目录
[1. 结构体类型的声明](#1. 结构体类型的声明)
[1.1 结构体回顾](#1.1 结构体回顾)
[1.2 结构的特殊声明](#1.2 结构的特殊声明)
[1.3 结构的自引用](#1.3 结构的自引用)
[2. 结构体的内存对齐](#2. 结构体的内存对齐)
[2.1 对齐规则](#2.1 对齐规则)
[2.2 为什么要存在内存对齐?](#2.2 为什么要存在内存对齐?)
[3. 结构体传参](#3. 结构体传参)
[4. 结构体实现位段](#4. 结构体实现位段)
[4.1 什么是位段](#4.1 什么是位段)
[4.2 位段的内存分配](#4.2 位段的内存分配)
[4.3 位段的跨平台问题](#4.3 位段的跨平台问题)
[4.4 位段的应用](#4.4 位段的应用)
1. 结构体类型的声明
1.1 结构体回顾
我们之前就或多或少的学习了结构体的相关知识。现在,我们先来回顾一下:
结构体的声明
代码块
struct tag
{
member - list;
}variable-list;
比如说描述一个学生:
// 描述一个学生
struct stu
{
char name[40]; // 名字
int age; // 年龄
char sex[10]; // 性别
char id[11]; // 学号
}; // 这里的分号不能丢结构体变量的初始化:
// 描述一个学生
struct stu
{
char name[40]; // 名字
int age; // 年龄
char sex[10]; // 性别
char id[11]; // 学号
};
int main()
{
struct stu s1 = { "zhangsan",21,"man","23405010211" };
struct stu s2 = { .name = "lisi",.age = 18, .id = "23405010101", .sex = "man" };
return 0;
}1.2 结构的特殊声明
在声明结构体的时候,可以不完全声明。
例如:
// 匿名结构体 -- 只能使用一次
struct
{
int a;
char b;
float c;
}x,y,z;
struct
{
int a;
char b;
float c;
}*p;
int main()
{
p = &x;
return 0;
}这个代码运行的时候是会报警告的,因为匿名结构体只能使用一次。
1.3 结构的自引用
在一个结构体中包含一个类型为该结构体本身的成员是否可以呢?可以的。
struct Node
{
int data;
struct Node;
};你们看段代码对不对。答案是不对的,这样子写,我们无法确定这个结构体占据多少字节,而且它会一直递归下去是死递归。那么,如何写才是对的,没错就是使用指针。
struct Node
{
int data;
struct Node* count;
};这样子就是正确的。
我们在书中会看到结构体的重命名。
typedef struct Node
{
int data;
struct Node* count;
}Node;这段代码相当于把结构体重命名为Node,使用起来更加方便。
2. 结构体的内存对齐
我们已经初步了解了结构体,接下来我们计算一下结构体的大小。
一个示例:
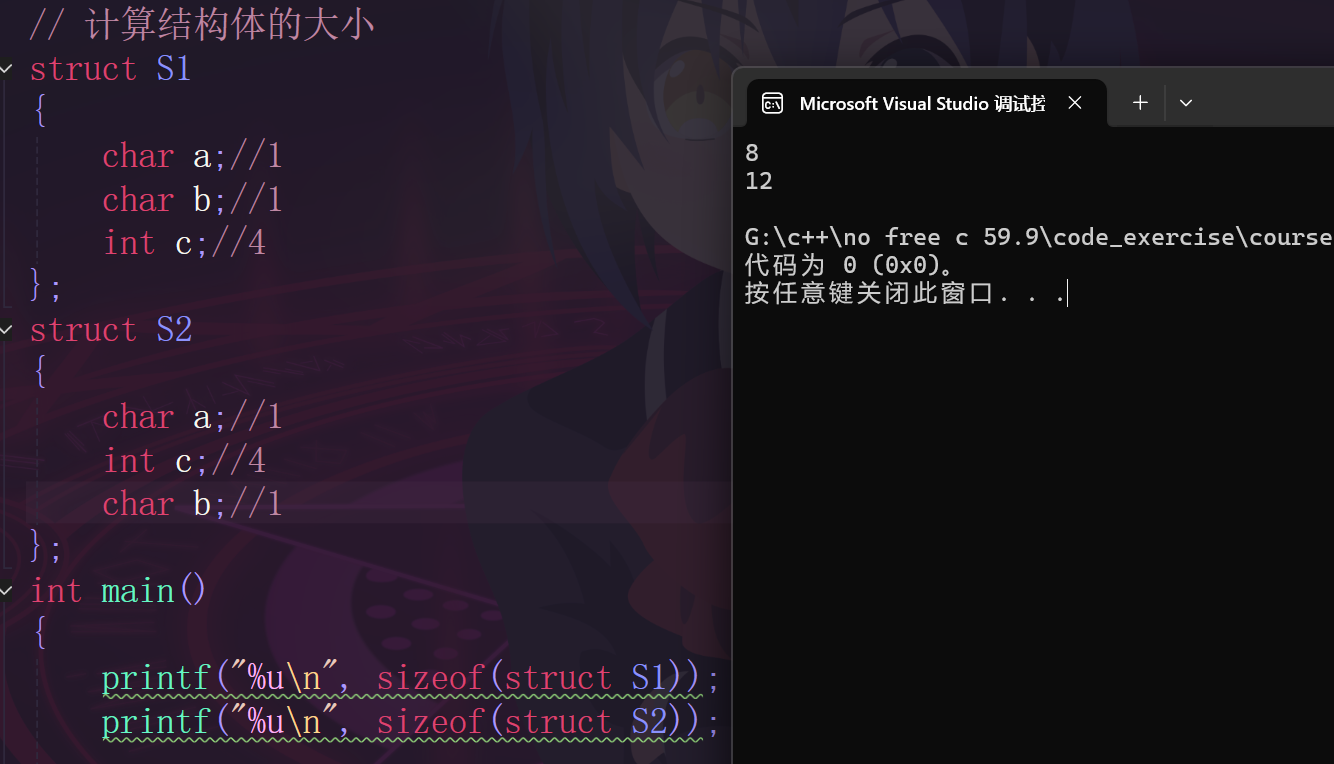
从代码码运行的结果来看,和我们的预算值不一样,这就要学习一下结构体的内存对齐。
2.1 对齐规则
首先得掌握结构体的对齐规则
- 结构体的第1个成员对齐到和结构体变量起始位置偏移量为0的地址处。
- 从第2个成员变量开始,都要对齐到某个对齐数的整数倍地址处。 对齐数 = 编译器默认的一个对齐数 与 该成员变量大小的较小值。 VS的默认值为8 Linux中gcc没有默认对齐数,对齐数就是成员自身的大小
- 结构体总大小为最大对齐数的整数倍。
- 如果嵌套了结构体的情况,嵌套的结构体成员对齐到自己的成员中最大对齐数的整数倍处,结构体的整体大小就是所以最大对齐数的整数倍。
我们在举例子之前先了解一个计算偏移量的宏:offsetof
我们就计算一下上面代码中S1的各成员偏移量。
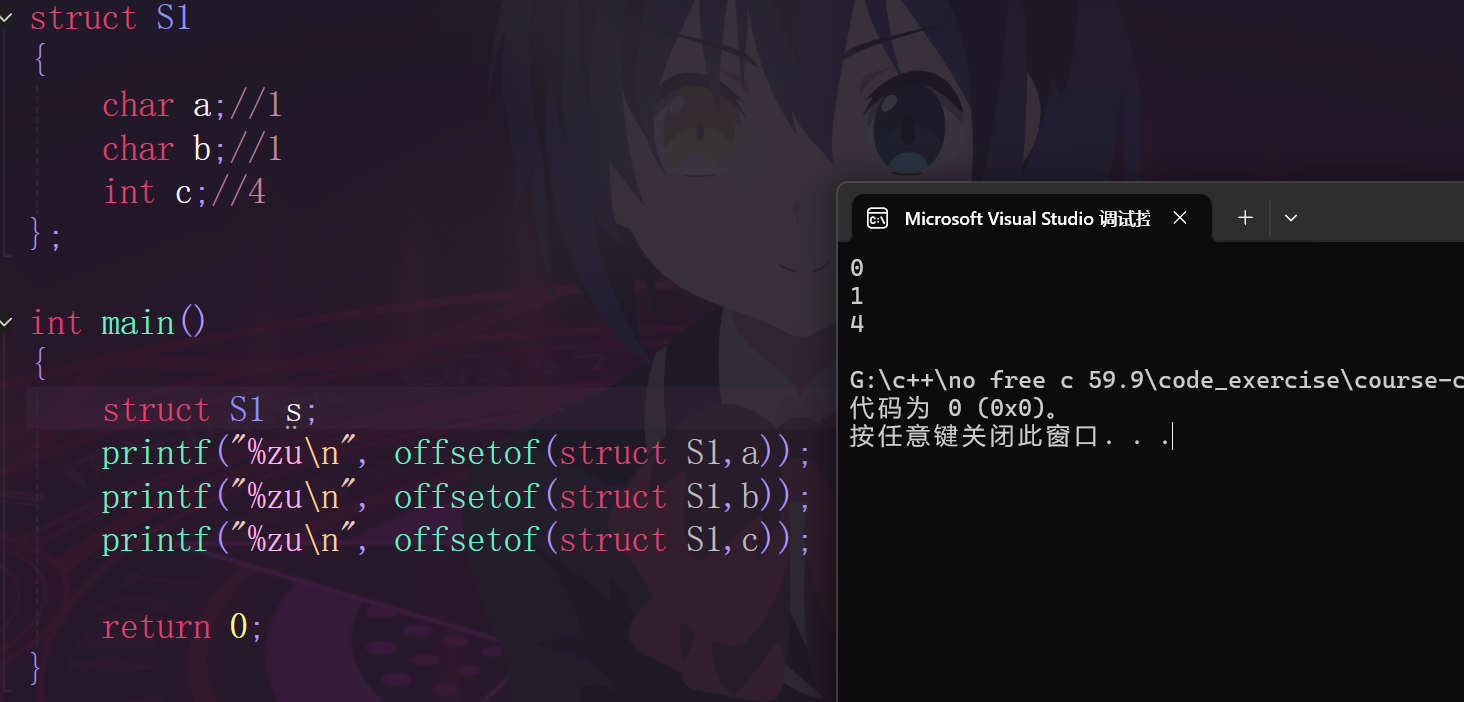
接下来我们说说这是怎么来的,根据对齐规则。
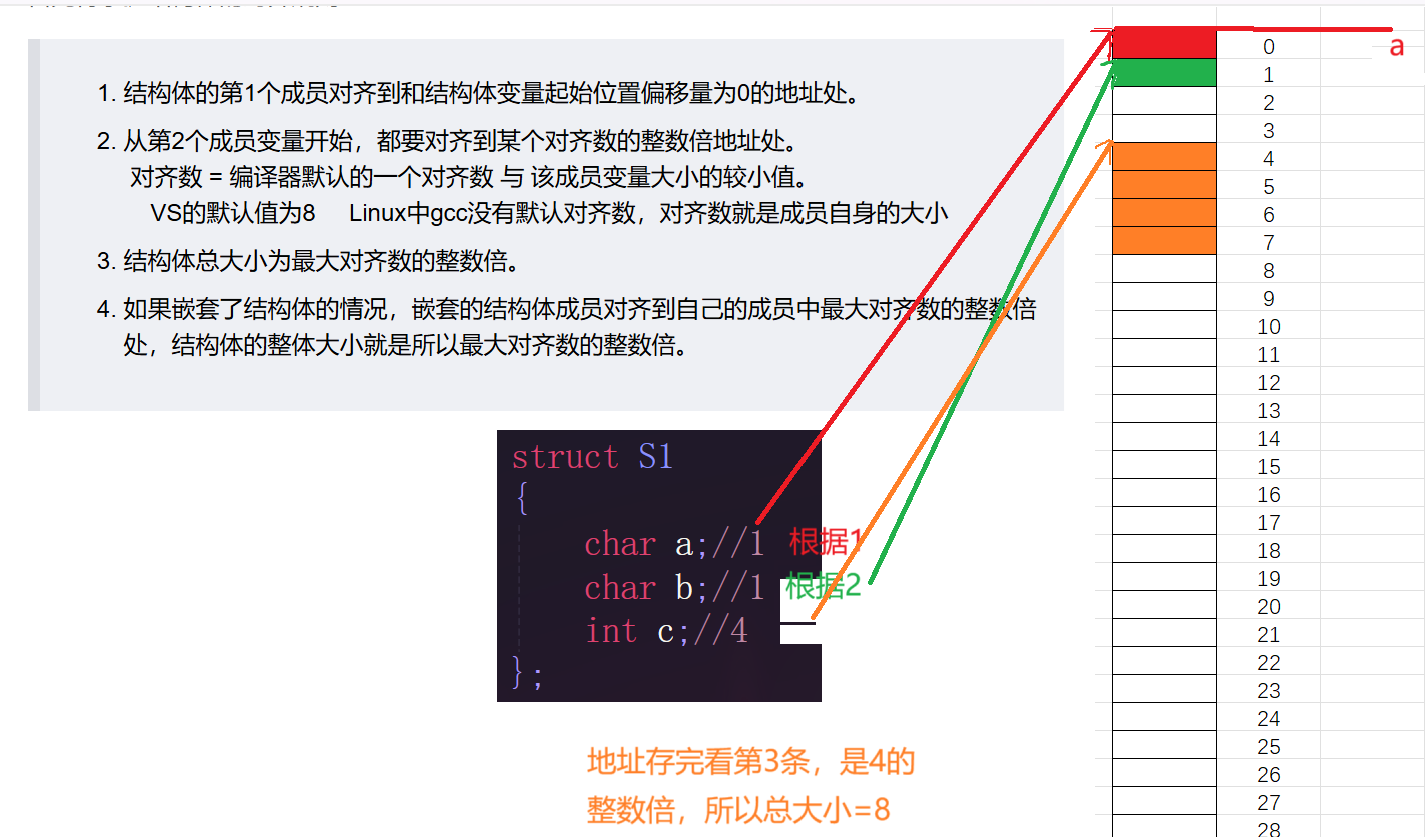
我们就可以得到结构体S1在内存中如何存储,中间的空白就相当于浪费了。
现在,我们明白了如何储存,根据对齐规则趁热打铁对S2分析作为练习。
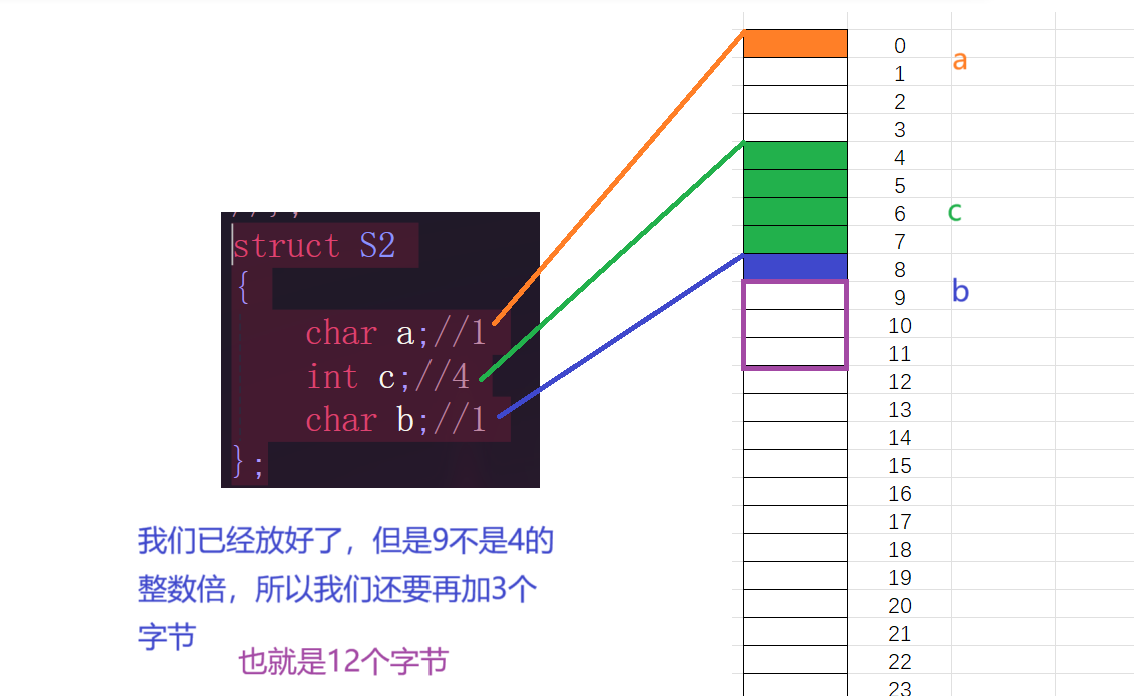
中间空白空间仍然是被浪费了。
2.2 为什么要存在内存对齐?
- 平台原因(移植原因)
不是所有的硬件平台都能访问任意地址上的任意数据的;某些平台只能在某些地址处取某些特定类型的数据,否则会出现异常。
- 性能原因
数据结构(尤其是栈)应该尽可能的在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。
总而言之:结构体的内存对齐是拿空间来换取时间的做法。
那么,在设计结构体的时候,我们急要满足对齐,又要节省空间,该怎么做?让占用空间小的成员尽量集中在一起。
3. 结构体传参
我们了解了结构体在内存中的存储和结构体的取出,现在我们来使用一下结构体。
// 结构体传参
struct S
{
int data[1000];
int num;
};
struct S s = { {1,2,3,4},1000 };
// 结构体传参
void print1(struct S t)
{
printf("print1: %d\n", t.num);
}
// 结构体地址传参
void print2(struct S* ps)
{
printf("print2: %d\n", ps->num);
}
int main()
{
print1(s); // 传结构体 传值调用
print2(&s);// 传地址 传址调用
}我们在上面的代码中使用了两种传参方式,哪一种更好呢?第二种。
因为:函数传参的时候,参数是需要压栈,会有时间和空间上的系统开销。如果传递一个结构体对象的时候,结构体过大,参数压栈的系统开销比较大,会导致性能的下降。
总而言之:结构体传参的时候,要传结构体的地址。
4. 结构体实现位段
结构体的知识了解完之后,我们就可以通过结构体实现位段了。
4.1 什么是位段
位段和结构体的声明类似,有两个不同:
1.位段成员必须是int、unsigned int或signed int。
2.位段的成员名后边有一个冒号和一个数字。
代码演示
struct A
{
int _a : 2;
int _b : 5;
int _c : 10;
int _d : 30;
};A就是一个位段类型。那么它占据多大的空间呢?
会和结构体一样吗? -- 答案是不一样。
4.2 位段的内存分配
-
位段的成员可以是int、unsigned int、signedint或者char类型
-
位段的空间上是按照需要以4个字节或者1个字节的方式来开辟的
-
位段设计很多不确定因素,位段是不跨平台的,注重可移植的程序应该避免使用位段。
这里我就不过多介绍了。
4.3 位段的跨平台问题
- int位段当成有符号还是无符号是不确定的
2.位段中最大数目不确定。
-
位段中的成员在内存中从左向右还是从右向左分配不确定,标准是未定义的。
-
空间的利用是不稳定的。
位段可以节省空间,但是不稳定因素有点多。
4.4 位段的应用
我们在知晓每个成员占据多少位的时候,我们就可以设计位段。就比如网络传输,有的传输的内容大,有的小,特别小的我们就可以使用位段。