在开始动手使用数据工程工具之前,先总体梳理一下数据工程师在构建基础设施时需要完成的任务。我们还将介绍常见的日志记录架构,并讨论工具在格式化日志数据时常用的数据序列化结构,包括 JSON 和 YAML。
常见数据工程任务
本节将介绍数据工程师通常要做的几类工作、可能遇到的挑战,以及为实现组织目标可以采用的策略。
将数据送入 SIEM
安全信息与事件管理系统(Security Information and Event Manager,SIEM) 是一个集中存放与安全相关数据的数据库。分析人员使用 SIEM 工具读取全组织范围内的日志、在各类仪表板中查看安全告警,并将看似无关的数据点进行关联,从而理解环境中发生的活动。在许多组织里,SIEM 对事件响应至关重要------例如,分析人员可以查看勒索软件的指示器(IoC),以便隔离主机或拦截恶意邮件发件人。
然而,把数据送入 SIEM 本身就可能充满挑战。对安全分析有用的数据(如登录事件、启动的进程、从互联网下载的文件等)来源各不相同:Windows、Linux、Unix 等操作系统,各类网络设备,甚至自研应用------它们彼此都有差异。贯穿全书,你将使用能够跨越这些障碍的工具,从多个来源采集数据;你还会在送入 SIEM 进行分析之前,对这些异构数据进行标准化处理。
本书默认将 SIEM 数据库作为安全数据的接收端,但若你愿意,也可以把数据发送到其他地方。书中许多示例会展示终端中的命令输出;这些输出也反映了传输到数据库进行存储时的事件格式。
管理吞吐量与延迟
在设计数据管道时,数据工程师力求降低延迟(latency) ------即事件进入数据管道或系统与其最终输出之间的时间差。延迟可能出现在多个场景:例如,用户向数据库发送请求后需要等待响应;又如,一条日志在落入 SIEM 前必须经过一条计算密集型的管道。
延迟会对安全数据管道造成影响:当通过的事件过多导致管道拥塞,或服务器故障减少了可用的处理节点时,重要告警(如数据窃取或勒索软件的指示器)就可能无法实时到达分析人员。
降低延迟的一种方法,是尽量精简处理流程 并避免过度复杂的代码。延迟也可能源于较高的计算需求、字符编码/解码、磁盘写入速度或网络瓶颈。我们将在全书中通过 if-else 等条件逻辑来避免不必要的处理。
作为数据工程师,你也需要理解负载均衡 与吞吐量 的概念。负载均衡是指将大量数据流分发给多个接收端,以避免单个接收服务器过载。虽然本书不会实现专用的负载均衡器,但我们将讨论的若干工具自带此类功能。
吞吐量(throughput)是指在给定时间内通过管道或系统的数据总量 。你应尽力提升吞吐量------如果你的目标是搬运海量安全数据,就应尽可能更快地完成。我们会在更高层面讨论如何避免瓶颈、提升吞吐。
事件的丰富化与标准化
除了将来自不同系统的日志发送到 SIEM,数据工程师还可能需要对这些日志进行丰富化(enrichment)与标准化 。丰富化是指为数据添加有用信息。例如:为传感器告警中的网络 IP 地址补充主机名;为用户访问的网站添加信誉评分或"恶意"标签;为常被入侵者在"借用系统工具"(living-off-the-land)手法中使用的命令打上标记,便于审查。
数据丰富化可以帮助分析人员排序优先级并减轻工作量 。如果他们经常需要查询与某类事件相关的特定属性(比如某个 IP 对应的主机名),那就可以考虑在管道内直接丰富这些数据源,以免分析人员反复人工查询。
同样地,标准化 数据也很重要,因为进入管道的事件可能具有多种格式。
- 结构化数据(structured) :整齐地组织为行列,如关系型数据库表。
- 半结构化数据(semi-structured) :以 JSON 、XML 、CSV 等格式保存。结构化数据通常已存入数据库并可用 SQL 查询;而半结构化数据多为工具与传感器的输出,处于向结构化数据转换并入库的准备阶段,或用于存入文档型数据库 。若需在数据库外使用半结构化数据,通常要借助命令行工具进行读取或解析。书中许多章节会在数据进入 SIEM 之前将其转换为 JSON。
- 非结构化数据(unstructured) :如图像、原始文本块、音频或二进制文件,通常不适合直接存入关系型数据库。若存入数据库,往往会带有描述其内容的元数据字段。
标准化后的数据能减少分析人员在跨来源关联 时的工作量。例如,若两台网络设备的日志格式不同,一个设计糟糕的管道可能要求分析人员自行处理这些差异,徒增分析开销;而设计良好的管道应将数据处理为统一格式 ,使工具之间的差异与分析人员无关。
本书主要处理时间序列数据(time-series) ------即带有时间戳、可用于确定事件顺序的数据。我们将从非结构化与半结构化的事件日志中解析时间戳与关键信息。我们也会简要涉及非时间序列 数据,如 Nmap 扫描结果的内容。非时间序列数据的其他例子包括:纯文本文档、网页抓取、姓名与地址、商品价格,以及某些类型的威胁指示器。
示例架构
数据管道本质上是一个转换过程:借助工具、脚本,甚至用户输入来加工并存储数据。数据工程师如何构建满足上一节目标的数据管道?下面介绍几种可用本书所述工具与配置实现的网络设计。
务必记住:可用性的敌人是无谓的复杂性 。避免对数据管道过度工程化 ,并保持目标切实可行。
一个基础数据管道
最基本的数据管道由三部分组成:数据源 (如组织内的网络设备或主机,负责生成并传输数据);接收与转换系统 ;以及存储系统 。例如,图 1-1 展示了一条示例管道:它接收来自联网设备传输的日志事件,将其格式化为 JSON,并将其存入数据库。
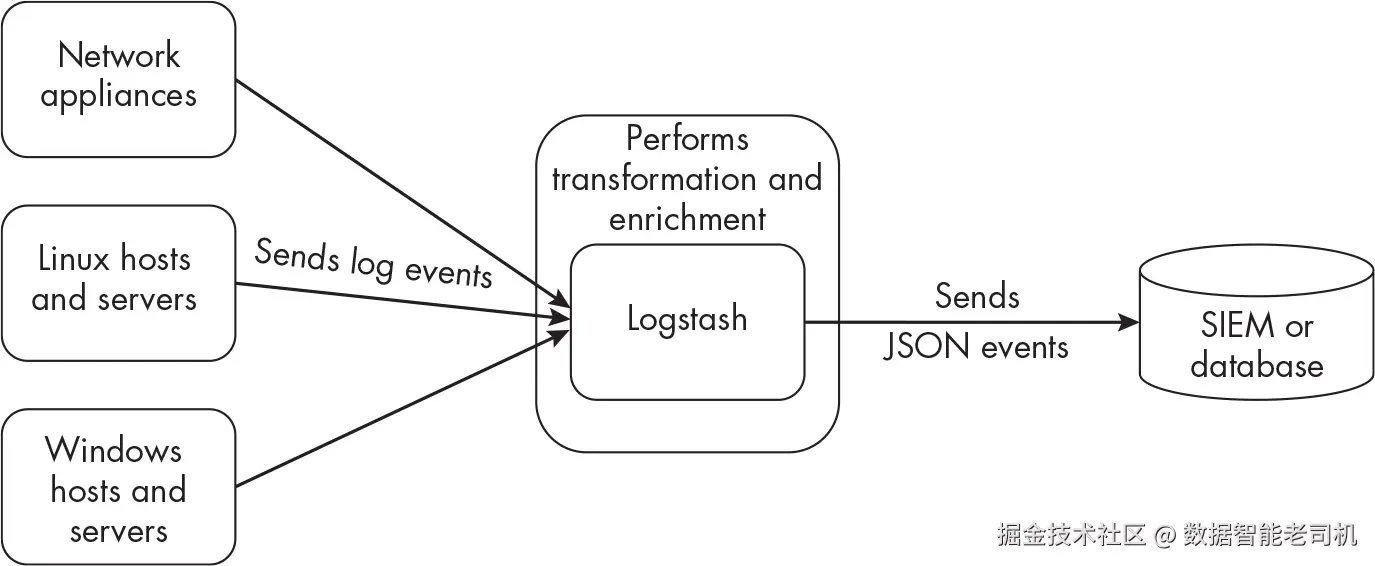
在这种设计中,环境中的各类设备都会把其日志数据发送到 Logstash ------这是一种用于接收与转换事件的工具(第 8、9 章会讲到)。Logstash 将所有事件转换为 JSON ,然后把数据加载到 SIEM 或某个数据库(例如 Elasticsearch )中。你会在第 6 章使用 Elasticsearch ;不过需要注意,Elasticsearch 并不是唯一能接收 JSON 数据的数据库 ,而 JSON 也只是众多数据库可能偏好的格式之一。
为从主机提取日志并将其传送到 Logstash ,你可以使用多种工具。第 4~7 章将分别介绍 Filebeat、Winlogbeat、Rsyslog 和 Elastic Agent 。这些工具可以从台式机、笔记本、服务器等主机采集日志 ,也能接收来自网络设备与传感器的日志。
这里展示的数据管道反映了最常见的场景:用户与计算机把数据发送到某处进行存储与分析 ,而数据工程师的职责就是确保数据到达目的地 。不过,数据管道也可以主动请求数据,下面将进行讨论。
主动式数据获取(Proactive Data Retrieval)
许多应用与云服务会通过 API(应用程序编程接口) 提供数据,允许你向服务发起请求 以获取数据。API 的类型五花八门:从天气预报、商业航班起降信息、恶意软件指示器,到数以百万计的其他数据点。你甚至可以使用 API 向之前用于分析的数据仓库/数据库发起请求,取回你曾经写入的数据。
我们将探讨使用多种工具(包括 Logstash )来接收 来自网络设备、服务器与主机的流式数据 ,并主动从 API 拉取数据,如图 1-2 所示。
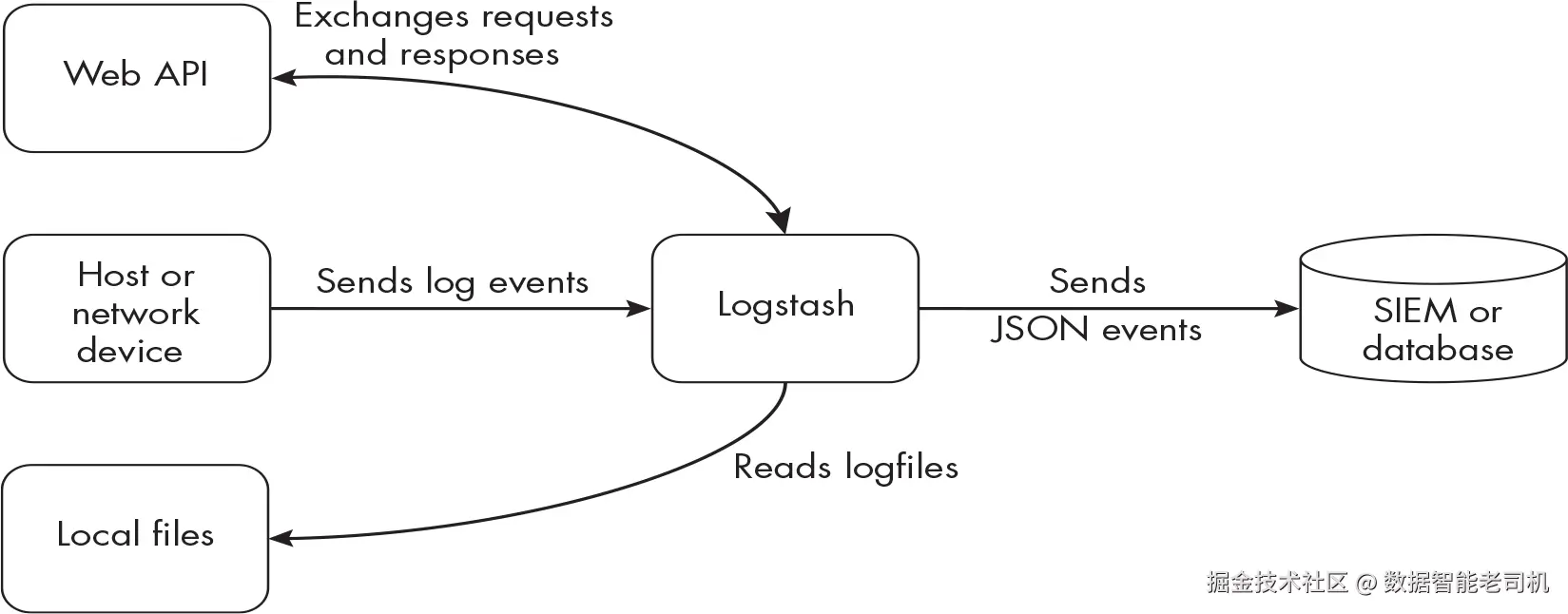
与前一个示例一样,Logstash 会在把事件发送到 SIEM 或数据库之前,获取所有事件并将其转换为 JSON 。不过,在这条管道中,Logstash 一方面接收 来自服务器的事件,另一方面还会通过 HTTPS 主动从 API 拉取 事件。举例来说,Logstash 可能会把某些 IP 地址、域名或文件哈希 发送到在线服务,以获取信誉评分 或将钓鱼域名 标记为恶意 。由于你不可能为互联网上的每个网站都拥有信誉评分,因此需要与外部服务提供商 交互以获取这类信息。此外,在这条管道里,Logstash 还会读取本地文件,然后再把它们发送到 SIEM。
临时性数据集中化(Temporary Data Centralization)
有时你需要把数据集中到一个服务 ,以便多个相关方 都能获得其副本。例如,组织的安全数据不仅与分析人员相关,也可能与合规团队、季节性审计人员 或内部威胁团队 相关。Kafka 是一个平台,用来连接数据发送方 与可能需要数据副本的消费者 ,并允许对流经其间的数据流 进行分析处理。该工具本身并不主动"传输"数据;相反,用户与服务通过连接 Kafka 来提供(发布)或接收(订阅)数据 。包含 Kafka 的管道可以是图 1-3 所示的样子。

在这条管道中,Filebeat 负责发布 (即连接并传输)数据到 Kafka 。Logstash 负责订阅 (即连接并接收)数据,然后对其进行转换并发送到数据库。我们将在第 10 章介绍 Kafka。
事件缓存(Event Caching)
缓存(cache)会把数据存放在系统内存中的数据库里,从而几乎即时 访问数据。将缓存工具加入你的数据管道,可以让你在事件进入 SIEM 之前,快速把"在途事件"与缓存中存放的值进行比对 并改写/丰富 事件。例如,第 13 章会使用缓存工具在事件中搜寻威胁情报(如恶意 IP 或域名),并据此丰富事件。关于这类缓存型管道的架构,我们将在该章展开详细说明。
数据序列化格式(Data Serialization Formats)
本书将反复讨论一个常见任务:让管道中的工具可访问 数据,这通常意味着要把不同来源的数据及其字段转换为统一格式。在动手之前,你需要理解常见的序列化格式。
序列化(serialization)是把某种编程语言内部的数据格式转成一种可在网络上传输 、与其他工具/语言交换 或存入数据库 的格式;反序列化(deserialization)则是反向过程,把通用语法再转回某种语言的内部表示。序列化/反序列化通常不是手工完成的;大多数编程语言都提供了相应的辅助函数。
接下来的章节中,我们会使用 JSON 序列化格式来组织数据;还会用 Elastic Common Schema(ECS) 来规范日志字段的命名。把数据转成 JSON 并应用 ECS 命名规范,有助于在管道中添加/删除/编辑 字段。最后,本节还会介绍 YAML ,我们将在后续章节用它编写配置文件。
JSON
JSON(JavaScript Object Notation) 以键-值对 的形式组织数据。几乎所有主流编程语言(不止 JavaScript)都在使用它,因为它对机器与人类都容易解析。很多时候你不需要自己手写或修改 JSON 结构------工具会替你完成。
JSON 的语法依赖引号与括号,例如:
json
'{"first_name": "Lily", "has_pets": true, "num_pets": 4, "pet_types": ["dog", "fish"]}'一个 JSON 字符串(上例用单引号 包裹整段)内部使用花括号 {} ,其中包含一个或多个相关的键-值对。如上例,括号内的键-值对描述的是名为 Lily 的人的属性。
键 必须是双引号 括起来的字符串;值 可以是多种数据类型。布尔值使用关键字 true/false 。数字不加引号(除非需要把它当作文本处理)。方括号 [] 表示数组(逗号分隔的值列表)。这种序列化后的字符串可供其他工具使用,也可存入支持 JSON 的数据库。
YAML
YAML 是短语 "YAML Ain't Markup Language" 的递归首字母缩写 。本书中,我们用 YAML 来创建/编辑配置文件,而不是用来传输或接收数据。你会从零编写大量 YAML 配置,因此需要熟悉其格式。
YAML 同样使用键-值对 ,但它依靠空白与缩进 而不是 JSON 的引号与括号来表达字段之间的层级关系。下面的片段展示了第 4 章将要配置的 filebeat.yml 的一部分(具体行此处无关紧要,留意层级缩进语法):
yaml
output.logstash:
enabled: true
hosts: ["logstash01:5044", "logstash02:5044"]
ssl.enabled: true
ssl.verification_mode: full
ssl.certificate: "wildcard.local.flex.cert.pem"
ssl.key: "wildcard.local.flex.key.pem"
ssl.key_passphrase: "abcd1234"
ssl.certificate_authorities:
- ca.cert.pem
- ca-int.cert.pem
- ca-chain.cert.pem在 YAML 中,缩进 用于表达行与行之间的从属关系 。在 output.logstash 元素下,相关设置被嵌套 (即缩进在其下)。列表既可以用方括号 (类似 Python 列表或 Ruby 数组,如 hosts),也可以使用连字符 - 的形式(如 ssl.certificate_authorities)。一般来说,引号是可选的 ------上面 ssl 相关行用了引号,其他行没有。
Elastic Common Schema(ECS)
ECS 是标准化的数据命名规范 (不是序列化格式),本书将贯穿使用。采集/处理日志的工具,常会把同一个字段(如"源 IP 地址")起成不同的名字:sip、src_ip、sourceip......使用 ECS 时,这些字段会统一为 source.ip 。常用 ECS 字段的概览见:
www.elastic.co/guide/en/ec...
以这种方式标准化数据,可以让你在构建数据管道时更轻松:你无需为了同一类数据 去适配不同工具的字段名 (除了在管道中把它们重命名为标准名 这一环节)。分析也会更简单:分析人员无需记住"某工具叫这个、另一工具叫那个",他们只需在所有工具中使用同一个通用字段名。
接下来,介绍后续章节的环境准备。
虚拟机环境(Virtual Machine Setup)
本书主要使用 Ubuntu Linux ,部分章节也会给出 Red Hat Enterprise Linux(RHEL) 等系统的命令。可从以下链接免费下载:
- Ubuntu:ubuntu.com/download/de...
- Red Hat(注册免费账户后):developers.redhat.com/products/rh...
为了跟随本书示例,建议配置 3 台 Linux 虚拟机 :一台作为主工作站 ,另外两台用于机器间数据传送 的练习。当然,你也可以只用两台,甚至一台(勉强可行)。但若只有一台,将无法练习集群 或同一应用多节点并行运行。
第 5 章将介绍 Winlogbeat (读取 Windows 事件日志的工具)。若想在虚拟机中练习,可注册微软账户后下载免费评估版 Windows;或者如果你的电脑本身跑的是 Windows,也可以直接安装在宿主上。第 5 章的步骤不会破坏系统 ,虽然部分内容需要更改域组策略,但完成后可以卸载 Winlogbeat 并停止收集事件日志。
本书中的所有工具均在 Ubuntu 与 Red Hat 虚拟机上测试通过,配置为 4GB RAM、2 CPU、50GB SSD 。你可以按需增加资源;在生产环境 中这些数值应高得多 。网络建议使用大多数虚拟机工具常见的 NAT(网络地址转换) :让同一物理宿主上的虚拟机彼此通信并访问互联网以下载文件,同时不会把你的虚拟机直接暴露给更广的网络。
网上有大量优秀的虚拟机安装教程,你可以自行选择虚拟化工具/管理程序(hypervisor) 。安装完成并验证工作正常后,请为每台虚拟机创建一个基线快照 。此后每当你配置一个新工具,建议关机并再次快照 以保留进度;这样一来,若后续出现问题,可以回滚至可用状态。
Windows 下的文件传输与 Shell 访问工具
如果你用 Windows 宿主来运行 Linux 虚拟机,建议安装两款工具以便文件传输 与 Shell 访问:
- WinSCP :在 Windows 与虚拟机之间搬运文件
winscp.net/eng/downloa... - PuTTY :SSH 客户端,可从 Windows 直接连接到虚拟机命令行(无需打开每台虚拟机的图形界面)
www.chiark.greenend.org.uk/~sgtatham/p...
注意:Windows 自带 SSH 客户端,但缺少一些让 PuTTY 更值得使用的功能。
其他实用工具
Linux 下的 jq 可读取 JSON 并在终端以缩进与配色友好展示。虽然本书示例不强制使用它,但对查看我们处理的数据很有帮助。可在工作站虚拟机上安装:
sudo apt install jq基本用法:读取整个 JSON 文件
arduino
jq '.' file.json读取特定字段(如 message):
css
jq '.["message"]' file.json最后,你需要一款轻量文本编辑器 来修改大量配置文件。推荐 Visual Studio Code 或 Windows 下的 Notepad++ ,它们支持语法高亮、多行编辑、正则查找替换等:
- VS Code:code.visualstudio.com
- Notepad++:notepad-plus-plus.org/downloads/
总结(Summary)
至此,你已了解网络安全数据工程师 的基础任务,并完成了环境搭建。接下来就可以开始学习如何为你的家庭实验室、企业或客户 采集、处理与存储数据了。本书中的工具将帮助你以服务目标所需的方式获取并塑形安全数据。让我们开始吧!