
先说结论:
对于相当多的图像模型,在输入图像四周主动加一圈 Padding(空白边),往往能提升边界区域的识别效果。
这听起来有点像玄学,但如果你做过图像路线,你大概率已经被它伤害过:模型对中间的文本/表格/标注稳得不行,一到页面边缘就开始:
- 识别丢字
- 表格线断掉
- 标题被识别成正文
- 图像区域边缘被切烂
- 区块重叠但不抑制
- ⚠️ 最经典的:有边界的文字被当成"噪声"抛弃
我是怎么发现这个问题的?
在我调试各种图像模型的过程中,偶尔会出现这种略微有点偏差的情况:
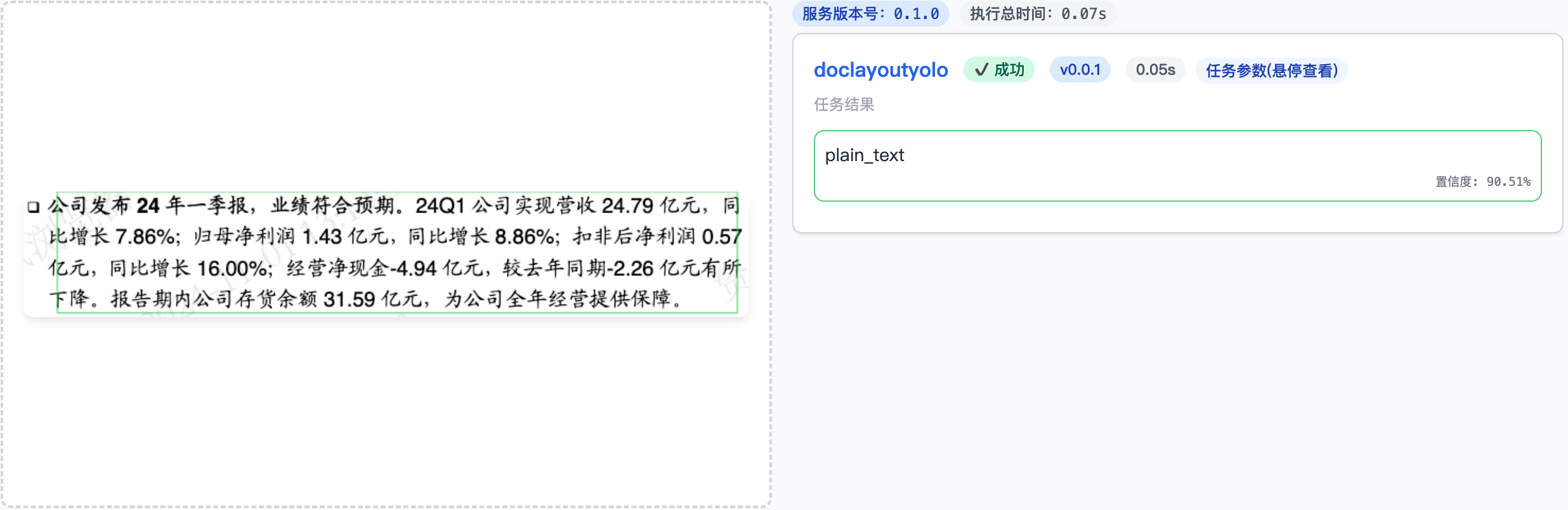
图:布局模型没框对bbox
于是我咨询了算法同事,对方告诉说:
padding一圈白边就好了。
然后我就加了一圈:
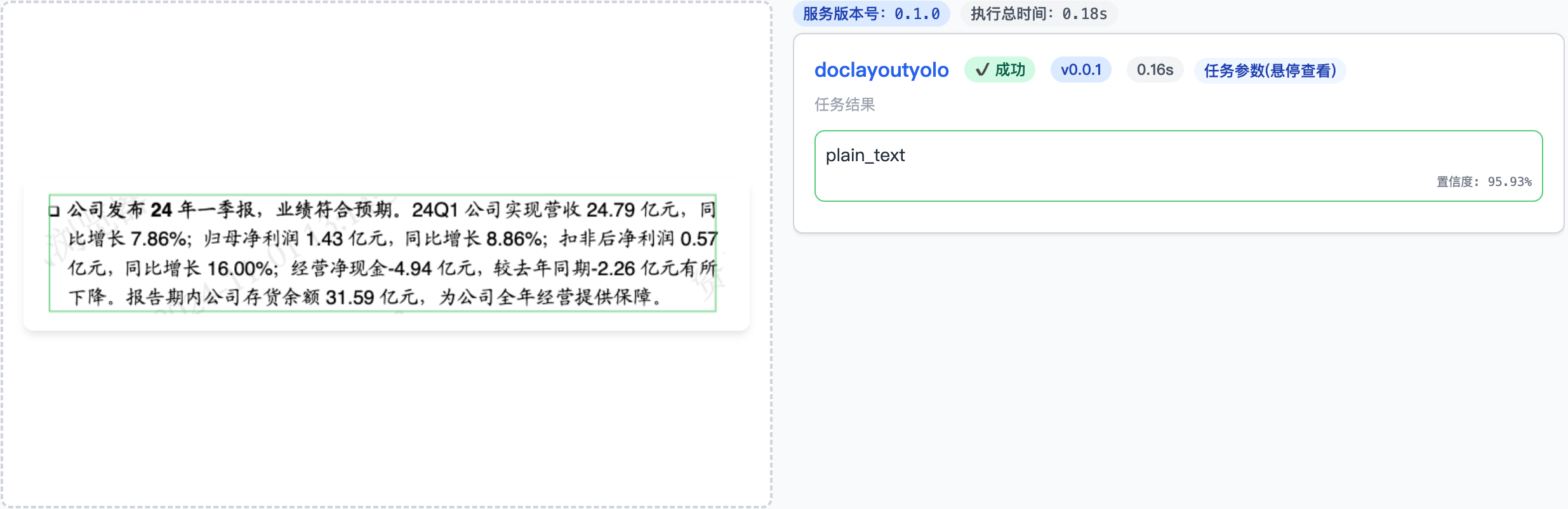
图:加白边后BBox框对了
从此开启了一个新的视角。🎉
为啥贴着边缘结果就开始崩?
这事不能死板归纳,但以下几个原因在工程里非常常见:
- 训练集偏差
- 模型训练数据里,大多数文字/表格/区域都不是贴边出现的
- 因此边缘 case 在推理中天然"少见 → 不自信"
- Feature Map 特性导致边缘信号损失
- 下采样层会让边缘像素的信息稀释得更快
- 当卷积核滑到边界外时,Padding 模式不同(zero / reflect / replicate)会产生不一致的响应
- 模型架构设计上的假设
- 很多视觉模型假设主体区域在中间
- 这不是明说,但你能感觉到它"希望你把东西摆在视野中央"
- 上下文不足
- 边界上天然缺一半的上下文(上下左/右缺),模型做"判定"时不够稳定
这一切加起来,就导致一种很熟悉的体验:
图片中心像世界冠军,图片边缘像刚学完拼音的小孩。
那为什么加 Padding 就变好了?
因为我们做了四件事:
- 给模型缓冲区(让它别贴墙走)
- 给边缘元素补了视觉上下文
- 让页面主体落回了模型舒适区
- 用最便宜的方式抹平了训练分布的差异
一句话总结:
Padding 的作用不是"让图变大",而是把模型讨厌的区域搬远一点。
具体怎么加?
是
否
图像输入
需要 Padding 吗?
在四周增加空白边
按比例或固定像素 Padding
保持原图像尺寸
得到最终输入图像
供布局/检测/多模态模型使用
坐标映射回原坐标系(如需)
图:padding整体流程
- 如果确定当前图像需要padding
- 在图像边缘按Padding策略增加白边
- 进行图像处理
- 如结果有坐标,映射回原坐标系(重要)
建议的 Padding 策略
| Padding 比例 | 适用场景 |
|---|---|
| 页面最短边的 5% - 8% | 推荐起步区间 |
| 10%+ | 复杂版面 / 边界密集对象 |
| "硬性保证最少 XX 像素" | 模型输入尺寸固定时更可控 |
你甚至可以用一种更工程思维的理解方式:
Padding 不是图像预处理,是"模型输入空间规划"。
哪些类型的模型最值得尝试?
- 版面分析 Layout 模型(DocLayout-YOLO、FCN、FasterRCNN系)
- 表格检测模型
- OCR 检测头
- 图像区域分类器
- 多模态结构化模型(Qwen-VL、Florence、GPT-4o-mini 系)
换句话说:
只要模型输出 bbox / 区域分类,Padding 可能有用。
我的工程经验:什么时候该上 Padding?
是
否
边缘文字丢字/错行
边缘表格切不全/列数错
边缘图像被切碎
是
否
观察模型在真实页面上的输出
边缘区域表现正常吗?
暂不启用 Padding
保持现有配置
收集典型问题样本
集中在页面边缘
问题类型
怀疑上下文不足
或边界特征弱
怀疑边界检测不稳定
怀疑区域过贴边
在推理前统一增加 Padding
例如最短边 5%~8%
对同一批样本重新评估效果
边缘问题明显改善?
在对应模型推理链路
默认开启 Padding
关闭或减小 Padding
改为排查模型/标注/训练问题
图:什么时候该考虑开启 Padding
⚠️ 不是所有情况都要开,根据现象判断:
| 现象 | 怀疑方向 | 建议 |
|---|---|---|
| 边缘文本识别不稳定 | 视觉上下文不足 | 开 Padding |
| 边缘表格识别切不全 | NMS 失败 / 边界缺特征 | 开 Padding |
| 大图片/横图解析效果差 | Resize 扭曲分布 | Padding + Resize |
| 模型输出 bbox 离边缘不贴合 | 输入视野编队问题 | 必开 Padding |
我自己的策略是:
默认不开,遇到边缘问题 → 开 → 观察收益 → 决定是否常驻。
Padding 不是"加了就一定变强"的魔法,但它是一个成本超低、收益可观、风险超小的试错选项。
这不是银弹(请读三遍)
为了防止这章看起来像"民科玄学",我要把这句话写清楚:
Padding 是临时性工程技巧,不是通用解法。
它解决的不是模型的智商问题,而是输入与模型预期不匹配的问题。
如果你的模型在中心区域也表现糟糕------请不要加 Padding,请去换模型。
收个尾:Padding 不是魔法,它只是让模型别撞墙
做到这里,能感觉到一个拐点:
- DPI 不会乱炸内存了
- Resize 终于是"规划"而不是"撞大运"
- Padding 也不再是"玄学",而是一个可控选项
你开始能感觉到模型没那么失控了。页面也不再像一场事故,而像一台勉强能开的机器。但等你兴致勃勃往下走的时候,现实通常是这样的:
模型输出回来了。
文档被拆成了几十个、几百个 bbox。
每个都自称"我有点用"。
有的重叠、有的互相踩脸、有的置信度模棱两可。
有的仿佛在说:
"来嘛,猜猜你先信谁?"
这才是真正的噩梦。而这件事,本质上已经和"模型推理"没什么关系了。这是一个工程系统的世界观问题:
当模型把文档拆碎,我们应该如何把它们拼回成一个"能继续往下走"的世界?
这一点,才是我觉得图像路线最迷人的地方。不是模型,而是我们如何跟模型对话。
下一章,我们来聊聊"框的政治关系"。