个人主页:chian-ocean
专栏
引言
人工智能技术和大数据的发展,实时访问网页数据成为许多应用的核心需求。相比传统方案依赖静态或定期更新的数据,AI可以实时抓取和分析网页上的及时更新的信息,迅速适应变化的环境,提取重要的信息。传统方案的局限性在于数据的时效性和灵活性比较差 ,无法及时反映信息的变化,而AI获取实时数据获取能力使其在动态场景中具有很好的优点了。
传统的网页爬虫虽然能够抓取数据,但在实际落地时存在以下痛点:
-
实现复杂:动态网页需要模拟浏览器环境,涉及大量工程工作;
-
维护成本高:网页结构频繁变化,爬虫脚本易失效;
-
实时性不足:数据更新与响应速度难以满足 AI 场景需求。
为什么说AI和MCP是完美伴侣
这个问题我们拆开分析,从AI和MCP两个角度。
1. AI 的短板
-
缺乏实时性:LLM 的知识停留在训练数据时间点,无法直接访问最新网页内容。
-
无法直接抓取网页:模型不会解析 HTML、执行 JavaScript,更无法应对反爬。
-
上下文有限:需要额外数据源,才能生成更精准答案。
2. MCP 的长板
-
实时网页访问能力:可获取静态页面与动态页面(JS 渲染内容)。
-
对开发者友好:统一 API,免去维护复杂爬虫的负担。
-
稳定可靠:内置反爬、并发和大规模请求处理机制
针对这些问题,Bright Data MCP 提供了一套面向开发者的 Web 数据访问 API。它不仅支持静态与动态网页抓取,还具备以下特性:
-
即插即用,降低开发与维护门槛;
-
每月 5,000 次请求免费额度(前三个月免费),适合快速验证;
-
支持 SSE(Server-Sent Events) 与标准 HTTP 请求,方便与现有系统集成;
-
提供远程托管与本地部署两种方式,分别满足入门开发者与高级用户需求。
总的来说: AI + MCP = 实时、智能、稳定的应用

获取 Bright Data 的 Json 以及 API-token
(点击)Bright Data随后进行注册,按照指引登录上就好了。
获取API-KEY
- 找到登录界面,点击账户设置就可以看到自己的API-KEY了
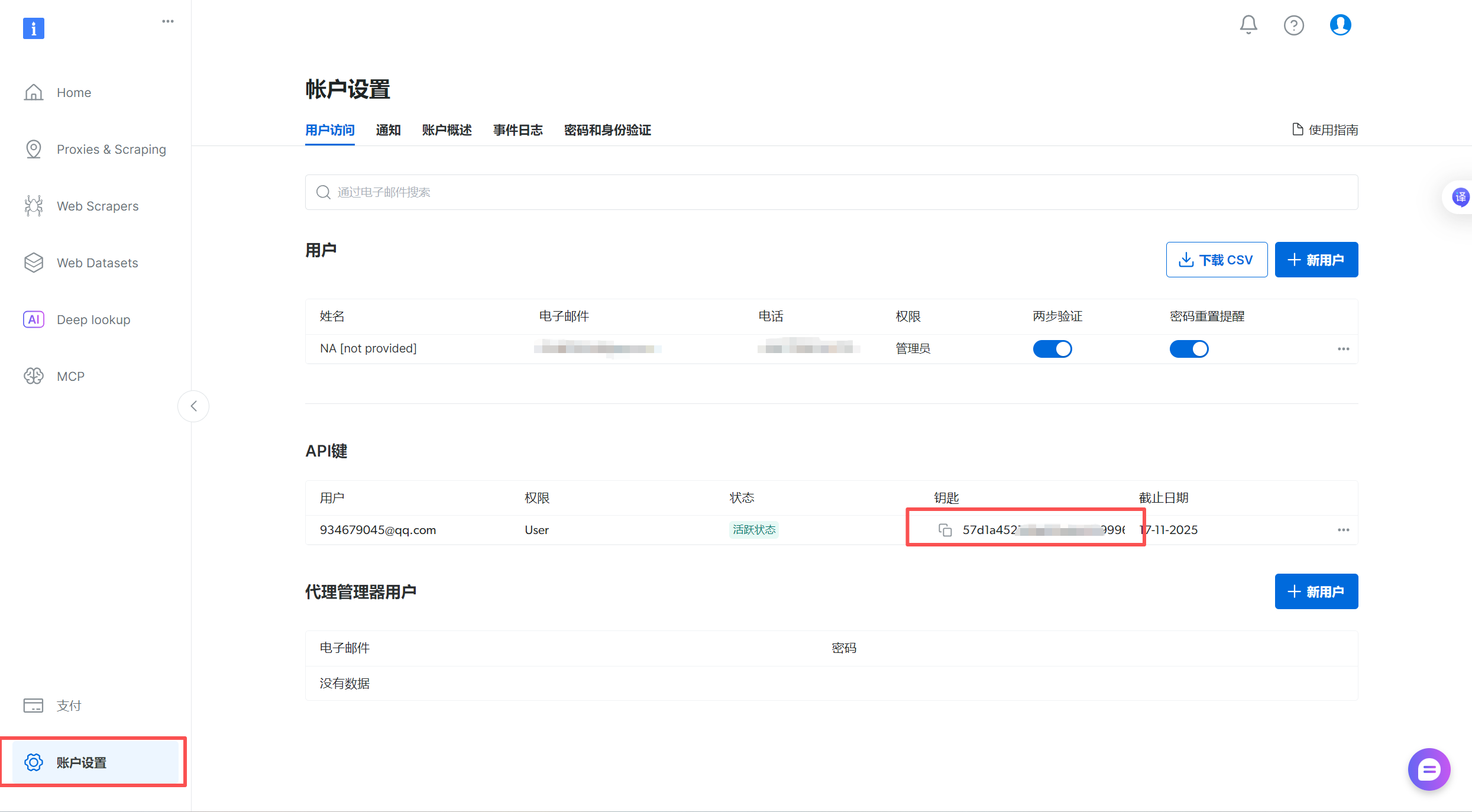
获取JSON串
中间黑色框框就是json串
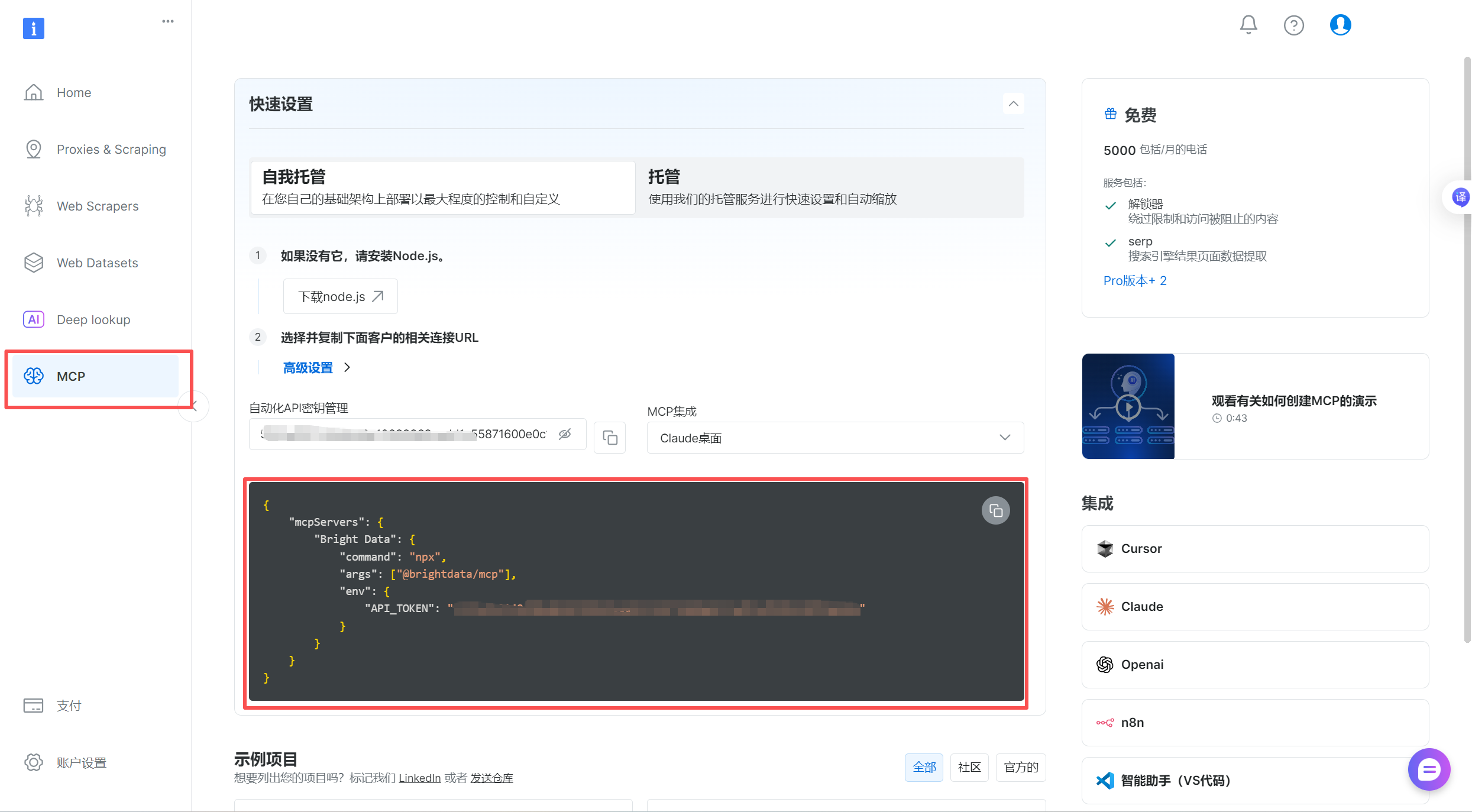
json
{
"mcpServers": {
"Bright Data": {
"command": "npx",
"args": ["@brightdata/mcp"],
"env": {
"API_TOKEN": "xxxxxxxxxxxxxxxxxxx" //这里是上面的API-KEY
}
}
}
}
高级选项设置
-
解锁区:控制代理 IP 的地区,让你的请求看起来像来自目标地区(比如美国、德国),突破网站的地区限制。
-
浏览器区域:模拟目标地区的浏览器环境(比如时区、语言),让请求更像真实用户,减少被网站识别为爬虫的概率。
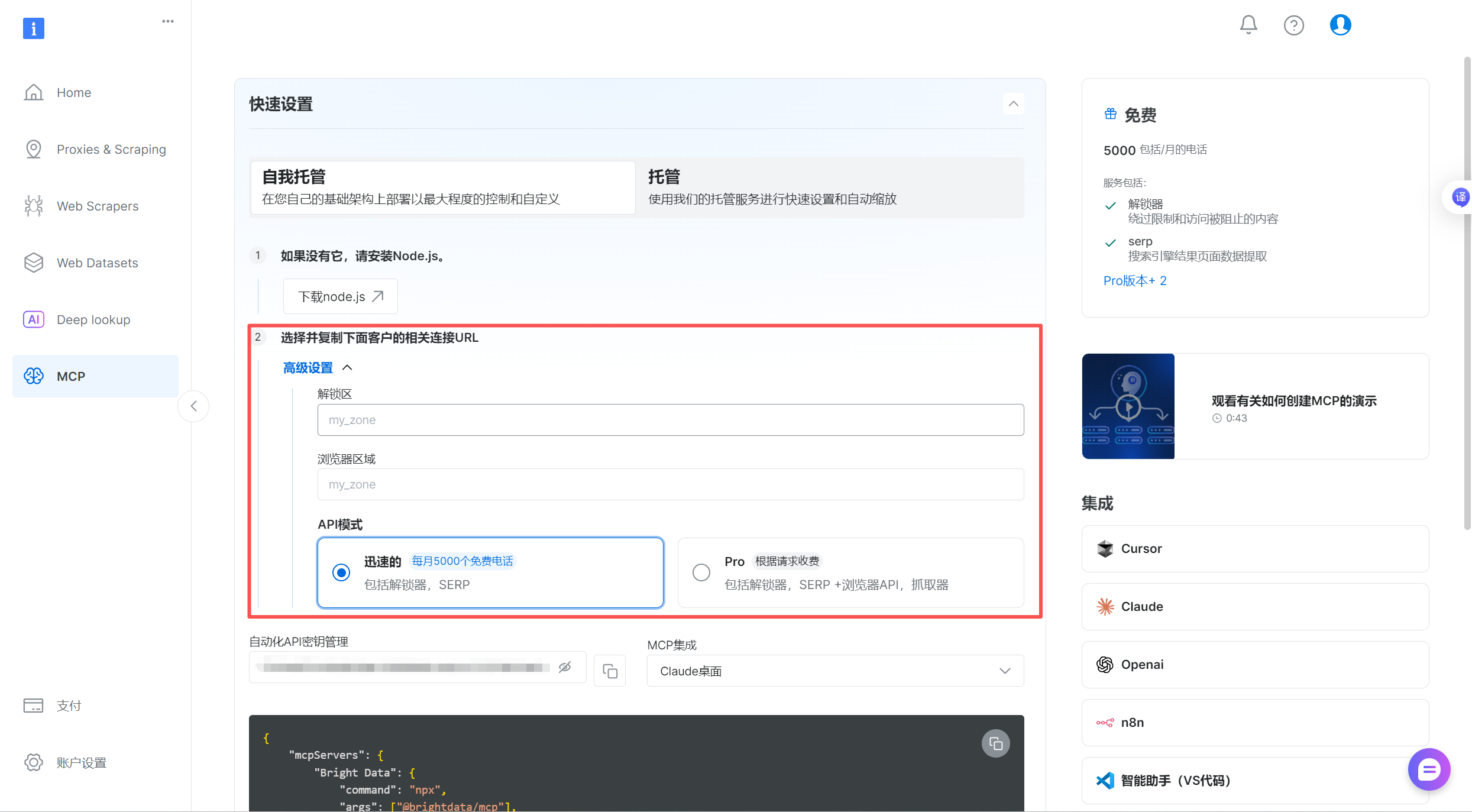
这点就提供了稳定可靠的反扒机制,举个例子:
- 配合美国 IP,将浏览器区域设为
US/en(美国时区 + 英语),让请求更像 "真实美国用户"; - 爬取德国网站时,设为
DE/de(德国时区 + 德语),避免因环境矛盾被拦截。
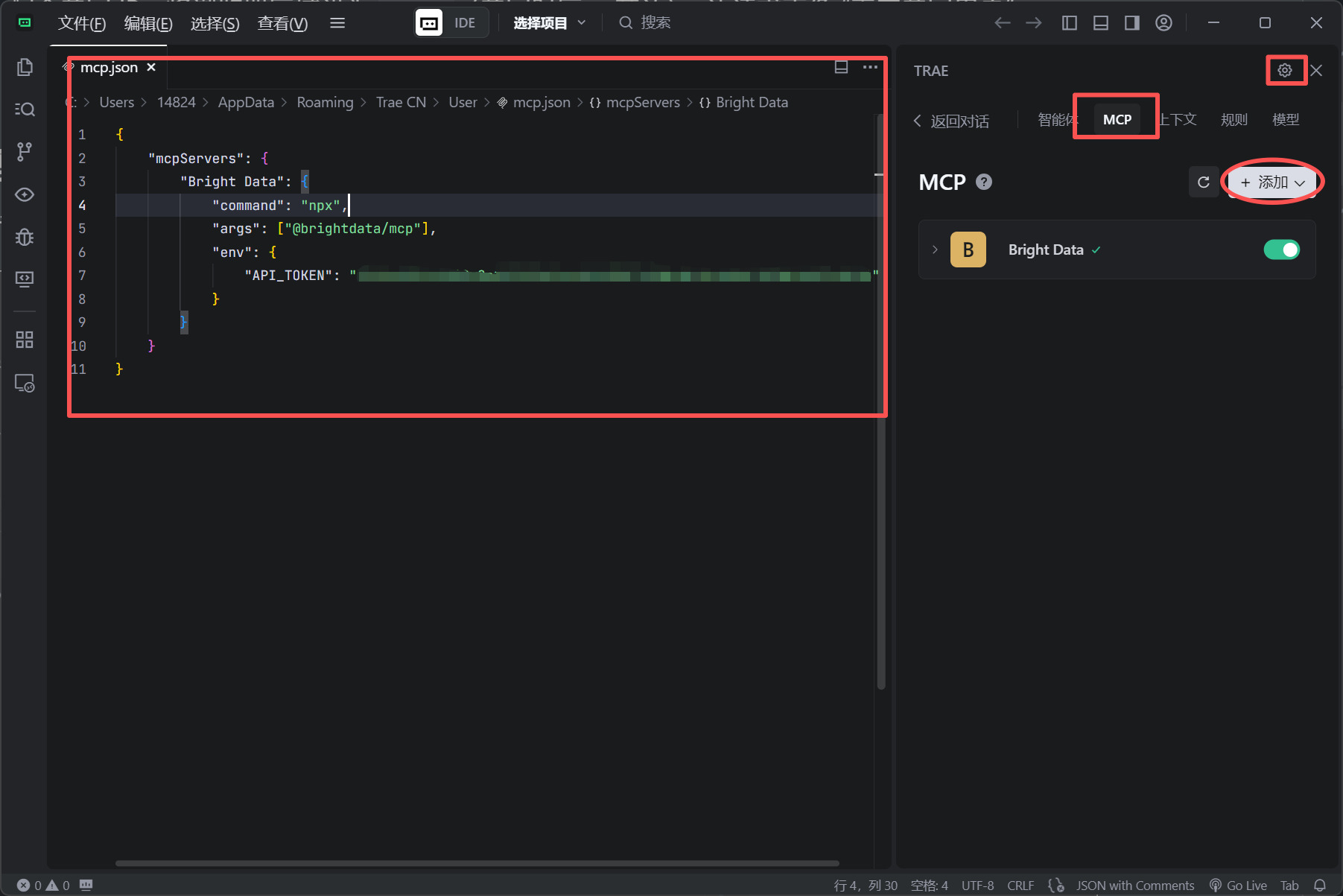
调用API接口
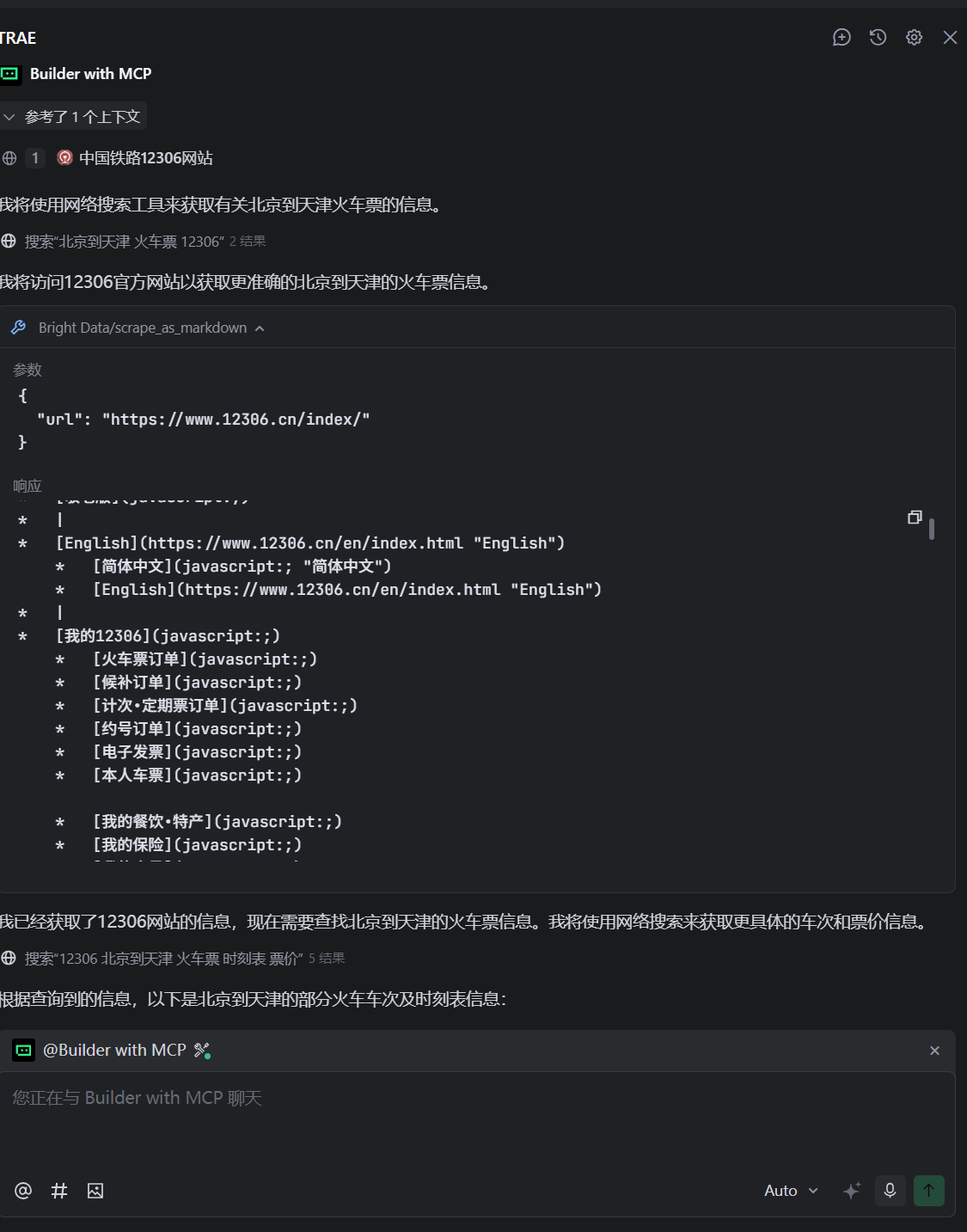
这里面用Trae打开,进入主界面,看右上角的锯齿的符号,配置添加MCP,左边mcp.json直接添加就好了,当Bright Data 显示对勾就显示连接上了。
json
{
"url": "https://www.12306.cn/index/" //这个是12306 网站
}下面进行获取和相应,效果还是非常明显的。
使用 Python 调用 MCP 实时抓取 Google 搜索结果(源码)
文件目录结构
cpp
├── 📄 config.py # 配置管理模块
├── 📄 example.py # 使用示例脚本
├── 📄 install_mcp.py # MCP 服务器安装助手
├── 📄 mcp_client.py # MCP 客户端核心模块
├── 📄 mcp_google_search.py # Google 搜索客户端
├── 📄 MCP_INSTALL_GUIDE.md # MCP 安装指南文档
├── 📄 README.md # 项目说明文档
├── 📄 requirements.txt # Python 依赖包列表
├── 📄 search_cli.py # 命令行搜索工具
└── 📄 test_mcp_client.py # 测试脚本简单总结就是:
-
核心模块(mcp_client、config 等)
-
搜索功能扩展(mcp_google_search、search_cli)
-
安装与示例(install_mcp、example)
-
文档说明(README、MCP_INSTALL_GUIDE)
-
依赖与测试(requirements、test_mcp_client)
项目架构
cpp
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ search_cli.py │ │ example.py │ │test_mcp_client.py│
│ (命令行工具) │ │ (使用示例) │ │ (测试脚本) │
└─────────┬───────┘ └─────────┬───────┘ └─────────┬───────┘
│ │ │
└──────────────────────┼──────────────────────┘
│
┌─────────────▼───────────────┐
│ mcp_client.py │
│ (MCP 客户端核心) │
└─────────────┬───────────────┘
│
┌─────────────▼───────────────┐
│ mcp_google_search.py │
│ (Google 搜索功能) │
└─────────────┬───────────────┘
│
┌─────────────▼───────────────┐
│ config.py │
│ (配置管理) │
└─────────────────────────────┘客户端主程序
python
"""
真正的 MCP 客户端,用于与 Bright Data MCP 服务器通信
"""
import os
import json
import asyncio
import logging
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
logger = logging.getLogger(__name__)
@dataclass
class SearchResult:
"""搜索结果数据类"""
title: str
url: str
snippet: str
position: int
source: str = "brightdata_mcp"
class BrightDataMCPClient:
"""真正的 Bright Data MCP 客户端"""
def __init__(self, api_token: Optional[str] = None):
"""
初始化 MCP 客户端
Args:
api_token: Bright Data API Token
"""
self.api_token = api_token or "57d1a452149d90e8e10399969cedd1c55871600e0c12ed12ef870b448f9a8c06" //这里是我的APIKEY
self.process = None
async def __aenter__(self):
"""异步上下文管理器入口"""
await self.connect()
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
"""异步上下文管理器出口"""
await self.disconnect()
async def connect(self):
"""连接到 MCP 服务器"""
try:
env = dict(os.environ)
env["API_TOKEN"] = self.api_token
self.process = await asyncio.create_subprocess_exec(
"npx", "@brightdata/mcp",
stdin=asyncio.subprocess.PIPE,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.PIPE,
env=env
)
logger.info("已连接到 Bright Data MCP 服务器")
except Exception as e:
logger.error(f"连接 MCP 服务器失败: {e}")
raise
async def disconnect(self):
"""断开 MCP 服务器连接"""
if self.process:
self.process.terminate()
await self.process.wait()
logger.info("已断开 MCP 服务器连接")
async def send_request(self, method: str, params: Dict[str, Any]) -> Dict[str, Any]:
"""发送 MCP 请求"""
if not self.process:
raise RuntimeError("MCP 服务器未连接")
request = {
"jsonrpc": "2.0",
"id": 1,
"method": method,
"params": params
}
request_json = json.dumps(request) + "\n"
try:
if self.process.stdin is None:
raise RuntimeError("进程的 stdin 不可用")
if self.process.stdout is None:
raise RuntimeError("进程的 stdout 不可用")
self.process.stdin.write(request_json.encode())
await self.process.stdin.drain()
response_line = await self.process.stdout.readline()
response = json.loads(response_line.decode().strip())
if "error" in response:
raise RuntimeError(f"MCP 错误: {response['error']}")
return response.get("result", {})
except Exception as e:
logger.error(f"MCP 请求失败: {e}")
raise
async def search(self, query: str, num_results: int = 10, lang: str = "zh-CN") -> List[SearchResult]:
"""
执行搜索
Args:
query: 搜索查询
num_results: 结果数量
lang: 搜索语言
Returns:
搜索结果列表
"""
try:
params = {
"query": query,
"num_results": min(num_results, 20),
"language": lang,
"country": "CN" if lang == "zh-CN" else "US"
}
result = await self.send_request("search", params)
return self._parse_search_results(result)
except Exception as e:
logger.error(f"搜索失败: {e}")
# 返回模拟结果作为后备
return self._get_mock_results(query, num_results)
def _parse_search_results(self, data: Dict[str, Any]) -> List[SearchResult]:
"""解析搜索结果"""
results = []
if "organic_results" in data:
for i, item in enumerate(data["organic_results"]):
result = SearchResult(
title=item.get("title", ""),
url=item.get("url", ""),
snippet=item.get("snippet", ""),
position=i + 1,
source="brightdata_mcp"
)
results.append(result)
return results
def _get_mock_results(self, query: str, num_results: int) -> List[SearchResult]:
"""获取模拟搜索结果(当 MCP 不可用时)"""
mock_data = [
{
"title": f"关于 '{query}' 的搜索结果 - 百度百科",
"url": f"https://baike.baidu.com/search?word={query}",
"snippet": f"这是关于 {query} 的详细介绍和相关信息。包含定义、特点、应用等内容。"
},
{
"title": f"{query} - 维基百科",
"url": f"https://zh.wikipedia.org/wiki/{query}",
"snippet": f"{query} 是一个重要的概念,在多个领域都有应用。本文详细介绍了其历史、发展和现状。"
},
{
"title": f"{query} 官方网站",
"url": f"https://www.{query.lower().replace(' ', '')}.com",
"snippet": f"欢迎访问 {query} 官方网站,了解最新信息、产品和服务。"
}
]
results = []
for i, item in enumerate(mock_data[:num_results]):
result = SearchResult(
title=item['title'],
url=item['url'],
snippet=item['snippet'],
position=i + 1,
source="mock_data"
)
results.append(result)
return results
# 为了向后兼容,保留旧的类名
MCPGoogleSearchClient = BrightDataMCPClient
class MockMCPSearchClient(BrightDataMCPClient):
"""模拟 MCP 客户端,用于演示"""
def __init__(self):
super().__init__("mock-token")
async def connect(self):
"""模拟连接"""
logger.info("使用模拟 MCP 客户端")
async def disconnect(self):
"""模拟断开连接"""
pass
async def search(self, query: str, num_results: int = 10, lang: str = "zh-CN") -> List[SearchResult]:
"""模拟搜索"""
return self._get_mock_results(query, num_results)
核心组件
-
SearchResult 数据类
- 用于存储搜索结果(标题、URL、摘要等)
- 使用
@dataclass装饰器实现
-
BrightDataMCPClient 类
- 真正的 MCP 客户端实现
- 通过子进程与 MCP 服务器通信
- 使用 JSON-RPC 2.0 协议发送请求
- 支持异步操作(async/await)
-
MockMCPSearchClient 类
- 模拟客户端,用于演示和测试
- 继承自 BrightDataMCPClient
- 不需要真实 MCP 服务器即可工作
README技术文档
rea
# MCP Google 搜索工具
这是一个使用 Python 调用 MCP API 实时抓取 Google 搜索结果的工具。
## 功能特性
- ✅ 异步 Google 搜索
- ✅ 实时搜索监控
- ✅ 模拟搜索演示
- ✅ 命令行工具
- ✅ 配置管理
- ✅ 错误处理和重试机制
## 安装依赖
```bash
pip install -r requirements.txt
```
## 配置 Google API
### 1. 获取 Google Custom Search API 密钥
1. 访问 [Google Cloud Console](https://console.developers.google.com/)
2. 创建新项目或选择现有项目
3. 启用 Custom Search API
4. 创建 API 密钥
### 2. 创建自定义搜索引擎
1. 访问 [Google Custom Search Engine](https://cse.google.com/)
2. 点击"添加"创建新的搜索引擎
3. 设置要搜索的网站(可以设置为整个网络)
4. 获取搜索引擎 ID
### 3. 设置环境变量
```bash
# Windows
set GOOGLE_API_KEY=你的API密钥
set GOOGLE_SEARCH_ENGINE_ID=你的搜索引擎ID
# Linux/Mac
export GOOGLE_API_KEY=你的API密钥
export GOOGLE_SEARCH_ENGINE_ID=你的搜索引擎ID
```
## 使用方法
### 1. 命令行工具
```bash
# 基本搜索(演示模式)
python search_cli.py "Python 教程" --demo
# 真实 Google 搜索
python search_cli.py "Python 教程" -n 5
# 实时搜索监控
python search_cli.py "Python 新闻" --realtime --interval 60
# 查看配置状态
python search_cli.py --config "test"
```
### 2. 编程接口
```python
import asyncio
from mcp_google_search import MCPGoogleSearchClient
async def main():
# 使用真实 API
async with MCPGoogleSearchClient(api_key="your_key", search_engine_id="your_id") as client:
results = await client.search("Python 教程", num_results=5)
for result in results:
print(f"{result.title}: {result.url}")
asyncio.run(main())
```
### 3. 模拟搜索演示
```python
import asyncio
from mcp_google_search import MockMCPSearchClient
async def demo():
async with MockMCPSearchClient() as client:
results = await client.search("Python", num_results=3)
for result in results:
print(f"{result.title}: {result.url}")
asyncio.run(demo())
```
## 命令行参数
```
positional arguments:
query 搜索查询关键词
optional arguments:
-h, --help 显示帮助信息
-n NUM, --num NUM 返回结果数量 (默认: 5, 最大: 10)
-l LANG, --lang LANG 搜索语言 (默认: zh-CN)
-d, --demo 使用演示模式 (模拟搜索)
-r, --realtime 启用实时搜索监控
-i INTERVAL, --interval INTERVAL
实时搜索间隔秒数 (默认: 30)
--iterations ITERATIONS
实时搜索最大迭代次数 (默认: 5)
--config 显示配置信息
```
## 使用示例
### 基本搜索
```bash
python search_cli.py "机器学习" --demo -n 3
```
### 实时监控
```bash
python search_cli.py "Python 新闻" --realtime -i 30 --iterations 10
```
### 中文搜索
```bash
python search_cli.py "人工智能" -l zh-CN -n 5
```
## 文件结构
```
├── mcp_google_search.py # 主要搜索客户端
├── config.py # 配置管理
├── search_cli.py # 命令行工具
├── requirements.txt # 依赖包
└── README.md # 说明文档
```
## API 限制
- Google Custom Search API 每天免费 100 次查询
- 每次请求最多返回 10 个结果
- 需要有效的 API 密钥和搜索引擎 ID
## 错误处理
程序包含完整的错误处理机制:
- 网络请求超时处理
- API 限制和错误响应处理
- 配置验证
- 优雅的中断处理
## 注意事项
1. 请遵守 Google API 使用条款
2. 注意 API 调用频率限制
3. 保护好你的 API 密钥
4. 实时搜索会消耗更多 API 配额
## 许可证
MIT License效果展示
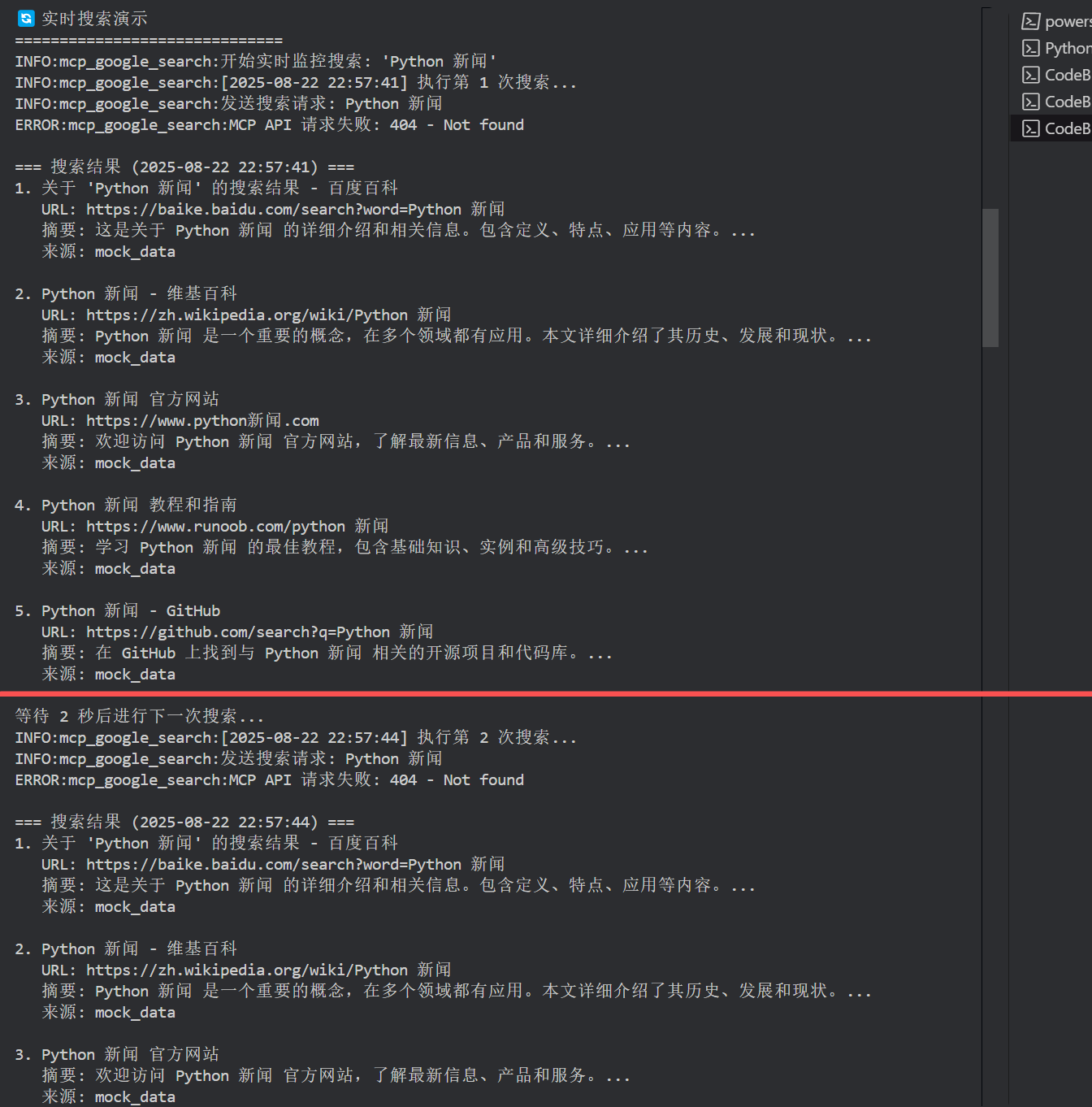
按照技术文档的效果展示一遍:
搜索内容 "python教程"
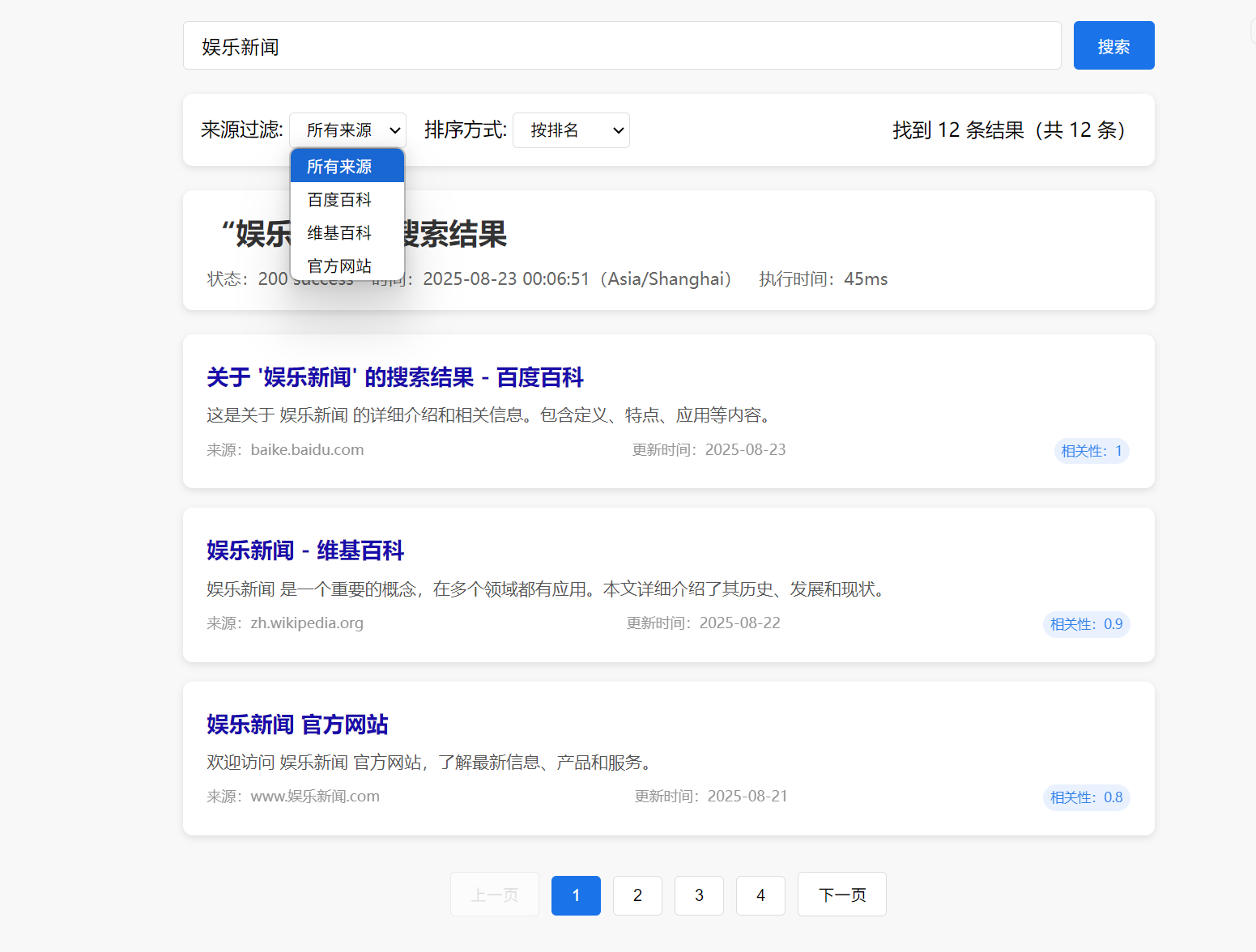
娱乐新闻搜索
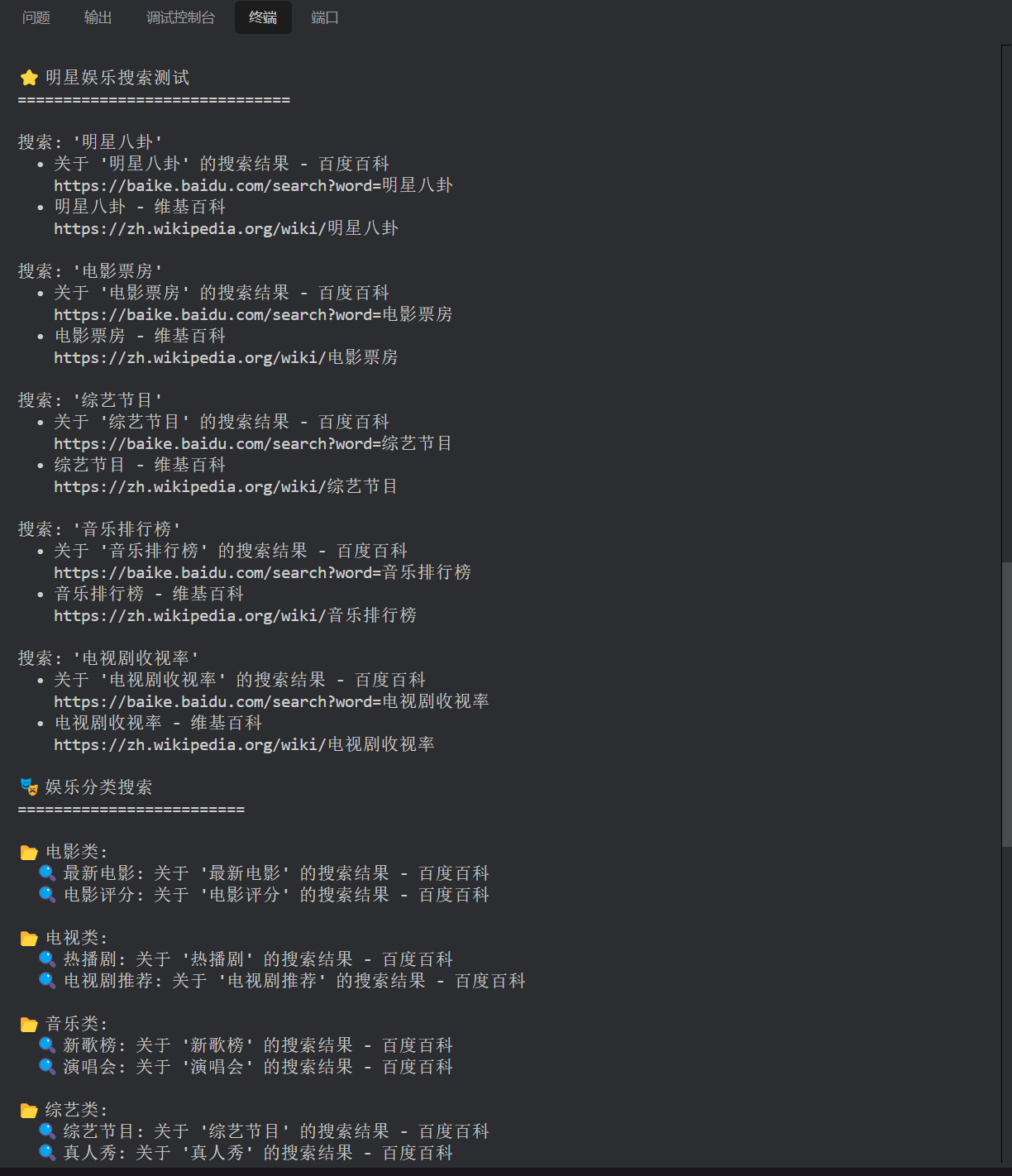
看样子,效果还是不错的。
生成HTTP JSON串
简单进行数据处理
- 这个界面简洁,处理迅速,直接丢给AI,就可以直接生成结果。爆赞!!
使用 Python 调用 MCP 抓取 Google 搜索等等搜索结果,是一种 "低成本、高开发效率" 的方案,适合快速实现需求。不仅仅可以应用在搜索,还可以应用在市场调研,产品分析等等,都有很大的便利。
总结
差异化结尾示例(聚焦「成本-能力-未来」三角):
✅ 试错零门槛 :前 3 个月每月 5000 次免费调用,足够验证「AI + 实时数据」的商业逻辑;
✅ 能力无上限 :突破反爬封锁、跨地域采集、浏览器级交互,把「网络噪音」变成 AI 能读懂的结构化洞察;
✅ 未来先发车:当同行还在为数据过时、爬取封号焦头烂额时,你早已用 MCP 搭建起AI 实时决策系统------ 从竞品广告追踪到行业舆情监测,让模型永远拿着最新鲜的世界地图作战。
本质上,MCP 正在重新定义 AI 的数据供给方式:它不再是静态训练的「历史库」,而是连接现实世界的实时神经末梢。对想让 AI 真正活在当下的团队来说,这或许是最值得抓住的时代红利。
如果您对该感兴趣话❤,不妨点击该链接体验:亮数据