一、Kubernetes介绍
1.简介

kubernetes的本质是一组服务器集群,它可以在集群的每个节点上运行特定的程序,来对节点中的容器进行管理。目的是实现资源管理的自动化,主要提供了如下的主要功能:
-
自我修复:一旦某一个容器崩溃,能够在1秒中左右迅速启动新的容器
-
弹性伸缩:可以根据需要,自动对集群中正在运行的容器数量进行调整
-
服务发现:服务可以通过自动发现的形式找到它所依赖的服务
-
负载均衡:如果一个服务起动了多个容器,能够自动实现请求的负载均衡
-
版本回退:如果发现新发布的程序版本有问题,可以立即回退到原来的版本
-
存储编排:可以根据容器自身的需求自动创建存储
2.常用名词感念
-
Master:集群控制节点,每个集群需要至少一个master节点负责集群的管控
-
Node:工作负载节点,由master分配容器到这些node工作节点上,然后node节点上的
-
Pod:kubernetes的最小控制单元,容器都是运行在pod中的,一个pod中可以有1个或者多个容器
-
Controller:控制器,通过它来实现对pod的管理,比如启动pod、停止pod、伸缩pod的数量等等
-
Service:pod对外服务的统一入口,下面可以维护者同一类的多个pod
-
Label:标签,用于对pod进行分类,同一类pod会拥有相同的标签
-
NameSpace:命名空间,用来隔离pod的运行环境
3.k8S的分层架构
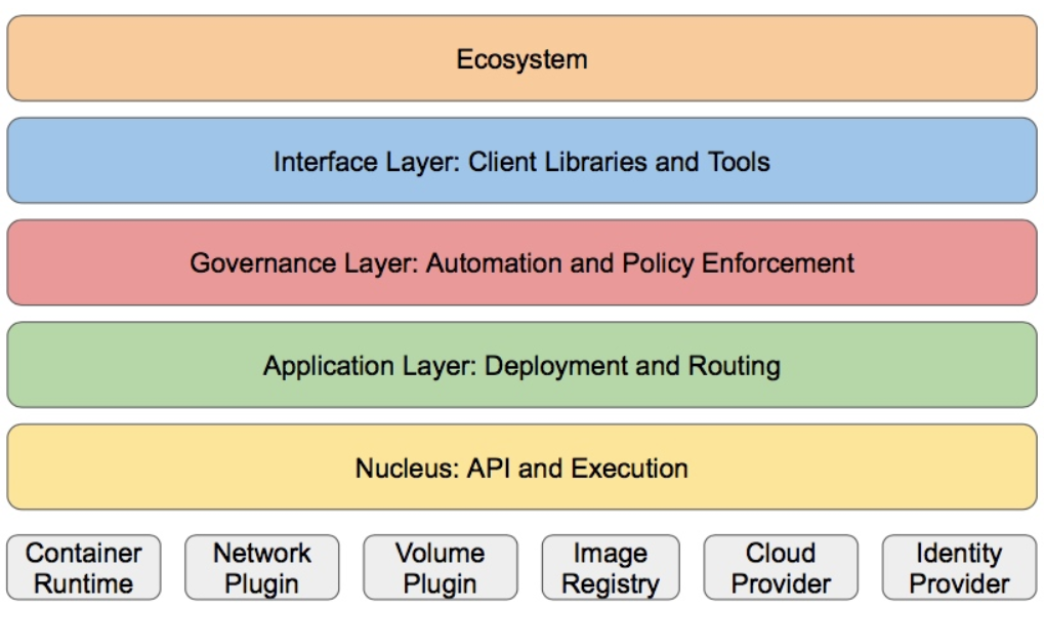
-
核心层:Kubernetes最核心的功能,对外提供API构建高层的应用,对内提供插件式应用执行环境
-
应用层:部署(无状态应用、有状态应用、批处理任务、集群应用等)和路由(服务发现、DNS解析等)
-
管理层:系统度量(如基础设施、容器和网络的度量),自动化(如自动扩展、动态Provision等)以及策略管理(RBAC、Quota、PSP、NetworkPolicy等)
-
接口层:kubectl命令行工具、客户端SDK以及集群联邦
-
生态系统:在接口层之上的庞大容器集群管理调度的生态系统,可以划分为两个范畴
-
Kubernetes外部:日志、监控、配置管理、CI、CD、Workflow、FaaS、OTS应用、ChatOps等
-
Kubernetes内部:CRI、CNI、CVI、镜像仓库、Cloud Provider、集群自身的配置和管理等
二、K8S集群环境搭建
1.K8s中容器的管理方式
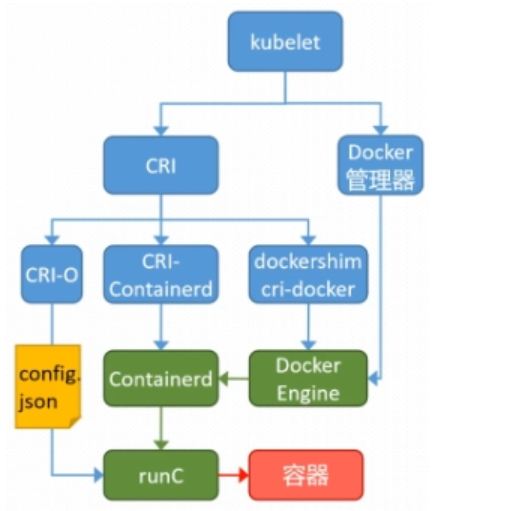
K8S 集群创建方式有3种:
centainerd
默认情况下,K8S在创建集群时使用的方式
docker
Docker使用的普记录最高,虽然K8S在1.24版本后已经费力了kubelet对docker的支持,但时可以借助cri-docker方式来实现集群创建
cri-o
CRI-O的方式是Kubernetes创建容器最直接的一种方式,在创建集群的时候,需要借助于cri-o插件的方式来实现Kubernetes集群的创建。
2.实验环境
|---------------|---------------------|----------------------|
| 名称 | IP | 角色 |
| harbor | 192.168.159.200 | harbor仓库 |
| master | 192.168.159.100 | master,k8s集群控制节点 |
| k8s-node1 | 192.168.159.50 | worker,k8s集群工作节点 |
| k8s-node2 | 192.168.159.60 | worker,k8s集群工作节点 |
bash
[root@reg ~]# systemctl disable --now firewalld
Removed "/etc/systemd/system/multi-user.target.wants/firewalld.service".
Removed "/etc/systemd/system/dbus-org.fedoraproject.FirewallD1.service".
[root@reg ~]# getenforce
Disableda.harbor环境安装
bash
[root@reg ~]# ls
anaconda-ks.cfg docker.tar.gz Downloads Pictures Templates
Desktop Documents Music Public Videos
[root@reg ~]# tar zxf docker.tar.gz
[root@reg ~]# ls
anaconda-ks.cfg docker Documents Music Public Videos
Desktop docker.tar.gz Downloads Pictures Templates
[root@reg ~]# cd docker/
[root@reg docker]# ls
containerd.io-1.7.27-3.1.el9.x86_64.rpm
docker-buildx-plugin-0.26.1-1.el9.x86_64.rpm
docker-ce-28.3.3-1.el9.x86_64.rpm
docker-ce-cli-28.3.3-1.el9.x86_64.rpm
docker-ce-rootless-extras-28.3.3-1.el9.x86_64.rpm
docker-compose-plugin-2.39.1-1.el9.x86_64.rpm
[root@reg docker]# dnf install *.rpm -y
bash
[root@reg docker]# vim /lib/systemd/system/docker.service 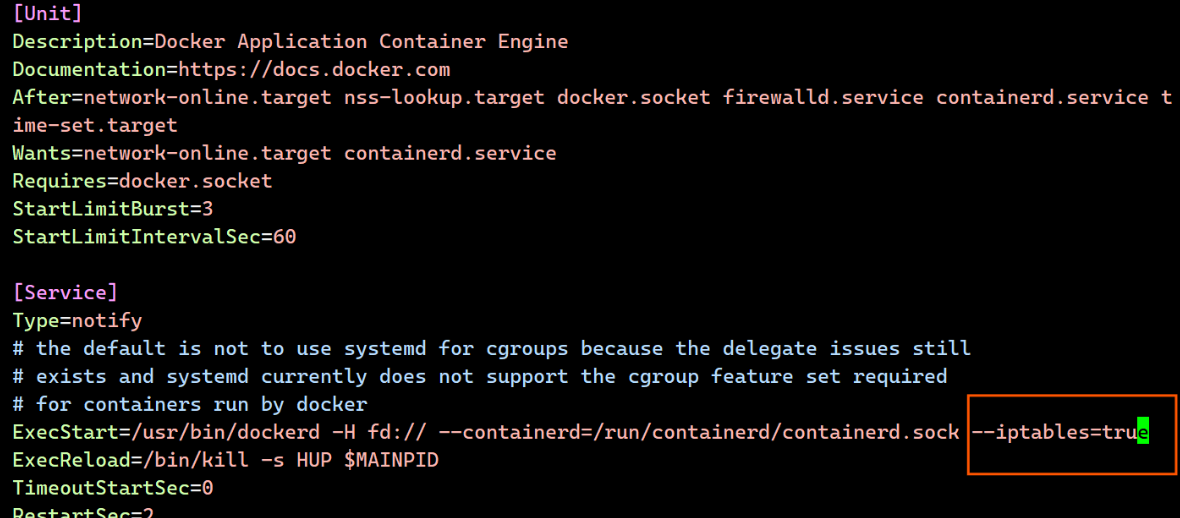
b.harbor仓库证书设定
bash
[root@reg ~]# ls
anaconda-ks.cfg docker.tar.gz harbor-offline-installer-v2.5.4.tgz Public
Desktop Documents Music Templates
docker Downloads Pictures Videos
#解压harbor镜像
[root@reg ~]# tar zxf harbor-offline-installer-v2.5.4.tgz
#编写证书策略
[root@reg ~]# mkdir -p /data/certs
[root@reg ~]# openssl req -newkey rsa:4096 -nodes -sha256 -keyout /data/certs/timinglee.org.key -addext "subjectAltName = DNS:reg.timinglee.org" -x509 -days 365 -out /data/certs/timinglee.org.crt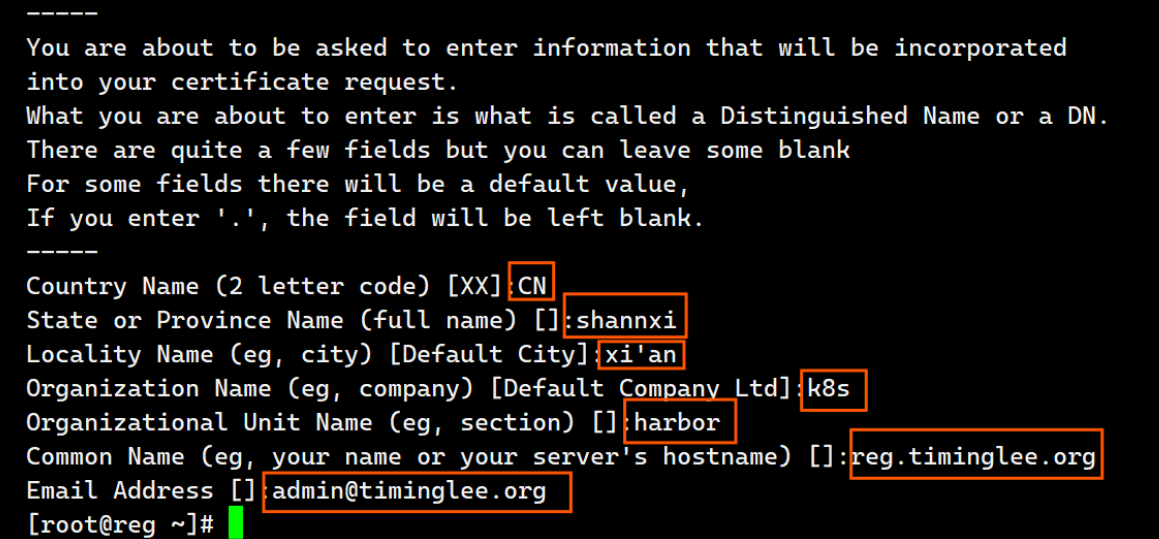
bash
#编写正确的证书信息
[root@reg ~]# cd harbor/
[root@reg harbor]# ls
common.sh harbor.v2.5.4.tar.gz harbor.yml.tmpl install.sh LICENSE prepare
[root@reg harbor]# cp harbor.yml.tmpl harbor.yml
[root@reg harbor]# vim harbor.yml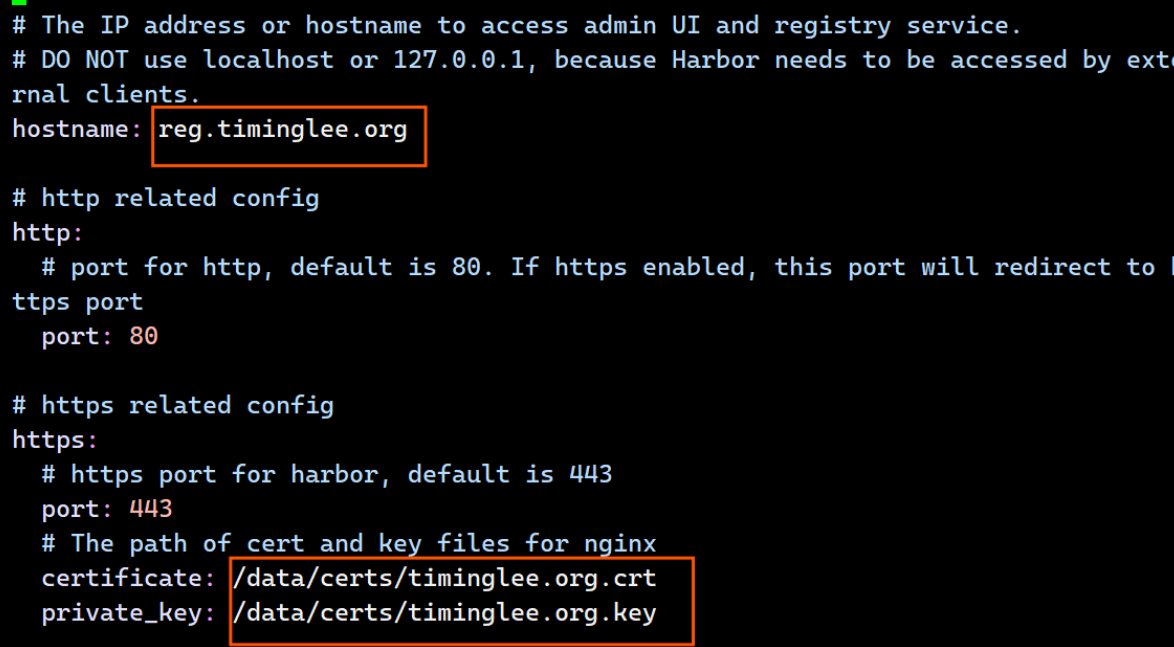
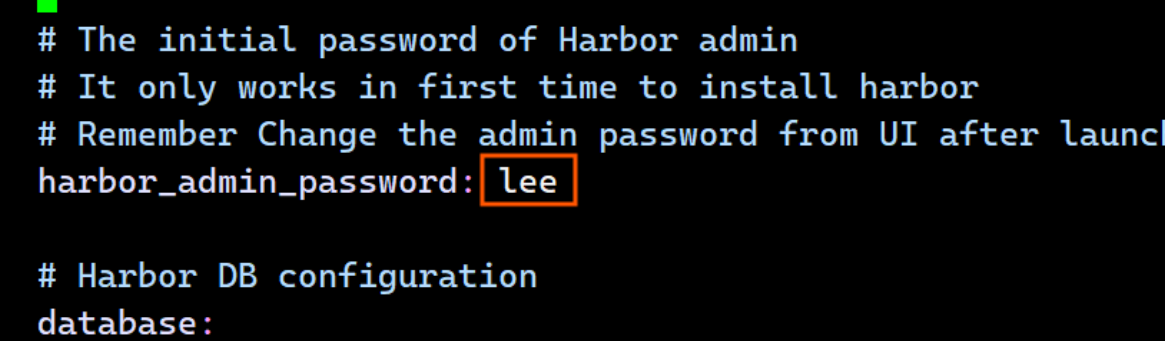
bash
#安装执行脚本启动harbor
[root@reg harbor]# ./install.sh --with-chartmuseum注意:若启动 Harbor 时失败解决方法:
1.启用并启动 iptables(或 firewalld)
systemctl enable --now iptables # 如果系统用 firewalld systemctl enable --now firewalld2.刷新 Docker 网络规则
systemctl restart docker3.确认链已创建(不为空)
iptables -t nat -L DOCKER -n4.再次启动 Harbor
cd /root/harbor ./install.sh --with-chartmuseum
3.集群环境初始化
所有k8s集群节点执行以下步骤
a.所有禁用swap
bash
[root@master+node1+node2 ~]# vim /etc/fstab
[root@master+node1+node2 ~]# systemctl daemon-reload
[root@master+node1+node2 ~]# systemctl mask swap.target
Created symlink /etc/systemd/system/swap.target → /dev/null.
[root@master+node1+node2 ~]# swapoff -a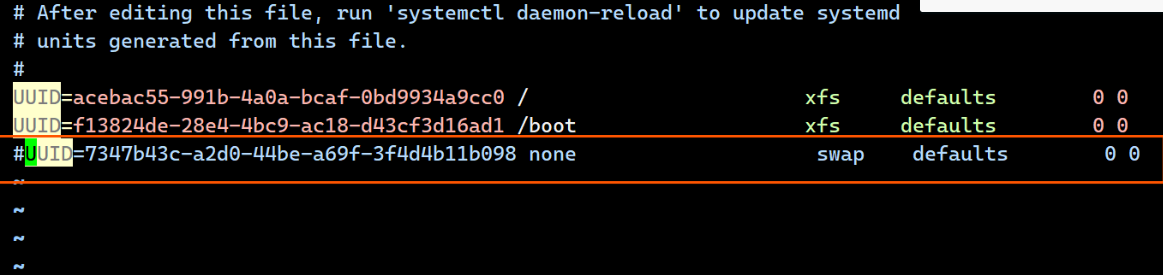 b.所有安装docker
b.所有安装docker
bash
[root@reg docker]# scp *.rpm root@192.168.159.100:/mnt
[root@reg docker]# scp *.rpm root@192.168.159.50:/mnt
[root@reg docker]# scp *.rpm root@192.168.159.60:/mnt
bash
[root@reg docker]# dnf install *.rpm -y
bash
[root@master mnt]# vim /lib/systemd/system/docker.service
[root@master mnt]# for i in 50 60
> do scp /lib/systemd/system/docker.service root@192.168.159.$i:/lib/systemd/system/docker.service
> done/895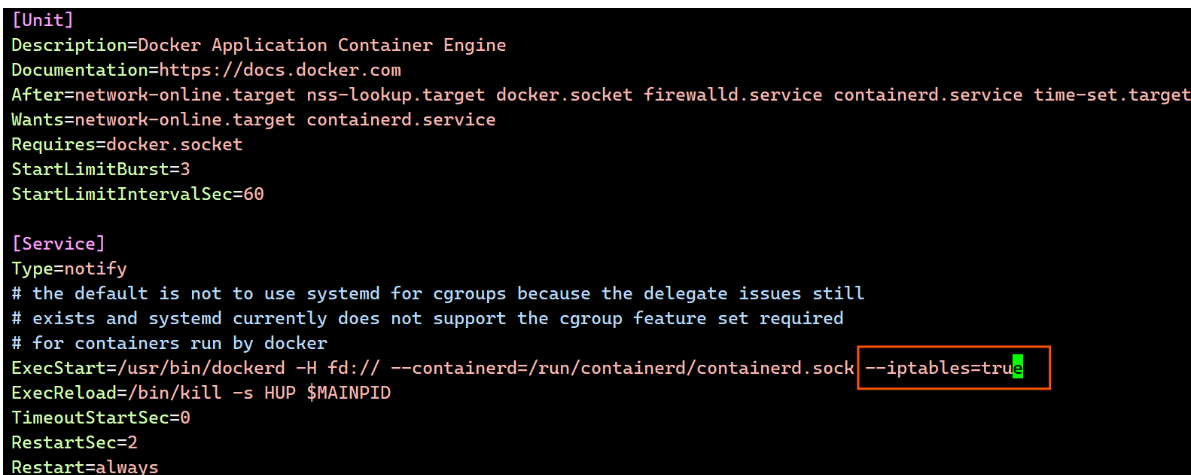
bash
[root@reg ~]# for i in 100 50 60 ; do ssh -l root 192.168.159.$i mkdir -p /etc/docker/certs.d ; scp /data/certs/timinglee.org.crt root@192.168.159.$i:/etc/docker/certs.d/ca.crt ; donec.所有节点设定docker的资源管理模式为systemd
bash
[root@master ~]# cd /etc/docker/
[root@master docker]# ls
certs.d
[root@master docker]# vim daemon.json
{
"registry-mirrors": ["https://reg.timinglee.org"]
}
[root@master docker]# for i in 50 60; do scp daemon.json root@192.168.159.$i:/etc/docker/ ; done
[root@master docker]# for i in 100 50 60 ; do ssh root@192.168.159.$i systemctl enable --now docker; doned.添加本地解析
bash
#添加解析
[root@master docker]# vim /etc/hosts
#复制给所有k8s主机
[root@master docker]# for i in 50 60 ; do scp /etc/hosts root@192.168.159.$i:/etc/hosts ;done
bash
#所有节点登录harbor
[root@master docker]# cd /etc/docker/certs.d/
[root@master certs.d]# ls
ca.crt
[root@master certs.d]# mkdir reg.timinglee.org
[root@master certs.d]# mv ca.crt reg.timinglee.org/
[root@master certs.d]# ls
reg.timinglee.org
[root@master certs.d]# systemctl restart docker
[root@master ~]# docker login reg.timinglee.org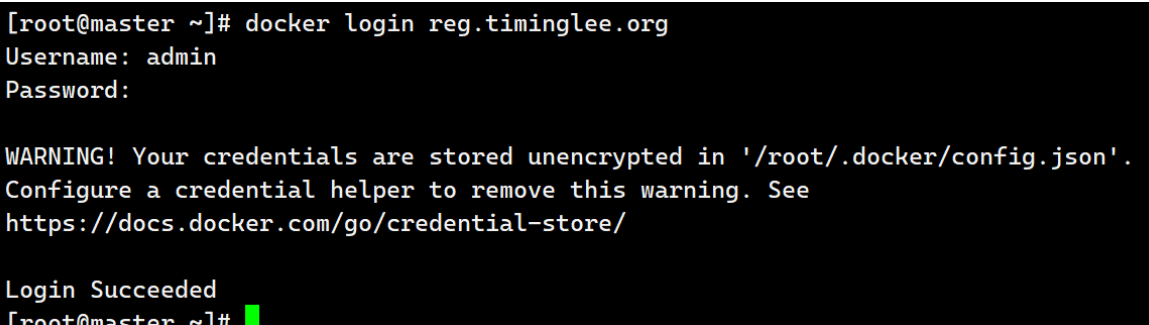
4.安装K8S部署工具
所有k8s集群节点执行以下步骤
a.部署软件仓库
bash
#部署软件仓库,添加K8S源
[root@master ~]# vim /etc/yum.repos.d/k8s.repo
[k8s]
name=k8s
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.30/rpm
gpgcheck=0
#安装软件
[root@master ~]# dnf install kubelet-1.30.0 kubeadm-1.30.0 kubectl-1.30.0 -yb.设置kubectl命令补齐功能
bash
[root@master ~]# dnf install bash-completion -y
[root@master ~]# echo "source <(kubectl completion bash)" >> ~/.bashrc
[root@master ~]# source ~/.bashrcc.在所节点安装cri-docker
k8s从1.24版本开始移除了dockershim,所以需要安装cri-docker插件才能使用docker
软件下载:https://github.com/Mirantis/cri-dockerd
Releases · Mirantis/cri-dockerd (github.com)
bash
[root@master ~]# for i in 50 60 ;do scp * root@192.168.159.$i:/root ;done
bash
[root@master ~]# dnf install libcgroup-0.41-19.el8.x86_64.rpm \
> cri-dockerd-0.3.14-3.el8.x86_64.rpm -y
bash
[root@master ~]# vim /lib/systemd/system/cri-docker.service
[Unit]
Description=CRI Interface for Docker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.target firewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
#指定网络插件名称及基础容器镜像
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --pod-infra-container-image=reg.timinglee.org/k8s/pause:3.9
ExecReload=/bin/kill -s HUP $MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
[root@master ~]# systemctl daemon-reload
[root@master ~]# systemctl start cri-docker
[root@master ~]# ll /var/run/cri-dockerd.sock
srw-rw---- 1 root docker 0 8月 26 22:14 /var/run/cri-dockerd.sock #cri-dockerd的套接字文件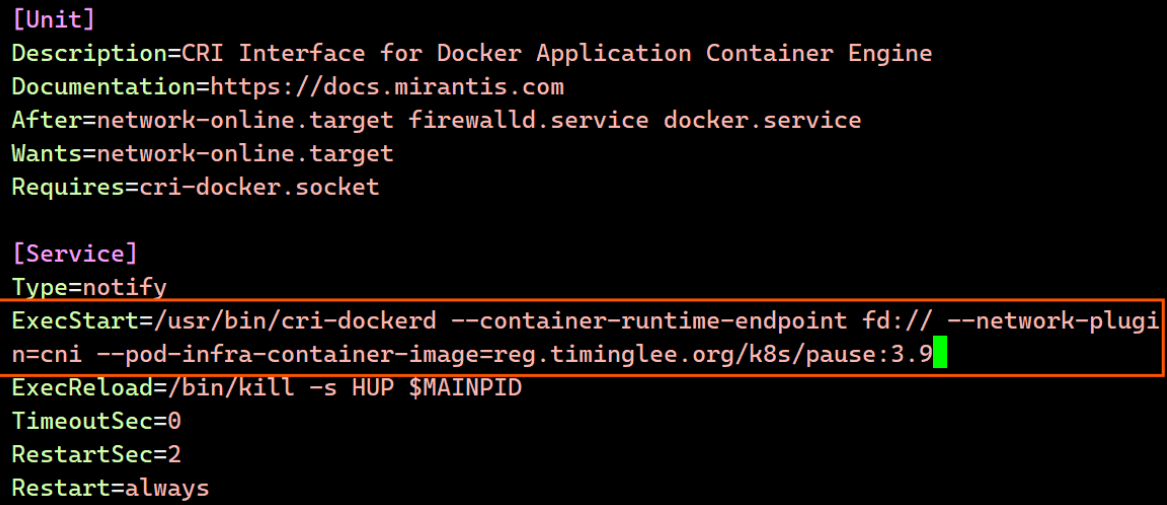
bash
[root@master ~]# for i in 50 60 ;do scp /lib/systemd/system/cri-docker.service root@192.168.159.$i:/lib/systemd/system/cri-docker.service ;done
bash
[root@master ~]# systemctl enable --now cri-docker.service
Created symlink /etc/systemd/system/multi-user.target.wants/cri-docker.service → /usr/lib/systemd/system/cri-docker.service.d.在master节点拉取K8S所需镜像
bash
#拉取k8s集群所需要的镜像
[root@master ~]# kubeadm config images pull \
--image-repository registry.aliyuncs.com/google_containers \
--kubernetes-version v1.30.0 \
--cri-socket=unix:///var/run/cri-dockerd.sock我这里直接使用压缩包:
bash
[root@master ~]# docker load -i k8s_docker_images-1.30.tar 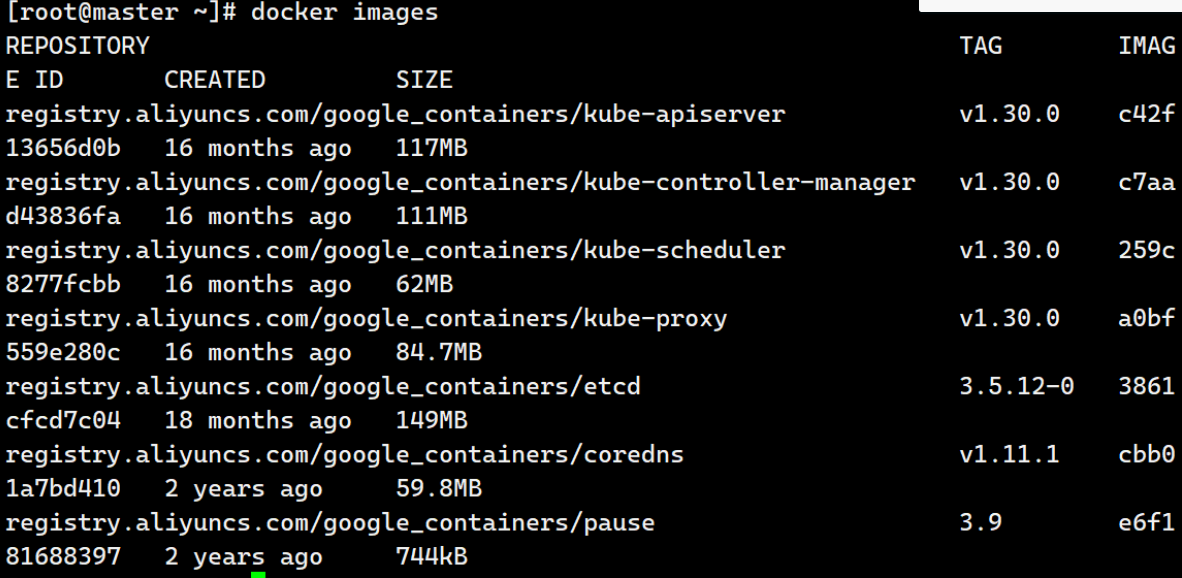
bash
#上传镜像到harbor仓库
[root@master ~]# docker images | awk '/google/{ print $1":"$2}' \
| awk -F "/" '{system("docker tag "$0" reg.timinglee.org/k8s/"$3)}'
[root@master ~]# docker images | awk '/k8s/{system("docker push "$1":"$2)}'
e.集群初始化
bash
#启动kubelet服务
[root@master ~]# systemctl status kubelet.service
#执行初始化命令
[root@master ~]# kubeadm init --pod-network-cidr=10.244.0.0/16 \
--image-repository reg.timinglee.org/k8s \
--kubernetes-version v1.30.0 \
--cri-socket=unix:///var/run/cri-dockerd.sock
#指定集群配置文件变量
[root@master ~]# echo "export KUBECONFIG=/etc/kubernetes/admin.conf" >> ~/.bash_profile
[root@master ~]# source ~/.bash_profile
#当前节点没有就绪,因为还没有安装网络插件,容器没有运行
[root@master ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
k8s-master.timinglee.org NotReady control-plane 4m25s v1.30.0
root@master ~]# kubectl get pod -A
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-647dc95897-2sgn8 0/1 Pending 0 6m13s
kube-system coredns-647dc95897-bvtxb 0/1 Pending 0 6m13s
kube-system etcd-k8s-master.timinglee.org 1/1 Running 0 6m29s
kube-system kube-apiserver-k8s-master.timinglee.org 1/1 Running 0 6m30s
kube-system kube-controller-manager-k8s-master.timinglee.org 1/1 Running 0 6m29s
kube-system kube-proxy-fq85m 1/1 Running 0 6m14s
kube-system kube-scheduler-k8s-master.timinglee.org 1/1 Running 0 6m29s!NOTE
在此阶段如果生成的集群token找不到了可以重新生成
[root@master ~]# kubeadm token create --print-join-command kubeadm join 172.25.254.100:6443 --token 5hwptm.zwn7epa6pvatbpwf --discovery-token-ca-cert-hash sha256:52f1a83b70ffc8744db5570288ab51987ef2b563bf906ba4244a300f61e9db23
f.安装flannel网络插件
官方网站:https://github.com/flannel-io/flannel
bash
#下载flannel的yaml部署文件
[root@master ~]# wget https://github.com/flannel-io/flannel/releases/latest/download/kube-flannel.yml
#下载镜像:
[root@master ~]# docker pull docker.io/flannel/flannel:v0.25.5
[root@master ~]# docekr docker.io/flannel/flannel-cni-plugin:v1.5.1-flannel1
bash
[root@master ~]# docker load -i flannel-0.25.5.tag.gz 
bash
#上传镜像到仓库
[root@master ~]# docker tag flannel/flannel:v0.25.5 reg.timinglee.org/flannel/flannel:v0.25.5
[root@master ~]# docker push reg.timinglee.org/flannel/flannel:v0.25.5
[root@master ~]# docker tag flannel/flannel-cni-plugin:v1.5.1-flannel1 reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
[root@master ~]# docker push reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
bash
#编辑kube-flannel.yml 修改镜像下载位置
[root@master ~]# vim kube-flannel.yml
[root@master ~]# kubectl apply -f kube-flannel.yml
#需要修改以下几行
[root@master ~]# grep -n image kube-flannel.yml
146: image: reg.timinglee.org/flannel/flannel:v0.25.5
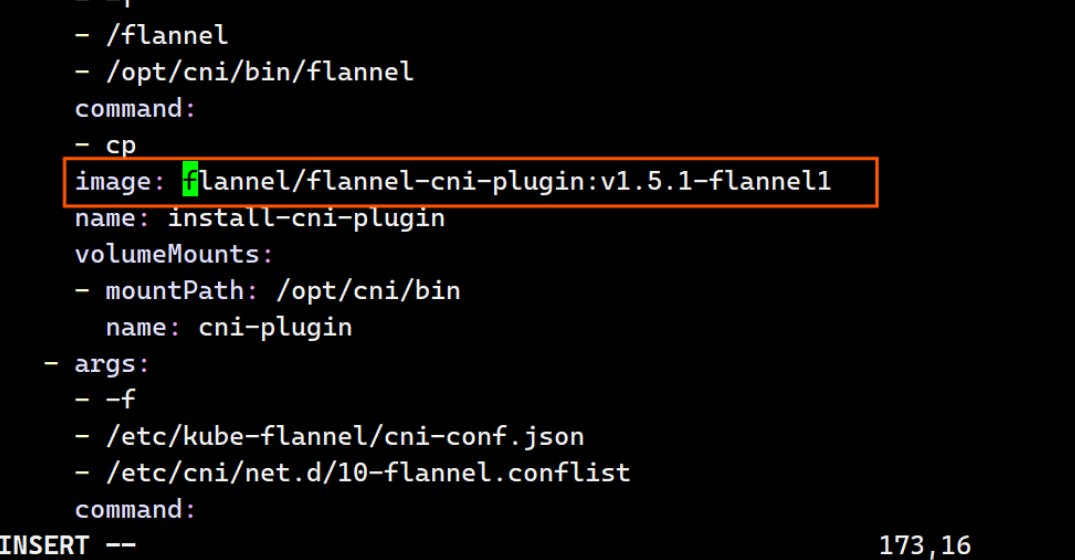
173: image: reg.timinglee.org/flannel/flannel-cni-plugin:v1.5.1-flannel1
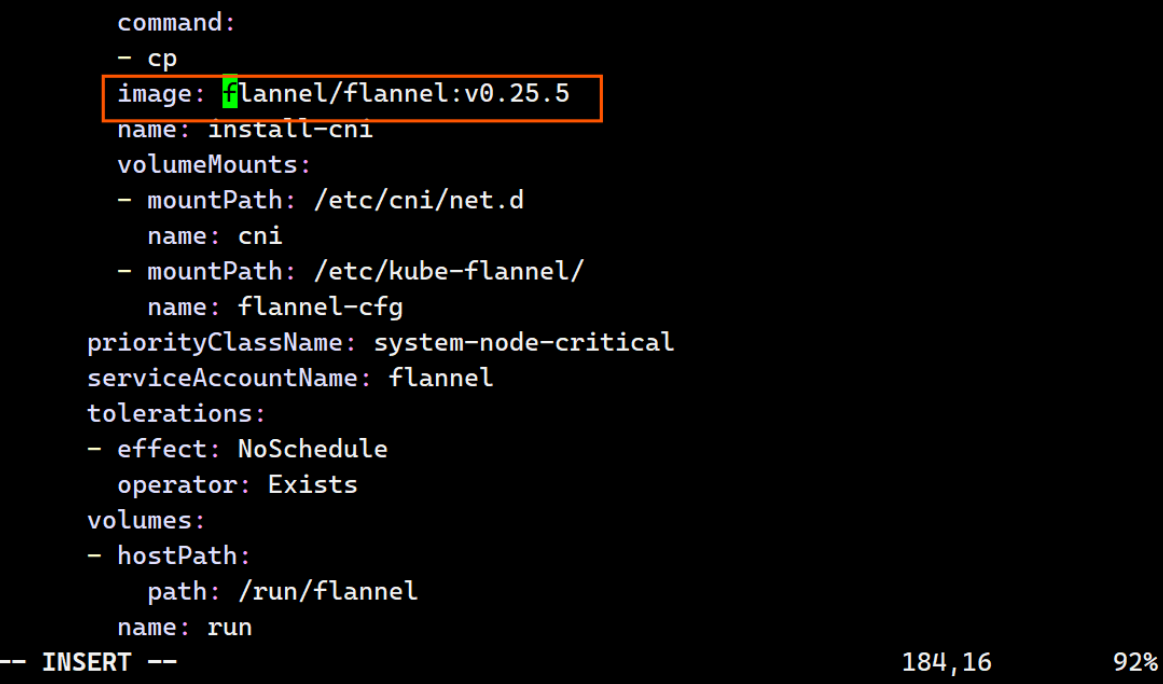
184: image: reg.timinglee.org/flannel/flannel:v0.25.5
#安装flannel网络插件
[root@master ~]# kubectl apply -f kube-flannel.yml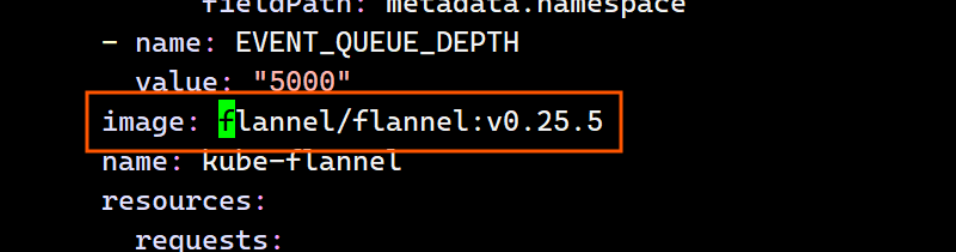
bash
[root@master ~]# kubectl get nodes 
g.节点扩容
bash
[root@node1+node2 ~]# kubeadm join 192.168.159.100:6443 --token m3a1to.yiz7eso1n9zvudss --discovery-token-ca-cert-hash sha256:2c96f2c3617acdfdaf970c9ba819b01d47581fa0a26eb47fdb4ace07a5333919 --cri-socket=unix:///var/run/cri-dockerd.sock 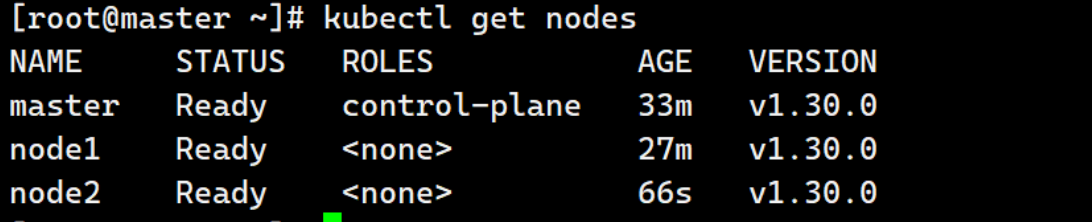
**测试集群运行情况**
bash
#建立一个pod
[root@master ~]# kubectl run test --image nginx
#查看pod状态
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 1/1 Running 0 6m29s
#删除pod
root@master ~]# kubectl delete pod三、kubernetes 中的资源
1. 资源管理介绍
-
在kubernetes中,所有的内容都抽象为资源,用户需要通过操作资源来管理kubernetes。
-
kubernetes的本质上就是一个集群系统,用户可以在集群中部署各种服务
-
所谓的部署服务,其实就是在kubernetes集群中运行一个个的容器,并将指定的程序跑在容器中。
-
kubernetes的最小管理单元是pod而不是容器,只能将容器放在
Pod中, -
kubernetes一般也不会直接管理Pod,而是通过
Pod控制器来管理Pod的。 -
Pod中服务的访问是由kubernetes提供的
Service资源来实现。 -
Pod中程序的数据需要持久化是由kubernetes提供的各种存储系统来实现
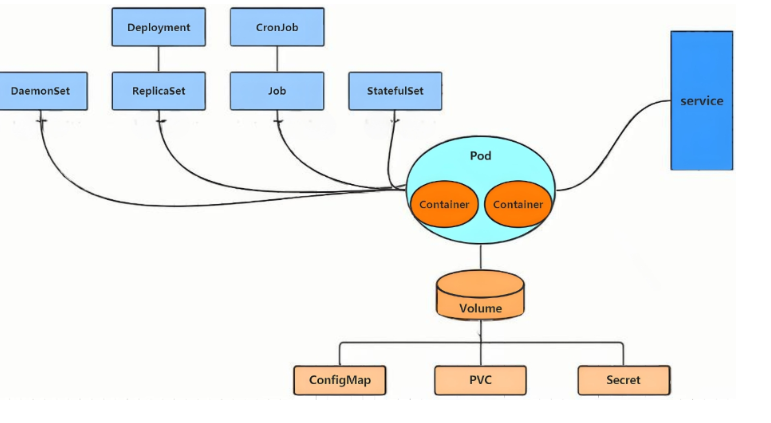
2.资源管理方式
-
命令式对象管理:直接使用命令去操作kubernetes资源
kubectl run nginx-pod --image=nginx:latest --port=80 -
命令式对象配置:通过命令配置和配置文件去操作kubernetes资源
kubectl create/patch -f nginx-pod.yaml -
声明式对象配置:通过apply命令和配置文件去操作kubernetes资源
kubectl apply -f nginx-pod.yaml bash
bash[root@master ~]# docker load -i busyboxplus.tar.gz [root@master ~]# docker load -i myapp.tar.gzbash[root@master ~]# docker tag busyboxplus:latest reg.timinglee.org/library/busyboxplus:latest [root@master ~]# docker push reg.timinglee.org/library/busyboxplus:latestbash[root@master ~]# docker tag timinglee/myapp:v1 reg.timinglee.org/library/myapp:v1 [root@master ~]# docker tag timinglee/myapp:v2 reg.timinglee.org/library/myapp:v2 [root@master ~]# docker push reg.timinglee.org/library/myapp:v1 [root@master ~]# docker push reg.timinglee.org/library/myapp:v2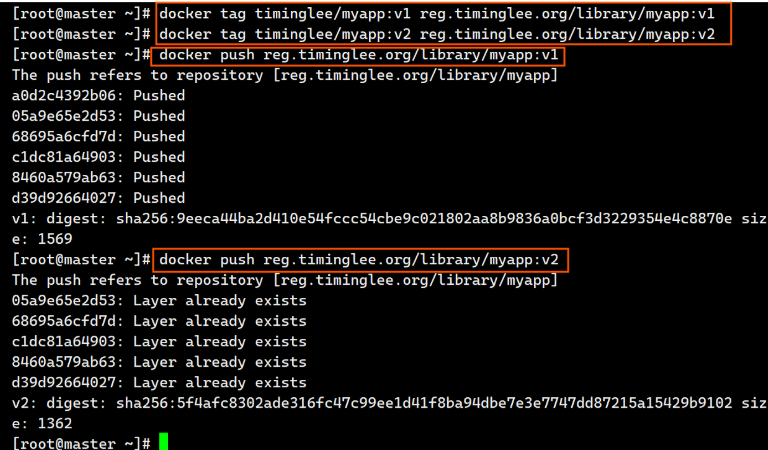
-
 bash
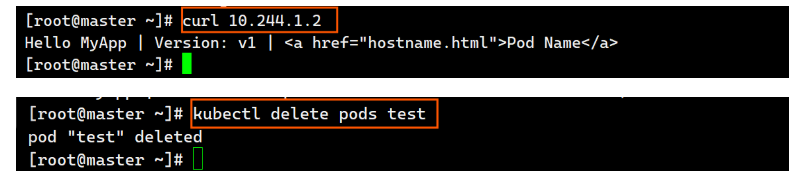
bash[root@master ~]# kubectl run test --image myapp:v1 pod/test created [root@master ~]# kubectl get pods NAME READY STATUS RESTARTS AGE test 1/1 Running 0 12s [root@master ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES test 1/1 Running 0 31s 10.244.1.2 node1 <none> <none>测试:
yaml页面形式:
bash
[root@master ~]# kubectl run test --image myapp:v1 --dry-run=client -o yaml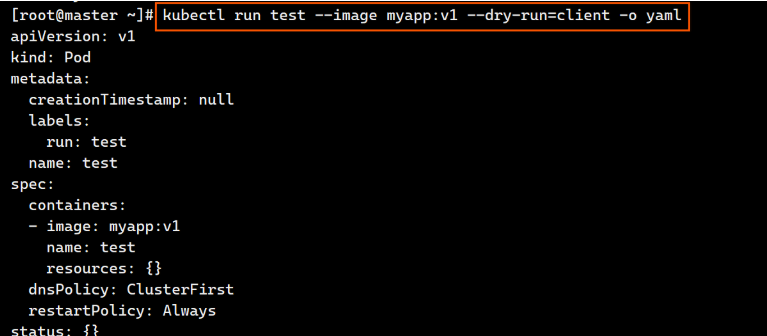
bash
[root@master ~]# kubectl run test --image myapp:v1 --dry-run=client -o yaml > yaml
[root@master ~]# vim test.yaml 
**最简单的1个pod运行一个容器: ** 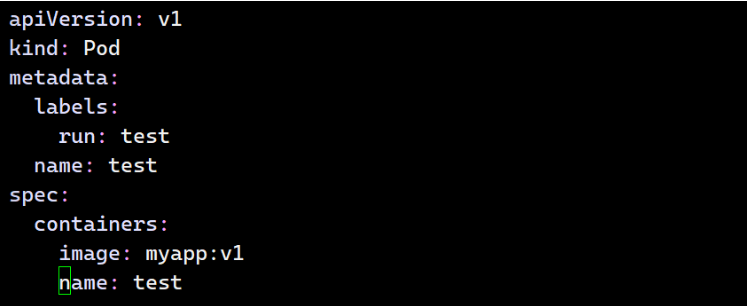
1个pod运行多个容器:
bash
[root@master ~]# vim test.yaml
apiVersion: v1
kind: Pod
metadata:
name: test
labels:
run: test
spec:
containers:
- name: test
image: myapp:v1
- name: test1
image: busyboxplus
command:
- /bin/sh
- -c
- sleep 100000
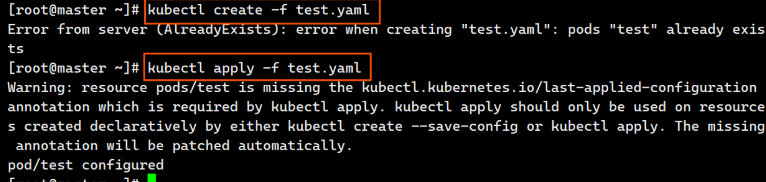
[root@master ~]# kubectl create -f test.yaml
pod/test created
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 2/2 Running 0 92s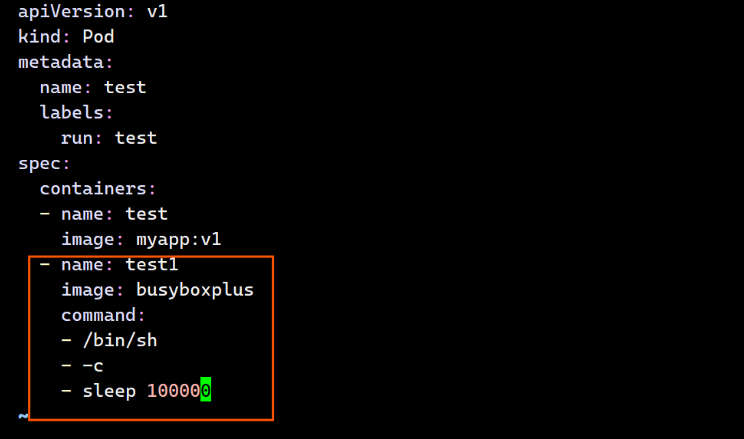

**声明式: ** 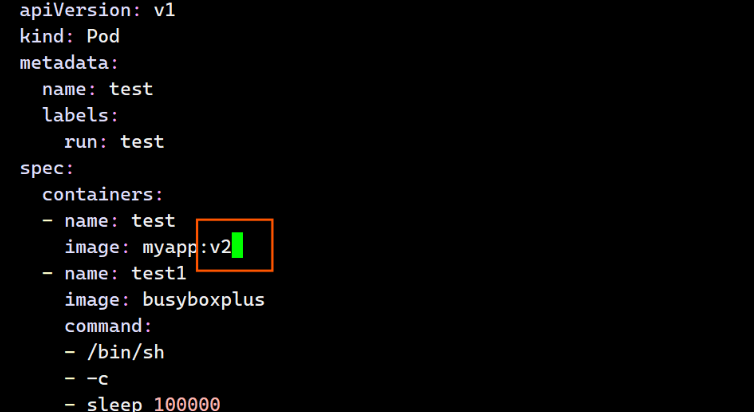


| 命令式对象管理 | 测试 | 简单 | 只能操作活动对象,无法审计、跟踪 |
|---|---|---|---|
| 命令式对象配置 | 开发 | 可以审计、跟踪 | 项目大时,配置文件多,操作麻烦 |
| 类型 | 适用环境 | 优点 | 缺点 |
| 声明式对象配置 | 开发 | 支持目录操作 | 意外情况下难以调试 |
a. 命令式对象管理
kubectl是kubernetes集群的命令行工具,通过它能够对集群本身进行管理,并能够在集群上进行容器化应用的安装部署
kubectl命令的语法如下:
kubectl [command] [type] [name] [flags]comand:指定要对资源执行的操作,例如create、get、delete、apply
type:指定资源类型,比如deployment、pod、service
name:指定资源的名称,名称大小写敏感
flags:指定额外的可选参数
bash
# 查看所有pod
kubectl get pod
# 查看某个pod
kubectl get pod pod_name
# 查看某个pod,以yaml格式展示结果
kubectl get pod pod_name -o yamlb.资源类型
kubernetes中所有的内容都抽象为资源 kubectl api-resources
常用资源类型
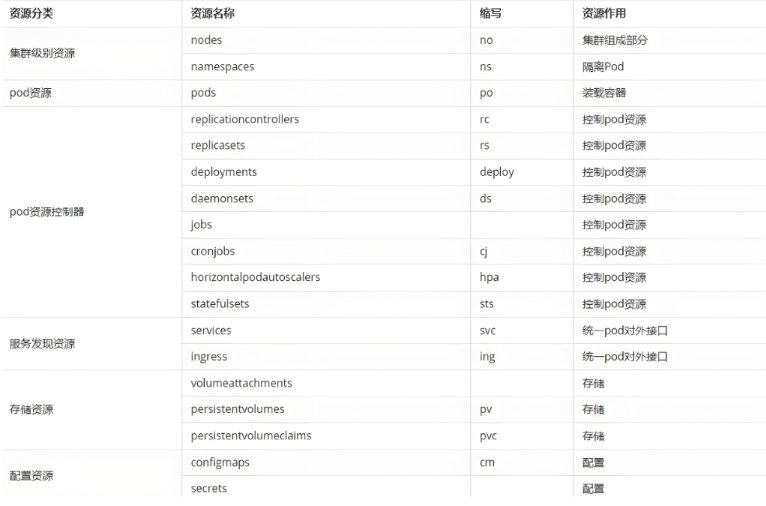
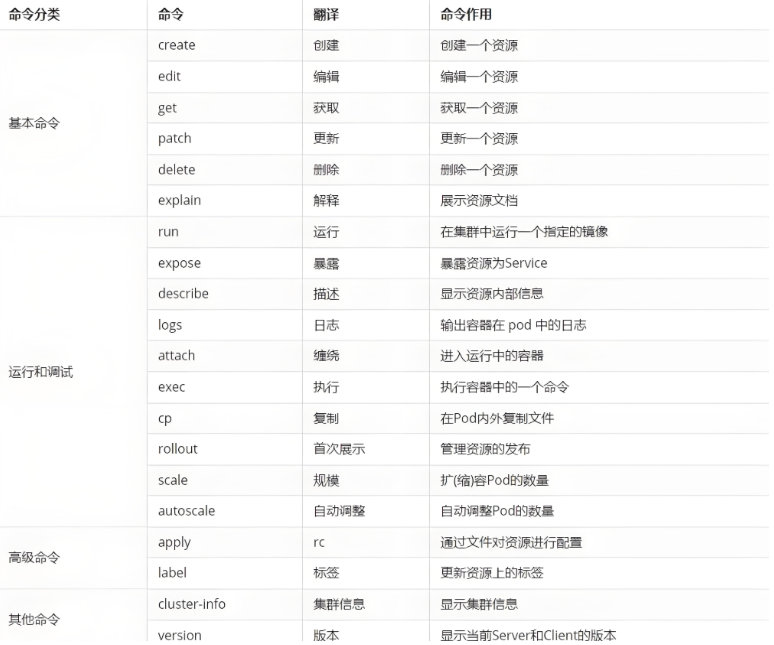
kubect 常见命令操作:
四、pod
-
Pod是可以创建和管理Kubernetes计算的最小可部署单元
-
一个Pod代表着集群中运行的一个进程,每个pod都有一个唯一的ip。
-
一个pod类似一个豌豆荚,包含一个或多个容器(通常是docker)
-
多个容器间共享IPC、Network和UTC namespace。

1. 创建自主式pod (生产不推荐)
优点:
灵活性高:
- 可以精确控制 Pod 的各种配置参数,包括容器的镜像、资源限制、环境变量、命令和参数等,满足特定的应用需求。
学习和调试方便:
- 对于学习 Kubernetes 的原理和机制非常有帮助,通过手动创建 Pod 可以深入了解 Pod 的结构和配置方式。在调试问题时,可以更直接地观察和调整 Pod 的设置。
适用于特殊场景:
- 在一些特殊情况下,如进行一次性任务、快速验证概念或在资源受限的环境中进行特定配置时,手动创建 Pod 可能是一种有效的方式。
缺点:
管理复杂:
- 如果需要管理大量的 Pod,手动创建和维护会变得非常繁琐和耗时。难以实现自动化的扩缩容、故障恢复等操作。
缺乏高级功能:
- 无法自动享受 Kubernetes 提供的高级功能,如自动部署、滚动更新、服务发现等。这可能导致应用的部署和管理效率低下。
可维护性差:
- 手动创建的 Pod 在更新应用版本或修改配置时需要手动干预,容易出现错误,并且难以保证一致性。相比之下,通过声明式配置或使用 Kubernetes 的部署工具可以更方便地进行应用的维护和更新。
bash
#查看所有pods
[root@master ~]# kubectl get pods
bash
#建立一个名为timinglee的pod
[root@master ~]# kubectl run timinglee --image nginx
bash
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee 1/1 Running 0 6s
bash
#显示pod的较为详细的信息
[root@master ~]# kubectl get pods -o wide
2.利用控制器管理pod(推荐)
高可用性和可靠性:
-
自动故障恢复:如果一个 Pod 失败或被删除,控制器会自动创建新的 Pod 来维持期望的副本数量。确保应用始终处于可用状态,减少因单个 Pod 故障导致的服务中断。
-
健康检查和自愈:可以配置控制器对 Pod 进行健康检查(如存活探针和就绪探针)。如果 Pod 不健康,控制器会采取适当的行动,如重启 Pod 或删除并重新创建它,以保证应用的正常运行。
可扩展性:
-
轻松扩缩容:可以通过简单的命令或配置更改来增加或减少 Pod 的数量,以满足不同的工作负载需求。例如,在高流量期间可以快速扩展以处理更多请求,在低流量期间可以缩容以节省资源。
-
水平自动扩缩容(HPA):可以基于自定义指标(如 CPU 利用率、内存使用情况或应用特定的指标)自动调整 Pod 的数量,实现动态的资源分配和成本优化。
版本管理和更新:
-
滚动更新:对于 Deployment 等控制器,可以执行滚动更新来逐步替换旧版本的 Pod 为新版本,确保应用在更新过程中始终保持可用。可以控制更新的速率和策略,以减少对用户的影响。
-
回滚:如果更新出现问题,可以轻松回滚到上一个稳定版本,保证应用的稳定性和可靠性。
声明式配置:
-
简洁的配置方式:使用 YAML 或 JSON 格式的声明式配置文件来定义应用的部署需求。这种方式使得配置易于理解、维护和版本控制,同时也方便团队协作。
-
期望状态管理:只需要定义应用的期望状态(如副本数量、容器镜像等),控制器会自动调整实际状态与期望状态保持一致。无需手动管理每个 Pod 的创建和删除,提高了管理效率。
服务发现和负载均衡:
-
自动注册和发现:Kubernetes 中的服务(Service)可以自动发现由控制器管理的 Pod,并将流量路由到它们。这使得应用的服务发现和负载均衡变得简单和可靠,无需手动配置负载均衡器。
-
流量分发:可以根据不同的策略(如轮询、随机等)将请求分发到不同的 Pod,提高应用的性能和可用性。
多环境一致性:
- 一致的部署方式:在不同的环境(如开发、测试、生产)中,可以使用相同的控制器和配置来部署应用,确保应用在不同环境中的行为一致。这有助于减少部署差异和错误,提高开发和运维效率。
示例:
bash
#建立控制器并自动运行pod
[root@master ~]# kubectl create deployment timinglee --image nginx
[root@master ~]# kubectl get pods
bash
#为timinglee扩容
[root@master ~]# kubectl scale deployment timinglee --replicas 6
deployment.apps/timinglee scaled
[root@master ~]# kubectl get pods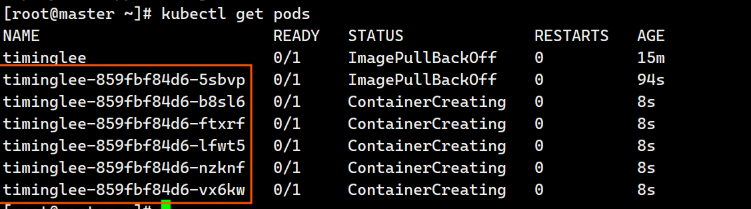
bash
#为timinglee缩容
root@master ~]# kubectl scale deployment timinglee --replicas 2
deployment.apps/timinglee scaled
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
timinglee-859fbf84d6-mrjvx 1/1 Running 0 38m
timinglee-859fbf84d6-tsn97 1/1 Running 0 73s
3. 应用版本的更新
bash
#利用控制器建立pod
[root@master ~]# kubectl create deployment timinglee --image myapp:v1 --replicas 2
deployment.apps/timinglee created
bash
#暴漏端口
[root@master ~]# kubectl expose deployment timinglee --port 80 --target-port 80
service/timinglee exposed
bash
[root@master ~]# kubectl get services
bash
[root@master ~]# curl 10.108.49.159
bash
#产看历史版本
[root@master ~]# kubectl rollout history deployment timinglee
bash
#更新控制器镜像版本
[root@master ~]# kubectl set image deployments/timinglee myapp=myapp:v2
bash
#查看历史版本
[root@master ~]# kubectl rollout history deployment timinglee
bash
#访问内容测试
[root@master ~]# curl 10.108.49.159
bash
#版本回滚
[root@master ~]# kubectl rollout undo deployment timinglee --to-revision 1
deployment.apps/timinglee rolled back
[root@master ~]# curl 10.110.195.120
4. 利用yaml文件部署应用
a.用yaml文件部署应用有以下优点
声明式配置:
-
清晰表达期望状态:以声明式的方式描述应用的部署需求,包括副本数量、容器配置、网络设置等。这使得配置易于理解和维护,并且可以方便地查看应用的预期状态。
-
可重复性和版本控制:配置文件可以被版本控制,确保在不同环境中的部署一致性。可以轻松回滚到以前的版本或在不同环境中重复使用相同的配置。
-
团队协作:便于团队成员之间共享和协作,大家可以对配置文件进行审查和修改,提高部署的可靠性和稳定性。
灵活性和可扩展性:
-
丰富的配置选项:可以通过 YAML 文件详细地配置各种 Kubernetes 资源,如 Deployment、Service、ConfigMap、Secret 等。可以根据应用的特定需求进行高度定制化。
-
组合和扩展:可以将多个资源的配置组合在一个或多个 YAML 文件中,实现复杂的应用部署架构。同时,可以轻松地添加新的资源或修改现有资源以满足不断变化的需求。
与工具集成:
-
与 CI/CD 流程集成:可以将 YAML 配置文件与持续集成和持续部署(CI/CD)工具集成,实现自动化的应用部署。例如,可以在代码提交后自动触发部署流程,使用配置文件来部署应用到不同的环境。
-
命令行工具支持:Kubernetes 的命令行工具
kubectl对 YAML 配置文件有很好的支持,可以方便地应用、更新和删除配置。同时,还可以使用其他工具来验证和分析 YAML 配置文件,确保其正确性和安全性。
b.编写示例
-- 示例1:运行简单的单个容器po
bash
[root@master ~]# kubectl run timinglee --image myapp:v1 --dry-run=client -o yaml > pod.yml
bash
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timing #pod标签
name: timinglee #pod名称
spec:
containers:
- image: myapp:v1 #pod镜像
name: timinglee #容器名称-- 示例2:运行多个容器pod
容器时一定要确保容器彼此不能互相干扰
bash
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: timinglee
spec:
containers:
- image: myapp:v1
name: web1
- image: busyboxplus:latest
name: busyboxplus
command: ["/bin/sh","-c","sleep 1000000"]
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/timinglee created
[root@k8s-master ~]# kubectl get pods
--示例3:理解pod间的网络整合
同在一个pod中的容器公用一个网络
bash
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: test
spec:
containers:
- image: myapp:v1
name: myapp1
- image: busyboxplus:latest
name: busyboxplus
command: ["/bin/sh","-c","sleep 1000000"]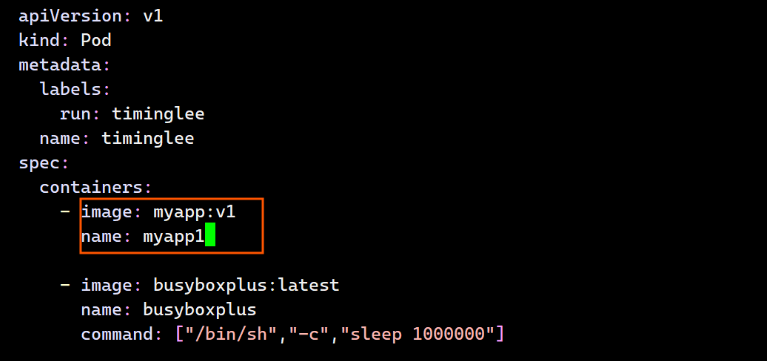
bash
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
test 2/2 Running 0 8s
[root@master ~]# curl 10.244.2.11 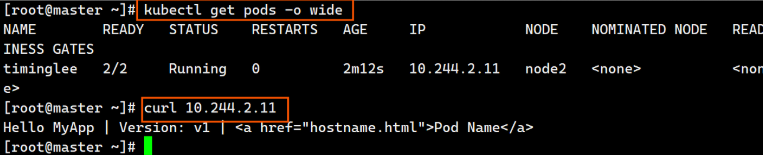
--示例4:端口映射
bash
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: timinglee
name: timinglee
spec:
containers:
- image: myapp:v1
name: myapp1
ports:
- name: http
containerPort: 80
hostPort: 80
protocol: TCP
#测试
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
timinglee 1/1 Running 0 6s 10.244.2.12 node2 <none> <none>
[root@master ~]# curl node2
Hello MyApp | Version: v1 | <a href="hostname.html">Pod Name</a>
--示例5:如何设定环境变量
bash
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
containers:
- image: busyboxplus
name: testpod
command: ["/bin/sh","-c","touch /$NAME;sleep 3000000"]
env:
- name: NAME
value: timinglee
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@master ~]# kubectl exec pods/testpod -c testpod -- ls /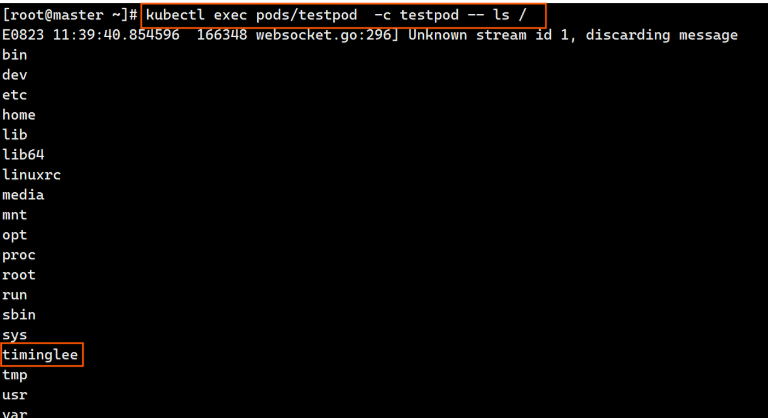
--示例6:资源限制
!NOTE
资源限制会影响pod的Qos Class资源优先级,资源优先级分为Guaranteed > Burstable > BestEffort
QoS(Quality of Service)即服务质量
资源设定 优先级类型 资源限定未设定 BestEffort 资源限定设定且最大和最小不一致 Burstable 资源限定设定且最大和最小一致(cpu和内存设定一致) Guaranteed
资源限定设定且最大和最小不一致:
bash
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
containers:
- name: testpod
image: myapp:v1
resources:
requests: #pod期望使用资源量,不能大于limits
cpu: 200m
limits: #pod使用资源的最高限制
cpu: 500m
bash
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@master ~]# kubectl get pods
[root@master ~]# kubectl describe pods test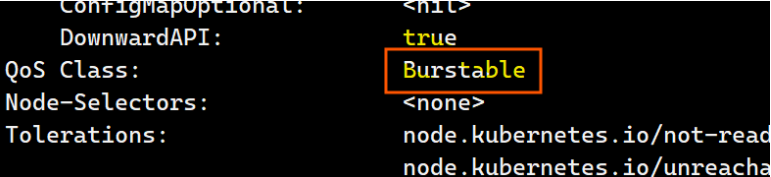
资源限定设定且最大和最小一致:
bash
[root@master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
containers:
- name: testpod
image: myapp:v1
resources:
requests:
cpu: 500m
memory: 200Mi
limits:
cpu: 500m
memory: 200Mi
[root@master ~]# kubectl apply -f pod.yml
pod/testpod created
[root@master ~]# kubectl describe pods test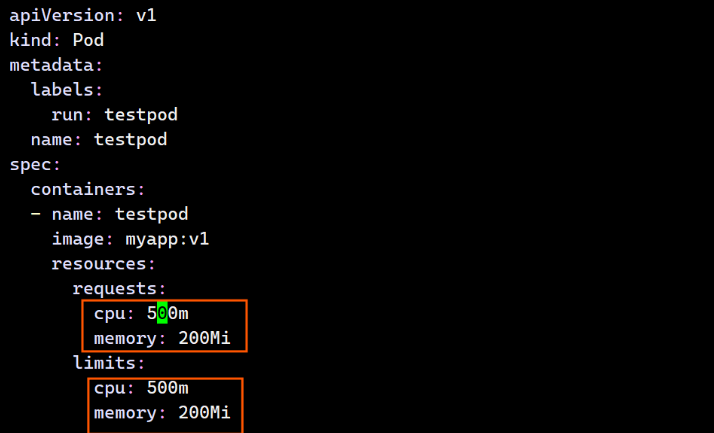

--示例7 容器启动管理
bash
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
containers:
- name: testpod
image: myapp:v1
resources:
requests:
cpu: 500m
memory: 200Mi
limits:
cpu: 500m
memory: 200Mi
restartPolicy: Always #(默认)
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
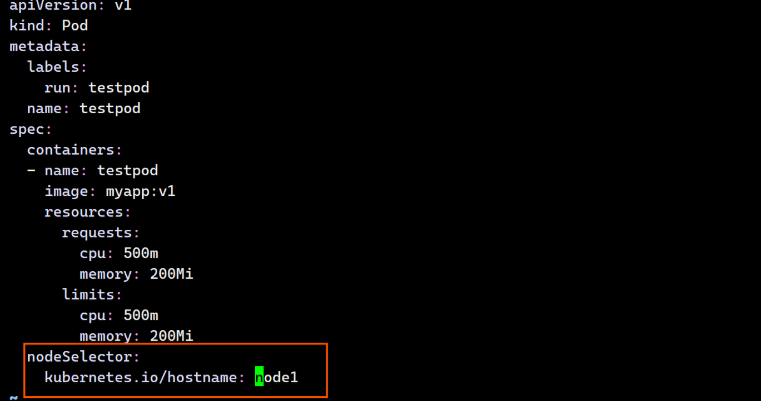
test 1/1 Running 0 6s 10.244.2.3 k8s-node2 <none> <none>-- 示例8 选择运行节点
bash
[root@k8s-master ~]# vim pod.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: testpod
name: testpod
spec:
containers:
- name: testpod
image: myapp:v1
resources:
requests:
cpu: 500m
memory: 200Mi
limits:
cpu: 500m
memory: 200Mi
nodeSelector:
kubernetes.io/hostname: node1
[root@k8s-master ~]# kubectl apply -f pod.yml
pod/test created
[root@k8s-master ~]# kubectl get pods -o wide

五、pod的生命周期
1.INIT 容器
官方文档:Pod | Kubernetes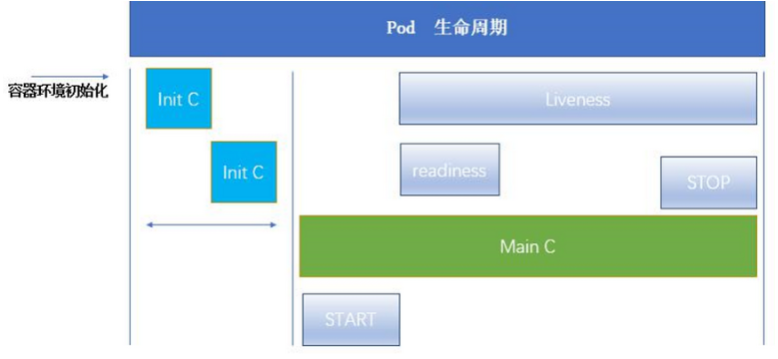
-
Pod 可以包含多个容器,应用运行在这些容器里面,同时 Pod 也可以有一个或多个先于应用容器启动的 Init 容器。
-
Init 容器与普通的容器非常像,除了如下两点:
-
它们总是运行到完成
-
init 容器不支持 Readiness,因为它们必须在 Pod 就绪之前运行完成,每个 Init 容器必须运行成功,下一个才能够运行。
-
-
如果Pod的 Init 容器失败,Kubernetes 会不断地重启该 Pod,直到 Init 容器成功为止。但是,如果 Pod 对应的 restartPolicy 值为 Never,它不会重新启动
a.INIT 容器的功能
-
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。
-
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
-
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
-
Init 容器能以不同于Pod内应用容器的文件系统视图运行。因此,Init容器可具有访问 Secrets 的权限,而应用容器不能够访问。
-
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。一旦前置条件满足,Pod内的所有的应用容器会并行启动。
b. INIT 容器示例
检查状态:

bash
[root@master ~]# mkdir pod
[root@master ~]# cd pod/
[root@master pod]# kubectl run init-example --image myapp:v1 --dry-run=client -o yaml > init-example.yml
[root@master pod]# vim init-example.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: init-example
name: init-example
spec:
containers:
- image: myapp:v1
name: init-example
initContainers:
- name: init-myservice
image: busybox
command: ["sh","-c","until test -e /testfile;do echo wating for myservice; sleep 2;done"]
[root@master pod]# watch -n 1 kubectl get pods -o wide
[root@master pod]# kubectl apply -f init-example.yml
pod/init-example created
[root@master pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-myservice 0/1 Init:0/1 0 3s
bash
[root@master ~]# kubectl logs pods/init-myservice init-myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
wating for myservice
[root@master ~]# kubectl exec pods/init-myservice -c init-myservice -- /bin/sh -c "touch /testfile"
[root@master ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
init-myservice 1/1 Running 0 62s2.探针
探针是由 kubelet 对容器执行的定期诊断:
-
ExecAction:在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。
-
TCPSocketAction:对指定端口上的容器的 IP 地址进行 TCP 检查。如果端口打开,则诊断被认为是成功的。
-
HTTPGetAction:对指定的端口和路径上的容器的 IP 地址执行 HTTP Get 请求。如果响应的状态码大于等于200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
-
成功:容器通过了诊断。
-
失败:容器未通过诊断。
-
未知:诊断失败,因此不会采取任何行动。
Kubelet 可以选择是否执行在容器上运行的三种探针执行和做出反应:
-
livenessProbe:指示容器是否正在运行。如果存活探测失败,则 kubelet 会杀死容器,并且容器将受到其重启策略的影响。如果容器不提供存活探针,则默认状态为 Success。
-
readinessProbe:指示容器是否准备好服务请求。如果就绪探测失败,端点控制器将从与 Pod 匹配的所有 Service 的端点中删除该 Pod 的 IP 地址。初始延迟之前的就绪状态默认为 Failure。如果容器不提供就绪探针,则默认状态为 Success。
-
startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探测(startup probe),则禁用所有其他探测,直到它成功为止。如果启动探测失败,kubelet 将杀死容器,容器服从其重启策略进行重启。如果容器没有提供启动探测,则默认状态为成功Success。
ReadinessProbe 与 LivenessProbe 的区别
-
ReadinessProbe 当检测失败后,将 Pod 的 IP:Port 从对应的 EndPoint 列表中删除。
-
LivenessProbe 当检测失败后,将杀死容器并根据 Pod 的重启策略来决定作出对应的措施
StartupProbe 与 ReadinessProbe、LivenessProbe 的区别
-
如果三个探针同时存在,先执行 StartupProbe 探针,其他两个探针将会被暂时禁用,直到 pod 满足 StartupProbe 探针配置的条件,其他 2 个探针启动,如果不满足按照规则重启容器。
-
另外两种探针在容器启动后,会按照配置,直到容器消亡才停止探测,而 StartupProbe 探针只是在容器启动后按照配置满足一次后,不在进行后续的探测。
a. 探针实例
--存活探针示例:
bash
[root@master pod]# vim live-example.yml
apiVersion: v1
kind: Pod
metadata:
labels:
run: live-example
name: live-example
spec:
containers:
- image: myapp:v1
name: live-example
livenessProbe:
tcpSocket: #检测端口存在性
port: 8080
initialDelaySeconds: 3 #容器启动后要等待多少秒后就探针开始工作,默认是 0
periodSeconds: 1 #执行探测的时间间隔,默认为 10s
timeoutSeconds: 1 #探针执行检测请求后,等待响应的超时时间,默认为 1s
#测试:
[root@master pod]# kubectl apply -f live-example.yml
pod/live-example created
bash
[root@master pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
live-example 0/1 CrashLoopBackOff 5 (15s ago) 108s
[root@k8s-master ~]# kubectl describe pods
Warning Unhealthy 3m4s (x9 over 3m18s) kubelet Liveness probe failed: dial tcp 10.244.2.17:8080: connect: connection refused
改成80端口:
bash
[root@master pod]# kubectl describe pods
-- 就绪探针示例:
bash
[root@master pod]# vim readness-example.yml
apiVersion: v1
kind: Pod
run: readness-example
periodSeconds: 3
periodSeconds: 3
run: readness-example
periodSeconds: 3
periodSeconds: 3
spec:
containers:
- image: myapp:v1
name: readness-example
readinessProbe:
httpGet:
path: /test.html
port: 80
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 1
[root@master pod]# kubectl apply -f readness-example.yml
pod/readness-example created
#测试:
[root@master pod]# kubectl expose pod readness-example --port 80 --target-port 80
service/readness-example exposed
[root@master pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readness-example 0/1 Running 0 3m2s
[root@master pod]# kubectl describe pods readness-example
Warning Unhealthy 50s (x22 over 112s) kubelet Readiness probe failed: HTTP probe failed with statuscode: 404


bash
[root@k8s-master ~]# kubectl describe services readness-example
Name: readness-example
Namespace: default
Labels: run=readness-example
Annotations: <none>
Selector: run=readness-example
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.110.4.19
IPs: 10.110.4.19
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: #没有暴漏端口,就绪探针探测不满足暴漏条件
Session Affinity: None
Events: <none>
[root@master pod]# kubectl exec pods/readness-example -c readness-example -- /bin/sh -c "echo test > /usr/share/nginx/html/test.html"
[root@master pod]# kubectl get pods
NAME READY STATUS RESTARTS AGE
readness-example 1/1 Running 0 12m
[root@master pod]# kubectl describe services readness-example
Name: readness-example
Namespace: default
Labels: run=readness-example
Annotations: <none>
Selector: run=readness-example
Type: ClusterIP
IP Family Policy: SingleStack
IP Families: IPv4
IP: 10.110.4.19
IPs: 10.110.4.19
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.2.18:80 #满组条件端口暴漏
Session Affinity: None
Events: <none>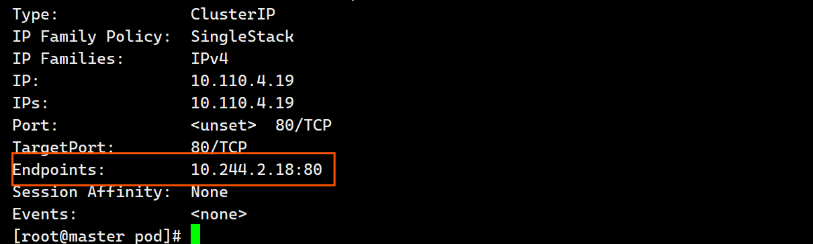
六、什么是控制器
官方文档:
控制器也是管理pod的一种手段
-
自主式pod:pod退出或意外关闭后不会被重新创建
-
控制器管理的 Pod:在控制器的生命周期里,始终要维持 Pod 的副本数目
Pod控制器是管理pod的中间层,使用Pod控制器之后,只需要告诉Pod控制器,想要多少个什么样的Pod就可以了,它会创建出满足条件的Pod并确保每一个Pod资源处于用户期望的目标状态。如果Pod资源在运行中出现故障,它会基于指定策略重新编排Pod
当建立控制器后,会把期望值写入etcd,k8s中的apiserver检索etcd中我们保存的期望状态,并对比pod的当前状态,如果出现差异代码自驱动立即恢复
1. 控制器常用类型
| 控制器名称 | 控制器用途 |
|---|---|
| Replication Controller | 比较原始的pod控制器,已经被废弃,由ReplicaSet替代 |
| ReplicaSet | ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行 |
| Deployment | 一个 Deployment 为 Pod 和 ReplicaSet 提供声明式的更新能力 |
| DaemonSet | DaemonSet 确保全指定节点上运行一个 Pod 的副本 |
| StatefulSet | StatefulSet 是用来管理有状态应用的工作负载 API 对象。 |
| Job | 执行批处理任务,仅执行一次任务,保证任务的一个或多个Pod成功结束 |
| CronJob | Cron Job 创建基于时间调度的 Jobs。 |
| HPA全称Horizontal Pod Autoscaler | 根据资源利用率自动调整service中Pod数量,实现Pod水平自动缩放 |
2. replicaset控制器
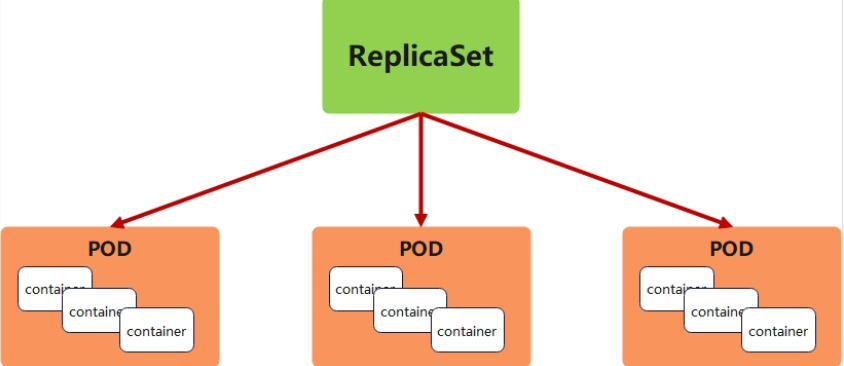
a. 功能
-
ReplicaSet 是下一代的 Replication Controller,官方推荐使用ReplicaSet
-
ReplicaSet和Replication Controller的唯一区别是选择器的支持,ReplicaSet支持新的基于集合的选择器需求
-
ReplicaSet 确保任何时间都有指定数量的 Pod 副本在运行
-
虽然 ReplicaSets 可以独立使用,但今天它主要被Deployments 用作协调 Pod 创建、删除和更新的机制
b. 参数说明
| 参数名称 | 字段类型 | 参数说明 |
|---|---|---|
| spec | Object | 详细定义对象,固定值就写Spec |
| spec.replicas | integer | 指定维护pod数量 |
| spec.selector | Object | Selector是对pod的标签查询,与pod数量匹配 |
| spec.selector.matchLabels | string | 指定Selector查询标签的名称和值,以key:value方式指定 |
| spec.template | Object | 指定对pod的描述信息,比如lab标签,运行容器的信息等 |
| spec.template.metadata | Object | 指定pod属性 |
| spec.template.metadata.labels | string | 指定pod标签 |
| spec.template.spec | Object | 详细定义对象 |
| spec.template.spec.containers | list | Spec对象的容器列表定义 |
| spec.template.spec.containers.name | string | 指定容器名称 |
| spec.template.spec.containers.image | string | 指定容器镜像 |
c.示例
bash
[root@master ~]# mkdir control
[root@master ~]# cd control/
#生成yml文件
[root@master control]# kubectl create deployment replicaset --image myapp:v1 --dry-run=client -o yaml > replicaset.yml
bash
[root@master control]# vim replicaset.yml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
labels:
app: replicaset
name: replicaset #指定pod名称,一定小写,如果出现大写报错
spec:
replicas: 2 #指定维护pod数量为2
selector: #指定检测匹配方式
matchLabels: #指定匹配方式为匹配标签
app: replicaset #指定匹配的标签为app=replicaset
template: #模板,当副本数量不足时,会根据下面的模板创建pod副本
metadata:
labels:
app: replicaset
spec:
containers:
- image: myapp:v1
name: myapp
[root@master control]# kubectl apply -f replicaset.yml
replicaset.apps/replicaset created
[root@master control]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-6xkz5 1/1 Running 0 113s app=replicaset
replicaset-vdd69 1/1 Running 0 113s app=replicaset
bash
#replicaset是通过标签匹配pod
[root@master control]# kubectl label pod replicaset-vdd69 app=timinglee --overwrite
pod/replicaset-vdd69 labeled
[root@k8s-master ~]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-4l8rr 1/1 Running 0 93s app=replicaset #新开启的pod
replicaset-6xkz5 1/1 Running 0 6m52s app=replicaset
replicaset-vdd69 1/1 Running 0 6m52s app=timinglee
bash
#恢复标签后
[root@master control]# kubectl label pod replicaset-vdd69 app=replicaset --overwrite
pod/replicaset-vdd69 labeled
[root@master control]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
replicaset-6xkz5 1/1 Running 0 11m app=replicaset
replicaset-vdd69 1/1 Running 0 11m app=replicaset
回收资源
[root@k8s2 pod]# kubectl delete -f rs-example.yml
3.deployment 控制器
a.功能
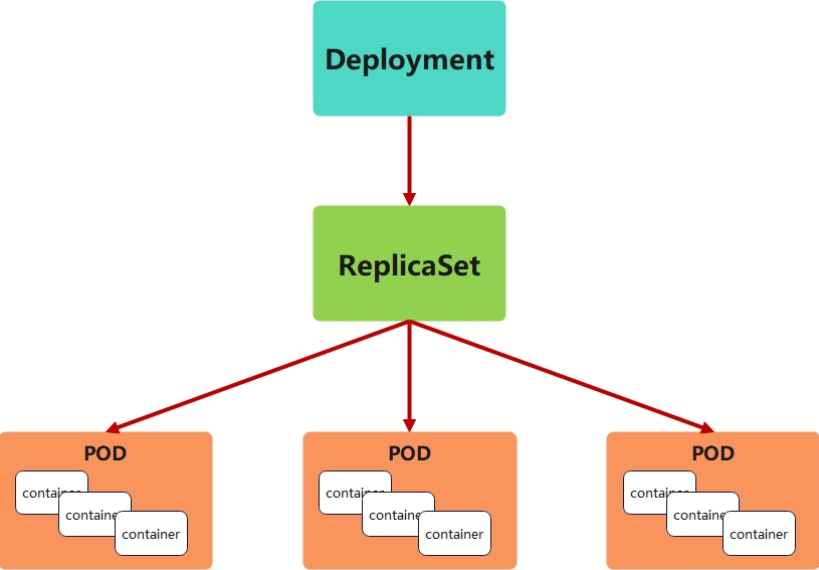
-
为了更好的解决服务编排的问题,kubernetes在V1.2版本开始,引入了Deployment控制器。
-
Deployment控制器并不直接管理pod,而是通过管理ReplicaSet来间接管理Pod
-
Deployment管理ReplicaSet,ReplicaSet管理Pod
-
Deployment 为 Pod 和 ReplicaSet 提供了一个申明式的定义方法
-
在Deployment中ReplicaSet相当于一个版本
典型的应用场景:
-
用来创建Pod和ReplicaSet
-
滚动更新和回滚
-
扩容和缩容
-
暂停与恢复
b. 示例
bash
#生成yaml文件
[root@master control]# kubectl create deployment deployment --image myapp:v1 --dry-run=client -o yaml > deployment.yml
[root@master control]# vim deployment.yml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deployment
spec:
replicas: 4
selector:
matchLabels:
app: myapp
template:
metadata:
labels:
app: myapp
spec:
containers:
- image: myapp:v1
name: myapp
[root@master control]# kubectl apply -f deployment.yml
deployment.apps/deployment created
#查看pod信息
[root@master control]# kubectl get pods --show-labels
NAME READY STATUS RESTARTS AGE LABELS
deployment-5d886954d4-7sqwf 1/1 Running 0 2m20s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-dsdtv 1/1 Running 0 2m20s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-g9zfv 1/1 Running 0 2m20s app=myapp,pod-template-hash=5d886954d4
deployment-5d886954d4-mp9sc 1/1 Running 0 2m20s app=myapp,pod-template-hash=5d886954d4
replicaset-bqbpq 1/1 Running 0 30s app=replicaset
replicaset-pqghw 1/1 Running 0 70s app=replicaset
4.daemonset控制器
a.功能
DaemonSet 确保全部(或者某些)节点上运行一个 Pod 的副本。当有节点加入集群时, 也会为他们新增一个 Pod ,当有节点从集群移除时,这些 Pod 也会被回收。删除 DaemonSet 将会删除它创建的所有 Pod
DaemonSet 的典型用法:
-
在每个节点上运行集群存储 DaemonSet,例如 glusterd、ceph。
-
在每个节点上运行日志收集 DaemonSet,例如 fluentd、logstash。
-
在每个节点上运行监控 DaemonSet,例如 Prometheus Node Exporter、zabbix agent等
-
一个简单的用法是在所有的节点上都启动一个 DaemonSet,将被作为每种类型的 daemon 使用
-
一个稍微复杂的用法是单独对每种 daemon 类型使用多个 DaemonSet,但具有不同的标志, 并且对不同硬件类型具有不同的内存、CPU 要求
5. job 控制器
a.功能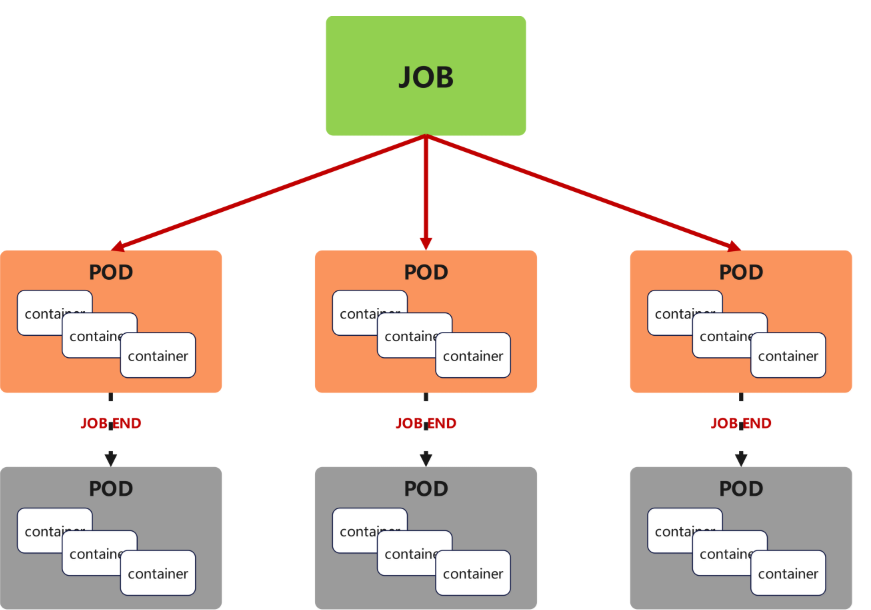
Job,主要用于负责批量处理(一次要处理指定数量任务)短暂的一次性(每个任务仅运行一次就结束)任务
Job特点如下:
-
当Job创建的pod执行成功结束时,Job将记录成功结束的pod数量
-
当成功结束的pod达到指定的数量时,Job将完成执行
6. cronjob 控制器
a.功能
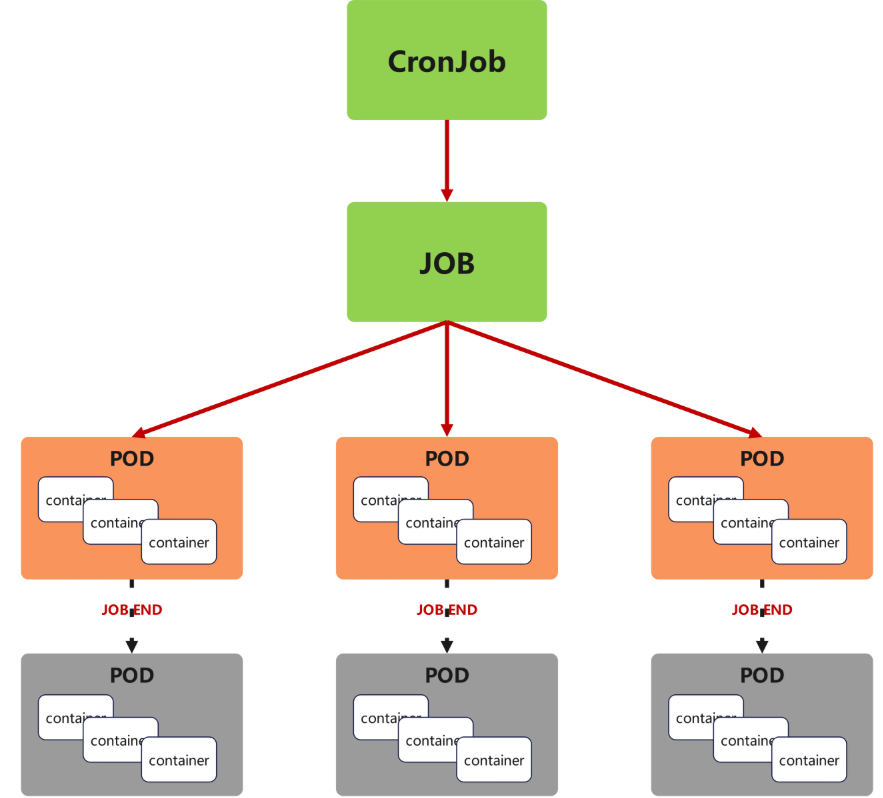
-
Cron Job 创建基于时间调度的 Jobs。
-
CronJob控制器以Job控制器资源为其管控对象,并借助它管理pod资源对象,
-
CronJob可以以类似于Linux操作系统的周期性任务作业计划的方式控制其运行时间点及重复运行的方式。
-
CronJob可以在特定的时间点(反复的)去运行job任务。