RAG : retrieval augmented generation : 检索增强生成
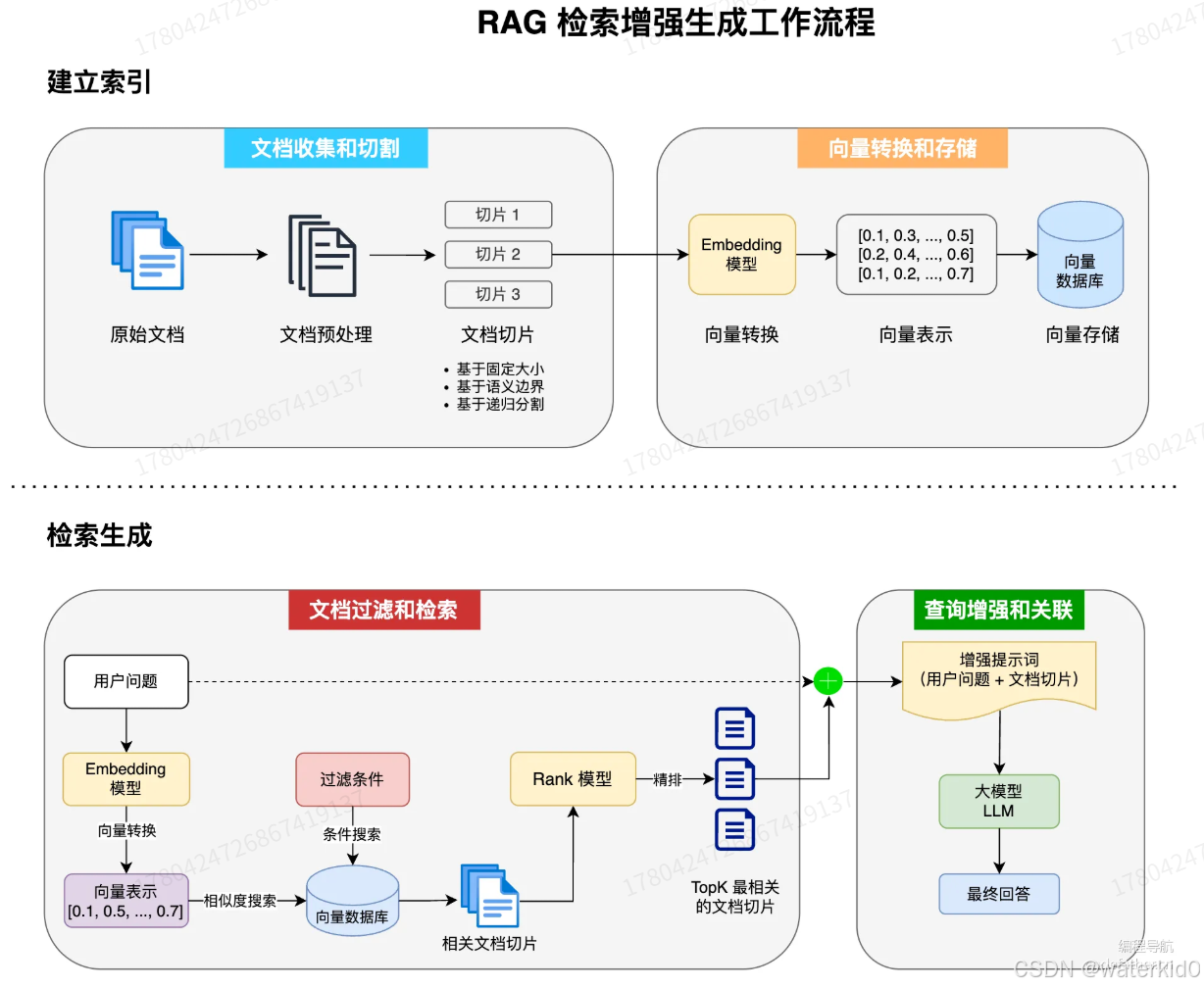
RAG工作流程
ETL : extract transform load
- extract : 准备文档,,将文档读取为spring ai中的
Document对象 - transform: 将获取到的
List<Document>转换成更加清晰的 `List - load: 将这些
Document写到目标存储中,,可以是文件系统FileDocumentWriter,, 也可以是向量数据库VectorStore
流程
文档的收集和切割
- 文档收集: 收集原始文档
- 文档预处理: 清洗,,标准化文本格式
- 文档切割: 基于不同的算法,,将长文档切割成适当大小的
chunks- 基于固定大小
- 基于语义
- 基于递归分割策略
如果用的是阿里云的百炼,,可以根据ai切割,,自己手动调整每个chunk的内容
在读取文本的时候,可以设置文档的标签,,可以基于ai去总结元数据:再查找的时候,可以根据元数据过滤调部分信息
MetadataEnricher : 元数据增强器
- KeywordMetadataEnricher: 使用ai提取关键字,并添加到元数据
- SummaryMetadataEnricher: 使用ai进行文档摘要,并添加到元数据,,和
KeywordMetadataEnricher不同的是,这个可以关联前后的文档片段,,进行总结(可以根据参数指定是否关联上下的文档片段,和提取几个关键词)
向量转换和存储
embedding : 嵌入: 是将 高维离散数据(如 文字,图片) 转换为 低维的连续向量的过程,,,,这些向量在数学空间中表示原始数据的语义特征,,使计算机能够理解数据间的相似性
向量转换: 使用Embedding模型 将 文本转换成 低维的连续向量,,可以捕获到文本的语义特性
向量存储: 将生成的向量 和 对应的文本,, 存放到向量数据库中,,支持高效的相似性搜索
文档过滤和检索
用户在查询的时候,也会把查询的内容转换成向量,,然后到向量数据库中查找相似的数据,,,,,基于元数据,关键词,自定义规则进行过滤,,搜索出来的东西根据相似度排序,,取最前面几个
名词
-
Embedding : 是将
高位离散数据(如 图片,文字)转换为低维连续向量的过程,,这些向量在数学空间中表示原始数据的语义特征,,使计算机能够理解数据间的相似性 -
Embedding模型: 是指执行这种转换算法的
机器学习模型,不同的Embedding模型产生的向量表示不同,维度数是向量表示的一个属性,,一般维度越高,表达能力更强,,可以捕获更丰富的语义信息和更细微的差别,,但同样也占用更多的存储空间 -
向量表示: vector representation : 是将文本,图像,声音等非结构化的数据转换为
稠密数值向量(dense vector)的过程 ,,,向量表示 = 维度数+ 各维度具体数值 -
向量数据库 : 专门存储和检索向量数据的数据库系统
-
召回 : 是信息检索的第一个阶段,,目标是从大规模数据集中快速筛选出可能相关的候选项子集,,
强调速度和广度,并非精确度 -
精排 : 是搜索 / 推荐系统 的最后阶段,,使用计算复杂度更高的算法,考虑更多特征和业务规则,对少量候选项进行更复杂,精细的排序

- Rank模型: 负责对召回阶段筛选出的候选集进行精确排序,考虑多种特征评估相关性(如:用户历史行为)
ETL 常用的类
-
DocumentReader接口
这个接口有很多实现类 ,,用来加载不同类型的数据,,变成
Document对象 -
DocumentTransformer接口 : 转换
- TextSplitter : 通过一些算法,把一个很长的文本,,切块,,,文本分割器
- TokenTextSplitter : 基于语义的文本分割器,,考虑了语义边界,,比如句子结尾,,来创建有意义的段落
这两个分割器都是不需要使用ai的,,,也可以调用ai来进行文档的分割
-
DocumentWriter接口: 将Document写到目标存储中
- FileDocumentWriter : 基于文件系统
- VectorStore : 基于向量数据库,