作者:来自 Elastic Jim Ferenczi

Elasticsearch 现在默认从 source 中排除向量,在需要时仍可访问向量,同时节省空间并提升性能。
自己动手试试向量搜索,使用这个面向 Search AI 的自学实践课程。你现在就可以开始免费的 cloud 试用,或者在本地机器上体验 Elastic。
我们正在更新 Elasticsearch 存储向量字段的方式,比如 dense_vector、sparse_vector 和 rank_vector。现在,在 Serverless 中,以及即将到来的 v9.2 版本里,新建索引时向量字段将默认从 _source 中排除。
这一变化开箱即用地减少存储开销、提升索引性能,并使 Elasticsearch 的行为符合用户对现代向量搜索引擎的期望。
为什么要更改默认设置?
到目前为止,Elasticsearch 会同时把向量存储在 doc_values(用于相似度搜索)和 _source(用于检索)中。然而,大多数向量工作负载在搜索响应里并不需要原始向量,只需要 top-k 结果和少量元数据字段。
把大型向量存两份是浪费的。这会增加索引大小、减慢索引速度,并让搜索响应变大。在大多数情况下,用户甚至没意识到自己在每个文档中检索了多 KB 的向量。
这一变化避免了重复,同时保留了 Elasticsearch 的优势:对存储在 _source 中的结构化元数据(比如标题和 URL)的快速访问。
一次罕见但必要的更改
我们通常不会在小版本或 Serverless 环境中引入破坏性更改。但在这种情况下,我们确信好处远远大于影响。
我们看到许多用户因为向量默认被存储和返回而遇到性能问题或响应过大的情况。与其要求额外配置,我们选择把高效的路径设为默认:
json
`"index.mapping.exclude_source_vectors": true`AI写代码无论你是在 Serverless、ESS,还是自管部署中使用 Elasticsearch,这个设置现在都会对所有新建索引默认启用。
现有索引不受影响。对于在此更改之前创建的索引,该设置依然为 false,向量字段会像之前一样继续存储并在 _source 中返回。
回填:它就是能用
回填(Rehydration)意味着 Elasticsearch 可以在需要时把已索引的向量重新加入 _source,即使它并没有存储在那里。这会在以下情况自动发生:
-
部分更新
-
重建索引
-
恢复
即使向量不再物理存储在 _source 中,这些工作流依然能无缝运行。
你也可以在搜索请求中使用 _source 选项手动触发回填(见下文)。
精度取舍
Elasticsearch 在内部将向量存储为 32 位浮点数,这也是索引和相似度搜索时使用的格式。然而,在 JSON 中提供的向量可能是更高精度的类型,比如 double 甚至 long。
当 _source 不再存储原始输入时,任何回填的向量都会反映用于索引的 float 表示。在几乎所有用例中,这就是搜索和评分所需要的。
但如果你需要保留精确的输入精度 ------ 例如必须检索原始的 double 值而不是索引时的 32 位浮点数 ------
你就必须在创建索引时禁用这个设置:
json
`"index.mapping.exclude_source_vectors": false`AI写代码这可以确保原始向量值保存在磁盘上的原始 _source 中。
在需要时访问向量字段
如果你的应用需要在搜索响应中获取向量值,你可以显式地检索它们。
- 使用 fields 选项:
bash
`
1. POST my-index/_search
2. {
3. "fields": ["my_vector"]
4. }
`AI写代码在 hits 旁返回已索引的向量字段,而不在 _source 中。
- 重新启用 _source 中的向量包含:
bash
`
1. POST my-index/_search
2. {
3. "_source": {
4. "exclude_vectors": false
5. }
6. }
`AI写代码此选项会将已索引的向量字段回填到该响应的 _source 中。
影响是什么?
我们使用 OpenAI Vector Rally 赛道对这一变化进行了基准测试。
突出结果:
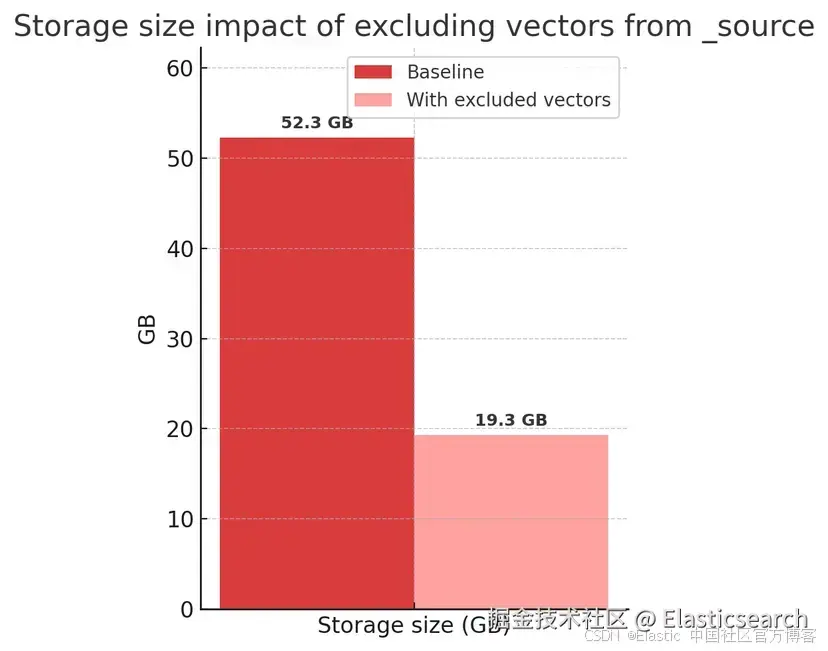
这带来了:
-
更快的索引
-
更少的磁盘 I/O
-
降低资源使用
尤其是在高量向量工作负载中。
最终想法
Elasticsearch 是一个功能齐全的向量搜索引擎,我们致力于确保它默认情况下运行良好。这一变化消除了大多数用户甚至未察觉的低效,同时保留了所有功能。
你仍然可以通过 _source 快速访问元数据,更新和恢复行为无缝,并且在需要时选择返回向量值。如果精确保留原始向量很重要,这种灵活性依然支持,你只需选择启用。
对大多数用户来说,开箱即用的效果会更好。
原文:Lighter by default: Excluding vectors from source - Elasticsearch Labs