"别把目标定在中庸。要敢于胸怀大志。去颠覆,去革新。别害怕树立一个宏大的梦想,它不仅要激励他人,也要激励你自己。渐进式创新不会带来真正的改变------它只会让事物略有改进。要追求突破性的创新,去实现真正有影响的改变。"
------莱昂纳德·布罗迪(Leonard Brody)与大卫·拉法(David Raffa)
云技术可以改变组织开展分析工作的方式。云让组织能够快速行动并采用业界最佳技术。传统上,数据仓库和商业智能(BI)项目被视为重大的投资,往往需要数年才能建成。它们需要一支由 BI、数据仓库和数据集成的开发人员与架构师组成的可靠团队。此外,还需要大量投入、IT 支持,以及硬件与资源采购。即便团队、预算和硬件都到位,仍然有可能失败。
云计算这一概念并不新,但直到近几年才在分析类用例中被广泛采用。云为你提供几乎无限、低成本的存储,可伸缩的计算能力,以及构建安全解决方案的工具。最后,你只需为所用即付费。
本章将梳理过去十年分析市场的趋势与数据仓库的演进,讲解关键云概念,并介绍 Snowflake 数据仓库及其独特架构。
是时候创新了
作为数据从业者,我们参与过许多数据仓库项目。在各行各业设计并实施过大量企业级数据仓库解决方案。有的项目从零搭建,有的则负责修复改造。此外,我们还将系统从"遗留"(legacy)平台迁移到现代的大规模并行处理(MPP)平台,并采用 ELT(抽取-加载-转换)方式,让 MPP 数据仓库平台承担主要的计算工作。
MPP 是分析型数据仓库的核心原则之一,至今依然适用。在 MPP 出现之前的替代方案------对称多处理(SMP)------也值得了解。图 1-1 提供了一个简单示例,帮助你理解对称多处理(SMP)与 MPP 的差别。
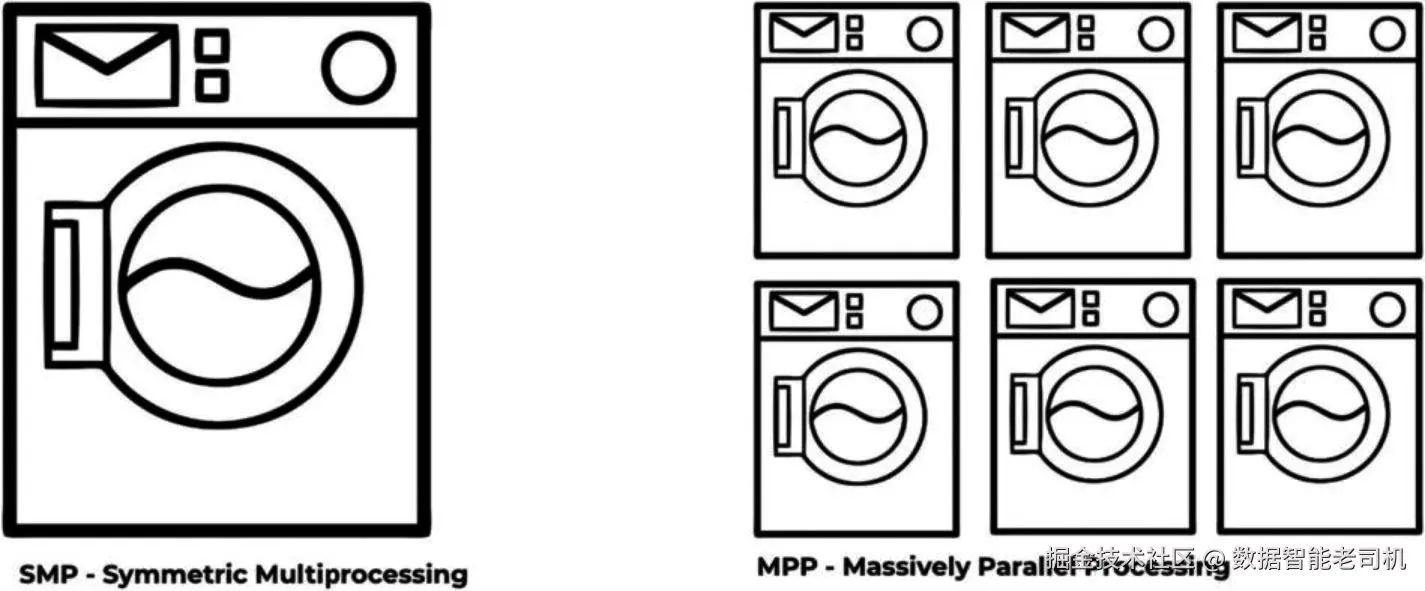
让我们看一个简单的例子。想象你要洗衣服,有两种选择:
- 牺牲周五晚上的派对,去自助洗衣店,因为大家都在派对上,你可以把所有脏衣服并行地同时洗 (这就是 MPP)。
- 周六再去洗衣店,但只用一台洗衣机 (这就是 SMP)。
同时运行六台洗衣机,显然比一台一台地洗要更快洗完更多衣物。正是这种线性可扩展性,让 MPP 系统能更快完成任务。表 1-1 对 SMP 和 MPP 做了比较。若你从事数据仓库相关工作,可能已熟悉这些概念。Snowflake 在这一领域做了创新,实际上结合 了 SMP 与 MPP。
表 1-1 MPP vs. SMP
| 模型 | 描述 |
|---|---|
| 大规模并行处理(MPP) | 多个处理器协同处理单一任务,每个处理器使用各自的操作系统(OS)与内存,并通过某种消息接口互相通信。通常,MPP 采用**无共享(share-nothing)**架构。 |
| 对称多处理(SMP) | 紧耦合的多处理器系统,处理器共享 资源,如单实例的操作系统、内存、I/O 设备以及公共总线。SMP 是一种共享磁盘架构。 |
回到我们的过往经历:在企业级组织里,Oracle 一度非常流行。所有数据仓库解决方案都有一个共同点:极其昂贵,并且需要采购硬件。对咨询公司而言,硬件生意能带来营收:即便某个咨询项目不赚钱,硬件合同也能"覆盖"年度奖金。
后来,Hadoop 与大数据 崛起。互联网上充斥着"用 Hadoop 生态取代传统数据仓库"的新闻。那段时间对 Java 开发者来说很美好,大家可以愉快地写代码、写 MapReduce 作业,直到社区推出了一堆 SQL 工具(如 Hive、Presto 等)。与其亲自去学 Java,我们更倾向于应用帕累托原则 :用传统数据仓库平台与 SQL 解决 20% 的任务,便能带来 80% 的价值。(实际上,我们认为更像是 80% 的场景贡献了 95% 的价值。)
接着是数据科学与机器学习 的兴起,开发者开始学习 R 和 Python 。然而我们发现,没有 ELT/ETL 与数据仓库的支撑 ,本地的 R/Python 脚本并没有太大价值。拿到样例数据集并用数据挖掘技术建个模型并不难,但自动化与规模化 很难,因为算力不足。
随后出现了数据湖(data lake) 。很明显,数据仓库装不下所有数据,而且把所有数据都放进仓库也太昂贵 。如果你不熟悉数据湖,可参见:medium.com/rock-your-d...
又一次,有人主张数据湖就是新的数据仓库,所有人都该立刻用 Hadoop 技术栈把传统方案迁到数据湖。基于我们服务 BI 与业务用户的经验,我们并不认为数据湖可以取代传统 SQL 数据仓库 。不过,当存在大量非结构化数据 、且我们不想用现有数据仓库(因为算力与存储能力不足)时,数据湖能够补充 现有数据仓库。像 Hive、Presto、Impala 这样的 Apache 项目,让我们可以用 SQL 访问大数据存储,并让传统 BI 能够利用数据湖中的数据。显然,这条路成本高 ,但对资源充足且 IT 团队强的大公司是可行的。
数据湖相较传统数据仓库的一个重大优势是:计算与存储解耦 。想象你有一个专用的 MPP 集群数据仓库,结果存储或算力不够了 。你得再加节点------而节点同时带来存储与计算资源,即便你只缺其中一个,也得为两者付费。在数据湖架构中,计算与存储可以独立扩展 。这带来诸多好处,包括扩展分析能力、提升性价比 。但这种方式也有缺点,比如缺乏传统数据库与数据仓库平台所具备的 ACID 能力 。表 1-2 概述了 ACID 特性并给出示例。
表 1-2 ACID 特性
| 模型 | 描述 |
|---|---|
| 原子性(Atomicity) | 确保每个事务被当作一个完整的工作单元,要么全部完成 ,要么完全不执行 。若事务的一部分失败,整个事务将回滚,使数据库回到先前状态。例如:在数据仓库中进行数据装载、要更新多张表时,原子性保证要么全部 应用更新,要么全部不应用,从而维护数据完整性。 |
| 一致性(Consistency) | 确保任意事务都会把数据库从一个有效状态 带到另一个有效状态,遵守预定义的规则与约束。例如:有外键或数据类型等约束时,一致性保证事务完成后数据仍符合这些规则。 |
| 隔离性(Isolation) | 保证每个事务的执行互不干扰 。例如:在分析查询场景,即便有多个用户同时运行查询或更新数据,隔离性确保他们不会相互影响。 |
| 持久性(Durability) | 确保一旦事务提交,其结果将持久保存 ,即便发生断电或系统崩溃也不会丢失。例如:把数据装载进仓库后,持久性保证系统重启后数据依然在且可用。 |
2013 年,我们听说了云上的数据仓库------Amazon Redshift 。我们并未看到它与本地的 Teradata 有本质差异,但显而易见的是:不用再买昂贵的专用设备 ,也能达到同样效果。那时我们就注意到 Redshift 的一个好处:它构建在开源数据库 Postgres 之上。这意味着我们几乎不用重新学习 :Teradata 给我们的 MPP 概念我们已经懂了,Postgres 我们也熟悉,于是可以立刻上手 Redshift 。在 Oracle、Teradata 这些"巨龙"主导的世界里,这简直像一股清风。
显而易见,Amazon Redshift 并非颠覆式创新 ,而是增量式 改进:在既有基础上做提升。换句话说,它是对既有技术/系统的改良。这正是 Snowflake 与其他云数据仓库平台之间核心差异的起点。
Amazon Redshift 很快流行起来,其他公司也陆续推出各自的云数据仓库平台。如今,所有大型厂商都在构建面向云的数据仓库解决方案。
Snowflake 则是一项颠覆式创新 。Snowflake 的创始人把既有数据仓库平台的各种痛点汇总,提出了全新的架构与产品 ,既能满足现代数据需求,又允许组织在有限预算与小团队 下快速推进。
每个人都有自己的道路:有人深耕 Hadoop 等大数据技术;也有人长期从事传统数据仓库与 BI 方案。但我们有一个共同目标------让组织真正以数据驱动 。随着云计算的兴起,我们拥有了更快更好 完成工作的机会,且云计算也打开了分析的新方式。Snowflake 创立于 2012 年 ,2014 年 10 月 以隐身模式对外,2015 年 6 月 正式商用(GA)。Snowflake 为数据仓库世界带来了创新,开启了数据仓库的新纪元。
如今有三个术语:数据仓库(data warehouse) 、数据湖(data lake) 与 湖仓一体(lakehouse) 。Databricks 在 2020 年 提出"lakehouse"一词,其想法是把数据湖与数据仓库的优点融合于同一平台 。这意味着 lakehouse 既能解耦存储与计算 并独立扩展,又在某种程度上支持 ACID 。当前较流行的开源方案有 Apache Iceberg、Apache Delta、Apache Hudi 。本书聚焦 Apache Iceberg ,因为 Snowflake 支持这种开放表格式 ,且其流行度很高。
在本章后续部分,我们将讨论 Snowflake 的架构,届时你可以自行判断:Snowflake 究竟更像是一个数据仓库 ,还是一个湖仓一体平台。
云计算关键概念
在深入 Snowflake 之前,我们先梳理一些云的基础知识,帮助你更好地理解云平台的价值。
从本质上说,云计算是一个远程的、虚拟化的按需共享资源池,提供计算、存储、数据库和网络等服务,并且能够快速、规模化地部署。图 1-2 展示了云计算的关键要素。

表 1-3 定义了云计算中的关键术语。 这些术语既是云分析解决方案的构建基石,也是 Snowflake 数据仓库的基础。
表 1-3 云计算关键术语
| 术语 | 说明 |
|---|---|
| Compute(计算/算力) | 处理工作负载的"大脑 "。包含 CPU 与内存(RAM),用于运行各类工作负载与进程------在我们的场景中即对数据进行处理。 |
| Databases(数据库) | 传统 SQL 或 NoSQL 数据库,可被应用与分析方案利用来存储结构化数据。 |
| Storage(存储) | 以原始格式 将数据保存为文件;可以是文本、图像、音频等。云中任何能够存放数据的资源都属于存储资源。 |
| Network(网络) | 为各类云服务与其使用者之间提供连接所需的资源。 |
| ML/AI(机器学习/人工智能) | 为重型计算 与分析型工作负载提供的专用资源。 |
另外,需要强调虚拟机监控器/管理程序(Hypervisor)是云计算的核心要素之一。图 1-3 展示了一台主机承载多个 虚拟机(VM)以及一个 Hypervisor:它创建出虚拟化环境,使得多台 VM 能同时部署在一台物理主机上。
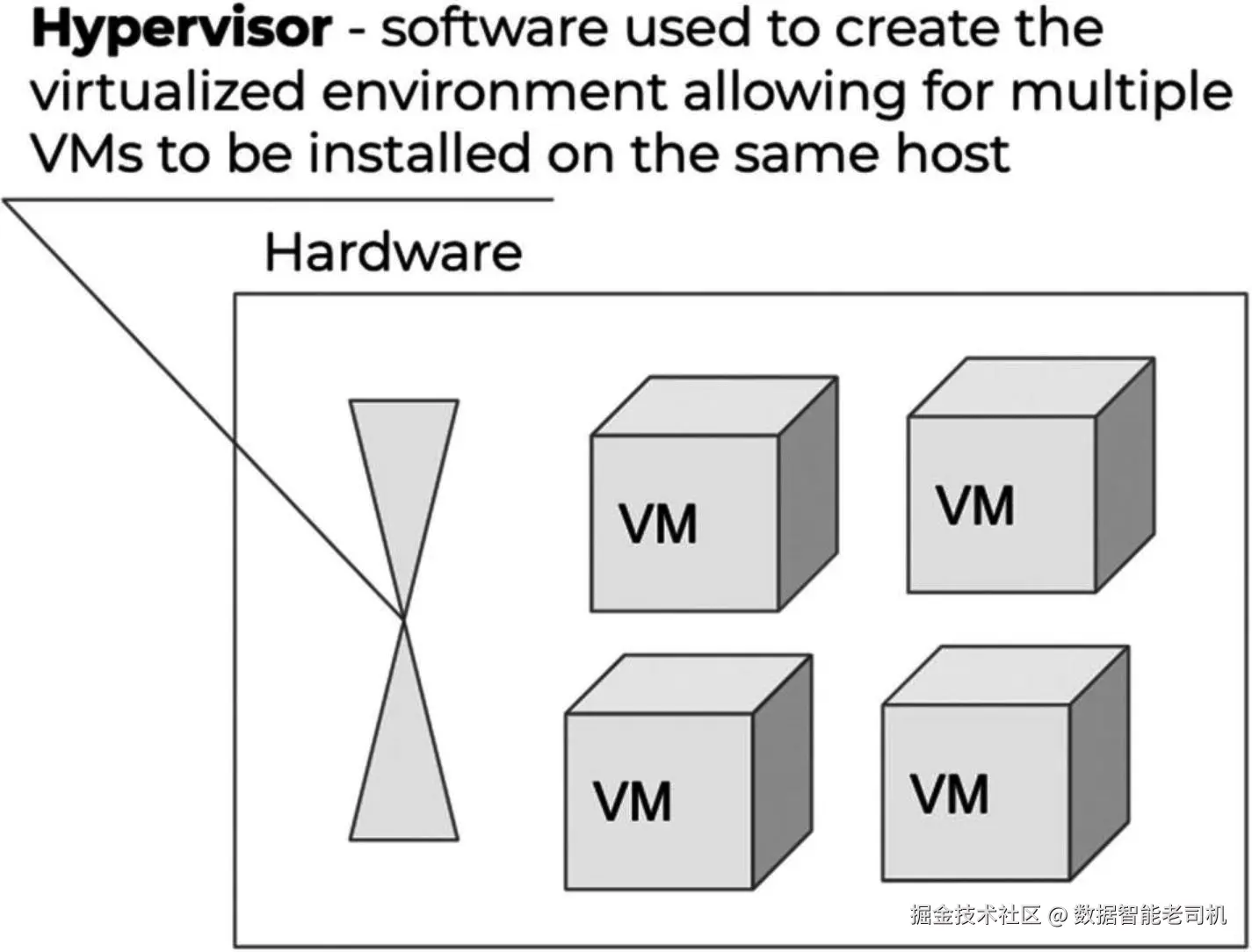
虚拟化带来的优势:
- 降低资本性支出(CapEx)
- 降低运营成本(OpEx)
- 占用空间更小(smaller footprint)
- 资源优化(提高资源利用率)
如图 1-4 所示,云有三种部署模型。
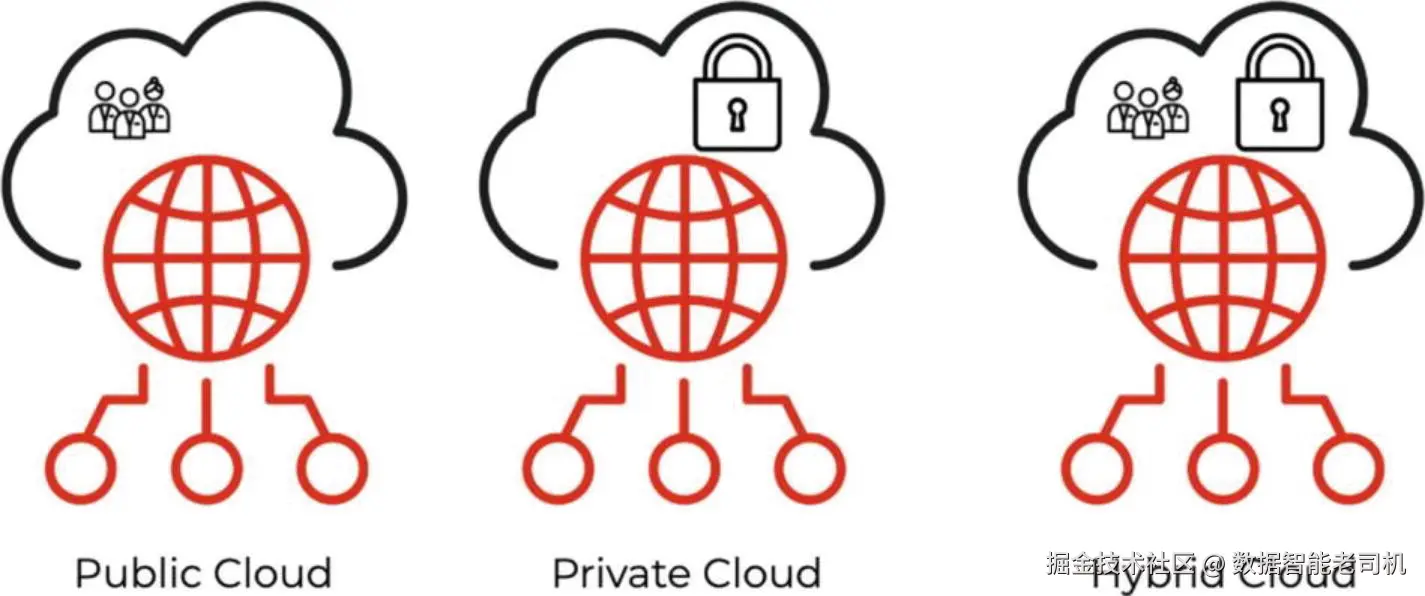
你选择哪种模型,取决于组织的数据处理政策与安全要求。比如,掌握大量关键客户信息的政府与医疗机构,往往更倾向于把数据保存在私有云 中。表 1-4 给出了云部署模型的定义。
表 1-4 云部署模型
| 模型 | 描述 |
|---|---|
| 公有云(Public cloud) | 服务提供商向各组织开放其云基础设施;该基础设施位于服务提供商的场地(数据中心),但由为其付费的组织来操作。 |
| 私有云(Private cloud) | 云由某个特定机构、组织或企业独享 与拥有。 |
| 混合云(Hybrid cloud) | 公有云与私有云的组合。 |
在大多数情况下,我们更倾向于使用公有云 。Amazon Web Services (AWS) 、Microsoft Azure 与 Google Cloud Platform 都是公有云,你可以立即开始构建解决方案与应用。
此外,了解云服务模型 (相对于本地部署 on-premises 方案)也很重要。图 1-5 用一个简单的类比------ "汉堡即服务(Hamburger as a Service)" ------来展示三种主要服务模型。
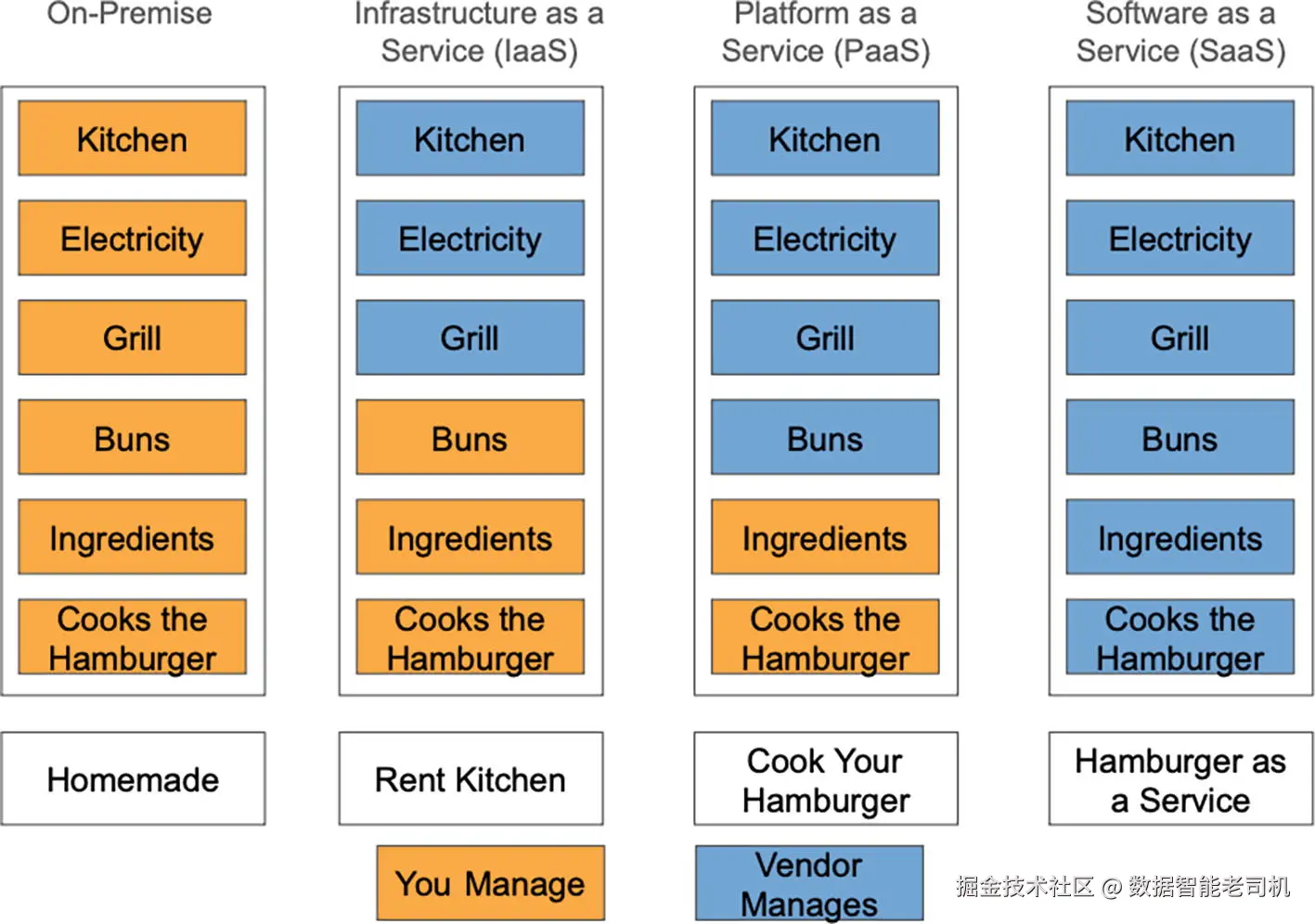
IaaS 的一个例子是云虚拟机 ;Amazon EC2 就是 IaaS 的代表。
Amazon Elastic MapReduce (即托管 Hadoop)和 Amazon Redshift 是 PaaS 的示例;而 DynamoDB (AWS 的 NoSQL 数据库)与 Lambda 则是 SaaS 的示例------由服务方为你全权托管。
注 :在云端软件交付模型中,SaaS 是最全面 的服务形态,它把大量底层硬件与软件的维护工作从终端用户处抽象 掉,特点是无缝的网页体验 ,用户侧所需的管理与优化最少。相比之下,IaaS 与 PaaS 往往需要用户对底层硬件或软件进行更多管理。
Snowflake 采用 SaaS 模式,也被称为数据仓库即服务(DWaaS) 。从数据库存储基础设施 、用于分析的计算资源 ,到库内数据的优化 ,都由 Snowflake 负责。
这对数据工程师意味着什么?我们用 Amazon Redshift 作个对比示例:假设你在构建数据仓库,需要创建一张数十亿行 的事实表 ,你必须为这张事实表选择数据分布方式 。Redshift 是 MPP 架构,包含多个节点,我们的目标是把数据尽可能均匀地分布 。数据仓库的性能会受这些决策影响;一旦设计不当,后续修改既痛苦 又耗时 ------这曾是数据工程师的日常工作。而在 Snowflake 中,这一流程由平台代为管理 :我们可以向事实表摄取 TB 级数据 ,Snowflake 会负责数据的分布与存储优化,确保以最高效的方式落盘。书中稍后会深入介绍。
值得一提的是,尽管 Snowflake 以其独特的 DWaaS 产品形态有了一个良好开局,近邻竞品 也在大力投入创新以匹配其能力。我们已提到 Amazon Redshift 作为首个真正的云端 MPP 数据仓库:为解决计算与存储独立扩展 的限制,Redshift 在 2019 年末 发布了新的 RA3 实例类型;2022 年 ,AWS 又推出 Amazon Redshift Serverless,让你无需预先配置集群即可管理工作负载。
云计算理论的最后一个方面是共享责任模型(Shared Responsibility Model,SRM) 。图 1-6 展示了 SRM 的关键要素。
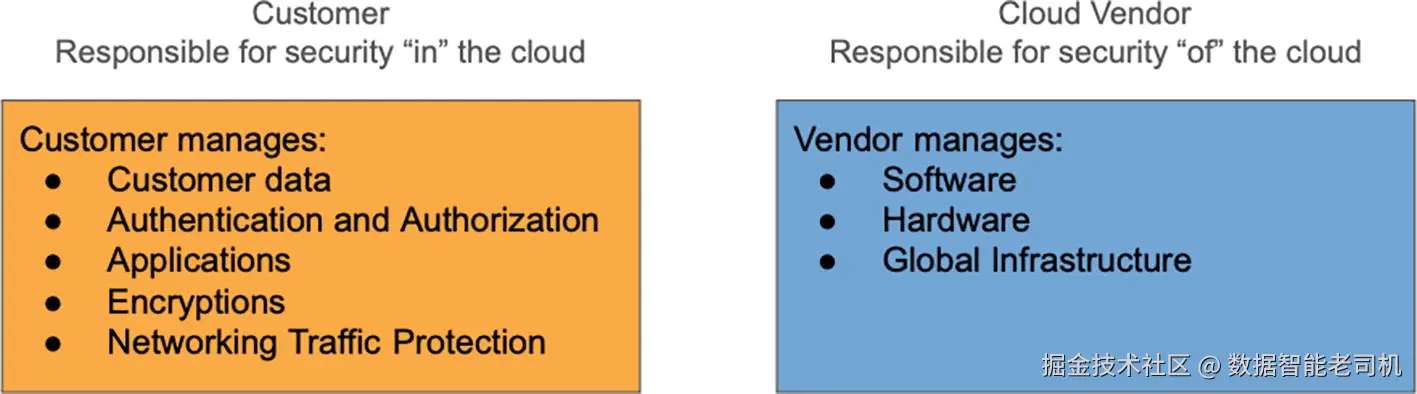
共享责任模型(SRM) 包含许多要素,但核心思想是:云厂商负责"云之安全",客户负责"云中的安全" 。也就是说,客户应制定自身的安全策略,并采纳数据安全的最佳实践来保护其数据。
谈到云时,需要了解云资源托管在各个数据中心,并存在区域(region) 这一概念。你可以在以下页面查阅不同云厂商与区域的 Snowflake 可用性信息:docs.snowflake.net/manuals/use...。
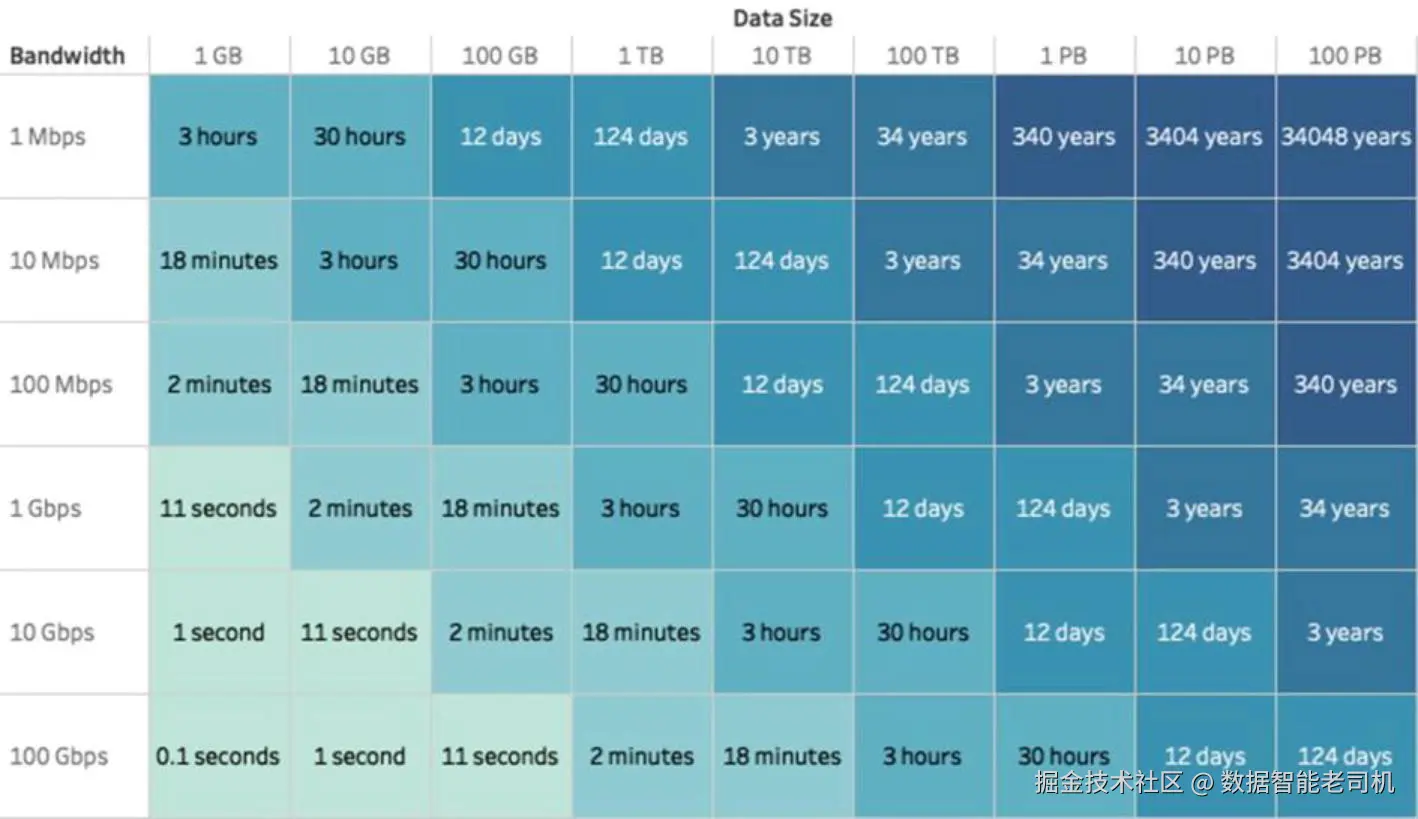
这张表在把数据仓库从本地(on-premises)迁移到云上时是一个有用的参考。关于数据仓库的迁移与现代化,你可以在第 14 章了解更多。
走近 Snowflake(Meet Snowflake)
Snowflake 是首个自底向上为云而生的数据仓库,是同类最佳的 DWaaS(数据仓库即服务) 。它运行在主流云服务商之上,如 Amazon Web Services 与 Microsoft Azure ,并已宣布在 Google Cloud Platform 上提供可用性。因此,我们可以在任一主流云厂商的平台上部署这一数据仓库。与传统数据仓库相比,Snowflake 更快、更易用、也更灵活;它负责认证、配置、资源管理、数据保护、可用性与优化等各个方面。
上手 Snowflake 很容易:选择合适的版本并注册即可。你可以从免费试用 开始,了解 Snowflake 的关键特性,或在 trial.snowflake.com 与其他数据仓库平台进行对比。你可以立即加载数据并获取洞见。Snowflake 的所有服务组件都运行在公有云基础设施上。
注 :Snowflake 无法运行在私有云基础设施(本地或托管环境)中;它并非用户可自行安装的"打包软件"。Snowflake 负责所有软件安装与更新的工作。
Snowflake 自底层重新构建,旨在应对现代大数据与分析挑战。它结合了 SMP 与 MPP 架构的优势,并充分利用云 。图 1-8 展示了 Snowflake 的架构。 在进入下一节之前,请参见图 1-7 ,其中展示了数据上传到云所需的时间 ;该参考来自 Google Cloud Platform 的演示文稿。
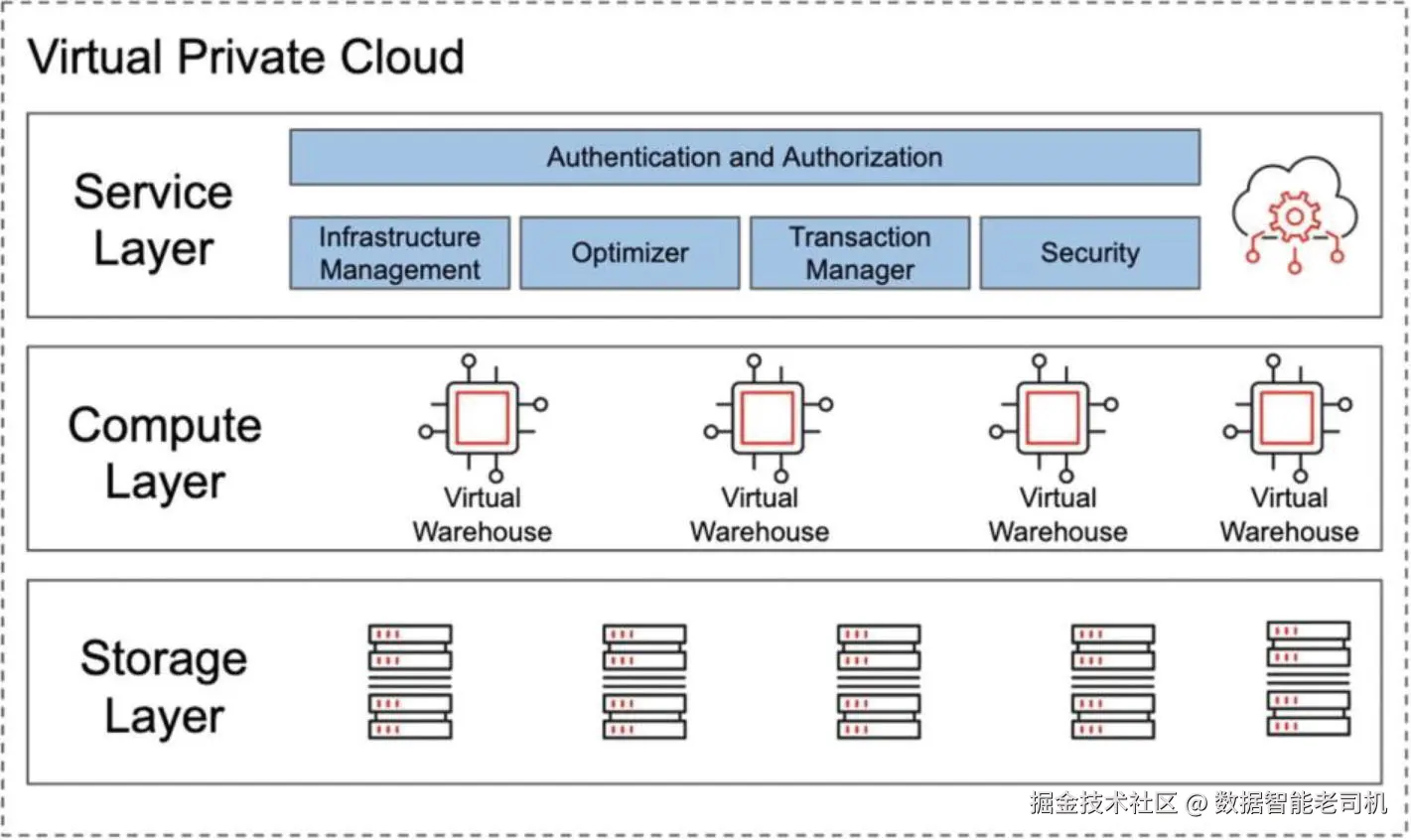
与 SMP 架构相似,Snowflake 采用一个中心化存储 ,所有计算节点都可访问。与此同时,类似 MPP 架构,Snowflake 使用 MPP 计算集群 来处理查询,这些集群也称为虚拟仓库(virtual warehouses) 。因此,Snowflake 将数据管理的简洁性与可伸缩性 ,与 MPP 式的**无共享(share-nothing)**架构相结合。
如图 1-8 所示,Snowflake 的架构由三个主要层次构成。表 1-5 对每一层做了说明。
表 1-5 Snowflake 的关键层次
| 层次 | 说明 |
|---|---|
| 服务层(Service layer) | 由一组用于协调 Snowflake 工作的服务组成,运行在专用实例上,包括认证 、基础设施管理 、元数据管理 、查询解析与优化 、访问控制等。 |
| 计算层(Compute layer) | 由**虚拟仓库(Virtual Warehouses,VW)**构成。每个 VW 都是一个 MPP 计算集群,由多台计算节点组成;各个 VW 彼此独立 、不共享资源。 |
| 存储层(Storage layer) | 通过云存储以内部压缩列式格式 保存数据。例如在 AWS 上使用 S3 ,在 Azure 上使用 Blob Storage 。Snowflake 负责存储的全部管理,客户不能直接 访问底层文件存储;数据只能通过 SQL 访问。 |
换句话说,Snowflake 通过利用云端的存储与计算,提供近乎无限 的计算和存储能力。看一个传统组织的例子:你有一个数据仓库,每晚运行 ETL(抽取-转换-加载) 。在 ETL 高峰期,业务用户几乎无法顺畅使用数据仓库,可用资源也很紧张。与此同时,市场部 需要跑复杂查询做归因模型 ,库存团队 要跑报表并优化库存。也就是说,组织里的每个流程与团队都很重要,但数据仓库成了瓶颈 。
在 Snowflake 场景下,每个团队/部门都可以拥有自己的虚拟仓库 ,并可根据需求即时扩容或缩容 。此外,ETL 流程也可以有自己只在夜间运行 的虚拟仓库。这样一来,数据仓库不再是瓶颈,组织能够释放数据潜能 。同时,组织只为实际使用 的资源付费------无需购买昂贵设备,也无需为未来负载操心。Snowflake 真正实现了数据的民主化,将近乎无限的能力交到业务用户手中。
除了可伸缩与简洁,Snowflake 还提供了许多此前不存在、其他云端或本地数据仓库也不具备 的特性,例如:数据共享(data sharing) 、时光回溯(time travel) 、数据库复制与故障切换、**零拷贝克隆(zero-copy cloning)**等(本书将进一步讨论)。
小结
本章简要回顾了数据仓库的发展史,并讲解了云计算基础,为理解为何 Snowflake 会进入市场、以及为何云 代表数据仓库与现代分析的未来提供了背景。你也了解了 Snowflake 的独特架构 及其关键层次。下一章将介绍如何开始使用 Snowflake。