制主库未同步到从库的binlog日志,最大程度减少数据丢失;支持GTID(全局事务标识),简化binlog定位与同步流程。
-
灵活的候选主库选择:可通过配置指定优先成为新主库的候选节点,优先选择数据最新、负载较低的从库,确保切换后服务稳定。
-
低性能损耗:监控过程对MySQL集群性能影响极小,仅通过SSH和MySQL账号进行轻量通信。
-
架构简洁:由Manager(管理节点)和Node(数据节点代理)两部分组成,Manager负责监控和决策,Node部署在所有MySQL节点上执行具体操作(如复制管理、binlog处理等)
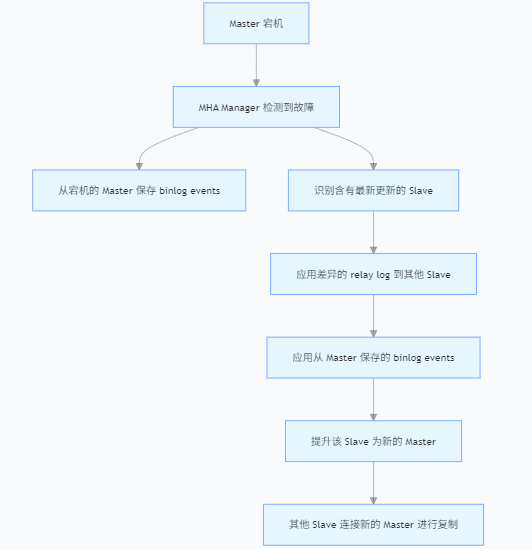
MHA实现原理
(1)从宕机崩溃的master保存二进制日志事件(binlog events);
(2)识别含有最新更新的slave;
(3)应用差异的中继日志(relay log)到其他的slave;
(4)应用从master保存的二进制日志事件(binlog events);
(5)提升一个slave为新的master;
(6)使其他的slave连接新的master进行复制;
实验步骤
1. 服务器规划(至少3节点)
| 角色 | 主机名 | IP地址 | 说明 |
|---|---|---|---|
| Master | mha-node1 | 192.168.1.10 | 主库 |
| Slave1 | mha-node2 | 192.168.1.20 | 从库(候选主库) |
| Slave2 | mha-node3 | 192.168.1.60 | 从库 |
| Manager | mha-manager | 192.168.1.40 | MHA管理节点(独立服务器) |
2. 基础配置(所有节点)
# 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
# 关闭SELinux
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
# 配置hosts(所有节点一致)
cat >> /etc/hosts << EOF
192.168.1.10 mha-node1
192.168.1.20 mha-node2
192.168.1.60 mha-node3
192.168.1.40 mha-manager
EOF
# 配置SSH免密登录(manager节点需免密登录所有数据库节点,数据库节点间也需互信)所有节点执行
ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa
nodes=("mha-manager" "mha-node1" "mha-node2" "mha-node3")
for host in "${nodes[@]}"; do
ssh-copy-id -i ~/.ssh/id_rsa.pub $host
done
执行时,会提示输入目标节点的登录密码(每个节点第一次执行时需要)。
就是我们登录不同设备的密码解释上面的ssh免密登录,不用做
在当前节点生成 SSH 密钥对
登录到一个节点(例如先在mha-manager执行,之后再依次在mha-node1、mha-node2、mha-node3重复),执行以下命令生成密钥(无密码):
bash
# 生成RSA密钥对,-N ''表示空密码,-f指定密钥文件路径
ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa
执行后会在~/.ssh/目录下生成id_rsa(私钥)和id_rsa.pub(公钥)。
将当前节点的公钥分发到所有其他节点
同样在当前节点,执行以下命令,将其公钥复制到包括自身在内的所有节点(确保所有节点的 hostname 能被解析,或用 IP 替代):
bash
# 定义所有节点的列表(包括当前节点自己)
nodes=("mha-manager" "mha-node1" "mha-node2" "mha-node3")
# 循环分发公钥到每个节点
for host in "${nodes[@]}"; do
# 输入目标节点的密码(首次需要,后续免密)
ssh-copy-id -i ~/.ssh/id_rsa.pub $host
done
执行时,会提示输入目标节点的登录密码(每个节点第一次执行时需要)。
ssh-copy-id的作用是将当前节点的id_rsa.pub内容追加到目标节点的~/.ssh/authorized_keys文件中。
在所有节点重复上述步骤
登录到下一个节点(例如mha-node1),重复步骤 1 和步骤 2,将其公钥分发到包括mha-manager、mha-node2、mha-node3在内的所有节点。
依次对mha-node2、mha-node3执行相同操作。
验证免密登录
在任意节点上,尝试 SSH 连接其他节点,若无需输入密码则表示配置成功:
bash
# 例如在mha-manager上测试连接mha-node1
ssh mha-node1
# 在mha-node1上测试连接mha-node2
ssh mha-node2
注意事项
节点 hostname 解析:确保所有节点的/etc/hosts文件中配置了彼此的 hostname 和 IP 映射,例如:
bash
# 所有节点的/etc/hosts都添加以下内容(IP替换为实际地址)
192.168.1.10 mha-manager
192.168.1.11 mha-node1
192.168.1.12 mha-node2
192.168.1.13 mha-node3
权限问题:SSH 对权限敏感,需确保相关文件权限正确:
bash
chmod 700 ~/.ssh # .ssh目录权限必须为700
chmod 600 ~/.ssh/authorized_keys # 授权文件权限必须为600
避免重复操作:如果节点数量较多,可编写一个脚本批量执行(但首次仍需手动输入各节点密码)。二、部署MySQL 8.0主从复制
安装好mysql
配置MySQL(主从差异化配置)
建议采用GTID依赖 :建议开启GTID,减少MHA切换时的binlog定位复杂度。
Master(mha-node1)配置
vim /etc/my.cnf
[mysqld]
# ...
# 在默认配置下方添加:
server-id=11 # 唯一ID
log_bin=mysql-bin # 开启binlog
binlog_format=ROW # ROW模式(MHA推荐)
gtid_mode=ON # 开启GTID
enforce_gtid_consistency=ON # 强制GTID一致性
log_slave_updates=ON # 从库同步时记录binlog(用于级联复制)
skip_name_resolve=ON # 跳过域名解析
systemctl restart mysqld
可直接复制
server-id=11
log_bin=mysql-bin
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
skip_name_resolve=ONSlave(mha-node2/mha-node3)配置
# mha-node2(server-id=12)
vim /etc/my.cnf
[mysqld]
# ...
server-id=12 # 唯一ID(mha-node3设为13)
log_bin=mysql-bin
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
skip_name_resolve=ON
relay_log=relay-bin # 开启中继日志
read_only=ON # 从库只读(可选)
systemctl restart mysqld
可复制
server-id=12
log_bin=mysql-bin
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
skip_name_resolve=ON
relay_log=relay-bin
read_only=ON
server-id=14
log_bin=mysql-bin
binlog_format=ROW
gtid_mode=ON
enforce_gtid_consistency=ON
log_slave_updates=ON
skip_name_resolve=ON
relay_log=relay-bin
read_only=ON3. 搭建主从复制(基于GTID)
在Master(mha-node1)创建复制用户
-- MySQL 8.0默认认证插件为caching_sha2_password,MHA需用mysql_native_password
CREATE USER 'repl'@'192.168.1.%' IDENTIFIED WITH mysql_native_password BY 'Repl@123';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'192.168.1.%';
FLUSH PRIVILEGES;在Slave(mha-node2/mha-node3)配置复制
-- 登录Slave的MySQL
CHANGE MASTER TO
MASTER_HOST='mha-node1',
MASTER_USER='repl',
MASTER_PASSWORD='Repl@123',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1; # 基于GTID自动定位
-- 启动复制
START SLAVE;
-- 检查复制状态(确保Slave_IO_Running和Slave_SQL_Running均为Yes)
SHOW SLAVE STATUS\G;
可复制
CHANGE MASTER TO
MASTER_HOST='mha-node1',
MASTER_USER='repl',
MASTER_PASSWORD='Repl@123',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1;三、部署MHA
1. 安装依赖(所有节点)
CentOS7安装依赖
# 安装wget
yum install -y wget
这时候需要先把ip改成dhcp
# 配置网络Yum源
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-7.repo
# 配置Yum扩展源
wget -O /etc/yum.repos.d/epel.repo https://mirrors.aliyun.com/repo/epel-7.repo
# 安装Perl依赖(MHA基于Perl开发)
yum install -y perl-DBD-MySQL perl-CPAN perl-Config-Tiny perl-Log-Dispatch perl-Parallel-ForkManager perl-ExtUtils-CBuilder perl-ExtUtils-MakeMaker
yum install -y perl-Email-Sender perl-Email-Valid perl-Mail-SenderUbuntu22.04安装依赖包
sudo apt install -y perl libdbi-perl libdbd-mysql-perl libperl-dev libconfig-tiny-perl liblog-dispatch-perl libparallel-forkmanager-perl2. 安装MHA包
下载MHA源码包
# 在教室可以使用局域网下载
# 管理节点下载
wget http://192.168.56.200/Software/mha4mysql-manager-0.58.tar.gz
# 所有节点下载
wget http://192.168.56.200/Software/mha4mysql-node-0.58.tar.gz
# github下载
# 管理节点下载
# wget https://github.com/yoshinorim/mha4mysql-manager/releases/download/v0.58/mha4mysql-manager-0.58.tar.gz
# 所有节点下载
# wget https://github.com/yoshinorim/mha4mysql-node/releases/download/v0.58/mha4mysql-node-0.58.tar.gz安装MHA Node(所有节点)管理节点也要做这个不然下一个步骤装不成功
tar -zxvf mha4mysql-node-0.58.tar.gz
cd mha4mysql-node-0.58
perl Makefile.PL
make && make install安装MHA Manager(仅manager节点)
tar -zxvf mha4mysql-manager-0.58.tar.gz
cd mha4mysql-manager-0.58
perl Makefile.PL
make && make install
# 创建MHA工作目录
mkdir -p /etc/mha/mha_cluster /var/log/mha/mha_cluster创建MHA配置文件(manager节点)
vim /etc/mha/mha_cluster.cnf
[server default]
user=mha_user # MHA管理用户(需在所有MySQL节点创建)
password=Mha@123
ssh_user=root # SSH登录用户
repl_user=repl # MySQL复制用户
repl_password=Repl@123
ping_interval=1 # 健康检查间隔(秒)
master_binlog_dir=/usr/local/mysql/data # master的binlog目录
remote_workdir=/tmp # 远程节点临时目录
secondary_check_script=masterha_secondary_check -s mha-node2 -s mha-node3 # 二次检查节点
manager_workdir=/var/log/mha/mha_cluster # manager工作目录
manager_log=/var/log/mha/mha_cluster/manager.log # manager日志
[server1]
hostname=mha-node1
port=3306
candidate_master=0 # 不优先作为候选主库
[server2]
hostname=mha-node2
port=3306
candidate_master=1 # 优先作为候选主库(数据最新时)
check_repl_delay=0 # 忽略复制延迟,强制作为候选
[server3]
hostname=mha-node3
port=3306
candidate_master=0
可复制
[server default]
user=mha_user
password=Mha@123
ssh_user=root
repl_user=repl
repl_password=Repl@123
ping_interval=1
master_binlog_dir=/usr/local/mysql/data
remote_workdir=/tmp
secondary_check_script=masterha_secondary_check -s mha-node2 -s mha-node3
manager_workdir=/var/log/mha/mha_cluster
manager_log=/var/log/mha/mha_cluster/manager.log
[server1]
hostname=mha-node1
port=3306
candidate_master=0
[server2]
hostname=mha-node2
port=3306
candidate_master=1
check_repl_delay=0
[server3]
hostname=mha-node3
port=3306
candidate_master=0创建MHA管理用户,因为前面做了主从所以只在主上做就好了(所有MySQL节点)
CREATE USER 'mha_user'@'192.168.1.%' IDENTIFIED BY 'Mha@123';
GRANT ALL PRIVILEGES ON *.* TO 'mha_user'@'192.168.1.%';
FLUSH PRIVILEGES;四、验证MHA配置
1. 检查SSH连接(manager节点)
masterha_check_ssh --conf=/etc/mha/mha_cluster.cnf
# 输出"All SSH connection tests passed successfully."即为正常2. 检查主从复制(manager节点)
masterha_check_repl --conf=/etc/mha/mha_cluster.cnf
# 输出"MySQL Replication Health is OK."即为正常五、启动MHA Manager
# 前台启动(测试用,日志实时输出)
masterha_manager --conf=/etc/mha/mha_cluster.cnf
# 后台启动(生产用)
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/nohup.log 2>&1 &
# 检查MHA状态
masterha_check_status --conf=/etc/mha/mha_cluster.cnf
# 输出"mha_cluster (pid: xxxx) is running(0:PING_OK)"即为正常运行GTID依赖 :建议开启GTID,减少MHA切换时的binlog定位复杂度。
启动报错:排错(因为这个版本我做的时候主从复制采用的二进制,出了一堆错,现在还没解决所以我打算换一种复制方法。重新做)我现在照着前面文档做了一次,做成功了,有机会再拍这个错~(其实是失去了所有力气和手段了,算了吧,能做出来就可以了)
错误1:
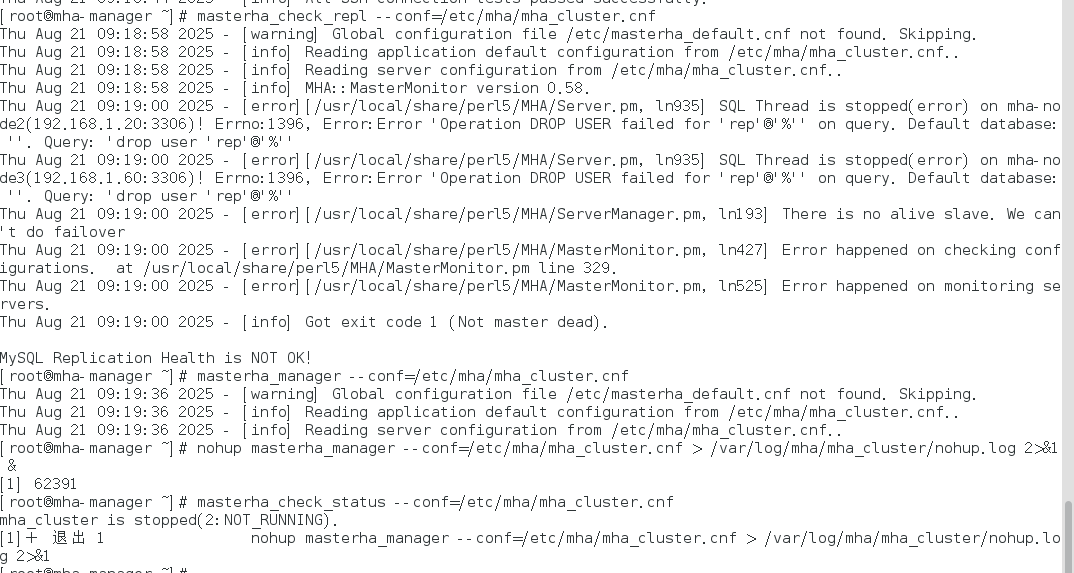
他显示删除用户失败,这个用户是我之前创的,没用我就直接删了,但是反而报错了,这时候需要检查是否真的删除了。这时候看了一下主从复制这里也报错了,所以直接排查主从复制的错误。最后我通过跳过执行成功了,因为真的没有这个用户了。
1. 确认用户是否真的不存在
先通过更全面的查询确认是否有类似用户:
-- 检查所有以'rep'为用户名的记录
SELECT user, host FROM mysql.user WHERE user LIKE 'rep';
-- 检查权限表中是否有残留记录
SELECT * FROM mysql.db WHERE user = 'rep';
SELECT * FROM mysql.tables_priv WHERE user = 'rep';
SELECT * FROM mysql.columns_priv WHERE user = 'rep';2. 清理残留权限记录(如果有)
如果上述查询发现残留记录,手动删除并刷新权限:
-- 删除残留的数据库级权限
DELETE FROM mysql.db WHERE user = 'rep';
-- 删除残留的表级权限
DELETE FROM mysql.tables_priv WHERE user = 'rep';
-- 刷新权限
FLUSH PRIVILEGES;3. 解决复制环境中的问题
如果这是从库(slave)的错误,可能是主库执行过 DROP USER 但从库无此用户导致的复制中断:
方法 A:跳过这个错误(临时解决)
-- MySQL 5.6及以下
STOP SLAVE;
SET GLOBAL sql_slave_skip_counter = 1;
START SLAVE;
-- MySQL 5.7及以上(GTID模式)
STOP SLAVE;
SET GTID_NEXT = 'AUTOMATIC';
START SLAVE;方法 B:在从库手动创建再删除用户
-- 在从库执行
CREATE USER 'rep'@'%' IDENTIFIED BY '任意密码';
DROP USER 'rep'@'%';
FLUSH PRIVILEGES;
-- 然后重启复制
STOP SLAVE;
START SLAVE;错误2
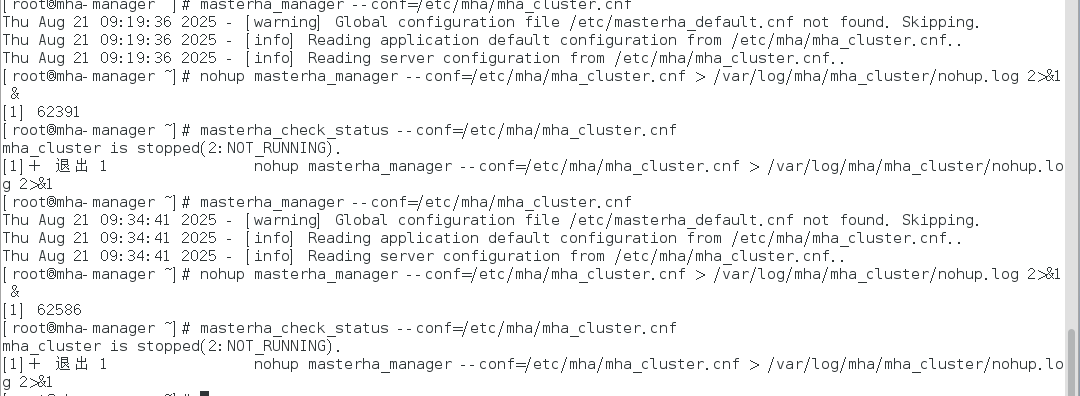
主要问题是 masterha_manager 启动后立即停止(状态为 NOT RUNNING),结合提示和常见 MHA 启动失败场景,可从以下方面排查:
查看报错日志:/var/log/mha/mha_cluster/manager.log
Thu Aug 21 09:34:50 2025 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln359] Slave configurations is not valid.
Thu Aug 21 09:34:50 2025 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln427] Error happened on checking configurations. at /usr/local/bin/masterha_manager line 50.
Thu Aug 21 09:34:50 2025 - [error][/usr/local/share/perl5/MHA/MasterMonitor.pm, ln525] Error happened on monitoring servers.
Thu Aug 21 09:34:50 2025 - [info] Got exit code 1 (Not master dead).六、测试故障切换
1. 模拟Master故障(在mha-node1执行)
systemctl stop mysqld # 停止主库服务2. 观察故障切换(manager节点日志)
tail -f /var/log/mha/mha_cluster/manager.log
# 正常情况下,日志会显示:
# - 检测到master故障
# - 提升mha-node2为新master
# - 其他slave(mha-node3)指向新master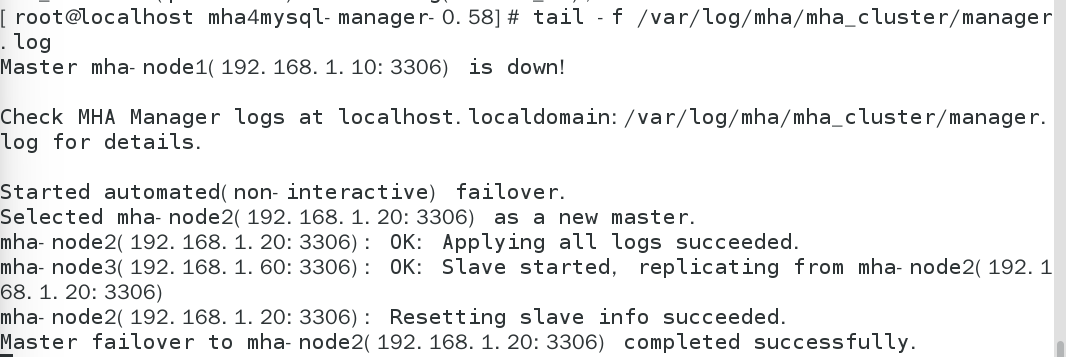
3. 验证切换结果
# 在新master(mha-node2)查看状态
mysql -uroot -p -e "SELECT @@server_id, @@read_only;"
# 应显示server_id=12,read_only=OFF 或者0
# 在mha-node3查看复制状态
mysql -uroot -p -e "SHOW SLAVE STATUS\G"
# 应显示Master_Host为mha-node2,且复制正常七、故障恢复后处理
-
修复原master(mha-node1),重新安装MySQL并配置为新master(mha-node2)的从库。
-
重新启动MHA Manager(故障切换后Manager会自动退出):
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/nohup.log 2>&1 &
恢复步骤
mha-node1启动服务
获取 mha-node2 的 binlog 位置
在 mha-node2 上执行,记录 File 和 Position(用于 mha-node1 同步起点):
SHOW MASTER STATUS;在 mha-node1 上配置从库同步
登录 mha-node1 的 MySQL,设置同步源为 mha-node2:
CHANGE MASTER TO
MASTER_HOST = '192.168.1.20',
MASTER_USER = 'repl',
MASTER_PASSWORD = 'Repl@123',
MASTER_PORT = 3306,
MASTER_LOG_FILE = 'mysql-bin.000001',
MASTER_LOG_POS = 2866; 验证同步状态
在 mha-node1 上执行,确保 Slave_IO_Running 和 Slave_SQL_Running 均为 Yes:
SHOW SLAVE STATUS\G四、手动触发主库切换(可选,若需立即切回)
若需主动将主库切回 mha-node1,在 manager 节点执行手动故障转移(模拟主库故障,强制切换):
# 停止当前 MHA Manager(若正在运行)
masterha_stop --conf=/etc/mha/mha_cluster.cnf
# 执行手动故障转移,指定目标主库为 mha-node1
masterha_master_switch --conf=/etc/mha/mha_cluster.cnf \
--master_state=alive \
--new_master_host=mha-node1 \
--interactive=0五、重启 MHA Manager 监控
故障切换后,重启 MHA Manager 以监控新的主从架构:
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/nohup.log 2>&1 &六、验证最终主库状态
在 manager 节点检查 MHA 状态,确认主库已切回 mha-node1:
masterha_check_status --conf=/etc/mha/mha_cluster.cnf同时在从库mha-node3执行 SHOW SLAVE STATUS\G,确保同步源已指向 mha-node1。
如果我们想让2接着当备胎,那么就是重复上述步骤,将2设置为1的备重新再配置一下
CHANGE MASTER TO
MASTER_HOST='mha-node1',
MASTER_USER='repl',
MASTER_PASSWORD='Repl@123',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1;现在就恢复到了第五大步做完时候的样子了!!喜大普奔
报错提示:
Last_Error: Error 'Operation CREATE USER failed for 'mha_user'@'192.168.68.%'' on query. Default database: ''. Query: 'CREATE USER 'mha_user'@'192.168.68.%' IDENTIFIED WITH 'mysql_native_password' AS '*B0878D325DEBC019F3AB1BC3522CC9310F887A9B'
这时候我们需要哦
SHOW SLAVE STATUS\G
找到 Retrieved_Gtid_Set: c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:1-6
Executed_Gtid_Set: c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:1-6,
e64cc74a-79a3-11f0-aa84-000c29ad973b:1-3
1. 已获取的 GTID 范围(Retrieved_Gtid_Set)
从 SHOW SLAVE STATUS\G 中可知:
plaintext
Retrieved_Gtid_Set: c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:1-6
这表示从库已经从主库完整接收了 GTID 为 c81dbb0b-... 的 1-6 号事务(即主库执行过这 6 个事务,且从库已下载到本地)。
2. 已执行的 GTID 范围(Executed_Gtid_Set)
同时,从库已执行的事务是:
plaintext
Executed_Gtid_Set: c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:1-3, ...
这表示从库只成功执行了 GTID 为 c81dbb0b-... 的 1-3 号事务,而 4-6 号事务尚未执行(或执行失败)。
3. 错误位置推断
结合错误信息 Last_SQL_Error 可知,从库在执行某条 SQL 时失败(创建用户冲突)。由于:
1-3 号事务已成功执行(Executed_Gtid_Set 包含)
4-6 号事务已接收但未执行(Retrieved_Gtid_Set 包含,Executed_Gtid_Set 不包含)
因此,第一个执行失败的事务必然是第 4 号事务,对应的 GTID 就是 c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:4。
简单说就是:已接收的事务范围(1-6)减去已成功执行的范围(1-3),第一个未执行的就是失败的事务(4)。
-- 停止从库复制
STOP SLAVE;
-- 指定要跳过的GTID事务
SET GTID_NEXT = 'c81dbb0b-7c0f-11f0-ab4d-000c296e2d0c:4';
-- 执行空事务跳过该GTID
BEGIN; COMMIT;
-- 恢复自动同步模式
SET GTID_NEXT = 'AUTOMATIC';
-- 重启复制
START SLAVE;
-- 验证同步状态(确保Slave_SQL_Running变为Yes)
SHOW SLAVE STATUS\G注意事项
- MySQL 8.0兼容性 :需使用MHA 0.58版本,且用户认证插件必须为
mysql_native_password。 - GTID依赖 :建议开启GTID,减少MHA切换时的binlog定位复杂度。
- 候选主库选择 :
candidate_master=1的节点应尽量与原master数据一致(复制延迟小)。 - 日志监控:定期检查MHA日志,及时发现潜在问题(如SSH连接失败、复制延迟等)。
后面的内容我没试,可以看一下了解一下
MHA与VIP(虚拟IP)集成配置
在MHA架构中,虽然其核心功能是实现主从自动切换,但应用程序通常通过固定IP地址连接数据库。为避免主库切换后需手动修改应用连接地址,可引入VIP(虚拟IP) 实现IP漂移------VIP始终绑定当前主库节点,切换时自动迁移至新主库,确保应用无感知。
"虚拟 IP"(Virtual IP,简称 VIP)是一个在网络技术中常见的概念,指的是不直接绑定到特定物理网络接口(如网卡)的 IP 地址,而是通过软件或网络设备(如路由器、负载均衡器)逻辑分配和管理的 IP 地址。它的核心作用是实现网络服务的高可用性、负载均衡、故障转移等功能。
一、VIP规划与原理
1.VIP设定 :为MHA集群分配一个独立的虚拟IP(如192.168.8.100),不直接绑定到某台物理机,而是随主库节点动态迁移。
2.实现逻辑 :通过MHA的master_ip_failover脚本,在主库故障切换时自动执行以下操作:
- 从原主库(故障节点)移除VIP;
- 在新主库(提升的slave)绑定VIP;
- 确保VIP在网络中唯一,避免冲突。
二、VIP配置步骤
1. 环境准备(所有节点)
确保所有节点支持VIP配置,关闭网络管理工具(如NetworkManager)对VIP的干扰:
# 关闭NetworkManager(避免自动清理VIP)
systemctl stop NetworkManager && systemctl disable NetworkManager
# 安装arping工具(用于发送ARP广播,刷新网络缓存)
# CentOS
yum install -y arping
# Ubuntu
apt install -y arping2. 编写VIP切换脚本
在MHA Manager节点创建master_ip_failover脚本(用于控制VIP漂移),路径为/etc/mha/master_ip_failover:
#!/usr/bin/perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
# VIP配置
my $vip = '192.168.8.100/24'; # 虚拟IP及子网掩码
my $key = '0'; # 虚拟网卡标识(如需)
my $dev = 'eth0'; # 物理网卡名称(根据实际环境修改)
# 解析MHA传递的参数
my ($command, $ssh_user, $orig_master_host, $orig_master_ip, $orig_master_port, $new_master_host, $new_master_ip, $new_master_port);
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
);
# 执行VIP操作的函数
sub exec_cmd {
my $cmd = shift;
my $result = system($cmd);
if ($result != 0) {
die "Failed to execute: $cmd\n";
}
}
# 从原主库移除VIP
if ($command eq "stop" || $command eq "stopssh") {
print "Removing VIP $vip from old master $orig_master_host...\n";
exec_cmd("ssh $ssh_user\@$orig_master_host \"ip addr del $vip dev $dev; arping -c 3 -I $dev $vip\"");
}
# 在新主库绑定VIP
elsif ($command eq "start") {
print "Adding VIP $vip to new master $new_master_host...\n";
exec_cmd("ssh $ssh_user\@$new_master_host \"ip addr add $vip dev $dev; arping -c 3 -I $dev $vip\"");
}
# 忽略其他命令
elsif ($command eq "status") {
exit 0;
}
exit 0;给脚本添加执行权限:
chmod +x /etc/mha/master_ip_failover3. 集成VIP脚本到MHA配置
修改MHA配置文件/etc/mha/mha_cluster.cnf,添加VIP脚本路径:
[server default]
# ... 原有配置 ...
# 添加VIP切换脚本
master_ip_failover_script=/etc/mha/master_ip_failover4. 初始化VIP(首次部署)
手动在当前主库(mha-node1)绑定VIP:
# 在mha-node1执行
ip addr add 192.168.8.100/24 dev eth0 # 绑定VIP到网卡
arping -c 3 -I eth0 192.168.8.100 # 发送ARP广播,通知网络设备更新缓存验证VIP绑定:
ip addr show eth0 | grep 192.168.8.100
# 输出包含"192.168.8.100/24"即为成功三、验证VIP漂移功能
1. 重启MHA Manager
使VIP配置生效:
# 先停止原有MHA进程
masterha_stop --conf=/etc/mha/mha_cluster.cnf
# 后台重启
nohup masterha_manager --conf=/etc/mha/mha_cluster.cnf > /var/log/mha/mha_cluster/nohup.log 2>&1 &2. 模拟主库故障(同前文步骤)
在原主库(mha-node1)停止MySQL服务:
systemctl stop mysqld3. 检查VIP漂移结果
-
查看MHA日志:确认脚本执行成功
tail -f /var/log/mha/mha_cluster/manager.log
应包含"Removing VIP from old master"和"Adding VIP to new master"的成功日志
-
验证新主库VIP:在mha-node2(新主库)执行
ip addr show eth0 | grep 192.168.8.100
输出包含VIP即为漂移成功
-
应用连接测试:通过VIP连接数据库,验证可用性
mysql -h 192.168.8.100 -u root -p
能成功登录即表示应用无感知切换
四、VIP配置注意事项
- 网络兼容性:确保交换机、防火墙支持VIP漂移(允许同一IP在不同节点间切换),避免因网络策略导致VIP不可用。
- ARP缓存刷新 :脚本中
arping命令用于强制更新网络中其他设备的ARP缓存,必须添加,否则可能出现VIP切换后短时间无法访问的问题。 - 脚本权限 :
master_ip_failover脚本需保证MHA Manager用户(通常为root)有执行权限,且SSH免密登录对所有节点生效(否则脚本无法远程执行命令)。 - 故障恢复后处理 :原主库修复后,需手动将其作为新主库的从库,不要手动绑定VIP(VIP应由MHA脚本自动管理)。
通过集成VIP,MHA集群可实现"主库切换+IP漂移"全自动化,进一步降低故障对应用的影响,提升整体高可用能力。
8.21 超级不开心的一上午,好累