Milvus:高性能云原生向量数据库

什么是 Milvus?
🐦 Milvus 是一个为大规模向量近似最近邻(ANN)检索而构建的高性能向量数据库。它能够有效地组织和搜索大量的非结构化数据,包括文本、图像和多模态信息,是连接AI应用和数据的重要桥梁。
Milvus采用编写于Go和C++的代码构造,并实现了CPU/GPU硬件加速,达到业界领先的向量搜索性能。由于具备全分布式 和K8s原生架构 ,Milvus不仅支持横向扩展,可以处理成千上万的搜索查询,还可以确保数据实时更新,保持数据的最新状态。此外,Milvus还支持Standalone模式,适合单机部署。而Milvus Lite是一个轻量级版本,特别适合Python用户进行快速入门。
想要零配置使用Milvus?可以尝试使用Zilliz Cloud ☁️免费体验。Milvus在Zilliz Cloud中作为完全托管的服务提供,包括无服务器、专享和自带云选项。
快速开始
要开始使用Milvus,您可以通过以下方式快速入门:
python
$ pip install -U pymilvus安装完pymilvus后,您就可以创建一个Milvus客户端:
python
from pymilvus import MilvusClientMilvus Lite同样包括在内,只需实例化一个客户端并指定本地文件名称以便持久化数据:
python
client = MilvusClient("milvus_demo.db")如果您希望连接部署在Milvus服务器或Zilliz Cloud,可以使用以下代码:
python
client = MilvusClient(
uri="",
token="")通过这个客户端,您可以创建集合:
python
client.create_collection(
collection_name="demo_collection",
dimension=768, # 此示例中的向量维度为768
)接下来,您可以插入数据:
python
res = client.insert(collection_name="demo_collection", data=data)最后执行向量搜索:
python
query_vectors = embedding_fn.encode_queries(["Who is Alan Turing?", "What is AI?"])
res = client.search(
collection_name="demo_collection", # 目标集合
data=query_vectors, # 一个或多个查询向量的列表,支持批量
limit=2, # 返回结果的数量(topK)
output_fields=["vector", "text", "subject"], # 返回的字段
)为什么选择 Milvus?
Milvus专为处理大规模的向量搜索而设计。它能够存储向量(非结构化数据的学习表示),同时支持多种标量数据(如整数、字符串和JSON对象)。用户可以通过元数据过滤或混合搜索进行高效的向量检索。以下是开发人员选择Milvus作为AI应用向量数据库的原因:
高性能与高可用性
- Milvus具有分布式架构,将计算与存储分离。通过横向扩展,Milvus可以适应不同的流量模式,独立增加查询节点以应对读重 workloads,并增加数据节点以处理写重 workloads。K8s上的无状态微服务实现了快速恢复,确保高可用性。同时,支持副本,进一步增强容错能力和吞吐量。
多种向量索引类型和硬件加速支持
- Milvus分离了系统和核心向量搜索引擎,支持针对不同场景优化的主要向量索引类型,包括HNSW、IVF、FLAT(暴力搜索)、SCANN和DiskANN等,提供量化或内存映射的变体。Milvus优化向量搜索以支持高级功能,如元数据过滤和范围搜索。
灵活的多租户和冷热存储
- Milvus支持通过数据库、集合、分区或分区键级别隔离实现的多租户。这些策略使得单个集群可以处理从数百到数百万的租户,确保优化搜索性能和灵活的访问控制。
稀疏向量以实现全文搜索和混合搜索
- 除了通过稠密向量进行语义搜索,Milvus还原生支持使用BM25的全文搜索,以及诸如SPLADE和BGE-M3的学习稀疏嵌入。用户可以在同一集合中存储稀疏向量和稠密向量,并定义函数以重新排序来自多个搜索请求的结果。
数据安全和细粒度访问控制
- Milvus通过实施强制用户身份验证、TLS加密和基于角色的访问控制(RBAC)确保数据安全。用户认证确保只有持有有效凭证的用户才能访问数据库,而TLS加密则保障网络内所有通信的安全。此外,RBAC允许为用户分配特定权限以实现精细的访问控制。这些功能使Milvus成为企业应用的强大且安全的选择,保护敏感数据不被未授权访问和潜在泄露。
Milvus广受AI开发者信赖,用于构建各种应用程序,如文本与图像搜索、增强检索生成(RAG)和推荐系统。
演示和教程
Milvus提供多种演示和教程,帮助您使用Milvus构建各种类型的AI应用:
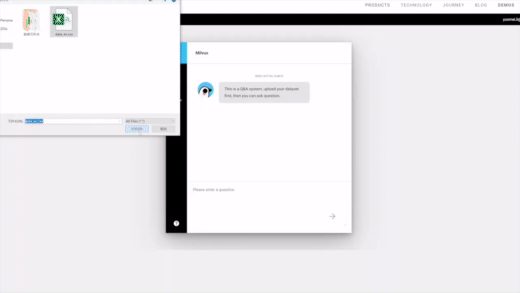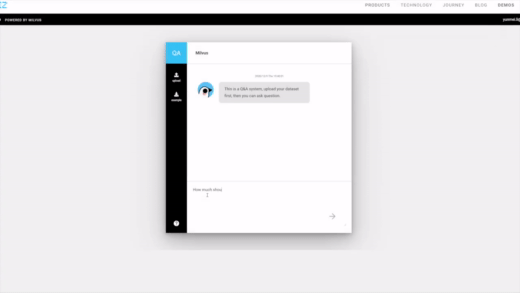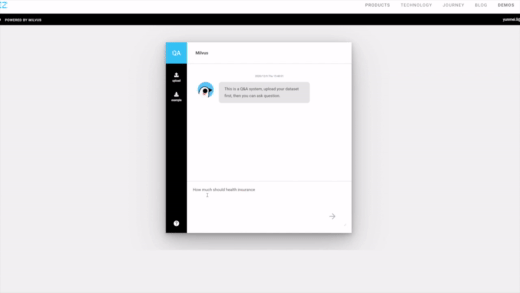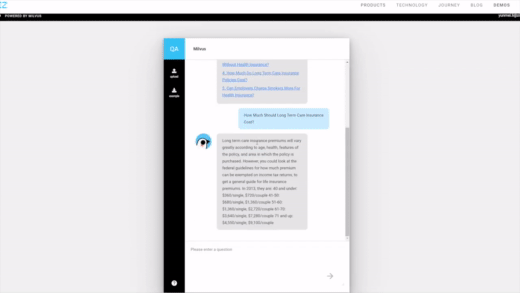
您可以探索全面的教程概述,涵盖主题如增强检索生成(RAG)、语义搜索、混合搜索、问答、推荐系统和各种快速入门指南。这些资源旨在帮助您快速高效地入门。
| 教程 | 用例 | 相关Milvus功能 |
|---|---|---|
| 使用Milvus构建RAG | RAG | 向量搜索 |
| RAG的高级优化 | RAG | 向量搜索,全文搜索 |
| 使用Milvus进行全文搜索 | 文本搜索 | 全文搜索 |
| 使用Milvus进行混合搜索 | 混合搜索 | 混合搜索,多个向量,稠密嵌入,稀疏嵌入 |
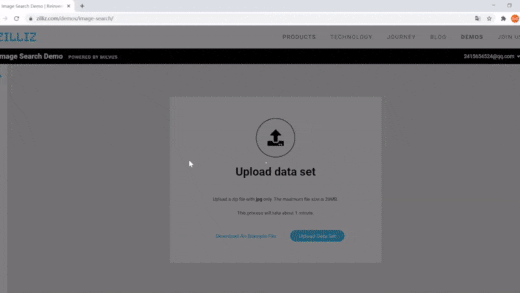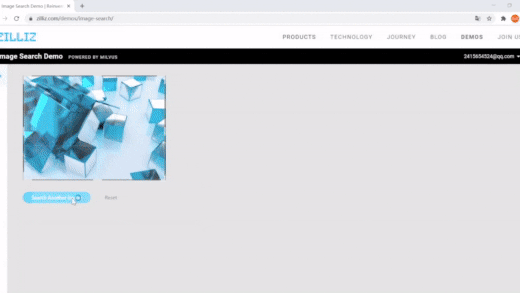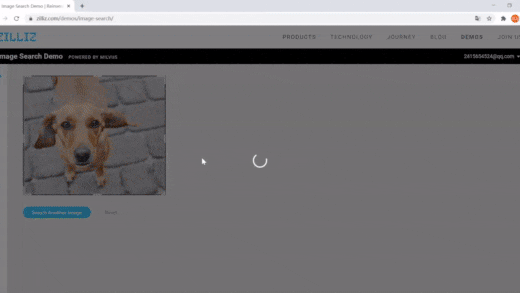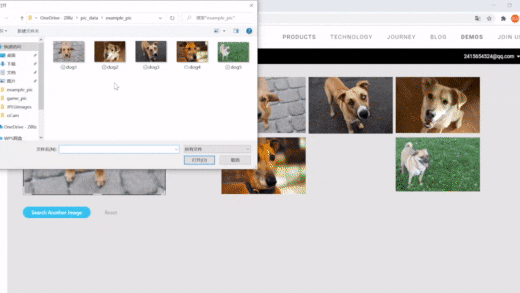
| 使用Milvus进行图像搜索 | 语义搜索 | 向量搜索,动态字段 |
| 多模态搜索与多个向量 | 语义搜索 | 多个向量,混合搜索 |
| 使用Milvus的电影推荐系统 | 推荐系统 | 向量搜索 |
| 使用Milvus的图形RAG | RAG | 图搜索 |
| 使用Milvus的上下文检索 | 快速入门 | 向量搜索 |
| 向量可视化 | 快速入门 | 向量搜索 |
| 使用Milvus的HDBSCAN聚类 | 快速入门 | 向量搜索 |
| 使用ColPali与Milvus进行多模态检索 | 快速入门 | 向量搜索 |
|-------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------|-------------------------------------------------------------------------------------------------------------------|
|  |
|  |
|  |
|
生态系统和集成
Milvus与一整套综合的AI开发工具集成,如LangChain、LlamaIndex、OpenAI和HuggingFace,使其成为增强检索生成(RAG)应用的理想向量存储。Milvus支持开放源代码嵌入模型和嵌入服务,涉及文本、图像和视频等多种模态。Milvus还提供了一个方便的pymilvusmodel实用工具,用户可以使用简单的包装代码将非结构化数据转换为向量嵌入,并利用重新排序模型优化搜索结果。
Milvus的同类项目
除了Milvus之外,还有一些同类向量数据库项目也在市场上具有影响力,它们各自具备特色功能与优势:
- Pinecone: 提供全托管的向量数据库服务,专注于高效的相似度搜索,尤其适合用于机器学习应用和AI的产品推荐功能。
- Faiss: Facebook开发的一个库,针对高效的相似度搜索进行了优化,支持多个索引和距离计算方法,适合需要强大存储和检索能力的数据密集型场景。
- Weaviate: 结合向量搜索和知识图谱,适合于构建语义理解应用,支持物体、图像等多种数据类型。
- Annoy: Spotify推出的一个C++库,用于帮助快速匹配相似项,强调高效内存利用,适合实时推荐系统和搜索引擎。
通过选择适合您的项目需求的向量数据库,您可以更好地提升AI应用的效率与准确性。