
zip

zip 与 gzip、bzip2的区别,
当压缩多个文件时,zip 是最终将多个文件压缩到一个包,
而gzip、bzip2 是一个文件压一个包,多个文件压成多个包

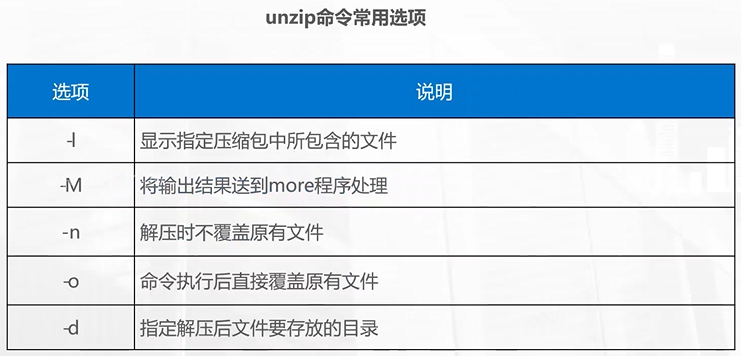
unzip

tar

Tape Archive
磁带归档
在计算机早期,磁带是最主要、最经济的大容量存储和备份介质
tar 命令最初就是设计用来将多个文件打包成一个单独的归档文件,以便写入磁带进行备份或传输。
把一大堆文件和目录集合成一个单一的文件
这个过程本身并不进行压缩
打包后的单个文件的大小与源文件的大小之和相同
为了节省空间,我们通常会在打包后立即进行压缩,或者反过来,先解压再解开打包
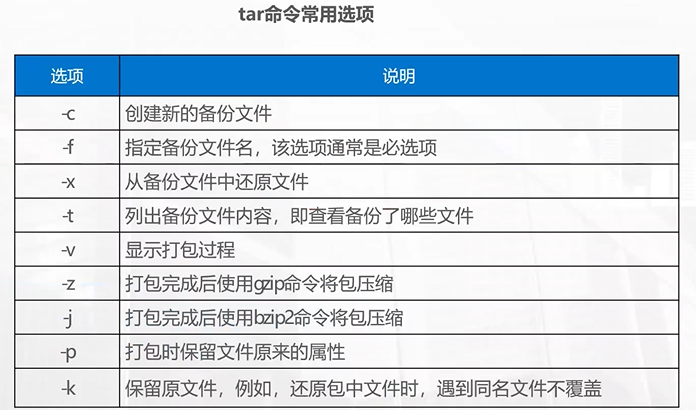
创建 tar 包时,会保留原文件


Yellowdog Updater Modified
Yellowdog Updater (YU):
yum 的前身是一个名为 yup 的软件包管理器,
它用于另一个叫做 Yellow Dog Linux 的发行版(这个发行版主要运行在 PowerPC 架构上,比如早期的苹果 Mac 电脑)
Modified (M):
后来,杜克大学的开发团队在 yup 的基础上进行了大量的改进和重写,
形成了我们今天使用的 yum。
为了向它的前身致敬,
并表明它是一个修改版,
就命名为 "Yellowdog Updater, Modified"
90年代末苹果还在用PowerPC,Linux社区想支持更多硬件,于是就有了 Yellowdog 这版 linux
"黄狗"的直白来源:公司的标志
开发 Yellow Dog Linux 的公司叫 Terra Soft Solutions。
这家公司的标志/吉祥物就是一只黄色的
拉布拉多犬,名字叫 "Penguin"(没错,就是Linux那只企鹅的名字)。/ˈpeŋɡwɪn/公司标志性的"黄狗"来命名其旗舰产品
"Underdog"的精神:在英语中,"Yellow Dog"有一个不太常用的含义,指"卑劣的人"或"懦夫",但更贴切的理解是它与
"Underdog" 这个概念相关联
"Underdog"指的是比赛中不被看好的、处于劣势的一方。
在当时的个人电脑市场,基于PowerPC架构的计算机(主要是苹果的Power Mac)相对于统治性的Intel x86架构,就是这样一个"Underdog"。
Yellow Dog Linux 就是要为这些"非主流"平台提供强大的操作系统支持, empowering the underdog。
对"红帽"的调侃:这是最广为人知、也最有趣的一点。当时Linux世界最著名的发行版是 Red Hat Linux。Terra Soft Solutions的创始人之一曾经开玩笑地说,给系统起名"Yellow Dog"是因为 "黄狗(Yellow Dog)总得找点东西吃,而红帽子(Red Hat)看起来就是个不错的目标"。
这个说法非常形象地体现了Linux世界百花齐放、互相竞争又充满幽默感的社区文化。Yellow Dog Linux 明确地将自己定位为Red Hat在PowerPC平台上的一个替代品和竞争者。
"黄狗"不仅仅是一个随意的名字,它是一个充满了故事、态度和时代印记的符号。
虽然Yellow Dog Linux现在已经不再活跃,
但它的遗产------yum包管理器,
以及这个有趣的名字由来------依然被很多人记住
yum 是 Red Hat、CentOS、Fedora 等 Linux
发行版上默认的 RPM 软件包管理器。
yum会从指定的在线软件仓库(repository)上自动下载、安装、更新、删除软件包,并自动处理依赖关系
Red Hat Package Manager
Red Hat Linux 开发的命令行方式的包管理系统
基于 Red Hat 的 Linux 发行版(如 RHEL, CentOS, Fedora, openSUSE 等)上安装、卸载、验证、查询和更新软件包
yum 的主要竞争对手是 Debian/Ubuntu 系列上的 APT
Advanced Package Tool
yum 带点草根幽默,APT 则更官方严谨
Debian/Ubuntu 系列使用 APT
一套完整的、智能的软件包管理系统
Package: 指软件包。在 Debian/Ubuntu 上,就是那些以 .deb 结尾的文件
APT 的"高级"之处主要体现在它的依赖关系处理能力上
自动处理依赖:
当你安装一个软件包 A 时,APT 会自动计算出 A 需要哪些库和程序(即依赖包
B、C、D),然后从软件源(repository)中一起下载并安装所有必需的包
智能解决冲突:
它会尝试解决不同软件包之间可能存在的冲突
提供统一的软件源接口:
你只需要配置好软件源地址(在 /etc/apt/sources.list 中),APT 就能处理所有与服务器通信、获取软件包列表、下载和安装的工作
当提到 Debian/Ubuntu 的包管理系统时,APT 是它的正式名称和技术总称
yum 已经被 dnf 所取代
dnf 是 yum 的下一代版本,
但为了保持用户习惯,在系统中仍然保留了 yum 命令,
它实际上是指向 dnf 的一个软链接。
所以在这些新系统上使用 yum 命令,实际上是在使用 dnf。
在 RHEL 8、CentOS 8、Rocky Linux 8、AlmaLinux 8 及更新的版本,以及 Fedora 22+ 等系统中,当你运行 yum 命令时,你实际上是在使用 dnf。
yum现在只是dnf的软链接
DNF 代表 "Dandified YUM"。
Dandified:意为"华丽的"、"时髦的"、"改良的"。这表示它是 YUM 的一个更先进、更现代化的版本。
/'dændifaid/
花花公子
November2025the16thSunday

这里说的避免,指的是 gzip、bzip2 都是只能单入单出的压缩,不能多入单出,所以先用 tar 命令把多个文件归档成单一的文件,然后再使用 gzip、bzip2 进行文件压缩,这样就避免了gzip、bzip2 都是只能单入单出的压缩的问题了。
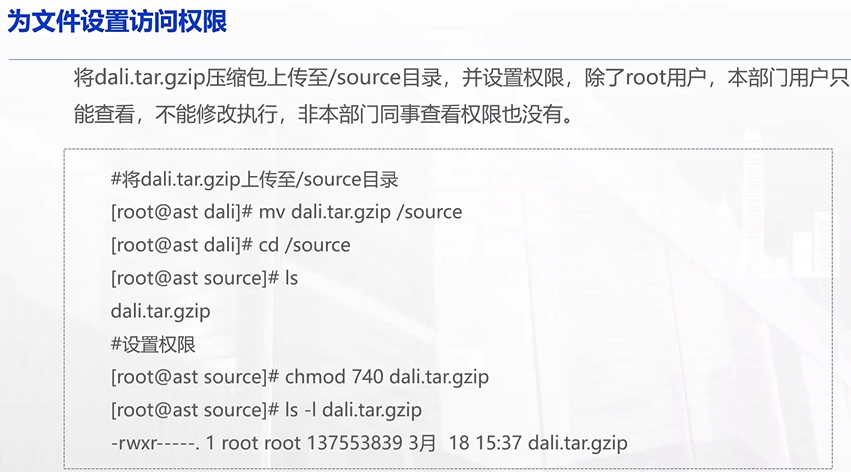
chmod

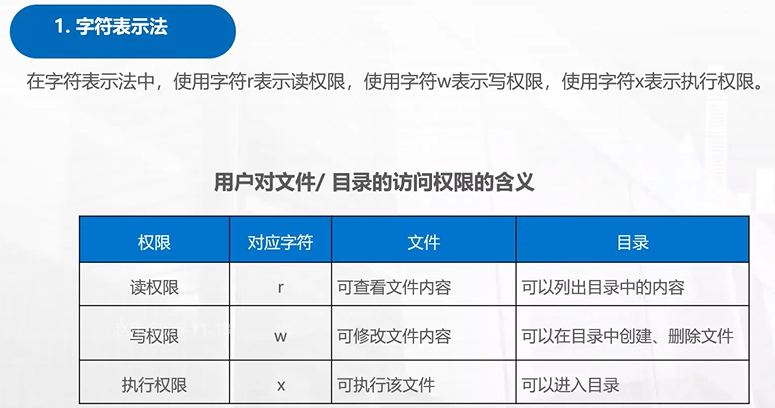

rwx
读(r)、写(w)、执行(x)
文件的所有者、所属组的用户、其他用户
分别拥有自己的rwx权限
读权限(r):
允许读取文件内容,或列出目录中的文件(如果用于目录)。
写权限(w):允许修改文件内容,或在目录中创建、删除文件(如果用于目录)。
执行权限(x):允许执行文件(如果是可执行文件或脚本),或允许进入目录(如果用于目录)。
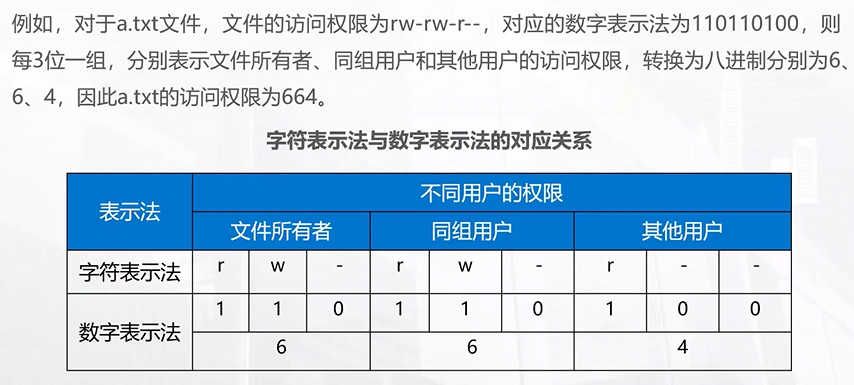
3位二进制数
111 7 可读、可写、可执行
110 6 可读、可写、不可执行
101 5 可读、不可写、可执行
100 4 只可读
011 3 不可读、可写、可执行
cpp
可写必先可读010 2 只可写
cpp
只可写(仅写权限)在技术上是可行的,
但实际使用中不常见,
因为写操作通常伴随着读操作(如编辑文件)001 1 只可执行
cpp
只可执行(仅执行权限)在技术上也可以设置,
但对于二进制文件可能无法正常执行,
对于脚本文件则肯定无法执行,
因为解释器需要读权限所以,
001、010、011 的权限类型不常被使用
也就是说,
每种权限类型中至少要有可读权限那么用十进制表示权限的时候,权限类型的数字表示形式其值不会小于4
写入文件之前需要先读取文件
在目录中创建文件之前需要列出目录内容和进入目录
文件是二进制可执行文件,那么没有读权限可能不会影响执行,因为执行时不需要读取文件内容(实际上,执行时需要读取文件中的指令,但是这是由系统通过内存映射等方式完成的,不需要用户态的读权限?)。
然而,实际上,对于可执行文件,通常需要读权限才能被加载执行。因为执行一个文件时,系统需要读取文件的内容来加载到内存中。所以,如果去掉读权限,可能会导致无法执行。
对于脚本文件(如shell脚本),则必须要有读权限,因为解释器需要读取脚本内容。因此,只设置执行权限而不设置读权限对于二进制可执行文件可能可以工作(取决于系统如何执行,但通常需要读权限),但对于脚本文件则不行。
Linux系统上,要执行一个文件,通常需要同时具有读和执行权限
November2025the18thTuesday



使用 chmod 给文件加上写权限(w)时,不会自动添加读权限(r)。
读、写、执行是三个完全独立的权限位,修改其中一个不会影响另外两个
ls -l total 8
---------- 1 root root 0 Nov 19 10:47 a.txt
-rw-r--r-- 1 root root 114 Dec 26 2020 bench.py
-rw-r--r-- 1 root root 185 Sep 9 2018 hello.c
---------- 是以字符模式显示权限,减号等于0。
这10个减号也意味着是10个0即没有任何权限
第一个字符 - 是文件类型,其他减号分成3组,
第一组三个减号表示用户,
第二组三个减号表示用户所在的组
第三组三个减号表示其他用户
使用数字模式表达文件权限相对于字符模式表达文件权限的优势是:
1.直观,rwx 等于 7
2.简洁,一组 rwx 用 1 个二进制位就可以表示了
-rwxrwxrwx 可以使用 000 来表示
3.不需要指定对象,3 位二进制数 000 分别对应,持有者、所在组、其他用户
对于一个目录有写权限但没有执行权限,操作仍然会失败
给目录设置权限时,w 和 x 权限通常是捆绑的(例如 chmod 777)
November2025the19th


chown

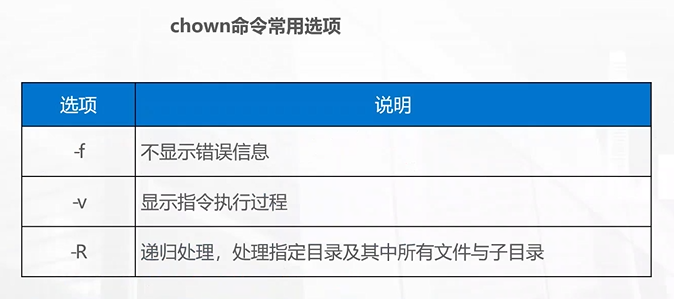
想要做 chown 相关的实验,
需要先知道当前系统有多少个可以使用的用户
使用 getent 命令可以列出当前系统都有哪些用户
也可以显示指定的某个用户的具体信息
使用 getent 命令列出当前系统中 root 用户在 passwd 数据库文件中的具体信息。
cpp
getent passwd rootroot❌0:0:root:/root:/bin/bash
getent 数据库名称 键
getent passwd
相当于查看 /etc/passwd
获取所有用户信息
getent passwd root查看 /etc/passwd
并获取 root 用户的信息
getent hosts www.google.comgetent hosts 8.8.8.8
相当于查询 /etc/hosts
查询主机名/IP地址
getent services ssh相当于查看 /etc/services
查询 ssh 服务
getentget entries
获取条目
从系统管理的各种数据库中获取条目
getent 命令的作用就是提供一个统一、一致的接口,按照 nsswitch.conf 文件(Name Service Switch config )定义的顺序,从这些配置的数据库中查询信息
在 Linux 系统中,很多信息(如用户、组、主机名、服务等)并不只是存储在单一的 /etc/passwd 或 /etc/hosts 文件中。
它们可能来自多个来源,例如:
本地文件:如 /etc/passwd, /etc/group, /etc/hosts
顺序由 /etc/nsswitch.conf 文件定义
(Name Service Switch config )
可通过 cat 命令来查看 nsswitch.conf 文件,以获取其中各个数据库文件的排序。
getent 可以查询多种数据库,常见的包括:
passwd
group
hosts
services
protocols
networks
aliases(用于邮件别名)
getent 的核心思想就是:
"给我(get) 指定数据库里关于这个键的条目(entry)"
关于 passwd 文件的一些内容
在 /etc/passwd 文件中,每行包含
7个字段,用冒号分隔
username:x:UID:GID:comment:home_directory:shell
username:用户名
x:密码占位符(实际密码在 /etc/shadow)
UID:用户ID
GID:主组ID
comment:用户全名或描述
home_directory:家目录路径
shell:默认shell
通常UID从1000开始的是普通用户,
1000以下的是系统用户
getent passwd root
c
root:x:0:0:root:/root:/bin/bash- 用户名 root
- 密码占位符 x
- 用户ID 0
- 主组ID 0
- 用户全名 root
- 家目录路径 /root
- 默认shell /bin/bash
getent 命令支持的数据库
Supported databases:
ahosts
ahostsv4
ahostsv6
aliases
ethers
group
gshadow
hosts
initgroups
netgroup
networks
passwd
protocols
rpc
services
shadow
用 getent 命令对数据库 passwd 中 test 用户的信息进行查询
getent passwd test
test❌1000:1000::/home/test:/bin/bash
- 用户名 test
- 密码占位符 x
- 用户ID 1000
- 主组ID 1000
- 用户全名 无
- 家目录路径 /home/test
- 默认shell /bin/bash

文件链接

文件信息:
1.文件大小
2.文件类型
3.创建时间
4.访问权限
5.文件位置
。。。
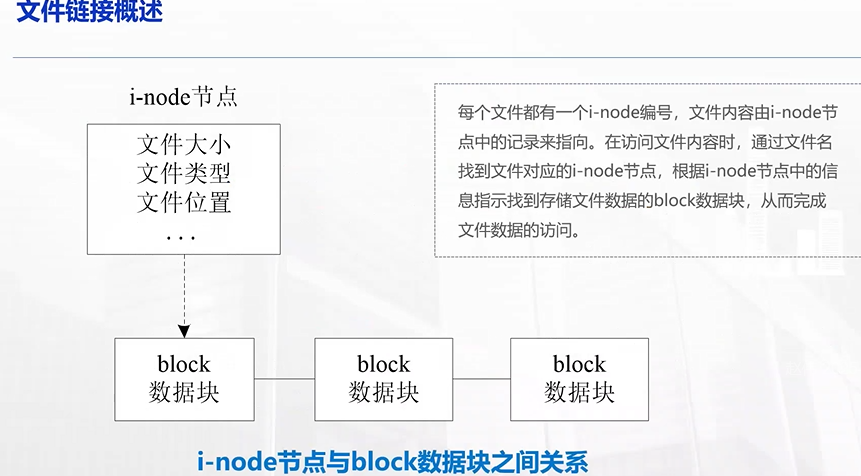
注意看,
i-node 存储着文件位置,也就是数据块的位置,
所以找到了 i-node 就能找到文件的内容了

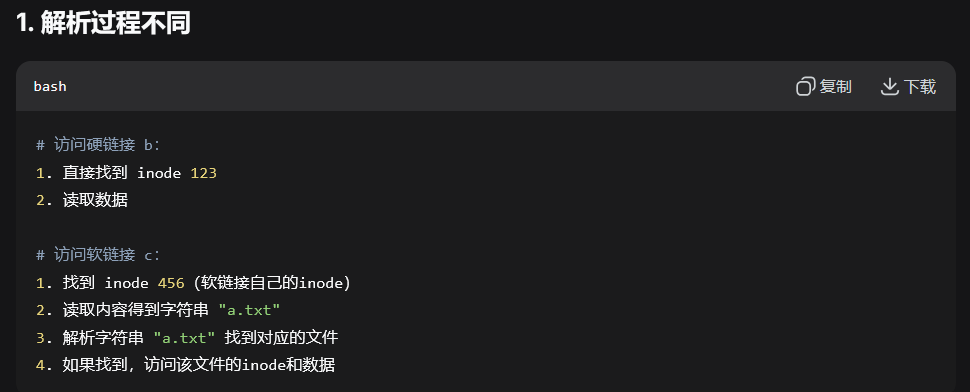
通过硬链接可以找到 i-node 进而再通过 i-node 找到数据块的位置最终找到文件内容。
创建硬链接后,原始文件名和硬链接都指向同一个i-node,该i-node的链接计数变为2。
当删除原始文件时,i-node的链接计数减1,变成1(因为还有硬链接指向它),所以文件数据并没有被删除,仍然可以通过硬链接来访问。
硬链接示意图,如下:
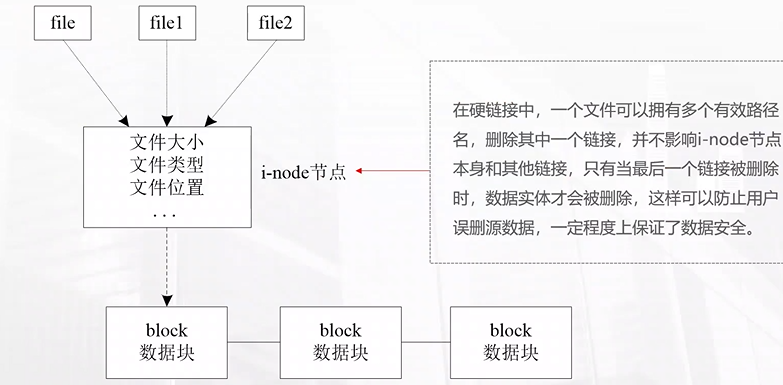
硬链接示意图内容,文字图在下方:
1.一个文件(File)由inode(索引节点)表示,inode中包含文件的元数据(如权限、所有者、时间戳等)以及指向数据块(Data Blocks)的指针。
2.多个文件名(例如:File1, File2)指向同一个inode。
3.每个文件名都是一个硬链接,它们通过inode号与inode关联。
4.inode中有一个计数器(link count)记录指向它的硬链接数量,图中显示为2。

1.文件A和文件B都是硬链接,指向同一个i-node 8
2.i-node中的链接计数为2
3.删除任何一个文件名都不会影响数据,只有当链接数为0时数据才被真正删除
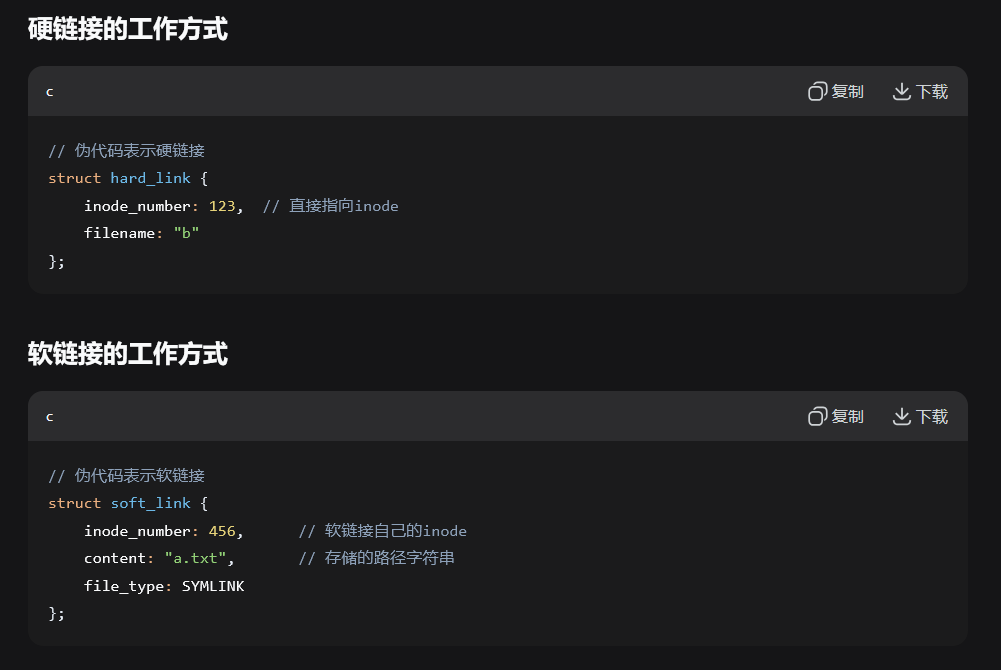
硬链接 (Hard Link)
ln source_file hard_link
本质:是同一个文件的另一个名称(指向相同的 i-node)
就像是 i-node 的 n 个快捷方式中的一个
存储:不占用额外的磁盘空间
关系:与原始文件完全平等,没有主从关系
ln a.txt ba.txt (i-node 123) ← 文件数据
b (i-node 123) ← 指向相同的数据
删除 a.txt 后,文件数据(因为 i-node 123还在,i-node存储着数据块的地址,所以通过 i-node 123 还能找到数据块)仍然存在,因为还有 b 指向它(i-node 123)
注意:只有i-node 123 所有的硬链接都没有了,系统才会释放掉 i-node 123 占用的存储空间,
硬链接是多个目录条目(文件名)直接指向同一个 i-node
硬链接:与目标文件共享同一个 i-node,因此它们是完全平等的,删除目标文件(即减少一个硬链接)只要还有硬链接存在,文件数据就不会被删除。

软链接 (Symbolic Link / Soft Link)
ln -s source_file soft_link
本质:是一个特殊的文件,包含目标文件的路径
cpp
对于这个"目标文件的路径",可以这么理解
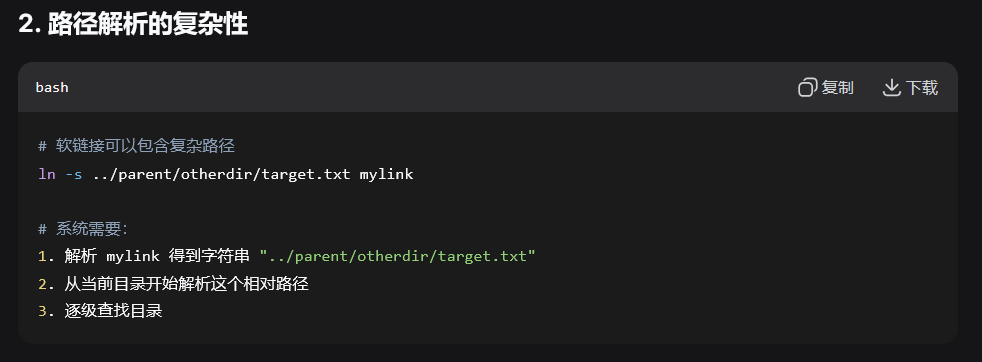
假设我们有一个软链接c,它指向a.txt。
那么软链接c文件的内容就是字符串"a.txt"
(实际上是包含路径的字符串,可能是绝对路径或相对路径)。
当我们通过软链接c访问时,
系统会读取c的内容,
然后去查找名为a.txt的文件。
如果a.txt被删除了,那么查找就会失败。存储:占用少量磁盘空间存储路径信息
关系:依赖于原始文件,是原始文件的 "快捷方式"
ln -s a.txt ca.txt (inode 123) ← 文件数据
c (inode 456) ← 包含字符串 "a.txt"
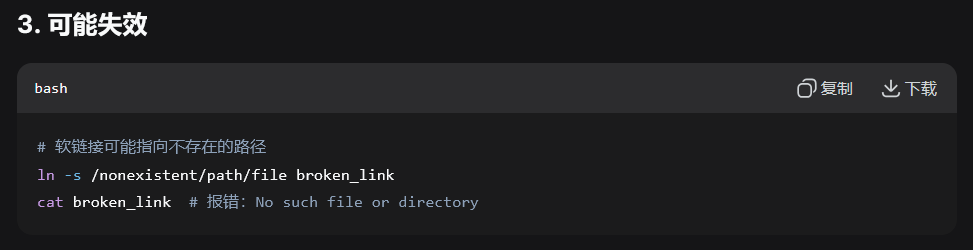
删除 a.txt 后,c 仍然指向 "a.txt",但该文件(a.txt)已不存在。断链了。
因为 c 是软链接,它只包含指向 "a.txt" 的路径。当 a.txt 被删除后,这个路径就无效了
软链接是一个独立的文件,其内容是一个路径字符串。当我们访问软链接时,系统会读取这个路径字符串,然后去访问该路径所指向的文件
cpp
对于这个"目标文件的路径",可以这么理解
假设我们有一个软链接c,它指向a.txt。
那么软链接c文件的内容就是字符串"a.txt"
(实际上是包含路径的字符串,可能是绝对路径或相对路径)。
当我们通过软链接c访问时,
系统会读取c的内容,
然后去查找名为a.txt的文件。
如果a.txt被删除了,那么查找就会失败。软链接示意图

软链接相当于 Windows 系统中的快捷方式,
但是软链接 指向的是原始文件名 ,而原始文件名已经被删除,所以当通过软链接访问时,系统找不到始文件名,因此报错
如果原始文件名被删除,软链接就会变成"断链",访问时就会报错。
软链接是一个指向文件路径的快捷方式,如果原始文件被删除,软链接就会失效。
原始文件本质上也可以被视为一个硬链接。
在Linux文件系统中,每个文件至少有一个硬链接(即其本身)。
当创建一个文件时,系统会分配一个i-node(索引节点)来存储文件的元数据(如权限、所有者、时间戳等)以及指向文件数据块的指针。
同时,目录中会创建一个条目(即文件名)指向这个inode。
这个条目就是硬链接
cpp
原始文件名--->i-node 123--->数据块
cpp
硬链接--->i-node 123--->数据块所以,原始文件名等同于硬链接
上图解释:
1.软链接有自己的 i-node 和数据块
即 i-node 15 和数据块2050
2.数据块中存储的是目标文件的路径字符串
即 target_file ,
系统将会按照 2050数据块中存储的信息(目标文件的路径字符串)去定位目标文件 target_file
3.删除目标文件( target_file )后,软链接成为"悬空链接"
因为,
在删除目标文件 target_file后, 系统根据2050数据块中存储的字符串 target_file 是无法定位到 i-node 22 的,因此就找不到 i-node 22 指向的 数据块 1001,所以就报错断链了。
当创建文件t时,
文件名它就是一个硬链接,链接计数为1
假设,使用 ln 创建另一个硬链接时,
实际上是在目录中创建了一个新条目(文件名),但都指向同一个i-node,同时链接计数增加为2
当删除原文件名t时,
只是删除了一个指向该i-node的硬链接,链接计数减1。
由于还有另一个硬链接存在,
所以i-node和数据块不会被释放,
仍然可以通过存在的硬链接进行访问。
原始文件名和硬链接在本质上是相同的,
都是指向同一个inode的硬链接。
所谓的"原始文件"和"硬链接"没有区别,
它们都是同一个文件的多个名称(文件的快捷方式)
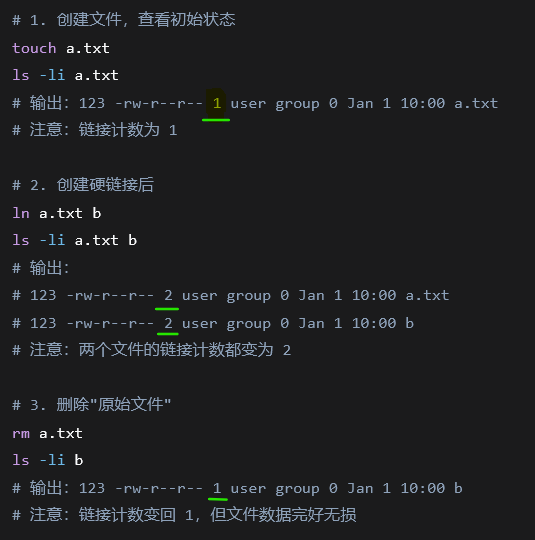
在 Linux/Unix 文件系统中,所谓的"原始文件"其实就是一个硬链接。更准确地说:
每个文件都至少有一个硬链接(即它的文件名)
创建文件时,系统在目录中创建一个条目(文件名),将文件名映射到 inode
这个映射关系就是硬链接
文件数据块的指针存储在 inode 中
目录条目(文件名)是文件的硬链接
所有硬链接都是平等的,没有主次之分
当链接计数降为 0 时,文件数据才真正被删除为什么可以这样操作?
mv original_file new_name
实际上只是修改了一个目录条目(硬链接的名称)
为什么文件可以在不同目录中有不同名称?
因为每个目录条目(文件名)都是独立的硬链接(指向i-node)
为什么删除文件有时很快,有时很慢?
删除最后一个硬链接时需要真正释放数据块
而软链接则不同,它是一个独立的文件,有自己的i-node,其中存储的是目标文件的路径。当目标文件被删除时,软链接就会变成"断链"。
cpp
对于这个"文件的路径",
可以这么理解
假设我们有一个软链接c,它指向a.txt。
那么软链接c文件的内容就是字符串"a.txt"
(实际上是包含路径的字符串,可能是绝对路径或相对路径)。
当我们通过软链接c访问时,
系统会读取c的内容,
然后去查找名为a.txt的文件。
如果a.txt被删除了,那么查找就会失败。硬链接:多个文件名指向同一个i-node,删除其中一个不会影响其他硬链接对文件的访问。
软链接:一个独立文件,内容为目标文件的路径,如果目标文件被删除,软链接将失效。
cpp
对于这个"文件的路径",可以这么理解
假设我们有一个软链接c,它指向a.txt。
那么软链接c文件的内容就是字符串"a.txt"
(实际上是包含路径的字符串,可能是绝对路径或相对路径)。
当我们通过软链接c访问时,
系统会读取c的内容,
然后去查找名为a.txt的文件。
如果a.txt被删除了,那么查找就会失败。Unix 文件系统设计的核心理念------文件名与文件数据的分离
所谓的"原始文件" 确实只是一个硬链接,与其他硬链接在本质上没有任何区别
硬链接b和a.txt则是指向同一个i-node,
所以它们本质上是同一个文件的两个名字。
删除a.txt只是删除了一个名字,
但是文件数据还在,
因为还有一个名字b指向它(i-node)。
cpp
软链接--->i-node(软自己的节点)--->硬链接--->i-node(原文件的节点)--->数据块
软链接是一个快捷方式,它指向
原文件的硬链接
硬链接是一个快捷方式,它指向原文件名对应的
i-node
i-node可以看成一个快捷方式,它指向
数据块
软链接是一个指向文件路径的快捷方式,如果原始文件被删除,软链接就会失效。
c
软链接的实际内容
# 创建软链接并查看其内容
echo "Hello World" > a.txt
ln -s a.txt c
# 查看软链接文件的实际内容
ls -l c
# 输出:lrwxrwxrwx 1 user group 5 Jan 1 10:00 c -> a.txt
# 实际上,软链接文件c中存储的就是字符串 "a.txt"那么可不可以把软链中存储的原始文件路径字符串理解成是一个硬链接

软链中存储的原始文件路径字符串,它只是一个字符串,只是告诉系统去哪里找谁,而不具备硬链接那种自带的更新机制、有效性和解析时机
查看软链接的原始内容(需要特殊工具)
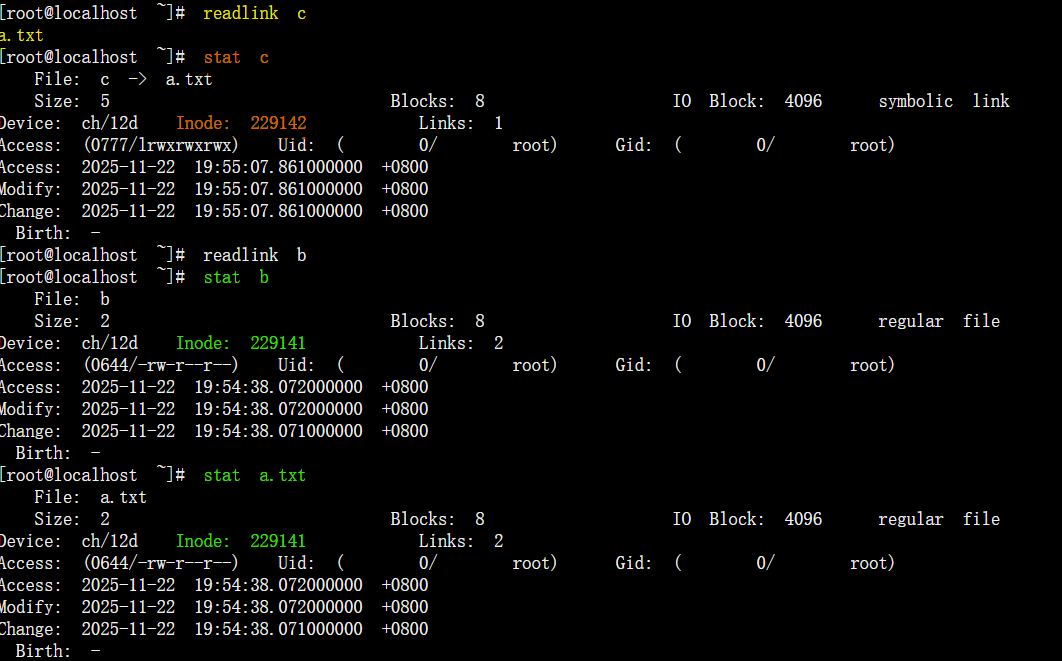
ls -l c # 显示指向关系
readlink c # 直接输出软链接内容
stat c # 显示软链接的inode信息
hexdump -C c # 以十六进制查看实际存储的内容
把软链接理解为:
一个特殊的文本文件
内容是一个文件路径字符串
操作系统在访问时会自动解析这个字符串
类似于编程中的"指针"或"引用"软链接中存储的"目标文件的路径"只是一个字符串,文件系统需要额外的工作来解析这个字符串并找到实际文件,这与硬链接的直接inode映射有本质区别

ln

November2025the22thSaturday
2> 表示 :标准错误重定向
在Linux中,有三个标准数据流:
0 - 标准输入 (stdin)
1 - 标准输出 (stdout)
2 - 标准错误 (stderr)
2> 合起来表示将标准错误流重定向到其他地方。
/dev/null 表示: 空设备
这是一个特殊的设备文件,所有写入它的数据都会被丢弃,就像进入黑洞一样。
所以,
2>/dev/null
表示:
将标准错误输出重定向到 /dev/null,黑洞设备,即不显示任何错误信息。
df = Disk Free(磁盘空闲空间)
显示文件系统的磁盘空间使用情况,包括已用空间、可用空间、挂载点等信息
du = Disk Usage(磁盘使用)
df - 查看文件系统级别的磁盘使用情况
du - 查看文件和目录级别的磁盘使用情况
人类可读格式(自动转换单位) df -h
显示inode使用情况 df -i
显示完整信息(包括文件系统类型) df -T
df 命令最早出现在 Unix 系统中,后来被所有类Unix系统(包括Linux)继承。它的设计初衷是让系统管理员能够快速了解磁盘空间的使用情况
echo 具体内容
>文件名echo 具体内容
>>文件名区别是:
>改写
>>追加
归档文件
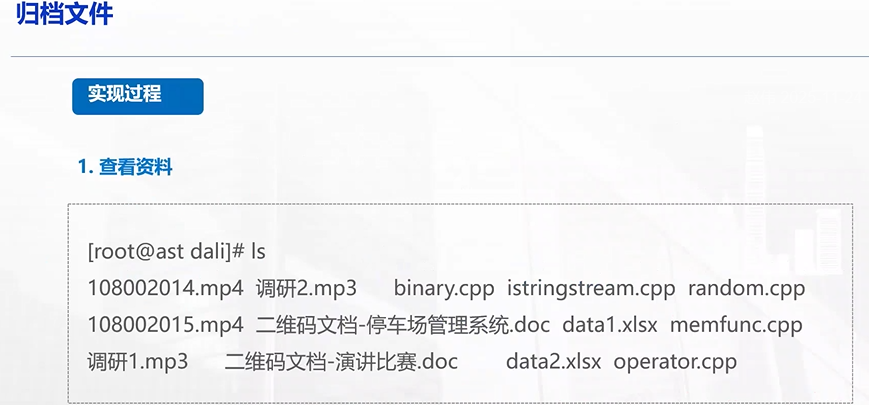
归档之前,
目录下的文档是杂乱无章的,
将文件转移到创建好的目录中
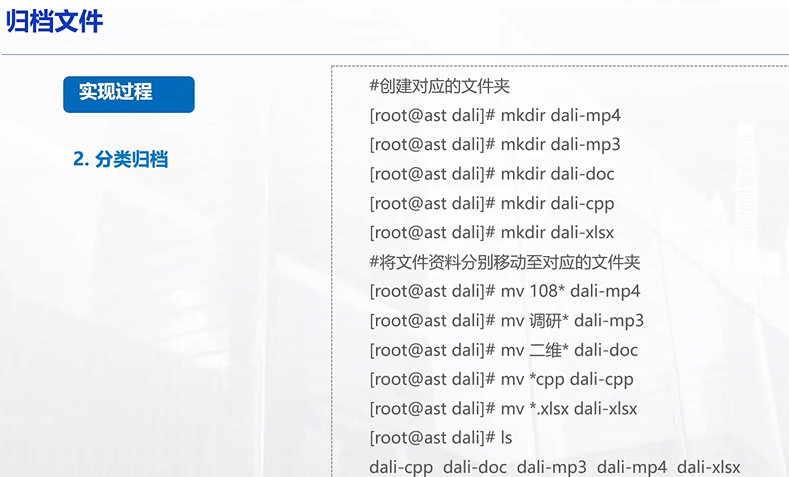
归档后,再次查看目录,文件变得有序了,一目了然
打包文件

November2025the24thMonday
November2025the25thTuesday