从Q-Learning到DQN-AI Agent自主决策能力的进化
引言
人工智能(Artificial Intelligence, AI)的发展已逐步走向自主决策与环境交互,其中 强化学习(Reinforcement Learning, RL) 扮演着关键角色。传统的Q-Learning方法虽然能够在简单环境中有效运行,但在状态与动作空间较大时表现不足。为解决这一问题,深度Q网络(Deep Q-Network, DQN) 将深度神经网络与强化学习结合,使得AI Agent能够在高维环境中进行智能决策。本文将系统研究DQN在AI Agent中的联合应用,结合理论与代码实战,展示其核心价值。
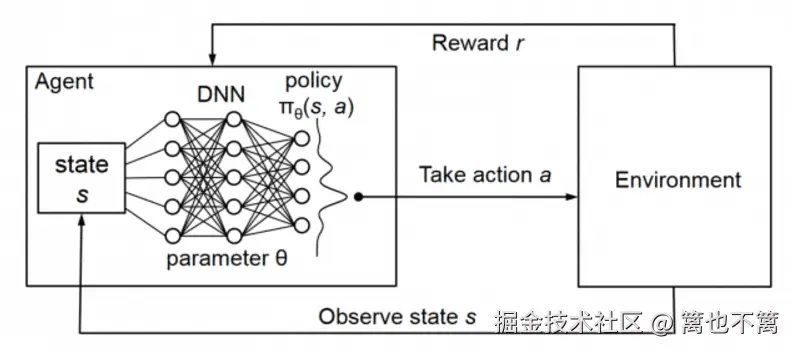
一、强化学习基础
1.1 强化学习概念
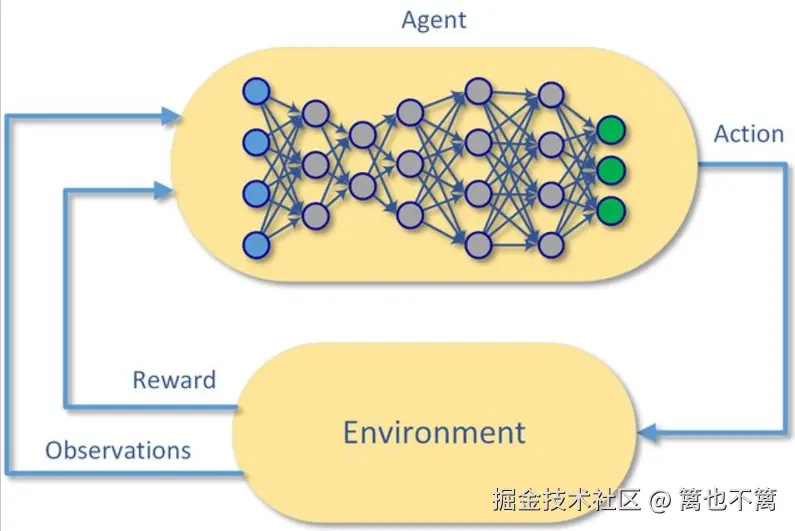
强化学习是机器学习的一种方法,核心思想是 智能体(Agent) 通过与 环境(Environment) 的交互,在试错过程中学习最优策略,以最大化长期累积奖励。
- 状态 (State, s): 环境当前的情况。
- 动作 (Action, a): 智能体采取的行为。
- 奖励 (Reward, r): 环境给予的反馈信号。
- 策略 (Policy, π): 决定在某状态下选择哪个动作的规则。
1.2 Q-Learning方法
Q-Learning的核心是 动作价值函数Q(s,a):
Q(s,a)←Q(s,a)+α(r+γa′maxQ(s′,a′)−Q(s,a))
其中:
- α:学习率
- γ:折扣因子
- s′:执行动作后的新状态
二、深度Q网络(DQN)
2.1 DQN的提出
Q-Learning在状态空间较大时,难以维护Q表。DQN引入深度神经网络近似Q函数,将状态作为输入,输出各个动作的Q值,从而在复杂环境中有效运行。
2.2 DQN关键技术
- 经验回放(Experience Replay): 存储交互数据,打乱采样,减少相关性。
- 目标网络(Target Network): 引入延迟更新的目标网络,提升训练稳定性。
三、DQN在AI Agent中的联合应用
3.1 典型应用场景
- 游戏智能体: Atari游戏AI、围棋AlphaGo的早期版本。
- 机器人控制: 路径规划、机械臂抓取。
- 智能推荐: 在推荐系统中基于用户反馈进行动态调整。
3.2 研究意义
通过DQN,AI Agent能够实现:
- 在高维连续状态下高效学习;
- 改善传统Q-Learning收敛慢的问题;
- 具备跨任务迁移与泛化能力。
四、代码实战:DQN训练CartPole智能体
下面通过OpenAI Gym环境中的 CartPole 平衡杆任务,展示DQN在AI Agent中的应用。
4.1 环境准备
bash
pip install gym torch numpy matplotlib tqdm -i https://pypi.tuna.tsinghua.edu.cn/simple4.2 代码实现
python
import gym
import torch
import torch.nn as nn
import torch.optim as optim
import random
import numpy as np
from collections import deque
from tqdm import trange
# 定义Q网络
class QNetwork(nn.Module):
def __init__(self, state_size, action_size):
super(QNetwork, self).__init__()
self.fc1 = nn.Linear(state_size, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, action_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# DQN Agent
class DQNAgent:
def __init__(self, state_size, action_size):
self.state_size = state_size
self.action_size = action_size
self.memory = deque(maxlen=2000)
self.gamma = 0.95
self.epsilon = 1.0
self.epsilon_min = 0.01
self.epsilon_decay = 0.995
self.lr = 0.001
self.model = QNetwork(state_size, action_size)
self.target_model = QNetwork(state_size, action_size)
self.update_target()
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
def update_target(self):
self.target_model.load_state_dict(self.model.state_dict())
def act(self, state):
if np.random.rand() <= self.epsilon:
return random.randrange(self.action_size)
state = torch.FloatTensor(state).unsqueeze(0)
q_values = self.model(state)
return torch.argmax(q_values).item()
def remember(self, state, action, reward, next_state, done):
self.memory.append((state, action, reward, next_state, done))
def replay(self, batch_size=64):
if len(self.memory) < batch_size:
return
minibatch = random.sample(self.memory, batch_size)
for state, action, reward, next_state, done in minibatch:
state = torch.FloatTensor(state).unsqueeze(0)
next_state = torch.FloatTensor(next_state).unsqueeze(0)
target = self.model(state)
with torch.no_grad():
q_next = self.target_model(next_state).max(1)[0].item()
target_val = reward if done else reward + self.gamma * q_next
target[0][action] = target_val
loss = nn.MSELoss()(self.model(state), target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
if self.epsilon > self.epsilon_min:
self.epsilon *= self.epsilon_decay
# 训练CartPole
env = gym.make("CartPole-v1")
agent = DQNAgent(env.observation_space.shape[0], env.action_space.n)
episodes = 300
for e in trange(episodes):
state = env.reset()[0]
done = False
while not done:
action = agent.act(state)
next_state, reward, done, _, _ = env.step(action)
agent.remember(state, action, reward, next_state, done)
state = next_state
agent.replay(32)
if e % 10 == 0:
agent.update_target()
env.close()
print("训练完成!")五、实验与结果分析
5.1 收敛效果
在训练初期,Agent的平衡时间较短,随着迭代次数增加,DQN逐渐学会保持杆子平衡,平均奖励显著提升。
5.2 DQN改进方向
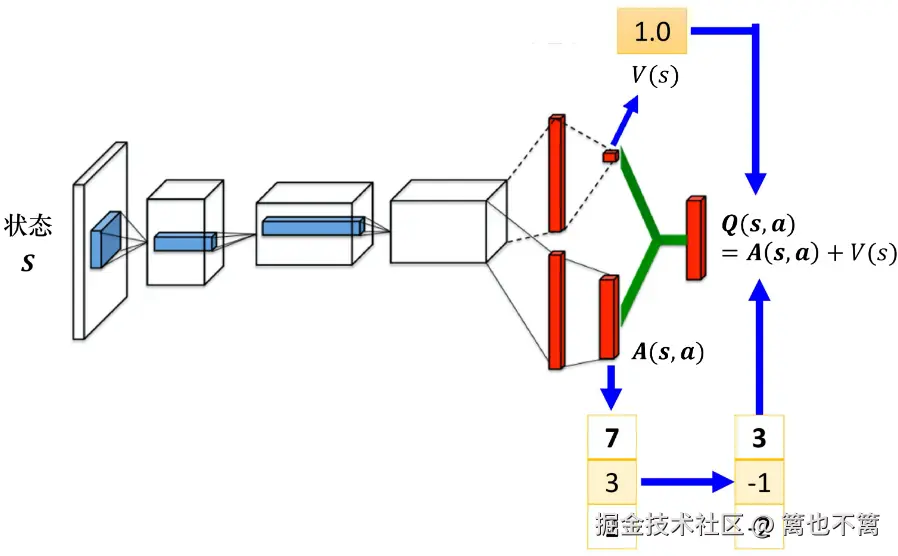
- Double DQN:缓解过估计问题。
- Dueling DQN:分离状态价值与动作优势。
- Prioritized Replay:优先采样高TD误差的数据,提高效率。
六、结论
本文系统研究了强化学习与深度Q网络在AI Agent中的联合应用,结合理论与代码实战验证了其有效性。实验表明,DQN能够显著提升智能体在高维状态空间下的学习能力,并为机器人、游戏AI与智能推荐系统等领域提供了坚实的技术支撑。未来,结合进化算法与多智能体协作的 强化学习+深度学习 框架将成为AI Agent研究的重要方向。