
在训练大语言模型(LLM)时,我们常常聚焦于模型架构、数据质量和训练规模,但一个"幕后英雄"同样至关重要------优化器。多年来,AdamW 一直是训练Transformer模型的黄金标准。但它真的完美无缺吗?
ArXiv URL:http://arxiv.org/abs/2511.14721v1
文本转载自公众号【AI研究】
来自哈佛和斯坦福大学的一项新研究指出,AdamW存在一个关键缺陷:过度衰减 (over-decay)。这会导致模型训练后期性能不佳。为了解决这个问题,研究者们提出了AdamHD,一个AdamW的即插即用替代品,效果惊人!
AdamW的"中年危机":过度衰减
要理解AdamHD的巧妙之处,我们得先聊聊AdamW的问题。
AdamW的核心之一是权重衰减 (Weight Decay ),它通过一个 L2L_2L2 惩罚项来正则化模型,防止过拟合。你可以把它想象成一种"引力",不断将所有模型参数拉向原点。
在训练初期,这很有效。但到了后期,当模型已经学到很多知识,一些关键参数(权重)变得很大时,这种"一视同仁"的引力就成了问题。它会过度压制那些已经很重要的参数,限制了模型的全部潜力,这就是"过度衰减"。
AdamHD的智慧:刚柔并济的Huber衰减
如何解决这个问题?AdamHD的答案是:用更智能的Huber正则化 替换掉简单粗暴的 L2L_2L2 惩罚。
Huber损失函数本身并不新鲜,它在机器学习中常用于回归任务。但把它用到优化器的权重衰减上,却是个绝妙的创举。
它的核心思想是"看人下菜碟":
- 当参数的绝对值小于某个阈值 δ\deltaδ 时,它采用二次方(L2L_2L2-like)衰减,温和地进行正则化。
- 当参数的绝对值超过阈值 δ\deltaδ 时,它切换为线性(L1L_1L1-like)衰减,施加一个恒定的、有上限的拉力。
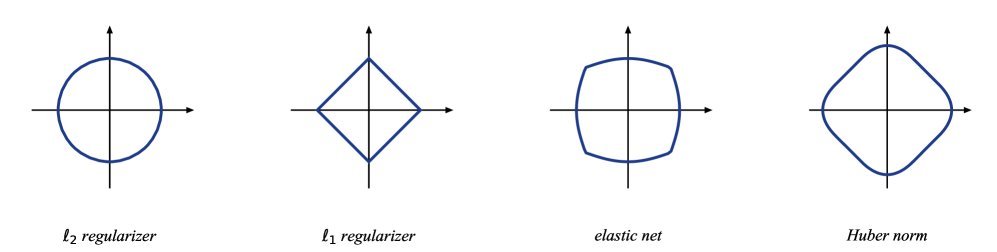
图1:Huber正则化(红色)结合了L2L_2L2(蓝色)在原点附近的平滑性和L1L_1L1(绿色)在远离原点处的线性增长特性。
这种设计一举多得:
- 有界梯度:避免了对大参数施加过大的惩罚。
- 尺度不变性:对参数的缩放不敏感,训练更稳定。
- 促进稀疏性 :对大参数施加类似 L1L_1L1 的惩罚,能将一些不那么重要的参数推向零,使模型更稀疏。
即插即用,几乎零成本
最棒的是,AdamHD被设计成解耦的Huber衰减 (Decoupled Huber Decay)。
这意味着它和AdamW一样,将正则化步骤与梯度更新步骤分开。研究者们推导出了一个闭式解 (closed-form solution ),使得这个新步骤的计算复杂度仅为 O(1)O(1)O(1)。
简单来说,你可以像替换一个灯泡一样,将现有训练代码中的AdamW优化器换成AdamHD,而几乎不会增加任何计算开销!
它的更新规则可以直观地表示为:
θt+1=θt−αt mtvt+ε−αt λ clip(θt,−δt,+δt) \mathbf{\theta}{t+1} =\mathbf{\theta}{t}-\alpha_{t}\,\frac{\mathbf{m}{t}}{\sqrt{\mathbf{v}{t}}+\varepsilon}-\alpha_{t}\,\lambda\;\mathrm{clip}\bigl(\mathbf{\theta}{t},-\mathbf{\delta}{t},+\mathbf{\delta}_{t}\bigr) θt+1=θt−αtvt +εmt−αtλclip(θt,−δt,+δt)
这里的 clip\mathrm{clip}clip 操作就体现了Huber衰减的核心:对参数的衰减力度设置了一个上限 δ\deltaδ。
实验效果:全面超越
理论说得再好,也要看实际效果。研究团队在GPT-2和GPT-3等不同规模的模型上进行了从零开始的预训练实验,结果令人振奋。
更快的收敛速度
与AdamW相比,AdamHD在达到相同的验证集困惑度(Perplexity)目标时,训练速度(墙上时钟时间)快了10-15%。这意味着更少的计算资源和时间成本。
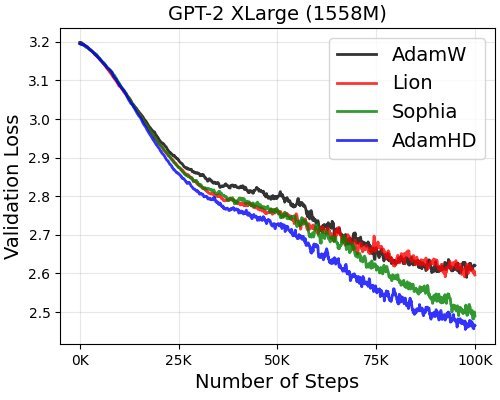
图2:在GPT-2 1.5B模型上,AdamHD(蓝色)的验证损失下降速度明显快于AdamW(橙色)。
更低的困惑度
在相同的训练步数下,AdamHD训练的模型验证集困惑度最多降低了4个点。困惑度越低,代表模型对文本的预测能力越强。
更强的下游任务性能
预训练完成后,模型在各种下游任务上的表现才是最终的试金石。实验结果显示,使用AdamHD训练的模型在常识推理、数学问题、知识问答等多个基准测试中,性能普遍提升了2.5%至4.7%。
更稀疏的模型,更少的显存
AdamHD促进了模型的稀疏性。这意味着模型中许多参数值接近于零。通过简单的幅度剪枝 (magnitude pruning ),可以在不显著影响性能的情况下,节省20-30%的存储空间。这对于模型部署和推理优化是巨大的利好。
结论
AdamHD通过一个简单而优雅的改进------将AdamW中的 L2L_2L2 权重衰减替换为解耦的Huber衰减,成功解决了大模型训练后期的"过度衰减"问题。
它不仅训练更快、模型性能更强,还能带来显著的显存节省,而且几乎没有额外的计算成本。
这项研究为我们提供了一个原则性强、实现简单且效果显著的优化器新选择。对于正在努力训练下一代基础模型的团队来说,AdamHD无疑是一个值得立即尝试的强大工具。