PyTorch生成式人工智能------PatchGAN详解与实现
-
- [0. 前言](#0. 前言)
- [1. PatchGAN 核心原理](#1. PatchGAN 核心原理)
- [2. 网络架构](#2. 网络架构)
- [3. 实现 PatchGAN](#3. 实现 PatchGAN)
-
- [3.1 数据集加载](#3.1 数据集加载)
- [3.2 模型构建](#3.2 模型构建)
- [3.3 模型训练](#3.3 模型训练)
- 相关链接
0. 前言
在生成对抗网络 (Generative Adversarial Network, GAN)的发展历程中,如何提升生成图像的细节质量一直是研究者关注的核心问题。传统的全局判别器往往过于关注图像的整体结构,而忽略了局部细节的真实性,导致生成的面部图像缺乏细腻的纹理特征。正是在这样的技术背景下,PatchGAN 作为一种创新的判别器架构脱颖而出。它通过将图像分割为多个局部区域并进行独立判别,极大地增强了对高频细节的感知能力。本节将深入探讨 PatchGAN 相关原理,并使用 PyTorch 从零开始实现 PatchGAN,并使用 huggan/selfie2anime 数据集训练模型生成动漫人脸图像。
1. PatchGAN 核心原理
PatchGAN 的设计是为了解决图像生成任务中一个常见问题:传统的判别器 (Discriminator) 需要将一整张图片输入,然后输出单一标量值用于预测输入是真实/虚假。这可能导致生成图片在整体结构上看起来合理,但局部细节模糊或缺乏高频信息。
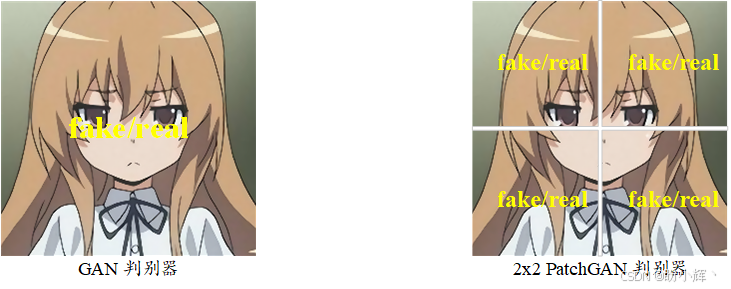
PatchGAN 判别器不是将整张图像分类为真或假,而是将图像分割成重叠的 N x N 图像块 (Patche),并尝试对每个图像块的真假进行分类,如下图所示。最终,判别器的输出不是一个值,而是一个矩阵(或特征图),其中的每个元素代表对应图像块为真实图像的概率。
PatchGAN 提供了全局图像块级约束,为了进一步强化关键细节可以采用局部判别 (Local Discriminator)。全局判别容易忽略微小纹理(如眼睛高光、睫毛、皮肤纹理),局部判别补强这些高频信息。选取图像中的局部裁剪(例如 128×128 )(随机或其它感兴趣区域),专门训练一个判别器区分该局部图像的真实/虚假。
2. 网络架构
模型采用一个生成器与两个判别器,两个分别提供全局图像块级约束(判别器 D_patch )与局部关键细节约束(判别器 D_local),判别器 D_patch 接受生成器产生的图像与真实图像作为输入,并输出 一个 M x M 的矩阵(例如 30x30, 70x70 等,取决于架构深度和输入大小),矩阵中的每个元素 (i, j) 对应于输入图像中的一个感受野 (Receptive Field),即一个图像块 Patch。计算这个 M x M 输出矩阵与一个全为 1 (真实)或 0 (虚假)的同样大小矩阵之间的损失,使用 BCEWithLogitsLoss (或 hinge loss)。
判别器 D_local 与原始生成对抗网络 (Generative Adversarial Network, GAN)类似,不同之处在于接收图像中的局部裁剪区域作为输入,用于强化细节纹理与局部结构的真实感。
3. 实现 PatchGAN
接下来,我们使用 Hugging Face 的 huggan/selfie2anime 数据集(仅动漫脸部分 imageB )训练 PatchGAN,并采用 PatchGAN + 局部判别器的复合判别策略提升局部细节质量。
3.1 数据集加载
(1) 首先,导入所需库,并定义超参数与设备:
python
import os
import math
import random
from pathlib import Path
from tqdm import tqdm
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms, utils
from PIL import Image
from datasets import load_dataset
IMG_SIZE = 256
BATCH_SIZE = 16
Z_DIM = 256
LR = 2e-4
BETA1, BETA2 = 0.5, 0.999
EPOCHS = 200
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
SAMPLES_DIR = Path("samples")
CHECKPOINT_DIR = Path("checkpoints")
SAMPLES_DIR.mkdir(exist_ok=True, parents=True)
CHECKPOINT_DIR.mkdir(exist_ok=True, parents=True)(2) 下载huggan/selfie2anime 数据集并定义数据集类 HFImageDataset():
python
def prepare_hf_dataset(image_field="imageB", split="train"):
print("Loading dataset from Hugging Face: huggan/selfie2anime ...")
hf = load_dataset("huggan/selfie2anime", split=split) # split='train'
print("Dataset loaded. Rows:", len(hf))
return hf
class HFImageDataset(Dataset):
def __init__(self, hf_dataset, image_field="imageB", transform=None):
self.ds = hf_dataset
self.image_field = image_field
self.transform = transform
def __len__(self):
return len(self.ds)
def __getitem__(self, idx):
item = self.ds[idx]
img = item[self.image_field]
if isinstance(img, (list, tuple)):
img = img[0]
if not isinstance(img, Image.Image):
img = Image.fromarray(img)
if self.transform:
img = self.transform(img)
return img(3) 预处理使用 RandomCrop 缩放后裁剪,并归一化到 [-1,1],便于在生成器中使用 tanh 输出:
python
train_transform = transforms.Compose([
transforms.Resize(int(IMG_SIZE * 1.12), interpolation=Image.BICUBIC),
transforms.RandomCrop(IMG_SIZE),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.5]*3, [0.5]*3),
])(4) 加载数据集,且仅使用动漫脸图像 (imageB):
python
hf = prepare_hf_dataset(image_field="imageB", split="train")
dataset = HFImageDataset(hf, image_field="imageB", transform=train_transform)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True, num_workers=4, pin_memory=True)3.2 模型构建
(1) 定义生成器,先将长度为 Z_DIM 的噪声通过全连接映射到 ngf x 4 x 4,再通过一系列 ConvTranspose2d 逐步放大到 256×256,输出用 tanh 映射到 [-1, 1],与数据归一化一致:
python
class Generator(nn.Module):
def __init__(self, z_dim=Z_DIM, ngf=1024, out_channels=3):
super().__init__()
# 从 z 映射到 4x4 特征图
self.fc = nn.Linear(z_dim, ngf * 4 * 4)
self.net = nn.Sequential(
# 4x4 -> 8x8
nn.ConvTranspose2d(ngf, ngf//2, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf//2),
nn.ReLU(True),
# 8x8 -> 16x16
nn.ConvTranspose2d(ngf//2, ngf//4, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf//4),
nn.ReLU(True),
# 16x16 -> 32x32
nn.ConvTranspose2d(ngf//4, ngf//8, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf//8),
nn.ReLU(True),
# 32x32 -> 64x64
nn.ConvTranspose2d(ngf//8, ngf//16, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf//16),
nn.ReLU(True),
# 64x64 -> 128x128
nn.ConvTranspose2d(ngf//16, ngf//32, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(ngf//32),
nn.ReLU(True),
# 128x128 -> 256x256
nn.ConvTranspose2d(ngf//32, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 最后一层输出 3 通道
nn.Conv2d(64, out_channels, kernel_size=3, padding=1),
nn.Tanh()
)
def forward(self, z):
x = self.fc(z).view(z.size(0), -1, 4, 4) # B x ngf x 4 x 4
return self.net(x)(2) 定义 PatchGAN 判别器,输出为特征图(每个位置对应一个 patch 的判别),在训练过程中,我们可以对这个输出使用 BCEWithLogitsLoss 损失,标签 1 对应真实 patch、0 对应虚假 patch:
python
class PatchDiscriminator(nn.Module):
def __init__(self, in_channels=3, ndf=64):
super().__init__()
# 多层卷积下采样,最后输出单通道特征图(判别 map)
def conv_block(in_c, out_c, stride, use_bn=True):
layers = [nn.Conv2d(in_c, out_c, kernel_size=4, stride=stride, padding=1, bias=not use_bn)]
if use_bn:
layers.append(nn.BatchNorm2d(out_c))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
layers = []
layers += [nn.Conv2d(in_channels, ndf, kernel_size=4, stride=2, padding=1), nn.LeakyReLU(0.2, inplace=True)]
layers += conv_block(ndf, ndf*2, stride=2)
layers += conv_block(ndf*2, ndf*4, stride=2)
layers += conv_block(ndf*4, ndf*8, stride=1) # keep stride=1 to keep patch granularity
layers += [nn.Conv2d(ndf*8, 1, kernel_size=4, stride=1, padding=1)] # 单通道 logits map
self.model = nn.Sequential(*layers)
def forward(self, x):
return self.model(x) # 输出 shape: (B,1,H_p,W_p)(3) 定义局部判别器,最终输出一个标量 logit (每个局部 patch 一个判别),训练过程中我们从真实图像与生成图像中随机裁剪局部 patch (例如 128×128) 传递给局部判别器:
python
class LocalDiscriminator(nn.Module):
def __init__(self, in_channels=3, ndf=64):
super().__init__()
self.net = nn.Sequential(
nn.Conv2d(in_channels, ndf, 4, 2, 1), nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf, ndf*2, 4, 2, 1), nn.BatchNorm2d(ndf*2), nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf*2, ndf*4, 4, 2, 1), nn.BatchNorm2d(ndf*4), nn.LeakyReLU(0.2, True),
nn.Conv2d(ndf*4, ndf*8, 4, 2, 1), nn.BatchNorm2d(ndf*8), nn.LeakyReLU(0.2, True),
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(ndf*8, 1, kernel_size=1) # 输出 1x1 logit
)
def forward(self, x):
# x 形状 (B,3,H_loc,W_loc)(例如 128x128)
out = self.net(x) # B x 1 x 1 x 1
return out.view(x.size(0), 1) # (B,1)3.3 模型训练
(1) 初始化模型、优化器以及损失:
python
G = Generator(z_dim=Z_DIM).to(DEVICE)
D_patch = PatchDiscriminator().to(DEVICE)
D_local = LocalDiscriminator().to(DEVICE)
# 初始化权重
def init_weights(m):
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d, nn.Linear)):
nn.init.normal_(m.weight.data, 0.0, 0.02)
if hasattr(m, "bias") and m.bias is not None:
nn.init.constant_(m.bias.data, 0)
G.apply(init_weights)
D_patch.apply(init_weights)
D_local.apply(init_weights)
# 优化器
opt_G = optim.Adam(G.parameters(), lr=LR, betas=(BETA1, BETA2))
opt_D = optim.Adam(list(D_patch.parameters()) + list(D_local.parameters()), lr=LR, betas=(BETA1, BETA2))
# 损失
bce_loss = nn.BCEWithLogitsLoss().to(DEVICE)(2) 定义辅助函数,random_local_patches() 用于在每张图像上随机裁剪同一大小的局部 patch,训练局部判别器,save_samples() 把生成图像从 [-1,1] 映射回 [0,1] 并保存:
python
def random_local_patches(imgs, loc_size=128):
B, C, H, W = imgs.shape
patches = []
for i in range(B):
top = random.randint(0, H - loc_size)
left = random.randint(0, W - loc_size)
patches.append(imgs[i:i+1, :, top:top+loc_size, left:left+loc_size])
return torch.cat(patches, dim=0).to(imgs.device) # (B,3,loc_size,loc_size)
def save_samples(fake_imgs, step, nrow=4):
grid = utils.make_grid((fake_imgs + 1) / 2.0, nrow=nrow, padding=2, normalize=False)
save_path = SAMPLES_DIR / f"sample_{step:06d}.png"
utils.save_image(grid, save_path)
print("Saved samples to", save_path)(3) 定义训练流程,判别器训练阶段同时训练 Patch 判别器和局部判别器;Patch 判别器的损失与局部判别器按比例合并,生成器阶段以欺骗两个判别器为目标:
python
global_step = 0
sample_z = torch.randn(16, Z_DIM, device=DEVICE) # 固定噪声用于可视化
for epoch in range(EPOCHS):
loop = tqdm(dataloader, desc=f"Epoch {epoch+1}/{EPOCHS}")
for real in loop:
real = real.to(DEVICE) # (B,3,256,256)
B = real.size(0)
# Train Discriminators (patch + local)
opt_D.zero_grad()
# Patch discriminator on real
logits_real_patch = D_patch(real)
# create labels (same shape as logits)
labels_real_patch = torch.ones_like(logits_real_patch, device=DEVICE) * 0.9 # label smoothing
loss_D_patch_real = bce_loss(logits_real_patch, labels_real_patch)
# Generate fake images
z = torch.randn(B, Z_DIM, device=DEVICE)
fake = G(z)
logits_fake_patch = D_patch(fake.detach())
labels_fake_patch = torch.zeros_like(logits_fake_patch, device=DEVICE)
loss_D_patch_fake = bce_loss(logits_fake_patch, labels_fake_patch)
loss_D_patch = (loss_D_patch_real + loss_D_patch_fake) * 0.5
# Local discriminator on random patches
real_local = random_local_patches(real, loc_size=128) # (B,3,128,128)
fake_local = random_local_patches(fake.detach(), loc_size=128)
logits_real_local = D_local(real_local) # (B,1)
logits_fake_local = D_local(fake_local) # (B,1)
labels_real_local = torch.ones_like(logits_real_local, device=DEVICE) * 0.9
labels_fake_local = torch.zeros_like(logits_fake_local, device=DEVICE)
loss_D_local = 0.5 * (bce_loss(logits_real_local, labels_real_local) +
bce_loss(logits_fake_local, labels_fake_local))
# Total discriminator loss
loss_D = loss_D_patch + 0.7 * loss_D_local
loss_D.backward()
opt_D.step()
# Train Generator
opt_G.zero_grad()
z2 = torch.randn(B, Z_DIM, device=DEVICE)
fake2 = G(z2)
# Try to fool both discriminators
# Patch GAN objective (we want D_patch(fake) -> 1)
logits_fake_patch_forG = D_patch(fake2)
labels_G_patch = torch.ones_like(logits_fake_patch_forG, device=DEVICE)
loss_G_patch = bce_loss(logits_fake_patch_forG, labels_G_patch)
# Local objective
fake_local2 = random_local_patches(fake2, loc_size=128)
logits_fake_local_forG = D_local(fake_local2)
labels_G_local = torch.ones_like(logits_fake_local_forG, device=DEVICE)
loss_G_local = bce_loss(logits_fake_local_forG, labels_G_local)
loss_G = loss_G_patch + 0.7 * loss_G_local
loss_G.backward()
opt_G.step()
global_step += 1
if global_step % 10 == 0:
loop.set_postfix({
"loss_D": f"{loss_D.item():.4f}",
"loss_G": f"{loss_G.item():.4f}"
})
if global_step % 500 == 0:
with torch.no_grad():
samples = G(sample_z).cpu()
save_samples(samples, global_step, nrow=4)
torch.save({
'epoch': epoch,
'G_state_dict': G.state_dict(),
'D_patch_state_dict': D_patch.state_dict(),
'D_local_state_dict': D_local.state_dict(),
'opt_G': opt_G.state_dict(),
'opt_D': opt_D.state_dict()
}, CHECKPOINT_DIR / f"ckpt_epoch_{epoch:03d}.pth")
print(f"Saved checkpoint for epoch {epoch}")生成结果如下所示,可以看到随着训练生成的图像越来越逼真:

相关链接
PyTorch生成式人工智能实战:从零打造创意引擎
PyTorch生成式人工智能(1)------神经网络与模型训练过程详解
PyTorch生成式人工智能(2)------PyTorch基础
PyTorch生成式人工智能(3)------使用PyTorch构建神经网络
PyTorch生成式人工智能(4)------卷积神经网络详解
PyTorch生成式人工智能(5)------分类任务详解
PyTorch生成式人工智能(6)------生成模型(Generative Model)详解
PyTorch生成式人工智能(7)------生成对抗网络实践详解
PyTorch生成式人工智能(8)------深度卷积生成对抗网络
PyTorch生成式人工智能(9)------Pix2Pix详解与实现
PyTorch生成式人工智能(10)------CyclelGAN详解与实现
PyTorch生成式人工智能(11)------神经风格迁移
PyTorch生成式人工智能(12)------StyleGAN详解与实现
PyTorch生成式人工智能(13)------WGAN详解与实现
PyTorch生成式人工智能(14)------条件生成对抗网络(conditional GAN,cGAN)
PyTorch生成式人工智能(15)------自注意力生成对抗网络(Self-Attention GAN, SAGAN)
PyTorch生成式人工智能(16)------自编码器(AutoEncoder)详解
PyTorch生成式人工智能(17)------变分自编码器详解与实现
PyTorch生成式人工智能(18)------循环神经网络详解与实现
PyTorch生成式人工智能(19)------自回归模型详解与实现
PyTorch生成式人工智能(20)------像素卷积神经网络(PixelCNN)
PyTorch生成式人工智能(24)------使用PyTorch构建Transformer模型
PyTorch生成式人工智能(25)------基于Transformer实现机器翻译
PyTorch生成式人工智能(26)------使用PyTorch构建GPT模型
PyTorch生成式人工智能(27)------从零开始训练GPT模型
PyTorch生成式人工智能(28)------MuseGAN详解与实现