Prometheus运维(接入AlertManager 实现邮件告警)
你还不知道如何将AlertManager接入Prometheus的话,可以参考其他网上文章或者我之前的部署文章
如果文章帮助到了你请帮我点个赞做个转发嘿嘿再次感谢!
1 创建Prometheus规则
1.1 创建规则存放目录
ruby
# 在Prometheus挂载到本次磁盘的目录中创建rule文件夹
root@ubuntu2204-98:/usr/local/prometheus_monitor/prometheus# mkdir /usr/local/prometheus_monitor/prometheus/rules
root@ubuntu2204-98:/usr/local/prometheus_monitor/prometheus# chmod -R 777 rules1.2 将规则接入到Prometheus
ruby
root@ubuntu2204-98:/usr/local/prometheus_monitor/prometheus# vi prometheus.yml
# 规则文件
rule_files:
- /etc/prometheus/rules/*.rules1.3 创建主机监控规则
bash
# 主机规则
groups:
- name: hostStatusAlert
rules:
- alert: MemUsageAlert
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 85
for: 3m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{{ $labels.instance }}内存使用率超过85%,当前使用率{{ $value }}%."
btn: "点击查看详情"
link: "grafana.test.com"
- alert: ServUpStatus
expr: up == 0
for: 1s
labels:
severity: warning
annotations:
summary: "{{$labels.instance}} 服务器宕机, 请尽快处理!"
description: "{{$labels.instance}} 服务器延时超过3分钟,当前状态{{ $value }}. "
btn: "点击查看详情"
link: "grafana.test.com"
- alert: CPUUsageAlert
expr: 100 - (avg by (instance,job)(irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 90
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}} CPU使用率过高,请尽快处理!"
description: "{{$labels.instance}} CPU使用大于90%,当前使用率{{ $value }}%. "
btn: "点击查看详情"
link: "grafana.test.com"
- alert: DiskIO
expr: avg(irate(node_disk_io_time_seconds_total[1m])) by(instance,job)* 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}} 流入磁盘IO使用率过高,请尽快处理!"
description: "{{$labels.instance}} 流入磁盘IO大于90%,当前使用率{{ $value }}%."
btn: "点击查看详情"
link: "grafana.test.com"
- alert: NetworkIN
expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}} 流入网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流入网络带宽持续5分钟高于100M. RX带宽使用量{{$value}}."
btn: "点击查看详情"
link: "grafana.test.com"
- alert: NetworkOUT
expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance,job)) / 100) > 102400
for: 5m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}} 流出网络带宽过高,请尽快处理!"
description: "{{$labels.instance}} 流出网络带宽持续5分钟高于100M. RX带宽使用量{$value}}."
btn: "点击查看详情"
link: "grafana.test.com"
- alert: TcpESTABLISHED
expr: node_netstat_Tcp_CurrEstab > 10000
for: 2m
labels:
severity: warning
annotations:
summary: " TCP_ESTABLISHED过高!"
description: "{{$labels.instance}} TCP_ESTABLISHED大于100%,当前使用率{{ $value }}%."
btn: "点击查看详情"
link: "grafana.test.com"
- alert: DiskUse
expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 90
for: 1m
labels:
severity: warning
annotations:
summary: "{{$labels.mountpoint}} 磁盘分区使用率过高,请尽快处理!"
description: "{{$labels.instance}} 磁盘分区使用大于90%,当前使用率{{ $value }}%."
btn: "点击查看详情"
link: "grafana.test.com"1.4 连接Prometheus查看规则
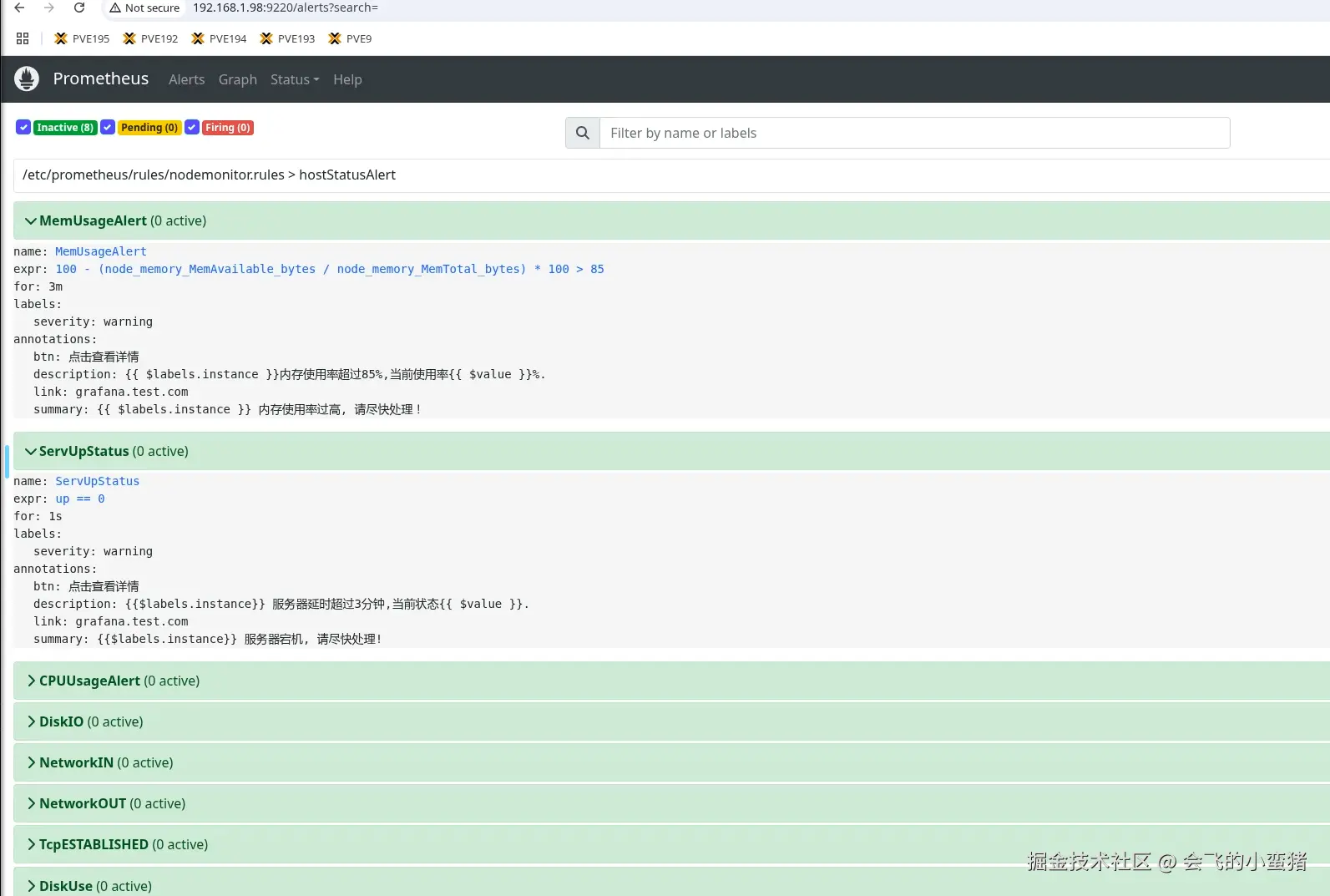
image-20250825233547139
1.5 修改Prometheus规则测试是否告警生效
bash
# 我们将上面内存的告警阈值改小来看是否会触发报警
groups:
- name: hostStatusAlert
rules:
- alert: MemUsageAlert
expr: 100 - (node_memory_MemAvailable_bytes / node_memory_MemTotal_bytes) * 100 > 1 # 修改阈值
for: 1m # 到达阈值后连续多久告警
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} 内存使用率过高, 请尽快处理!"
description: "{{ $labels.instance }}内存使用率超过85%,当前使用率{{ $value }}%."
btn: "点击查看详情"
link: "grafana.test.com"首先进入到了PENDING状态,但是没有到时间所以还在持续探测
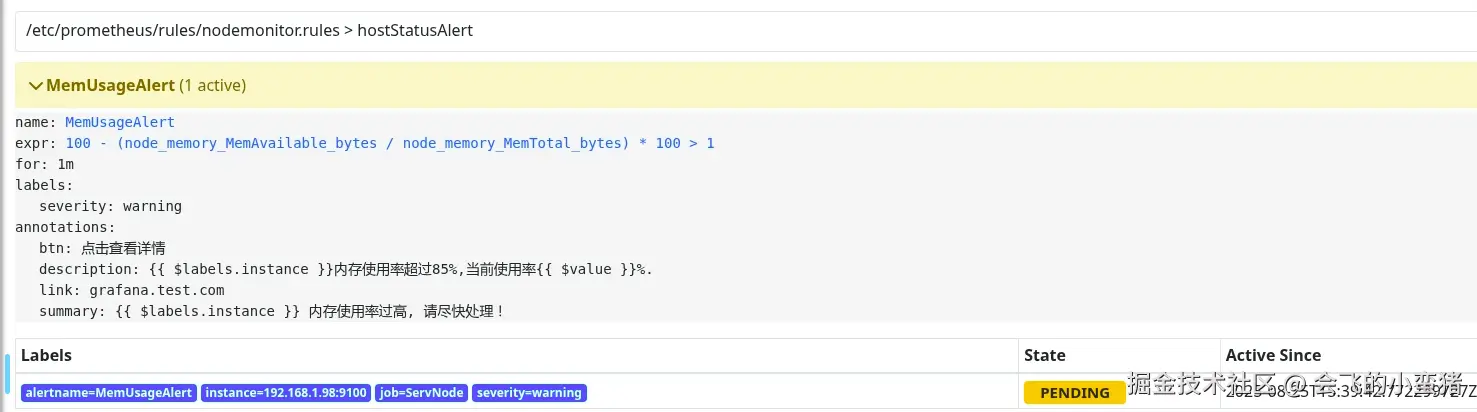
image-20250825234054905
到达告警时间后变为FIRING
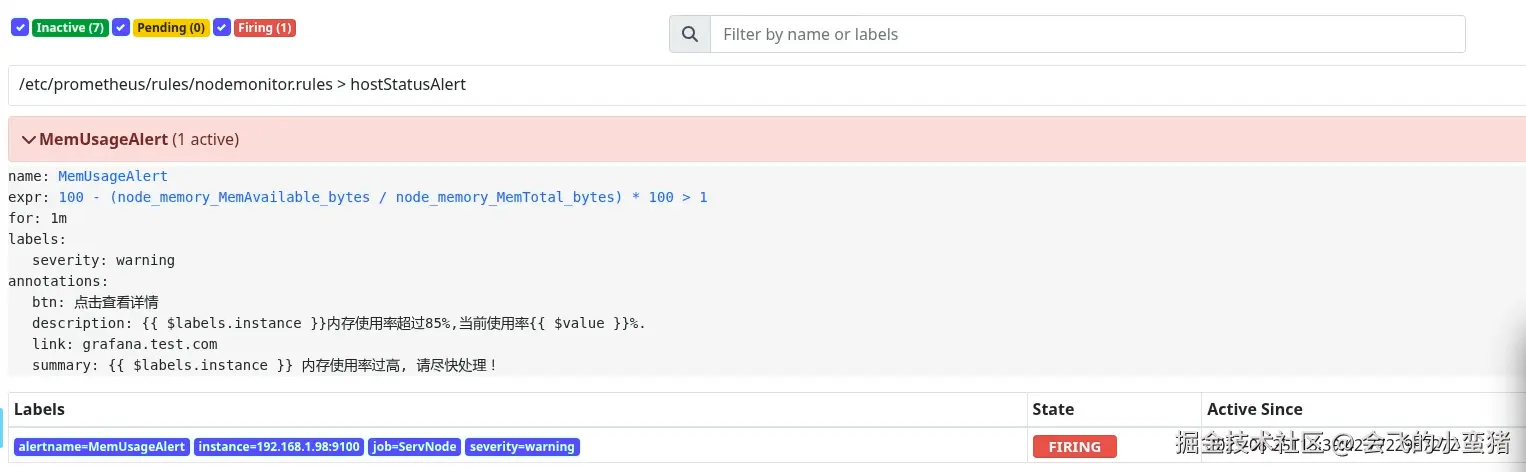
image-20250825234137926
2. 接入AlertManager规则进行邮件告警
2.1 AlertManager配置文件及规则定义
ruby
root@ubuntu2204-98:~# cd /usr/local/prometheus_monitor/alertmanager
root@ubuntu2204-98:/usr/local/prometheus_monitor/alertmanager# ls
alertmanager.yml
root@ubuntu2204-98:/usr/local/prometheus_monitor/alertmanager# mkdir template
# 修改配置文件,定义告警规则
root@ubuntu2204-98:/usr/local/prometheus_monitor/alertmanager# vi alertmanager.yml
global:
resolve_timeout: 5m
# 这里是发送告警邮件的邮件服务器配置,我用的是163
smtp_smarthost: 'smtp.163.com:465'
smtp_from: 'xxxx@163.com'
smtp_auth_username: 'xxxxxx@163.com'
smtp_auth_password: 'xxxxxxxxxx'
smtp_require_tls: false
# 模板在容器中的位置,别搞错了。之前是用容器启动的。
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
group_by: ['alertname', 'instance', 'severity']
group_wait: 10s
group_interval: 1m
repeat_interval: 360m
receiver: 'mail'
routes:
- match:
severity: warning
receiver: mail
receivers:
- name: 'mail'
email_configs:
- to: '101536363@qq.com'
html: '{{ template "mail.html" . }}'
headers:
Subject: '{{ if gt (len .Alerts.Firing) 0 }}[WARN] 报警邮件{{ else if gt (len .Alerts.Resolved) 0 }}[INFO] 恢复邮件{{ else }}[INFO] 无告警状态{{ end }}'
send_resolved: true
inhibit_rules:
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname','instance', 'severity']2.2 定义告警使用的模板
ruby
root@ubuntu2204-98:/usr/local/prometheus_monitor/alertmanager# vi template/mail.tmpl
{{ define "mail.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
标题:告警通知 - {{ .Alerts.Firing | len }} 条告警<br>
{{- else if gt (len .Alerts.Resolved) 0 -}}
标题:告警恢复通知 - {{ .Alerts.Resolved | len }} 条告警已恢复<br>
{{- end }}
{{- if gt (len .Alerts.Firing) 0 -}}
{{- range $index, $alert := .Alerts -}}
========= ERROR ==========<br>
告警名称:{{ .Labels.alertname }}<br>
告警级别:{{ .Labels.severity }}<br>
告警机器:{{ .Labels.instance }} {{ .Labels.device }}<br>
告警详情:{{ .Annotations.summary }}<br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
========= 状态 ==========<br>
系统状态告警!<br>
========= END ==========<br>
{{- end }}
{{- end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
{{- range $index, $alert := .Alerts -}}
========= INFO ==========<br>
告警名称:{{ .Labels.alertname }}<br>
告警级别:{{ .Labels.severity }}<br>
告警机器:{{ .Labels.instance }}<br>
告警详情:{{ .Annotations.summary }}<br>
告警时间:{{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
恢复时间:{{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}<br>
========= 状态 ==========<br>
系统状态告警已恢复!<br>
========= END ==========<br>
{{- end }}
{{- end }}
{{- end }}3.测试下邮件告警是否成功
3.1 shell来增加cpu负载
使用shell增加cpu的负载,验证告警机制,我是4c机器所以用了创建了4个死循环来家中cpu压力,请根据自己情况来测试
ruby
root@ubuntu2204-98:/usr/local/prometheus_monitor# for i in {1..4}; do (while true; do echo "scale=5000; 4*a(1)" | bc -l > /dev/null; done) & done
[1] 1361096
[2] 1361097
[3] 1361100
[4] 1361103
root@ubuntu2204-98:/usr/local/prometheus_monitor# kill -9 1361096 1361097 1361100 1361103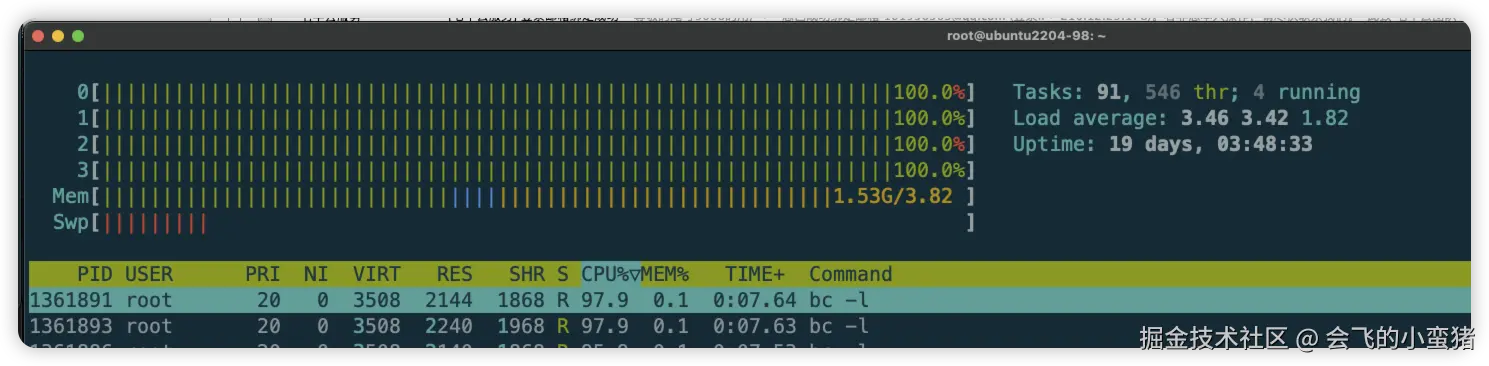
image-20250826145138590
3.2 查看告警及恢复告警

image-20250826151829035
修改主机监控值来触发告警
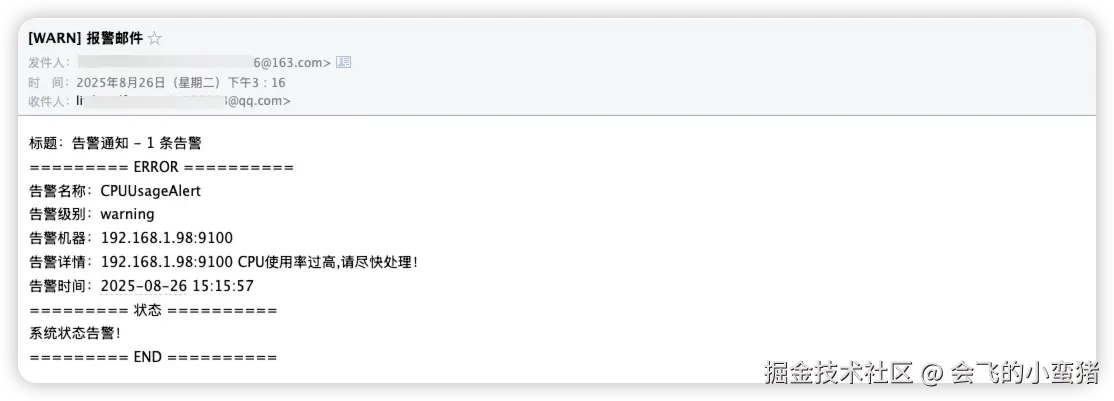
image-20250826151852495
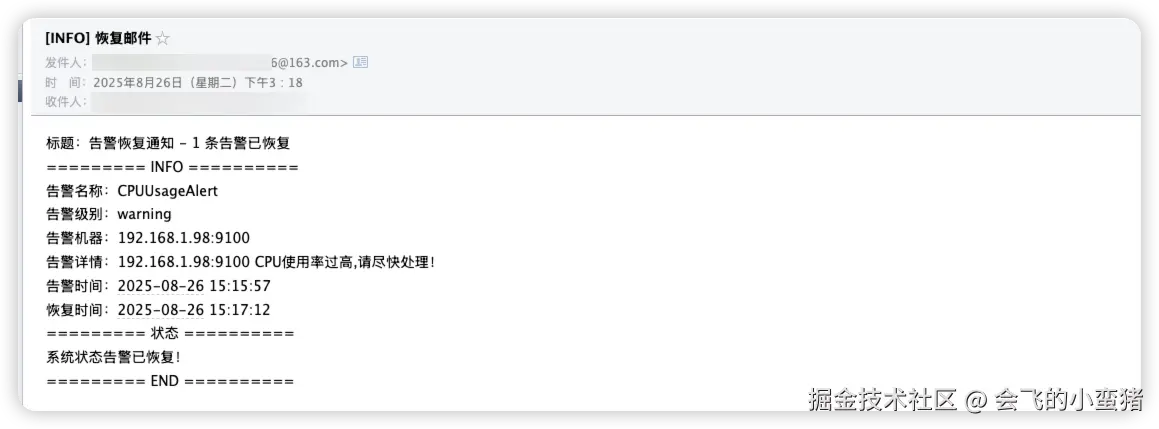
image-20250826151933427
本章演示完结撒花,后面看时间在写一下将告警接入到钉钉,飞书,企微等,因为个人是在工作时间或者下班在家抽空写所以文章也有些赶(可能有太着急格式没弄好的地方 还请见谅) 但是具体按照相关步骤都差不多,模板我都贴出来了,相信老铁们也能顺利使用。