随着人工智能模型规模扩大和数据复杂度提升,整合多源异构数据实现多模态协同建模,已成为提升模型性能的核心路径。高效的数据预处理体系需在保证数据质量与多样性的前提下,突破大规模数据清洗、增强与合成的系统性技术瓶颈,以平衡训练效能与成本控制。阿里云人工智能平台 PAI 分布式训练 PAI-DLC 推出的一项全新任务类型 DataJuicer on DLC,旨在为用户带来开箱即用、高性能、稳定高效的数据处理能力。用户可以一键提交 DataJuicer 框架任务,高效地完成大规模数据的清洗、过滤、转换和增强, 实现大模型场景下文本及多模态数据处理计算能力。
在大规模数据集样本下,DataJuicer on DLC 支持异构集群、具备多模态协同处理引擎, 表现出更高效的数据处理效率和更优资源利用率。本文将介绍 DataJuicer 和 PAI-DLC,以及如何在 PAI-DLC 支持快速提交 DataJuicer 框架任务。
PAI-DLC 及 DataJuicer 相关介绍
DataJuicer 介绍
DataJuicer是一款专注于处理大规模多模态数据(如文本、图像、音频和视频)的开源工具。旨在帮助研究人员和开发者高效地清洗、过滤、转换和增强大规模数据集,为大语言模型 (LLM) 提供更高质量、更丰富、更易"消化"的数据。 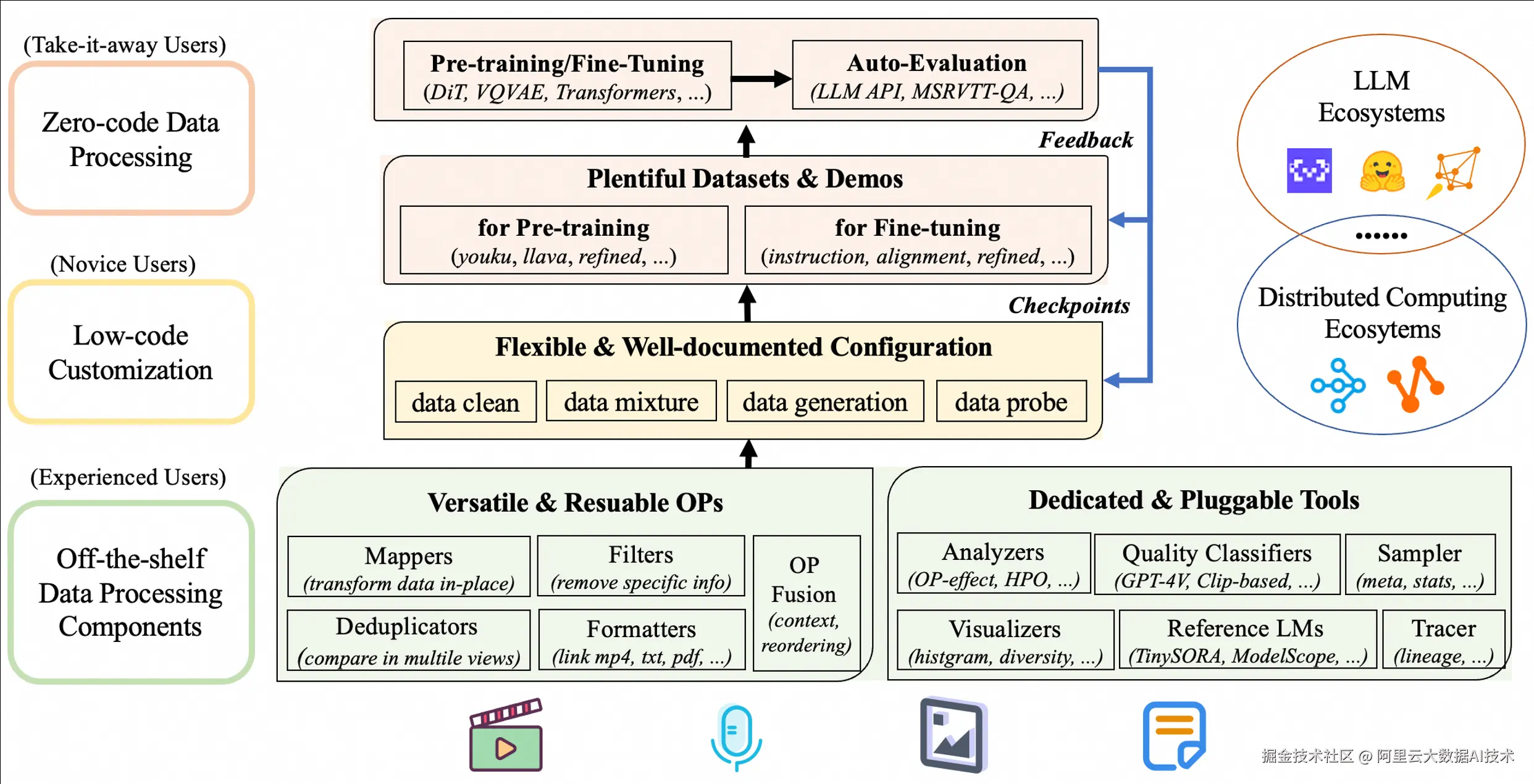
PAI-DLC 介绍
PAI-DLC是阿里云人工智能平台PAI提供的云原生AI分布式训练服务,为开发者和企业提供灵活、稳定、易用和高性能的训练环境, 支持多种AI训练框架,能够处理大规模分布式模型训练任务,在降低成本的同时提升训练效率。 
DataJuicer on DLC 介绍
DataJuicer on DLC 是由阿里云人工智能平台PAI和通义实验室,联合推出的一款数据处理服务,支持用户在云上一键提交DataJuicer框架任务,高效地完成大规模数据的清洗、过滤、转换和增强, 实现LLM多模态数据处理计算能力。
3.1 DataJuicer on DLC 技术特性
-
高性能:DataJuicer on DLC 在千万级多模态数据集的处理中,展现出卓越的线性扩展性能,和数据处理速度优势,有效优化资源利用。
-
支持异构集群: 在海量多模态数据处理场景下,支持不同类型的算子、以及同一个数据处理管线的不同阶段算子,在异构集群(GPU/CPU)分别执行,进一步提升资源利用效率和处理性能
-
多模态协同处理引擎: 内置文本、图像、视频、音频等专用算子,支持视觉-文本-时序数据的联合清洗与增强,不同类型算子可以灵活调度在异构集群(比如文本用cpu,图像视频用gpu)执行,避免传统工具链的"碎片化"处理的同时大大提升资源利用率。
-
-
算子丰富: 为用户提供 100 多个核心算子,包含 aggregator、deduplicator、filter、formatter、grouper、mapper、selector 等, 覆盖了数据加载和规范化,数据编辑和转换,数据过滤和去重,及高质量样本筛选的数据处理全周期。

- 大规模: 依托 PAI DLC 的分布式计算框架与深度硬件加速优化(CUDA/OP 融合),支持从千级样本的实验到百亿级生产数据的高效处理。
- 自动容错: PAI DLC 本身提供节点、任务、容器维度的容错和自愈能力,同时 DataJuicer 进一步提供算子级别的容错能力,解决服务器、网络等基础设施等故障导致的中断风险。
- 资源预估: DataJuicer 支持智能平衡资源限制与运行效率,自动预估算子OP最优并发数,显著降低内存溢出(OOM)导致的任务失败率,同时优化资源分配策略,有效提升数据处理效率。
- 简单易用: 开发者可依据业务场景灵活编排算子链,精准满足不同类型的数据处理需求, 并且总结多个行业级模板,方便用户一键使用。PAI DLC 提供直观的用户界面和易于理解的API,免部署、免运维, 用户无需关注底层基础设施的部署与运维复杂性, 一键提交DataJuicer任务进行AI数据处理。
3.2 性能优势
-
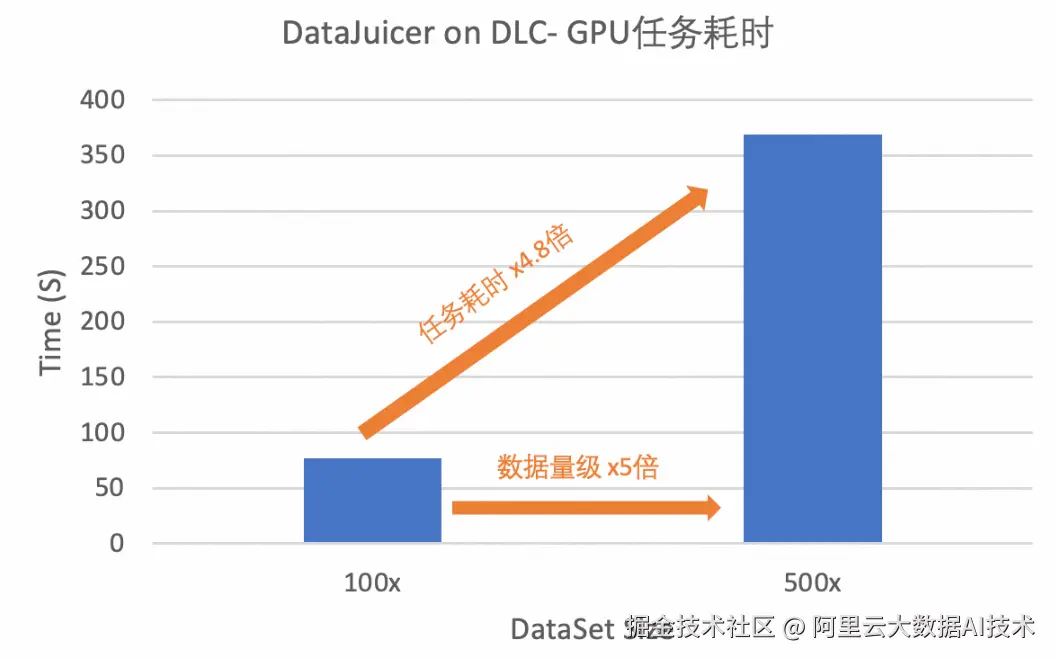
在亿级超大规模数据处理场景, DataJuicer on DLC 呈现出显著的线性加速比与可扩展性。GPU资源配置相同情况下,当数据集扩展至5倍时,数据处理耗时约扩展4.8倍,其线性效率高达96%,最大化GPU资源利用率。
-
在千万级中等规模数据处理场景, DataJuicer on DLC 与云原生节点运行相比,耗时更短,速度更快,约节省24.8%的处理时间。
多模态数据(千万级规模)CPU任务耗时对比图
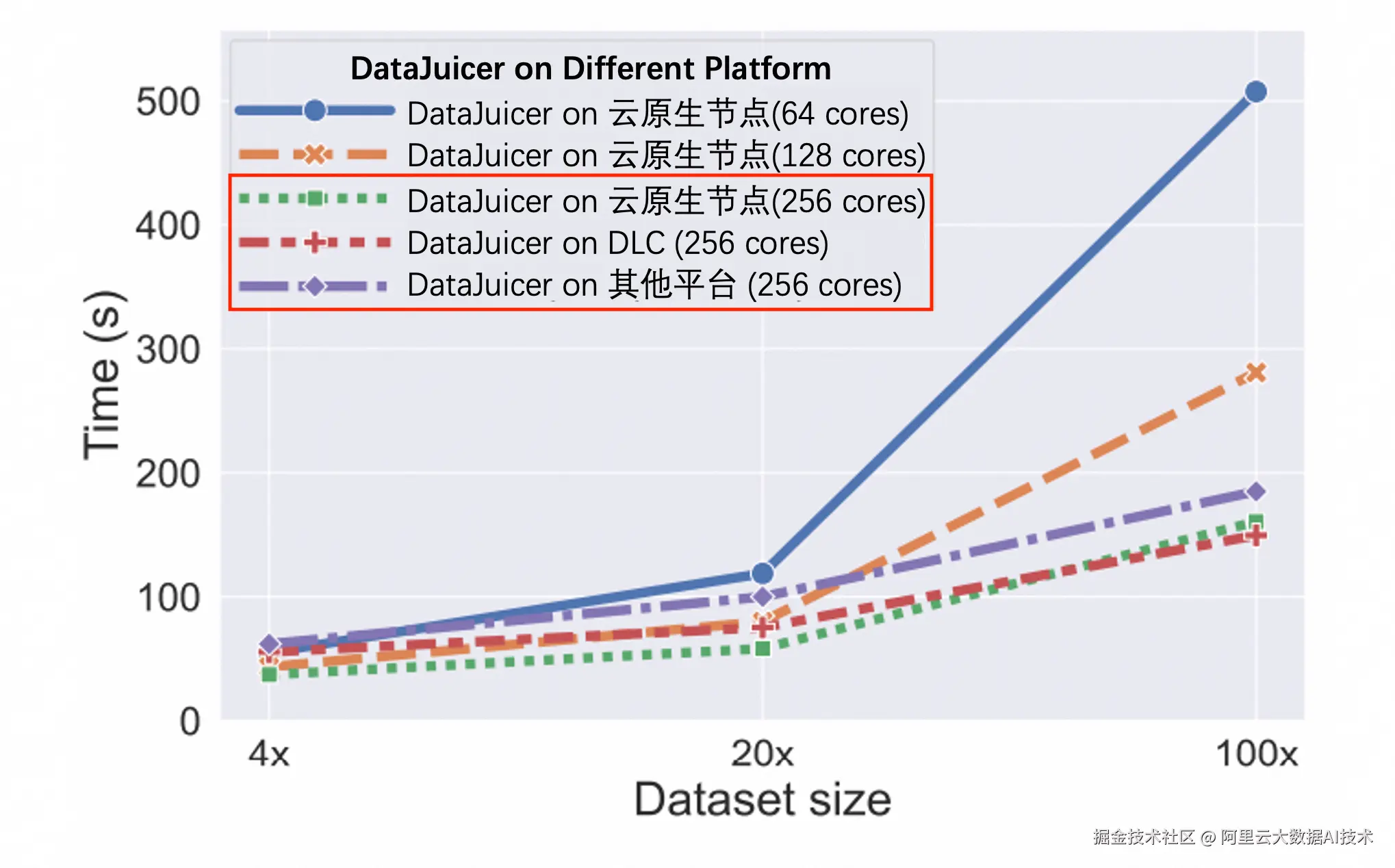 文本数据(千万级规模)CPU任务耗时对比图
文本数据(千万级规模)CPU任务耗时对比图
-
在 200GB、1TB、5TB 的数据集上测试了基于 MinHash 的 Ray 去重算子,测试机器的 CPU 核数从 640 核到 1280 核。实验表明,当数据集大小增长 5 倍,处理时间增长 4.02 到 5.62 倍。当 CPU 核数翻倍,处理时间较原来减少了 58.9% 到 67.1%。
实操案例
以海量视频数据处理场景为例,随着多模态大语言模型(MLLM)在自动驾驶、具身智能等领域的突破性应用,海量视频数据的精细化处理已成为构建行业核心竞争力的技术高地。在自动驾驶场景中,模型需从车载摄像头持续输入的视频流中实时解析复杂路况、交通标识、行人行为等多维度信息;而具身智能系统则依赖视频数据构建物理世界动态表征,以完成机器人运动规划、环境交互等高阶任务。然而,传统数据处理方案面临三大核心挑战:
-
模态割裂:视频数据包含视觉、音频、时序、文本描述等多源异构信息,需跨模态特征融合工具链,而传统流水线式工具难以实现全局关联分析。
-
质量瓶颈:数据清洗需经历去重、标注修复、关键帧提取、噪声过滤等多个环节,传统多阶段处理易造成信息损失与冗余计算。
-
工程效能:大规模视频数据(TB/PB级)处理对分布式算力调度、异构硬件适配提出极高要求,自建系统存在开发周期长、资源利用率低等问题。
PAI-DLC DataJuicer 框架为上述挑战提供端到端解决方案。DataJuicer on DLC 解决方案技术优势体现在:
-
多模态协同处理引擎:内置文本、图像、视频、音频等专用算子,支持视觉-文本-时序数据的联合清洗与增强,避免传统工具链的"碎片化"处理。
-
云原生弹性架构:深度集成PAI的百GB/s级分布式存储加速、GPU/CPU异构资源池化能力,支持千节点任务自动扩缩容。
-
本案例以自动驾驶和具身智能所需的视频处理流程为例,演示如何通过DataJuicer完成以下处理:
-
过滤原始数据中时长过短的视频频段
-
根据NSFW得分过滤脏数据
-
对视频抽帧 生成视频的文本caption描述
Step1 数据准备: 以Youku-AliceMind数据集为例,抽取2000条视频数据。原始数据参考:modelscope.cn/datasets/mo...。
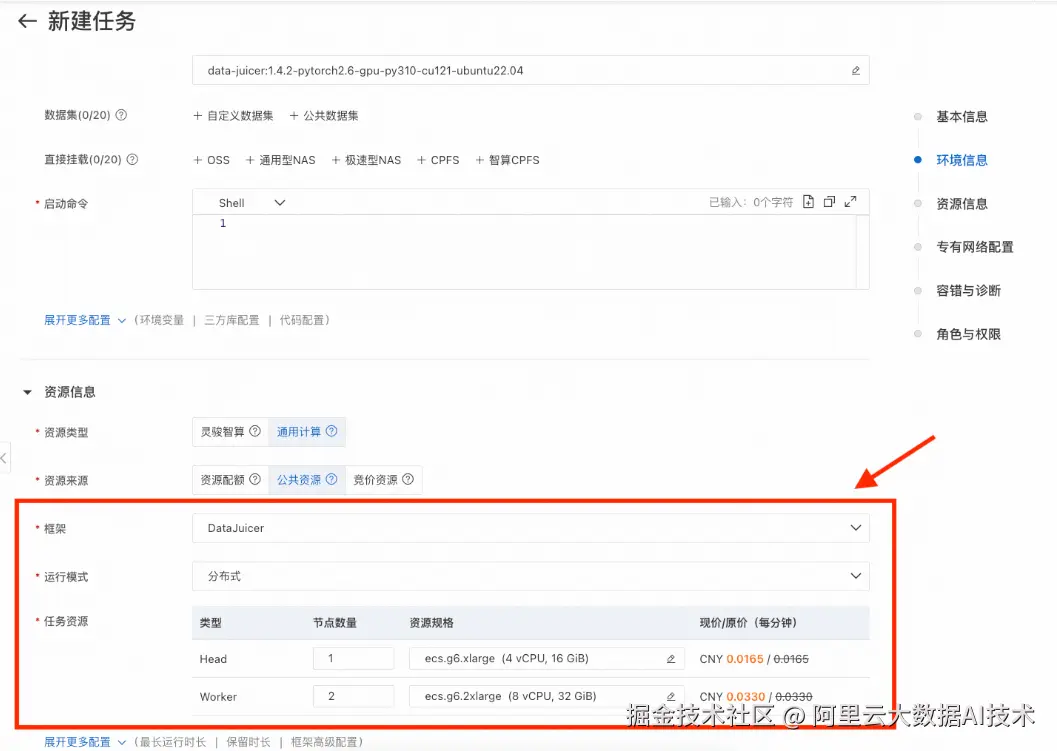
Step2 镜像选择: 选择官方镜像,data-juicer:1.4.3-pytorch2.6-gpu-py310-cu121-ubuntu22.04。 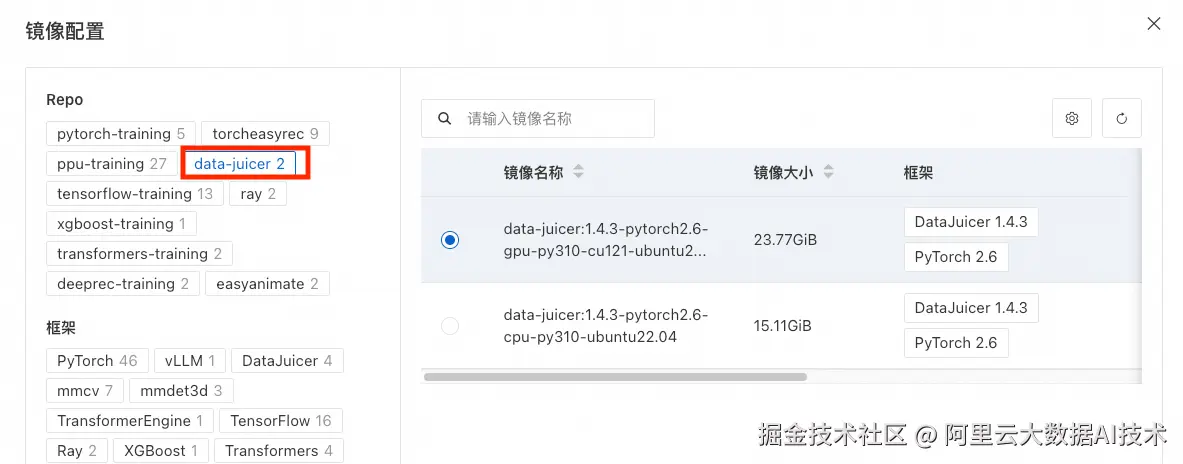 Step3 资源配置: 选择DataJuicer框架,选择分布式的运行模式,并配置如下资源。
Step3 资源配置: 选择DataJuicer框架,选择分布式的运行模式,并配置如下资源。 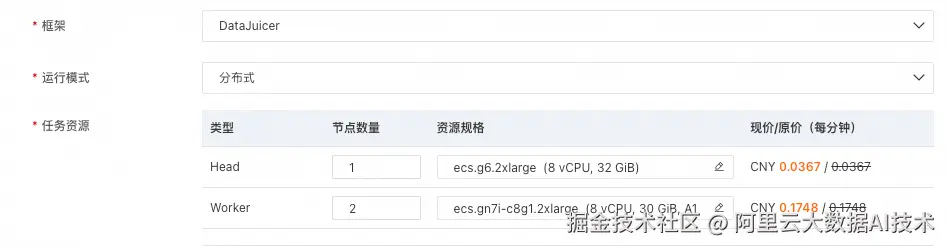
Step4 YAML配置:
yaml
# global parameters
project_name: 'dj-video-demo'
dataset_path: '/mnt/data/data/Youku-AliceMind/caption/validation/youku_alice_mind_dj_2k.jsonl'
executor_type: 'ray'
skip_op_error: false # 调试阶段
export_type: 'jsonl'
export_path: '/mnt/data/outputs/video_demo/v1'
video_key: 'videos'
video_special_token: '<__dj__video>'
eoc_special_token: '<|__dj__eoc|>'
# process schedule
# a list of several process operators with their arguments
process:
- video_duration_filter:
min_duration: 0
max_duration: 3600
any_or_all: any
- video_nsfw_filter:
hf_nsfw_model: Falconsai/nsfw_image_detection
max_score: 0.5
frame_sampling_method: all_keyframes
frame_num: 3
reduce_mode: avg
any_or_all: any
- video_captioning_from_frames_mapper:
hf_img2seq: 'Salesforce/blip2-opt-2.7b'
caption_num: 1
keep_candidate_mode: 'random_any'
keep_original_sample: true
frame_sampling_method: 'all_keyframes'
frame_num: 3PAI 全链路加速套件
高效、高质量的多模态数据处理为业务提供良好的起点之后,人工智能平台 PAI 提供全链路加速套件,覆数据处理、模型训练和模型推理等阶段,所有加速套件都可以在 PAI 上实现与业务的无缝衔接。
paiTurboX
在自动驾驶场景,paiTurboX 为复杂数据预处理、离线大规模模型训练和实时智能驾驶推理提供了全方位的加速解决方案,深度融合 PAI 平台的异构算力调度、分布式训练和分布式推理等核心能力,显著提升了感知、规划、控制等多模块系统的训练与推理效率。
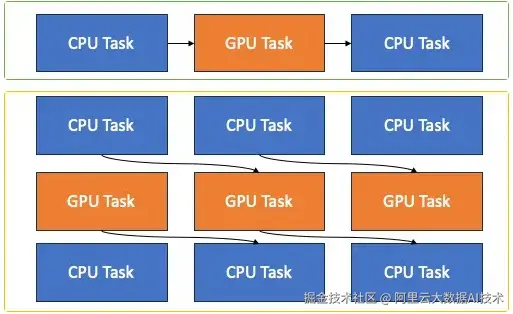
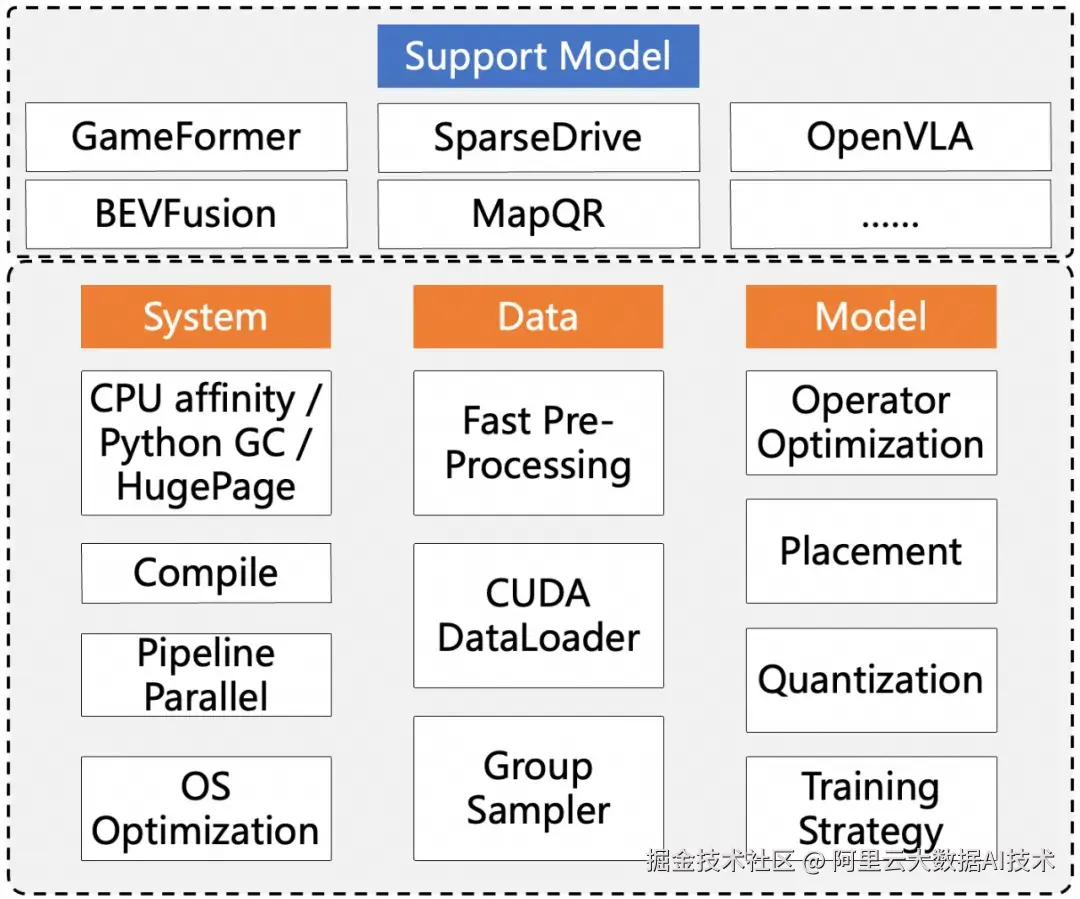
paiTurboX 从系统、数据、模型三个方面针对自动驾驶面临的两大难题进行优化。在系统侧,TurboX 通过优化 CPU 亲和性、流水线并行和动态编译等方案,支持 CPU 计算和 GPU 计算流水并行调度执行,提升模型训练推理效率。
paiFuser
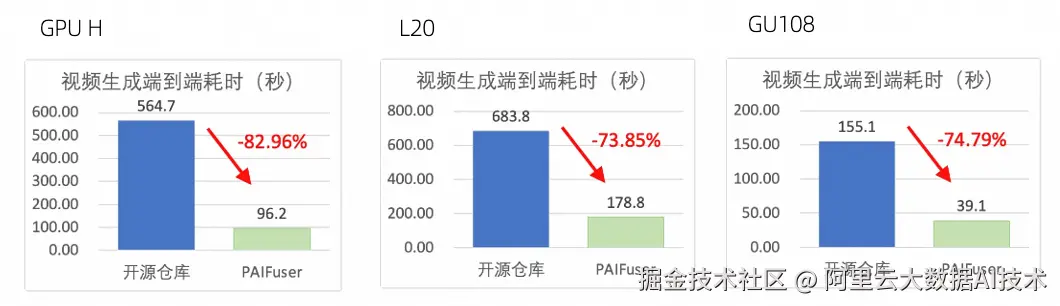
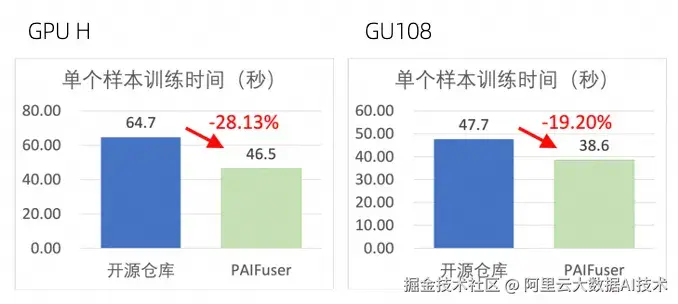
针对扩散模型(Diffusion Models),尤其是 DiT(Diffusion Transformer)架构,paiFuser 通过高性能一体化训练与推理加速框架,有效解决高计算复杂度、显存消耗大、实时性不足等问题。结合 PAI 平台的灵活、稳定、易用和高性能的训练/推理环境,在数千卡集群,训练场景达到了40%+的 MFU;在单机8卡条件下,推理场景生成时间最高减少80%+。
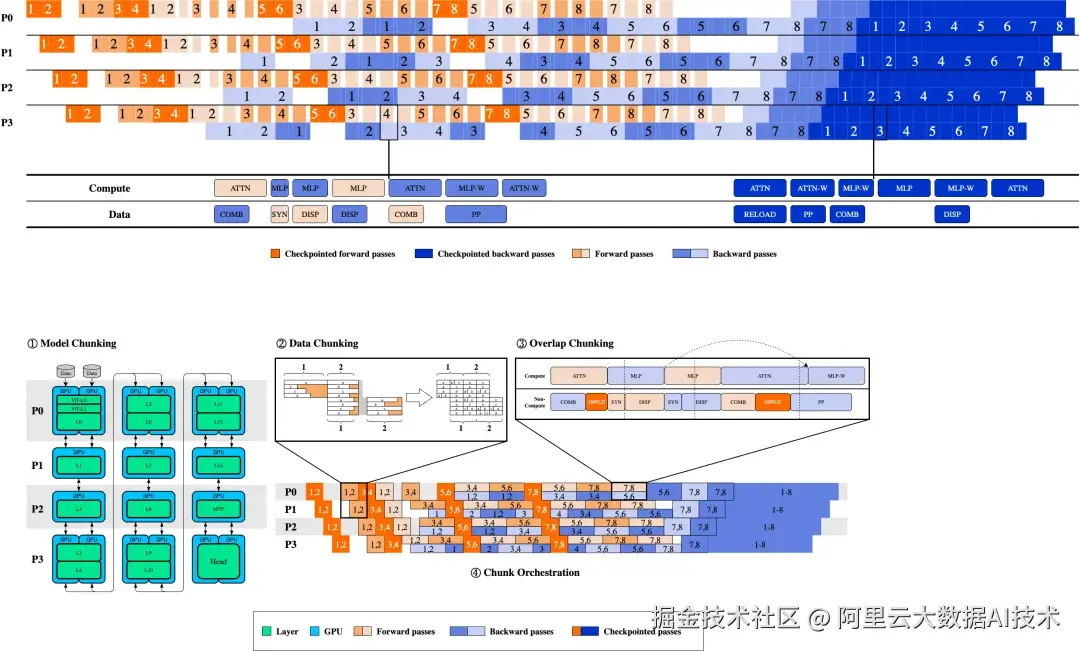
paiMoE
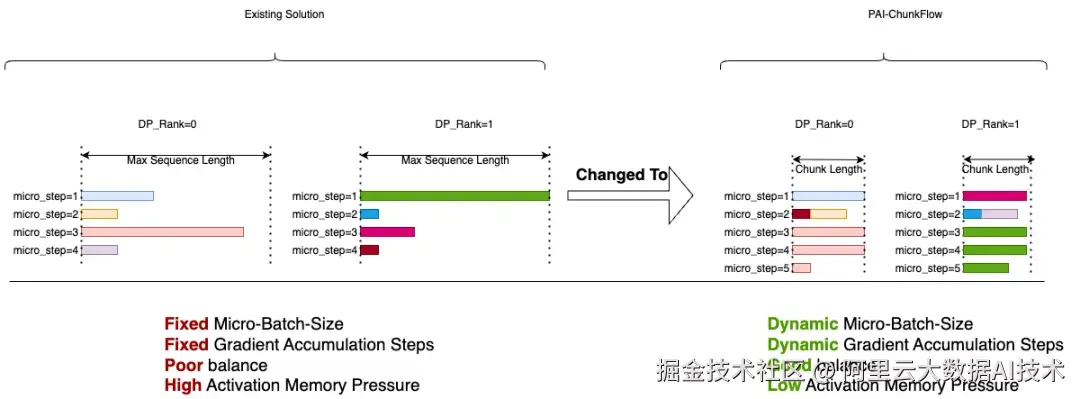
针对大规模 MoE 模型,PAI 提供 paiMoE 引擎。paiMoE 核心技术含 MoE 高性能训练优化 Tangram 和 长序列训练优化 ChunkFlow,通过统一调度机制、自适应计算通信掩盖、EP计算负载均衡和计算显存分离式并行等方面深度优化,有效解决工作负载不同、稀疏 MoE 通信占比高等问题,实测达到 Qwen3 训练端到端加速比提效 3 倍。