作者:来自 Elastic Jen-Luther-Thomas

学习如何使用 Elastic Agent Builder 立即排查 Kubernetes pod 重启和 OOMKilled 事件。我们将展示如何检测、分析并修复故障。
初始摘要
- 使用 Elastic Agent Builder 检测 Kubernetes pod 重启和 OOMKilled 事件
- 使用 ES|QL 基于 Kubernetes 指标分析 CPU 和内存压力
- 生成故障排查摘要和修复指导
本文解释如何使用 Elastic Agent Builder 自动检测、分析并修复由资源压力( CPU 和内存 )导致的 Kubernetes pod 故障,重点关注频繁重启和发生 OOMKilled 事件的 pod 。Elastic Agent Builder 让你可以快速创建精确的 agent ,利用你所有的数据以及强大的工具(例如 ES|QL 查询)、聊天界面和自定义 agent 。
介绍:什么是 Elastic Agent Builder ?
Elastic 内置了一个 AI Agent ,你可以用它从已摄取的所有日志、指标和追踪中获得更多洞察。这本身已经很好,但你还可以更进一步,通过创建 agent 可以使用的工具来简化流程。
为 agent 提供工具意味着它花更少时间 "思考",更快聚焦于对你重要的事情。例如,如果我有一个需要监控的 Kubernetes 环境,并且我想在不一直守在终端前的情况下关注 pod 重启以及内存和 CPU 使用情况,我可以让 Elastic 在出现问题时提醒我。
有告警当然很好,但如何更快获得整体视图?你需要知道是哪个服务出现了(或引发了)问题、为什么会这样,以及该如何修复。
前提条件
本指南假设:
- 一个正在运行的 Kubernetes 集群
- 一个 Elastic Observability 部署
- Kubernetes 指标已索引到 Elastic
步骤 1:创建一个新的 Elastic Agent
在 Elastic Observability 中,使用顶部搜索栏搜索 Agents。创建一个新的 agent。
这个 agent 将是 Kubernetes Pod Troubleshooter agent,旨在帮助用户排查 pod 重启、OOMKill 终止,并评估 CPU 或 内存 压力。
Kubernetes Pod Troubleshooter agent 将会:
- 识别重启次数超过一次的 pod
- 过滤出不处于 running 状态的 pod
- 获取容器终止原因(例如 OOMKilled)
- 分析受影响服务的 CPU 和 内存利用率
- 将资源利用率高于 60%(警告)和 80%(严重)标记出来
- 提供修复建议
该 agent 需要一些指令,用于指导 agent 在与 tools 交互或响应查询时的行为。这些描述可以设置语气、优先级或特殊行为。下面的指令告诉 agent 执行上述步骤。
sql
`
1. You will help users troubleshoot problematic pods by searching the metrics for pods that have restarted more than once and the status is not running. Pods that have the highest number of restarts will be returned to the user.
2. Once the containers that are not running and have restarted multiple times are found you will use their container ID or image name to to look up the container status reason and reason for the last termination. You will return that reason to the user.
3. You will also begin basic troubleshooting steps, such as checking for insufficient cluster resources (CPU or memory) from the metrics and tools available.
4. Any CPU or memory utilization percentages over 60%, and definitely over 80% should be flagged to the user with remediation steps.
`AI写代码在排查高价值系统和环境时,快速获得答案至关重要。使用 Tools 可以确保工作流是可重复的,并且结果值得信任。你还可以获得完整的过程可视性,因为 Elastic Agent 会列出它执行的每一步和每个查询,你可以在 Discover 中进一步查看结果。
你将创建自定义 tools,供 agent 运行,以完成自定义指令中提到的 Kubernetes 排查任务,例如:look up the container status reason and reason for the last termination and checking for insufficient cluster resources (CPU or memory)./查找容器状态原因和最近一次终止原因,以及检查是否存在集群资源不足( CPU 或 内存 )。
步骤 2:创建 Tools ------ Pod 重启
第一个 tool 使用 Kubernetes metrics 来评估 pod 是否发生过重启,以及是否存在最近一次终止原因。如果存在,agent 将把这些信息呈现给用户。
这个 pod-restarts tool 使用一个自定义的 ES|QL 查询,用于查询来自 OTel 的 Kubernetes metrics 数据。
该 ES|QL 查询:
- 过滤出已重启且存在终止原因的容器;
- 计算重启次数;
- 按服务返回重启次数和终止原因。
sql
`
1. FROM metrics-k8sclusterreceiver.otel-default
2. | WHERE metrics.k8s.container.restarts > 0
3. | WHERE resource.attributes.k8s.container.status.last_terminated_reason IS NOT NULL
4. | STATS total_restarts = SUM(metrics.k8s.container.restarts),
5. reasons = VALUES(resource.attributes.k8s.container.status.last_terminated_reason)
6. BY resource.attributes.service.name
7. | SORT total_restarts DESC
`AI写代码步骤 3:创建 Tools ------ Service Memory
自定义 tools 可以接收输入变量,这可以提高结果的速度和准确性。
pod 无法被调度或频繁重启的常见原因,是集群或节点资源不足。 pod-restarts tool 会返回重启次数较多且终止原因是 OOMKill 的 service,这通常表明存在 内存 压力。
eval-pod-memory tool 是一个自定义的 ES|QL ,它将:
- 在最近 12 小时 内,过滤与 pod-restarts tool 返回的 service name 匹配的 metrics 数据;
- 将 内存 使用量、请求量、限制值 和 利用率 转换为 MB;
- 计算这些指标的平均值;
- 按 1 分钟 分组并进行排序。
ini
`
1. FROM metrics-*
2. | WHERE resource.attributes.service.name == ?servicename
3. | WHERE @timestamp >= NOW() - 12 hours
4. | EVAL
5. memory_usage_mb = metrics.container.memory.usage / 1024 / 1024,
6. memory_request_mb = metrics.k8s.container.memory_request / 1024 / 1024,
7. memory_limit_mb = metrics.k8s.container.memory_limit / 1024 / 1024,
8. memory_utilization_pct = metrics.k8s.container.memory_limit_utilization * 100
9. | STATS
10. avg_memory_usage = AVG(memory_usage_mb),
11. avg_memory_request = AVG(memory_request_mb),
12. avg_memory_limit = AVG(memory_limit_mb),
13. avg_memory_utilization = AVG(memory_utilization_pct)
14. BY bucket = BUCKET(@timestamp, 1 minute)
15. | SORT bucket ASC
`AI写代码步骤 4:创建 Tools:Service CPU
由于 CPU 使用率 是 pod 调度失败或陷入无限重启循环的另一个常见原因,下一个 tool 将评估 CPU 使用量、请求量 和 限制值。
eval-pod-cpu tool 是一个自定义的 ES|QL ,它将:
- 在最近 12 小时 内,过滤与 pod-restarts tool 返回的 service name 匹配的 metrics 数据;
- 计算 CPU 使用量、CPU request 利用率 和 CPU limit 利用率 的平均值。
ini
`
1. FROM metrics-kubeletstatsreceiver.otel-default
2. | WHERE k8s.container.name == ?servicename OR resource.attributes.k8s.container.name == ?servicename
3. | STATS
4. avg_cpu_usage = AVG(container.cpu.usage),
5. avg_cpu_request_utilization = AVG(k8s.container.cpu_request_utilization) * 100,
6. avg_cpu_limit_utilization = AVG(k8s.container.cpu_limit_utilization) * 100
7. | LIMIT 100
`AI写代码步骤 5:将 Tools 分配给 Kubernetes Pod Troubleshooter Agent
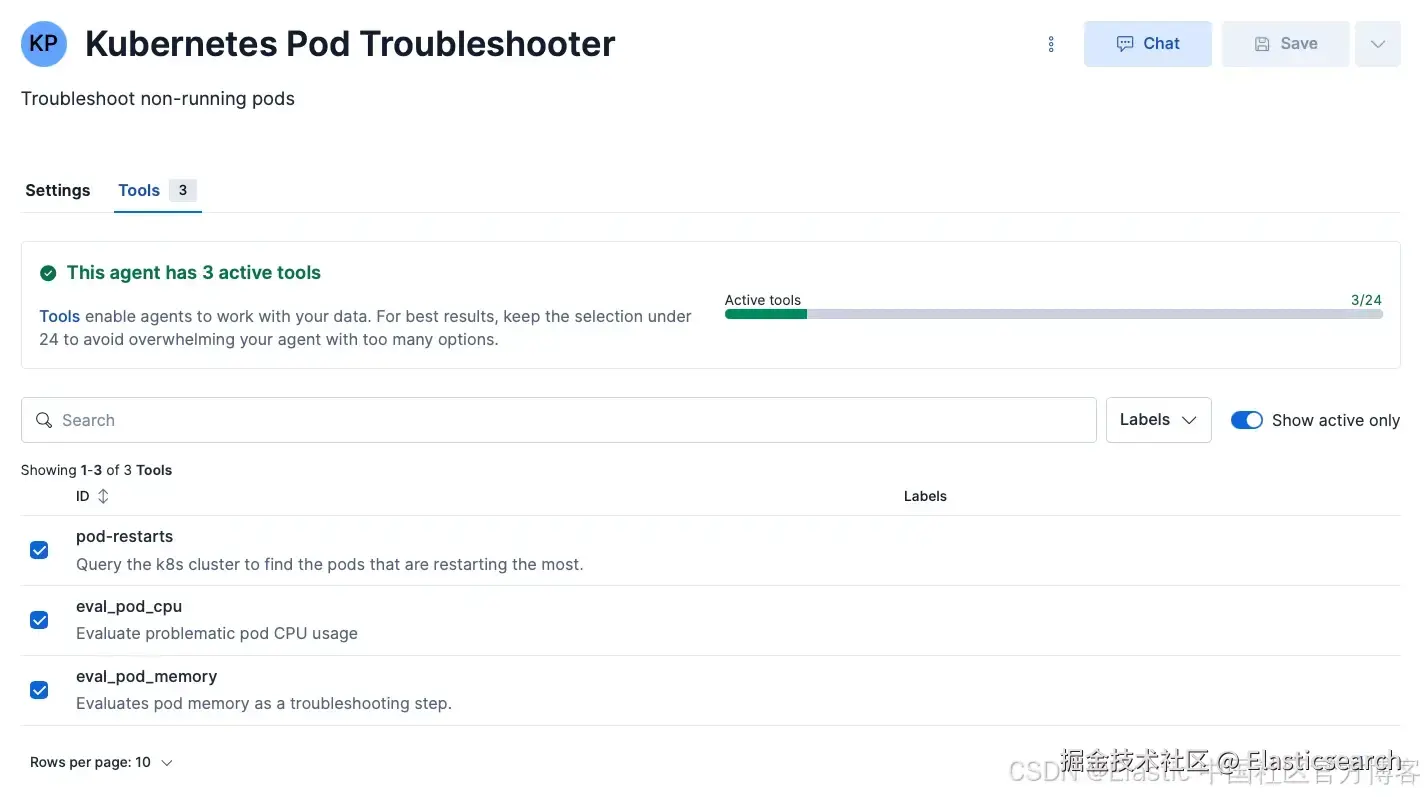
当所有 tools 构建完成后,你需要将它们分配给 agent。
该图片展示了 Kubernetes Pod Troubleshooter agent ,并且三个 tools 已分配并处于激活状态: pod-restarts 、 eval-pod-cpu 和 eval-pod-memory 。
步骤 6:测试 Kubernetes Pod Troubleshooter Agent
为了模拟内存压力,集群中正在运行 Open Telemetry demo 。人为降低内存 requests 和 limits ,并增加服务负载,将会导致 pods 重启。
要在你 的 集群中对 open telemetry demo 执行此操作,请按照以下步骤进行。
通过缩放 deployment ,将 cart service 减少到一个 replica 。完成后,通过降低 memory requests 和 limits 来修改该 deployment 的 resources ,如下命令所示:
ini
`
1. kubectl -n otel-demo scale deploy/cart --replicas=1
2. kubectl -n otel-demo set resources deploy/cart -c cart --requests=memory=50Mi --limits=memory=60Mi
`AI写代码OpenTelemetry demo 应用自带一个 load-generator 。它通过修改 load generator deployment 中的 users 和 spawn rate 来模拟对 demo site 的请求,如下命令所示:
bash
`kubectl -n otel-demo set env deploy/load-generator LOCUST_USERS=800 LOCUST_SPAWN_RATE=200 LOCUST_BROWSER_TRAFFIC_ENABLED=false` AI写代码如果你列出集群或 namespace 中的所有 pods ,你应该会开始看到重启情况。
现在你可以与 Kubernetes Pod Troubleshooter agent 聊天,并询问:"Are any of my Kubernetes pods having issues?" 。
截图显示了 Kubernetes Pod Troubleshooter agent 的最终响应。它基于每个 tool 的结果提供了问题总结,展示了哪些 services 出现了最多的重启,以及 memory 和 CPU utilization 情况。
阈值解释已在初始 agent 指令中说明,其中 >60% utilization 表示 warning(持续压力),>80% utilization 表示 critical(高度可能发生重启或 throttling)。这与 Kubernetes Pod Troubleshooter agent 给出的发现一致,即重启次数最高的 services 的 memory utilization 都高于 90% 。agent 需要清晰定义的阈值,才能正确评估返回的 memory 和 CPU utilization 值。
Kubernetes Pod Troubleshooter agent 返回的问题总结:

不仅如此,agent 还可以更进一步,根据 tools 输出的结果提供 remediation recommendation 。
Kubernetes Pod Troubleshooter agent 返回的 remediation recommendation:

注册 Elastic Cloud Serverless,并在你的 Kubernetes clusters 上试用此功能。
常见问题解答
1)何时使用 Elastic Agent Builder 进行 Troubleshooting
使用 Elastic Agent Builder 进行 Troubleshooting 最合适的情况是:
-
你需要可重复、可审计的 troubleshooting workflows
-
你希望得到确定性分析,而不是自由形式的 AI 响应
-
你正在调查日志或 metrics 中报告的问题(例如 pod restarts、OOMKills 或 resource pressure)
-
你想减少平均解决时间 (MTTR)
2)我需要 OpenTelemetry 才能使用 Elastic Agent Builder 进行 Kubernetes troubleshooting 吗?
不,你不需要使用 OpenTelemetry。你有两个选项:
-
可以使用 Elastic Agent 从 Kubernetes 收集 logs 和 metrics;或
-
可以使用 Elastic Distro for OTel (EDOT) Collector 收集 logs、traces 和 metrics
按照上述步骤操作时,这会改变 tools 中使用的 field names。例如,kubernetes.container.memory.usage.bytes vs metrics.container.memory.usage。
3)这个 agent 可以适应 node-level failures 吗?
可以,Elastic 提供数百个 integrations,包括 AWS (用于 EKS)、Azure (用于 AKS)、Google Cloud (用于 GKE),以及 host operating system monitoring。
上面展示的 queries 可以修改为使用正确的 field。
4)这些 tools 可以在 automation workflows 中重用吗?
可以,Elastic Workflows 可以重用你在 Elastic 中构建的相同 scripted automations 和 AI agents。agent 可以处理初步分析和调查(减少手动工作),workflow 可以继续执行结构化步骤,例如运行 Elasticsearch queries、transform 数据、基于条件分支、调用外部 APIs 或 tools,如 Slack、Jira 和 PagerDuty。Workflow 还可以暴露给 Agent Builder 作为可重用的 tools,就像本指南中创建的 tool 一样。
对于类似场景的高级自动化,了解如何将 AI agents 集成到 GitHub Actions,以监控 K8s health 并通过 Observability 提高部署可靠性。
5)这些 tools 可以由 alerts 触发吗?
可以,alerts 可以触发 Elastic Workflows,并将 alert context 传递给 workflow。这个 workflow 也可以集成到 Elastic Agent 中,如上所述。
此外,Elastic Alerts 允许你在 alerts 旁边发布 investigation guides,让 SRE 拥有开始调查所需的全部信息。任何 troubleshooting 或 investigative agents 都可以通过 investigation guide 链接,这意味着 SRE 不必遵循 guide 中的手动流程,而是让 agent 处理手动、重复的调查。
6)如何开始使用 Agent Builder?
注册 Elastic Cloud Serverless,这是一个新的全托管、无状态架构,无论你的 data、usage 和 performance 需求如何,都能自动扩展。