✨作者主页 :IT毕设梦工厂✨
个人简介:曾从事计算机专业培训教学,擅长Java、Python、PHP、.NET、Node.js、GO、微信小程序、安卓Android等项目实战。接项目定制开发、代码讲解、答辩教学、文档编写、降重等。
文章目录
一、前言
本系统基于大数据技术,结合丙型肝炎患者的临床数据,提供了一个全面的数据可视化分析平台。该平台通过Hadoop和Spark技术,处理并分析患者的大规模数据集,采用Python和Java开发,并通过Django和Spring Boot后端框架提供数据处理和服务。前端则使用Vue、ElementUI以及ECharts进行用户界面的构建与数据可视化展示,支持用户在不同维度上对患者的基础特征、生化指标及疾病进展进行深度分析。通过系统,用户可以直观地获取丙型肝炎患者的年龄、性别、疾病进展阶段等信息,辅助临床决策并为公共卫生政策的制定提供数据支持。
选题背景
丙型肝炎是由丙型肝炎病毒(HCV)引起的疾病,通常以慢性肝病的形式存在,且多为无症状的长期潜伏期。这使得患者常常在没有明显症状的情况下发展至肝硬化甚至肝癌,给公共健康带来了极大的挑战。随着大数据技术和人工智能的发展,数据驱动的疾病管理和早期预警系统成为改善肝炎防治的重要工具。然而,由于传统方法在处理海量复杂数据方面的局限性,基于大数据的健康管理模式尚处于探索阶段。丙型肝炎患者的诊断、治疗和疾病进展监测依赖于患者的基础特征、生化指标及其他多维度数据,这使得多层次的数据整合与分析尤为重要。
选题意义
本课题旨在通过大数据和数据可视化技术,构建丙型肝炎患者的综合分析平台。通过对患者群体的年龄、性别、疾病分类等基础信息进行分析,揭示丙型肝炎的疾病分布特点,帮助制定更有针对性的预防和治疗策略。此外,通过对生化指标和疾病进展的深入分析,可以为医生提供量化的风险评估,支持个性化治疗方案的制定。对于公共卫生领域而言,本系统不仅能够为丙型肝炎的管理提供数据支持,还可以为相关部门提供决策依据,推动疾病防控工作更加精准化、高效化。在实际应用中,系统能够有效提高临床诊断和治疗的效率,同时为科学研究提供丰富的数据基础。
二、开发环境
- 大数据框架:Hadoop+Spark(本次没用Hive,支持定制)
- 开发语言:Python+Java(两个版本都支持)
- 后端框架:Django+Spring Boot(Spring+SpringMVC+Mybatis)(两个版本都支持)
- 前端:Vue+ElementUI+Echarts+HTML+CSS+JavaScript+jQuery
- 详细技术点:Hadoop、HDFS、Spark、Spark SQL、Pandas、NumPy
- 数据库:MySQL
三、系统界面展示
- 基于大数据的丙型肝炎患者数据可视化分析系统界面展示:
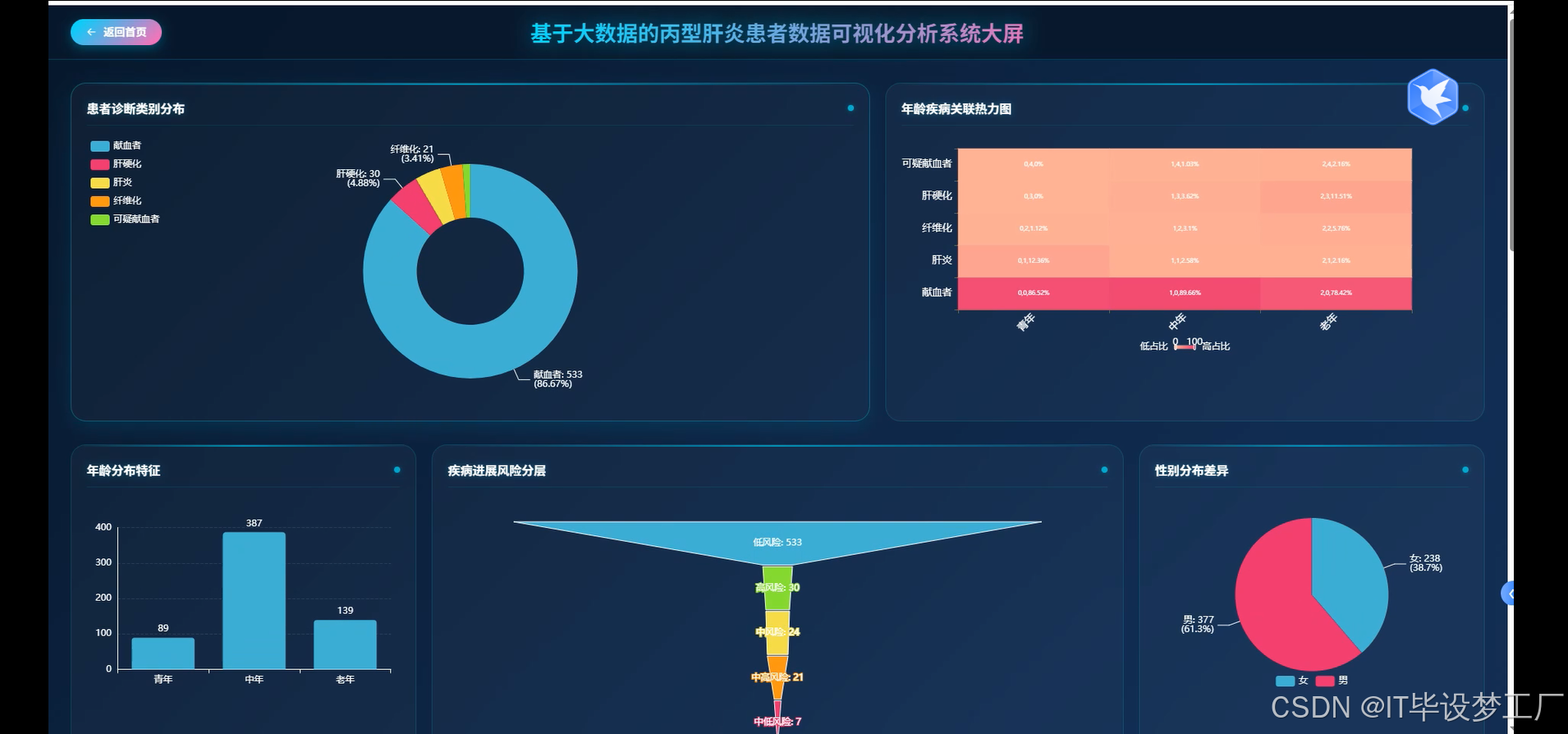
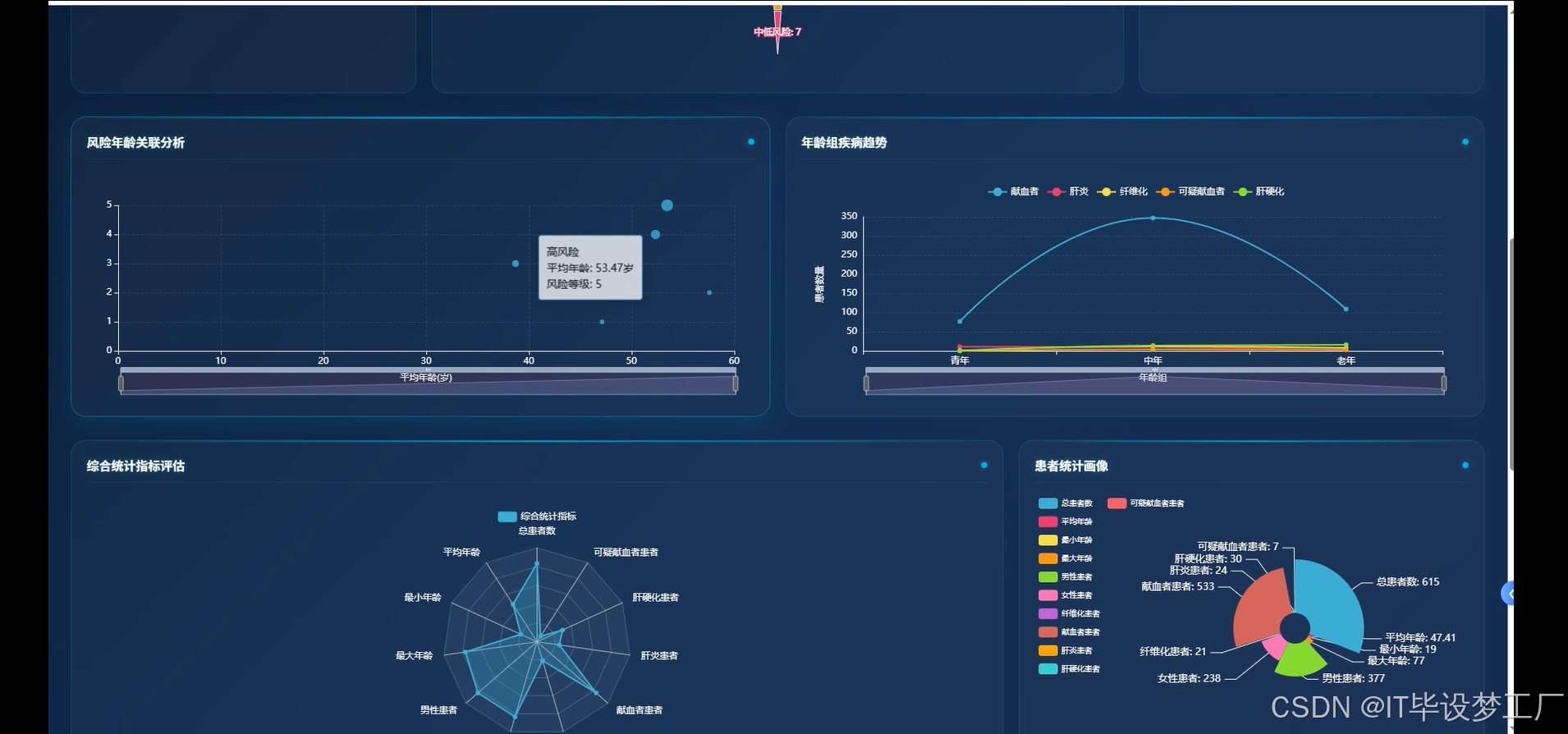
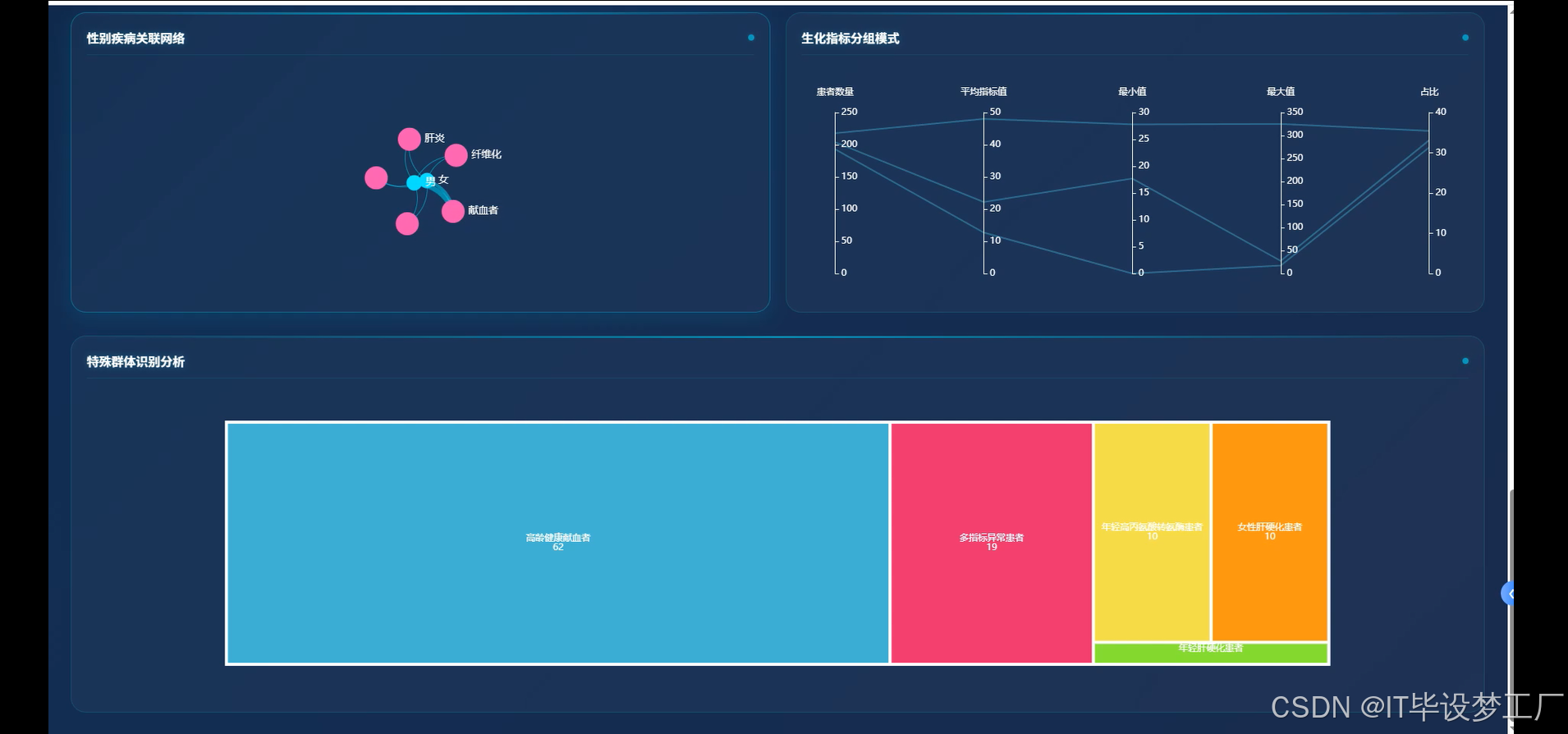
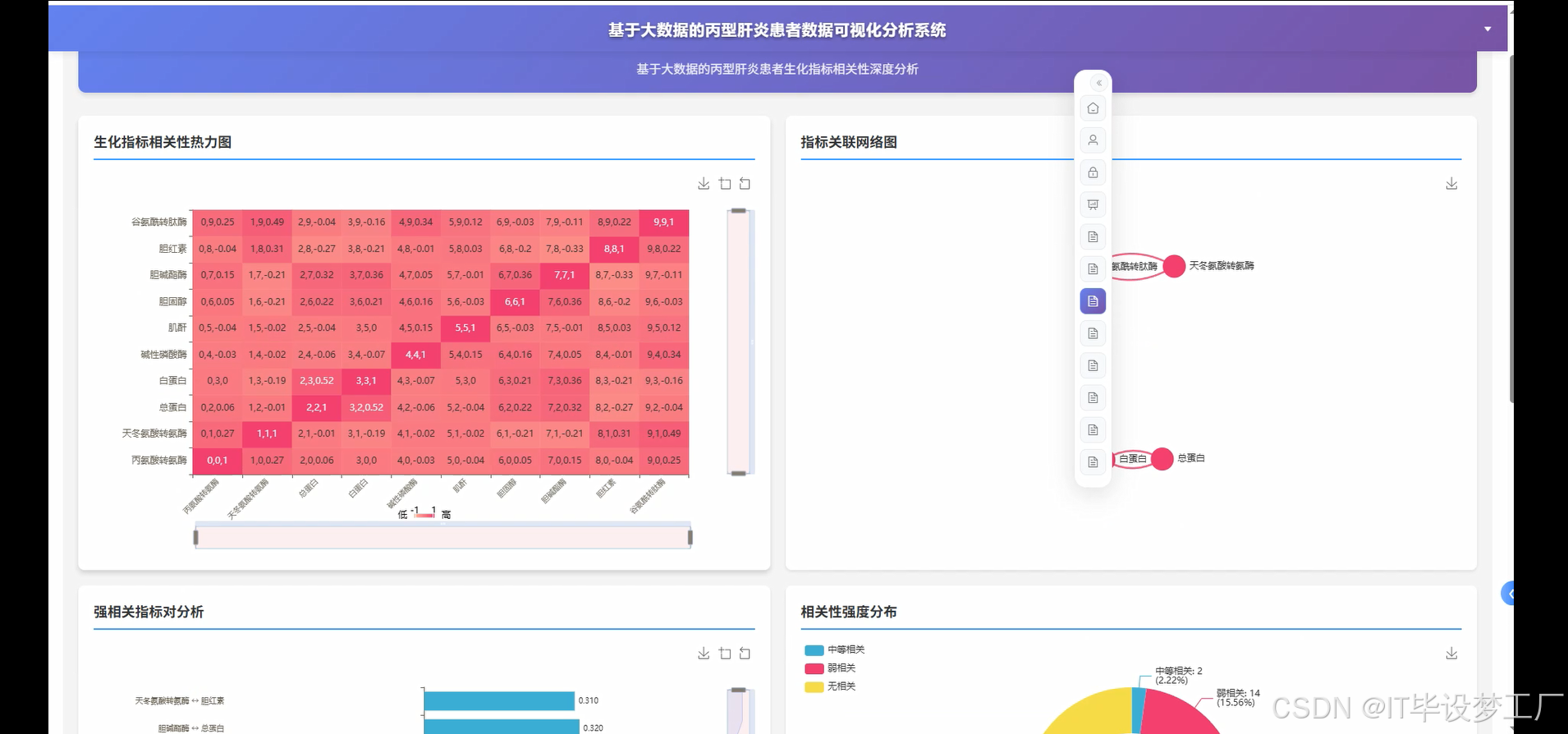
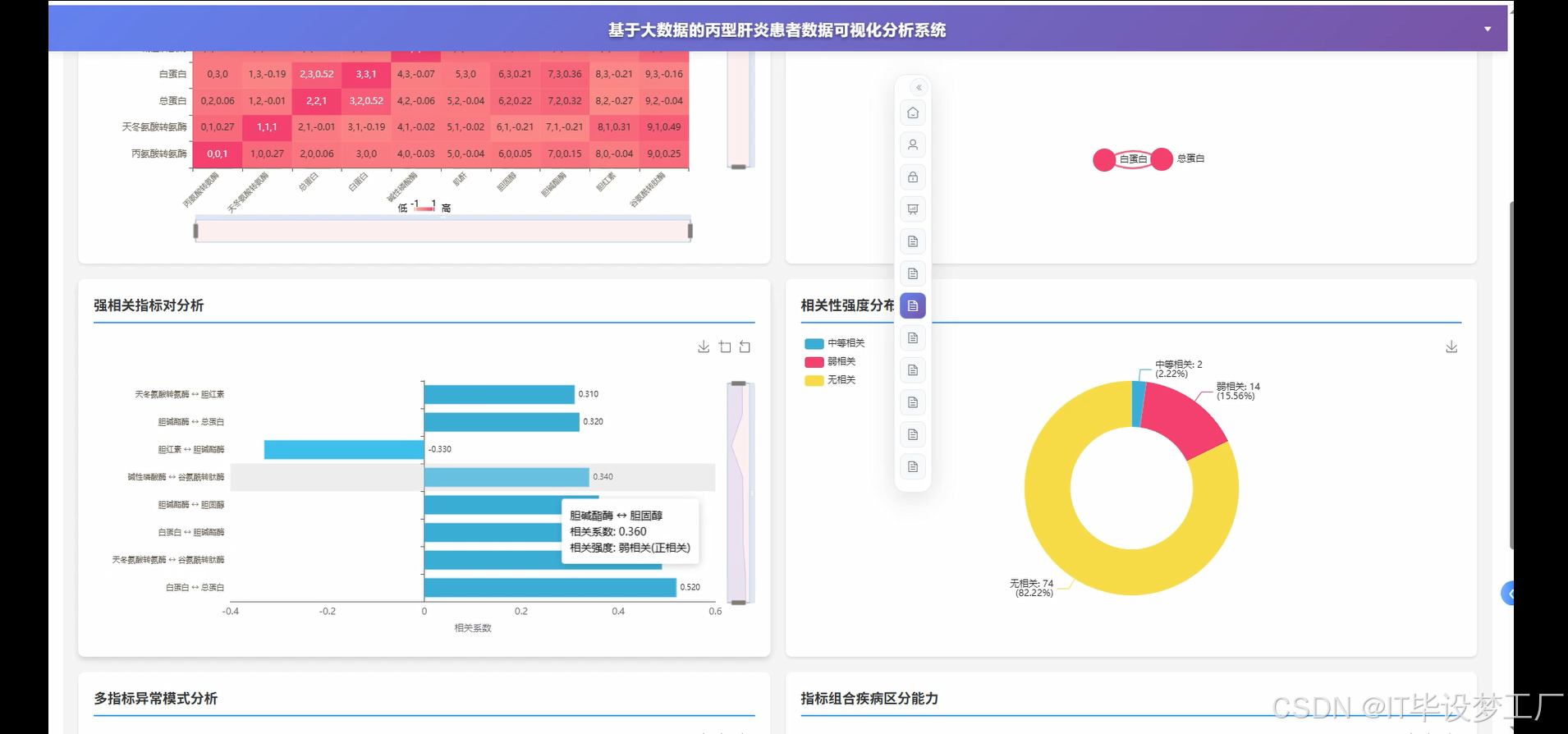
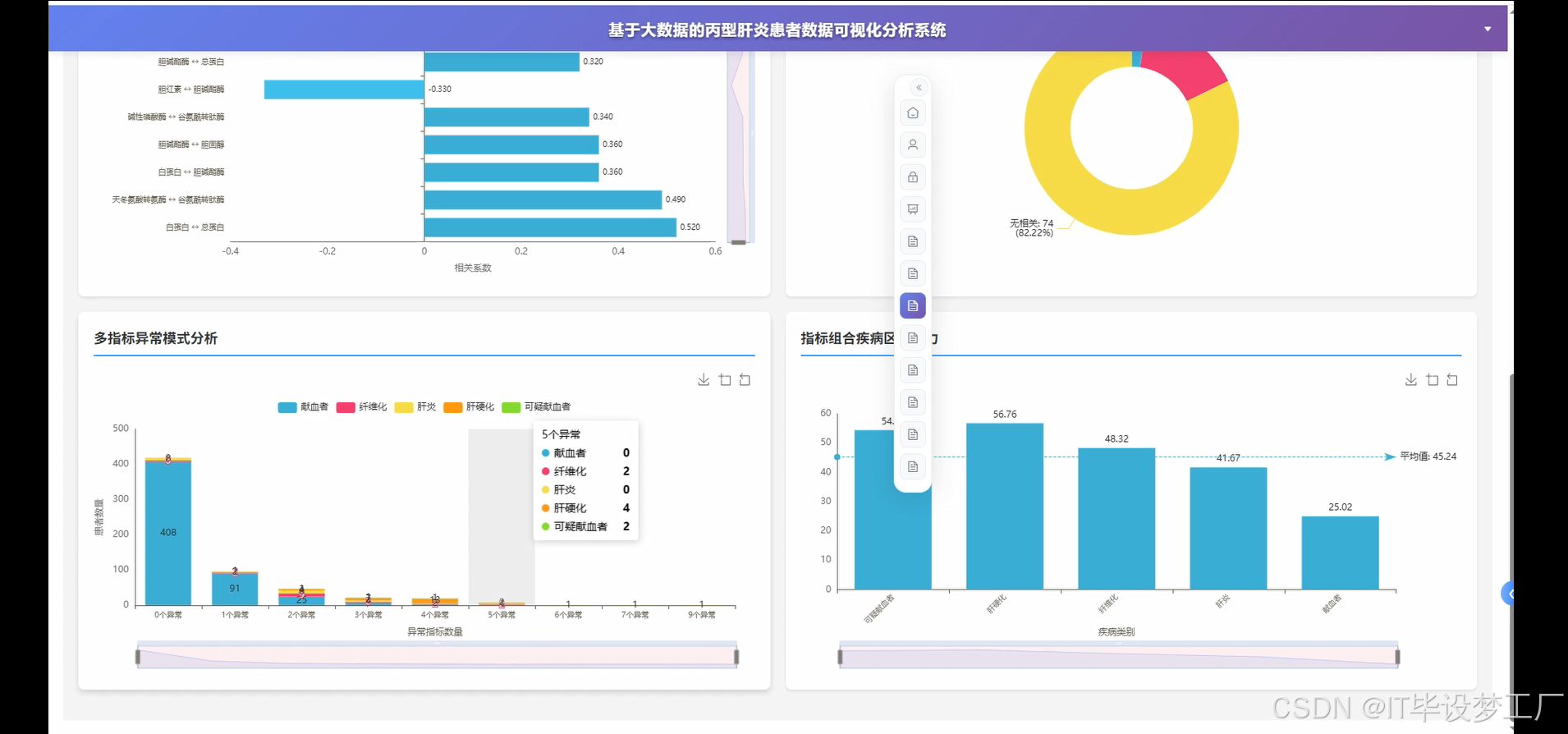
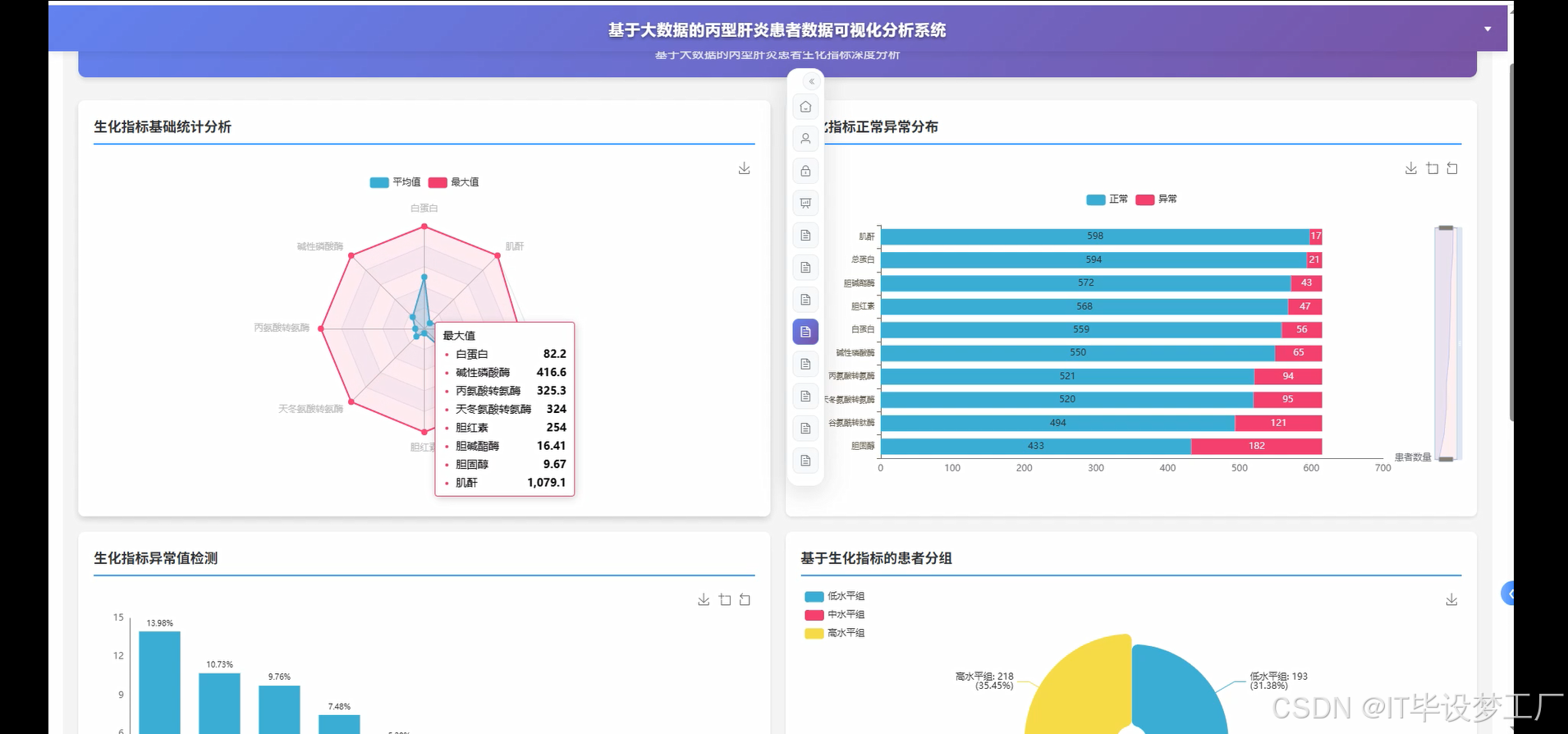
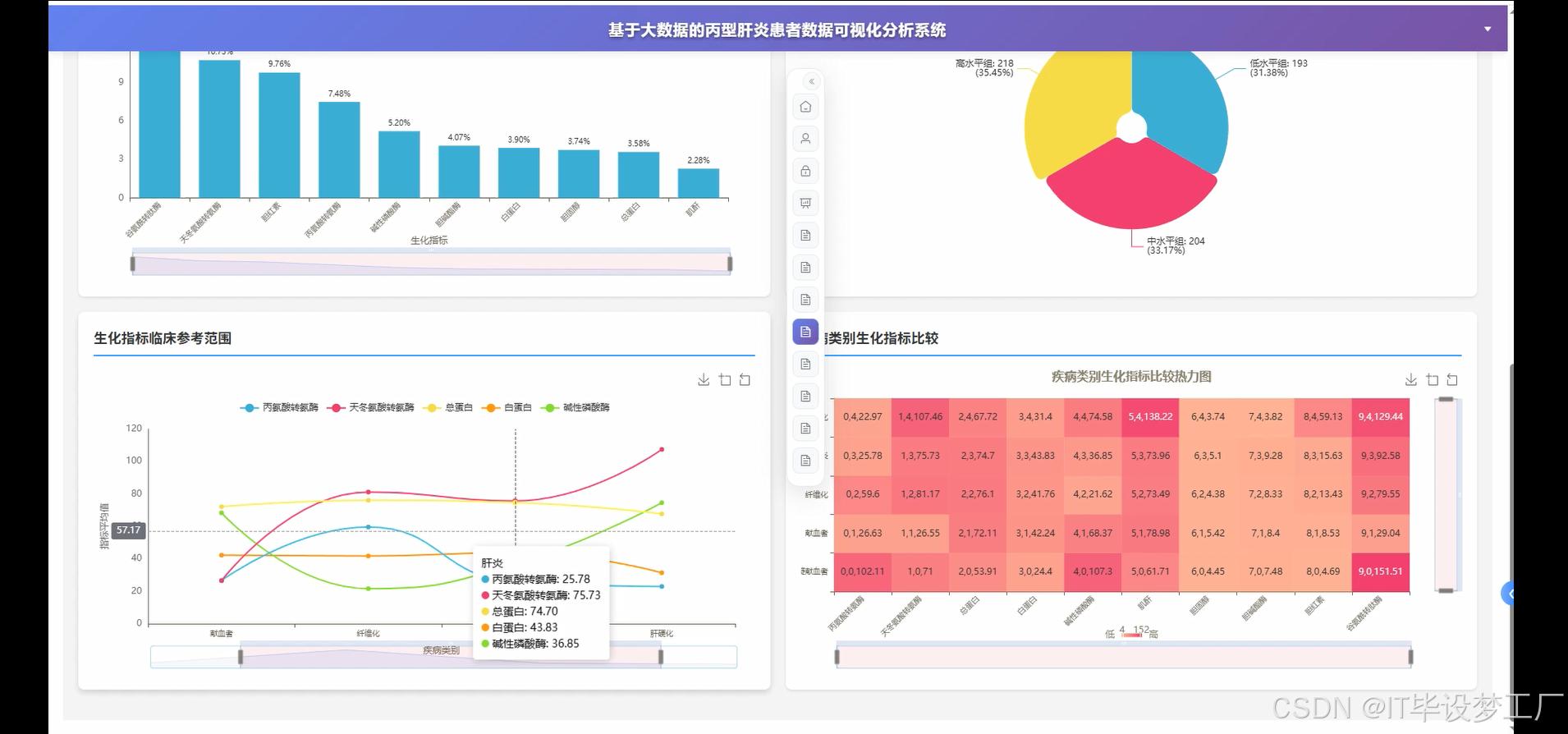
四、部分代码设计
- 项目实战-代码参考:
java(贴上部分代码)
from pyspark.sql import SparkSession
import pandas as pd
# 使用SparkSession初始化
spark = SparkSession.builder.appName("HepatitisAnalysis").getOrCreate()
def analyze_patient_age_distribution(data):
df = spark.read.csv(data, header=True, inferSchema=True)
df.createOrReplaceTempView("patients")
query = """
SELECT Age, COUNT(*) as patient_count
FROM patients
GROUP BY Age
ORDER BY Age
"""
result = spark.sql(query)
result_pd = result.toPandas()
return result_pd
java(贴上部分代码)
def analyze_biochemical_abnormalities(data):
df = spark.read.csv(data, header=True, inferSchema=True)
df.createOrReplaceTempView("biochemicals")
query = """
SELECT Category, AVG(ALB) as avg_ALB, AVG(ALP) as avg_ALP,
AVG(ALT) as avg_ALT, AVG(AST) as avg_AST
FROM biochemicals
GROUP BY Category
"""
result = spark.sql(query)
result_pd = result.toPandas()
return result_pd
java(贴上部分代码)
def analyze_disease_progression_by_age(data):
df = spark.read.csv(data, header=True, inferSchema=True)
df.createOrReplaceTempView("patients")
query = """
SELECT Age, Category, COUNT(*) as patient_count
FROM patients
GROUP BY Age, Category
ORDER BY Age, Category
"""
result = spark.sql(query)
result_pd = result.toPandas()
return result_pd五、系统视频
- 基于大数据的丙型肝炎患者数据可视化分析系统-项目视频:
大数据毕业设计选题推荐-基于大数据的丙型肝炎患者数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
结语
大数据毕业设计选题推荐-基于大数据的丙型肝炎患者数据可视化分析系统-Hadoop-Spark-数据可视化-BigData
想看其他类型的计算机毕业设计作品也可以和我说都有 谢谢大家!
有技术这一块问题大家可以评论区交流或者私我~
大家可以帮忙点赞、收藏、关注、评论啦~
源码获取:⬇⬇⬇