一、介绍
360Zhinao-1.8B-Reranking 模型以自主研发的 360Zhinao_1.8B_base 模型为基础,其中自主研发的单向生成模型 360Zhinao_1.8B_reranking 平均得分为 70.13,目前位居总体第一及开源模型第一,为生成模型承担判别性任务开辟了新的可能性。
C-MTEB-Reranking 排行榜包含四个子任务,分别是判断不同领域用户问答的相似度,以 MAP(Mean-average-precision)作为评价指标。目前该排行榜上的开源模型以双向判别模型(BERT 类模型)为主,唯一的单向生成模型(GP T 类模型)为 gte-Qwen1.5-7B-instruct,平均得分为 66.38,排名第 25 位,成绩不太理想。
| Model | T2Reranking | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|---|---|---|---|---|---|
| 360Zhinao-1.8B-Reranking | 68.55 | 37.29 | 86.75 | 87.92 | 70.13 |
| piccolo-large-zh-v2 | 67.15 | 33.39 | 90.14 | 89.31 | 70 |
| Baichuan-text-embedding | 67.85 | 34.3 | 88.46 | 88.06 | 69.67 |
| stella-mrl-large-zh-v3.5-1792d | 66.43 | 28.85 | 89.18 | 89.33 | 68.45 |
| PEG | 69.43 | 33.55 | 86.56 | 84.09 | 68.41 |
| bge-reranker-base | 67.28 | 35.46 | 81.27 | 84.1 | 67.03 |
| bge-reranker-large | 67.6 | 37.17 | 82.14 | 84.19 | 67.78 |
优化点
通过迭代发现和解决以下技术问题,它在预训练阶段不断刺激大型模型中固有的世界知识,更好地弥合生成模型和判别任务之间的差距。
- 数据处理:模型训练没有利用世界知识,没有继续用领域特定数据进行预训练,也没有对排行榜四大数据集之外的数据集进行微调,只使用排行榜内的四大数据集,通过数据感知进行精细迭代,并针对不同的数据集进行数据清洗和挖掘,确保在各个任务中的排名能够达到前三。
- 解决任务冲突:在合并四个任务时,由于数据域分布、答案模式、训练数据量、收敛步骤甚至序列长度的不同,不同任务之间存在冲突。深入解决这些冲突问题对于获得一个在不同任务中综合指标最优的通用模型至关重要。
- 解决训练不稳定性:与生成多个字符的任务不同,使用生成模型进行判别任务需要模型输出连续值。因此,训练过程中存在振荡问题。深入分析和解决训练不稳定性问题,可以使模型具有更好的泛化能力和鲁棒性。
二、部署过程
基础环境最低要求说明:
| 环境名称 | 版本信息 |
|---|---|
| Ubuntu | 22.04.5 LTS |
| python | 3.10 |
| Cuda | 12.1.1 |
| NVIDIA Corporation | 3090 |
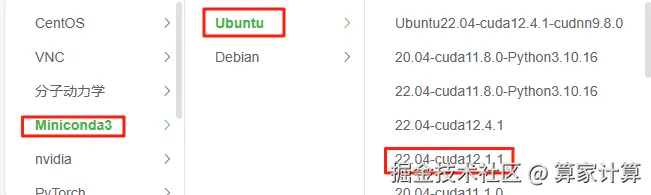
1. 构建基础镜像 Miniconda-Ubuntu-22.04-cuda12.1.1
2.从 github 仓库 克隆项目:
bash
git clone https://github.com/Qihoo360/360zhinao.git
3.创建虚拟环境
ini
# 创建一个名为zhinao_rerank的新虚拟环境,并指定 Python 版本为 3.10
conda create -n zhinao_rerank python=3.10 -y4.安装模型依赖包
激活 zhinao_rerank,并进入到 360zhinao/Reranking
bash
# 激活 zhinao_rerank 虚拟环境
conda activate MiniCPM4
# 切换到项目工作目录
cd 360zhinao/Reranking
# 安装 requirements.txt 依赖
pip install -r requirements.txt
注意!安装完requirements.txt 依赖后需要安装 flash-attention,需要PyTorch 2.2 及以上版本。
git clone https://github.com/Dao-AILab/flash-attention
cd flash-attention && pip install .5.下载预训练模型
从 huggingface 下载模型,如果不能访问,使用它的镜像网站:HF-Mirror
bash
pip install -U huggingface_hub
export HF_ENDPOINT=https://hf-mirror.com # 使用镜像网站
cd /360zhinao/Retrieval
hf download qihoo360/360Zhinao-1.8B-Reranking --local-dir ./model三、模型推理
1.测试官方test_model.py
进入到Reranking目录中运行test_model.py文件。
bash
cd Reranking
python test_model.py结果如下:

2.huaggingface上的推理脚本测试
- 新建一个test.py文件,具体代码如下:
ini
from typing import cast, List, Union, Tuple, Dict, Optional
import numpy as np
import torch
from tqdm import tqdm
from transformers import AutoModel, AutoTokenizer, AutoModelForSequenceClassification
import transformers
from transformers.trainer_pt_utils import LabelSmoother
IGNORE_TOKEN_ID = LabelSmoother.ignore_index
def preprocess(
sources,
tokenizer: transformers.PreTrainedTokenizer,
max_len: int = 1024,
system_message: str = "",
device = None,
) -> Dict:
roles = {"user": "<|im_start|>user", "assistant": "<|im_start|>assistant"}
answer_len = 64
im_start = tokenizer.im_start_id
im_end = tokenizer.im_end_id
nl_tokens = tokenizer('\n').input_ids
_system = tokenizer('system').input_ids + nl_tokens
_user = tokenizer('user').input_ids + nl_tokens
_assistant = tokenizer('assistant').input_ids + nl_tokens
# Apply prompt templates
input_ids, targets = [], []
for i, source in enumerate(sources):
## system_message
input_id, target = [], []
system = [im_start] + _system + tokenizer(system_message, max_length=max_len-answer_len, truncation=True).input_ids + [im_end] + nl_tokens
input_id += system
target += [im_start] + [IGNORE_TOKEN_ID] * (len(system)-3) + [im_end] + nl_tokens
assert len(input_id) == len(target)
## query ans
source = "\n\n".join(source)
role = "<|im_start|>user"
_input_id = tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids + nl_tokens + \
tokenizer(source, max_length=max_len-answer_len, truncation=True).input_ids + [im_end] + nl_tokens
input_id += _input_id
if role == '<|im_start|>user':
_target = [im_start] + [IGNORE_TOKEN_ID] * (len(_input_id)-3) + [im_end] + nl_tokens
elif role == '<|im_start|>assistant':
_target = [im_start] + [IGNORE_TOKEN_ID] * len(tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids) + \
_input_id[len(tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids)+1:-2] + [im_end] + nl_tokens
else:
raise NotImplementedError
target += _target
## label use placeholder 0; It will be masked later in the modeling_zhinao.py
role = "<|im_start|>assistant"
_input_id = tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids + nl_tokens + \
tokenizer("0", max_length=max_len-answer_len, truncation=True).input_ids + [im_end] + nl_tokens
input_id += _input_id
if role == '<|im_start|>user':
_target = [im_start] + [IGNORE_TOKEN_ID] * (len(_input_id)-3) + [im_end] + nl_tokens
elif role == '<|im_start|>assistant':
_target = [im_start] + [IGNORE_TOKEN_ID] * len(tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids) + \
_input_id[len(tokenizer(role, max_length=max_len-answer_len, truncation=True).input_ids)+1:-2] + [im_end] + nl_tokens
else:
raise NotImplementedError
target += _target
assert len(input_id) == len(target)
input_id += [tokenizer.pad_token_id] * (max_len - len(input_id))
target += [IGNORE_TOKEN_ID] * (max_len - len(target))
if len(input_id) > max_len:
print("max_len_error")
print(tokenizer.decode(input_id))
input_ids.append(input_id[:max_len])
targets.append(target[:max_len])
input_ids = torch.tensor(input_ids, dtype=torch.int)
targets = torch.tensor(targets, dtype=torch.int)
#print(f"input_ids {input_ids.shape}")
#print(f"targets {targets.shape}")
return dict(
input_ids=input_ids.to(device),
labels=targets.to(device),
attention_mask=input_ids.ne(tokenizer.pad_token_id).to(device),
)
class FlagRerankerCustom:
def __init__(
self,
model_name_or_path: str = None,
use_fp16: bool = False
) -> None:
self.tokenizer = transformers.AutoTokenizer.from_pretrained(
model_name_or_path,
model_max_length=1024,
padding_side="right",
use_fast=False,
trust_remote_code=True
)
self.tokenizer.pad_token_id = self.tokenizer.eod_id
config = transformers.AutoConfig.from_pretrained(
model_name_or_path,
trust_remote_code=True,
bf16=True,
)
config.use_cache = False
self.model = transformers.AutoModelForCausalLM.from_pretrained(
model_name_or_path,
config=config,
trust_remote_code=True,
)
self.model.linear.bfloat16()
if torch.cuda.is_available():
self.device = torch.device('cuda')
elif torch.backends.mps.is_available():
self.device = torch.device('mps')
else:
self.device = torch.device('cpu')
use_fp16 = False
if use_fp16:
self.model.half()
self.model = self.model.to(self.device)
self.model.eval()
self.num_gpus = torch.cuda.device_count()
if self.num_gpus > 1:
print(f"----------using {self.num_gpus}*GPUs----------")
self.model = torch.nn.DataParallel(self.model)
@torch.no_grad()
def compute_score(self, sentence_pairs: Union[List[Tuple[str, str]], Tuple[str, str]], batch_size: int =128,
max_length: int = 1024) -> List[float]:
if self.num_gpus > 0:
batch_size = batch_size * self.num_gpus
assert isinstance(sentence_pairs, list)
if isinstance(sentence_pairs[0], str):
sentence_pairs = [sentence_pairs]
all_scores = []
for start_index in tqdm(range(0, len(sentence_pairs), batch_size), desc="Compute Scores",
disable=False):
sentences_batch = sentence_pairs[start_index:start_index + batch_size] # [[q,ans],[q, ans]...]
inputs = preprocess(sources=sentences_batch, tokenizer=self.tokenizer,max_len=1024,device=self.device)
scores = self.model(**inputs, return_dict=True).logits.view(-1, ).float()
all_scores.extend(scores.cpu().numpy().tolist())
if len(all_scores) == 1:
return all_scores[0]
return all_scores
if __name__ == "__main__":
model_name_or_path = "/360zhinao/model"
model = FlagRerankerCustom(model_name_or_path, use_fp16=False)
inputs=[["What Color Is the Sky","Blue"], ["What Color Is the Sky","Pink"],]
ret = model.compute_score(inputs)
print(ret)结果如下所示:

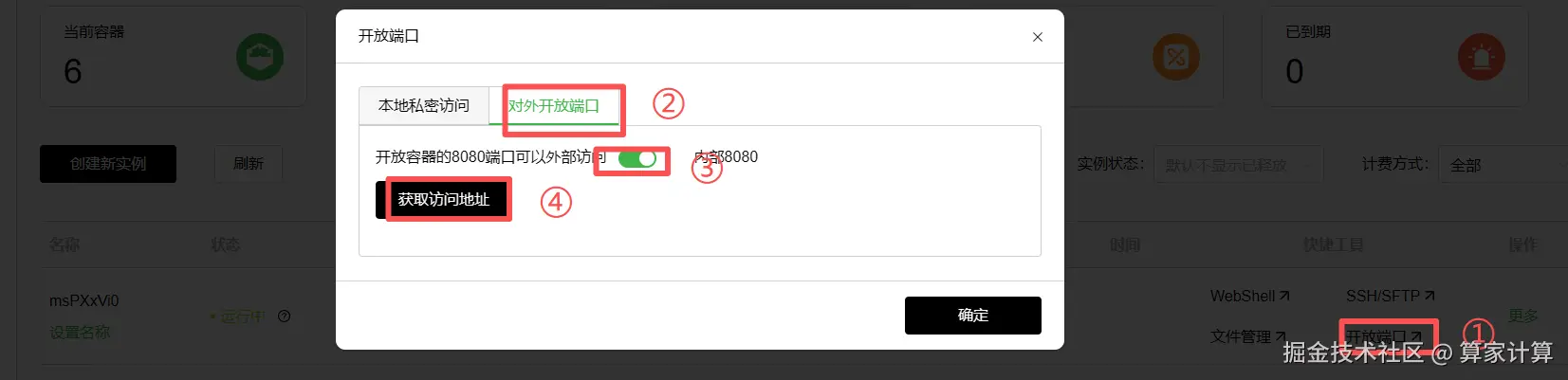
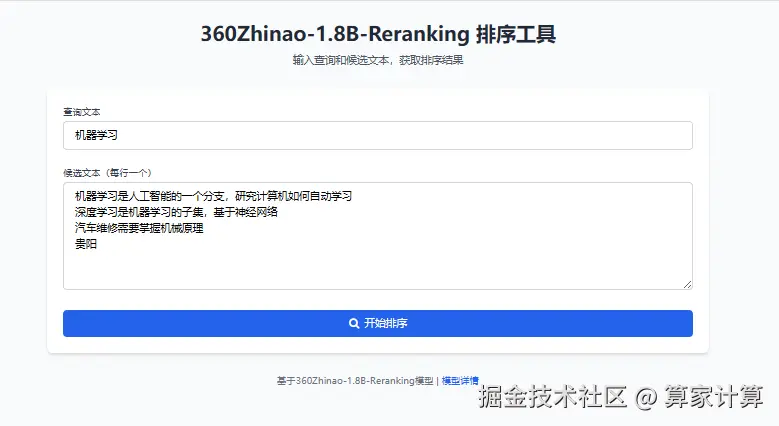
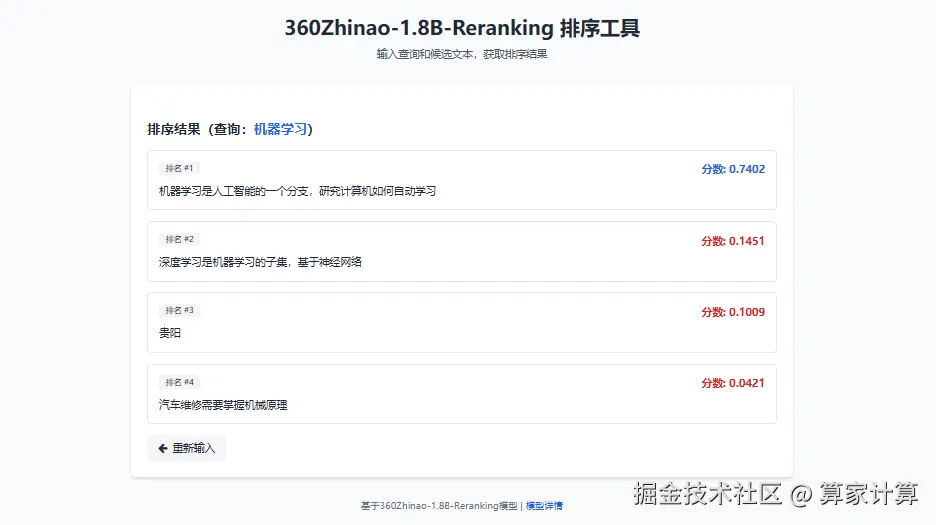
四、模型API测试例子
1.在/360zhinao/Reranking/目录下新建app.py文件,代码如下:
python
from fastapi import FastAPI, Form, Request, status
from fastapi.responses import HTMLResponse, JSONResponse
from fastapi.staticfiles import StaticFiles
from fastapi.middleware.cors import CORSMiddleware
from fastapi.templating import Jinja2Templates # 新增:用于更灵活的HTML渲染
import torch
import os
import logging
import asyncio
from argparse import ArgumentParser # 新增:支持命令行参数
from flag_models import FlagRerankerCustom
# 配置日志
logging.basicConfig(
level=logging.INFO,
format="%(asctime)s - %(name)s - %(levelname)s - %(message)s"
)
logger = logging.getLogger("reranking_service")
# 解析命令行参数
parser = ArgumentParser(description="360Zhinao-1.8B-Reranking 服务")
parser.add_argument("--port", type=int, default=8080, help="服务端口")
parser.add_argument("--model-path", type=str, default="/360zhinao/model/", help="模型文件路径")
parser.add_argument("--use-fp16", action="store_true", help="是否使用FP16精度")
args = parser.parse_args()
app = FastAPI(title="360Zhinao-1.8B-Reranking 排序工具")
# 解决跨域问题(生产环境建议限制origins)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"], # 生产环境替换为具体域名,如["http://localhost:8000"]
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 静态文件配置(使用绝对路径)
static_dir = os.path.abspath("/360zhinao/Reranking/static")
if not os.path.exists(static_dir):
logger.warning(f"静态文件目录不存在: {static_dir}")
app.mount("/static", StaticFiles(directory=static_dir), name="static")
# 模板配置(用于HTML渲染)
templates = Jinja2Templates(directory=static_dir)
# 全局模型实例
reranker = None
# 启动时加载模型(异步化处理,避免阻塞事件循环)
@app.on_event("startup")
async def load_model():
global reranker
try:
logger.info("开始加载360Zhinao-1.8B-Reranking模型...")
# 检查模型路径是否存在
model_path = os.path.abspath(args.model_path)
if not os.path.exists(model_path):
raise FileNotFoundError(f"模型路径不存在: {model_path}")
# 模型加载是同步操作,用线程池异步执行避免阻塞
reranker = await asyncio.to_thread(
FlagRerankerCustom,
model_name_or_path=model_path,
use_fp16=args.use_fp16
)
logger.info("模型加载完成!")
except Exception as e:
logger.error(f"模型加载失败: {str(e)}", exc_info=True) # 输出详细堆栈信息
raise # 启动失败时终止服务
# 首页路由(使用绝对路径读取HTML,更可靠)
@app.get("/", response_class=HTMLResponse)
async def index(request: Request):
html_path = os.path.join(static_dir, "index.html")
if not os.path.exists(html_path):
logger.error(f"index.html不存在: {html_path}")
return HTMLResponse(
content="<h1>服务异常:首页文件未找到</h1>",
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR
)
# 使用模板渲染(支持后续动态内容扩展)
return templates.TemplateResponse("index.html", {"request": request})
# 排序API(优化输入处理和错误反馈)
@app.post("/api/rerank")
async def rerank(
query: str = Form(..., description="查询文本"),
candidates: str = Form(..., description="候选文本,每行一个")
):
try:
# 严格处理候选文本(过滤空行和纯空白字符)
candidate_list = [c.strip() for c in candidates.split("\n") if c.strip()]
if not candidate_list:
return JSONResponse(
{"success": False, "error": "候选文本不能为空,请至少提供一个有效的候选文本"},
status_code=status.HTTP_400_BAD_REQUEST
)
# 构建输入对
sentence_pairs = [[query, candidate] for candidate in candidate_list]
# 模型推理(确保在无梯度环境下运行)
with torch.no_grad():
scores = reranker.compute_score(sentence_pairs)
# 转换为概率并限制小数位数
scores = torch.sigmoid(torch.tensor(scores)).tolist()
scores = [round(score, 6) for score in scores] # 保留6位小数,更精确
# 排序并构建结果
ranked_results = sorted(
zip(candidate_list, scores),
key=lambda x: x[1],
reverse=True
)
return JSONResponse({
"success": True,
"query": query,
"count": len(ranked_results), # 新增:返回结果数量
"results": [
{"text": text, "score": score}
for text, score in ranked_results
]
})
except Exception as e:
logger.error(f"推理过程出错: {str(e)}", exc_info=True)
return JSONResponse(
{"success": False, "error": "服务器内部错误,请稍后重试"},
status_code=status.HTTP_500_INTERNAL_SERVER_ERROR
)
if __name__ == "__main__":
import uvicorn
# 启动服务(使用命令行参数配置端口)
uvicorn.run(
app,
host="0.0.0.0", # 允许外部访问
port=args.port,
log_level="info",
workers=1 # 模型不支持多进程,保持单worker
)前端页面/360zhinao/Reranking/static/index.html代码如下:
xml
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>360Zhinao-1.8B-Reranking 排序工具</title>
<script src="https://cdn.tailwindcss.com"></script>
<link href="https://cdn.jsdelivr.net/npm/font-awesome@4.7.0/css/font-awesome.min.css" rel="stylesheet">
</head>
<body class="bg-gray-50 min-h-screen">
<div class="container mx-auto px-4 py-8 max-w-5xl">
<header class="mb-8 text-center">
<h1 class="text-3xl font-bold text-gray-800 mb-2">360Zhinao-1.8B-Reranking 排序工具</h1>
<p class="text-gray-600">输入查询和候选文本,获取排序结果</p>
</header>
<main class="bg-white rounded-lg shadow-md p-6 mb-8">
<!-- 输入表单 -->
<form id="rerankForm" class="space-y-6">
<div>
<label for="query" class="block text-sm font-medium text-gray-700 mb-1">查询文本</label>
<input
type="text"
id="query"
class="w-full px-4 py-2 border border-gray-300 rounded-md focus:ring-2 focus:ring-blue-500 focus:border-blue-500"
placeholder="例如:推荐一本机器学习入门书籍"
required
>
</div>
<div>
<label for="candidates" class="block text-sm font-medium text-gray-700 mb-1">
候选文本(每行一个)
</label>
<textarea
id="candidates"
rows="6"
class="w-full px-4 py-2 border border-gray-300 rounded-md focus:ring-2 focus:ring-blue-500 focus:border-blue-500"
placeholder="例如:
《机器学习实战》
《统计学习方法》
《深度学习入门》
《Python数据科学手册》"
required
></textarea>
</div>
<button
type="submit"
id="submitBtn"
class="w-full bg-blue-600 text-white py-2 px-4 rounded-md hover:bg-blue-700 focus:outline-none focus:ring-2 focus:ring-blue-500 focus:ring-offset-2 transition"
>
<i class="fa fa-search mr-2"></i>开始排序
</button>
</form>
<!-- 加载状态 -->
<div id="loading" class="hidden text-center py-6">
<i class="fa fa-spinner fa-spin text-2xl text-blue-600"></i>
<p class="mt-2 text-gray-600">正在排序,请稍候...</p>
</div>
<!-- 错误提示 -->
<div id="error" class="hidden bg-red-50 border border-red-200 rounded-md p-4 mb-6">
<p class="text-red-700"><i class="fa fa-exclamation-circle mr-2"></i><span id="errorMsg"></span></p>
</div>
<!-- 结果展示 -->
<div id="results" class="hidden mt-8">
<h2 class="text-xl font-semibold text-gray-800 mb-4">
排序结果(查询:<span id="resultQuery" class="text-blue-600"></span>)
</h2>
<div id="resultList" class="space-y-4">
<!-- 结果将通过JS动态插入 -->
</div>
</div>
</main>
<footer class="text-center text-gray-500 text-sm">
<p>基于360Zhinao-1.8B-Reranking模型 | <a href="https://huggingface.co/qihoo360/360Zhinao-1.8B-Reranking" class="text-blue-600 hover:underline">模型详情</a></p>
</footer>
</div>
<script>
// 表单提交处理
document.getElementById('rerankForm').addEventListener('submit', async (e) => {
e.preventDefault();
// 获取输入值
const query = document.getElementById('query').value.trim();
const candidates = document.getElementById('candidates').value.trim();
// 验证输入
if (!query) {
showError('请输入查询文本');
return;
}
if (!candidates) {
showError('请输入候选文本');
return;
}
// 显示加载状态
document.getElementById('rerankForm').classList.add('hidden');
document.getElementById('loading').classList.remove('hidden');
document.getElementById('error').classList.add('hidden');
document.getElementById('results').classList.add('hidden');
try {
// 使用FormData处理参数,支持多行文本
const formData = new FormData();
formData.append('query', query);
formData.append('candidates', candidates);
// 发送请求(使用相对路径,需与后端同域部署)
const response = await fetch('/api/rerank', {
method: 'POST',
body: formData
});
// 处理HTTP错误状态
if (!response.ok) {
const errorData = await response.json().catch(() => ({}));
throw new Error(errorData.error || `请求失败(状态码:${response.status})`);
}
const data = await response.json();
if (!data.success) {
throw new Error(data.error || '排序失败,请重试');
}
// 渲染结果
renderResults(data);
} catch (err) {
// 显示错误信息
console.error('请求错误:', err);
document.getElementById('loading').classList.add('hidden');
document.getElementById('error').classList.remove('hidden');
document.getElementById('errorMsg').textContent = err.message;
document.getElementById('rerankForm').classList.remove('hidden');
}
});
// 渲染排序结果
function renderResults(data) {
document.getElementById('loading').classList.add('hidden');
document.getElementById('results').classList.remove('hidden');
document.getElementById('resultQuery').textContent = data.query;
const resultList = document.getElementById('resultList');
resultList.innerHTML = '';
// 遍历结果生成列表
data.results.forEach((item, index) => {
const scoreColor = getScoreColor(item.score);
const resultItem = document.createElement('div');
resultItem.className = 'border border-gray-200 rounded-md p-4 hover:shadow-md transition';
resultItem.innerHTML = `
<div class="flex justify-between items-start mb-2">
<span class="bg-gray-100 text-gray-800 text-xs font-medium px-2.5 py-0.5 rounded">
排名 #${index + 1}
</span>
<span class="text-${scoreColor}-600 font-semibold">
分数: ${item.score.toFixed(4)}
</span>
</div>
<p class="text-gray-800">${item.text}</p>
`;
resultList.appendChild(resultItem);
});
// 添加"返回重新输入"按钮
const backBtn = document.createElement('button');
backBtn.className = 'mt-6 bg-gray-100 text-gray-800 py-2 px-4 rounded-md hover:bg-gray-200 focus:outline-none';
backBtn.innerHTML = '<i class="fa fa-arrow-left mr-2"></i>重新输入';
backBtn.onclick = () => {
document.getElementById('results').classList.add('hidden');
document.getElementById('rerankForm').classList.remove('hidden');
};
resultList.appendChild(backBtn);
}
// 显示错误信息
function showError(message) {
document.getElementById('error').classList.remove('hidden');
document.getElementById('errorMsg').textContent = message;
// 3秒后自动隐藏错误提示
setTimeout(() => {
document.getElementById('error').classList.add('hidden');
}, 3000);
}
// 根据分数获取颜色等级
function getScoreColor(score) {
if (score >= 0.8) return 'green';
if (score >= 0.6) return 'blue';
if (score >= 0.4) return 'yellow';
if (score >= 0.2) return 'orange';
return 'red';
}
</script>
</body>
</html>执行app.py文件
python app.py获取访问地址在浏览器打开: