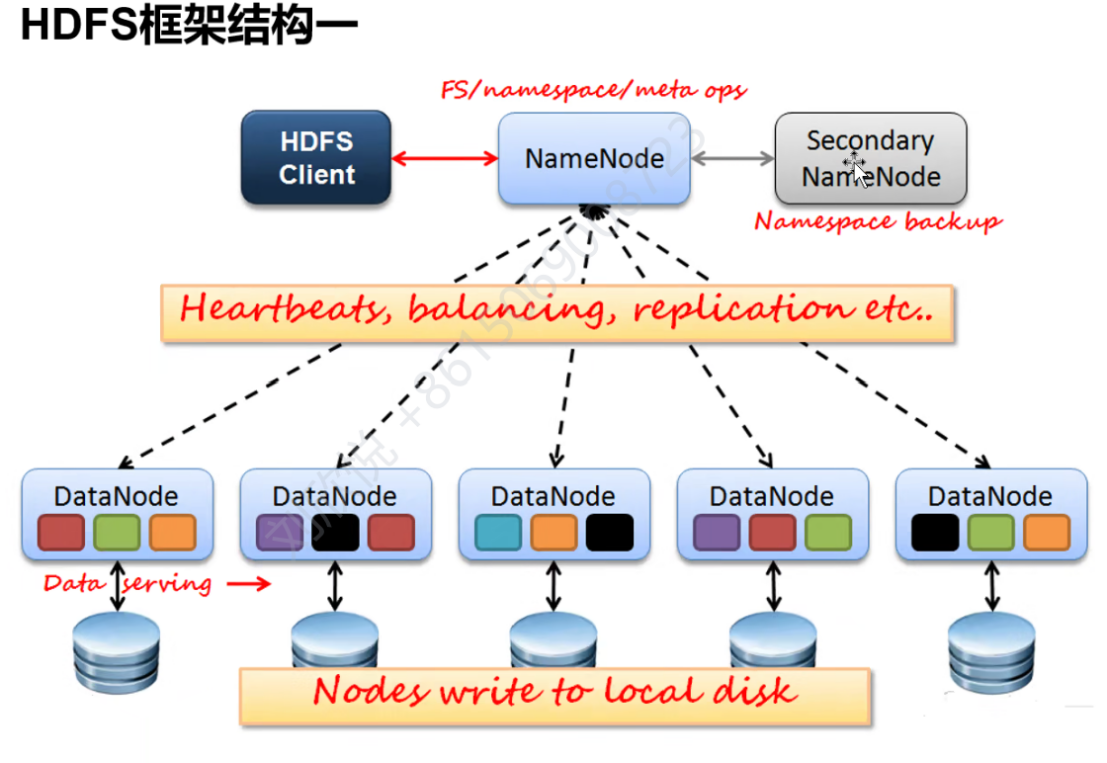
Namenode是整个HDFS文件系统的前端,只有一个,管理数据块映射信息,配置副本策略,处理客户端的读写请求。
Secondary namenode是namenode的热备,当active namenode出现故障时,快速切换为新的active namenode。定期更新系统镜像和操作日志。
Datanode有多个,存储数据块,执行数据块读写。
HDFS client与文件系统进行交互。
文件被切分成数据块,分布存储,默认情况下每个块有三个副本。
HDFS不适合保存小文件。一个k和一个t数据块的元数据大小是相同的,元数据会存储在namenode,但namenode内存是有限的。大小文件的访问速度相同,存取大量小文件浪费很多寻道时间。