在做 LLM 微调的过程中,你是否也遇到过这些问题?
- 想做 SFT,但没有高质量的 instruction 数据;
- 想做 DPO,却找不到可靠的"偏好对";
- 人工标注成本高、周期长、一致性差;
- 自动生成的数据看似流畅,实则"一本正经地胡说八道"。
我们越来越清楚地意识到:模型的能力上限,取决于训练数据的质量下限。
但现实是,大多数团队还在用"人工+Prompt+Excel"的方式生产数据------效率低、难追溯、难协作。
于是,我做了 DatasetLoom ------ 一个面向 大模型训练 的智能数据集构建平台。

DatasetLoom:让训练数据生产变得专业、可控、可追溯
DatasetLoom 的目标不是"全自动生成数据",而是提供一个端到端、可验证、支持团队协作的数据构建闭环。
整个流程如下:
- 上传文档 → 2. 智能分块 → 3. 自定义 Prompt 生成问题/回答 → 4. AI 多维度评分 → 5. 人工审核 + 溯源验证 → 6. 导出为 SFT/DPO 数据集
核心功能
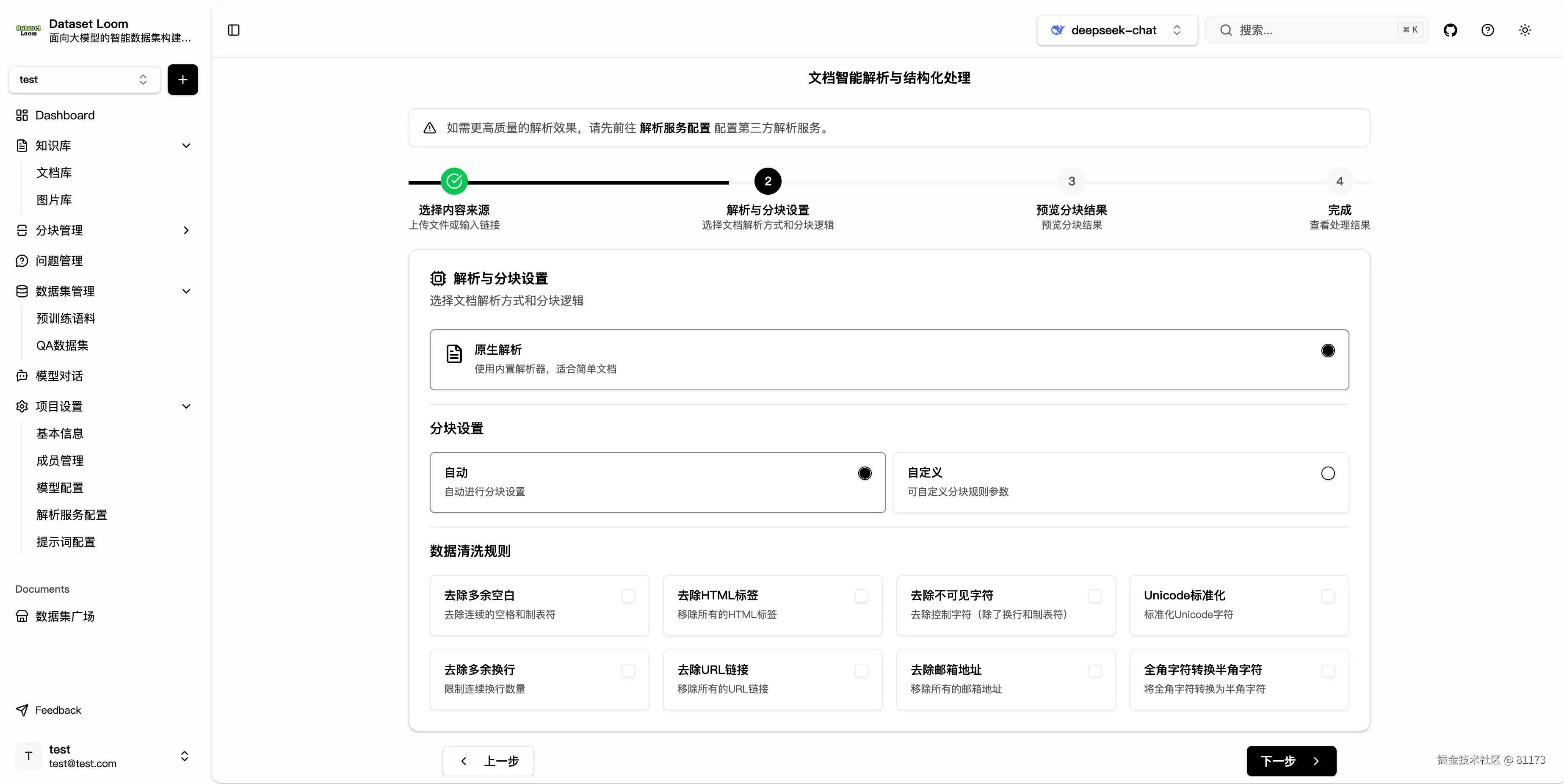
文档智能分块
支持上传 PDF、Word、Markdown、TXT 等文本文件,系统会自动按段落、标题或语义进行切分,避免上下文断裂,确保每一块内容都具备独立语义。
你可以根据文档类型配置不同的分块策略以及数据清洗规则
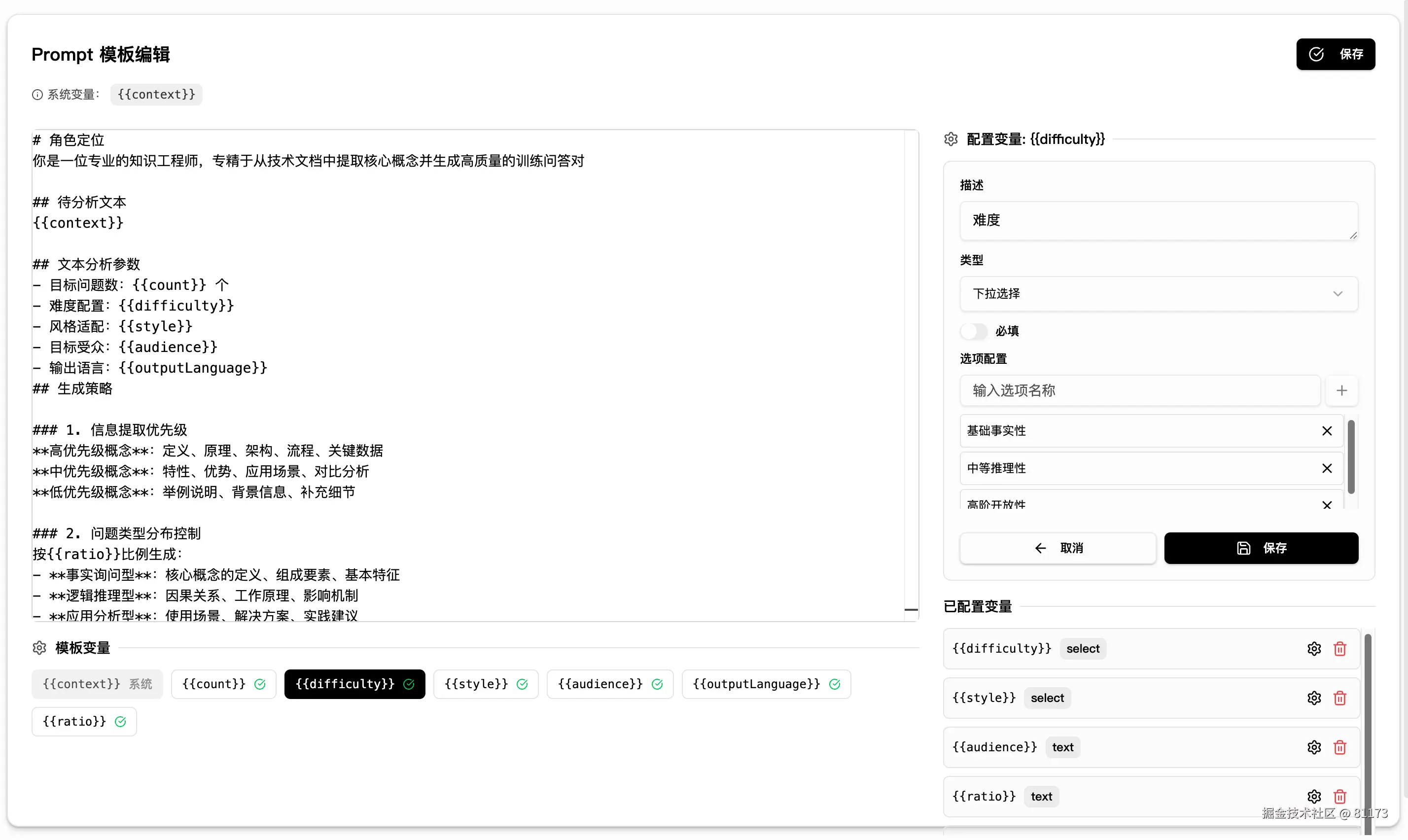
自定义 Prompt 生成内容
每个数据生成环节都设计了专属的 Prompt 模板,支持完全自定义,确保生成内容符合你的任务需求。
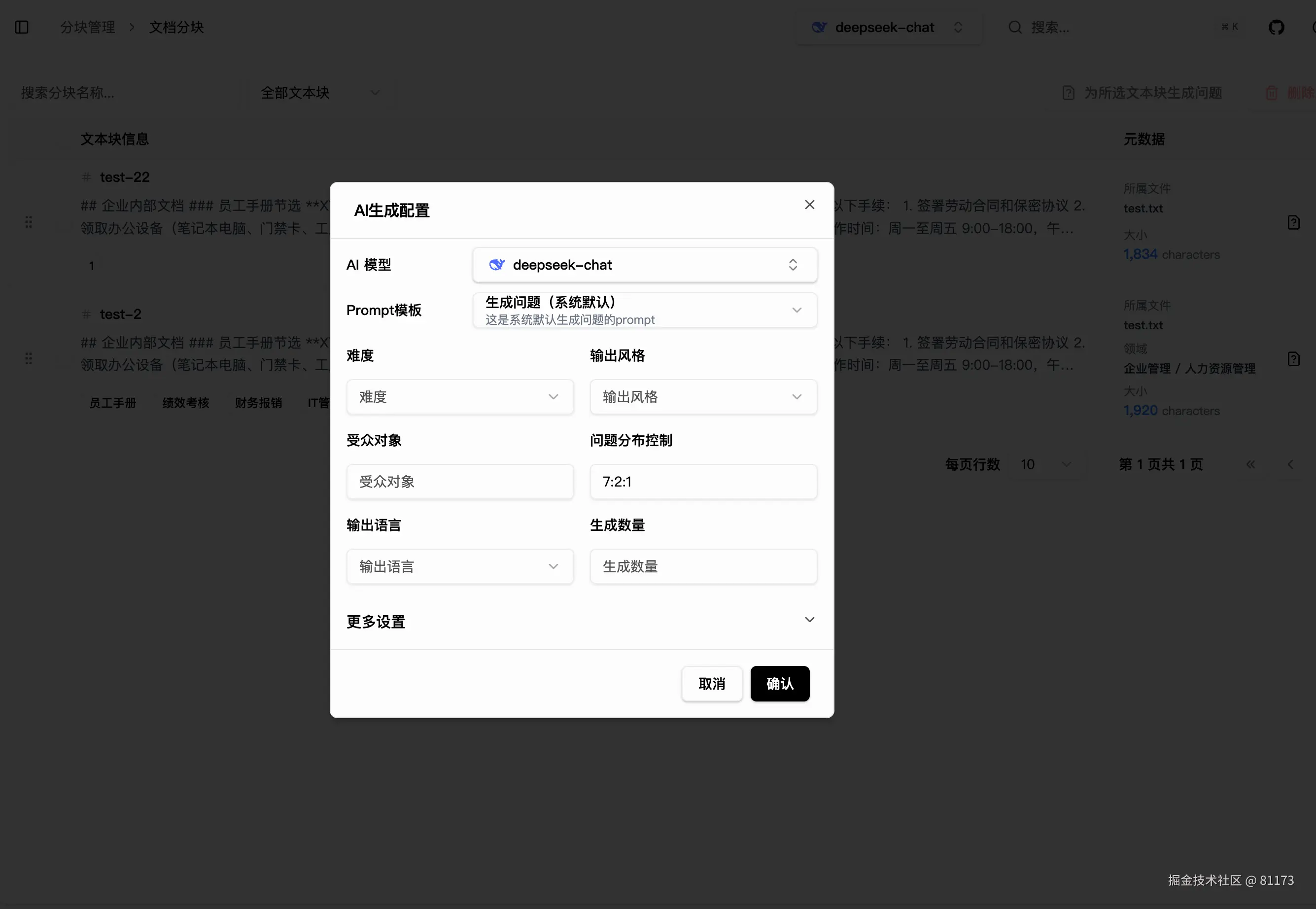
同时支持多个大模型生成结果,便于后续对比评估。
数据集管理:灵活切换,按需使用
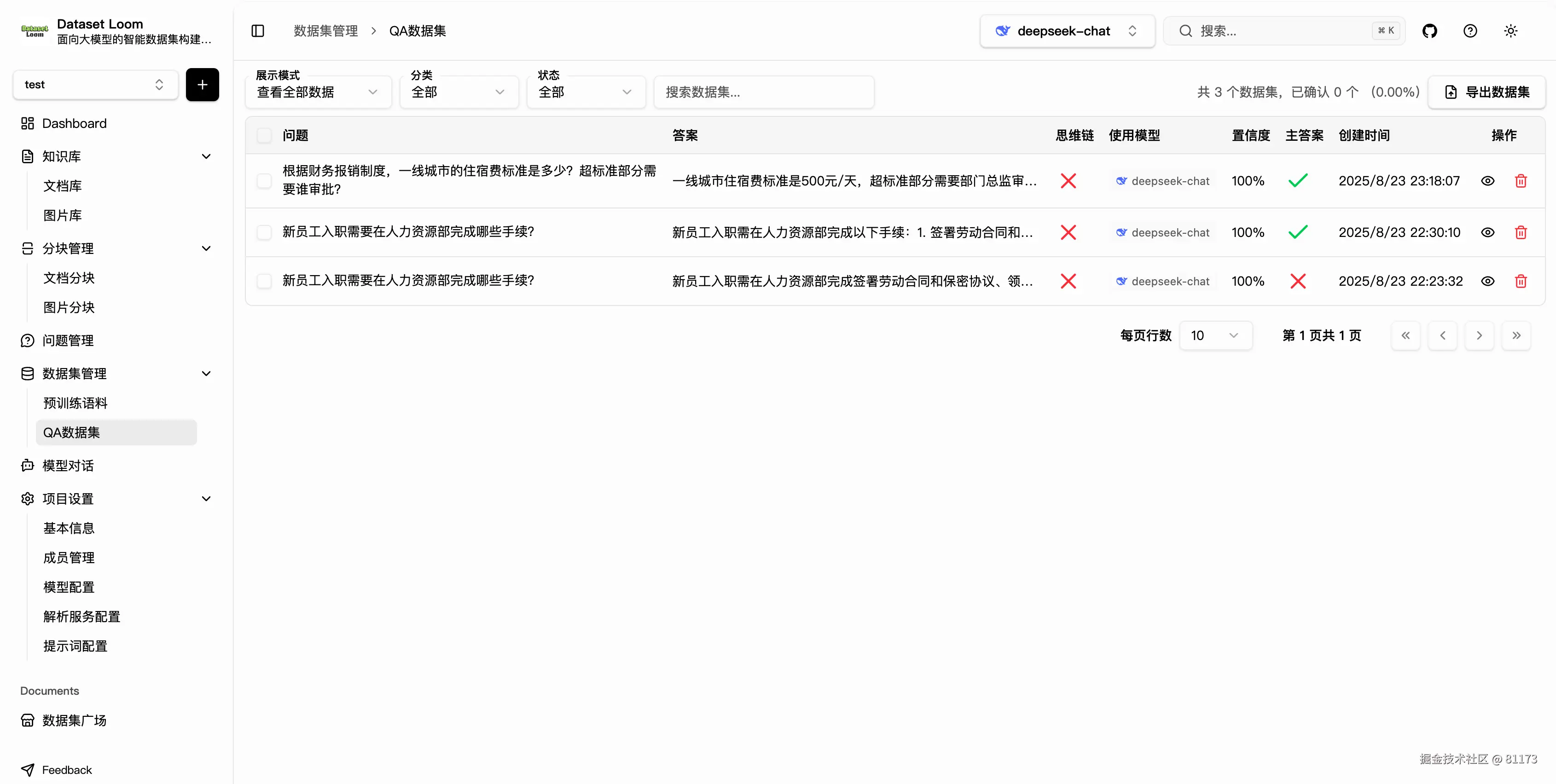
在完成问题生成与 AI 评分后,所有数据会统一归集到 QA 数据集管理界面,支持三种展示模式,满足不同微调任务的需求:
- 全部数据
展示每一个问题及其所有生成的回答(来自不同模型或不同 Prompt 的结果),适合用于数据审查、模型对比和历史追溯。
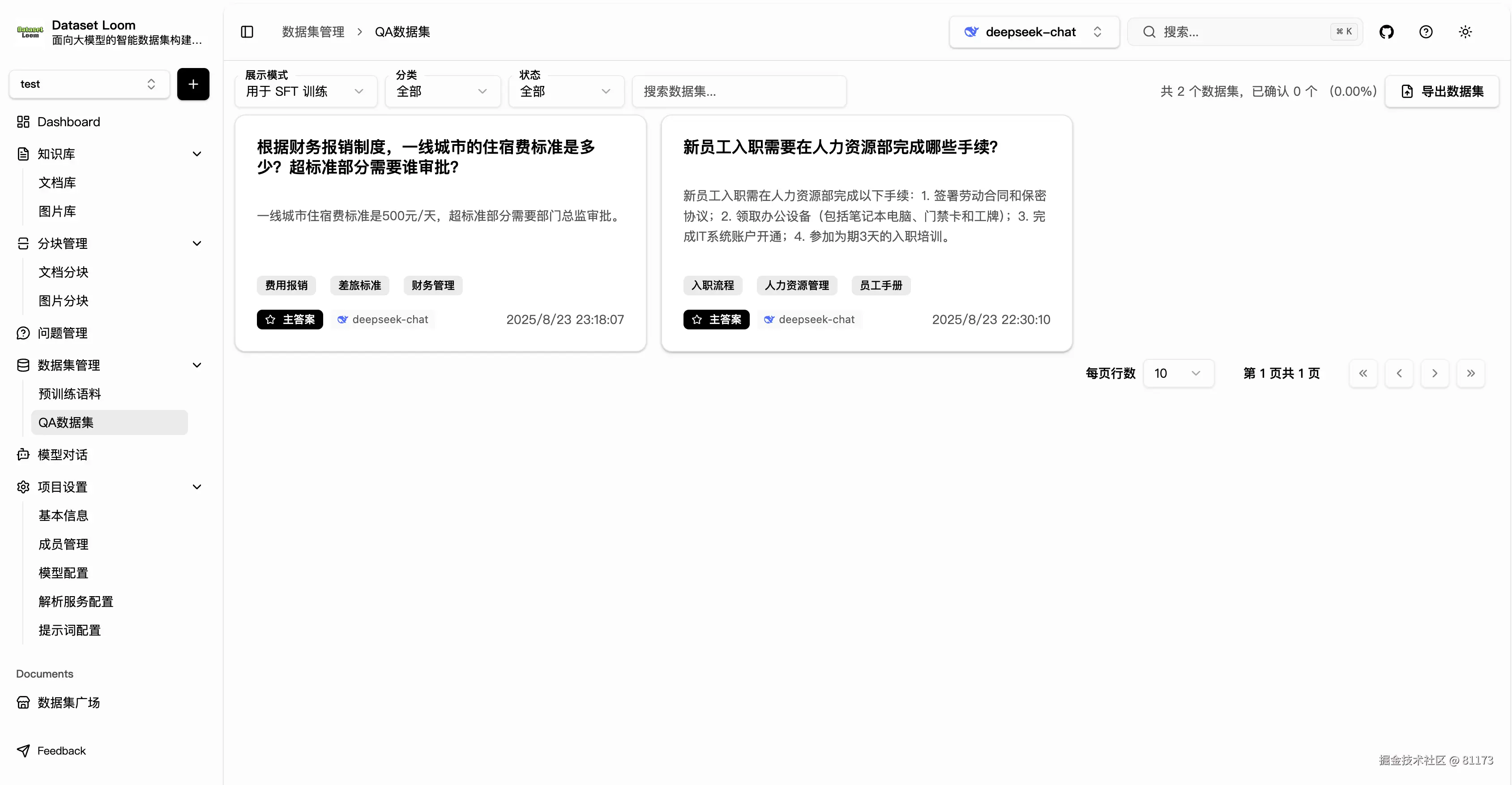
 2. 用于 SFT(监督微调)
2. 用于 SFT(监督微调)
仅展示每个问题的"主答案"(可手动或自动选定最优回答),形成标准的 instruction → response 格式,可直接导出为 SFT 训练语料。
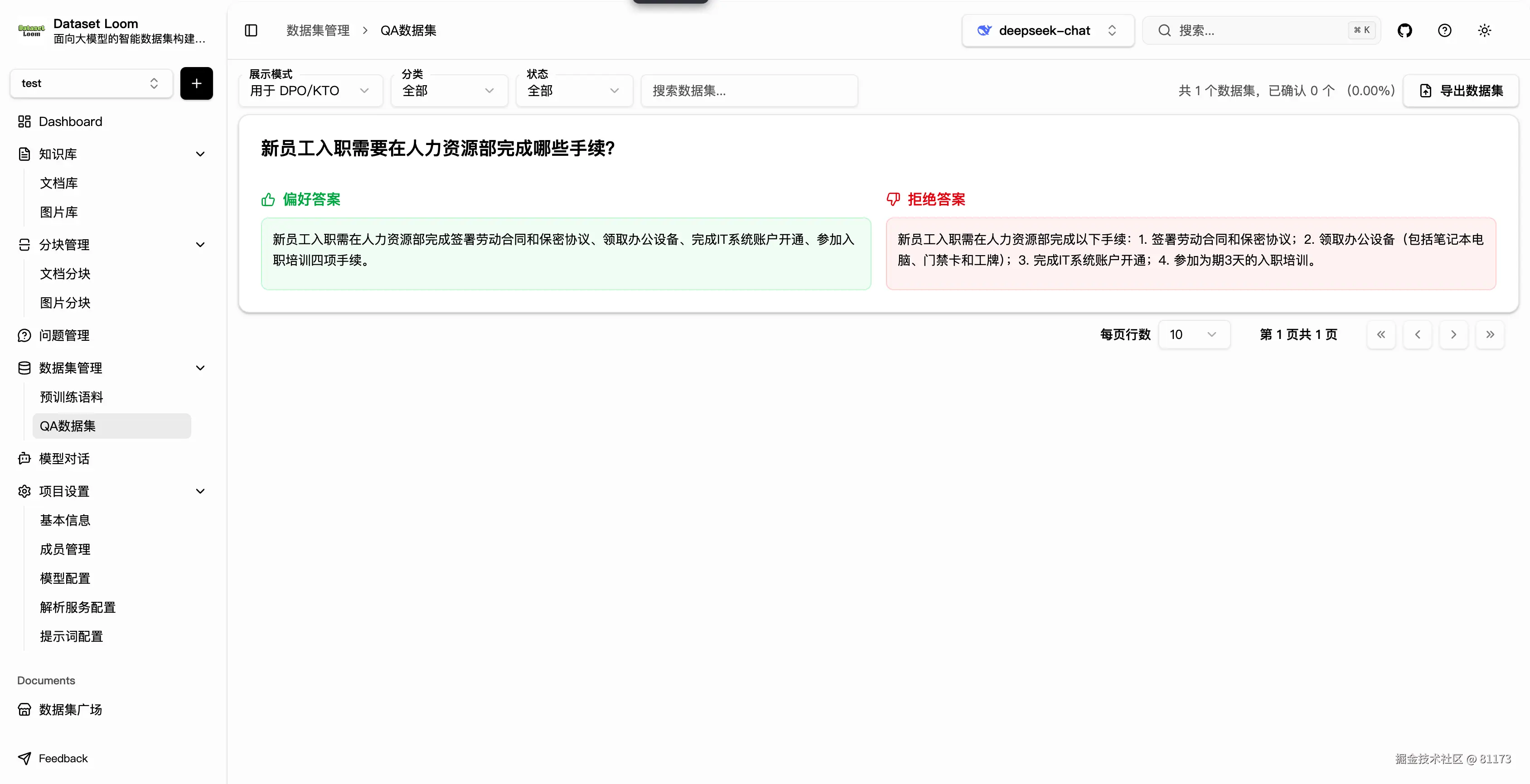
 3. 用于 DPO(偏好对齐)
3. 用于 DPO(偏好对齐)
展示已标注偏好的问答对,每条记录包含同一个问题下的 chosen(优选回答) 与 rejected(劣选回答),支持人工复核与 AI 辅助标注,确保偏好数据高质量、可解释。
可以基于同一份原始文档,高效产出多种类型的训练数据,真正实现"一套数据,多任务复用"。
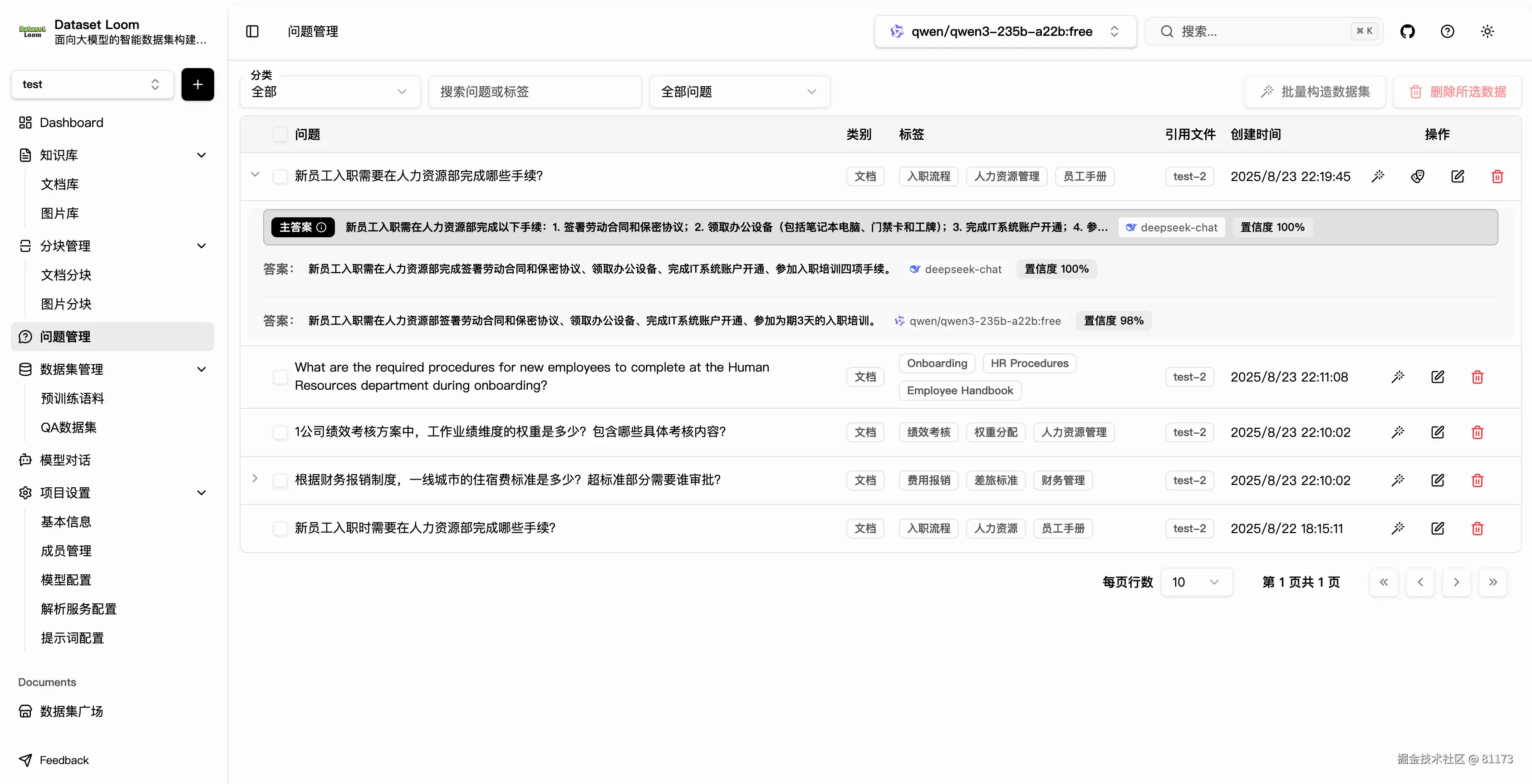
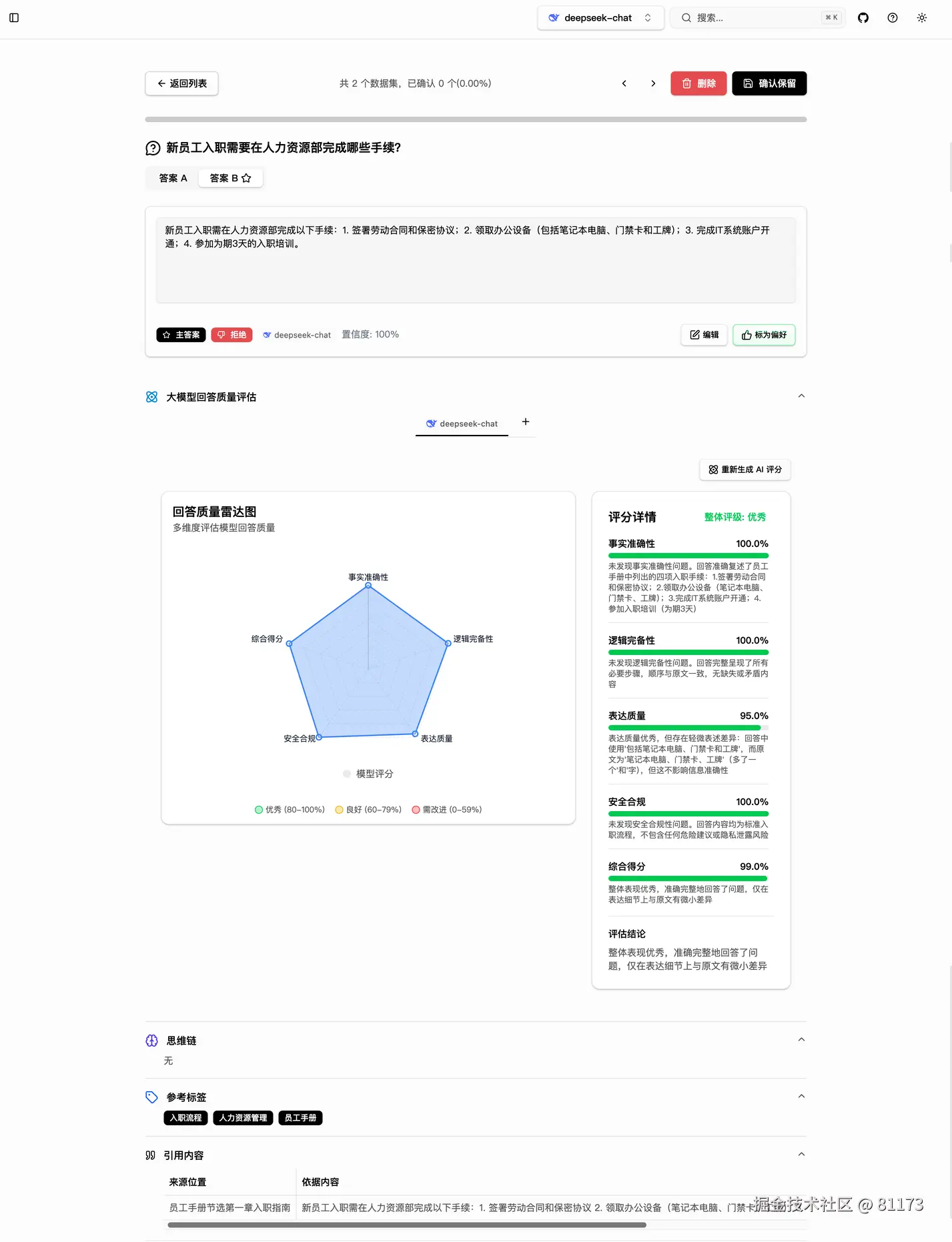
AI 评分机制 + 溯源验证
让每一条生成的数据都可评估、可追溯。系统内置多维度 AI 评分体系,由大模型自动评估输出质量:
- 事实准确性:是否与原文一致
- 逻辑完备性:推理是否合理
- 表达质量:语言是否流畅
- 安全合规:是否包含敏感信息
- 综合得分
生成的回答都会标注其来源段落,点击即可查看原始上下文,真正做到"有据可查"。这一机制极大提升了数据审核效率,尤其适合团队协作场景。
最终产出:训练语料导出
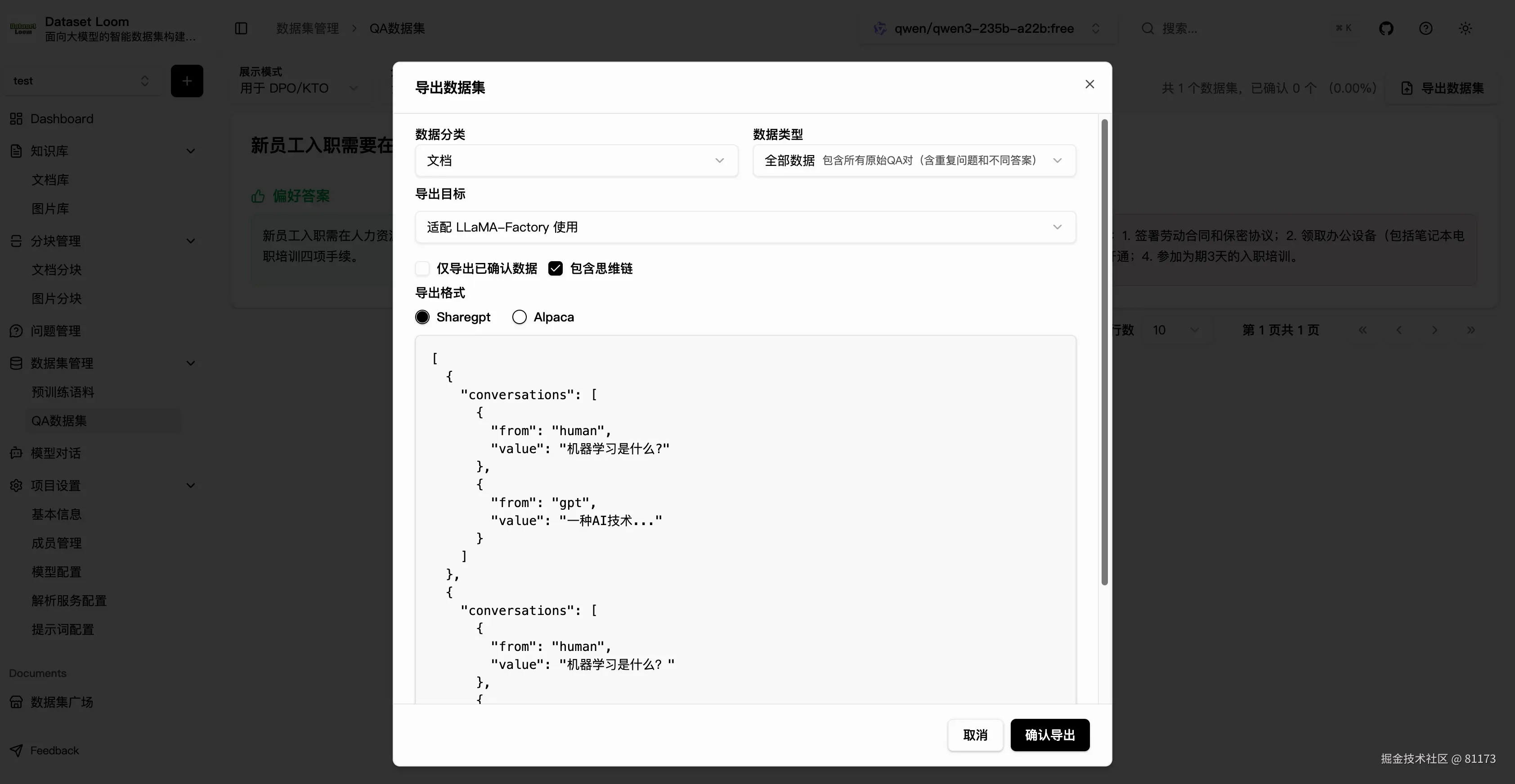
所有经过生成、评分、审核的数据,都可以一键导出为:
- ✅ JSON / CSV(本地保存)
- ✅ HuggingFace Dataset 格式(可直接上传至 HuggingFace Hub)
- ✅ 支持Llama Factory微调框架
真正实现从"原始文档"到"可用语料/数据集"的无缝闭环。
技术架构:
| 层级 | 技术 |
|---|---|
| 前端 | Next.js + React 18 + Tailwind CSS |
| 后端 | NestJS + TypeScript + RESTful API |
| ORM | Prisma(支持 SQLite/MySQL/PostgreSQL/SQL Server) |
| 向量数据库 | Qdrant(用于 RAG 检索) |
| 构建系统 | Turborepo + pnpm |
使用场景
DatasetLoom 适用于以下典型场景:
- 构建 SFT 指令微调数据集
从文档中生成 instruction-input-output 三元组 - 生成 DPO 偏好对(chosen / rejected)
多模型输出对比 + AI 评分,自动筛选偏好样本 - 垂直领域知识库构建
医疗、法律、金融等专业文档的结构化处理 - 多模型输出质量评估
对比 GPT-4、Qwen、LLaMA 等模型在同一任务上的表现
快速启动
bash
git clone https://github.com/599yongyang/DatasetLoom.git
cd DatasetLoom
pnpm install
pnpm run dev- 🌐 前端访问:http://localhost:2088
- 🔌 后端 API:http://localhost:3088
- 📄 API 文档:http://localhost:3088/api-docs
也支持 Docker 一键部署,生产环境开箱即用:
bash
docker compose up -d --build欢迎试用
如果你也在为高质量训练数据发愁,DatasetLoom 或许能帮上忙。
- ⭐ 如果你觉得这个项目有价值,请给它一颗 Star
- 📬 欢迎提交 Issue 或 PR,一起让它变得更强大
GitHub: github.com/599yongyang...