当我们一边惊叹🤯于ChatGPT等大语言模型(LLM)像脱口秀演员一样流畅输出文本,一边又得忍受它时不时"编故事""忘更新""查不到内部文件"的毛病时------你是不是也觉得这AI像个记忆力时好时坏的老教授?
于是,检索增强生成(Retrieval-Augmented Generation,简称RAG)闪亮登场!它就像是给这位"老教授"配了一位靠谱的图书管理员+实时百科小助手 🧠。
什么是RAG?
检索增强生成(RAG)是一种结合信息检索和生成式模型的技术方案。其主要流程包括两个核心环节:
1. 检索(Retrieval) :基于用户的输入,从外部知识库中检索与查询相关的文本片段,通常使用向量化表示和向量数据库进行语义匹配。
2. 生成(Generation):将用户查询与检索到的内容作为上下文输入给生成模型(如GPT等),由模型输出最终回答。
即我们在本地检索 到相关的内容,把它增强 到提示词里,然后再去做结果生成。
核心比喻
将RAG比作一个开卷考试的学生最为贴切:
- 传统LLM:如同闭卷考试的学生,只能依靠记忆(训练数据)回答问题,难免遗漏或错误
- RAG增强的LLM :如同开卷考试的学生,面对问题时先精准检索 相关资料,随后用这些权威信息增强 认知,最终生成准确可靠的答案。
这种方法完美解决了LLM的三大痛点:
- 知识的局限性:大模型自身的知识完全源于训练数据,而现有的主流大模型(deepseek、文心一言、通义千问...)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或私域的数据是没有。
- 幻觉问题:所有的深度学习模型的底层原理都是基于数学概率,模型输出实质上是一系列数值运算,大模型也不例外,所以它经常会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的任务场景。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,尤其是大公司,没有人将私域数据上传第三方平台进行训练会推理。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG的工作流程详解
RAG的实施分为两个主要阶段,下图清晰地展示了这一流程:
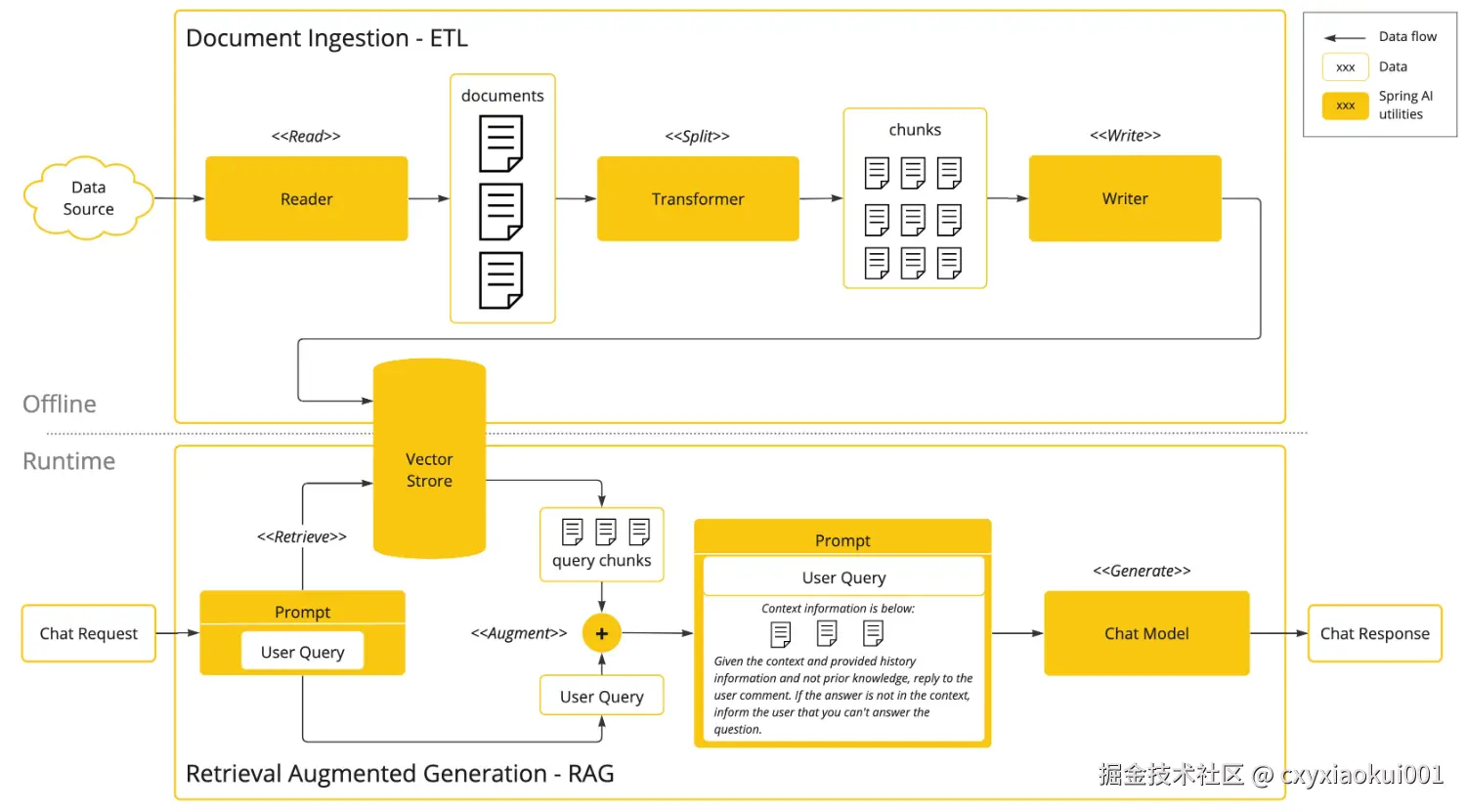
具体可分为以下两部分:
-
文档摄取(ETL)流程(离线处理)📥
- 数据读取:从数据源(如文档、数据库)读取原始文档。
- 分割文档 :通过分割模块(
<<Split>>)将文档切分为更小的数据块(chunks)。 - 转换数据 :通过转换模块(
Transformer)处理数据块(如向量化、添加元数据)。 - 写入存储 :将处理后的数据块写入向量数据库(
Vector Store),为后续检索做准备。 - 核心目标:将非结构化文档转化为结构化、可检索的向量数据。
-
检索增强生成(RAG)流程(实时处理)🧠
- 用户查询 :接收用户提问(
Chat Request)。 - 检索相关块 :从向量库中检索与查询最相关(相似度高)的数据块(
<<Retrieve>>)。 - 增强查询 :将检索到的上下文信息(
Context information)与用户问题结合,生成增强后的提示(<<Augment>>)。 - 生成响应 :通过聊天模型(
Chat Model)生成回答。 - 核心目标: 通过外部知识库提升生成结果的准确性,解决了大模型信息缺失或滞后的问题。
- 用户查询 :接收用户提问(
相似度计算
在上述的原理中,我们知道,在向大模型发起请求前,需要到向量库(知识库)查询,而且是相似性的查询,那究竟什么是相似性查询?也就是说,如何判断两个文字相似呢?比如:北京 和 北京市,这两个词相似度高,北京 和 天津市,这两个词相似度就低。怎么做到呢?
这就要用到计算机的"灵魂绝技"------把文字变成数学!
解决方案:
-
先将数据(文字或图片等)向量化
- 为什么要向量化?什么是向量化?
- 这是因为,计算机无法直接理解文本、图片等非结构化数据的,向量化就是把文本等数据转化为一组数字,这样计算机就能识别了。
-
通过相似度算法进行判断
- 余弦相似度: 是通过计算两个向量在多维空间中的夹角余弦值来评估它们的相似度。
- 欧式距离:是衡量空间中两点间直线距离典方法。
- 余弦相似度的取值范围是-1, 1,夹角越小(即余弦值越接近于1),两个向量越相似。
- 欧式距离值越小越相似,反之越不相似。
向量数据库
向量数据库就是用来存储向量数据的数据库,Spring AI也支持了很多的向量数据库,如下:👉Vector Databases
erlang
Azure Vector Search - The Azure vector store.
Apache Cassandra - The Apache Cassandra vector store.
Chroma Vector Store - The Chroma vector store.
Elasticsearch Vector Store - The Elasticsearch vector store.
GemFire Vector Store - The GemFire vector store.
MariaDB Vector Store - The MariaDB vector store.
Milvus Vector Store - The Milvus vector store.
MongoDB Atlas Vector Store - The MongoDB Atlas vector store.
Neo4j Vector Store - The Neo4j vector store.
OpenSearch Vector Store - The OpenSearch vector store.
Oracle Vector Store - The Oracle Database vector store.
PgVector Store - The PostgreSQL/PGVector vector store.
Pinecone Vector Store - PineCone vector store.
Qdrant Vector Store - Qdrant vector store.
Redis Vector Store - The Redis vector store.
SAP Hana Vector Store - The SAP HANA vector store.
Typesense Vector Store - The Typesense vector store.
Weaviate Vector Store - The Weaviate vector store.
SimpleVectorStore - 一种简单的基于内存存储的持久化向量存储实现,适合用于教育目的。RAG实战 :搭一个"会查资料的AI"
在学习过程中,我们一般使用SimpleVectorStore来进行向量存储,但是实际项目中,是不可能用内存存储的。此处我比较推荐选择Elasticsearch来存向量数据,主要是从实际业务和技术角度做的决定。说白了,就是看中它既稳当又能干,能帮我们解决具体的搜索问题。虽然大多数系统本来就在用ElasticSearch做搜索和日志处理,但建议重新搭建一个新的ES专门做向量存储。
集成ES的依赖
xml
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-elasticsearch-store-spring-boot-starter</artifactId>
<exclusions>
<exclusion>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>co.elastic.clients</groupId>
<artifactId>elasticsearch-java</artifactId>
<version>8.15.5</version>
</dependency>配置ES
在application.yml文件中进行配置,但此处我更推荐配置在nacos的配置中心,方便后续动态调整:
yml
spring:
elasticsearch:
uris: http://xxxx
ai:
dashscope:
api-key: ${kr.ai.dashscope.key}
chat:
enabled: true
options:
model: qwen-plus
embedding:
enabled: true
options:
model: text-embedding-v3 #向量模型
dimensions: 1024 #向量维度维度
vectorstore: #向量库配置
elasticsearch: #使用ES作为向量库存储
initialize-schema: true #开启初始化向量库结构
dimensions: 1024 #向量维度写入数据(EmbeddingController)
java
@Slf4j
@RestController
@RequestMapping("/embedding")
@RequiredArgsConstructor
public class EmbeddingController {
private final VectorStore vectorStore;
@PostMapping
public void saveVectorStore(@RequestParam("messages") List<String> messages) {
log.info("保存到向量数据库中,消息数据:{}", messages);
//构建文档
List<Document> documents = CollStreamUtil.toList(messages, message -> Document.builder()
.text(message)
.build());
//存储到向量数据库中
this.vectorStore.add(documents);
log.info("保存到向量数据库成功, 数量:{}", messages.size());
}
}集成到ChatClient
java
private final ChatMemory chatMemory;
private final VectorStore vectorStore;
@Override
public Flux<ChatEventVO> chat(String question, String sessionId) {
// 获取对话id
String conversationId = ChatService.getConversationId(sessionId);
// 大模型输出内容的缓存器,用于在输出中断后的数据存储
StringBuilder outputBuilder = new StringBuilder();
return chatClient.prompt()
.system(promptSystem -> promptSystem
.text(systemPromptConfig.getChatSystemMessage().get()) // 设置系统提示语
.param("now", DateUtil.now()) // 设置当前时间的参数
)
.advisors(advisor -> advisor
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.builder().query(question).topK(5).build()))
.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, conversationId)
.user(question)
.stream()
.chatResponse()
.doFirst(() -> { //输出开始,标记正在输出
GENERATE_STATUS.put(sessionId, true);
})
.doOnComplete(() -> { //输出结束,清除标记
GENERATE_STATUS.remove(sessionId);
})
.doOnError(throwable -> GENERATE_STATUS.remove(sessionId)) // 错误时清除标记
.doOnCancel(() -> {
// 当输出被取消时,保存输出的内容到历史记录中
saveStopHistoryRecord(conversationId, outputBuilder.toString());
})
// 输出过程中,判断是否正在输出,如果正在输出,则继续输出,否则结束输出
.takeWhile(s -> Optional.ofNullable(GENERATE_STATUS.get(sessionId)).orElse(false))
.map(chatResponse -> {
// 获取大模型的输出的内容
String text = chatResponse.getResult().getOutput().getText();
// 追加到输出内容中
outputBuilder.append(text);
// 封装响应对象
return ChatEventVO.builder()
.eventData(text)
.eventType(ChatEventTypeEnum.DATA.getValue())
.build();
})
.concatWith(Flux.just(ChatEventVO.builder() // 标记输出结束
.eventType(ChatEventTypeEnum.STOP.getValue())
.build()));
}
/**
* 保存停止输出的记录
*
* @param conversationId 会话id
* @param content 大模型输出的内容
*/
private void saveStopHistoryRecord(String conversationId, String content) {
chatMemory.add(conversationId, new AssistantMessage(content));
}RAG的优势与价值
| 特性 | 传统LLM | RAG增强的LLM |
|---|---|---|
| 知识来源 | 静态的训练数据 | 动态外部知识库 + 训练数据 |
| 时效性 | 知识滞后 | 可获取最新信息 |
| 准确性 | 可能产生"幻觉" | 大幅减少幻觉,有据可查 |
| 可信度 | 较低,"黑盒"操作 | 更高,可提供引用来源 |
| 成本 | 微调模型成本极高 | 低成本,仅需更新知识库 |
🎉 所以说,RAG就是那个让AI既保持才华、又不乱说话的"良心外挂"。现在你也能搭建一个既聪明又老实,还能引经据典的AI助手啦!