在微服务架构盛行的今天,服务间的调用链路变得越来越复杂。一个看似平静的系统,往往在瞬间的流量洪峰面前不堪一击。当双11零点、热门事件爆发、或者恶意攻击来临时,如何确保我们的服务能够稳定运行,而不是在流量面前缴械投降?
回答就是:限流。
今天,我们将深入探讨基于 Uber/Limit 的限流实现,以及经典的漏桶算法原理。
限流(uber/limit)的核心作用
为什么需要限流?
在微服务实战经验中,我曾遇到过无数次因为突发流量导致的系统故障。一个典型的场景是:某个营销活动突然火爆,用户请求量瞬间暴增10倍,结果数据库连接池被耗尽,缓存服务过载,整个系统陷入瘫痪。
限流(uber/limit)的三大核心作用恰好能够解决这些问题:
1. 限制流量,在服务端生效
限流的第一要务是控制进入系统的请求流量。与客户端的限制不同,服务端限流能够:
- 精确控制:在服务的入口处准确限制并发请求数量
- 实时生效:无需客户端配合,服务端直接生效
- 全局统一:对所有客户端请求统一限制,避免单点突破
在实际项目中,我通常会在以下几个层面设置限流:
- API 网关层:控制总体流量入口
- 服务实例层:保护单个服务节点
- 资源层面:保护数据库、缓存等关键资源
2. 保护后端服务
限流的本质是资源保护。当我们说保护后端服务时,实际上是在保护:
- 计算资源:CPU、内存不被过度消耗
- I/O资源:数据库连接、文件句柄等不被耗尽
- 网络资源:带宽、连接数不超过承载能力
- 业务资源:业务逻辑处理能力不被透支
一个经典的案例是电商系统的库存扣减操作。如果不进行限流,瞬间的大量请求可能导致数据库锁竞争激烈,反而降低了整体的处理效率。通过合理的限流策略,我们可以让系统在承载能力范围内稳定运行。
3. 与熔断互补
限流和熔断是微服务稳定性保障的两大支柱,它们的关系可以这样理解:
- 限流是预防:在问题发生前就控制流量,避免系统过载
- 熔断是应急:当问题已经发生时,快速切断故障传播
- 协同工作:限流降低了熔断触发的概率,熔断为限流提供了最后的保障
| 维度 | 限流 | 熔断 |
|---|---|---|
| 作用时机 | 请求进入前 | 调用失败后 |
| 保护对象 | 当前服务 | 下游依赖 |
| 触发条件 | 流量阈值 | 错误率/响应时间 |
| 处理方式 | 拒绝/排队 | 快速失败/降级 |
在实际架构设计中,我建议将两者结合使用:
bash
API请求 → 限流检查 → 业务处理 → 下游调用(熔断保护) → 返回结果漏桶算法:优雅的流量整形利器
漏桶算法的核心原理
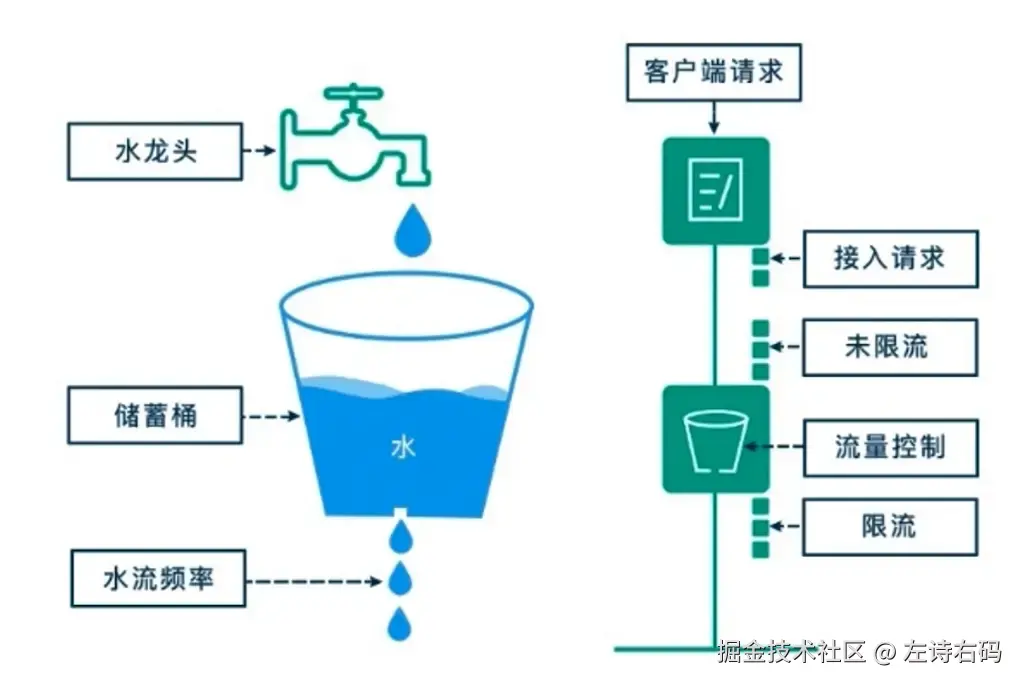
漏桶算法(Leaky Bucket Algorithm)是限流算法中的经典之作,它的设计思想既简单又精妙。就像一个底部有小洞的水桶:
- 桶的容量:代表系统能缓存的最大请求数
- 漏水速率:代表系统的处理能力(恒定速率)
- 入桶速率:代表外部请求的到达速率(可变)
漏桶算法的核心特性
1. 流量整形(Traffic Shaping)
漏桶算法最大的优势在于将不规律的流量整形为平滑的输出。无论输入流量如何波动,输出始终保持恒定的速率。这种特性在以下场景中特别有价值:
- 数据库保护:避免突发请求对数据库造成冲击
- 第三方API调用:遵守第三方服务的频率限制
- 消息队列:平滑消息处理,避免消费者过载
2. 缓冲能力
漏桶提供了一定的缓冲空间,能够:
- 吸收短期的流量突发:暂时存储超出处理能力的请求
- 提高用户体验:减少因瞬时流量峰值导致的请求拒绝
- 增加系统弹性:给系统一定的适应时间
3. 可预测的性能
由于输出速率恒定,漏桶算法提供了可预测的系统性能:
- 资源规划更准确:可以精确计算资源需求
- SLA更容易保证:稳定的处理速率有助于服务质量承诺
- 容量规划更科学:基于恒定速率进行系统扩容决策
漏桶算法的实际应用场景
漏桶算法特别适合以下场景:
1. API限流
go
// 示意代码:使用漏桶算法限制API调用频率
type LeakyBucket struct {
capacity int // 桶容量
tokens int // 当前令牌数
rate time.Duration // 漏出速率
lastUpdate time.Time // 上次更新时间
mutex sync.Mutex
}
func (lb *LeakyBucket) Allow() bool {
lb.mutex.Lock()
defer lb.mutex.Unlock()
now := time.Now()
// 计算应该漏出的令牌数
elapsed := now.Sub(lb.lastUpdate)
tokensToRemove := int(elapsed / lb.rate)
if tokensToRemove > 0 {
lb.tokens = max(0, lb.tokens-tokensToRemove)
lb.lastUpdate = now
}
// 检查是否可以放入新请求
if lb.tokens < lb.capacity {
lb.tokens++
return true
}
return false
}2. 消息处理
在消息队列消费场景中,漏桶算法能够确保消费者以稳定的速率处理消息,避免处理能力不足导致的消息积压。
3. 资源访问控制
对于昂贵的资源(如数据库连接、外部API调用),漏桶算法能够确保访问频率不超过系统承载能力。
漏桶算法的优缺点分析
优点
- 流量平滑:输出速率恒定,对下游系统友好
- 实现简单:算法逻辑清晰,易于理解和实现
- 内存友好:只需要记录少量状态信息
- 适合整形:特别适合需要流量整形的场景
缺点
- 不够灵活:无法利用系统的空闲时间处理更多请求
- 突发处理能力有限:即使系统有余力,也无法快速处理突发请求
- 延迟增加:请求可能需要在桶中等待,增加了响应延迟
与令牌桶算法的对比
为了更好地理解漏桶算法,我们来看看它与令牌桶算法的区别:
| 特性 | 漏桶算法 | 令牌桶算法 |
|---|---|---|
| 输出速率 | 恒定 | 可变(突发) |
| 突发处理 | 不支持 | 支持 |
| 流量整形 | 强 | 弱 |
| 实现复杂度 | 简单 | 中等 |
| 适用场景 | 严格限速 | 弹性限速 |
Uber/Limit 实战应用
Uber开源的limit库是一个高性能的限流实现,它支持多种算法,包括漏桶算法。在实际项目中的使用示例:
go
package main
import (
"context"
"log"
"time"
"go.uber.org/ratelimit"
)
func main() {
// 创建限流器,每秒允许100个请求
limiter := ratelimit.New(100) // per second
// 业务处理函数
for i := 0; i < 1000; i++ {
limiter.Take() // 获取令牌,会阻塞直到获得令牌
go func(id int) {
// 处理业务逻辑
processRequest(id)
}(i)
}
}
func processRequest(id int) {
// 模拟业务处理
log.Printf("Processing request %d", id)
time.Sleep(10 * time.Millisecond)
}高级用法:动态限流
在实际生产环境中,我们经常需要根据系统负载动态调整限流阈值:
go
type DynamicLimiter struct {
limiter ratelimit.Limiter
monitor *SystemMonitor
}
func (dl *DynamicLimiter) adjustRate() {
cpuUsage := dl.monitor.GetCPUUsage()
memUsage := dl.monitor.GetMemoryUsage()
// 根据系统负载动态调整限流速率
var newRate int
if cpuUsage > 80 || memUsage > 80 {
newRate = 50 // 降低限流阈值
} else if cpuUsage < 50 && memUsage < 50 {
newRate = 200 // 提高限流阈值
} else {
newRate = 100 // 保持默认值
}
// 重新创建限流器
dl.limiter = ratelimit.New(newRate)
}限流策略的最佳实践
1. 分层限流
不要依赖单一的限流点,而应该建立多层防护:
- 边界限流:在系统边界设置粗粒度限流
- 服务限流:在各个微服务内部设置细粒度限流
- 资源限流:在关键资源访问点设置专门限流
2. 差异化限流
不同的业务场景需要不同的限流策略:
- 核心接口:设置较高的限流阈值,确保可用性
- 非核心接口:可以设置较低的限流阈值,节约资源
- 批量接口:需要特殊的限流策略,避免影响实时接口
3. 监控与告警
建立完善的限流监控体系:
- 实时监控:监控限流器的触发频率和拒绝率
- 趋势分析:分析流量模式,优化限流策略
- 及时告警:当限流频繁触发时及时通知
4. 优雅降级
当触发限流时,应该提供优雅的降级策略:
- 返回缓存数据:对于查询接口,可以返回缓存的数据
- 异步处理:对于非实时要求的操作,可以转为异步处理
- 友好提示:给用户明确的反馈,而不是简单的错误信息
总结
限流是构建稳定可靠微服务系统的重要基石。通过合理使用 Uber/Limit 等工具,结合漏桶算法等经典算法,我们可以有效保护系统免受流量冲击。
关键要点回顾:
- 限流的三大作用:限制流量、保护后端服务、与熔断互补
- 漏桶算法特点:流量整形、缓冲能力、可预测性能
- 实践建议:分层限流、差异化策略、监控告警、优雅降级
不过,限流也不是万能的,需要结合具体的业务场景和系统特点来设计合适的策略。