
文章目录
- 1、MXNet
- 2、MXIndexedRecordIO
- [3、MXNet RecordIO vs. Torchvision Image Folder](#3、MXNet RecordIO vs. Torchvision Image Folder)
Apache MXNet(简称 MXNet)是一个 开源的深度学习框架 ,由 Apache 软件基金会维护,支持高效的模型训练与部署。它以 灵活性 、高性能 和 多语言支持 为核心特点,广泛应用于学术研究和工业界。
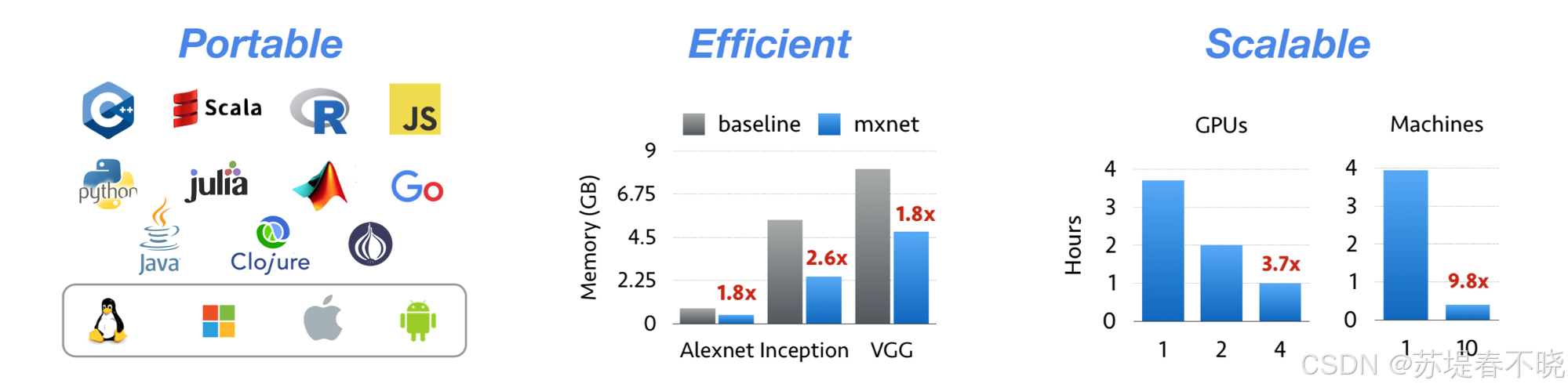
MXNet 库可移植并且规模小巧。它采用 NVIDIA Pascal™ GPU 加速,可以跨多个 GPU 和多个节点进行扩展,从而更快地训练模型。
https://www.nvidia.cn/glossary/mxnet/
1、MXNet
1.1、核心特性
(1) 多语言支持
- 提供 Python、R、Scala、Julia、C++、Java、Perl、Go 等语言的 API,方便不同背景的开发者使用。
- 与 PyTorch 和 TensorFlow 类似,但更强调轻量级和跨平台兼容性。
(2) 动态与静态图混合
- 动态计算图(Dynamic Graph):支持类似 PyTorch 的即时执行模式,便于调试和快速迭代。
- 静态计算图(Static Graph):支持类似 TensorFlow 的符号式编程,优化性能并支持部署到移动端或嵌入式设备。
(3) 分布式训练
- 内置 参数服务器(Parameter Server) 和 分布式优化器,支持多机多卡训练(如 GPU 集群)。
- 通过 KVStore(键值存储) 实现高效的梯度同步和模型更新。
(4) 高效内存管理
- 自动优化内存使用,减少训练大规模模型时的显存占用(如支持 内存复用 和 梯度压缩)。
(5) 预训练模型库
- 提供 GluonCV、GluonNLP、GluonTS 等工具库,包含大量预训练模型(如 ResNet、BERT、Transformer),覆盖计算机视觉、自然语言处理等领域。
1.2、架构设计
MXNet 的架构分为 前端(Frontend) 和 后端(Backend):
- 前端 :用户接口层,支持多种语言(如 Python 的
mxnet模块)。 - 后端 :
- 计算图引擎:负责构建和优化计算图(动态/静态)。
- 执行引擎:调度操作到不同设备(CPU/GPU)并管理并行计算。
- 存储引擎:高效管理张量(Tensor)的内存分配和释放。
关键组件:
- NDArray:类似 NumPy 的多维数组,支持 GPU 加速。
- Symbol:符号式编程接口,用于定义静态计算图。
- Gluon:高级神经网络 API,提供类似 Keras 的简洁接口(支持动态图)。
1.3、适用场景
- 学术研究:灵活的动态图模式适合快速实验和算法验证。
- 工业部署:静态图模式可生成高效计算图,支持移动端(如 Android/iOS)和边缘设备部署。
- 大规模训练:分布式训练能力适用于处理海量数据(如推荐系统、大规模图像分类)。
1.4、与主流框架对比
| 特性 | MXNet | PyTorch | TensorFlow |
|---|---|---|---|
| 编程模式 | 动态+静态图混合 | 动态图(默认) | 静态图(默认,支持动态图) |
| 性能 | 高(优化内存和并行计算) | 高(动态图调试方便) | 高(静态图优化强) |
| 部署支持 | 优秀(支持移动端/嵌入式) | 良好(通过 TorchScript) | 优秀(TF Lite/TF.js) |
| 生态 | 中等(Gluon 库增长中) | 强大(Hugging Face 等) | 强大(TF Hub/TF Addons) |
| 社区活跃度 | 中等(Apache 维护) | 极高(Facebook 主导) | 高(Google 主导) |
1.5、安装与快速入门
(1) 安装
bash
# 使用 pip 安装(CPU 版本)
pip install mxnet
# GPU 版本(需指定 CUDA 版本,如 11.8)
pip install mxnet-cu118(2) 示例代码
python
import mxnet as mx
from mxnet import nd, autograd, gluon
# 创建 NDArray
x = nd.array([1, 2, 3])
y = nd.array([4, 5, 6])
print(x + y) # 输出: [5. 7. 9.]
# 使用 Gluon 定义简单模型
net = gluon.nn.Sequential()
net.add(gluon.nn.Dense(10, activation='relu'))
net.add(gluon.nn.Dense(1))
net.initialize()
# 训练循环(简化版)
trainer = gluon.Trainer(net.collect_params(), 'sgd')
for epoch in range(10):
with autograd.record():
output = net(x.reshape(-1, 1))
loss = nd.mean((output - y.reshape(-1, 1)) ** 2)
loss.backward()
trainer.step(1)1.6、典型应用案例
- 计算机视觉 :使用
GluonCV实现目标检测(如 YOLO、SSD)、图像分类(ResNet)。 - 自然语言处理 :通过
GluonNLP训练 BERT、Transformer 模型。 - 推荐系统:利用 MXNet 的分布式训练能力处理用户行为数据。
1.7、资源与学习
- 官方文档 :https://mxnet.apache.org/
- 教程 :MXNet Tutorials
- GitHub :https://github.com/apache/mxnet
Apache MXNet 是一个 全能型深度学习框架 ,兼顾灵活性与性能,适合从研究到生产的全流程开发。若需平衡 动态图易用性 和 静态图部署效率,MXNet 是一个值得考虑的选择。
2、MXIndexedRecordIO
mxnet.recordio.MXIndexedRecordIO 是 Apache MXNet 中用于高效读写 RecordIO 数据格式的类,支持 随机访问(通过索引快速定位记录),适用于大规模数据集的分布式存储与加载(如 Hadoop HDFS、AWS S3)。
2.1、核心功能
- 随机访问 :通过索引文件(
.idx)直接定位记录,无需顺序扫描。 - 高效存储:紧凑打包数据,减少 I/O 开销。
- 兼容性:支持 Python 2 字符串和 Python 3 字节类型(需注意版本差异)。
2.2、类定义与参数
python
class MXIndexedRecordIO(MXRecordIO):
def __init__(self, idx_path, uri, flag, **kwargs):
"""
参数:
idx_path (str): 索引文件路径(如 `data.idx`)。
uri (str): 数据文件路径(如 `data.rec`)。
flag (str): 模式,`'w'`(写入)或 `'r'`(读取)。
"""2.3、主要方法
1. 写入数据
-
write(buf)将字符串缓冲区
buf作为一条记录写入数据文件(.rec),并更新索引文件(.idx)。
示例:pythonimport mxnet.recordio as recordio # 写入模式 writer = recordio.MXIndexedRecordIO('data.idx', 'data.rec', 'w') for i in range(5): record = f"Record {i}".encode('utf-8') # Python 3 需转为字节 writer.write(record) writer.close() -
write_idx(idx, buf)将记录
buf写入指定索引idx处(覆盖或插入)。
示例:pythonwriter.write_idx(10, b"Special record at index 10") # 写入索引 10
2. 读取数据
-
read()顺序读取下一条记录(返回字符串缓冲区)。
示例:pythonreader = recordio.MXIndexedRecordIO('data.idx', 'data.rec', 'r') while True: buf = reader.read() if not buf: break print(buf.decode('utf-8')) # Python 3 需解码 reader.close() -
read_idx(idx)通过索引
idx直接读取记录。
示例:pythonrecord = reader.read_idx(10) print(record.decode('utf-8')) # 输出: "Special record at index 10"
3. 其他操作
-
open()/close()
显式打开或关闭文件(构造函数已隐式调用open)。 -
reset()
将读取指针重置到文件开头。
示例 :pythonreader.reset() # 重新从头读取
2.4、使用场景示例
场景 1:构建图像数据集
-
生成记录文件 :
使用
mxnet.image.ImageIter或自定义脚本将图像和标签打包为RecordIO格式。pyimport mxnet as mx import os import numpy as np from mxnet.io import DataBatch, DataIter from mxnet import recordio # 1. 准备示例数据(假设我们有一些图像和标签) # 创建临时目录存放示例图像 os.makedirs('temp_images', exist_ok=True) # 创建3个示例图像(实际应用中替换为你的真实图像) for i in range(3): # 创建随机图像数据 (100x100 RGB) img = np.random.randint(0, 256, (100, 100, 3), dtype=np.uint8) # 保存为JPEG文件 mx.image.imwrite(f'temp_images/img_{i}.jpg', img) # 对应的标签(假设有3个类别) labels = [0, 1, 2] # 每个图像的标签 # 2. 创建图像列表文件(.lst格式) lst_filename = 'train.lst' with open(lst_filename, 'w') as f: for i, label in enumerate(labels): # 格式: index \t label \t image_path f.write(f"{i}\t{label}\ttemp_images/img_{i}.jpg\n") # 3. 使用 im2rec 工具创建 RecordIO 文件 record_filename = 'train.rec' mx.io.ImageRecordIter.recordio_writer( record_filename=record_filename, list_file=lst_filename, root_dir='.', # 图像路径的根目录 width=100, # 调整图像宽度 height=100, # 调整图像高度 ) # 4. 使用 ImageIter 读取 RecordIO 文件(验证) data_iter = mx.image.ImageIter( batch_size=2, data_shape=(3, 100, 100), # CHW格式 path_imgrec=record_filename, path_imglist=lst_filename ) # 打印一个批次的数据 batch = data_iter.next() print(f"数据形状: {batch.data[0].shape}") # 应该输出 (2, 3, 100, 100) print(f"标签形状: {batch.label[0].shape}") # 应该输出 (2,) print(f"第一批次的标签: {batch.label[0].asnumpy()}") # 5. 清理临时文件(可选) import shutil shutil.rmtree('temp_images') os.remove(lst_filename) os.remove(record_filename)如果你不想使用 .lst 文件,也可以直接使用 recordio 模块创建 RecordIO 文件:
pyimport mxnet as mx import numpy as np import os # 创建临时图像 os.makedirs('temp_images', exist_ok=True) images = [] for i in range(3): img = np.random.randint(0, 256, (100, 100, 3), dtype=np.uint8) mx.image.imwrite(f'temp_images/img_{i}.jpg', img) images.append(img) labels = [0, 1, 2] # 创建 RecordIO 文件 record_file = 'data.rec' writer = recordio.MXIndexedRecordIO(record_file, 'w') for idx, (img, label) in enumerate(zip(images, labels)): # 将图像编码为 JPEG 二进制 header = mx.recordio.IRHeader(flag=0, label=label, id=idx, id2=0) img_bytes = mx.image.imencode(img) s = mx.recordio.pack(header, img_bytes) writer.write_idx(idx, s) writer.close() # 读取 RecordIO 文件 reader = recordio.MXIndexedRecordIO(record_file, 'r') for idx in range(3): s = reader.read_idx(idx) header, img_bytes = mx.recordio.unpack(s) img = mx.image.imdecode(img_bytes) print(f"图像 {idx}: 标签={header.label}, 形状={img.shape}") # 清理 os.remove(record_file) shutil.rmtree('temp_images') -
创建索引文件:
python# 假设已生成 data.rec writer = recordio.MXIndexedRecordIO('data.idx', 'data.rec', 'w') # 写入记录(实际场景中可能通过迭代器批量写入) writer.close() -
随机访问训练样本:
pythonreader = recordio.MXIndexedRecordIO('data.idx', 'data.rec', 'r') # 读取索引 5 的样本 sample = reader.read_idx(5) # 解包数据(需根据实际打包格式解析)
场景 2:分布式训练
- 将
.rec和.idx文件上传至 HDFS/S3,通过MXIndexedRecordIO直接读取,避免全量下载。
2.5、注意事项
- 版本兼容性 :
- MXNet 0.9.5 及以下版本可能不支持
MXIndexedRecordIO,建议升级至最新稳定版。 - Python 3 需确保数据为字节类型(如
b"data"或str.encode())。
- MXNet 0.9.5 及以下版本可能不支持
- 索引文件同步 :
- 写入时需同时更新
.idx文件,否则可能导致索引与数据不一致。
- 写入时需同时更新
- 性能优化 :
- 批量写入(如
write_idx批量操作)比单条写入更高效。 - 大文件建议分片存储(如
data_000.rec+data_000.idx)。
- 批量写入(如
2.6、常见问题
-
错误:
AttributeError: module 'mxnet.recordio' has no attribute 'MXIndexedRecordIO'原因:MXNet 版本过低或安装不完整。
解决方案:升级 MXNet 或重新编译安装(如
pip install --upgrade mxnet)。 -
如何解包记录数据?
使用
mxnet.recordio.unpack或自定义解析逻辑(如图像数据需结合mxnet.img.imdecode)。
通过 MXIndexedRecordIO,用户可以高效管理大规模数据集,尤其适合深度学习训练中的随机数据加载需求。
3、MXNet RecordIO vs. Torchvision Image Folder
torchvision.datasets.ImageFolder
py
import torch
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义数据预处理(与MXNet的ImageIter类似)
transform = transforms.Compose([
transforms.Resize((256, 256)), # 调整大小
transforms.RandomCrop(224), # 随机裁剪(数据增强)
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(), # 转为Tensor并归一化到[0,1]
transforms.Normalize( # 标准化(需提供均值和标准差)
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
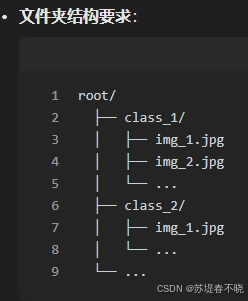
# 加载数据集(自动按子文件夹分类)
dataset = datasets.ImageFolder(
root="path/to/data_root", # 替换为你的根目录
transform=transform
)
# 创建DataLoader(支持多线程加载和批处理)
dataloader = DataLoader(
dataset,
batch_size=32,
shuffle=True,
num_workers=4, # 多线程加速
pin_memory=True # GPU加速
)
# 迭代数据
for images, labels in dataloader:
print(f"Batch shape: {images.shape}") # [batch_size, 3, 224, 224]
print(f"Labels: {labels}")
break # 仅演示一个批次| 对比维度 | MXNet RecordIO | Image Folder |
|---|---|---|
| 存储格式 | 二进制文件(.rec),包含图像和标签的序列化数据 |
文件夹结构,图像按类别分目录存放(或单独标签文件) |
| 读取速度 | ⚡ 极快(顺序读取,支持多线程预取) | ⏳ 较慢(需逐个读取文件,磁盘I/O开销大) |
| 存储效率 | 📦 高效(无文件系统开销,可压缩) | 🗂️ 较低(每个图像单独存储,文件系统元数据占用空间) |
| 随机访问 | ❌ 需通过索引(.idx)文件定位,随机访问较慢 |
✅ 直接通过文件路径访问,随机访问快 |
| 数据增强支持 | 🔧 内置支持 (可在ImageIter中配置随机裁剪、翻转等) |
⚙️ 需手动实现或依赖外部库(如torchvision.transforms) |
| 多标签支持 | ✅ 支持(通过IRHeader存储多个标签) |
❌ 需额外处理(如文件名编码或单独CSV文件) |
| 跨平台兼容性 | ⚠️ 依赖MXNet解析库 | ✅ 通用(所有框架均可直接读取) |
| 适用场景 | 🚀 大规模训练(如ImageNet)、分布式训练、移动端部署 | 🔍 小规模数据、快速原型开发、需要频繁随机访问的场景 |
| 工具链支持 | 🛠️ 需MXNet工具(im2rec.py)生成,生态较封闭 |
🌍 广泛支持(Python标准库、OpenCV、Pillow等) |
| 内存占用 | 💾 较低(可分块加载) | 📈 较高(需加载文件列表到内存) |
| 扩展性 | ⚠️ 仅限MXNet生态 | ✅ 高度灵活(可结合任何预处理库) |
补充说明
- RecordIO 的索引文件(
.idx) :记录图像在.rec文件中的偏移量,支持快速定位,但生成需额外步骤。 - Image Folder 的变体 :可通过
CSV或JSON文件存储标签,但会增加复杂性。 - 性能实测 :在ImageNet训练中,RecordIO可比Image Folder快 3-5倍(参考MXNet官方文档)。