前言
在使用RAG辅助LLM完成知识问答任务时,无论检索是否必要或者段落是否相关,不加选择地检索和合并固定数量的检索段落,都会降低LM的通用性,或者可能生成无益的反应。
本工作引入了一种名为自反思检索增强生成(Self-RAG)的新框架,通过检索和自我反思来提高LM的质量和真实性:
(1)以端到端的方式训练一个任意的LM,该LM按需自适应地检索段落;
(2)使用称之为反思token(包含检索token和评论token)的特殊token生成和反思检索到的段落及其自己的生成;
(3)反思token使LM在推理阶段可控,使其能够根据不同的任务要求调整其行为。
一、模型结构
Self-RAG是一个框架,通过检索和自我反思提高LLM的质量和真实性,同时不牺牲LLM的原始创造力和多功能性。模型结构如下图所示:
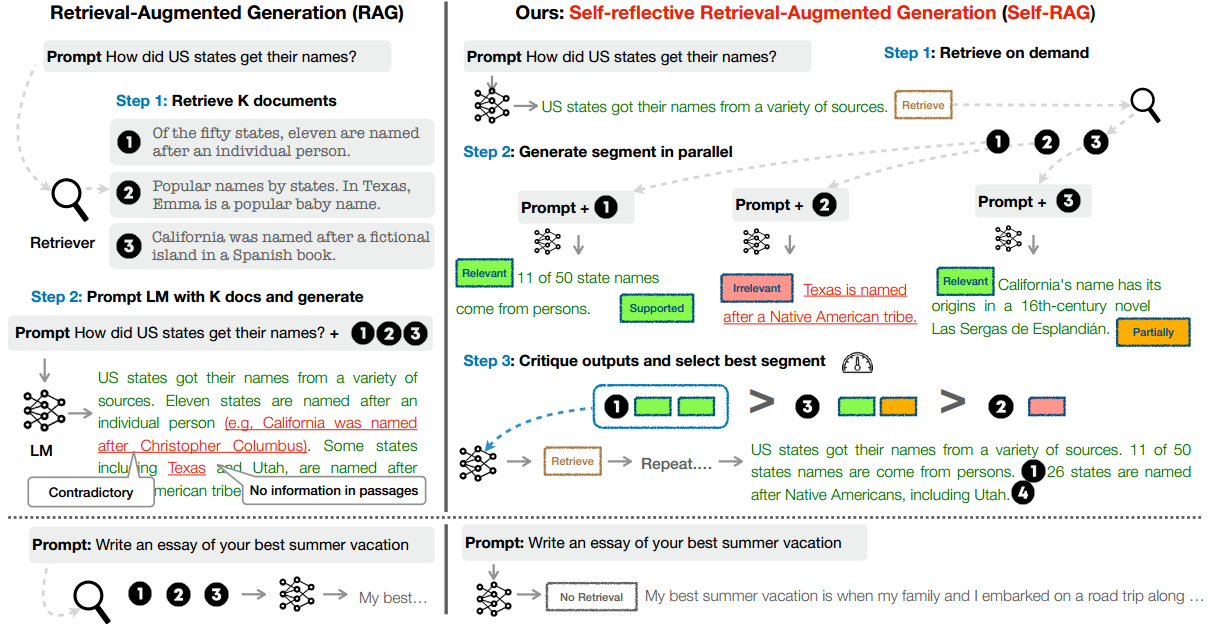
1.1 问题形式化和概述
形式上,给定输入 ,我们训练生成器
,顺序生成由多个片段
组成的文本输出
,其中
表示第
个片段的token序列。
中生成的token包括原始词汇表中的文本token以及反思token。
反思token的构成如下表所示:

1.2 步骤
Self-RAG的步骤:
(1)在给定输入提示词和先前生成的情况下,Self-RAG首先确定用检索到的段落增强下一次生成是否有帮助。如果是,它会输出一个检索token,按需调用检索器模型;
(2)Self-RAG同时处理多个检索到的段落,评估它们的相关性,然后生成相应的任务输出;
(3)它生成评论token来批评自己的输出,并在事实性和整体质量方面选择最佳输出。
二、 训练
我们在一个多样化的数据集上训练生成模型 ,该数据集由自然文本、反思token以及检索到的段落交错组成。
反思token并非在模型训练过程中实时生成,而是由一个预先训练好的评论模型 在数据预处理阶段离线生成的,这样能降低开销。该评论模型部分地基于一个监督数据集进行训练,该数据集包含输入、输出以及对应的反思token,这些token通过对专有语言模型(GPT-4)进行提示而收集得到。
简而言之,先训练评论模型 (数据集是输入输出文本,以及由LLM生成的反思token)。训练完毕之后,评论模型生成反思token语料库,与自然文本和检索到的段落混合到一起,再训练生成模型
。
2.1 训练评论模型
2.1.1 收集训练数据
主要通过一下两个步骤来收集训练评论模型的数据集:
(1)提示GPT-4生成反思token来创建监督数据;
(2)将它们的知识蒸馏到内部语料库中(也即随机采样,
)。
2.1.2 模型训练
在收集完毕训练数据 后,用预训练的LM初始化
,并使用标准的条件语言建模目标在
上训练它,最大限度地提高似然性:
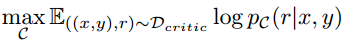
其中 是反思token。在训练评论模型
时,本工作所选的预训练模型是Llama 2-7B。
2.2 训练生成模型
2.2.1 收集训练数据
收集训练生成模型的数据集的步骤:
(1)首先给定输入-输出对 ;
(2)运行评论模型 判断是否需要检索(即使用评论模型
生成检索token);
(3)需要检索,则添加 tokenRetrieve =Yes ,然后检索器 检索得到前K个段落;
(4)对于每一个检索得到的段落, 进一步评论是否相关,得到token ISREL (同理,使用评论模型
生成评论token);
(5)如果是相关的,则对比检索得到的段落与输出 ,确认该段落是否支持模型生成输出
,得到token ISSUP (同理,使用评论模型
生成评论token);
(6)在输出 的最后,评估整体效用,得到token ISUSE (同理,使用评论模型
生成评论token)。
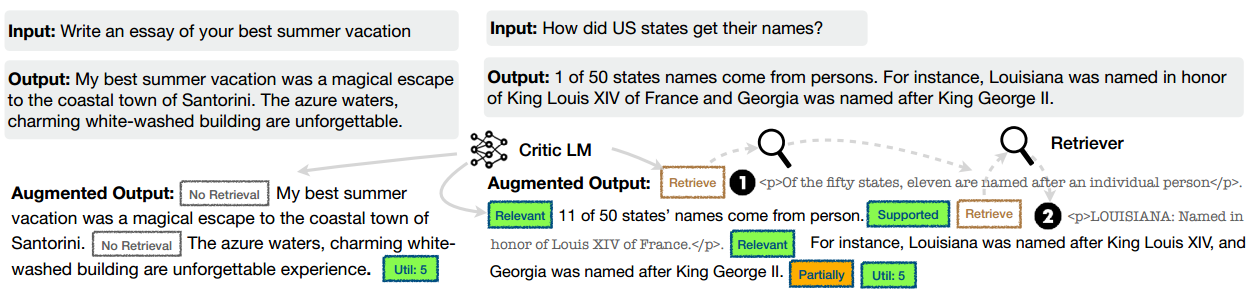
生成的数据示例如下图所示。其中左边的例子不需要检索,而右边的例子需要检索,因此,段落被插入:
2.2.2 模型训练
通过使用标准的下一个token目标 在语料库(自然文本、反思token以及检索到的段落)上训练生成模型 :
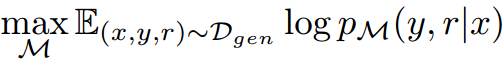
与训练评论模型 不同,训练生成模型
,使之预测目标输出以及反思token。在训练过程中,我们屏蔽了检索到的文本块(数据示例图中被<p>和</p>包围)以进行损失计算。
三、推理
对于要求事实准确性的任务,我们的目标是使模型更频繁地检索段落,以确保输出与可用证据紧密一致。相反,在更开放的任务中,比如写一篇个人经历文章,重点转向检索更少的内容,并优先考虑整体创造力或实用性得分。
本工作在推理过程中通过实施控制,可以满足这些不同目标的方法。
3.1 推理层面1
推理的流程如下算法所示:

对于每一个 和先前生成
,该模型都会对检索token Retrive进行解码,以评估检索的使用:
(1)不需要检索。模型直接预测下一个输出段(与标准LLM一样);
(2)需要检索。生成四部分:
a)一个评价token ISREL。先检索,后评价检索到的文章的相关性;
b)下一个生成的段;
c)一个评价token ISSUP,评价下一个生成的段中的信息是否得到检索到的文章的支持;
d)一个评价token ISUSE,评价响应的整体效用。
3.2 推理层面2
LLM是一个片段(segment)一个片段生成的,先检索段落,再生成候选。在每一个步骤 :
(1)检索器 检索K个段落,生成器
并行的根据每个段落生成K个不同的候选;
(2)根据评论token,计算各个候选的得分(由基础生成概率和一个评论得分 共同更新,其中评论得分是各类反思 token 归一化概率的线性加权和);
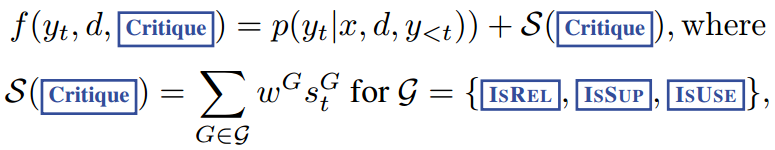
其中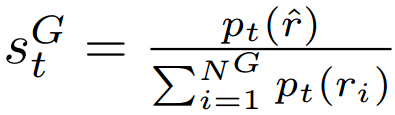 表示在评论 token 类型
表示在评论 token 类型 中,最理想反思 token
(例如 IsREL=Relevant)的生成概率;其中
表示该类型
中 token 的数量。权重
是超参数,可以在推理时进行调整,以在测试时实现定制行为。例如,为了确保结果
得到证据的支持,我们可以为ISSUP评分设置一个更高的权重项,同时相对降低其他方面的权重。
(3)选择前B个候选,作为最终生成的输出(这一步即是片段级束搜索的核心);
(4)本轮步骤t结束,将输入和步骤t的输出拼接,作为下一步骤的输入(输入的数量为B);
(5)继续判断是否需要检索,如果检索,则进入步骤 ,继续执行(1)。
(6)最终结束时,只保留得分最高的一条输出(即"从头到尾表现都最好"的路径),作为最终整个过程的输出。
3.3 带阈值的自适应检索
Self-RAG通过预测Retrieve来动态决定何时检索文本段落。或者,我们的框架允许设置阈值。具体来说,如果生成token Retrive=Yes的可能性经过归一化后,超过指定阈值,则触发检索。
四、总结
(1)Self-RAG通过将反思token统一建模为"扩展模型词表中的下一词预测任务",从而训练任意LLM,生成带有反思标记的文本;
(2)Self-RAG可以按需选择是否检索文档,以及评论自己的生成内容是否准确;
(3)基于训练好的生成模型,Self-RAG还可以通过利用反思token在推理时定制LM行为。