
文章目录
[三、INSERT INTO SELECT语句](#三、INSERT INTO SELECT语句)
一、分组查询
1.1简介
分组查询是指使用group by字句对查询信息进行分组。
格式:
select 字段1,字段2... from 表名 group by 分组字段 having 分组条件;
1.2操作
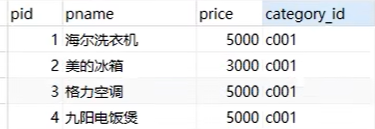
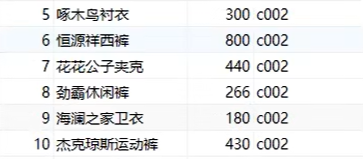
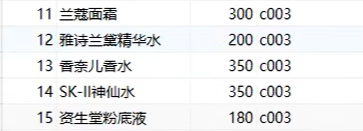

sql
-- 1 统计各个分类商品的个数
select category_id ,count(*)from product group by category_id ;这里代码的意思就是我们将表product中的数据根据category_id分组,然后用count计算每个组中的元素个数,count中既可以是*也可以是pid,都用于计数,就相当于将product根据category_id这个条件分成几个小表,再对每个小表进行计数。

另外,gruop by之后也可以跟多个参数,只有同时满足这几个参数,才会归为一组。

如果要进行分组的话,则SELECT子句之后,只能出现分组的字段和统计函数,其他的字段不能出现。
1.3分组的条件筛选having
- 分组之后对统计结果进行筛选的话必须使用having,不能使用where
- where子句用来筛选 FROM 子句中指定的操作所产生的行
- group by 子句用来分组 WHERE 子句的输出
- having 子句用来从分组的结果中筛选行
格式:select 字段1 ,字段2..from 表名 group 分组字段 having 分组条件;
sql
-- 2.统计各个分类商品的个数,且只显示个数大于4的信息count(*)>4;
select category_id,count(*) from product group by category_id having count(*) > 4;我们还可以使用order by将分类后的数据进行排序,代码如下:
sql
select
category_id,count(pid) cnt
from
product
group by
category_id
having
cnt > 4
order by
cnt;SQL代码的执行顺序为:from->group by -> count(pid) - > select -> having -> order by,我们先from找到是对哪一个表进行操作,接着group by将表拆成多个临时子表进行分组,然后count(pid)进行统计个数,接着select进行筛选,筛选成一个新的表,再用having进行条件筛选,最后用order by按照cnt进行排序。
二、分页查询
2.1简介
分页查询在项目开发中常见,由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式。例如数据有30条,每页显示5条,第一页显示1-5条,第二页显示6-10条。
格式:
-- 方式1-显示前n条
select 字段1,字段2... from 表名 limit n;
-- 方式2分页显示
select 字段1,字段2... from 表名 limit m,n;
m:整数,表示从第几条索引开始,计算方式(当前页-1)*每页显示条数
n:整数,表示查询多少条数据
2.2操作
sql
-- 查询product表的前5条记录
select * from product limit 5;
-- 从第4条开始显示,显示5条
select * from product limit 3,5;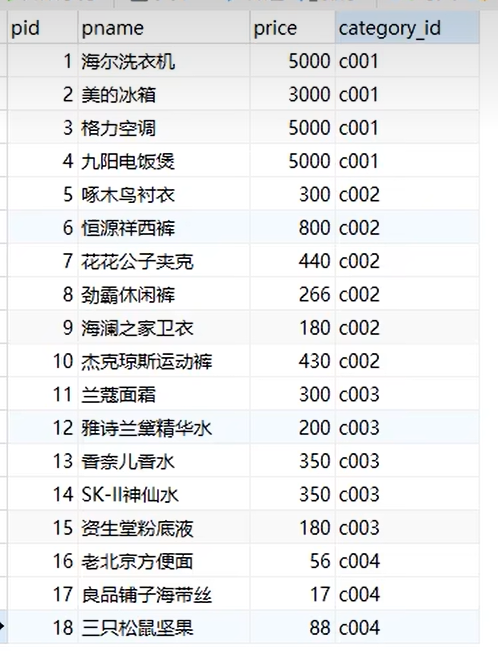
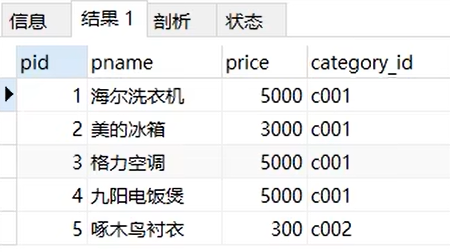
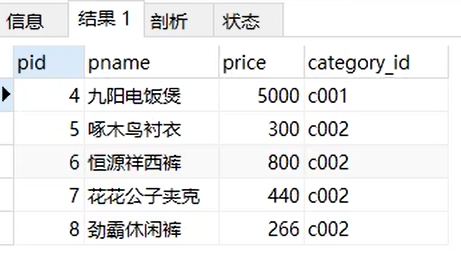

记录的条数是从0开始记录的,所以第1条信息是从0开始的,从第4条开始显示,显示5条,就写成limit 3,5。
三、INSERT INTO SELECT语句
3.1简介
将一张表的数据导入到另一张表中,可以使用INSERTINTOSELECT语句。
格式:
insert into Table2 (fieldl,field2,.) select valuel,value2... from Table1
或者:
insert into Table2 select * from Table1
要求目标表Table2必须存在。Table1中的字段和Table2中的字段都要一一对应。
3.2操作
sql
create table product2(
pname varchar(20),
price double
);
insert into product2(pname,price) select pname,price from product;
select * from product2;这里我们先创建表pruduct2,然后查找表product中的pname和price字段,将这2个字段复制给product2。再查询product2,查看是否复制成功。
sql
create table product3(
categroy_id varchar(20),
product_count int
);
insert into product3 select category_id,count(*) from product group by category_id;
select * from product3;这里我们创建表product3,这里面存储categroy_id和以categroy_id分组后每组的记录条数,第2条代码调用的顺序为:先from找到表product,然后group by按照categroy_id分组,接着select查询每个分组中的category_id和记录条数count(*),最后insert into将查询到的信息存到product3中。