在构建垂直领域 RAG 系统时,信息抽取是连接**"原始文档 → 知识图谱 / 向量库 → 智能问答"的关键一环。如果没有稳定、可控、可溯源**的抽取能力,后面的 RAG、Agent、溯源问答都只是空中楼阁。
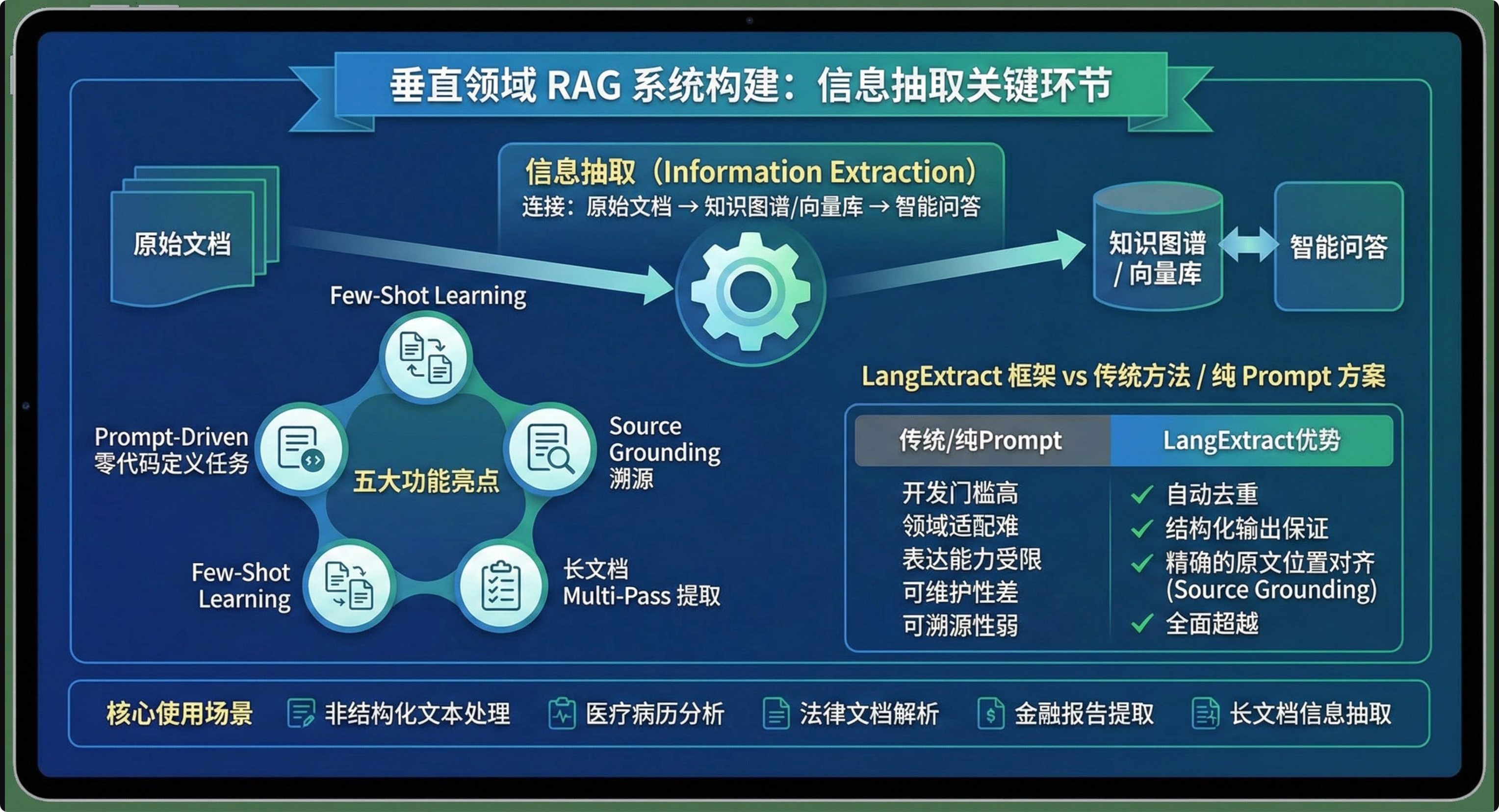
本文系统讲解 Google 开源的 LangExtract 框架,重点围绕:
- 核心使用场景:非结构化文本处理、医疗病历分析、法律文档解析、金融报告提取、长文档信息抽取
- 五大功能亮点:Prompt-Driven 零代码定义任务、Few-Shot Learning、Source Grounding 溯源、Schema Enforcement、长文档 Multi-Pass 提取
- 与传统方法 / 纯 Prompt 方案的对比:自动去重、结构化输出保证、精确的原文位置对齐(Source Grounding),从开发门槛、领域适配、表达能力、可维护性、可溯源性五大维度全面超越传统方案
一、非结构化文本的痛点与 LangExtract 的定位
1.1 非结构化文本:信息密度高,结构混乱复制
以医疗场景为例:
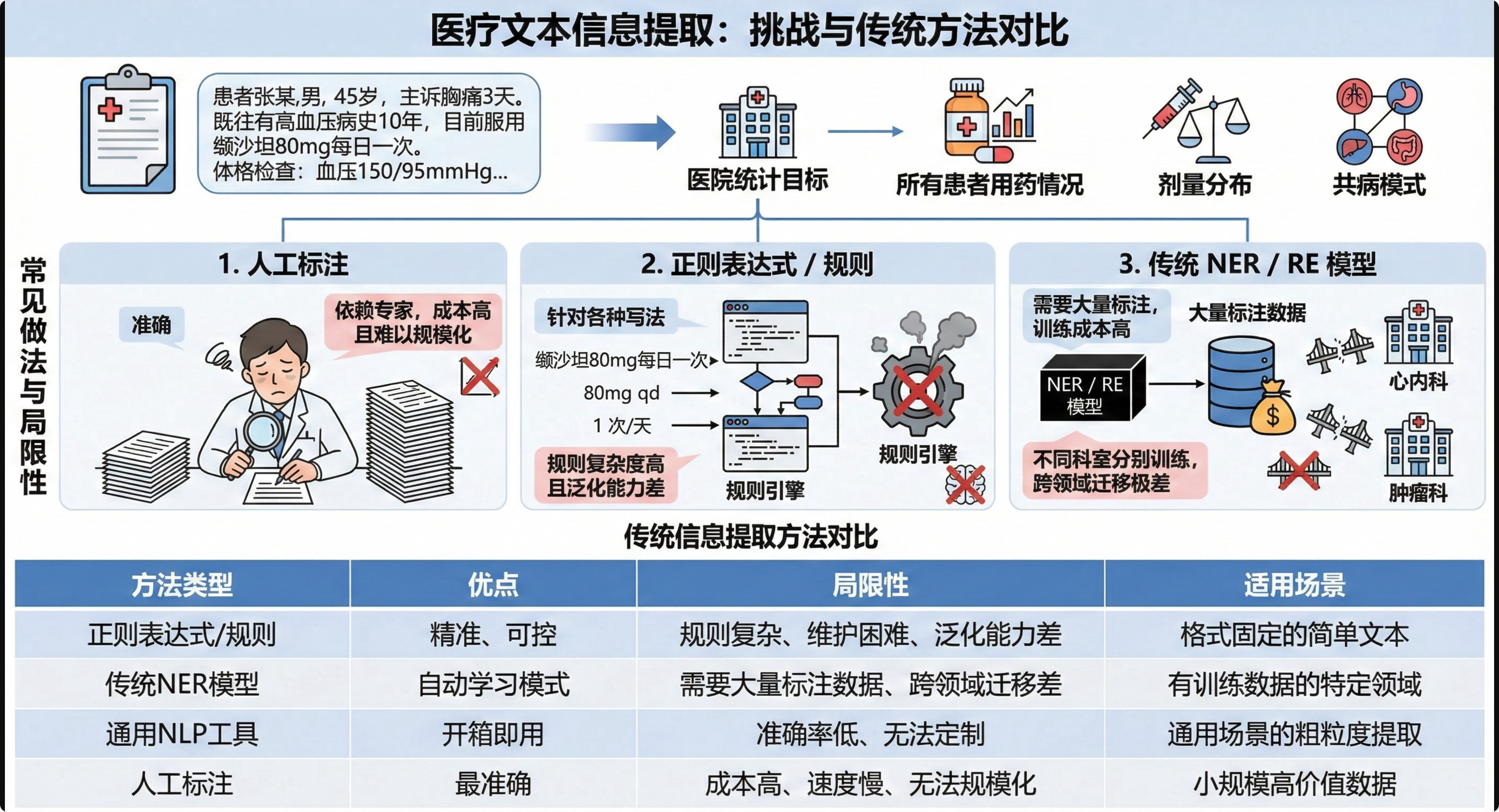
"患者张某,男,45岁,主诉胸痛3天。既往有高血压病史10年,目前服用缬沙坦80mg每日一次。体格检查:血压150/95mmHg..."
医院想要统计:所有患者的用药情况、剂量分布、共病模式,常见做法有:
- 人工标注 :
- 准确但依赖领域专家标注,成本高且难以规模化
- 正则表达式 / 规则 :
- 针对"缬沙坲80mg每日一次 / 80mg qd / 1 次/天"等各种写法,规则复杂度高且泛化能力差
- 传统 NER / RE 模型 :
- 需要大量标注数据,训练成本高,不同科室还要分别训练,跨领域迁移极差
传统信息提取方法对比
| 方法类型 | 优点 | 局限性 | 适用场景 |
|---|---|---|---|
| 正则表达式/规则 | 精准、可控 | 规则复杂、维护困难、泛化能力差 | 格式固定的简单文本 |
| 传统NER模型 | 自动学习模式 | 需要大量标注数据、跨领域迁移差 | 有训练数据的特定领域 |
| 通用NLP工具 | 开箱即用 | 准确率低、无法定制 | 通用场景的粗粒度提取 |
| 人工标注 | 最准确 | 成本高、速度慢、无法规模化 | 小规模高价值数据 |
总结:在医疗病历、法律文书、金融报告、长篇技术报告这些高价值文本上,传统方法要么贵,要么脆,要么不够智能。
1.2 LangExtract:让 LLM 变成"可控的信息抽取引擎"
为解决上述问题,Google 开源了 LangExtract。这是一个 Python 库,其核心使命可以用一句话概括:利用大型语言模型,将非结构化文本转换为结构化数据,并确保每个提取结果都精确对应回原文位置。
它不是一个具体的"大模型",而是一个围绕 LLM 抽取能力的 工程框架,提供以下五大核心能力:
能力一:零代码定义提取任务(Prompt-Driven)
在传统方案中,为了抽取药物信息,可能需要编写:
- 大量正则(匹配剂量、时间、频率)
- 自定义分词、语法分析
在 LangExtract 中,只需要一个 Prompt:
python
# 示例:定义提取任务的 Prompt
extraction_prompt = """
从临床笔记中提取以下信息:
1. 药物名称(medication)
2. 剂量(dosage)
3. 给药频率(frequency)
4. 持续时间(duration)
请确保提取的内容与原文完全一致。
"""
# 这就是全部!无需编写任何解析逻辑能力二:少样本学习能力(Few-Shot Learning)
只需给模型 1~3 个高质量示例,就能显著提升抽取效果。
python
import langextract as lx
# 定义一个示例:告诉模型"什么样的输入应该产生什么样的输出"
example = lx.data.ExampleData(
text="患者目前服用缬沙坲80mg每日一次,已持续3个月。",
extractions=[
lx.data.Extraction(
extraction_class="medication",
extraction_text="缬沙坲"
),
lx.data.Extraction(
extraction_class="dosage",
extraction_text="80mg"
),
lx.data.Extraction(
extraction_class="frequency",
extraction_text="每日一次"
),
lx.data.Extraction(
extraction_class="duration",
extraction_text="3个月"
)
]
)
# 提供1-3个这样的示例,模型就能学会输出格式!在医疗病历场景,一个这样的 ExampleData 就可以教会模型:
- 什么算"药物名称"
- 什么算"剂量 / 频率 / 持续时间"
能力三:精确的来源定位(Source Grounding)
LangExtract 的每一个抽取结果都自带 char_interval,记录其在原文的起止字符位置。
这在以下场景尤为关键:
- 医疗审计:监管部门核查 AI 提取的诊断结论是否真的出现在病历中
- 法律合规:合规审查时必须能追溯每条规定来自合同的哪一页哪一行
- 企业知识管理:构建企业知识库时,需链接回原始文档以供查证
能力四:结构化输出保证(Schema Enforcement)
大模型的常见问题之一是:输出格式不稳定。同一个任务可能出现:
- 一次返回 JSON
- 一次返回 Markdown 表格
- 一次返回自然语言解释 + JSON 混合
LangExtract 通过两种机制解决:
- 基于 Few-Shot 的格式约束:示例中使用目标结构,模型会模仿
- Schema Enforcement(受控生成):对支持 JSON Schema 的模型(如 Google Gemini),可以强制其输出符合预定义 Schema
在实际应用中,LangExtract 可以批量处理成千上万份文档,而不必担心某一份输出格式错误导致整个流水线崩溃。
能力五:长文档多轮提取(Multi-Pass Extraction)
对于 100 页的合同 / 法规合集 / 白皮书,常见问题是:
- 单次上下文放不下
- 一次扫描漏掉隐蔽信息
LangExtract 的长文档策略包括:
- 自动分块(Automatic Chunking)
- 将长文档切分为适合模型处理的小块
- 保留块之间的上下文重叠
- 多块并行处理,提高速度
- 多轮提取(Multi-Pass)
- 第 1 轮:全面扫描,提取显著信息
- 第 2 轮:针对第一轮可能遗漏的内容再次扫描
- 第 3 轮:面向特定信息类型进行深挖
这种策略在合规审查、法律分析等不允许遗漏任何细节的场景中至关重要。
与传统方法的对比分析
| 对比维度 | 正则 / 规则 | NER / 传统模型 | LangExtract |
|---|---|---|---|
| 开发门槛 | 需要熟悉文本模式、规则设计 | 需要数据标注 + 训练 + 调参 | Prompt + 少量示例即可启动 |
| 领域适配 | 改一条规则可能影响多个场景 | 跨领域要重新标注和训练 | 换领域只需换 Prompt + 示例 |
| 表达能力 | 适合模式固定的字段抽取 | 适合浅层实体识别 | 可同时抽实体、关系、事件、指标 |
| 可维护性 | 场景增多后规则庞大难维护 | 模型更新需重新训练 | 维护 Prompt & 示例集,迭代成本低 |
| 可溯源性 | 无 | 无 | 每条结果携带 char_interval |
以上五大能力使得 LangExtract 非常适合作为 医疗 / 法律 / 金融 / 合规审查 / 企业知识库 等场景的抽取底座。
二、LangExtract 的典型使用场景
2.1 非结构化文本处理(通用场景)
- 海量 FAQ、工单、客服对话日志
- 企业内部技术文档、设计文档
- 论坛 / 社区 / 评论文本
利用 LangExtract 可以低成本定义:
- 关键实体(人 / 组织 / 产品 / 功能)
- 事件(发布、故障、变更)
- 指标(数值、时间、地点)
并将其批量转化为结构化数据,供搜索、分析和下游任务使用。
2.2 医疗病历分析
医疗场景中的典型需求:
从病历中抽取 药物名称、剂量、给药频率、持续时间 等字段,用于统计研究、风险预警、智能随访。
通过 LangExtract,可以用非常少的 Few-Shot 示例,快速搭建:
- 用药模式分析(同一疾病下不同用药方案)
- 不良反应监控(药物组合 + 病史)
- 个体化治疗决策支持
2.3 法律文档解析
在 合同、判决书、法律条款 等场景中,LangExtract 可抽取:
- 条款编号、条款标题
- 权利义务主体
- 违约责任、赔偿条款
- 关键期限、金额
结合 Source Grounding,审查人员可以做到:
- "这条风险提示来自合同第几条、第几款?"
- "这个结论有没有对应的原文依据?"
2.4 金融报告与监管文本抽取
对上市公司年报、季报、监管报告等:
- 抽取关键指标:营收、净利、现金流、负债率等
- 抽取风险提示:重大诉讼、合规风险
- 抽取相关主体:控股股东、实控人、主要客户 / 供应商
LangExtract 支持:
- 直接从 PDF 经 OCR + Markdown 解析后进行结构化抽取
- 通过长文档 Multi-Pass 确保指标不遗漏
2.5 长文档信息抽取
不论是:
- 戏剧脚本(如《罗密欧与朱丽叶》)
- 长篇技术白皮书
- 成百页的法律合约合订本
LangExtract 都可以通过:
- 文本分块(max_char_buffer)
- 多轮抽取(extraction_passes)
- 并行处理(max_workers)
实现 完整覆盖 + 较高精度 的长文档抽取,并为每条结果提供位置索引,便于可视化和溯源。
三、【实战】Prompt Engineering 对比 LangExtract
在实际项目中,一个常见的疑问是:"直接用提示词让大模型提取不就行了吗?为什么还要用 LangExtract?"
本节通过 真实的新闻信息提取场景,分别运行纯提示词方式和 LangExtract 方式,从重复实体、完整性、原文对齐能力三个维度进行深度对比。
安装依赖:
python
%pip install langextract
python
%pip install openai python-dotenv3.1 环境准备
导入纯提示词所需的 OpenAI 客户端和 LangExtract 框架:
python
# 导入所有需要的库
import os
import time
import json
from pathlib import Path
from collections import Counter
# 纯提示词方式所需
from openai import OpenAI
# LangExtract 方式所需
import langextract as lx
from langextract.providers.openai import OpenAILanguageModel
from langextract.prompt_validation import PromptValidationLevel
# 环境变量加载
from dotenv import load_dotenv
print("所有依赖库导入成功")加载 DeepSeek API 配置,确保两种方案使用完全相同的模型和配置:
python
# 加载环境变量
load_dotenv()
# 读取 API 配置
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
DEFAULT_MODEL = os.getenv("DEFAULT_MODEL", "deepseek-chat")
# 创建输出目录
OUTPUT_DIR = Path("./outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
print("环境变量加载完成")
print(f" 模型: {DEFAULT_MODEL}")
print(f" API: {DEEPSEEK_BASE_URL}")3.2 准备测试文本
测试文本采用真实新闻风格的复杂文本,包含多个时间、机构、人物、地点、事件和指标,用于压力测试两种方案:
python
# 定义测试文本
input_text = """
2025年12月22日上午,国家统计局在北京国务院新闻办公室举行新闻发布会,公布2025年前11个月国民经济运行情况。
国家统计局新闻发言人付凌晖表示,规模以上工业增加值同比增长6.1%,社会消费品零售总额增长7.3%。
同日,国家发展改革委(以下简称"发改委")在例行发布会上介绍,将于2026年起对"人工智能+制造"试点城市给予专项资金支持,首批覆盖上海、深圳、成都等10个城市。
发改委副主任李春临称,资金将重点投向算力基础设施和工业软件,并与地方财政配套安排相衔接。
22日傍晚,中国人民银行(央行)公告,自12月23日起下调金融机构存款准备金率0.25个百分点。
央行副行长宣昌能在答记者问时称,此举旨在保持流动性合理充裕,并支持中小微企业融资。
对此,清华大学经济管理学院教授李稻葵认为,上述措施有助于稳定市场预期,但需警惕部分行业"低价竞争"风险。
他同时提到,地方政府隐性债务化解仍是明年宏观政策的重要约束。
""".strip()
print("✓ 测试文本已准备")
print(f"文本长度: {len(input_text)} 字符")
print(f"\n原文预览(前200字符):\n{input_text[:200]}...")重点关注:文本中包含"2026年起"、"12月23日起"等时间表达,两种方案对此的处理方式有明显差异。
3.3 纯提示词方案
纯提示词方案直接调用 DeepSeek API,通过精心设计的 Prompt 提取信息。
定义 Few-shot 示例,引导大模型输出格式:
python
# 定义 Few-shot 示例文本
example_text = (
"2025年6月3日,工业和信息化部在北京发布《算力基础设施高质量发展行动计划》。"
"工信部副部长张云明表示,到2027年全国算力总规模将达到300 EFLOPS。"
)
# 定义示例的标准输出格式
example_output = """{
"extractions": [
{"class": "时间", "text": "2025年6月3日"},
{"class": "机构", "text": "工业和信息化部"},
{"class": "地点", "text": "北京"},
{"class": "人物", "text": "张云明"},
{"class": "事件", "text": "发布《算力基础设施高质量发展行动计划》"},
{"class": "指标", "text": "300 EFLOPS"}
]
}"""
print("Few-shot 示例已准备")
print(f"示例文本: {example_text}")
print(f"\n示例输出:\n{example_output}")示例包含所有实体类别(时间、地点、机构、人物、事件、指标),用于引导 LLM 的提取行为。
构建完整 Prompt,包含任务说明、输出格式要求、Few-shot 示例和待提取文本:
python
# 构建完整 Prompt
prompt = f"""
请从下面的新闻文本中提取结构化信息。
【抽取类别】
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标(数值/增速/比例/数量等)
【要求】
1. 所有 `text` 必须是原文中的精确子串,不要改写
2. 去重并按原文出现顺序输出
【输出格式】
请严格输出 JSON(不要添加任何解释、Markdown、代码块):
{{
"extractions": [
{{
"class": "类别",
"text": "原文精确文本"
}}
]
}}
【Few-shot 示例】
示例文本:
{example_text}
示例输出:
{example_output}
---
现在请抽取这段新闻文本:
{input_text}
"""
print("Prompt 构建完成")
print(f"Prompt 总长度: {len(prompt)} 字符")调用 DeepSeek API 进行提取:
python
# 创建 DeepSeek 客户端
client = OpenAI(
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
print("DeepSeek 客户端创建成功")调用大模型提取信息:
python
# 调用 DeepSeek API
print("正在调用 DeepSeek API...")
start_time = time.time()
response = client.chat.completions.create(
model=DEFAULT_MODEL,
messages=[
{
"role": "system",
"content": "你是一个文本信息抽取助手,请严格按照用户指定的 JSON 格式输出,不要添加多余解释。"
},
{
"role": "user",
"content": prompt
}
],
temperature=0.3,
max_tokens=2000,
stream=False
)
result_prompt = response.choices[0].message.content
elapsed = time.time() - start_time
print(f"提取完成(耗时 {elapsed:.2f} 秒)")查看纯提示词提取结果:
python
# 打印原始结果
print("纯提示词提取结果:")
print("=" * 80)
print(result_prompt)
print("=" * 80)解析并统计纯提示词的结果:
python
# 解析 JSON 并统计
prompt_result = json.loads(result_prompt)
prompt_extractions = prompt_result["extractions"]
# 基本统计
total_count_prompt = len(prompt_extractions)
type_counts_prompt = Counter(ext["class"] for ext in prompt_extractions)
print(f"纯提示词统计:")
print(f" 总实体数: {total_count_prompt}")
print(f" 按类型分布:")
for entity_type, count in sorted(type_counts_prompt.items()):
print(f" - {entity_type}: {count} 个")纯提示词提取了大量实体,但数量多不代表质量高------需要检查重复问题:
python
# 检查重复
text_counts = Counter(ext["text"] for ext in prompt_extractions)
duplicates = {text: count for text, count in text_counts.items() if count > 1}
if duplicates:
print("发现重复实体:")
for text, count in duplicates.items():
print(f" - '{text}' 重复了 {count} 次")
total_duplicates = sum(count - 1 for count in duplicates.values())
unique_count_prompt = total_count_prompt - total_duplicates
print(f"\n去重后实际数量: {unique_count_prompt} 个(减少了 {total_duplicates} 个重复)")
else:
print("✓ 未发现重复实体")
unique_count_prompt = total_count_prompt纯提示词存在明显的重复问题,这会导致:
- 数量虚高
- 需要人工去重
3.4 LangExtract 方案
LangExtract 框架会自动处理去重、原文对齐等细节。
定义 LangExtract 任务描述 ,比纯提示词简洁得多,因为它内置了很多最佳实践:
python
# 定义 LangExtract 的任务描述
langextract_prompt = """
从新闻文本中提取以下信息:
- 时间
- 地点
- 机构
- 人物
- 事件
- 指标(数值/增速/比例/数量等)
要求:
1. 使用原文中的完整表述
2. 不要重复
3. 按出现顺序提取
"""
print("LangExtract 任务描述已定义")
print(f"Prompt 长度: {len(langextract_prompt)} 字符(比纯提示词简洁得多)")LangExtract 会自动处理输出格式、去重等细节。
定义 Few-shot 示例 ,与纯提示词使用完全相同的示例文本,确保对比公平性:
python
# 定义 LangExtract 的 Few-shot 示例
examples = [
lx.data.ExampleData(
text=example_text,
extractions=[
lx.data.Extraction("时间", "2025年6月3日"),
lx.data.Extraction("机构", "工业和信息化部"),
lx.data.Extraction("地点", "北京"),
lx.data.Extraction("人物", "张云明"),
lx.data.Extraction("事件", "发布《算力基础设施高质量发展行动计划》"),
lx.data.Extraction("指标", "300 EFLOPS"),
]
)
]
print("LangExtract Few-shot 示例已定义")
print(f"示例数量: {len(examples)}")
print(f"示例实体数: {len(examples[0].extractions)}")初始化 LangExtract 模型 ,使用相同的 DeepSeek API:
python
# 创建 LangExtract 模型
model = OpenAILanguageModel(
model_id=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
print("LangExtract 模型创建成功")
print(f"使用模型: {DEFAULT_MODEL}(与纯提示词相同)")执行 LangExtract 提取 ,自动完成:构建优化的 Prompt、调用 LLM、解析结果、对齐原文位置、自动去重:
python
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model=model,
fence_output=True,
use_schema_constraints=False,
prompt_validation_level=PromptValidationLevel.OFF,
)查看 LangExtract 提取结果 ,注意每个实体都有精确的位置信息:
python
# 打印 LangExtract 结果
print("LangExtract 提取结果:")
print("=" * 80)
for ext in result.extractions:
if ext.char_interval:
pos_info = f"[{ext.char_interval.start_pos}-{ext.char_interval.end_pos}]"
print(f"[{ext.extraction_class}] {ext.extraction_text} {pos_info}")
print("=" * 80)LangExtract 的每个实体都有精确的位置信息,这意味着可以回到原文验证、可视化高亮展示。
统计 LangExtract 结果:
python
# 统计 LangExtract 结果
langextract_extractions = result.extractions
total_count_lang = len(langextract_extractions)
type_counts_lang = Counter(ext.extraction_class for ext in langextract_extractions)
# 统计有位置信息的实体数
with_position = sum(1 for ext in langextract_extractions if ext.char_interval is not None)
print(f"LangExtract 统计:")
print(f" 总实体数: {total_count_lang}")
print(f" 按类型分布:")
for entity_type, count in sorted(type_counts_lang.items()):
print(f" - {entity_type}: {count} 个")四、【实战】LangExtract 长文本提取
本节通过实战深入理解 LangExtract 处理长文本的核心能力。
以完整的《罗密欧与朱丽叶》中文版(约 54,000 字符)作为案例,演示如何从长文档中提取人物、情感和关系信息。
本章核心要点:
- 长文本处理策略:分块 + 多轮 + 并行
- 戏剧文本特点:角色对话、情感丰富、关系复杂
- 数据分析与可视化:从 1,889 个实体中挖掘价值
- 核心参数调优 :
extraction_passes、max_workers、max_char_buffer
4.1 配置运行环境
导入必要的 Python 库:
os和Path:文件和目录操作textwrap:格式化多行字符串Counter和defaultdict:统计和数据聚合langextract:核心提取框架OpenAILanguageModel:DeepSeek 兼容的模型接口dotenv:加载环境变量
python
import os
import textwrap
from pathlib import Path
from collections import Counter, defaultdict
from dotenv import load_dotenv
import langextract as lx
from langextract.providers.openai import OpenAILanguageModel
from langextract.prompt_validation import PromptValidationLevel
print("所有依赖库导入成功!")
python
# 加载环境变量
load_dotenv()
print("环境变量加载成功!")load_dotenv() 从项目根目录的 .env 文件中读取配置信息,主要是 API Key 和相关配置。
配置 API 参数:
python
# 配置 DeepSeek API
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY", "")
DEEPSEEK_BASE_URL = os.getenv("DEEPSEEK_BASE_URL", "https://api.deepseek.com")
DEFAULT_MODEL = os.getenv("DEFAULT_MODEL", "deepseek-chat")
# 配置输出目录
OUTPUT_DIR = Path("./outputs")
OUTPUT_DIR.mkdir(exist_ok=True)
print(f"配置完成!")
print(f" 模型: {DEFAULT_MODEL}")
print(f" API 端点: {DEEPSEEK_BASE_URL}")
print(f" 输出目录: {OUTPUT_DIR}")这里完成了三件事:
- 读取 API 配置:从环境变量中获取 DeepSeek API Key 和端点
- 设置默认模型 :使用
deepseek-chat模型 - 创建输出目录 :
OUTPUT_DIR.mkdir(exist_ok=True)创建outputs目录,已存在则不报错
4.2 读取长文本数据
从本地文件读取《罗密欧与朱丽叶》的完整中文文本(约 54,000 字符),是典型的长文档场景。
由于中文文本可能有不同的编码格式,需要尝试多种编码读取:
python
# 读取《罗密欧与朱丽叶》中文文本
romeo_file = Path("罗密欧与朱丽叶.txt")
if romeo_file.exists():
# 尝试多种编码
for encoding in ['gbk', 'gb2312', 'utf-8', 'utf-16']:
try:
with open(romeo_file, 'r', encoding=encoding) as f:
input_text = f.read()
print(f"✓ 成功使用 {encoding} 编码读取文件")
break
except:
continue
else:
print("错误: 未找到 罗密欧与朱丽叶.txt 文件")
print("请确保文件存在于当前目录")
print(f"✓ 成功读取 {len(input_text):,} 字符")
print(f"\n文本预览(前 200 字符):")
print("-" * 60)
print(input_text[:200])
print("...")这里有几个关键点:
- 多编码尝试 :依次尝试
gbk、gb2312、utf-8、utf-16,确保正确读取中文文本 - 字符数统计:约 54,000 字符,典型的长文档场景
- 文本预览 :通过
input_text[:200]查看前 200 字符,确认文本格式正确
4.3 定义提取任务 Prompt
Prompt 是告诉模型"要提取什么"的核心指令。对于戏剧文本,关注三类信息:
- 人物:剧中角色
- 情感:情感表达和心理活动
- 关系:人物之间的关系描述
同时明确告诉模型戏剧脚本的特点:角色名称后跟冒号:
python
# 定义提取任务的 Prompt 描述
prompt = textwrap.dedent("""\
从中文戏剧文本中提取人物、情感和关系信息。
为每个实体添加有意义的属性以增加上下文。
重要: extraction_text 必须是原文的精确子串,不要改写。
按出现顺序提取实体,不要重叠。
注意: 在戏剧脚本中,角色名称后跟冒号。""")
print("Prompt 定义完成!")
print("\n" + "=" * 60)
print("Prompt 内容:")
print("=" * 60)
print(prompt)Prompt 包含几个关键要求:
- 提取目标:人物、情感、关系
- 属性要求:为每个实体添加属性,增加上下文信息
- 精确对齐 :
extraction_text必须是原文精确子串 - 戏剧格式:角色名称后跟冒号,是戏剧脚本的特殊格式
4.4 定义 Few-shot 示例
Few-shot 示例是 LangExtract 的核心。通过提供高质量的示例,引导模型理解"什么是好的提取"。使用一段经典的罗密欧与朱丽叶对话作为示例:
python
# 定义 Few-shot 示例
examples = [
lx.data.ExampleData(
text=textwrap.dedent("""\
罗密欧: 轻声!那边窗子里亮起来的是什么光?
那就是东方,朱丽叶就是太阳。
朱丽叶: 啊!罗密欧,罗密欧!为什么你偏偏是罗密欧呢?"""),
extractions=[
lx.data.Extraction(
extraction_class="人物",
extraction_text="罗密欧",
attributes={"情感状态": "惊叹"}
),
lx.data.Extraction(
extraction_class="情感",
extraction_text="轻声!",
attributes={"情感": "温柔敬畏", "人物": "罗密欧"}
),
lx.data.Extraction(
extraction_class="关系",
extraction_text="朱丽叶就是太阳",
attributes={"类型": "比喻", "人物1": "罗密欧", "人物2": "朱丽叶"}
),
lx.data.Extraction(
extraction_class="人物",
extraction_text="朱丽叶",
attributes={"情感状态": "渴望"}
),
lx.data.Extraction(
extraction_class="情感",
extraction_text="为什么你偏偏是罗密欧呢?",
attributes={"情感": "渴望的疑问", "人物": "朱丽叶"}
),
]
)
]
print("Few-shot 示例定义完成!")
print(f"\n示例数量: {len(examples)}")
print(f"示例文本长度: {len(examples[0].text)} 字符")
print(f"示例提取数量: {len(examples[0].extractions)} 个")
print("\n" + "=" * 60)
print("示例文本:")
print("=" * 60)
print(examples[0].text)Few-shot 示例展示了高质量提取的标准:
- 人物提取:提取"罗密欧"和"朱丽叶",并添加"情感状态"属性
- 情感提取:提取"轻声!"和"为什么你偏偏是罗密欧呢?",标注情感类型和归属人物
- 关系提取:提取"朱丽叶就是太阳"这个比喻,标注类型和涉及的人物
注意每个 extraction_text 都是原文的精确子串,这是 LangExtract 的核心要求。
4.5 创建 LangExtract 模型
使用 OpenAILanguageModel 对接 DeepSeek API,LangExtract 的设计可以轻松使用任何 OpenAI 兼容的 API:
python
# 创建 DeepSeek 模型实例
model = OpenAILanguageModel(
model_id=DEFAULT_MODEL,
api_key=DEEPSEEK_API_KEY,
base_url=DEEPSEEK_BASE_URL
)
print("模型创建成功!")
print(f" 模型 ID: {DEFAULT_MODEL}")
print(f" API 端点: {DEEPSEEK_BASE_URL}")传入三个参数:
model_id:模型名称,这里是deepseek-chatapi_key:API 密钥,从环境变量读取base_url:API 端点,DeepSeek 的 API 端点
4.6 运行长文本提取(核心)
本节的核心部分。使用 lx.extract() 函数,配合长文本处理的三大核心参数:
长文本处理核心参数
| 参数名 | 值 | 作用 |
|---|---|---|
extraction_passes |
3 | 多轮提取,提高召回率 |
max_workers |
20 | 并行处理,加快速度 |
max_char_buffer |
1000 | 分块大小,保持准确性 |
这三个参数是 LangExtract 处理长文本的核心策略:分块 + 多轮 + 并行。
注意 :运行这个 Cell 会调用 DeepSeek API,处理 54,000 字符的文本,大约需要 1-2 分钟。
python
# 运行长文本提取
print("开始运行长文本提取...")
print(f" 输入文本: {len(input_text):,} 字符")
print(f" 提取轮数: 3 轮")
print(f" 并行数: 20 workers")
print(f" 分块大小: 1000 字符")
print("\n正在处理,请稍候...\n")
result = lx.extract(
text_or_documents=input_text,
prompt_description=prompt,
examples=examples,
model=model,
extraction_passes=3, # 多轮提取提高召回率
max_workers=20, # 并行处理加速
max_char_buffer=1000 # 较小的上下文提高准确性
)
print("\n" + "=" * 60)
print("提取完成!")
print("=" * 60)
print(f"文本长度: {len(result.text):,} 字符")
print(f"提取实体总数: {len(result.extractions)} 个")从 54,000 字符的文本中,提取了约 1,889 个实体。
LangExtract 的长文本处理策略:
- 分块处理 :
max_char_buffer=1000将文本分成多个 ~1000 字符的块 - 并行执行 :
max_workers=20同时处理 20 个块,大幅提速 - 多轮提取 :
extraction_passes=3执行 3 轮独立提取,将不重叠的结果合并
4.7 保存提取结果
LangExtract 使用 JSONL 格式保存结果。JSONL 是一种人类可读的格式,每行是一个独立的 JSON 对象,便于解析和分享:
python
# 保存提取结果为 JSONL 格式
lx.io.save_annotated_documents(
[result],
output_name="罗密欧与朱丽叶_extractions.jsonl",
output_dir=str(OUTPUT_DIR)
)
output_jsonl_path = OUTPUT_DIR / "罗密欧与朱丽叶_extractions.jsonl"
print(f"结果已保存: {output_jsonl_path}")JSONL 文件保存到 outputs 目录,包含:
- 原始文本
- 所有提取的实体
- 每个实体的位置信息(
start_pos、end_pos) - 每个实体的属性
LangExtract 提供强大的可视化功能。通过 lx.visualize() 函数,生成交互式 HTML 页面,用于查看和分析提取结果:
python
# 生成交互式可视化
html_content = lx.visualize(str(output_jsonl_path))
html_file = OUTPUT_DIR / "罗密欧与朱丽叶_visualization.html"
with open(html_file, "w", encoding="utf-8") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data)
else:
f.write(html_content)
print(f"交互式可视化已生成: {html_file}")
print("\n提示: 在浏览器中打开 HTML 文件可以:")
print(" - 查看高亮显示的所有提取结果")
print(" - 按类别筛选实体")
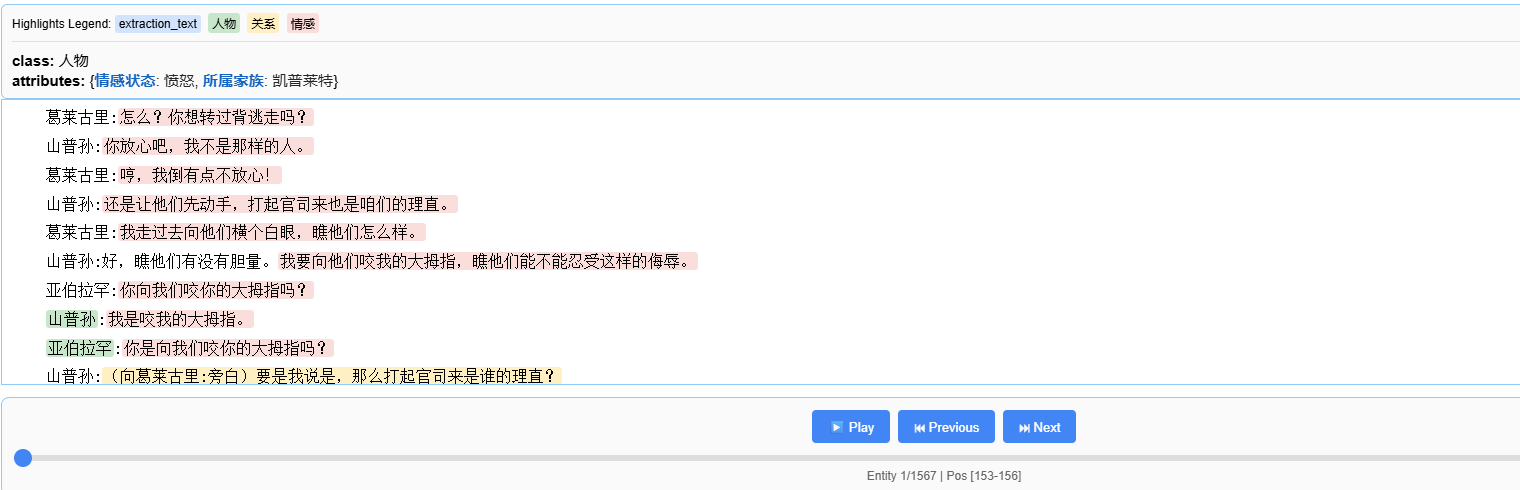
print(" - 查看每个实体的详细属性")可视化 HTML 文件提供:
- 原文高亮显示
- 按类别筛选
- 点击实体查看详细信息
- 可搜索、可导航
加入赋范空间,获取更多技术资源
如果你对本文内容感兴趣,欢迎加入 赋范空间 技术社区!
包括本文配套完整的 LangExtract 信息抽取技术实战。
我们提供系统的课程体系,帮助你从零开始掌握:
- AI Agent 开发:基于 LangChain 1.0、Google ADK 等主流框架,深入理解 Agent 架构与实战,打造智能体
- RAG 技术:构建高性能的企业级知识库问答系统,涵盖混合检索、智能路由、以图搜图、视频检索等
- MCP 协议:掌握下一代 AI 连接标准,连接万物
- 大模型微调:掌握 Fine-tuning、RL 等技术,打造专属垂直领域模型
- 企业项目实战:15+ 项目实战(多模态 RAG、实时语音助手、文档审核、智能客服系统等),将理论知识应用到实际项目中,解决真实业务问题
LangExtract 提供强大的可视化功能。通过 lx.visualize() 函数,生成交互式 HTML 页面,用于查看和分析提取结果:
python
# 生成交互式可视化
html_content = lx.visualize(str(output_jsonl_path))
html_file = OUTPUT_DIR / "罗密欧与朱丽叶_visualization.html"
with open(html_file, "w", encoding="utf-8") as f:
if hasattr(html_content, 'data'):
f.write(html_content.data)
else:
f.write(html_content)
print(f"交互式可视化已生成: {html_file}")
print("\n提示: 在浏览器中打开 HTML 文件可以:")
print(" - 查看高亮显示的所有提取结果")
print(" - 按类别筛选实体")
print(" - 查看每个实体的详细属性")可视化 HTML 文件提供:
- 原文高亮显示
- 按类别筛选
- 点击实体查看详细信息
- 可搜索、可导航
加入赋范空间,获取更多技术资源
如果你对本文内容感兴趣,欢迎加入 赋范空间 技术社区!
包括本文配套完整的 LangExtract 信息抽取技术实战。
我们提供系统的课程体系,帮助你从零开始掌握:
- AI Agent 开发:基于 LangChain 1.0、Google ADK 等主流框架,深入理解 Agent 架构与实战,打造智能体
- RAG 技术:构建高性能的企业级知识库问答系统,涵盖混合检索、智能路由、以图搜图、视频检索等
- MCP 协议:掌握下一代 AI 连接标准,连接万物
- 大模型微调:掌握 Fine-tuning、RL 等技术,打造专属垂直领域模型
- 企业项目实战:15+ 项目实战(多模态 RAG、实时语音助手、文档审核、智能客服系统等),将理论知识应用到实际项目中,解决真实业务问题