目录
[1. mysql部署](#1. mysql部署)
[1.1 环境准备](#1.1 环境准备)
[1.2 修改环境变量](#1.2 修改环境变量)
[1.3 添加数据库用户](#1.3 添加数据库用户)
[2. mysql的组从复制](#2. mysql的组从复制)
[2.1 配置master(主)](#2.1 配置master(主))
[2.2 配置salve(从)](#2.2 配置salve(从))
[2.3 添加slave2](#2.3 添加slave2)
[2.4 gtid模式](#2.4 gtid模式)
[2.5 启用半同步模式](#2.5 启用半同步模式)
[3. mysql高可用之MHA](#3. mysql高可用之MHA)
[3.1 MHA简介](#3.1 MHA简介)
[3.2 部署](#3.2 部署)
[3.3 配置MHA环境](#3.3 配置MHA环境)
[3.4 mysql-router](#3.4 mysql-router)
1. mysql部署
在企业中90%的服务器操作系统均为Linux
在企业中对于Mysql的安装通常用源码编译的方式来进行
1.1 环境准备
准备两台虚拟机(红帽7)
mysqla:172.25.254.10
mysqlb:172.25.254.20

解压gcc
全部解压完成
检查

安装所需插件

安装cmake3

解压MySQL包

root@mysqla \~# cd mysql-8.3.0/
建立安装目录
root@mysqla mysql-8.3.0# mkdir build
源码编译:
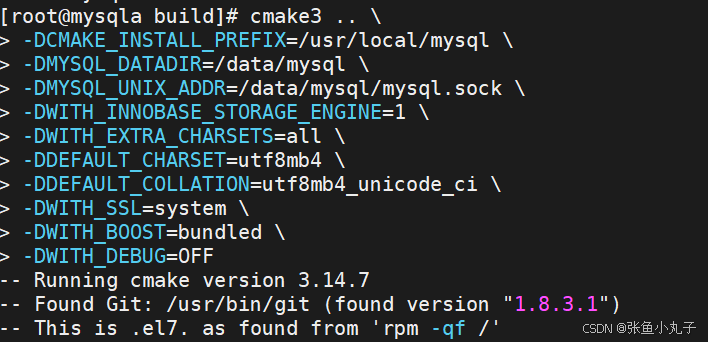
完成即可
make开始编译
编译完成即可
make install
生成启动脚本

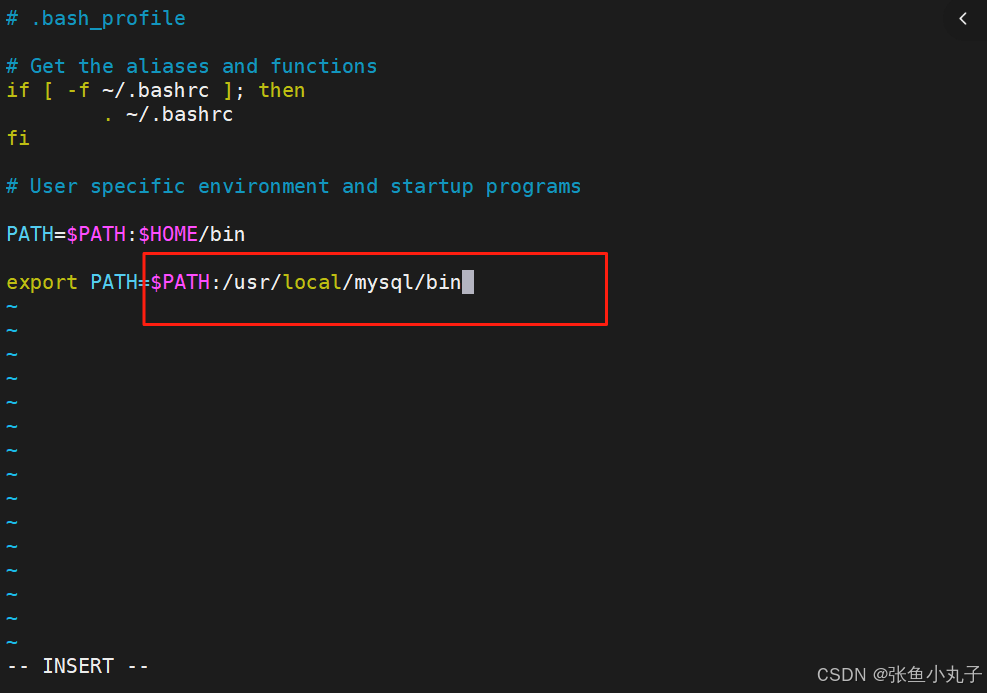
1.2 修改环境变量
root@mysqla \~# vim ~/.bash_profile
root@mysqla \~# source ~/.bash_profile
1.3 添加数据库用户
root@mysqla \~# useradd -M -s /sbin/nologin mysql
建立数据库目录

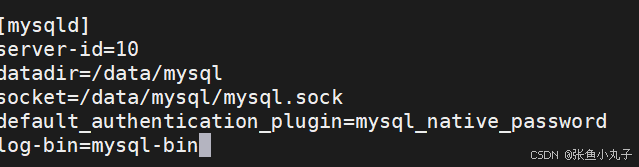
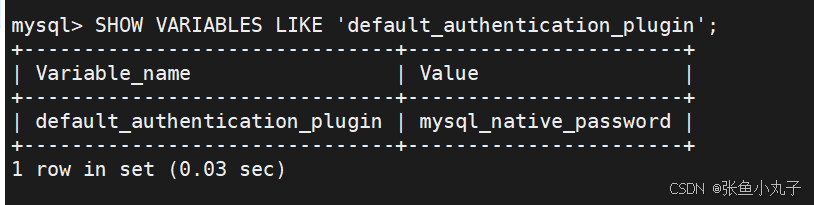
修改配置文件
root@mysqla \~# vim /etc/my.cnf
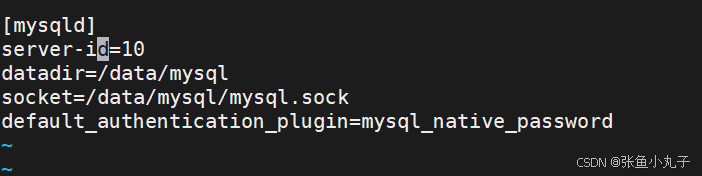
建立数据库基本信息
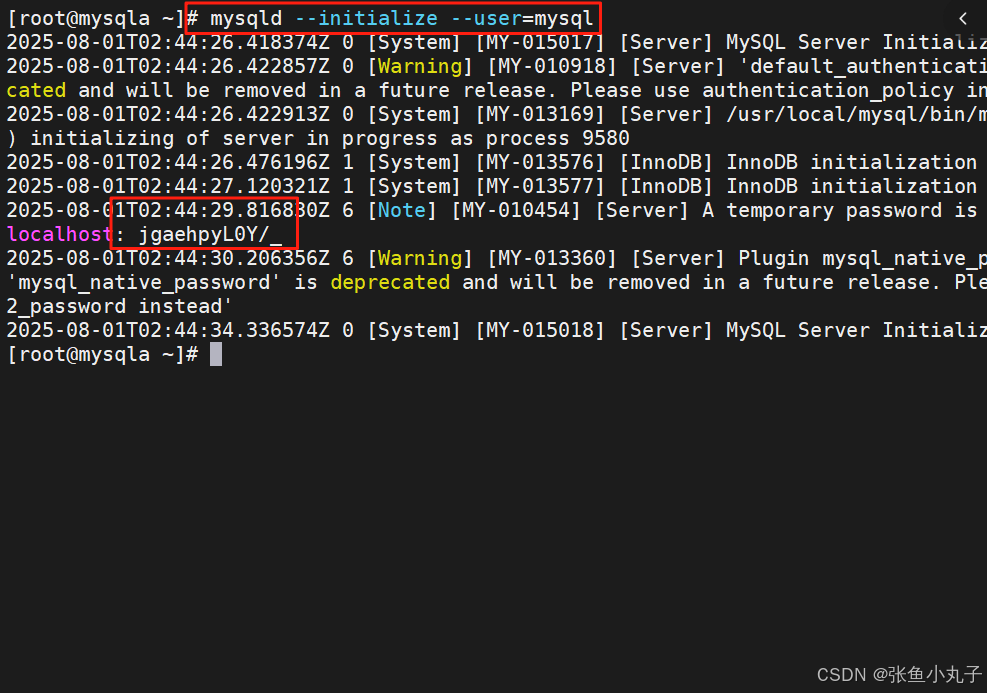


数据库安全初始化
root@mysqla \~# mysql_secure_installation
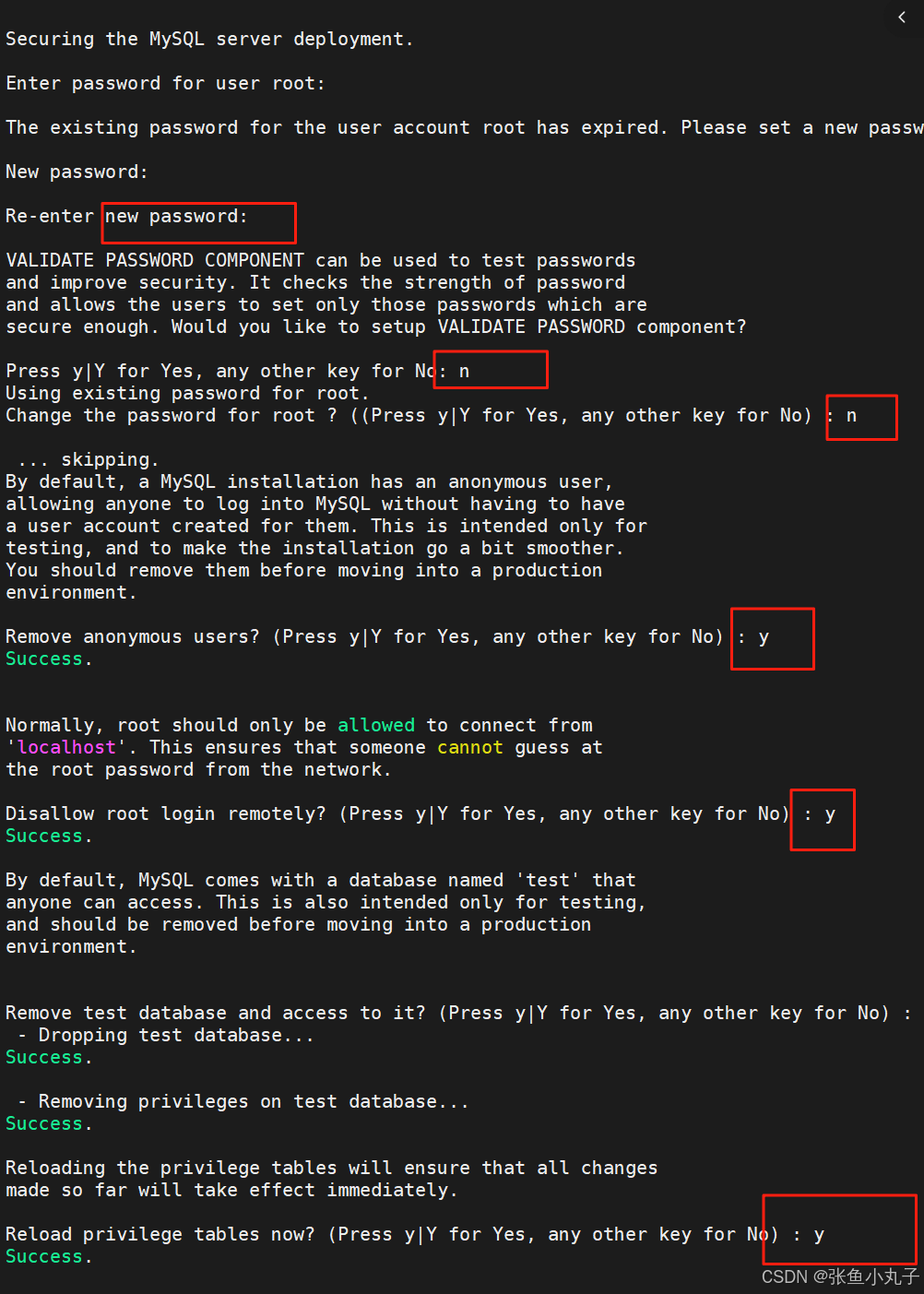
测试:
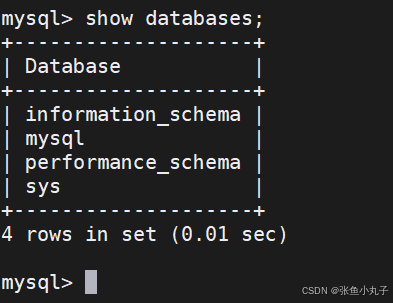
展示数据库
把mysqla的数据库复制到b去

其他操作跟a一致
2. mysql的组从复制
2.1 配置master(主)
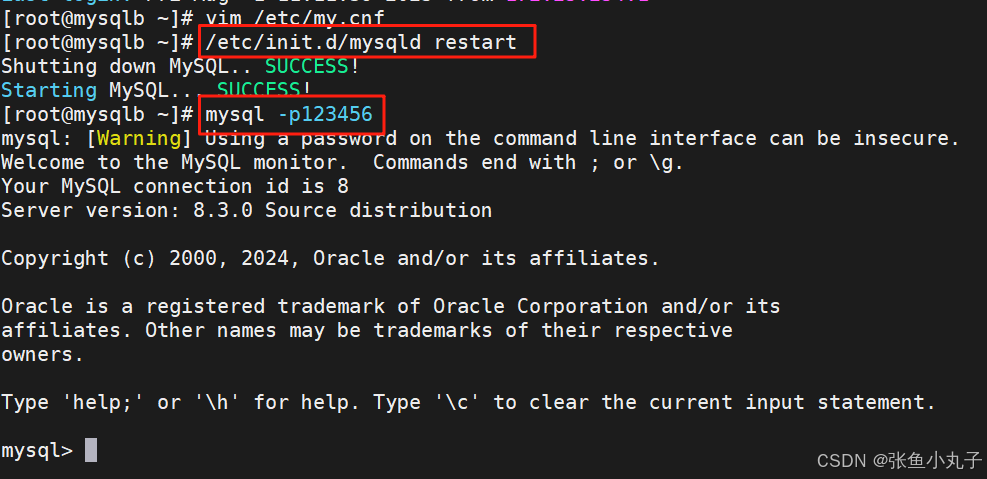
root@mysqla \~# vim /etc/my.cnf
root@mysqla \~# /etc/init.d/mysqld restart
Shutting down MySQL.. SUCCESS!
Starting MySQL.. SUCCESS!
生成专门用来做复制的用户,此用户是用于slave端做认证用
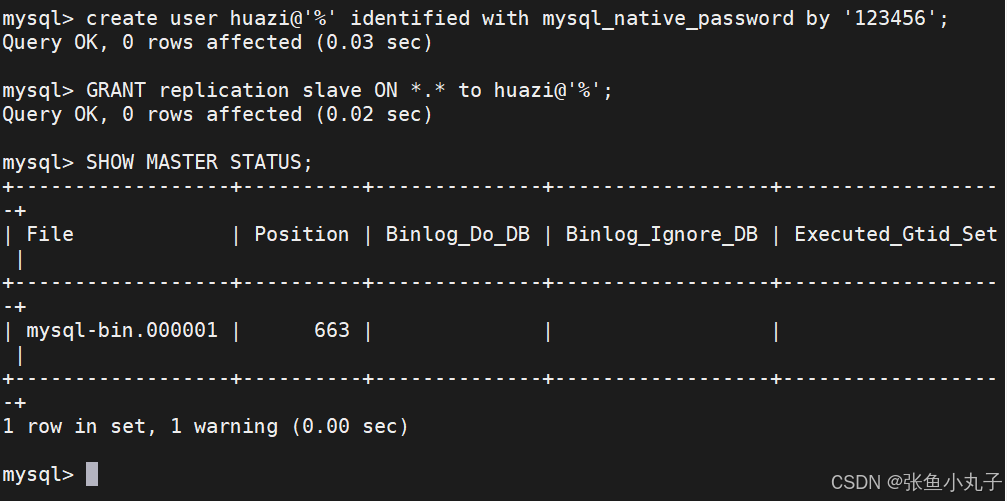
查看日志
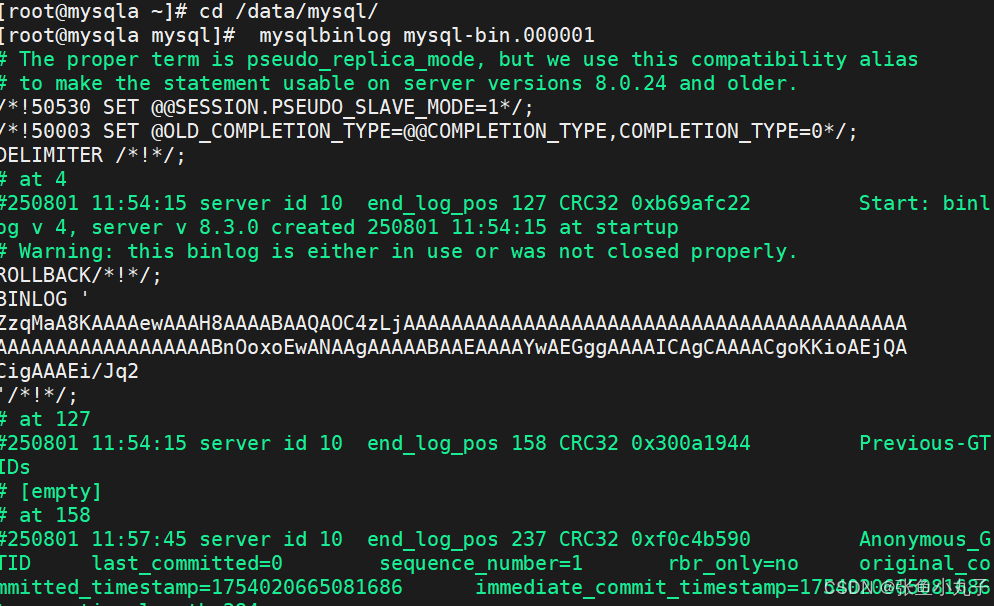
2.2 配置salve(从)
启动mysql
 查看
查看
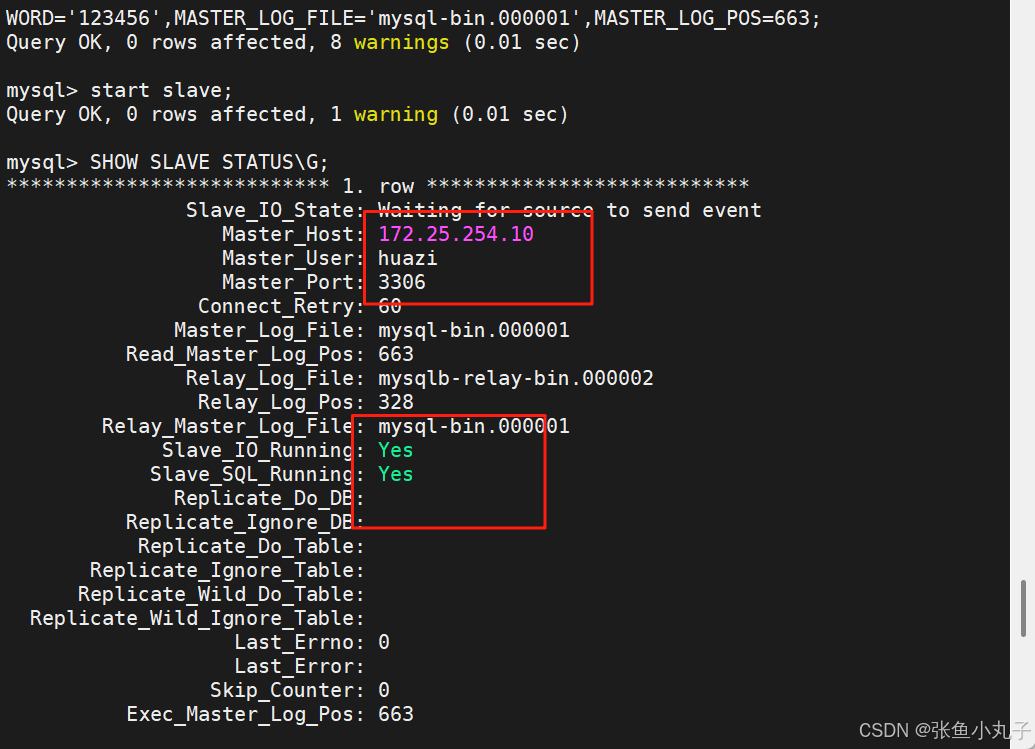
测试
在主中创表
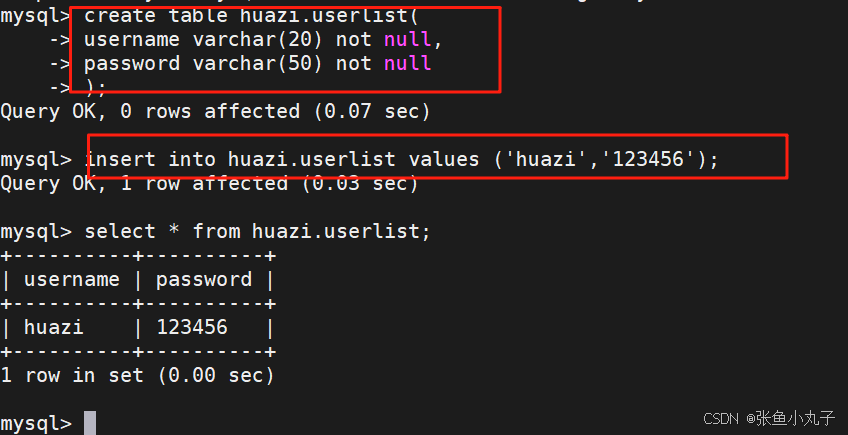
在从中可以看到主中的信息、
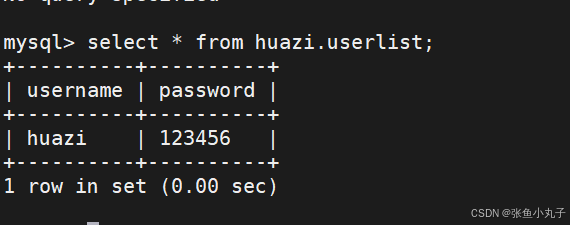
主从测试完成
2.3 添加slave2
再增加一台虚拟机,IP为172.25.254.30
把10的mysql复制到30去
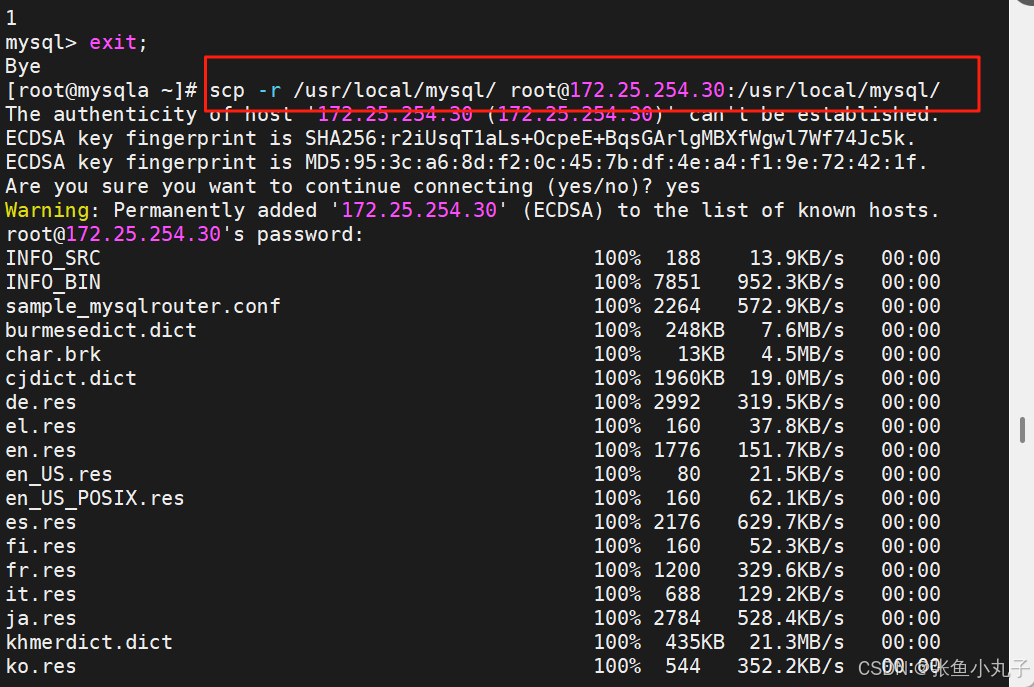
配置30,过程跟10一致
从10备份数据
把备份数据扯平

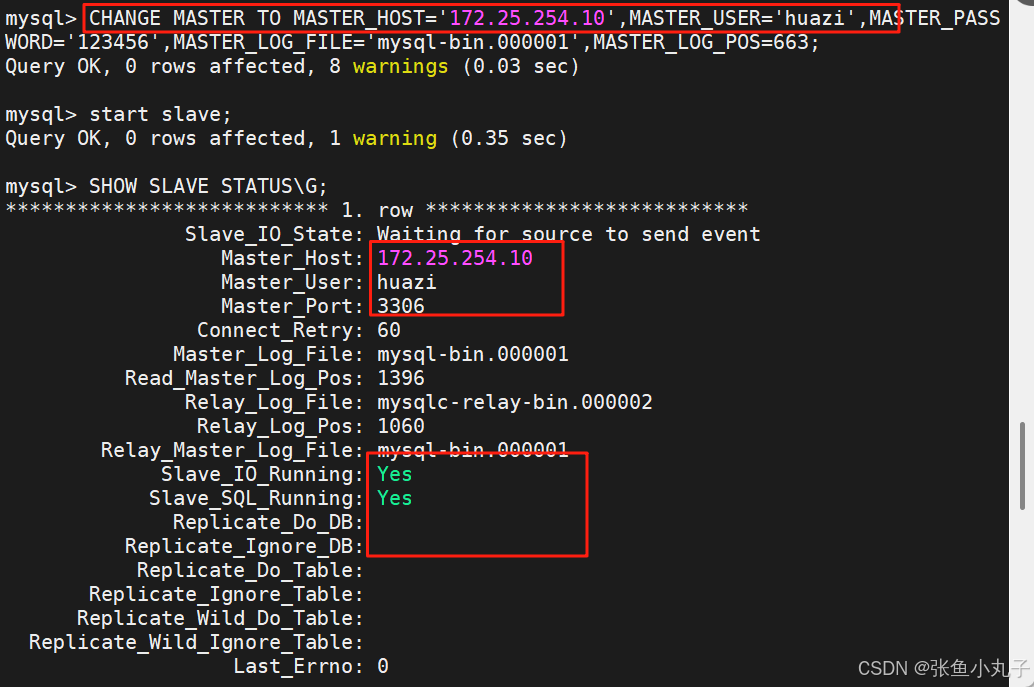
配置30的slave
在10中添加测试信息

在20中查看
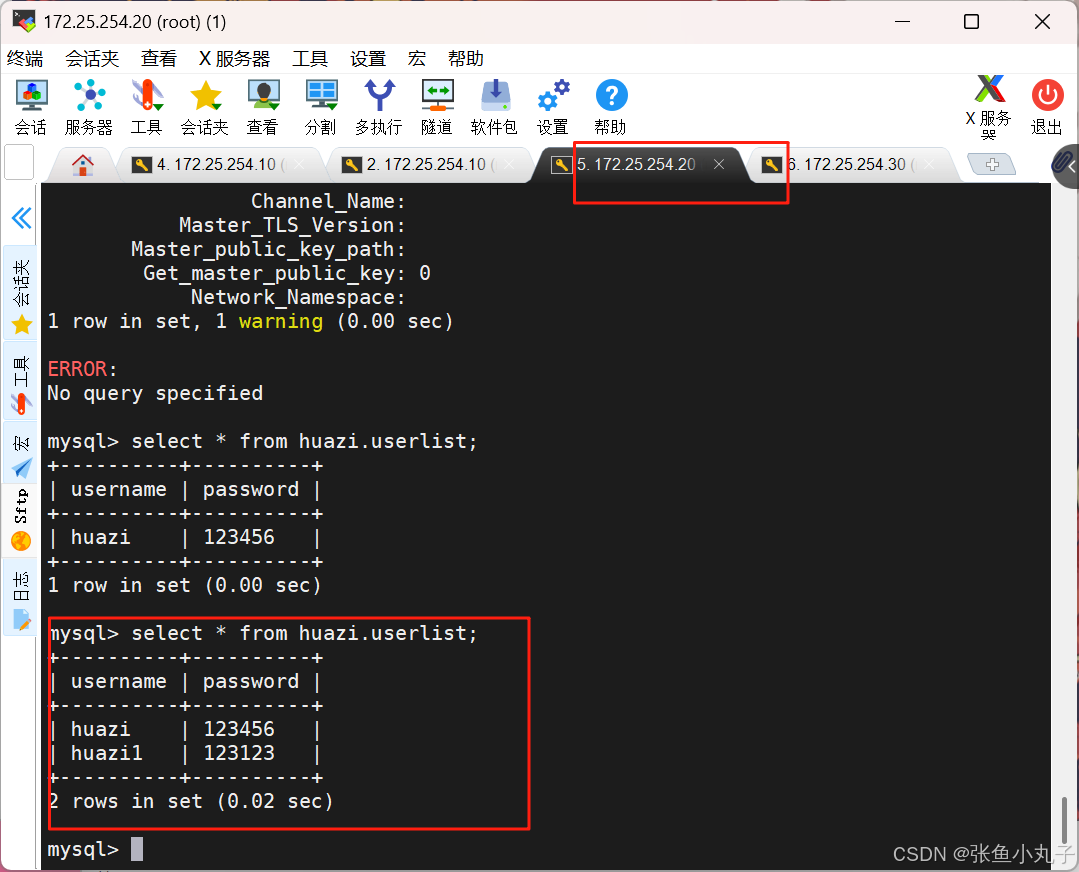
在30中查看
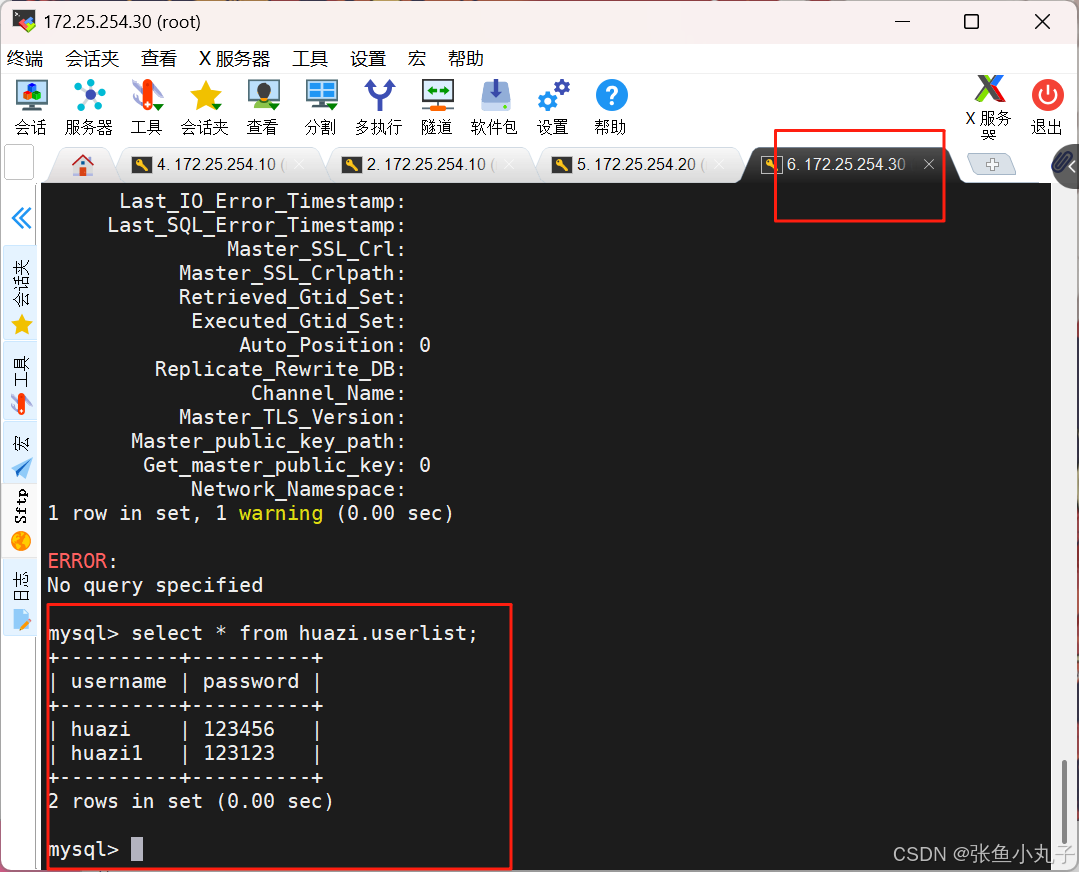
主从复制成功
2.4 gtid模式
当为启用gtid时我们要考虑的问题
在master端的写入时多用户读写,在slave端的复制时单线程日志回放,所以slave端一定会延迟与master端
这种延迟在slave端的延迟可能会不一致,当master挂掉后slave接管,一般会挑选一个和master延迟日志最接近的充当新的master
那么为接管master的主机继续充当slave角色并会指向到新的master上,作为其slave
这时候按照之前的配置我们需要知道新的master上的pos的id,但是我们无法确定新的master和slave之间差多少
当master出现问题后,slave2和master的数据最接近,会被作为新的masterslave1指向新的master,但是他不会去检测新的master的pos id,只需要继续读取自己gtid_next即可
设置gtid,在10和20中开启gtid模式
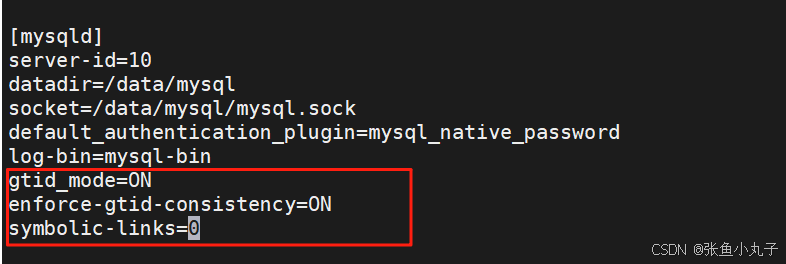
查看gtid
在20和30上停止slave

开启10的gtid

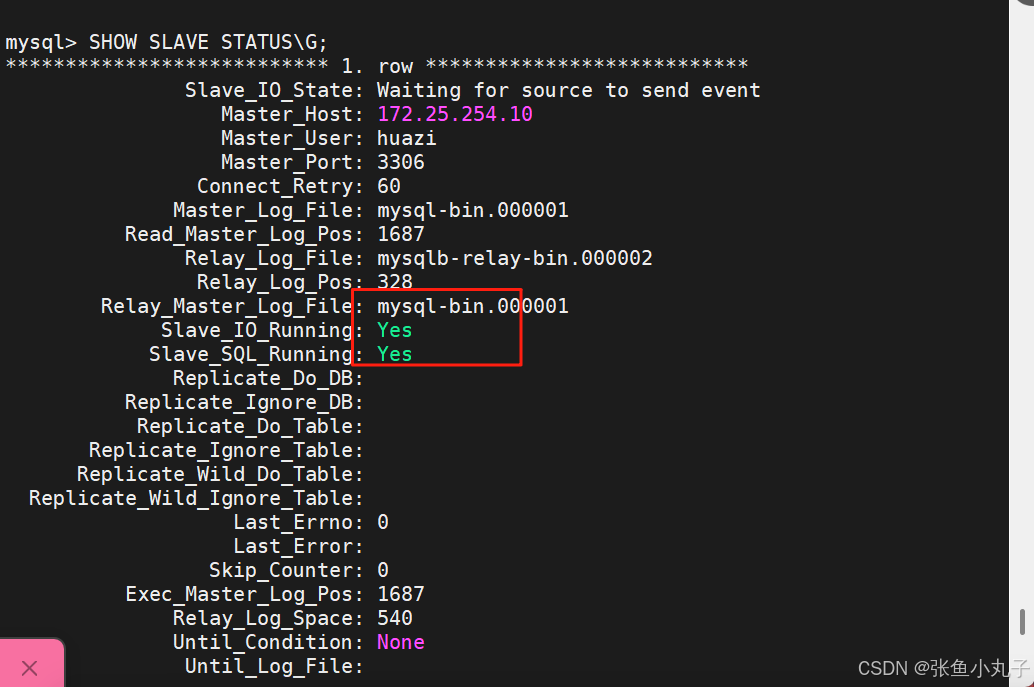 查看功能开启即可
查看功能开启即可
2.5 启用半同步模式
在10中编辑配置文件,启用半同步模式
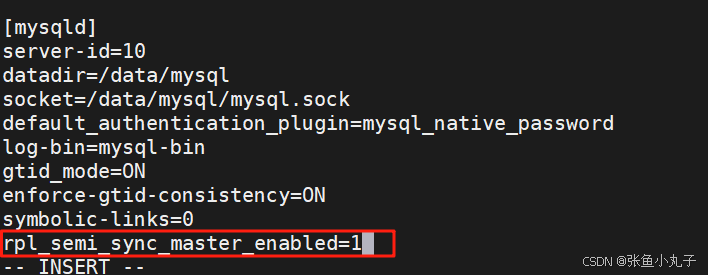
安装同步插件

查看安装情况
在20中开启同步功能
编写配置文件
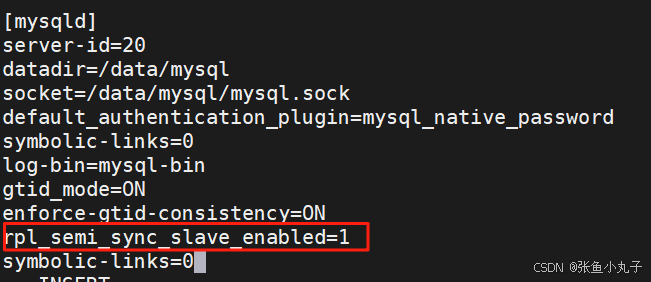
进入数据库设置

重启IO线程,重启之后半同步才可以生效

在10端写入数据,未同步时数据为0个
在20端和30端停止 slave,操作一致
mysql> STOP SLAVE IO_THREAD;
再次在10中插入与上述类似数据
一笔数据为同步,后面自动转为异步,当slave恢复时,后续也会自动恢复
3. mysql高可用之MHA
3.1 MHA简介
什么是 MHA?
MHA(Master High Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。
MHA 的出现就是解决MySQL 单点的问题。
MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。
MHA能在故障切换的过程中最大程度上保证数据的一致性,以达到真正意义上的高可用。
MHA 的组成
MHA由两部分组成:MHAManager (管理节点) MHA Node (数据库节点),
MHA Manager 可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台 slave 节点上。
MHA Manager 会定时探测集群中的 master 节点。
当 master 出现故障时,它可以自动将最新数据的 slave 提升为新的 master, 然后将所有其他的 slave 重新指向新的 master。
MHA 的特点
自动故障切换过程中,MHA从宕机的主服务器上保存二进制日志,最大程度的保证数据不丢失
使用半同步复制,可以大大降低数据丢失的风险,如果只有一个slave已经收到了最新的二进制日志,MHA可以将最新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性
目前MHA支持一主多从架构,最少三台服务,即一主两从
故障切换备选主库的算法
1.一般判断从库的是从(position/GTID)判断优劣,数据有差异,最接近于master的slave,成为备选主。
2.数据一致的情况下,按照配置文件顺序,选择备选主库。
3.设定有权重(candidate_master=1),按照权重强制指定备选主。
(1)默认情况下如果一个slave落后master 100M的relay logs的话,即使有权重,也会失效。
(2)如果check_repl_delay=0的话,即使落后很多日志,也强制选择其为备选主。
MHA工作原理
目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群必须最少有3台数据库服务器,一主二从,即一台充当Master,台充当备用Master,另一台充当从库。
MHA Node 运行在每台 MySQL 服务器上
MHAManager 会定时探测集群中的master 节点
当master 出现故障时,它可以自动将最新数据的slave 提升为新的master
然后将所有其他的slave 重新指向新的master,VIP自动漂移到新的master。
整个故障转移过程对应用程序完全透明。
3.2 部署
增加一台虚拟机,IP为172.25.254.100

解压并安装MHA-7.zip
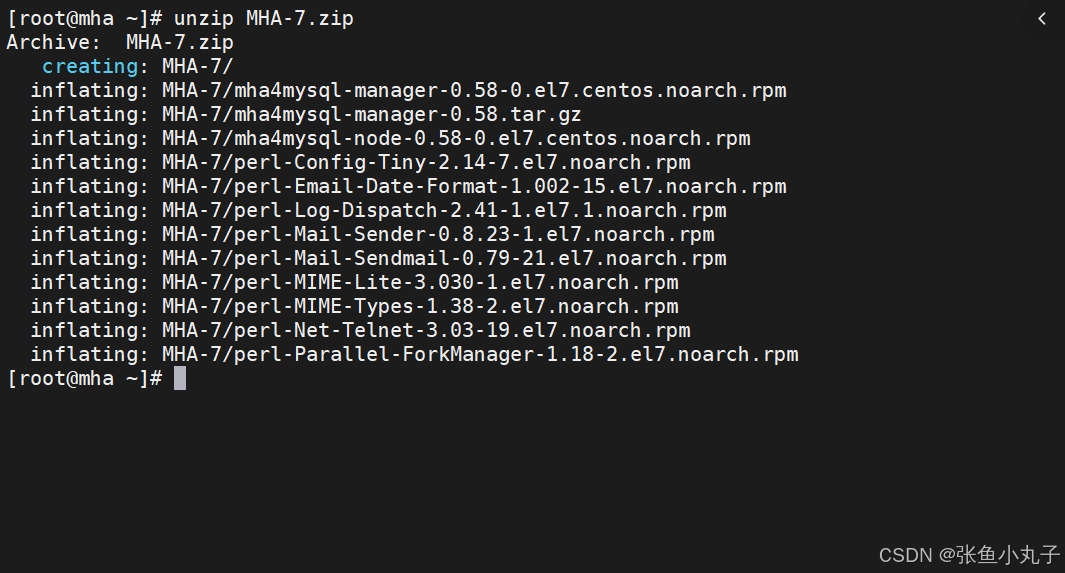
安装
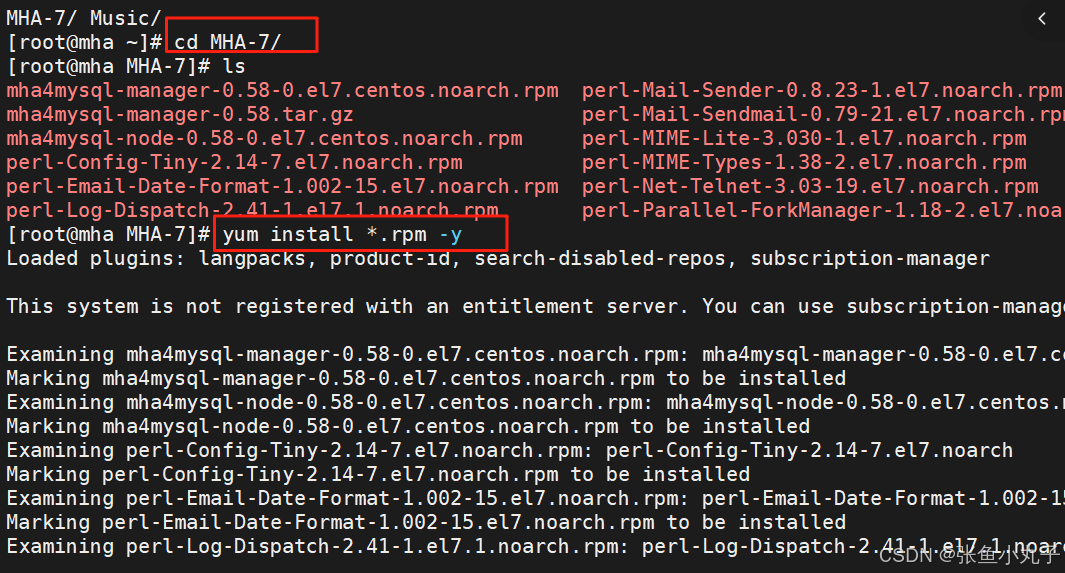
复制节点
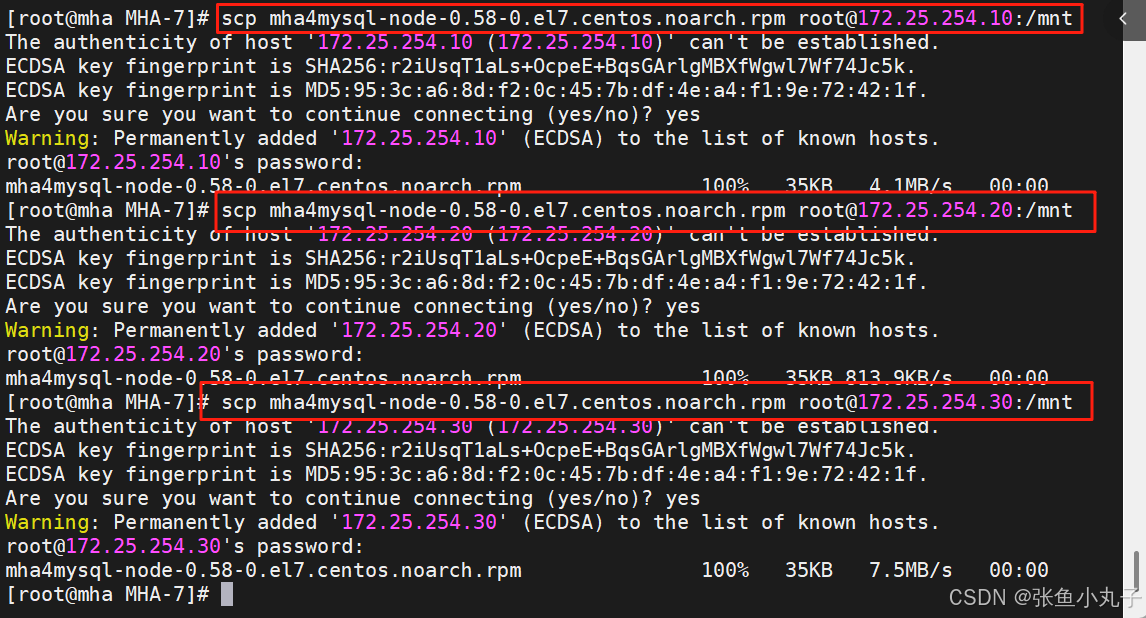
分别在3个主机中安装
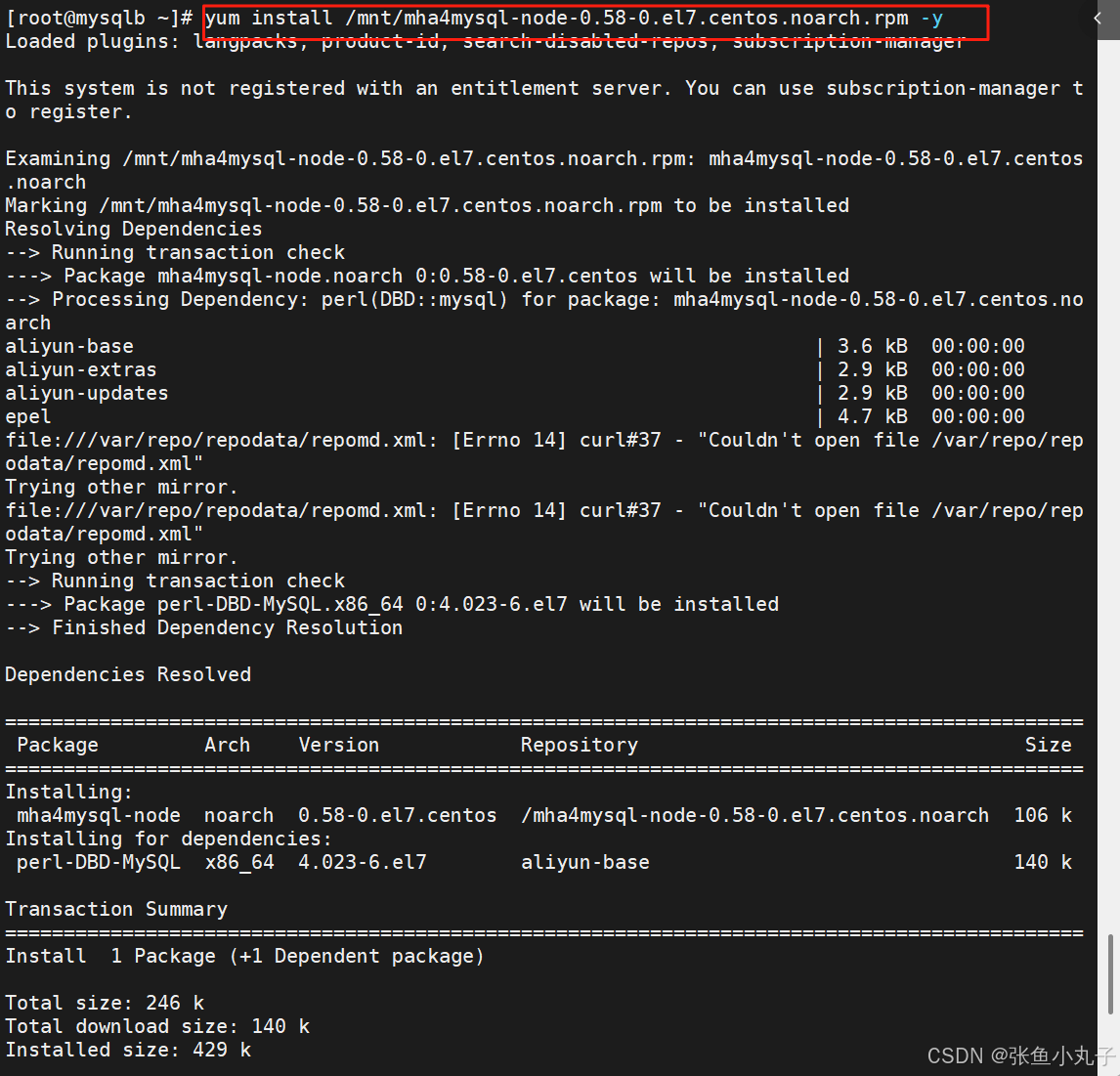
安装完成即可
3.3 配置MHA环境
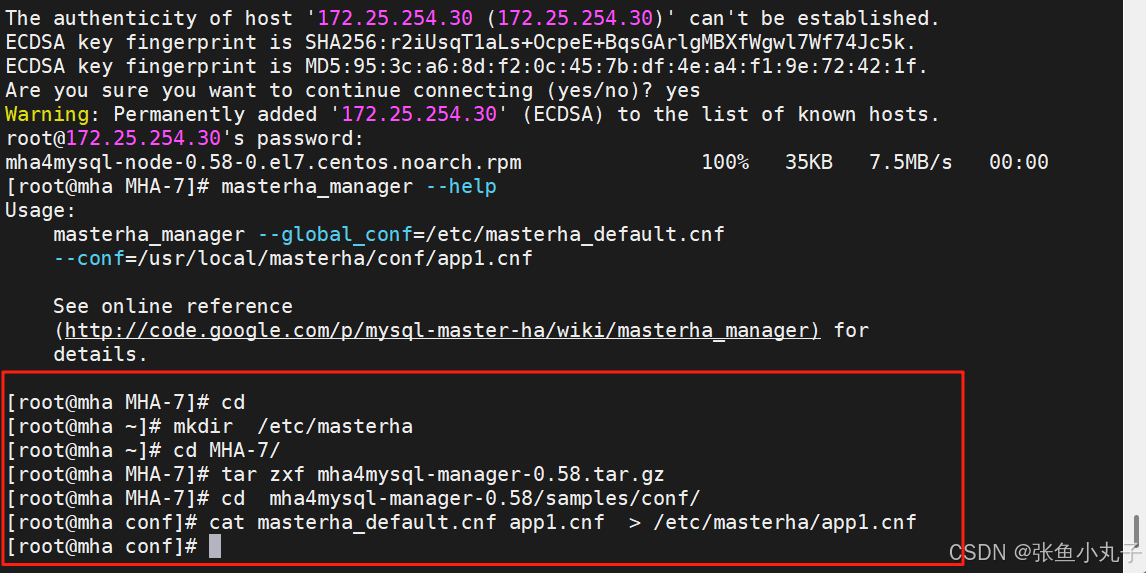
生成配置目录和文件
因为我们当前只有一套主从,所以我们只需要写一个配置文件即可
rpm包中没有为我们准备配置文件的模板
可以解压源码包后在samples中找到配置文件的模板文件
生成配置文件
编辑配置文件

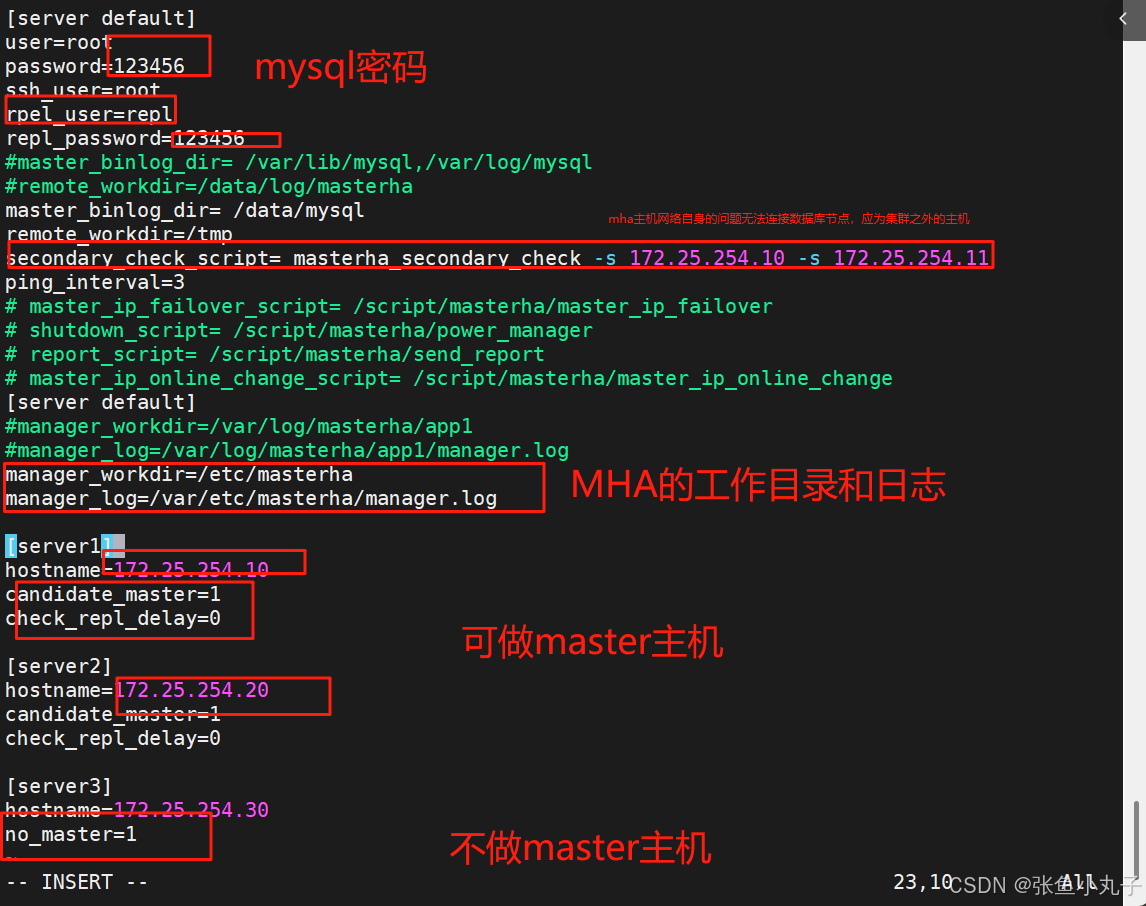
每个节点ssh允许登录
root@mysqlc \~# vim /etc/ssh/sshd_config
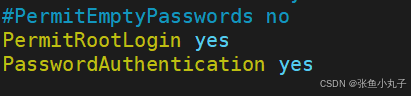
重启ssh服务

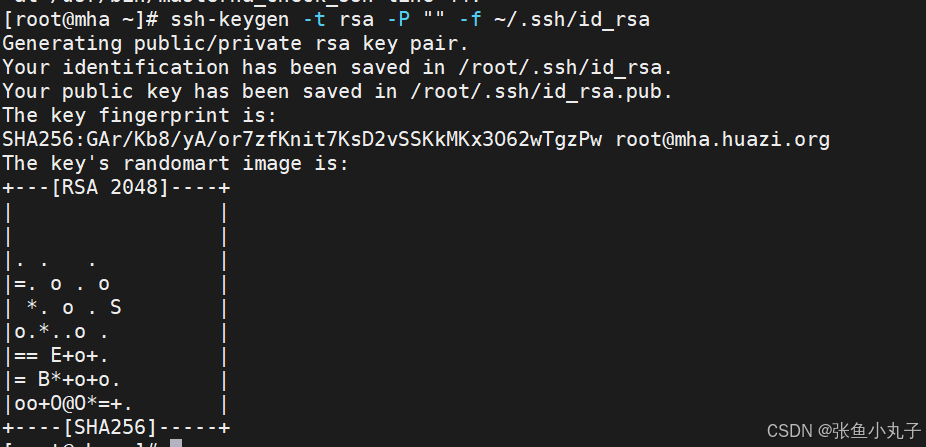
在 MHA Manager 节点(root@mha)生成 SSH 密钥
将公钥分发到所有数据库节点(172.25.254.10/20/30)
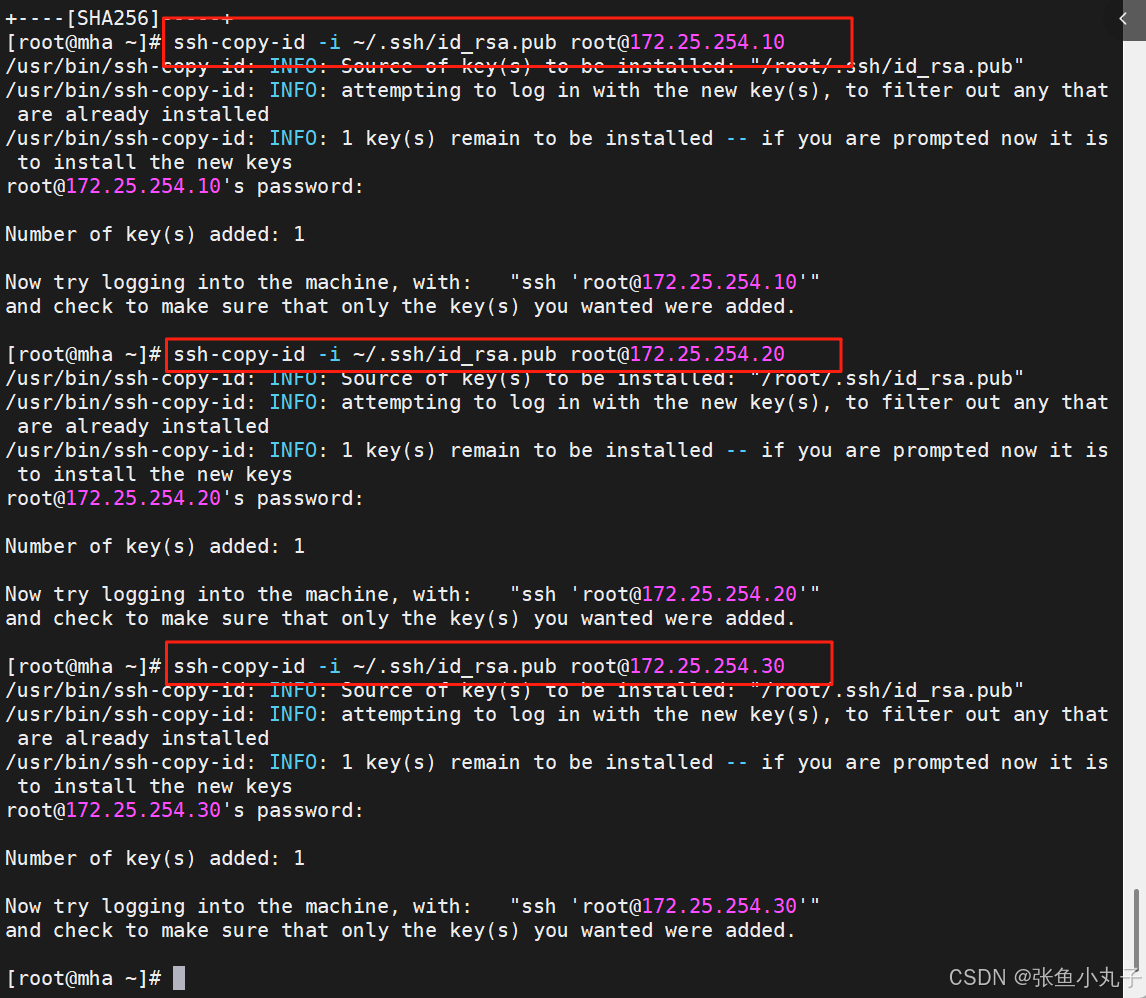
在每个数据库节点上,互相分发公钥(确保双向免密)
例如10,20和30与10一样
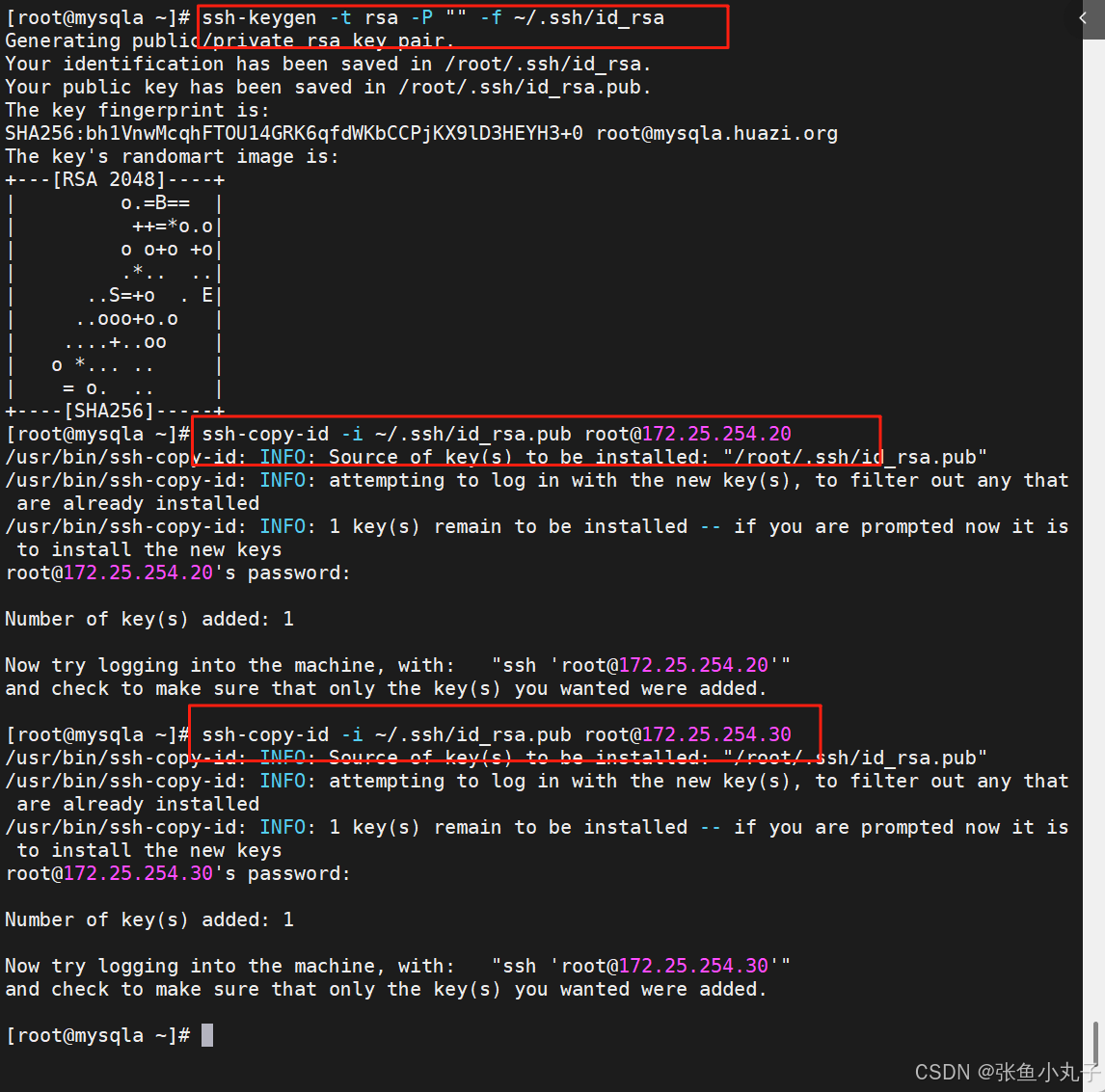
在任意节点测试到其他节点的免密登录,例如在mha节点:
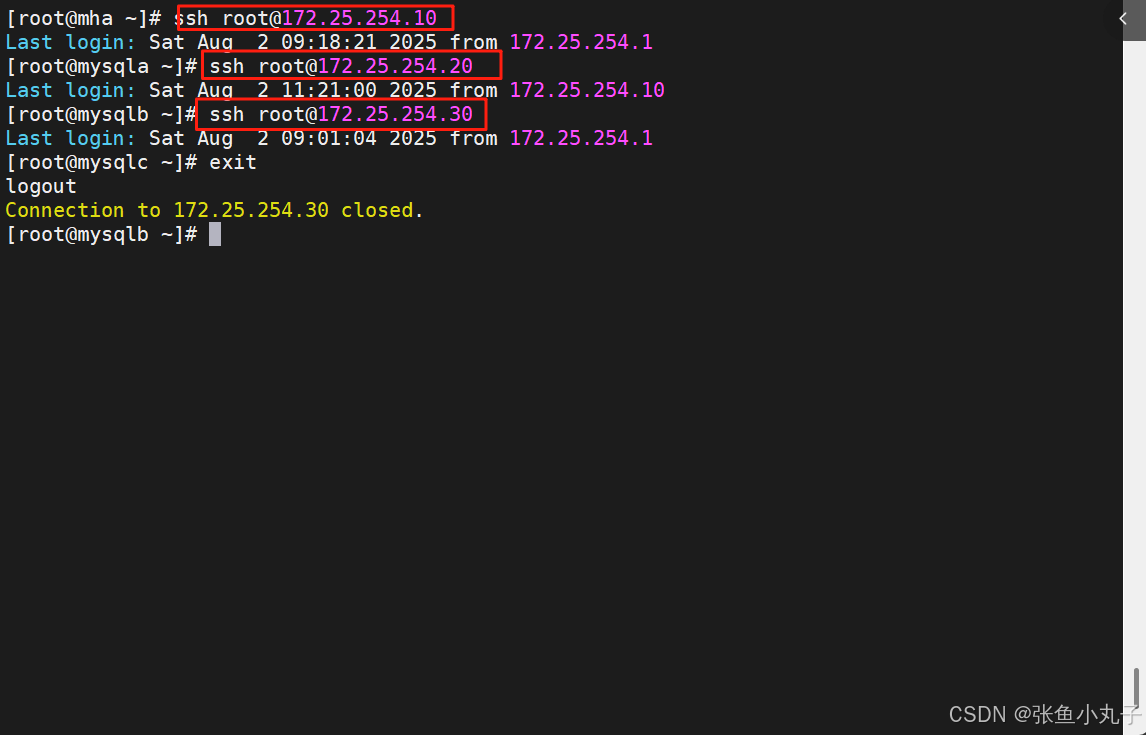
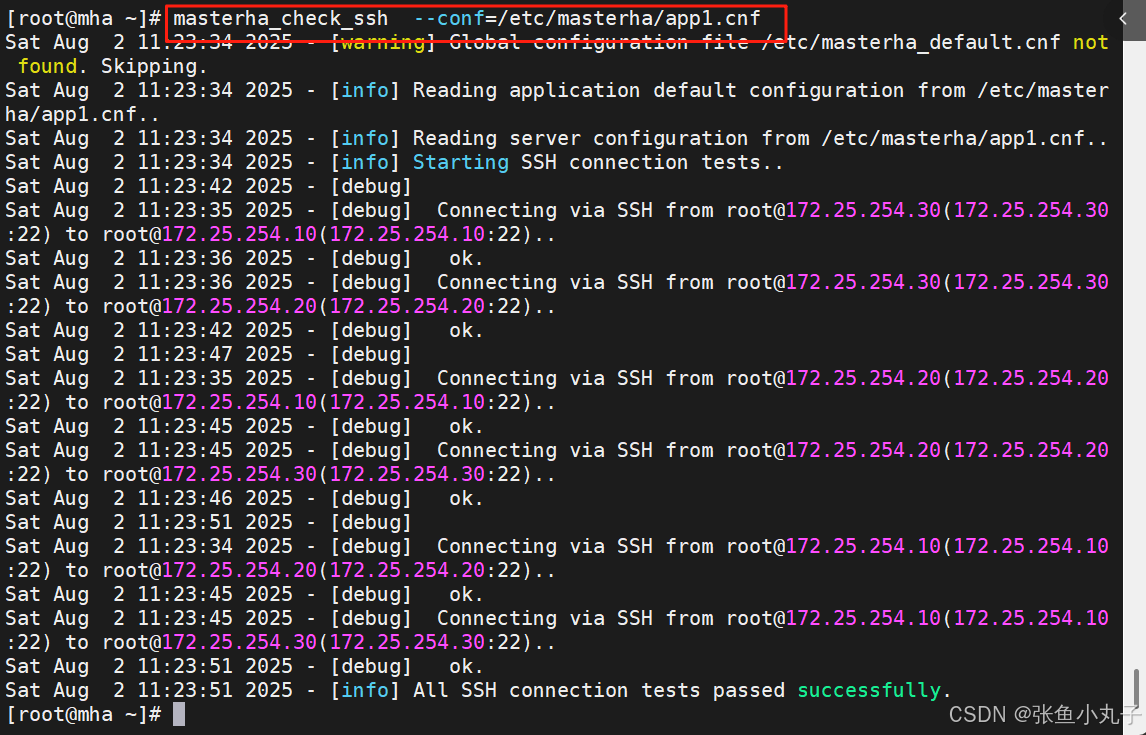
检测网络及ssh免密(测试成功)
在master允许root远程登录
- 先创建用户 root@'%'

- 再授予权限

- 刷新权限使配置生效

安装 DBD::mysql 及其依赖
先安装 MySQL 客户端开发库
安装 DBD::mysql 模块
在10,20和30配置如下
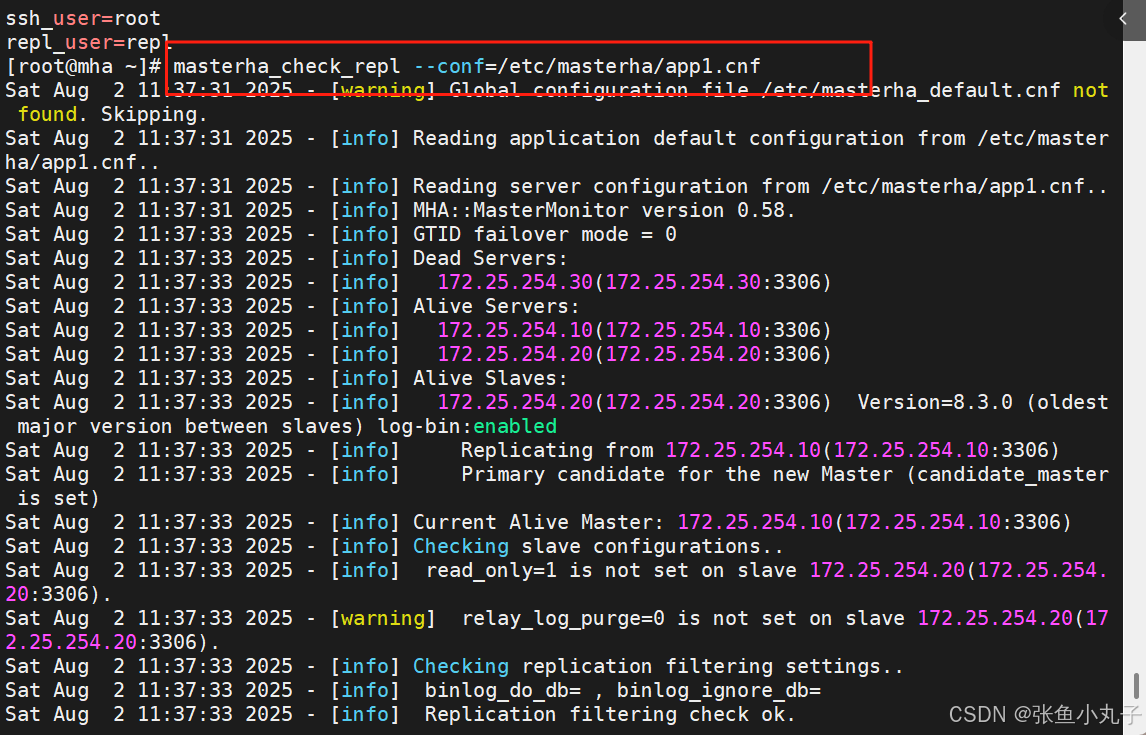
 检测主从复制情况
检测主从复制情况
为MHA添加VIP功能,上传脚本
更换地址并赋权

增加VIP的IP地址
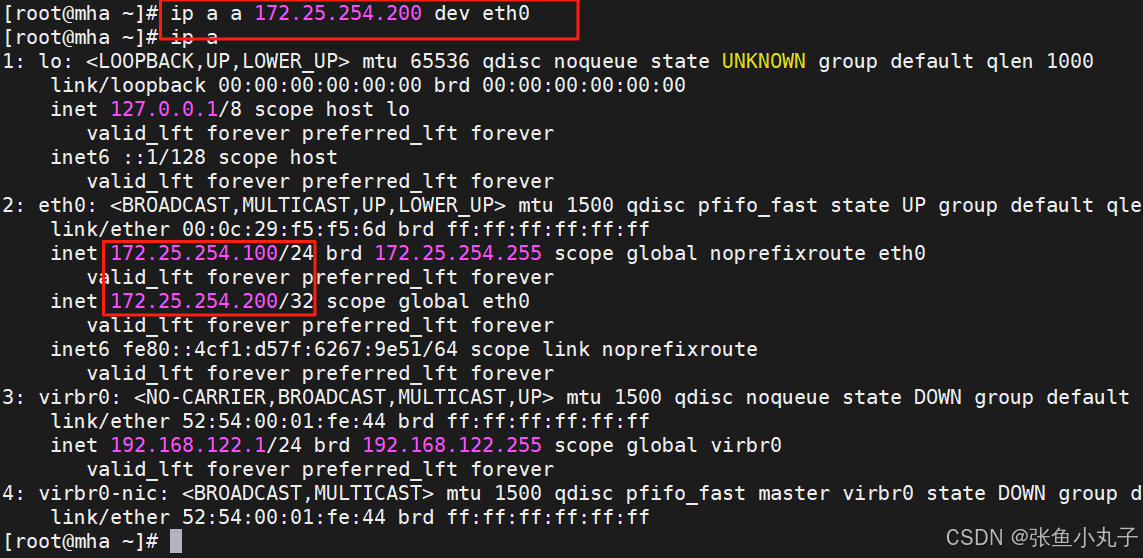
修改failover脚本,两个脚本都要修改
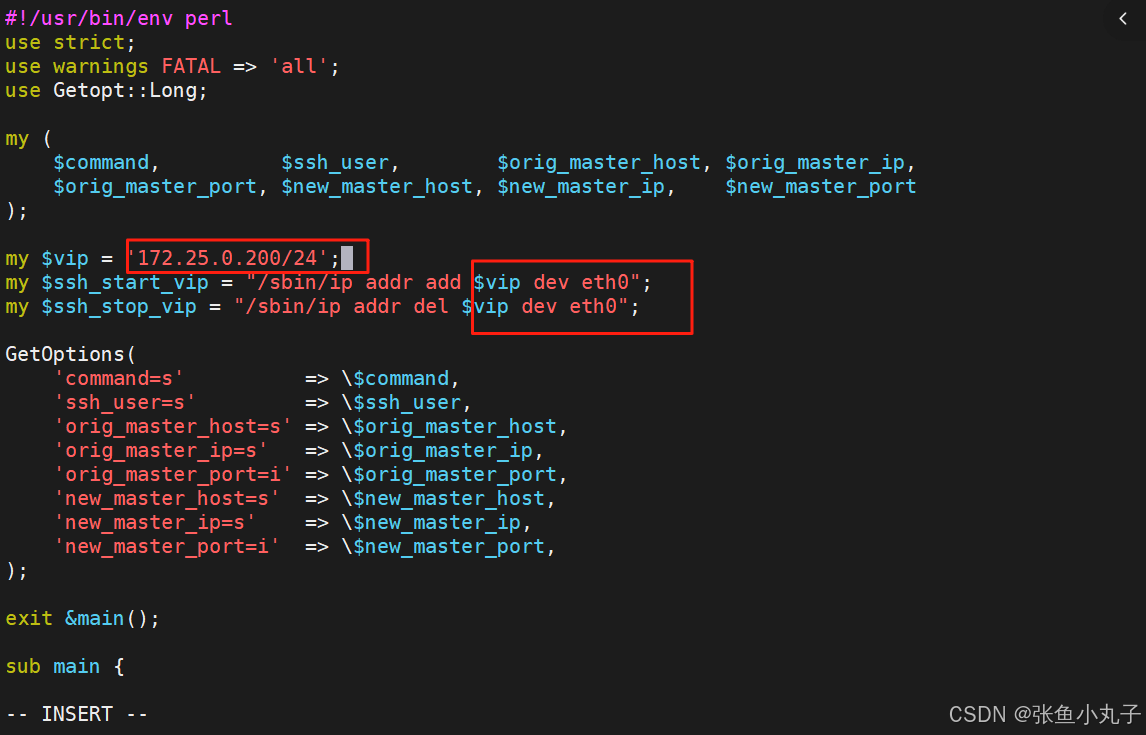
启动监控

3.4 mysql-router
MySQL Router
是一个对应用程序透明的InnoDB Cluster连接路由服务,提供负载均衡、应用连接故障转移和客户端路由。
利用路由器的连接路由特性,用户可以编写应用程序来连接到路由器,并令路由器使用相应的路由策略来处理连接,使其连接到正确的MySQL数据库服务器。
安装包
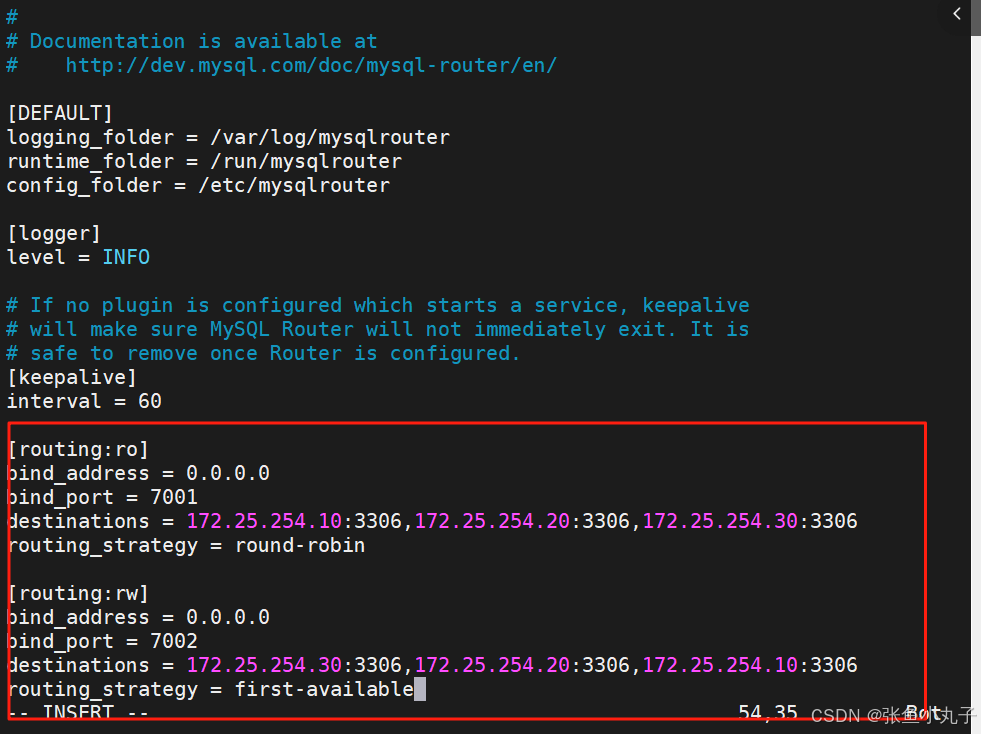
配置mysql-router
重启服务

建立测试用户
 查看调度效果
查看调度效果
root@mysqlb \~# watch -n 1 lsof -i :3306
