一、groupByKey和reduceByKey的区别

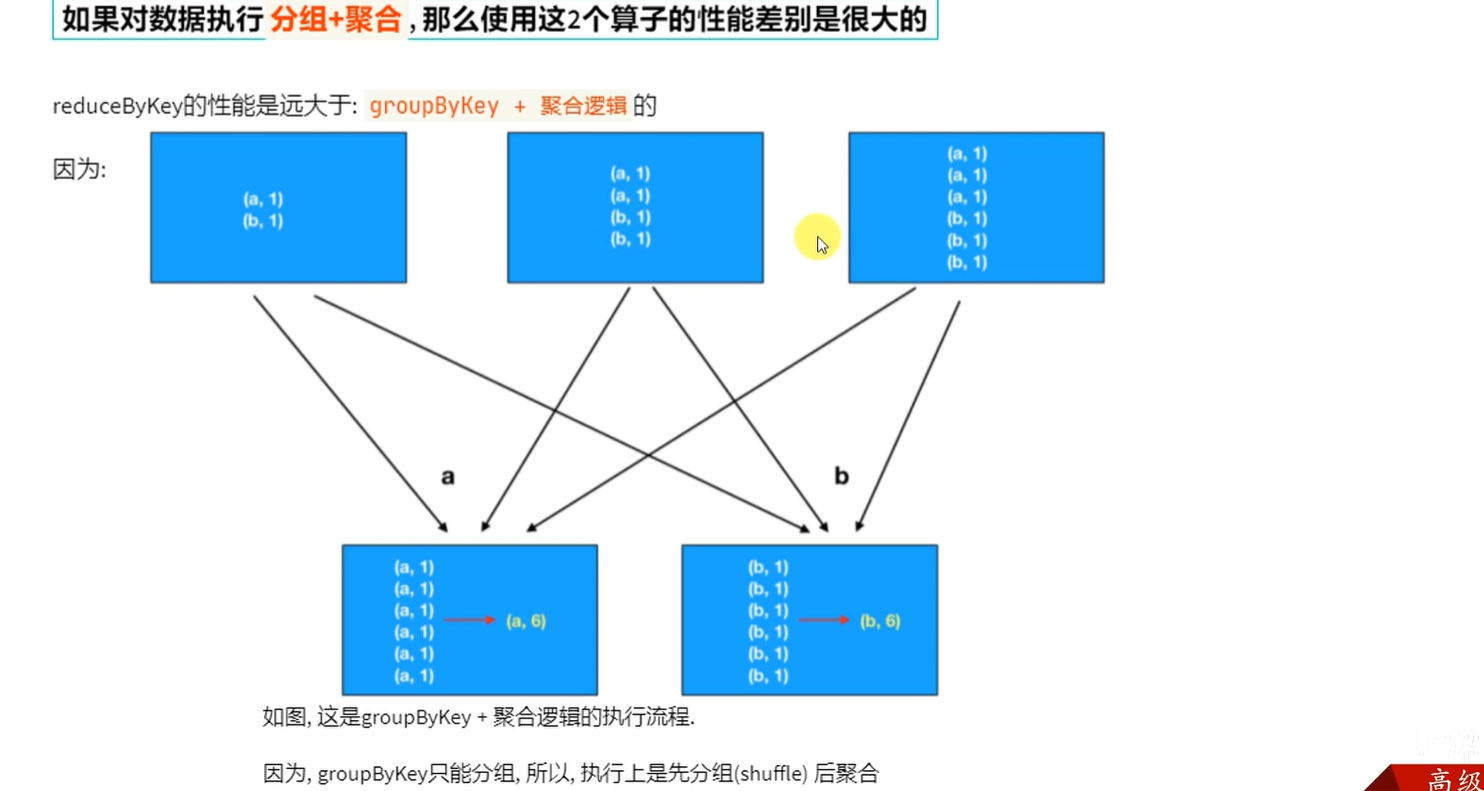
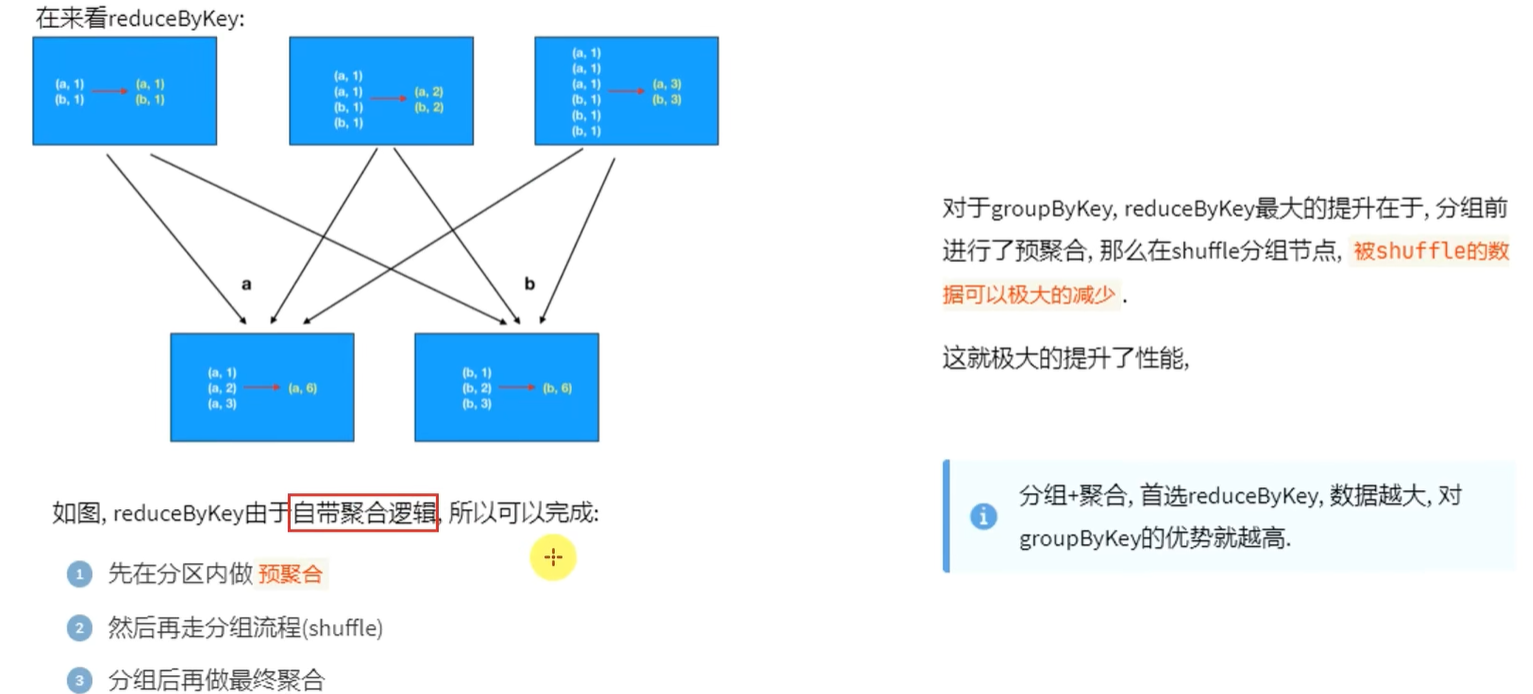
groupByKey仅仅只有分组功能,reduceByKey是先预聚合在shuffle在最终聚合,减少了网络io传输
二、关于数仓方面
数仓建设整体流程是什么?你参与哪些环节?
提出需求 需求分析 模型设计【概念模型、逻辑模型】 实施【ETL、MAPPING、写SQL】测试 上线
参与了实施【ETL、MAPPING、写SQL】测试也就是写sql
在数据仓库(数仓)建设的语境中,Mapping(映射) 是指明确源系统数据与目标数据仓库模型中数据之间的对应关系。
具体来说,它要定义清楚:
源系统的哪些表、哪些字段,对应目标数仓模型里的哪个维度表、哪个事实表,以及哪个字段。
数据在从源系统向数仓转移过程中,需要进行怎样的转换(比如数据类型转换、业务规则转换等),才能适配数仓模型的要求。
简单讲,Mapping 就像一份 "数据搬运与改造的说明书",指导 ETL(提取、转换、加载)过程中数据如何从源头准确、合规地进入数仓。
三、SparkContext 和 SparkSession 有什么区别?
SparkContext:整个应用的上下文,控制应用的生命周期。
SparkSession:是在Spark2.0中引入的,它使开发人员可以轻松的使用它,这样我们就不用担心不同的上下文,并简化了对不同上下文的访问。通过访问SparkSession,我们可以自动访问SparkContext
四、Spark是怎么做内存计算的?DAG的作用?Stage阶段划分的作用?

根据宽窄依赖关系划分阶段时,每遇到一个宽依赖就划分,这样就可以保证每一个阶段内都是窄依赖。
五、Spark为什么比MapReduce快

Spark有更多的算子,Spark可以基于内存迭代,MapReduce是通过硬盘来交互。