⚠️ 还在手忙脚乱创建线程?你的服务器是否扛得住生产环境的"狂风暴雨"?
💼 1. 案例引入
凌晨2点,你的电商后台突然收到流量告警------秒杀活动意外提前曝光,海量用户涌入抢购!之前运行良好的订单处理服务瞬间卡死,监控面板一片飘红。检查日志,发现罪魁祸首是"OutOfMemoryError: unable to create new native thread"。原来,每个订单处理请求都简单粗暴地 new Thread(),瞬间创建了成千上万线程,系统资源被耗尽...
Java线程池这时便如救火队员般登场,它像一个高效的"线程资源调度中心"。
❓ 2. 引言:为什么需要线程池?
在多线程编程中,直接创建和管理线程(new Thread().start())存在显著缺陷:
- 资源消耗大:线程的创建和销毁是昂贵的操作,涉及操作系统内核调用和资源分配。
- 稳定性风险 :无限制地创建线程会耗尽系统资源(如内存、CPU时间片),导致
OutOfMemoryError或系统崩溃。 - 管理困难:缺乏统一的管理,难以对线程进行跟踪、监控和资源控制。
线程池(Thread Pool) 是一种基于池化思想的线程管理机制。它通过预先创建一定数量的线程并放入"池"中,当有任务需要执行时,从池中获取线程而非创建新线程,任务完成后线程返回池中等待下一次任务。这种模式有效解决了上述问题,实现了:
- 降低资源消耗:通过线程复用。
- 提高响应速度:任务到达时,线程已存在,无需等待创建。
- 提高线程的可管理性:可对线程进行统一的分配、调优和监控。
🧩 3. 核心设计理念与工作原理
3.1 🔄 池化思想 (Pooling)
线程池的核心是"池化",即复用。它维护着一个线程集合,将昂贵的线程生命周期管理集中化,避免了频繁创建和销毁带来的开销。这与数据库连接池、HTTP连接池的设计理念一脉相承。
3.2 ↔️ 生产者-消费者模型
线程池完美实现了生产者-消费者模型:
- 生产者 :提交任务的线程(调用
execute()或submit()方法)。 - 消费者:线程池中的工作线程(Worker Thread)。
- 交易场所:任务队列(Blocking Queue)。
这种设计解耦了任务提交与任务执行,使得双方可以独立地、异步地工作。
3.3 🚦 执行流程
Java ThreadPoolExecutor的核心执行逻辑遵循一个严谨的决策流程,下图清晰地展示了当一个新任务被提交时,线程池是如何工作的:
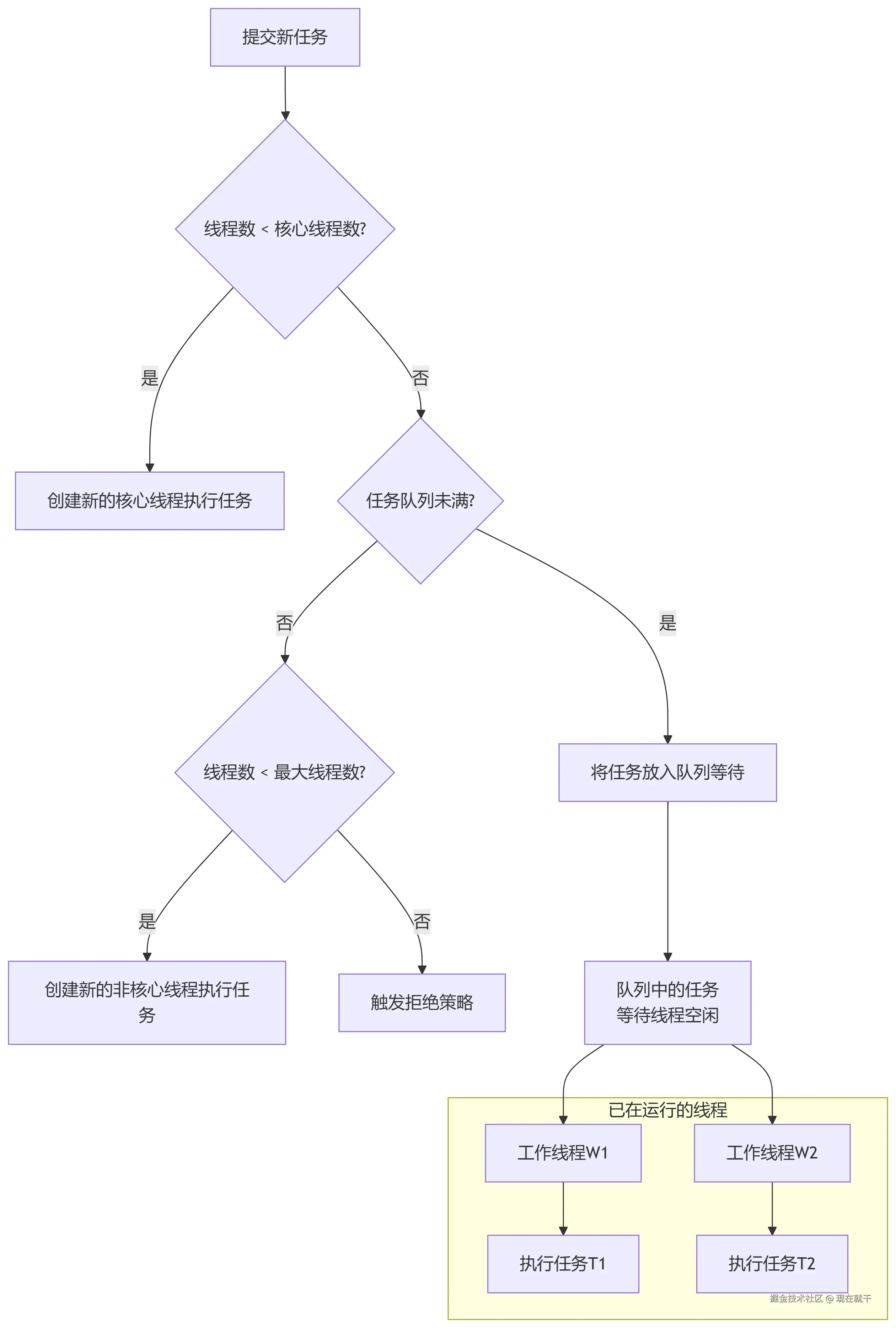
⚙️ 4. 核心参数详解
java.util.concurrent.ThreadPoolExecutor的构造函数是其灵魂,理解其参数是正确使用的关键。
java
public ThreadPoolExecutor(
int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler
)| 参数 | 含义 | 说明与影响 |
|---|---|---|
corePoolSize |
核心线程数 | 线程池的基本大小。即使线程空闲,也会保留在池中(除非设置allowCoreThreadTimeOut)。 |
maximumPoolSize |
最大线程数 | 线程池允许创建的最大线程数。这是资源消耗的硬性上限。 |
keepAliveTime |
线程空闲时间 | 非核心线程空闲多久后被终止回收。 |
unit |
空闲时间单位 | 如TimeUnit.SECONDS。 |
workQueue |
任务队列 | 用于保存等待执行的任务的阻塞队列。队列的选择至关重要。 |
threadFactory |
线程工厂 | 用于创建新线程。可用于设置线程名、优先级、守护状态等,便于监控和调试。 |
handler |
拒绝策略 | 当线程和队列都已满时,如何处理新提交的任务。这是系统的安全保护机制。 |
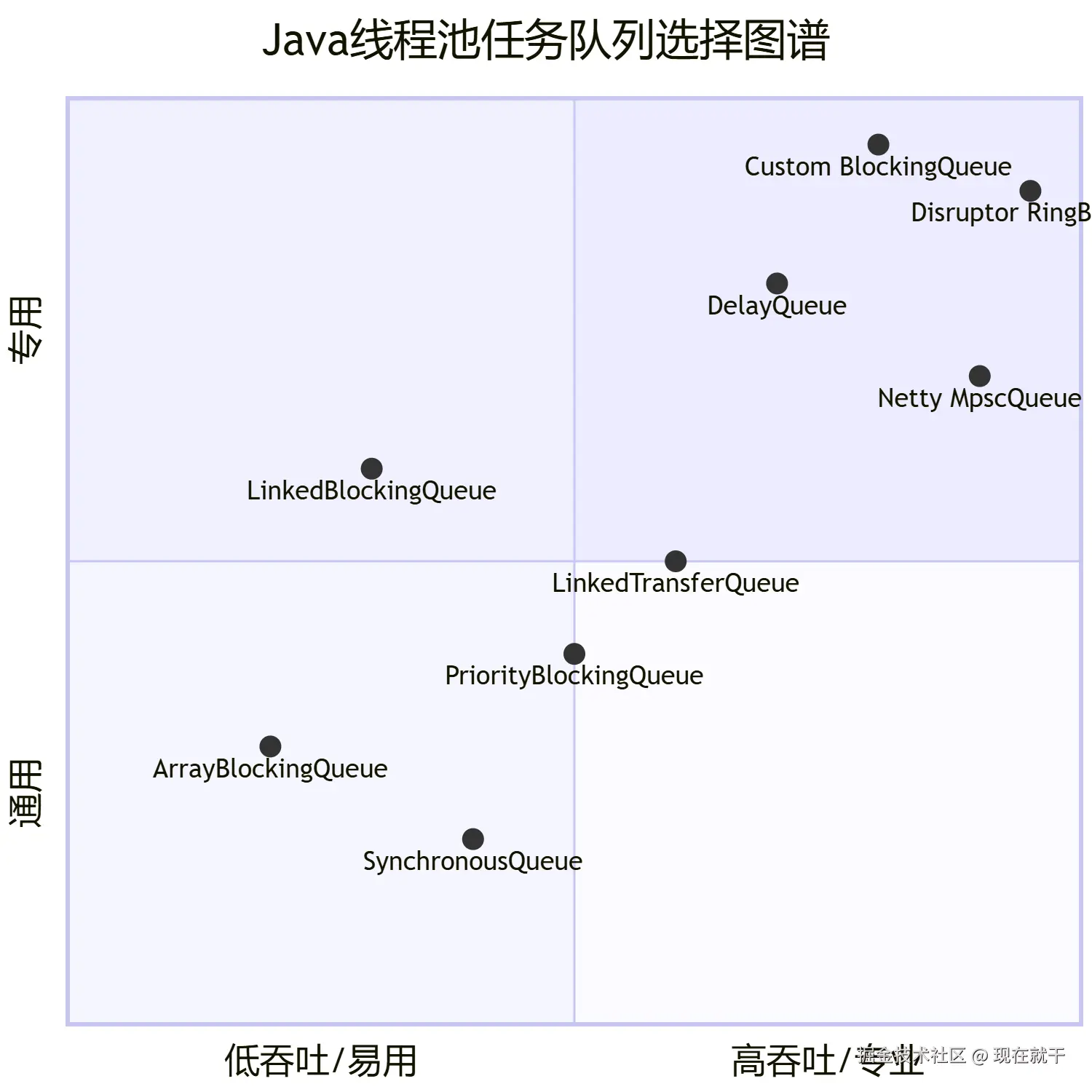
4.1 🧾 任务队列 (workQueue) 类型
| 队列类型(中文名) | 特性 | 队列类型(Class) | 适用场景 | 重要提醒 |
|---|---|---|---|---|
| 同步队列 | 一个不存储任何元素的阻塞队列。每个插入操作必须等待另一个线程的移除操作,反之亦然。 | SynchronousQueue |
用于希望直接传递 任务的场景,如 CachedThreadPool。任务提交时若无空闲线程,则立即创建新线程。 |
⛔ 必须设置很大的 maximumPoolSize,否则极易触发拒绝策略。 |
| 链式阻塞队列(无界) | 基于链表结构的无界 (默认Integer.MAX_VALUE)阻塞队列。FIFO(先进先出)。 |
LinkedBlockingQueue |
FixedThreadPool和 SingleThreadExecutor的默认选择。适用于任务量未知,但需要保证任务都被处理的场景。 |
⛔ 默认无界,任务持续堆积会消耗大量内存,极易导致 OutOfMemoryError,生产环境不推荐使用无界模式。 |
| 数组阻塞队列(有界) | 基于数组结构的有界阻塞队列。FIFO(先进先出)。 | ArrayBlockingQueue |
生产环境推荐。需要在吞吐量和资源消耗之间取得平衡。允许定义公平策略。 | 需要**⚖️ 合理设置队列容量**。容量太小容易触发拒绝策略,太大则会增加延迟和消耗内存。 |
| 优先级阻塞队列(无界) | 具有优先级排序的无界 阻塞队列。元素必须实现 Comparable接口或提供 Comparator。 |
PriorityBlockingQueue |
任务有优先级之分,需要高优先级的任务被优先执行的场景。 | ⚠️ 虽然无界,但任务按优先级排序,不会造成内存泄漏,但仍有OOM风险。 |
| 延迟队列 | 一个无界 的阻塞队列,其中的元素只有在其指定的延迟时间到期后 才能被获取。元素必须实现 Delayed接口。 |
DelayQueue |
用于定时任务调度。例如,实现缓存过期、定时重试、周期性任务等。 | ⚠️ 无界队列,有OOM风险。 队列头部的元素是延迟最短的。 |
| 链式传输队列 | 一个无界 的队列,实现了 TransferQueue接口。提供了 transfer()方法(会阻塞直到被消费)和 tryTransfer()方法。 |
LinkedTransferQueue |
适用于 "直接传递" 模式。生产者可以等待直到消费者准备好接收任务,实现了更严格的生产者-消费者协作。 | ⚠️ 无界队列,有OOM风险。 transfer()方法提供了更强的同步控制。 |
| 链式双向阻塞队列 | 一个由链表结构组成的双向 阻塞队列。可以从队列的头部 和尾部插入和移除元素。 | LinkedBlockingDeque |
工作窃取(Work-Stealing)算法、双端任务管理、"生产者-消费者"模式中消费者也可以 steals 任务等特殊场景。 | 提供了比普通队列更大的灵活性。可以作为有界或无界队列使用。 |
除了上述几个队列,还可以选择自定义队列
🛠️ 自定义队列 :实现 BlockingQueue接口
这是最灵活的方式。如果以上所有现成的队列都无法满足你的特殊业务需求,你可以实现 BlockingQueue接口来自定义一个队列。
🔨 一个简单的自定义有界优先级队列思路:
java
public class BoundedPriorityBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E> {
private final PriorityQueue<E> priorityQueue; // 底层存储
private final int capacity;
private final ReentrantLock lock = new ReentrantLock();
private final Condition notEmpty = lock.newCondition();
private final Condition notFull = lock.newCondition();
public BoundedPriorityBlockingQueue(int capacity, Comparator<? super E> comparator) {
this.capacity = capacity;
this.priorityQueue = new PriorityQueue<>(comparator);
}
@Override
public void put(E e) throws InterruptedException {
lock.lockInterruptibly();
try {
while (priorityQueue.size() == capacity) {
notFull.await(); // 队列满,等待"不满"的信号
}
priorityQueue.offer(e);
notEmpty.signal(); // 放入元素后,发出"非空"信号
} finally {
lock.unlock();
}
}
// ... 其他必要方法实现
}🔍 选择哪个队列,取决于你的具体需求:
- 需要简单有界队列? ->
ArrayBlockingQueue - 需要无界队列? ->
LinkedBlockingQueue(需警惕OOM) - 需要直接传递? ->
SynchronousQueue - 任务需要优先级? ->
PriorityBlockingQueue - 任务是定时触发? ->
DelayQueue - 追求极致的性能? ->
Disruptor或MpscQueue - 有特殊业务规则? ->
实现自定义队列
📊 总结与选型建议
- 安全首选 :对于绝大多数生产场景,
ArrayBlockingQueue(有界队列) 是最安全、最可控的选择,它迫使你考虑系统的承载能力。 - 性能极致 :在对性能有极端要求(如金融、游戏)的场景,可以考虑
Disruptor的RingBuffer(顶级队列方案)。 - 特殊需求 :
- 定时任务 ->
DelayQueue - 任务优先级 ->
PriorityBlockingQueue - 直接传递 ->
SynchronousQueue或LinkedTransferQueue
- 定时任务 ->
- 坚决避免 :在生产环境 中,应尽量避免使用默认的、无参的
LinkedBlockingQueue()(即无界模式),除非你能绝对保证任务不会无限堆积。
4.2 🛑 拒绝策略 (RejectedExecutionHandler)
当线程池和队列都饱和时,线程池会调用拒绝策略。
| 策略 | 行为 | 说明 |
|---|---|---|
AbortPolicy |
默认策略 。直接抛出RejectedExecutionException。 |
抛出异常,任务丢失。策略明确,利于发现问题。 |
CallerRunsPolicy |
由提交任务的线程自己来执行这个任务。 | 负反馈机制,减缓任务提交速度,给线程池喘息之机。 |
DiscardPolicy |
静默地丢弃无法处理的任务,不做任何通知。 | 不推荐,任务丢失无感知,难以排查。 |
DiscardOldestPolicy |
丢弃队列中最老的任务,然后尝试重新提交当前任务。 | 可能丢失重要旧任务,需谨慎使用。 |
📦 5. Java内置线程池类型(通过Executors工厂)
Executors类提供了几种快速创建线程池的工厂方法,但它们各有陷阱,生产环境不推荐直接使用,理解它们有助于理解配置。
| 工厂方法 | 底层配置 | 问题与风险 |
|---|---|---|
newFixedThreadPool(n) |
core=n, max=n, queue=无界LinkedBlockingQueue |
无界队列,任务堆积可能导致OOM。 |
newCachedThreadPool() |
core=0, max=Integer.MAX_VALUE, keepAlive=60s, queue=SynchronousQueue |
最大线程数无界,大量创建线程导致OOM。 |
newSingleThreadExecutor() |
core=1, max=1, queue=无界LinkedBlockingQueue |
无界队列,同上问题。 |
newScheduledThreadPool(n) |
支持定时及周期性任务。 | 同样存在无界队列问题。 |
📌 核心建议:不要使用Executors创建,而是通过ThreadPoolExecutor构造函数手动创建,以便明确指定所有参数,避免隐患。
📝 6. 线程池的选型与使用建议
6.1 🔍 选型与参数配置原则
- 任务性质定性 :
- CPU密集型 :任务主要消耗CPU资源(计算、逻辑判断)。建议配置较小的线程池 (
corePoolSize = CPU核数 + 1),避免过多线程切换。 - I/O密集型 :任务主要等待I/O(网络、数据库响应)。可配置较大的线程池 (
corePoolSize = CPU核数 × 2),重叠I/O等待时间,提高CPU利用率。 - 混合型:可拆分为不同线程池,或根据偏重权衡。
- CPU密集型 :任务主要消耗CPU资源(计算、逻辑判断)。建议配置较小的线程池 (
- 📊 参数配置策略 :
- 核心公式 :线程数 = CPU核数 × 目标CPU利用率 × (1 + 平均等待时间 / 平均计算时间) 。理论起点,必须通过压测验证。
- 队列选择 :强烈推荐使用有界队列 (如
ArrayBlockingQueue)。队列大小需根据业务容忍的延迟设定。 - 拒绝策略 :必须配置 。推荐使用
AbortPolicy(明确失败)或CallerRunsPolicy(负反馈)。
6.2 🏆 最佳实践
- 线程命名 :通过自定义
ThreadFactory为线程设置有意义的名字(如order-processor-thread-%d),极大便利日志调试。 - 资源释放 :应用关闭时,调用
shutdown()或shutdownNow()来优雅关闭线程池。 - 监控 :定期通过API监控线程池状态(
getPoolSize(),getActiveCount(),getQueue().size()),或集成到监控系统。 - 避免全局共享 :应为不同业务类型(如DB查询和CPU计算)划分不同的线程池,避免互相影响。