🟢 前言:拒绝机械劳动
你是否遇到过这样的场景: 老板发给你一个文件夹,里面装了几百份格式类似的 Word 文档(比如简历、报名表、调查问卷),让你把里面的"姓名"、"电话"、"毕业学校"等信息一个一个复制粘贴到 Excel 表格里汇总?
如果手动做,不仅眼睛都要看瞎,而且极其容易出错。作为一名 Python 开发者,这种重复性劳动是绝对不能忍受的!
于是,我利用 Python 的 PyQt + pandas + python-docx 开发了一个带图形界面的自动化工具,能够自动遍历文件夹,识别 Word 表格内容,甚至支持 PDF 和老旧的 .doc 格式,最终一键生成 Excel 汇总表。
今天将源码分享给大家,希望能帮大家从繁琐的 Ctrl+C/V 中解脱出来。
项目开源地址 :github.com/xy200303/au... (欢迎 Star ⭐ 支持一下!)
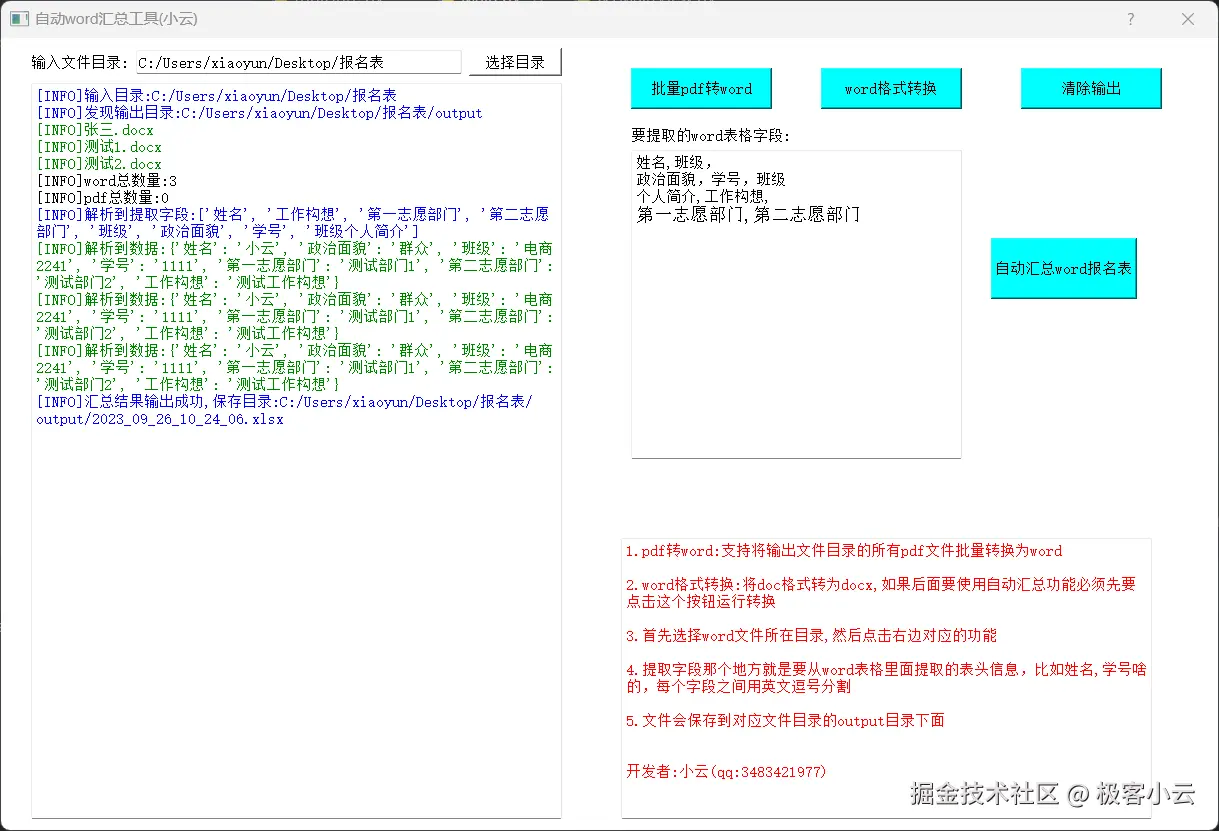
🚀 功能亮点
这个工具主要解决了以下几个痛点:
- 批量处理:支持选择文件夹,自动递归查找所有文件。
- 格式兼容 :
- 原生支持
.docx。 - 自动将
.doc转换为.docx(基于 pywin32)。 - 自动将
.pdf转换为.docx(基于 pdf2docx)。
- 原生支持
- 自定义提取:你只需要输入你想提取的字段(如:姓名,电话,邮箱),程序会自动在 Word 表格中查找对应的值。
- 图形界面:基于 PyQt 编写了 GUI,不懂代码的同事也能直接使用。
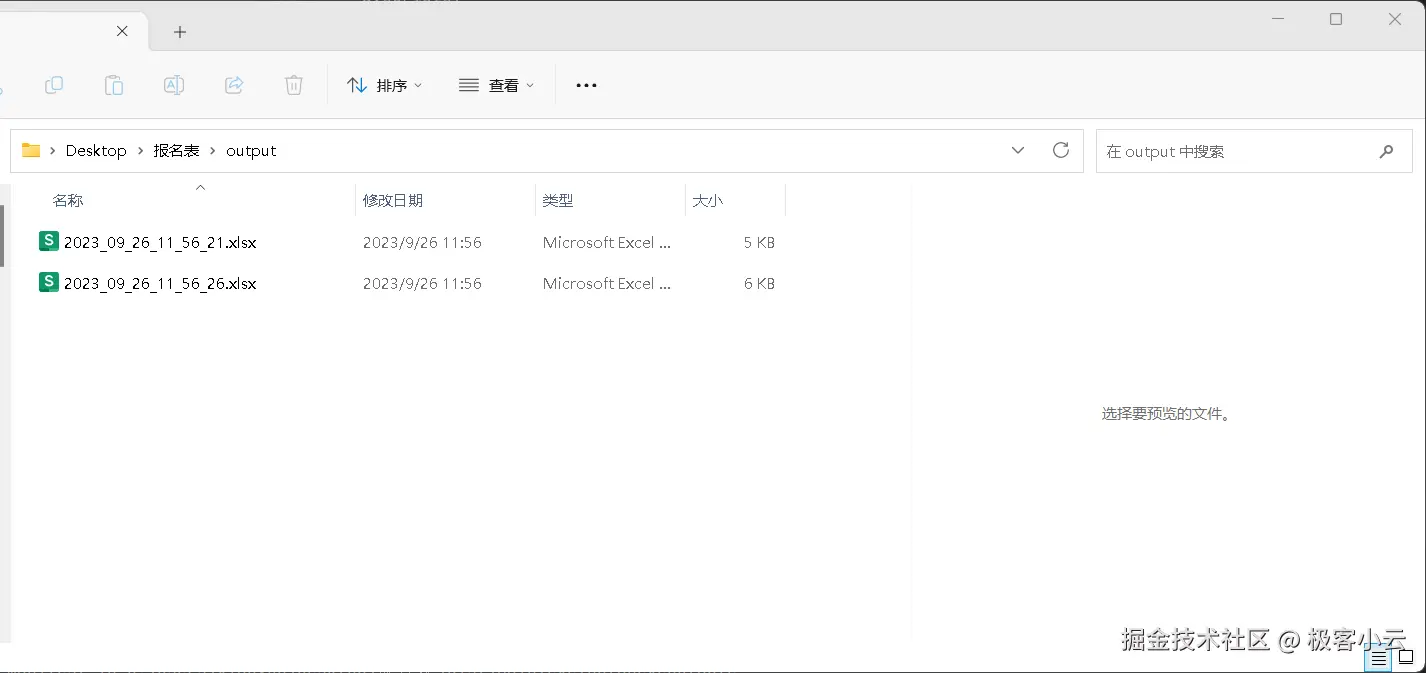
- 结果导出 :处理完成后自动生成带时间戳的
.xlsx文件。
🛠️ 技术栈与原理
- 界面 (UI): PyQt6 / PyQt5
- Word处理: python-docx (用于读取表格数据)
- PDF转Word: pdf2docx
- Doc转Docx: pywin32 (调用 Word 底层 COM 接口)
- 数据汇总: pandas
核心逻辑图解
- 用户输入:选择文件夹 + 输入关键词(如"姓名")。
- 文件预处理:如果是 PDF 或 .doc,先转换为 .docx。
- 读取内容 :利用
python-docx读取文档中的所有表格,将其展平为一个列表。 - 关键词匹配 :在列表中找到包含"姓名"的单元格,取其下一个非空单元格作为数据。
- 导出:使用 pandas 将字典列表写入 Excel。
💻 核心代码解析
1. 提取 Word 表格数据 (toolCore.py)
这是最关键的一步。由于 Word 排版复杂,我们统一将所有表格的内容读取出来,按顺序存入一个列表,这样就将二维的表格降维成了一维的线性数据,方便查找。
python
from docx import Document
def word_tables_to_list(file_path):
"""
读取 docx 中的所有表格,并将其展平为列表
"""
doc = Document(file_path)
cells = []
for table in doc.tables:
for row in table.rows:
for cell in row.cells:
text = cell.text.strip()
# 简单清洗数据
text = text.replace("\n", "").replace(" ", "")
cells.append(text)
return cells2. 智能匹配字段 (toolCore.py)
获取到列表后,如何提取数据?这里采用了一个简单的逻辑:查找 Key,取 Key 后面紧邻的 Value。
python
def get_info_from_cells(cells, keys_dict):
"""
cells: 文档所有内容的列表
keys_dict: 用户输入的关键词列表,如 ['姓名', '电话']
"""
info = {}
for k in keys_dict:
# 默认该字段为空
info[k] = ""
try:
# 在列表中找到关键词的位置
if k in cells:
k_index = cells.index(k)
# 取关键词的下一个位置作为值
# 这里的逻辑可以根据实际表格结构调整,比如 +2 或者 +3
value = cells[k_index + 1]
info[k] = value
except Exception as e:
print(f"提取 {k} 失败: {e}")
return info3. PDF 转 Word (toolCore.py)
为了支持 PDF 简历,我们集成了 pdf2docx 库:
python
from pdf2docx import Converter
def TransPdfToDocx(file_path, out_file):
cv = Converter(file_path)
cv.convert(out_file)
cv.close()4. 主程序调用 (Main.py)
在 PyQt 的主线程中,我们串联起所有逻辑:
python
# 伪代码逻辑演示
def ok(self):
# 1. 获取用户输入的关键词
keys_dict = self.getInput_Key_dict()
res = []
# 2. 遍历文件列表
for file in self.word_file_list:
# 3. 提取表格内容
cells = word_tables_to_list(file)
# 4. 匹配数据
info = get_info_from_cells(cells, keys_dict)
res.append(info)
# 5. 导出 Excel
if res:
data = pd.DataFrame(res)
data.to_excel("output.xlsx", index=False)📦 如何使用本项目
如果你想直接运行代码,请按照以下步骤操作:
第一步:克隆项目
bash
git clone https://github.com/xy200303/automatic-word-summary
cd automatic-word-summary第二步:安装依赖库
请确保你的 Python 环境安装了以下库(建议使用国内源):
bash
pip install pandas python-docx pdf2docx pywin32 PyQt6 openpyxl -i https://pypi.tuna.tsinghua.edu.cn/simple注意:如果你要修改界面,还需要安装 pyqt6-tools。
第三步:运行程序
bash
python Main.py第四步:操作流程
- 点击 "选取文件夹",选择包含简历/报名表的目录。
- 在 "提取字段" 输入框中,输入你想提取的表头名称,用逗号隔开。
- 例如:
姓名,性别,出生年月,毕业院校,联系电话
- 例如:
- 点击 "开始处理"。
- 等待日志滚动完毕,在原文件夹下的
output目录中即可找到汇总好的 Excel 表格。
📝 总结与扩展
这个脚本虽然简单,但解决的是实实在在的痛点。特别是在处理格式固定的政务表单、学校报名表时,效率提升是数量级的。
未来优化方向:
- 目前是取 Key 的下一个单元格,对于复杂的合并单元格表格,可能需要优化查找逻辑(比如根据坐标查找)。
- 可以加入多线程处理,加快 PDF 转换的速度。
- 利用正则表达式对提取出的电话、邮箱进行二次清洗。
如果你觉得这个项目对你有帮助,欢迎去 GitHub 点个 Star!如果有问题,也可以在评论区留言交流。
项目地址 👉 github.com/xy200303/au...