我在业余时间开发了一款自己的独立产品:升讯威在线客服与营销系统。陆陆续续开发了几年,从一开始的偶有用户尝试,到如今线上环境和私有化部署均有了越来越多的稳定用户,在这个过程中,我也积累了不少如何开发运营一款独立产品的经验。
我有很多次在版本发布之后会感觉:这个版本绝对稳如老狗了! 😎 结果每次都是在一段时间之后:欸?还有这种奇葩问题? 😗
从早几年经常性的 "欸?",到今年偶尔 "欸?"。到今天,我相信这回真的稳如老狗了,因为随着这些天给几个客户的环境升级到最新版本之后,一切都安稳了......
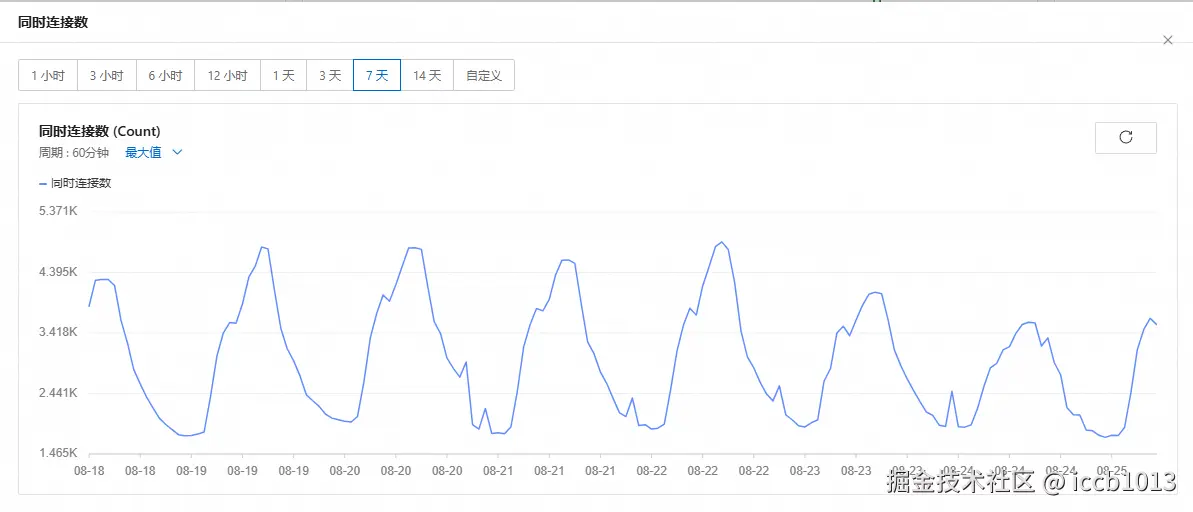
我自己的线上环境,也是从早先的经常有用户和我反馈在他们的环境或者场景中出现了什么问题,到现在,用的人更多了,在线访客总量也越来越多,可是几乎没人找我反馈问题了...... 😒
这是我官方环境的服务器同时连接数,去年同时连接数超过 2K 时,我还发过朋友圈,今年翻倍到了 4K+,我已经 淡然处之了(不发朋友圈了)。😂
这个客服系统,从我业余时间开始开发到今天,已经过去了 5 年,我会在本文中,分享一些这 5 年间让我感到:"欸?还有这种奇葩问题?" 的问题。
欸?还有这种奇葩问题?
有些表情能毁掉一段历史:UTF-8 与数据库编码不一致
"为什么昨天聊的东西今天全没了?!"
我连夜排查日志,发现数据库居然正常返回0条记录,不是超时、不是权限问题------就像这段聊天从未存在过。
再往前翻,发现客服当时的最后一句记录是:
"好的,请稍等一下🥲"
这个小小的"🥲"干掉了整条记录。
问题症状:看似插入成功,其实SQL崩溃。
初始建表时,我用了"UTF-8",但疏忽了MySQL里的utf8和utf8mb4不是一回事:
sql
CREATE TABLE chat_message (
id BIGINT AUTO_INCREMENT PRIMARY KEY,
visitor_id VARCHAR(50),
content TEXT CHARACTER SET utf8 COLLATE utf8_general_ci,
created_at DATETIME
);当访客发的消息里包含四字节字符(如emoji、特殊符号)时,插入就会失败:
sql
INSERT INTO chat_message (visitor_id, content, created_at)
VALUES ('A123', '好的,请稍等一下🥲', NOW());
-- Error: Incorrect string value: '\xF0\x9F\xA5\xB2' for column 'content'应用层"假成功":驱动层吞掉了异常
我用的 .NET MySQL Connector,默认IgnorePrepare = true,加上代码没捕获具体异常,结果就是"插入失败但返回成功":
csharp
try
{
await db.ExecuteAsync(
"INSERT INTO chat_message (visitor_id, content, created_at) VALUES (@v, @c, @t)",
new { v = visitorId, c = content, t = DateTime.UtcNow }
);
logger.Info("消息存储成功:" + content);
}
catch (Exception ex)
{
// 没有打出SQL错误码,只记录 ex.Message,最终被上层忽略
logger.Warn("消息存储异常:" + ex.Message);
}所以以为"成功存了",客服第二天一查------空的。
深入原因:MySQL的"utf8"是三字节UTF-8。
MySQL的utf8只支持1-3字节字符(BMP平面),而emoji在U+1F600及以上,需要四字节:
r
🥲 = U+1F972
UTF-8编码 = F0 9F A5 B2这类字符会直接导致插入失败。
解决方案:全面切换到utf8mb4 + 兼容性改造
第一步,修改表结构与库:
sql
ALTER DATABASE mychat CHARACTER SET = utf8mb4 COLLATE = utf8mb4_unicode_ci;
ALTER TABLE chat_message CONVERT TO CHARACTER SET utf8mb4 COLLATE utf8mb4_unicode_ci;第二步,连接字符串明确声明:
csharp
var connStr = "Server=localhost;Database=mychat;Uid=root;Pwd=xxx;CharSet=utf8mb4;";第三步,测试代码验证emoji可正常存取:
csharp
var testMessage = "欢迎使用升讯威在线客服系统🥳🔥";
await db.ExecuteAsync(
"INSERT INTO chat_message (visitor_id, content, created_at) VALUES (@v, @c, @t)",
new { v = "T001", c = testMessage, t = DateTime.UtcNow }
);
var result = await db.QuerySingleAsync<string>(
"SELECT content FROM chat_message WHERE visitor_id = @v ORDER BY id DESC LIMIT 1",
new { v = "T001" }
);
Console.WriteLine(result); // 输出: 欢迎使用升讯威在线客服系统🥳🔥更深一层的坑:索引长度与utf8mb4的冲突
切换utf8mb4后,我的复合索引突然建不起来了:
sql
ALTER TABLE chat_message ADD INDEX idx_v_c(visitor_id, content);
-- Error: Specified key was too long; max key length is 767 bytes因为utf8mb4每字符最多4字节,VARCHAR(255)就可能超出InnoDB的索引限制。 解决办法:只索引前缀或使用全文索引:
sql
ALTER TABLE chat_message ADD INDEX idx_v_c(visitor_id, content(100));总结与经验教训
- 不要以为utf8=UTF-8,MySQL的utf8是阉割版。
- 日志与异常必须精确记录SQL错误码,否则你根本不会发现消息丢失。
- 测试数据必须包含emoji,否则你永远不知道生产环境有多少小猫小狗在毁你的数据。
最终,我写了一个测试用例:
javascript
it("should store emoji without error", async () => {
const message = "测试emoji 🐱🐶🔥";
const res = await api.sendMessage({ visitorId: "U999", content: message });
const saved = await api.getLastMessage("U999");
expect(saved.content).toBe(message);
});这个测试每次部署都跑,保证历史不会再被一个🥲毁掉。
负载均衡 + Sticky Session 失效:消息乱序与丢失
在线客服系统为什么一定要"粘人"
在线客服系统的核心就是实时双向通信 。访客的每条消息必须按顺序送达客服端,否则就会出现这样的惨剧:
访客:"你好" 客服:"请问有什么可以帮您?" 访客:"我想咨询一下价格" 客服突然看到第一条:"你好" (延迟5秒) 客服:"???你已经走了啊......"
问题是:服务器明明都有收到消息,为什么到客服端时顺序乱了?
负载均衡让消息"分身"
我的架构是这样的:
scss
Visitor <-> Nginx(Load Balancer) <-> Node1(Node.js + WebSocket)
Node2(Node.js + WebSocket)按理说,访客连上Node1后,后续消息都应该走Node1。可在高并发下,我看到日志:
css
[Node1] Received Message ID 1001 from Visitor A
[Node2] Received Message ID 1002 from Visitor A访客的两条消息跑到了不同节点,结果:
- Node1的消息发给客服A
- Node2的消息发给客服B
- 客服端UI收到的顺序是 1002 -> 1001
更坑的是,消息确认ACK回到访客时,对不上号,导致重发,最终客服端收到两条重复的消息,顺序还错了。
根本原因:Sticky Session失效
我以为Nginx的默认负载均衡会保持连接稳定,其实不是。Nginx对HTTP有ip_hash、sticky模块,但对WebSocket如果配置不当,会出现两种问题:
问题1:没有Session绑定
nginx
upstream websocket_backend {
server 10.0.0.1:3000;
server 10.0.0.2:3000;
}
server {
location /ws {
proxy_pass http://websocket_backend;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}这种配置下,连接建立时随机选一个节点,但重连时可能连到别的节点。
问题2:TCP层断开重连未保持同一节点
即使初始连到Node1,一旦网络波动或心跳失败,客户端重连后可能跑到Node2。
现场"事故"日志
真实日志片段:
ini
2025-08-24 14:00:01 Node1 [Visitor: V001] Received message seq=15
2025-08-24 14:00:01 Node2 [Visitor: V001] Received message seq=16
2025-08-24 14:00:01 Node1 -> AgentA send seq=15
2025-08-24 14:00:01 Node2 -> AgentA send seq=16
2025-08-24 14:00:01 AgentA UI shows: (16) 我想咨询价格
2025-08-24 14:00:02 AgentA UI shows: (15) 你好客服直接懵逼:"怎么问候语在报价后面出现?"
解决方案
方案1:启用真正的Sticky Session
在Nginx里使用 sticky 模块,按连接ID/SessionID绑定节点:
nginx
upstream websocket_backend {
sticky cookie srv_id expires=1h domain=.example.com path=/;
server 10.0.0.1:3000;
server 10.0.0.2:3000;
}
server {
location /ws {
proxy_pass http://websocket_backend;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "Upgrade";
}
}客户端建立连接后,会拿到 srv_id,后续请求保持在同一节点。
方案2:无状态化:消息中心化路由
彻底放弃Sticky,改为:
- 每个节点只负责接入,不存状态;
- 所有消息都通过一个中心化的消息路由(Redis Pub/Sub、Kafka、RabbitMQ)转发;
- 时序由消息中心保证。
javascript
// Node1收到消息 -> 发布到Redis频道
redis.publish(`chat:${visitorId}`, JSON.stringify(msg));
// 订阅消息并发送给客服
redis.subscribe(`chat:${visitorId}`, (msg) => {
sendToAgent(JSON.parse(msg));
});这样即使访客在不同节点间跳转,也能保证消息顺序统一。
方案3:应用层顺序控制
即使采用中心化,也建议用递增序列号控制最终显示顺序:
javascript
// 客服端消息队列
onMessageReceived(msg) {
if (msg.seq <= lastSeq) return; // 丢弃重复或过期消息
renderMessage(msg);
lastSeq = msg.seq;
}总结与经验教训
- 实时通信+负载均衡=天然陷阱,没配置好Sticky等于自找麻烦。
- 分布式必须要么粘人要么无状态化,不能一半一半。
- 应用层必须有时序保证,即使网络重传也不能乱。
最终我迁移到了Redis消息路由+应用层序列号双重保障,消息顺序和丢失率归零。
定时任务与时区:凌晨4点没人值班,消息队列卡死
一觉醒来,消息爆炸
"为什么今天早上第一波客户消息都是延迟5分钟才到的?客服端全部卡死!"
我翻日志,发现凌晨4:00到4:10期间,消息队列(RabbitMQ)消费速率掉为0,积压到10万条,直到4:15自动恢复。
这意味着客户夜间留言全部堆积,早班一上来直接崩溃。
怀疑是队列或网络问题,结果是"自杀式定时任务"
检查监控:
- CPU、内存正常;
- RabbitMQ自身状态正常;
- 消费者日志显示:凌晨4点消费者全部停工。
最终在消费者代码中发现了"罪魁祸首":
javascript
// 消费者应用启动时,每天凌晨4点清理过期会话数据
cron.schedule('0 4 * * *', async () => {
await cleanupSessions(); // 清理数据库中过期session
});问题是,这个cleanupSessions()里有个长事务 ,锁了整张session表,消费者处理消息时需要更新session的最后活跃时间,结果所有消费者线程全部阻塞:
csharp
Deadlock waiting for table `session` lock...凌晨4点"清理任务"把自己的兄弟"消息消费"干死了。
更坑的点:时区错乱,任务比预期多跑了一次
我发现有些节点的定时任务在3:00也执行过一次。为什么?
Docker镜像默认UTC时区,而Kubernetes节点是Asia/Shanghai,Cron表达式用的是本地时区,结果:
- 容器里4:00 UTC = 北京时间12:00,错了一次;
- 容器外4:00 Asia/Shanghai = 正常凌晨4点。
同一个任务在两套时区环境里跑了两遍:
- 凌晨4点锁表一次;
- 中午12点又锁一次(正好是客服高峰期)。
事故日志现场
数据库慢查询日志:
sql
2025-08-24T04:00:00Z LOCK table session (cleanupSessions)
2025-08-24T04:00:02Z UPDATE session SET last_active=... (BLOCKED)
2025-08-24T04:10:00Z UNLOCK table session消费者日志:
csharp
[04:00:01] Received message ID 9991
[04:00:01] ERROR: Deadlock - waiting for session lock
[04:05:02] Retrying message ID 9991
[04:10:00] Successfully processed message ID 9991RabbitMQ监控:
makefile
04:00:00 - Queue length: 0
04:05:00 - Queue length: 105,332
04:10:00 - Queue length: 2,105正确解决方案
方案1:任务与业务彻底解耦
- 把清理任务移到单独的Worker节点,与消息消费者分开;
- 使用消息队列通知清理,而不是直接Cron扫全表。
javascript
// 消费者只发事件,不清理
if (sessionExpired) redis.publish('cleanup', sessionId);
// 专门的Cleanup Worker订阅事件
redis.subscribe('cleanup', async (id) => await deleteSession(id));方案2:统一时区 & 避免Cron表达式歧义
- 所有容器、数据库、代码统一使用UTC;
- Cron任务统一用UTC表达式,并在代码中转换为业务时区。
javascript
// node-cron配置,统一UTC
cron.schedule('0 20 * * *', cleanupSessions); // UTC 20:00 = 北京凌晨4:00方案3:非锁表清理 + 分批执行
避免长事务锁表,改成分页清理:
sql
DELETE FROM session WHERE expired=1 LIMIT 1000;循环执行,避免一次性锁整个表。
方案4:监控 + 自动报警
- 增加消息队列积压阈值报警;
- 定时任务执行超时报警。
yaml
# Prometheus规则示例
- alert: QueueBacklog
expr: rabbitmq_queue_messages_ready{queue="chat"} > 1000
for: 5m
labels:
severity: critical
annotations:
summary: "Chat queue backlog"这样即使凌晨没人值班,自动报警也会通知到值班机器人。
经验教训
- 凌晨任务不等于安全时段,分布式业务可能24/7在线;
- 时区不一致是生产杀手,统一UTC是第一原则;
- 任务与核心业务必须解耦,不要在主进程里干副业;
- 测试必须模拟生产时区+定时任务行为,不要只在本地跑一下。
我最后把这个坑写进了上线检查清单:
"所有定时任务必须标明时区、不可阻塞主业务进程,且须有报警。"
独立者的产品成果
可全天候 7 × 24 小时挂机运行,网络中断,拔掉网线,手机飞行模式,不掉线不丢消息,欢迎实测。
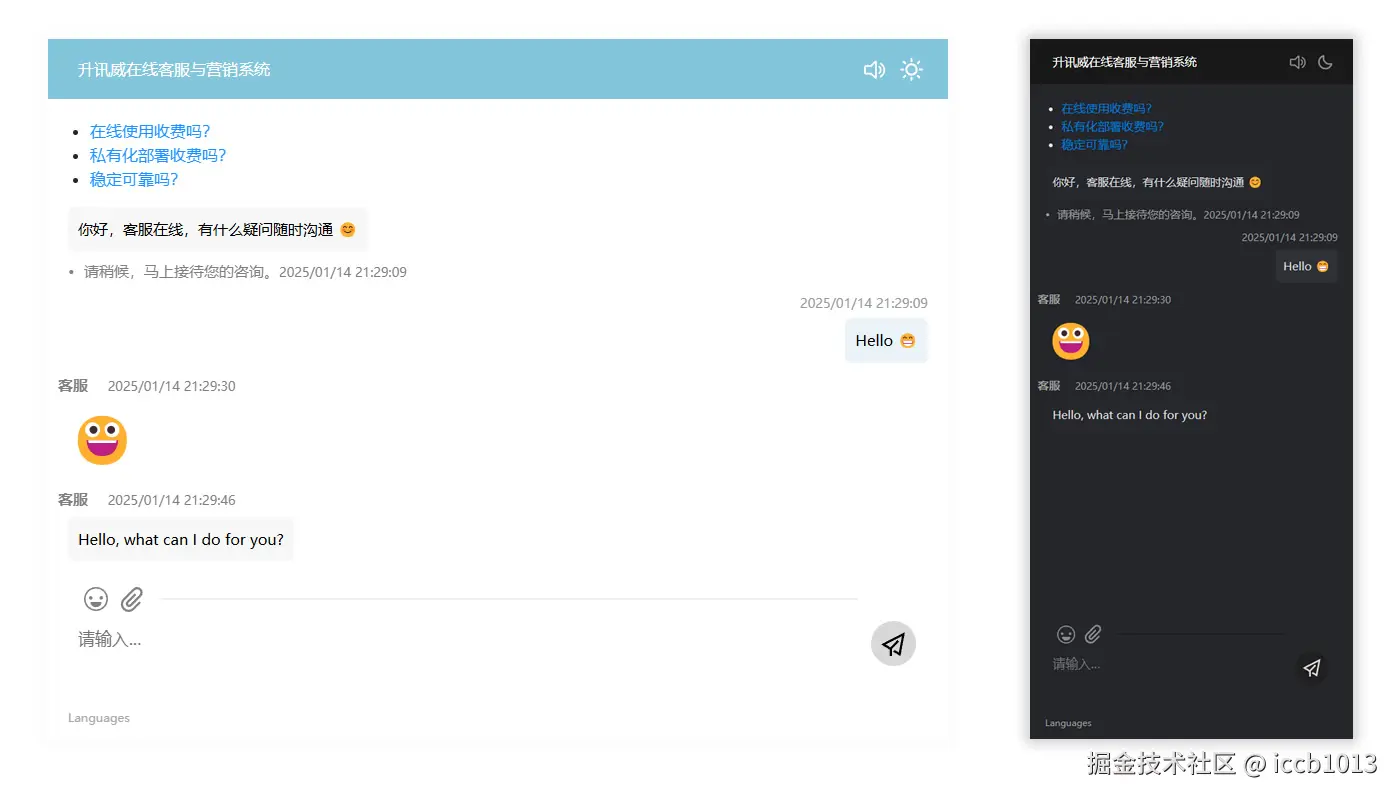
访客端:轻量直观、秒级响应的沟通入口
访客端是客户接触企业的第一窗口,我精心打磨每一处交互细节,确保用户无需任何学习成本即可发起对话。无论是嵌入式聊天窗口、悬浮按钮,还是移动端自适应支持,都实现了真正的"即点即聊"。系统支持智能欢迎语、来源识别、设备类型判断,可自动记录访客路径并呈现于客服端,帮助企业更好地理解用户意图。在性能方面,访客端采用异步加载与自动重连机制,即使网络波动也能保障消息顺畅送达,真正做到------轻量不失稳定,简单不失智能。
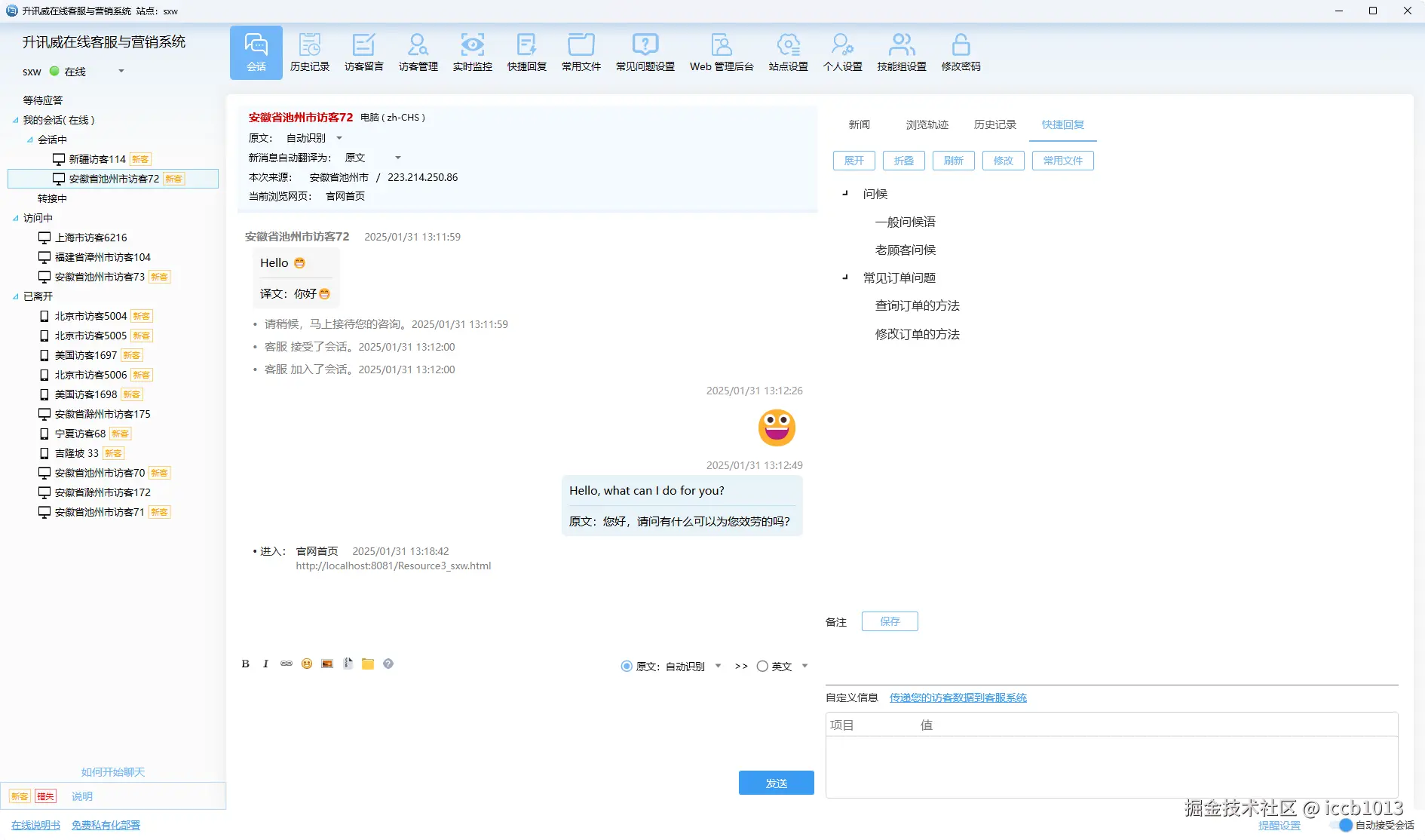
客服端软件:为高效率沟通而生
客服端是客服人员的作战平台,我构建了一个专注、高效、响应迅速的桌面级体验。系统采用多标签会话设计,让客服可同时处理多组对话;访客轨迹、历史会话、地理位置、设备信息、来源渠道等关键信息一目了然,协助客服快速做出判断。内置快捷回复、常用文件、表情支持和智能推荐功能,大幅降低重复劳动成本。同时,系统还支持智能分配、会话转接、转人工、自定义状态等多种机制,保障团队协作流畅,让客服不仅能应对高峰,更能稳定交付满意度。
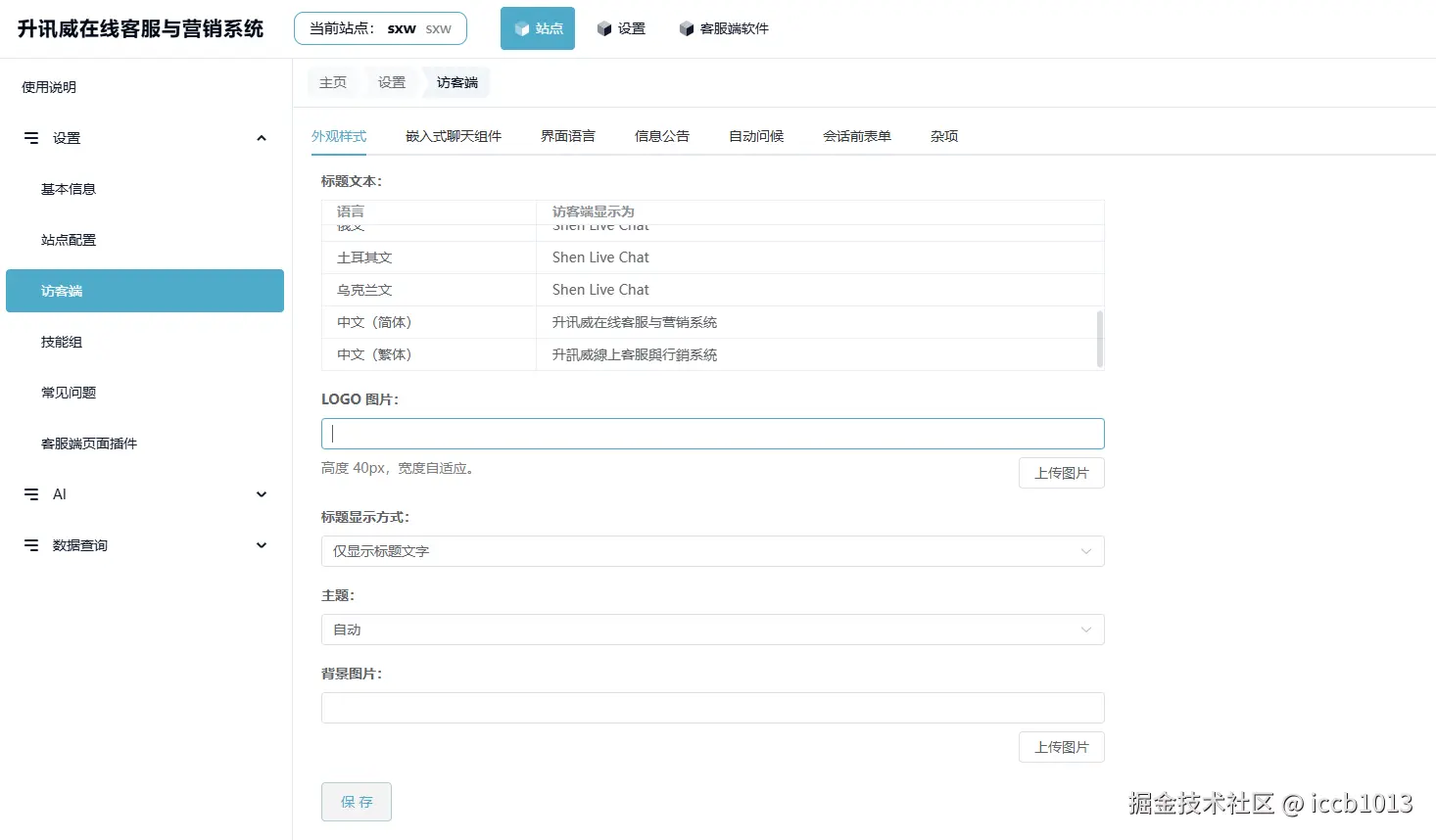
Web 管理后台:
Web 管理后台是企业对客服系统的"驾驶舱",从接入配置、坐席管理,到数据统计、权限控制,一切尽在掌握。你可以灵活设置接待策略、工作时间、转接规则,支持按部门/标签/渠道精细分配访客,满足复杂业务场景。系统还内置访问监控、聊天记录检索、客服绩效统计、错失会话提醒等运营级功能,助力管理者洞察服务瓶颈,持续优化资源配置。支持私有化部署、分权限管理、日志记录与数据导出,为追求安全性与高可控性的企业,提供真正"掌握在自己手里的客服系统"。
希望能够打造: 开放、开源、共享。努力打造一款优秀的社区开源产品。
钟意的话请给个赞支持一下吧,谢谢~