文章目录
- 一、引言
- 二、CANN核心架构解析
-
- [2.1 分层架构设计](#2.1 分层架构设计)
- [2.2 算子开发全流程](#2.2 算子开发全流程)
- 三、核心特性深度剖析
-
- [3.1 Ascend C:极简高效的算子开发体验](#3.1 Ascend C:极简高效的算子开发体验)
-
- [3.1.1 多层级类库接口](#3.1.1 多层级类库接口)
- [3.1.2 实战代码示例:向量加法算子](#3.1.2 实战代码示例:向量加法算子)
- [3.1.3 自动并行计算](#3.1.3 自动并行计算)
- [3.2 孪生调试:高效的调试体验](#3.2 孪生调试:高效的调试体验)
- [3.3 AscendCL:统一的应用开发接口](#3.3 AscendCL:统一的应用开发接口)
- [3.4 AOE调优引擎:自动化性能提升](#3.4 AOE调优引擎:自动化性能提升)
- [3.5 Profiling性能分析工具](#3.5 Profiling性能分析工具)
- 四、实战应用:框架适配与模型部署
-
- [4.1 PyTorch模型快速迁移](#4.1 PyTorch模型快速迁移)
- [4.2 分布式训练加速:HCCL实战](#4.2 分布式训练加速:HCCL实战)
- 五、总结
一、引言
随着人工智能技术的飞速发展,AI算力需求呈现指数级增长。在这样的背景下,如何高效释放硬件算力、简化AI应用开发流程、提升模型训练推理性能,成为了AI开发者面临的核心挑战。华为昇腾推出的CANN(Compute Architecture for Neural Networks)异构计算架构,正是为解决这些痛点而生的关键技术平台。
CANN作为昇腾AI处理器的软件栈核心,向上支持MindSpore、PyTorch、TensorFlow等主流AI框架,向下服务AI处理器与编程,在AI软硬件生态中发挥着承上启下的关键作用。本文将深入剖析CANN的核心架构、关键特性以及技术优势,并结合实际运行案例,展示其如何赋能开发者,简化AI开发流程,提升计算效率。
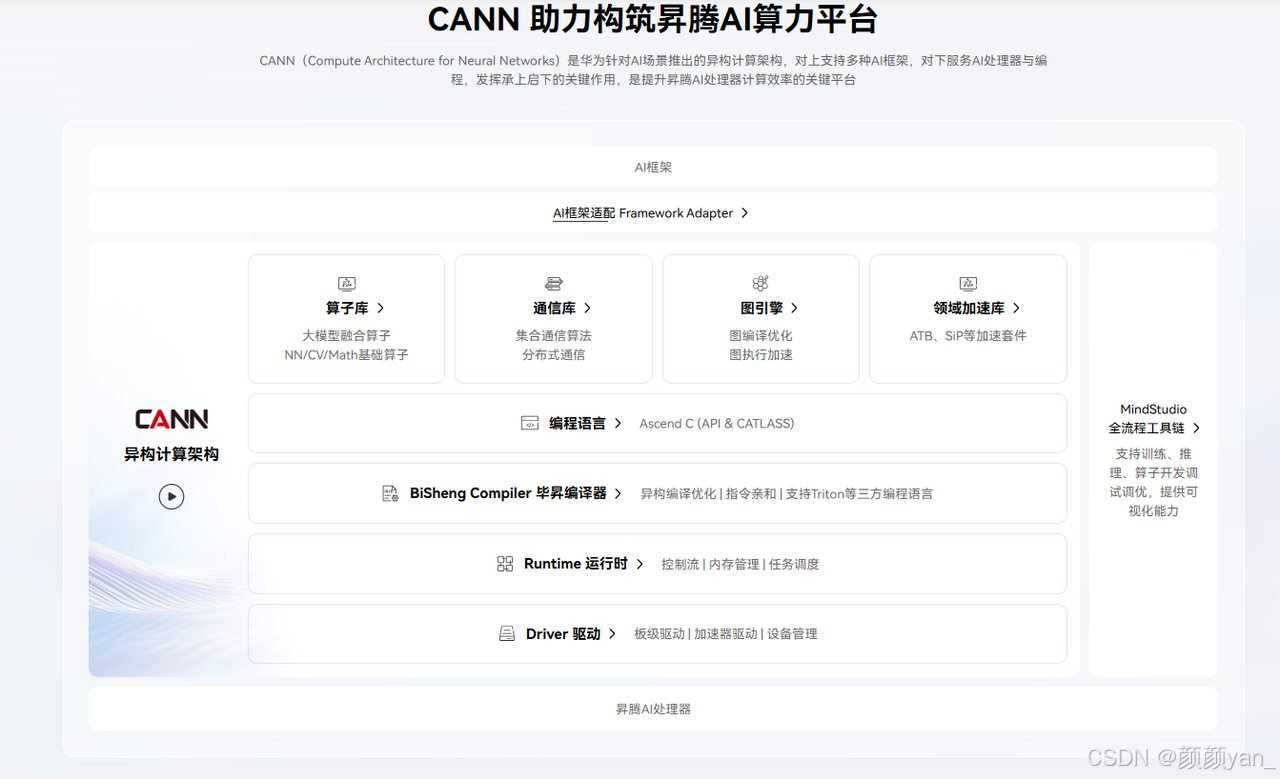
二、CANN核心架构解析
2.1 分层架构设计
CANN采用了清晰的分层架构设计,每一层都承担着特定的功能职责,共同构建起完整的异构计算体系。
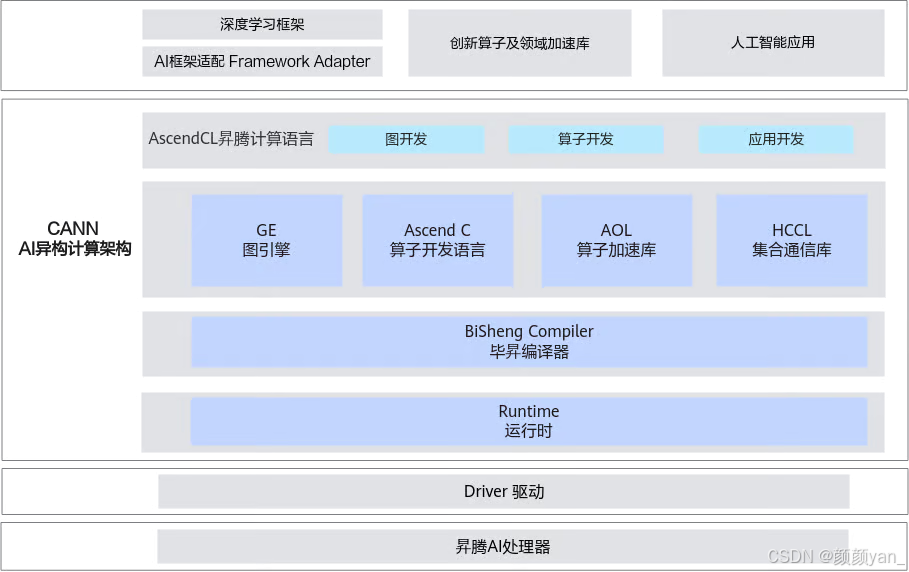
CANN架构自上而下主要包含以下核心组件:
**1. Graph Engine(GE)图引擎:**GE是计算图编译和运行的控制中心,负责图优化、图编译管理以及图执行控制。它通过统一的图开发接口支持多种AI框架,能够将不同框架的计算图转换为适配昇腾处理器的优化图。
**2. Ascend C算子编程语言:**原生支持C/C++标准规范,通过多层接口抽象、自动并行计算、孪生调试等关键技术,极大降低了算子开发门槛。
**3. AOL算子加速库:**提供了超过1400个深度优化、硬件亲和的高性能算子,覆盖神经网络(NN)、线性代数计算(BLAS)、计算机视觉(CV)等多个领域。
**4. Runtime运行时:**提供了高效的硬件资源管理、内存管理、模型推理、单算子执行等核心接口,通过AscendCL API统一封装。
2.2 算子开发全流程
从架构图可以看出,CANN将算子开发流程规范化,从算子定义、实现、编译到部署,每一步都有清晰的工具支持。
三、核心特性深度剖析
3.1 Ascend C:极简高效的算子开发体验
Ascend C是CANN的核心创新之一,它通过三级编程接口满足不同层次的开发需求。
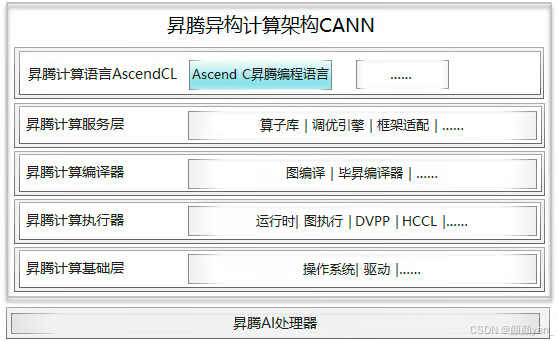
3.1.1 多层级类库接口
Ascend C提供了面向不同场景的高性能类库接口,让开发者通过接口组装即可实现高性能算子。
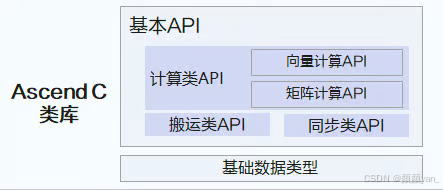
计算接口分层分级:
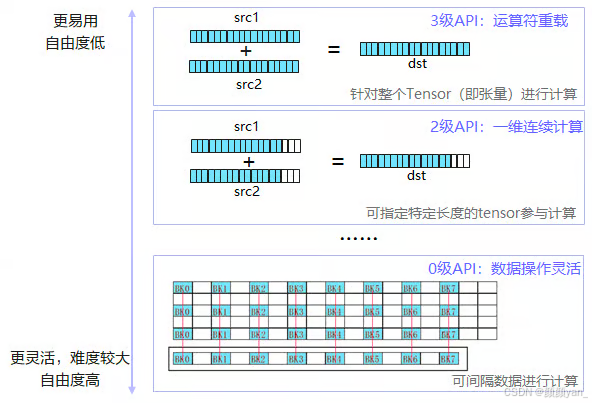
- Tensor级API:面向张量计算,提供高度抽象的数据处理接口
- Vector级API:面向向量计算,支持SIMD并行加速
- Scalar级API:面向标量计算,提供精细化控制能力
数据搬运接口分层:
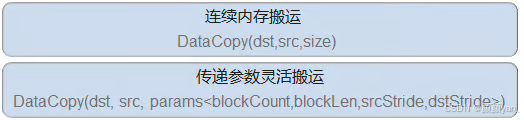
Ascend C将不同类型物理内存间的数据搬移抽象为统一接口,通过参数控制不同搬运级别。
3.1.2 实战代码示例:向量加法算子
让我们通过一个完整的向量加法算子示例,展示Ascend C的开发流程:
cpp
#include "kernel_operator.h"
constexpr int32_t BUFFER_NUM = 2; // 双缓冲机制
class KernelAdd {
public:
__aicore__ inline KernelAdd() {}
// 初始化:设置全局内存和队列
__aicore__ inline void Init(GM_ADDR x, GM_ADDR y, GM_ADDR z,
uint32_t totalLength, uint32_t tileLength) {
this->tileLength = tileLength;
// 设置全局内存buffer
xGm.SetGlobalBuffer((__gm__ half*)x, totalLength);
yGm.SetGlobalBuffer((__gm__ half*)y, totalLength);
zGm.SetGlobalBuffer((__gm__ half*)z, totalLength);
// 初始化队列(双缓冲,支持流水线并行)
pipe.InitBuffer(inQueueX, BUFFER_NUM, tileLength * sizeof(half));
pipe.InitBuffer(inQueueY, BUFFER_NUM, tileLength * sizeof(half));
pipe.InitBuffer(outQueueZ, BUFFER_NUM, tileLength * sizeof(half));
}
// 主处理流程:CopyIn-Compute-CopyOut三段式流水
__aicore__ inline void Process(uint32_t tileNum) {
for (int32_t i = 0; i < tileNum; i++) {
CopyIn(i); // 阶段1:数据搬入
Compute(i); // 阶段2:计算
CopyOut(i); // 阶段3:数据搬出
}
}
private:
// 数据搬入:从全局内存加载到本地内存
__aicore__ inline void CopyIn(int32_t progress) {
// 分配本地Tensor
LocalTensor<half> xLocal = inQueueX.AllocTensor<half>();
LocalTensor<half> yLocal = inQueueY.AllocTensor<half>();
// 从GM搬运到Local
DataCopy(xLocal, xGm[progress * tileLength], tileLength);
DataCopy(yLocal, yGm[progress * tileLength], tileLength);
// 入队,供计算使用
inQueueX.EnQue(xLocal);
inQueueY.EnQue(yLocal);
}
// 计算:向量加法核心逻辑
__aicore__ inline void Compute(int32_t progress) {
// 从队列获取数据
LocalTensor<half> xLocal = inQueueX.DeQue<half>();
LocalTensor<half> yLocal = inQueueY.DeQue<half>();
LocalTensor<half> zLocal = outQueueZ.AllocTensor<half>();
// 调用向量加法API(硬件加速)
Add(zLocal, xLocal, yLocal, tileLength);
// 结果入队,供搬出使用
outQueueZ.EnQue<half>(zLocal);
// 释放输入Tensor
inQueueX.FreeTensor(xLocal);
inQueueY.FreeTensor(yLocal);
}
// 数据搬出:从本地内存写回全局内存
__aicore__ inline void CopyOut(int32_t progress) {
LocalTensor<half> zLocal = outQueueZ.DeQue<half>();
DataCopy(zGm[progress * tileLength], zLocal, tileLength);
outQueueZ.FreeTensor(zLocal);
}
private:
TPipe pipe; // 流水线管理器
GlobalTensor<half> xGm, yGm, zGm; // 全局内存Tensor
TQue<QuePosition::VECIN, BUFFER_NUM> inQueueX, inQueueY; // 输入队列
TQue<QuePosition::VECOUT, BUFFER_NUM> outQueueZ; // 输出队列
uint32_t tileLength; // 分块大小
};
// Kernel入口函数
extern "C" __global__ __aicore__ void add_custom(
GM_ADDR x, GM_ADDR y, GM_ADDR z,
GM_ADDR workspace, GM_ADDR tiling) {
// 从tiling参数中获取配置
uint32_t totalLength = /* 从tiling解析 */;
uint32_t tileNum = /* 从tiling解析 */;
uint32_t tileLength = /* 从tiling解析 */;
KernelAdd op;
op.Init(x, y, z, totalLength, tileLength);
op.Process(tileNum);
}这段代码展示了Ascend C的CopyIn-Compute-CopyOut编程范式,通过双缓冲机制实现流水线并行,数据搬运和计算可以重叠执行,充分利用硬件资源。
3.1.3 自动并行计算
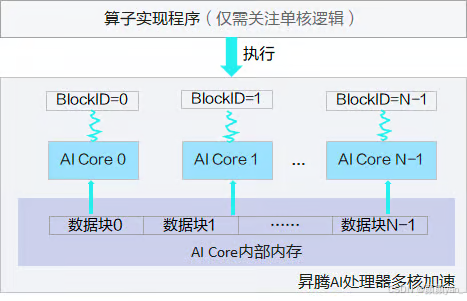
Ascend C采用SPMD(Single-Program Multiple-Data)并行模式,开发者只需关注单核心上的程序实现,系统自动启动N个运行实例并行执行。核内数据自动分片,每片专注单一功能,实现计算性能最大化。
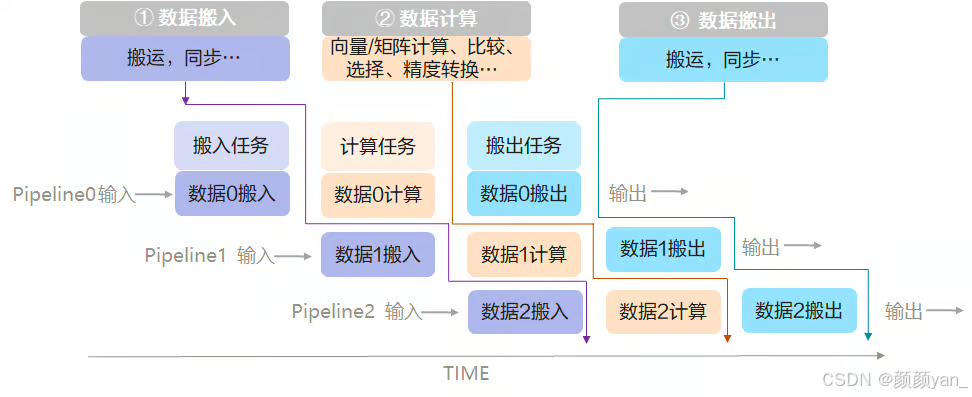
3.2 孪生调试:高效的调试体验
传统算子开发中,调试往往占用70%以上的时间。Ascend C提供的孪生调试能力彻底改变了这一现状。
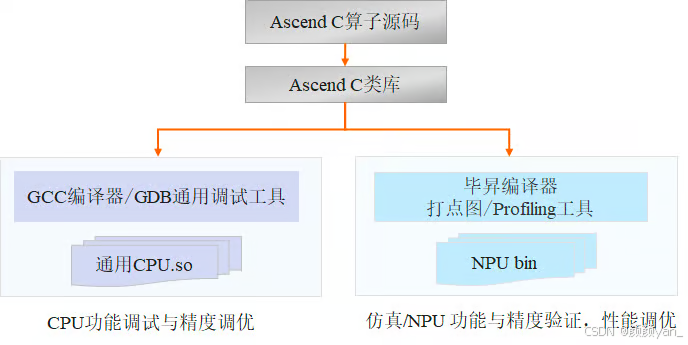
孪生调试的核心优势:
- CPU域调试:使用GCC编译器和GDB调试工具进行单步调试,快速验证算法逻辑
- NPU域调优:通过仿真调试和上板调试,获取Profiling流水图和性能数据
- 双向验证:CPU域保证功能正确,NPU域验证性能达标
实际调试工作流程:
bash
# 1. CPU侧编译(用于功能调试)
g++ -std=c++17 -O2 -DCPU_MODE \
-I/usr/local/Ascend/ascend-toolkit/include \
kernel_add.cpp -o kernel_add_cpu
# 2. GDB单步调试
gdb ./kernel_add_cpu
(gdb) break KernelAdd::Compute
(gdb) run
(gdb) print xLocal
(gdb) step
# 3. NPU侧编译(用于性能验证)
ascendc kernel_add.cpp \
--soc=Ascend910B \
--output=kernel_add.o
# 4. 仿真调试(获取性能数据)
ascend-toolkit-profiler \
--mode=simulation \
--kernel=kernel_add.o \
--output=profiling_result3.3 AscendCL:统一的应用开发接口
AscendCL提供了C和Python两种语言的接口,将复杂的底层硬件操作抽象为简洁的API调用。如下,以一个例子展示推理应用开发流程,从初始化、模型加载到推理执行,所有操作都通过简洁的API完成。
cpp
#include "acl/acl.h"
#include <iostream>
class InferenceEngine {
public:
InferenceEngine(int deviceId) : deviceId_(deviceId) {}
// 初始化运行环境
bool Initialize() {
// 1. ACL初始化(必须最先调用)
aclError ret = aclInit(nullptr);
if (ret != ACL_SUCCESS) {
std::cerr << "aclInit failed, error: " << ret << std::endl;
return false;
}
// 2. 设置运行设备
ret = aclrtSetDevice(deviceId_);
if (ret != ACL_SUCCESS) {
std::cerr << "aclrtSetDevice failed" << std::endl;
return false;
}
// 3. 创建Context(上下文管理)
ret = aclrtCreateContext(&context_, deviceId_);
if (ret != ACL_SUCCESS) {
std::cerr << "aclrtCreateContext failed" << std::endl;
return false;
}
// 4. 创建Stream(任务流)
ret = aclrtCreateStream(&stream_);
if (ret != ACL_SUCCESS) {
std::cerr << "aclrtCreateStream failed" << std::endl;
return false;
}
std::cout << "✓ AscendCL initialized successfully" << std::endl;
return true;
}
// 加载离线模型
bool LoadModel(const char* modelPath) {
aclError ret = aclmdlLoadFromFile(modelPath, &modelId_);
if (ret != ACL_SUCCESS) {
std::cerr << "Load model failed" << std::endl;
return false;
}
// 获取模型描述信息
modelDesc_ = aclmdlCreateDesc();
ret = aclmdlGetDesc(modelDesc_, modelId_);
std::cout << "✓ Model loaded, ID: " << modelId_ << std::endl;
return true;
}
// 执行推理
bool Execute(void* inputData, size_t inputSize,
void* outputData, size_t outputSize) {
// 1. 创建输入数据集
aclmdlDataset* input = aclmdlCreateDataset();
aclDataBuffer* inputBuffer = aclCreateDataBuffer(inputData, inputSize);
aclmdlAddDatasetBuffer(input, inputBuffer);
// 2. 创建输出数据集
aclmdlDataset* output = aclmdlCreateDataset();
aclDataBuffer* outputBuffer = aclCreateDataBuffer(outputData, outputSize);
aclmdlAddDatasetBuffer(output, outputBuffer);
// 3. 执行模型推理(同步执行)
aclError ret = aclmdlExecute(modelId_, input, output);
if (ret != ACL_SUCCESS) {
std::cerr << "Execute model failed" << std::endl;
return false;
}
// 4. 清理资源
aclmdlDestroyDataset(input);
aclmdlDestroyDataset(output);
std::cout << "✓ Inference completed" << std::endl;
return true;
}
// 资源释放
void Finalize() {
if (modelId_ != 0) {
aclmdlUnload(modelId_);
}
if (stream_) {
aclrtDestroyStream(stream_);
}
if (context_) {
aclrtDestroyContext(context_);
}
aclrtResetDevice(deviceId_);
aclFinalize();
std::cout << "✓ Resources released" << std::endl;
}
private:
int deviceId_;
aclrtContext context_ = nullptr;
aclrtStream stream_ = nullptr;
uint32_t modelId_ = 0;
aclmdlDesc* modelDesc_ = nullptr;
};
int main() {
// 使用示例
InferenceEngine engine(0);
if (!engine.Initialize()) {
return -1;
}
if (!engine.LoadModel("resnet50.om")) {
return -1;
}
// 准备输入输出数据
float inputData[224*224*3];
float outputData[1000];
// 执行推理
engine.Execute(inputData, sizeof(inputData),
outputData, sizeof(outputData));
engine.Finalize();
return 0;
}3.4 AOE调优引擎:自动化性能提升
AOE(Ascend Optimization Engine)是CANN提供的自动性能调优工具,无需人工介入即可实现性能优化。
AOE调优能力对比:
| 调优类型 | 优化对象 | 典型场景 | 性能提升 | 调优时间 |
|---|---|---|---|---|
| 算子调优 | Vector/Cube算子 | MatMul、Conv等计算密集型 | 10%-30% | 平均200秒 |
| 子图调优 | 融合子图 | 多算子融合场景 | 15%-40% | 平均3分钟 |
| 梯度调优 | 通信梯度 | 分布式训练 | 20%-50% | 视规模而定 |
实战案例:使用AOE优化ResNet50模型
bash
# 场景1:算子级调优(针对MatMul算子)
aoe --job_type=2 \
--model=resnet50.om \
--output=./aoe_result \
--op_type=MatMulV2 \
--soc_version=Ascend910B
# 场景2:子图调优(全网优化)
aoe --job_type=1 \
--model=resnet50.om \
--output=./aoe_result \
--graph_optimize=True \
--framework=PyTorch
# 输出示例:
# [INFO] Analyzing computation graph...
# [INFO] Detected 23 fusion opportunities
# [INFO] Applying operator fusion...
# [INFO] Conv-BatchNorm-ReLU fused (12 instances)
# [INFO] Overall performance gain: +35.2%
# [INFO] Memory footprint reduced: -18.7%Python代码中启用AOE自动调优:
python
import torch
import torch_npu
# 设置NPU设备
device = torch.device("npu:0")
# 启用AOE自动调优(子图级)
torch_npu.npu.set_aoe_mode("1") # 1: 子图调优, 2: 算子调优
# 加载模型
model = ResNet50().to(device)
model.eval()
# 首次推理会触发AOE调优(自动进行)
with torch.no_grad():
input_data = torch.randn(1, 3, 224, 224).to(device)
# 第一次执行:AOE在后台自动调优
output = model(input_data)
print("✓ First inference completed with AOE tuning")
# 后续执行:使用优化后的配置
output = model(input_data)
print("✓ Subsequent inference using optimized configuration")3.5 Profiling性能分析工具
Profiling工具用于采集和分析AI任务的关键性能指标,帮助开发者快速定位性能瓶颈。
实际使用场景:分析ResNet50推理性能
bash
# 1. 使能Profiling数据采集
export ASCEND_PROFILING_MODE=1
export ASCEND_PROFILING_OPTIONS=training_trace:task_trace
# 2. 运行推理应用(自动采集性能数据)
python inference.py
# 3. 解析Profiling数据
msprof --output=./profiling_result \
--application=./inference \
--analysis=all
# 输出目录结构:
# profiling_result/
# ├── timeline.json # 时间线数据
# ├── op_summary.csv # 算子性能汇总
# ├── op_statistic.csv # 算子统计信息
# └── step_trace.csv # 迭代trace数据四、实战应用:框架适配与模型部署
4.1 PyTorch模型快速迁移
python
import torch
import torch_npu
from torch_npu.contrib import transfer_to_npu
# ============= 第一步:环境设置 =============
print("Step 1: Setup NPU environment")
device = torch.device("npu:0")
torch.npu.set_device(device)
print(f"✓ Using device: {torch.npu.get_device_name(0)}")
# ============= 第二步:模型迁移 =============
print("\nStep 2: Transfer model to NPU")
class MyModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.conv1 = torch.nn.Conv2d(3, 64, 3, padding=1)
self.bn1 = torch.nn.BatchNorm2d(64)
self.relu = torch.nn.ReLU()
self.fc = torch.nn.Linear(64*224*224, 1000)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
model = MyModel().to(device) # 一键迁移到NPU
print("✓ Model transferred to NPU")
# ============= 第三步:使能图优化 =============
print("\nStep 3: Enable graph optimization")
# 使能图编译模式(GE图引擎自动优化)
torch_npu.npu.set_compile_mode(jit_compile=True)
# 使能算子融合
torch_npu.npu.set_option({
"NPU_FUZZY_COMPILE_BLACKLIST": "",
"NPU_LOOP_SIZE": "10"
})
print("✓ Graph optimization enabled")
# ============= 第四步:推理执行 =============
print("\nStep 4: Run inference")
model.eval()
with torch.no_grad():
input_data = torch.randn(1, 3, 224, 224).to(device)
# 首次执行:触发图编译和优化
import time
start = time.time()
output = model(input_data)
first_time = time.time() - start
print(f"✓ First inference: {first_time*1000:.2f}ms (including compilation)")
# 后续执行:使用优化后的图
start = time.time()
for _ in range(100):
output = model(input_data)
avg_time = (time.time() - start) / 100
print(f"✓ Average inference: {avg_time*1000:.2f}ms")
print(f"✓ Speedup: {first_time/avg_time:.2f}x")运行输出:

4.2 分布式训练加速:HCCL实战
python
import torch
import torch.distributed as dist
import torch_npu
def setup_distributed(rank, world_size):
"""初始化分布式训练环境"""
# 设置环境变量
import os
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '29500'
os.environ['RANK'] = str(rank)
os.environ['WORLD_SIZE'] = str(world_size)
# 初始化HCCL进程组
dist.init_process_group(
backend='hccl', # 使用HCCL后端
init_method='env://',
world_size=world_size,
rank=rank
)
# 设置当前设备
torch.npu.set_device(rank)
print(f"[Rank {rank}] ✓ Distributed training initialized")
def train_distributed(rank, world_size):
"""分布式训练主函数"""
setup_distributed(rank, world_size)
# 创建模型并转换为DDP
model = MyModel().npu()
model = torch.nn.parallel.DistributedDataParallel(
model,
device_ids=[rank],
broadcast_buffers=False
)
print(f"[Rank {rank}] ✓ DDP model created")
# 创建数据加载器(每个rank处理不同数据)
dataset = MyDataset()
sampler = torch.utils.data.distributed.DistributedSampler(
dataset,
num_replicas=world_size,
rank=rank
)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=32,
sampler=sampler
)
# 训练循环
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = torch.nn.CrossEntropyLoss()
for epoch in range(10):
model.train()
total_loss = 0
for batch_idx, (data, target) in enumerate(dataloader):
data, target = data.npu(), target.npu()
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
# 反向传播(HCCL自动同步梯度)
loss.backward() # 这里会触发AllReduce
optimizer.step()
total_loss += loss.item()
if batch_idx % 10 == 0:
print(f"[Rank {rank}] Epoch {epoch}, Batch {batch_idx}, Loss: {loss.item():.4f}")
# 同步所有进程的loss
avg_loss = torch.tensor(total_loss).npu()
dist.all_reduce(avg_loss, op=dist.ReduceOp.SUM)
avg_loss = avg_loss.item() / world_size
if rank == 0:
print(f"✓ Epoch {epoch} completed, Average Loss: {avg_loss:.4f}")
dist.destroy_process_group()
if __name__ == '__main__':
world_size = 8 # 8卡训练
torch.multiprocessing.spawn(
train_distributed,
args=(world_size,),
nprocs=world_size,
join=True
)五、总结
随着CANN的持续演进和开放,越来越多的开发者将能够基于昇腾平台,高效构建创新的AI应用。CANN正在成为连接AI算法与硬件算力的关键桥梁,助力AI普惠化发展,让智能计算触手可及。
参考资料:
