1、Elasticsearch整体架构
Elasticsearch是一个分布式、多节点、对等架构(peer-to-peer)的搜索引擎,其架构设计目标是:高可用、可扩展、近实时搜索。
1、节点和节点角色
节点(Node):
每个运行的Elasticsearch实例称为一个节点。
节点的角色:
- 数据节点 (Data Node):存储分片数据,执行CRUD操作。
- 主节点 (Master Node):管理集群元数据(如节点加入/退出、索引创建)。
- 协调节点 (Client Node):接收请求并转发到目标节点,不存储数据,可对数据节点数据进行聚合。
注意:
- 默认情况下,一个节点可以同时承担多个角色。
- 生产环境建议分离角色 :专用master + 专用data + 专用coordinating。
2、集群(Cluster)结构
集群(Cluster):
由多个节点组成,通过集群名称(Cluster Name)标识。集群内部通过Zen Discovery机制实现节点自动发现和主节点选举。
如:
java
Cluster: my-es-cluster
│
├── Node A (master, coordinating)
├── Node B (data, ingest)
├── Node C (data, ingest)
└── Node D (data, coordinating)其他:
- 所有节点通过gossip协议自动发现彼此
- 使用Zen Discovery (ES 7.x)或Coordinator-based discovery(ES 8+)管理集群状态
- Master节点不直接参与数据操作,避免负载过高
2、数据存储与分片机制(Sharding)
1、为什么需要分片?
- 单机无法存储PB级数据
- 搜索请求由多个节点共同处理
- 高可用:副本机制防止单点故障
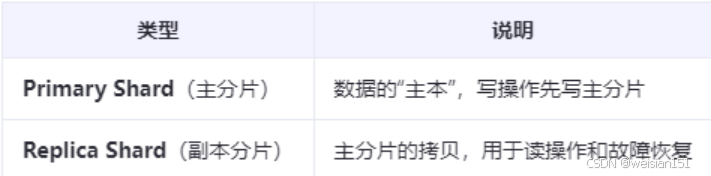
2、分片(Shard)类型
分片(Shard):
-
主分片(Primary Shard):数据写入的起点,数量在索引创建时固定。
-
副本分片(Replica Shard):主分片的拷贝,提升容错性和查询性能。
-
分片策略 : 数据通过文档ID的哈希值均匀分布到主分片中,副本分片分布在不同节点上。
说明:一个索引创建后,主分片数不可更改(除非reindex),副本数可动态调整。
3、分片分配示例
创建索引:
java
PUT /my_index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}解释:
创建一个my_index索引(类似mysql的数据表),主分片有3个,副本1个。
创建如上的索引后,分片分布示例如:
java
Index: my_index
│
├── Shard 0 (P) → Node B
│ └── Replica → Node C
├── Shard 1 (P) → Node C
│ └── Replica → Node D
└── Shard 2 (P) → Node D
└── Replica → Node B读写处理关系:
- 写请求 → 主分片 → 同步到副本
- 读请求 → 轮询主分片或副本(负载均衡)
3、数据写入流程(Indexing)
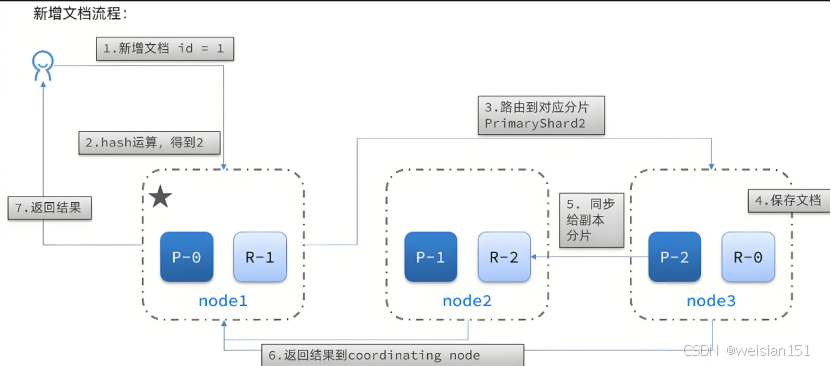
当你执行PUT /my_index/_doc/1写入文档时,ES内部发生了什么?
步骤详解:
(1)、客户端发送请求 → 协调节点 (Coordinating Node)
(2)、路由计算 :
示例:
java
shard = hash(routing) % number_of_primary_shards解释:
默认routing = _id,确保同一文档始终路由到同一分片。
(3)、协调节点将请求和数据转发到主分片节点
(4)、主分片执行写操作:
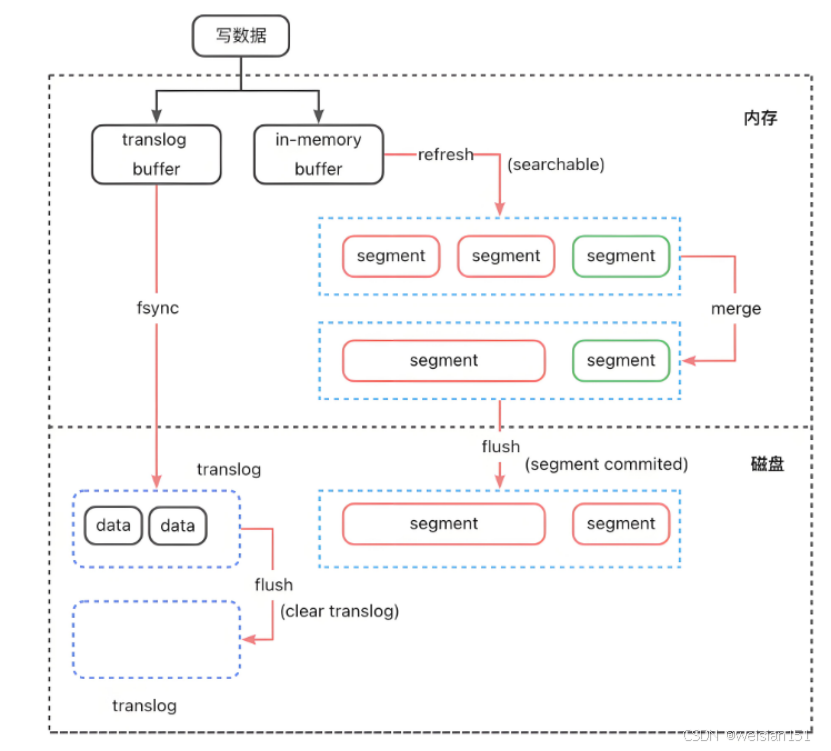
- 写入内存buffer
- 追加到translog(事务日志)
(5)、同步到副本 分片(如果replication=sync)
(6)、副本返回成功 响应
(7)、定期刷新(Refresh): - 默认每1秒,buffer → in-memory segment (segment中的数据可被搜索)
- 实现近实时搜索(NRT)
(8)、定期刷盘(Flush): - 将segment写入磁盘,清空translog
- 确保持久化
(9)、定期合并 - 定期将小segment进行合并,提升查询性能
说明:
- 定期刷新Refresh:将数据由**内存缓冲区buffer → 内存段segment中。segment是倒排索引的结构,可以被ES所查询,而buffer中的数据还是原始待处理的json格式,无法被ES查询。**所以没有这一步的话,读请求无法查到对应的数据。
- 定期刷盘Flush:让数据持久化(内存段 → 磁盘),防止数据丢失。
- 段合并(Segment Merge):每秒1次的任务将数据写入in-memory segment段,时间长了也会造成大量Segment段存在。**ES会定期合并小Segment为大Segment,减少文件数量,提升搜索性能。**可通过index.merge.policy配置合并策略(如按大小或文档数)。
简单理解:
- 写请求进入主分片 后,主分片会将此时的数据(JSON)保存到buffer内存中,同时追加到**translog日志(磁盘)**中(注意:追加translog日志是直接写入到磁盘中持久化保存的,防止意外宕机造成数据丢失)。
- 之后将请求转发到自己的副本分片中。
- 主分片和副本分片都会在1s的定时任务中,对buffer中的数据进行处理,将JSON结构转化为倒排索引的方式,并保存到各自的 in-memory segment中。此时数据存在倒排结构可被后续查询发现。
- 每30秒左右或translog满时,触发Flush,将in-memory segment数据持久化到磁盘中。
注意:
ES也是日志先行的机制,translog日志确保节点即使宕机了,之后重启也可以恢复数据。所以在第一步将数据保存buffer缓冲区时,就会完成translog日志的持久化。
内存原理图:
数据写入流程原理图:
4、搜索流程(Search)
当执行GET /my_index/_search时,ES又是如何处理的呢?
Elasticsearch的搜索流程分为查询(Query)和取回(Fetch)两个阶段:
(1)、查询阶段:
- 客户端发送搜索请求到协调节点。
- 协调节点将查询广播到所有相关分片(主分片或副本分片)。
- 各分片在本地执行查询,返回匹配文档的ID和相关性评分(如TF-IDF、BM25)。
(2)、取回阶段: - 协调节点根据文档ID向对应分片请求完整文档。
- 分片返回文档后,协调节点进行排序、分页等处理,最终返回结果给客户端。
逻辑原理如:
java
Client → Coordinating Node(协调节点)
↓
广播查询到所有相关分片(主或副本)(Fetch请求)
↓
每个分片本地搜索,返回"匹配文档ID + 排名"
↓
Coordinating Node(协调节点)合并结果,排序,确定最终Top N → Client注意:
- 使用query_then_fetch策略,平衡性能与准确性
- 支持分页(from + size),但深分页性能差(推荐search_after)
5、倒排索引(Inverted Index)------ 搜索的核心
1、什么是倒排索引?
倒排索引是Elasticsearch实现全文搜索的核心数据结构,将文档中的关键词映射到包含该词的文档列表。
构建过程:
(1)、分词 处理
使用分析器(Analyzer)将文本拆分为词条(Term )。例如,文档"The quick brown fox jumps over the lazy dog"会被拆分为"the", "quick", "brown", "fox", ...。
(2)、词汇表 (Dictionary)
所有唯一词条的集合,每个词条对应一个倒排列表(Posting List)。
(3)、倒排表 (Posting List)
记录包含该词条的文档ID、词频(TF)、位置等信息。
示例:
java
quick → [文档1(位置2)]
brown → [文档1(位置3), 文档3(位置2)]
dog → [文档2(位置5), 文档3(位置4)]常用中文分词器:IK Analyzer(ik_smart, ik_max_word)
2、Lucene存储结构
ES底层使用Lucene存储数据,每个分片核心是一个Lucene索引。
一个Lucene包含:
- Segments:不可变的倒排索引单元
- .fdt / .fdx:存储文档值(stored fields)
- .doc / .pos / .pay:倒排表、位置、偏移
- .dvd / .dvm:Doc Values(用于排序、聚合)
- _state:索引元数据
说明:
- Segments是只读的,删除通过.del文件标记
- 定期合并segments(Merge)以提升查询性能
6、近实时(NRT)搜索原理
ES为什么能做到1秒内搜索到新数据?
原理:
(1)、内存buffer:写入先到内存
(2)、Refresh(默认1s一次):
- 将buffer中的数据生成新的in-memory segment
- 清空buffer
- 新segment可被搜索(但未持久化)
(3)、Translog保证持久化:即使崩溃,也可从translog恢复
其他:
- 可通过POST /my_index/_refresh手动刷新
- 可通过?refresh=wait_for等待刷新完成
7、高可用与故障恢复
1、副本机制
- 每个主分片有N个副本
- 读请求可走副本,提升吞吐
- 主分片宕机 → 副本提升为主
2、故障恢复流程
1、主分片节点宕机
2、Master 检测到节点失联
3、将该节点上的主分片标记为"未分配"
4、提升副本分片为新主分片
5、重新分配副本(可能从其他节点复制数据)
3、分布式协调与容错原理
- 主节点选举:
- 主节点负责管理集群状态(如节点加入、分片分配)。
- 若主节点宕机,其他节点通过投票重新选举新主节点。
- 分片故障转移:
- 若某节点宕机,其主分片的副本分片会晋升为主分片,并在其他节点上重新创建副本。
- 脑裂问题(Split Brain):
- 通过配置 discovery.zen.minimum_master_nodes(最小主节点数量)避免集群分裂。
8、扩展性与负载均衡
- 水平扩展:增加数据节点,自动重新平衡分片
- 读写分离**:写 → 主分片,读 → 主/副本**
- 冷热架构:
- 热节点:SSD,处理新数据写入
- 冷节点:HDD,存储历史数据
- Index Lifecycle Management(ILM):
- 自动滚动索引(rollover)
- 自动降级到冷节点
- 自动删除旧数据
9、核心工作流程图解

10、总结
总结说明:
-
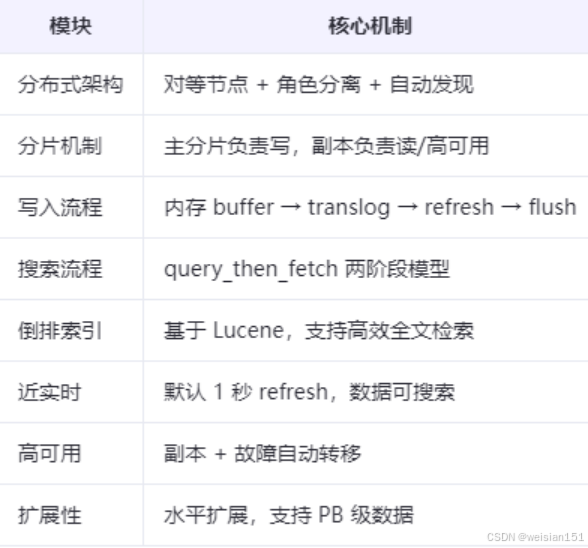
分布式 架构:Elasticsearch集群由多个节点组成,节点间默认对等 (P2P),通过角色划分(如主节点、数据节点、协调节点等 )实现职责分离 。新节点可自动发现并加入集群,无需手动配置,便于运维和扩展。
-
分片机制 :索引被拆分为多个主分片(Primary Shard),实现数据水平切分 ;每个主分片可配置多个副本分片(Replica Shard),用于提升读性能和容错能力 。分片机制是Elasticsearch实现分布式存储和并行处理的基础。
-
写入流程:
(1)、数据先写入内存buffer和磁盘上的translog (事务日志,用于故障恢复);
(2)、每秒执行一次refresh,将内存中的文档生成可搜索的倒排索引(实现近实时) ;
(3)、每30秒左右或translog达到阈值时执行flush,将内存中的segment写入磁盘,并清空translog。
-
段合并 (Segment Merge):合并小Segment为大Segment,减少文件数量,提升搜索性能。可通过index.merge.policy配置合并策略(如按大小或文档数)。
-
搜索流程(query_then_fetch):
- Query阶段:协调节点向所有相关分片发起查询,各分片返回匹配文档的ID和得分;
- Fetch阶段:协调节点汇总结果,排序后向对应分片请求完整文档,最终合并返回给客户端。
-
倒排索引 :基于底层Lucene实现 ,将"文档 → 词项"的映射反转为"词项 → 文档列表" ,极大提升全文检索效率,支持关键词查找、模糊匹配、高亮等功能。
-
近实时(NRT , Near Real-Time):由于默认每1秒refresh一次,新写入的数据在1秒内即可被搜索到,实现"近实时"而非"实时"搜索。
-
高可用 :通过副本机制,每个主分片都有一个或多个副本。当主分片所在节点宕机时,集群会自动从副本中选举新的主分片,继续提供服务,保障数据不丢失和查询可用。
-
扩展性 :支持水平扩展(横向扩容),通过增加数据节点可线性提升存储容量和查询性能,广泛应用于日志、监控、搜索等场景,可支撑PB级数据规模。
向阳前行,Dare To Be!!!