🚀 特别适合
- 想系统补强AI知识的开发者
- 转型人工智能领域的从业者
- 需要项目经验的学生
2.正文
2.1引入事务概念
2.1.1什么是事务
在日常开发中,我们经常需要确保一系列操作要么全部成功,要么全部失败------这就是事务的核心价值。简单来说,事务是数据库管理系统执行过程中的一个逻辑单位,由有限的数据库操作序列构成,这些操作要么全部执行,要么都不执行,以此保证数据的一致性和完整性。比如银行APP的转账功能,"扣款"和"入账"两个操作必须在同一个事务中完成,否则可能出现"扣款成功但对方未收到"的异常情况。
2.1.2事务的基本操作指令
数据库为事务提供了标准操作接口,开发者可通过以下指令控制事务生命周期:
- 开启事务:
start transaction或begin transaction - 提交事务 :
commit(确认所有操作生效) - 回滚事务 :
rollback(取消所有操作,恢复到事务开始前状态)
这些指令看似简单,却是构建可靠业务系统的基础。
2.1.3为什么需要事务
在日常开发中,数据一致性是业务可靠性的基石。想象这样一个场景:用户注册时,系统需要完成"插入用户信息"和"记录操作日志"两个步骤。如果没有事务保障,可能出现用户信息插入成功,但日志记录失败的情况,最终导致数据不一致------这就是事务要解决的核心问题。
总之,事务是保障数据一致性的"安全网",而 Spring 事务则是这张网的"智能控制系统"------既解决了无事务时的数据混乱问题,又通过简化配置和精准控制,让开发者在复杂业务中依然能轻松确保数据可靠性。
2.2Spring中的事务实现
2.2.1数据与代码的准备
为了更直观地理解 Spring 事务传播机制,我们以用户注册功能为业务场景展开分析。该场景中,用户注册时需要完成两项核心操作:将用户信息存入用户表(T_USER),同时将注册行为记录到日志表(T_LOG)。这两个操作的原子性(要么同时成功,要么同时失败)是事务管理的关键,也是后续演示传播机制的基础。
数据库表结构设计
首先创建核心业务表,用于存储用户数据和操作日志:
sql
-- 创建数据库
DROP DATABASE IF EXISTS trans_test;
CREATE DATABASE trans_test DEFAULT CHARACTER SET utf8mb4;
USE trans_test;
-- 用户表
DROP TABLE IF EXISTS user_info;
CREATE TABLE user_info (
`id` INT NOT NULL AUTO_INCREMENT,
`user_name` VARCHAR(128) NOT NULL,
`password` VARCHAR(128) NOT NULL,
`create_time` DATETIME DEFAULT now(),
`update_time` DATETIME DEFAULT now() ON UPDATE now(),
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8mb4 COMMENT='用户表';
-- 操作日志表
DROP TABLE IF EXISTS log_info;
CREATE TABLE log_info (
`id` INT PRIMARY KEY AUTO_INCREMENT,
`user_name` VARCHAR(128) NOT NULL,
`op` VARCHAR(256) NOT NULL,
`create_time` DATETIME DEFAULT now(),
`update_time` DATETIME DEFAULT now() ON UPDATE now()
) DEFAULT CHARSET=utf8mb4;
AI写代码sql核心代码组件解析
实体类(Entity)
typescript
@Data
public class LogInfo {
private Integer id;
private String userName;
private String op;
private Date createTime;
private Date updateTime;
}
AI写代码java
运行
typescript
@Data
public class UserInfo {
private Integer id;
private String userName;
private String password;
private Date createTime;
private Date updateTime;
}
AI写代码java
运行数据访问层接口(Mapper)
java
@Mapper
public interface LogInfoMapper {
@Insert("insert into log_info(`user_name`,`op`)values(#{name},#{op})")
Integer insertLog(String name,String op);
}
AI写代码java
运行
java
@Mapper
public interface UserInfoMapper {
@Insert("insert into user_info(`user_name`,`password`)values(#{name},#{password})")
Integer insert(String name,String password);
}
AI写代码java
运行业务服务层(Service)
less
@Slf4j
@Service
public class LogService {
@Autowired
private LogInfoMapper logInfoMapper;
public void insertLog(String name, String op){
//插入用户信息
logInfoMapper.insertLog(name, op);
}
}
AI写代码java
运行
less
@Slf4j
@Service
public class UserService {
@Autowired
private UserInfoMapper userInfoMapper;
public void registryUser(String name, String password){
//插入用户信息
userInfoMapper.insert(name, password);
}
}
AI写代码java
运行上述代码构建了用户注册的基础业务框架:当调用 UserService.registryUser 时,会依次执行用户插入和日志插入操作。后续章节将通过在这些方法上添加 @Transactional 注解并配置不同传播属性(如 REQUIRED、REQUIRES_NEW 等),结合异常场景(如注册过程中抛出异常),直观展示事务传播机制如何影响两个操作的数据一致性。
2.2.2编程式事务
在 Spring 中,编程式事务是通过手动编写代码来控制事务的开启、提交和回滚过程,适用于需要明确且细粒度控制事务边界 的场景。这种方式直接通过 TransactionManager 或 TransactionTemplate 操作事务,让开发者能精确管理事务的生命周期。
代码实现示例
以下是 UserController 中使用编程式事务的典型代码片段,通过 PlatformTransactionManager 手动控制事务:
less
@RequestMapping("/user")
@RestController
public class UserController {
//JDBC事务管理器
@Autowired
private DataSourceTransactionManager dataSourceTransactionManager;
//定义事务属性
@Autowired
private TransactionDefinition transactionDefinition;
@Autowired
private UserService userService;
@RequestMapping("/registry")
public String registry(String name, String password) {
//开启事务
TransactionStatus transactionStatus = dataSourceTransactionManager
.getTransaction(transactionDefinition);
//用户注册
userService.registryUser(name, password);
//提交事务
//dataSourceTransactionManager.commit(transactionStatus);
//回滚事务
dataSourceTransactionManager.rollback(transactionStatus);
return "注册成功";
}
}
AI写代码java
运行事务控制原理分析
编程式事务通过 TransactionManager 接口实现事务管理:当调用 getTransaction() 时「底层会根据事务定义从数据源获取数据库连接,并设置自动提交为 false 」;业务执行期间所有操作共享该连接; commit() 会触发数据库提交命令, rollback() 则执行回滚命令并释放连接。这种机制保证了事务内多个操作的原子性。
核心缺点:代码与事务逻辑强耦合
- 事务控制代码(开启/提交/回滚)与业务逻辑混杂,导致代码臃肿、可读性下降。
- 重复劳动:每个事务方法都需编写类似模板代码,增加维护成本。
- 侵入性高:修改事务属性需改动业务代码,不符合「开闭原则」。
虽然编程式事务在特殊场景(如动态调整事务参数)中仍有价值,但在日常开发中,我们更需要一种能解耦事务控制与业务代码 的方案------这正是声明式事务要解决的核心问题。
2.2.3声明式事务@Transaction
在Spring框架中,声明式事务通过@Transactional注解实现了事务管理的"优雅降级"------无需手动编写beginTransaction()、commit()、rollback()等样板代码,只需一个注解就能让方法具备事务特性。这种"无侵入式"设计极大简化了开发流程,尤其在复杂业务场景中更能体现其价值。
事务行为对比实验
我们通过两个注册方法的执行结果,直观感受rollbackFor属性的关键作用:
registry1(事务未回滚)``
typescript
@Transactional // 未指定rollbackFor,默认仅回滚RuntimeException
public void registry1(String name, String password) {
userService.registryUser(name, password); // 步骤1:保存用户
try {
logService.insertLog(name, "用户注册"); // 步骤2:插入日志(假设抛出IOException)
} catch (IOException e) {
// 异常被捕获但未抛出,事务无法感知
}
}
AI写代码java
运行结果 :用户数据被保存,日志插入失败但事务未回滚
registry2(事务回滚)``
typescript
@Transactional(rollbackFor = Exception.class) // 显式指定回滚所有Exception
public void registry2(String name, String password) {
userService.registryUser(name, password); // 步骤1:保存用户
logService.insertLog(name, "用户注册"); // 步骤2:插入日志(抛出IOException)
}
AI写代码java
运行结果:日志插入失败后,用户数据也被回滚,保持数据一致性
从上述对比可以清晰看到,声明式事务的核心优势在于:
无侵入性:通过AOP在方法执行前后自动织入事务逻辑,业务代码与事务控制完全分离
配置简单:在Spring Boot中仅需两步即可启用:
less// 1. 入口类添加注解开启事务管理 @SpringBootApplication @EnableTransactionManagement public class Application { ... } // 2. 业务方法添加@Transactional注解 @Transactional(propagation = Propagation.REQUIRED) public void businessMethod() { ... } AI写代码java 运行
这种设计让开发者能专注于业务逻辑,而事务的创建、提交、回滚等复杂操作则由Spring容器自动完成。不过,要充分发挥@Transactional的威力,还需要深入理解其背后的属性配置------比如传播行为如何控制嵌套事务、隔离级别如何避免并发问题等。接下来,我们将逐一解析这些核心属性的工作原理与实战配置。
2.3@Transaction详解
2.3.1rollbackFor
在使用 Spring 事务时,你可能遇到过这样的困惑:明明方法抛出了异常,数据库操作却没有回滚?这很可能与 @Transactional 注解的默认回滚机制有关。
Spring 事务的默认行为是仅在方法抛出未被捕获的 RuntimeException 或 Error 时才会触发回滚 ,而对于受检异常(如 IOException、SQLException 等 Exception 的直接子类),即使未被捕获也不会回滚事务。更需要注意的是,如果异常被 try-catch 捕获且未重新抛出,即使是运行时异常也不会触发回滚。
典型误区示例 :假设在 registry1 方法中执行数据库插入操作,过程中抛出 ArithmeticException(运行时异常),但被 try-catch 块捕获后未重新抛出:
csharp
@Transactional
public void registry1() {
try {
userDao.insert(user); // 数据库操作
int i = 1 / 0; // 抛出 ArithmeticException
} catch (ArithmeticException e) {
log.error("发生异常", e);
// 未重新抛出异常
}
}
AI写代码java
运行此时事务不会回滚,usermapper.insert 的结果会被提交到数据库。
若希望受检异常或特定异常触发回滚,需通过 @Transactional 的 rollbackFor 属性显式指定异常类型。例如,当设置 rollbackFor = Exception.class 时,所有 Exception 及其子类(包括受检异常)抛出时都会触发事务回滚。
正确用法示例 :在 registry2 方法中,指定 rollbackFor = Exception.class 后,即使抛出受检异常 IOException,事务也会回滚:
java
@Transactional(rollbackFor = Exception.class)
public void registry2() throws IOException {
userDao.insert(user); // 数据库操作
throw new IOException("文件读取失败"); // 受检异常,触发回滚
}
AI写代码java
运行此时 usermapper 的操作会被回滚,数据库不会留下新增记录 。
总结来说,rollbackFor 的核心作用是自定义事务回滚的异常触发条件 ,打破默认仅回滚 RuntimeException 和 Error 的限制。实际开发中需根据业务场景,明确指定所有需要触发回滚的异常类型,避免因异常类型或捕获方式不当导致事务失效。
2.3.2事务隔离级别
在多事务并发执行时,可能出现脏读、不可重复读、幻读等数据一致性问题。事务隔离级别通过控制并发事务间的数据可见性,平衡数据一致性与系统性能,是保障业务正确性的核心机制之一。
Spring 事务隔离级别定义
Spring 基于 SQL92 标准封装了五种事务隔离级别,通过 Isolation 枚举类定义,本质是对数据库隔离级别的抽象适配。枚举源码如下:
scss
public enum Isolation {
DEFAULT(-1), // 依赖数据库默认隔离级别
READ_UNCOMMITTED(1), // 读未提交
READ_COMMITTED(2), // 读已提交
REPEATABLE_READ(4), // 可重复读
SERIALIZABLE(8); // 串行化
private final int value;
private Isolation(int value) { this.value = value; }
public int value() { return this.value; }
}
AI写代码java
运行其中 DEFAULT 是 Spring 事务的默认配置,实际隔离级别由底层数据库决定(如 MySQL 默认 REPEATABLE_READ,Oracle 默认 READ_COMMITTED)。
核心隔离级别解析
1. DEFAULT (默认隔离级别)
- 特性:不定义具体隔离规则,但继承数据库自身默认级别。
- 应用场景:大多数无特殊一致性要求的业务,如电商商品浏览、内容管理系统。
- 风险提示 :需明确底层数据库默认级别(如 MySQL 为
REPEATABLE_READ,PostgreSQL 为READ_COMMITTED),避免跨库部署时出现行为差异。
2. READ_COMMITTED (读已提交)
定义:事务只能读取其他事务已提交的数据,可避免脏读,但可能出现不可重复读。
数据库支持 : Oracle、SQL Server 等默认隔离级别,MySQL 通过
SET TRANSACTION ISOLATION LEVEL READ COMMITTED手动开启。示例流程:
sqlSET TRANSACTION ISOLATION LEVEL READ COMMITTED; -- 设置隔离级别为读已提交事务A: SELECT balance FROM accounts WHERE id=1; -- 返回1000 -- 事务B更新balance=1500并提交 事务A: SELECT balance FROM accounts WHERE id=1; -- 返回1500 (不可重复读现象) AI写代码sql
3.REPEATABLE_READ (可重复读)
- 定义: MySQL InnoDB 默认隔离级别,通过 MVCC (多版本并发控制) 机制创建数据快照,确保同一事务内多次读取结果一致,并通过 Next-Key Lock (记录锁 +间隙锁) 防止幻读。
- 核心优势: 在并发读写场景下平衡一致性与性能,既能防止脏读、不可重复读,又通过行级锁减少锁竞争。
- 典型应用: 金融核心系统 (如账户余额管理)、库存扣减等需强一致性的场景。
| 隔离级别 (Isolation Level) | Spring 中常量值 | 脏读 (Dirty Read) | 不可重复读 (Non-Repeatable Read) | 幻读 (Phantom Read) | |
|---|---|---|---|---|---|
| 默认 (Default) | Isolation.DEFAULT |
取决于数据库 | 取决于数据库 | 取决于数据库 | |
| 读未提交 (Read Uncommitted) | Isolation.READ_UNCOMMITTED |
✅ 可能 | ✅ 可能 | ✅ 可能 | |
| 读已提交 (Read Committed) | Isolation.READ_COMMITTED |
❌ 避免 | ✅ 可能 | ✅ 可能 | |
| 可重复读 (Repeatable Read) | Isolation.REPEATABLE_READ |
❌ 避免 | ❌ 避免 | ✅ 可能 | |
| 串行化 (Serializable) | Isolation.SERIALIZABLE |
❌ 避免 | ❌ 避免 | ❌ 避免 |
注: MySQL 在 REPEATABLE_READ 级别通过 Next-Key Lock 解决幻读,而 SQL 标准定义此级别仍可能出现幻读。
实战配置与最佳实践
在 Spring 中通过 @Transactional 注解的 isolation 属性指定隔离级别:
java
// 金融交易服务: 使用可重复读保证余额一致性
@Service
public class FinancialTransactionService {
@Transactional(isolation = Isolation.REPEATABLE_READ)
public void transfer(Long fromId, Long toId, BigDecimal amount) {
// 1. 查询余额 (快照读,不受其他事务提交影响)
BigDecimal balance = accountMapper.selectBalance(fromId);
// 2. 校验余额并扣减
if (balance.compareTo(amount) < 0) {
throw new InsufficientFundsException();
}
accountMapper.updateBalance(fromId, balance.subtract(amount));
// 3. 转入目标账户
accountMapper.updateBalance(toId, accountMapper.selectBalance(toId).add(amount));
}
}
AI写代码java
运行选择建议:
- 高频读写场景 : 优先
READ_COMMITTED(如电商订单状态更新), 牺牲可重复读换取吞吐量。 - 数据强一致场景 : 强制
REPEATABLE_READ(如银行转账、库存锁定), 依赖 MySQL 幻读防护机制。 - 极端一致性需求 : 仅在对账、清算等场景使用
SERIALIZABLE, 需配合超时重试机制避免死锁。
通过合理配置隔离级别,可在并发性能与数据一致性间找到最优平衡点,这也是分布式系统设计中"CAP 取舍"的微观体现。
2.3.3事务传播机制
2.3.3.1什么是事务传播机制
在 Spring 事务管理中,事务传播机制 是针对事务嵌套场景的核心解决方案,它定义了多个事务方法嵌套调用时事务边界的控制规则------当一个事务方法(如用户注册)调用另一个事务方法(如日志记录)时,被调用方法如何处理现有事务上下文(如加入已有事务、创建新事务或不使用事务)。简单来说,它回答了"当方法 A(带事务)调用方法 B(带事务)时,B 的事务该如何与 A 的事务互动"这个关键问题。
核心作用:Spring 通过传播机制控制"哪些代码在同一个事务中执行,哪些不在",确保复杂业务流程中事务的一致性与隔离性。例如,订单支付流程中,"扣减库存"和"生成支付记录"方法是否共享事务,就由传播机制决定。
2.3.3.2与事务隔离级别的区别
很多开发者容易混淆事务传播机制和隔离级别,其实两者解决的问题截然不同:
- 隔离级别 :聚焦并发场景下的读写冲突 ,通过控制多个事务对同一数据的访问规则(如脏读、不可重复读、幻读)保证数据一致性(如
READ COMMITTED、REPEATABLE READ)。 - 传播机制 :聚焦事务嵌套关系,解决"多个事务方法互相调用时,事务如何在方法间传递"的问题(如方法 B 是否加入方法 A 的事务)。
生活场景理解:用户注册与日志记录
以常见的"用户注册"业务为例:
- 方法 A(用户注册) :带事务(传播机制
REQUIRED),负责保存用户信息到数据库。 - 方法 B(日志记录) :带事务(传播机制
REQUIRED),负责记录注册操作日志。
当 A 调用 B 时,传播机制 REQUIRED 会让 B "加入" A 的事务------两者共享同一个物理事务:如果注册失败(A 回滚),日志记录也会被回滚;如果日志记录失败(B 抛异常),整个注册流程同样会回滚。
反之,若 B 的传播机制为 REQUIRES_NEW,则会创建独立事务:即使注册失败(A 回滚),日志记录依然会提交,确保操作轨迹不丢失。这种灵活性正是传播机制的价值所在。
通过传播机制,Spring 允许开发者精细控制事务范围,既可以将多个操作"绑定"在同一事务中保证原子性,也可以将关键操作"隔离"在独立事务中确保数据安全性。
2.3.3.3事务传播机制有哪些
Spring 事务传播机制定义了多个事务方法嵌套调用时的行为规则,共包含七种类型,这些行为通过 org.springframework.transaction.annotation.Propagation 枚举类统一管理。理解传播机制是解决事务嵌套问题的核心,下面从定义、源码、关键属性对比三个维度展开说明。
定义
1. REQUIRED(默认传播行为)
- 定义 :如果当前存在事务,则加入该事务;如果当前没有事务,则创建新事务。这是
@Transactional注解的默认配置。 - 典型场景 :最常用的修改操作,如订单创建时需同时扣减库存。当 A 方法(REQUIRED)调用 B 方法(REQUIRED)时,B 会加入 A 的事务,若 B 抛出异常,A 和 B 的操作会一起回滚。
2. SUPPORTS
- 定义:如果当前存在事务,则加入该事务;如果当前没有事务,则以非事务方式执行。
- 典型场景:查询操作,如订单详情查询。当被事务方法调用时参与事务(保证数据一致性),独立调用时无需事务(提升性能)。
3. MANDATOR
- 定义 :必须在事务中执行,若当前没有事务则抛出
IllegalTransactionStateException异常。 - 典型场景:核心业务逻辑的后置处理,如订单支付成功后的日志记录,必须依赖上游事务存在。
4. REQUIRES_NEW(独立新事务)
- 定义:无论当前是否存在事务,均创建新事务;若当前有事务,则将其挂起。
- 实现机制:挂起现有事务 → 创建新事务 → 执行方法 → 提交/回滚新事务 → 恢复原有事务。
- 关键特性 :新事务独立于外部事务,外部事务回滚不影响新事务结果。例如,订单创建(外部事务)调用支付日志记录(REQUIRES_NEW),即使订单创建失败回滚,支付日志仍会保留。
5. NOT_SUPPORTED
- 定义:以非事务方式执行,若当前存在事务则挂起。
- 典型场景:耗时的只读操作,如数据报表生成,避免长期占用事务资源。
6. NEVER(禁止事务)
- 定义:以非事务方式执行,若当前存在事务则抛出异常。
- 使用注意:严格禁止在事务环境中调用,例如某些不允许事务参与的第三方接口调用。
7. NESTED(嵌套事务)
- 定义 :若当前存在事务,则以嵌套事务(基于数据库保存点)执行;若当前没有事务,行为同 REQUIRED。
- 实现依赖:需数据库支持保存点(如 MySQL InnoDB),嵌套事务回滚时仅回滚到保存点,不影响外部事务。
- 与 REQUIRES_NEW 区别:NESTED 是外部事务的子事务,依赖外部事务提交;REQUIRES_NEW 是完全独立的事务。
Propagation 枚举源码定义
Spring 通过 Propagation 枚举类定义七种传播行为,每个枚举值对应一个整数常量,源码如下:
scss
public enum Propagation {
REQUIRED(0), // 默认传播行为
SUPPORTS(1), // 支持事务或非事务执行
MANDATORY(2), // 必须在事务中执行
REQUIRES_NEW(3), // 新建独立事务
NOT_SUPPORTED(4), // 非事务执行,挂起现有事务
NEVER(5), // 禁止事务,存在则抛异常
NESTED(6); // 嵌套事务(基于保存点)
private final int value;
private Propagation(int value) { this.value = value; }
public int value() { return this.value; }
}
AI写代码java
运行通过 @Transactional(propagation = Propagation.XXX) 注解可指定传播行为,例如 @Transactional(propagation = Propagation.REQUIRES_NEW)。
传播机制关键属性对比表
| 传播行为名称 | 常量值 | 是否新建事务 | 当前事务存在时行为 | 当前事务不存在时行为 | 典型应用场景 |
|---|---|---|---|---|---|
| REQUIRED | 0 | 否(仅不存在时新建) | 加入当前事务 | 创建新事务 | 订单创建、库存扣减等核心操作 |
| SUPPORTS | 1 | 否 | 加入当前事务 | 非事务执行 | 订单详情查询 |
| MANDATORY | 2 | 否 | 加入当前事务 | 抛出异常 | 事务依赖的后置处理 |
| REQUIRES_NEW | 3 | 是 | 挂起当前事务,创建新事务 | 创建新事务 | 独立日志记录、第三方接口调用 |
| NOT_SUPPORTED | 4 | 否 | 挂起当前事务 | 非事务执行 | 耗时只读操作(报表生成) |
| NEVER | 5 | 否 | 抛出异常 | 非事务执行 | 禁止事务的第三方接口 |
| NESTED | 6 | 否(仅不存在时新建) | 基于保存点嵌套执行 | 同 REQUIRED(创建新事务) | 分步提交场景(如多步骤订单) |
注意事项:
- NESTED 依赖数据库支持:需数据库支持保存点(如 MySQL InnoDB),否则无法实现嵌套回滚。
- REQUIRES_NEW 与 NESTED 区别:前者是完全独立事务,后者是外部事务的子事务,外部事务回滚会导致 NESTED 事务也回滚,但 NESTED 内部回滚不影响外部事务。
- 默认传播行为:未指定时默认为 REQUIRED,需注意嵌套调用时的事务一致性问题。
2.3.3.4事务传播机制的使用
在Spring事务管理中,传播机制决定了多个事务方法嵌套调用时的行为模式。掌握不同传播机制的适用场景,能帮我们解决复杂业务中的数据一致性问题。下面通过实际场景和代码示例,详解四种常用传播机制的使用方式及核心区别。
REQUIRED:
REQUIRED 是Spring默认的传播机制,它的核心原则是"有则加入,无则新建"。当外层方法已存在事务时,内层方法会直接加入该事务,形成共享事务上下文;若外层无事务,则内层会创建新事务独立执行。
最典型的场景是业务流程中的强一致性需求,比如用户注册时同步创建账户和日志记录:
typescript
@Service
public class UserService {
@Autowired private LogService logService;
@Transactional(propagation = Propagation.REQUIRED) // 外层事务
public void register(User user) {
userMapper.insert(user); // 保存用户
logService.recordLog(user.getId(), "注册成功"); // 调用日志服务
}
}
@Service
public class LogService {
@Transactional(propagation = Propagation.REQUIRED) // 内层事务
public void recordLog(Long userId, String action) {
logMapper.insert(new Log(userId, action));
}
}
AI写代码java
运行此时用户注册和日志记录共享同一事务,若日志插入失败抛出异常,用户数据也会回滚,确保两者"同生共死"。
REQUIRES_NEW:
REQUIRES_NEW 与REQUIRED完全相反,它会强制创建新的独立事务,与外层事务彻底隔离。即使外层已有事务,内层方法也会挂起外层事务,新建物理事务执行,且内层事务的提交/回滚与外层互不影响。
典型应用于核心业务与非核心业务分离,比如订单支付失败时,支付记录需要回滚,但失败日志必须留存:
typescript
@Service
public class OrderService {
@Autowired private PaymentService paymentService;
@Autowired private LogService logService;
@Transactional(propagation = Propagation.REQUIRED) // 外层事务:订单支付
public void payOrder(Order order) {
try {
paymentService.transfer(order.getAmount()); // 调用支付服务(REQUIRES_NEW)
} catch (Exception e) {
// 支付失败,外层事务回滚,但日志已独立提交
logService.recordErrorLog(order.getId(), e.getMessage());
}
}
}
@Service
public class PaymentService {
@Transactional(propagation = Propagation.REQUIRES_NEW) // 独立事务:支付操作
public void transfer(BigDecimal amount) {
// 支付 logic,失败则回滚当前独立事务
if (amount.compareTo(BigDecimal.ZERO) <= 0) {
throw new IllegalArgumentException("金额必须大于0");
}
accountMapper.debit(amount); // 扣减账户余额
}
@Transactional(propagation = Propagation.REQUIRES_NEW) // 独立事务:错误日志记录
public void recordErrorLog(Long orderId, String message) {
logMapper.insert(new ErrorLog(orderId, message));
} // ⚠️ 即使外层回滚,此日志仍会提交
}
AI写代码java
运行NEVER:
NEVER 机制严格禁止在事务上下文中执行:若调用方存在事务,则直接抛出IllegalTransactionStateException异常终止执行;若调用方无事务,则以非事务方式运行。
常用于纯查询或无需事务的操作,防止被意外卷入事务导致性能损耗:
typescript
@Service
public class ReportService {
@Transactional(propagation = Propagation.NEVER) // 禁止在事务中调用
public List<OrderReport> generateDailyReport() {
// 复杂查询逻辑,无需事务支持
return reportMapper.selectDailySales();
}
}
// ❌ 错误用法:在事务中调用NEVER方法
@Service
public class OrderService {
@Autowired private ReportService reportService;
@Transactional // 外层事务
public void processOrder() {
reportService.generateDailyReport(); // 抛出异常!NEVER拒绝事务环境
}
}
AI写代码java
运行NESTED:
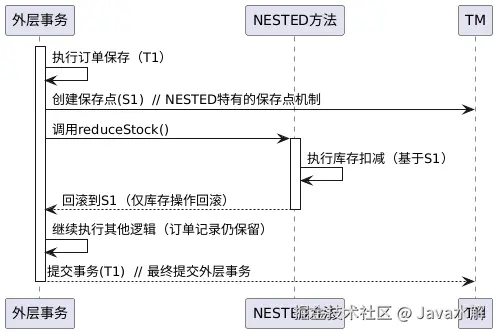
NESTED 是一种特殊的嵌套事务机制:它依赖外层事务存在,在执行时会创建保存点(Savepoint) ,允许内层事务独立回滚到保存点,而不影响外层事务的整体提交;若外层事务回滚,则嵌套事务也会一并回滚。
例如订单创建时需要先扣减库存,若扣减失败仅回滚库存操作,继续执行订单其他逻辑:
java
@Service
public class OrderService {
@Autowired private InventoryService inventoryService;
@Transactional(propagation = Propagation.REQUIRED) // 外层事务
public void createOrder(Order order) {
orderMapper.insert(order); // 保存订单(外层操作)
try {
inventoryService.reduceStock(order.getItems()); // 嵌套事务:扣减库存
} catch (Exception e) {
// 仅回滚库存扣减,订单记录仍保留
log.error("库存不足,回滚扣减操作", e);
}
}
}
@Service
public class InventoryService {
@Transactional(propagation = Propagation.NESTED) // 嵌套事务,依赖外层
public void reduceStock(List<OrderItem> items) {
for (OrderItem item : items) {
int rows = inventoryMapper.decrease(item.getProductId(), item.getQuantity());
if (rows == 0) {
throw new InsufficientStockException(); // 触发回滚到保存点
}
}
}
}
AI写代码java
运行核心对比:NESTED vs REQUIRED
NESTED和REQUIRED都依赖外层事务,但本质完全不同,最关键的区别在于事务边界和回滚机制:
| 维度 | REQUIRED(共享事务) | NESTED(嵌套事务) |
|---|---|---|
| 事务本质 | 同一物理事务,共享事务上下文 | 基于保存点的子事务,依赖外层事务 |
| 回滚范围 | 内层回滚导致整个事务回滚 | 内层可独立回滚到保存点,不影响外层 |
| 提交关系 | 内外事务同时提交或回滚 | 外层提交时才会最终提交嵌套部分 |
| 适用场景 | 强一致性业务(如转账+日志) | 局部失败不影响整体(如订单+库存) |
通过PlantUML可以更直观对比两者的执行流程:
REQUIRED传播流程(共享事务,同进退):
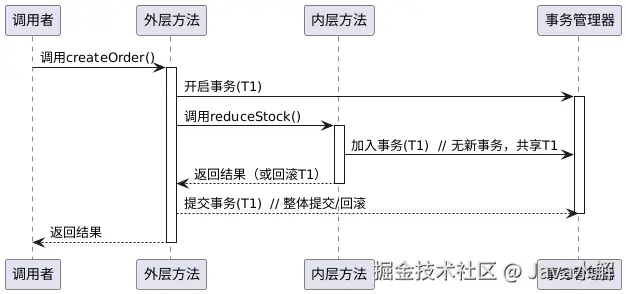
NESTED传播流程(保存点隔离,独立回滚):
实战选型建议:
- 需强一致性:用REQUIRED(如支付+订单)
- 需独立事务:用REQUIRES_NEW(如核心业务+审计日志)
- 需局部回滚:用NESTED(如主流程+可选步骤)
- 纯查询操作:用NEVER避免事务开销
通过合理搭配传播机制,既能保证数据一致性,又能提升系统灵活性和性能。实际开发中需结合业务场景选择,避免过度使用事务导致资源浪费或数据异常。
3.小结
事务管理是企业应用开发的关键环节,Spring 框架通过全面的事务管理支持简化了这一复杂任务。无论是编程式定义事务边界还是使用声明式注解,Spring 都为开发者提供了灵活选项以满足不同场景的事务管理需求。
开发注意事项
- 避免自调用导致事务失效 :类内部方法直接调用带
@Transactional注解的方法时,AOP 代理无法生效,需通过 Spring 上下文获取代理对象调用。 - 合理设置回滚规则 :
@Transactional默认仅回滚运行时异常(RuntimeException),需通过rollbackFor属性显式指定检查型异常的回滚策略。 - 传播机制选择需匹配业务语义 :例如转账场景适合
PROPAGATION_REQUIRED,而日志记录等独立操作建议使用PROPAGATION_REQUIRES_NEW隔离事务。
事务是保证数据一致性的基石,正确使用 Spring 事务机制可显著提升系统可靠性。