写 Skill 会不会很重?怎么让模型自己写 Skill,我们只做「架构师」?
一、导读
前几篇文章我们聊了 Skills 的价值、架构设计和工程规范。但很多读者可能会问:写一个高质量的 Skill 是不是很重?每次都要手敲几百行的 SKILL.md 和脚本吗?
答案是:不需要。
写 Skill 应该从「手敲所有文案」转向「Context Engineering(上下文工程)」------你负责梳理逻辑和准备素材,让模型帮你生成 Skill。
这篇文章要回答的核心问题是: 如何让模型自己写 Skill?从需求到可用的 Skill,需要哪些步骤?如何建立一个可复用的「AI 生成 Skill」工作流?
二、开发范式转变:从手敲到 Context Engineering
2.1 传统方式:手敲所有文案
传统写 Skill 的方式是这样的:
- 打开编辑器,新建
SKILL.md - 手写 YAML Frontmatter(name、description、argument-hint 等)
- 手写操作流程(步骤拆解、约束、错误处理)
- 手写脚本代码(Python、Bash 等)
- 反复调试,直到可用
这种方式的问题很明显:
- 效率低:一个完整的 Skill 可能需要几百行,手敲耗时
- 容易出错:元数据格式、YAML 语法、Markdown 结构都可能出错
- 难维护:需求变更时,需要手动修改多处
- 难复用:每个 Skill 都要从头写,无法复用模式
2.2 新范式:Context Engineering
Context Engineering(上下文工程) 的核心思想是:
你负责「架构设计」和「素材准备」,模型负责「内容生成」和「格式规范」。
具体来说:
-
你负责:
- 明确逻辑:输入/输出/边界条件梳理
- 准备素材:现有 SOP、规范、案例、历史对话
- 定义约束:安全要求、格式规范、业务规则
-
模型负责:
- 生成
SKILL.md初稿(包含元数据和指令) - 生成脚本骨架(Python、Bash 等)
- 生成 references 目录建议
- 保证格式规范(YAML、Markdown 语法正确)
- 生成
这样,你从「写代码的人」变成了「架构师」,模型从「执行者」变成了「代码生成器」。
三、一个可复用的「AI 生成 Skill」工作流
下面是一个经过实战验证的「AI 生成 Skill」工作流,你可以直接在国内外主流大模型中使用。这个工作流基于通用的 Prompt 工程原理,只要模型具备基本的文本生成和指令遵循能力即可。
3.1 工作流概览
整个工作流分为三个阶段:
- 明确逻辑:梳理输入/输出/边界条件
- 准备素材:收集现有 SOP、规范、案例
- 自动生成:用 Prompt 让模型生成 Skill
3.2 阶段一:明确逻辑
在生成 Skill 之前,你需要先明确这个 Skill 的「逻辑边界」:
核心问题清单
- 输入是什么? 用户需要提供什么参数?格式是什么?
- 输出是什么? Skill 应该产生什么结果?格式是什么?
- 边界条件是什么? 什么情况下 Skill 应该拒绝执行?什么情况下应该报错?
- 依赖什么? 需要哪些工具?需要哪些其他 Skill?
- 安全约束是什么? 哪些操作不能做?哪些数据不能访问?
示例:配图 Skill 的逻辑梳理
假设我们要做一个「长文配图 Skill」,逻辑梳理如下:
diff
输入:
- Markdown 文档路径(必填)
- 配图风格偏好(可选:tech/warm/data/auto)
输出:
- 修改后的 Markdown 文档(已插入配图)
- 配图文件列表(路径、描述、风格)
边界条件:
- 如果文档不存在 → 报错
- 如果文档格式不是 Markdown → 拒绝
- 如果文档长度 < 500 字 → 建议不配图
- 如果配图生成失败 → 记录错误,继续处理其他位置
依赖:
- 文件读写工具(file.read, file.write)
- 图片生成工具(image.generate)
- Markdown 解析工具(可选)
安全约束:
- 不能访问文档路径之外的文件
- 不能生成包含敏感内容的图片
- 不能修改文档的元数据部分3.3 阶段二:准备素材
有了逻辑边界,接下来需要准备「素材」------这些素材会被喂给模型,让它理解你的业务场景和规范。
素材类型
-
现有 SOP / 规范文档
- 如果你已经有相关的操作手册、规范文档,直接提供给模型
- 例如:公司报告格式规范、配图风格指南、安全审查清单
-
历史对话 / 案例
- 如果你之前用 Prompt 做过类似任务,把成功的对话记录提供给模型
- 例如:之前让模型配图的 Prompt、实际生成的配图示例
-
参考 Skill
- 如果有类似的 Skill(官方或自建),可以作为参考
- 例如:官方
article-illustratorSkill 的结构
-
业务约束 / 模板
- 输出格式模板、命名规范、错误处理规范等
- 例如:Markdown 图片插入格式、文件命名规则
素材准备示例
diff
素材1:公司配图风格指南(markdown)
- Tech 风格:简洁、现代、蓝色调为主
- Warm 风格:温馨、柔和、暖色调为主
- Data 风格:数据可视化、图表为主
素材2:历史 Prompt 示例
- "请为这篇文章生成配图,风格要求:Tech 风格,图片描述要简洁明了"
素材3:参考 Skill(官方 article-illustrator)
- 目录结构参考
- 元数据字段参考
- 操作流程参考
素材4:输出格式模板
- 图片插入格式:
- 文件命名:{article-name}-{index}.png3.4 阶段三:自动生成
有了逻辑和素材,接下来用 Prompt 让模型生成 Skill。
核心 Prompt 模板
下面是一个可以直接使用的「Skill 生成 Prompt」模板:
markdown
# 任务:生成一个 Agent Skill
## 背景信息
我需要创建一个 Skill,功能是:{功能描述}
## 逻辑边界
**输入:**
{输入参数说明}
**输出:**
{输出结果说明}
**边界条件:**
{边界条件说明}
**依赖:**
{依赖工具/Skill 列表}
**安全约束:**
{安全约束说明}
## 参考素材
{在这里粘贴你的 SOP、规范、案例、参考 Skill 等素材}
## 生成要求
请按照以下结构生成一个完整的 Skill:
1. **YAML Frontmatter**(元数据)
- name: {skill-name}
- description: {简短描述}
- argument-hint: {参数提示}
- user-invocable: true/false
- allowed-tools: {工具列表}
- version: 1.0.0
2. **操作流程**(Instructions)
- 步骤拆解清晰,每一步都要具体可操作
- 包含风格选择、约束说明、错误处理
3. **脚本建议**(Scripts)
- 如果需要脚本,提供 Python 或 Bash 脚本骨架
- 说明脚本的输入/输出和调用方式
4. **References 建议**(References)
- 如果有需要拆分的参考文档,建议目录结构
## 格式要求
- YAML Frontmatter 必须符合规范
- Markdown 格式正确
- 代码块使用正确的语言标识
- 所有路径使用相对路径
请开始生成:实际使用示例
使用时,将模板中的占位符替换为你的具体内容即可。例如生成「长文配图 Skill」时,填写片段如下(「参考素材」「生成要求」「格式要求」与模板一致,此处略):
markdown
## 背景信息
我需要创建一个 Skill,功能是:自动为长文生成配图并插入到合适位置
## 逻辑边界
**输入:** Markdown 文档路径(必填);配图风格偏好(可选:tech/warm/data/auto)
**输出:** 修改后的 Markdown 文档(已插入配图);配图文件列表
**边界条件:** 文档不存在→报错;非 Markdown→拒绝;<500 字→建议不配图;生成失败→记录错误并继续
**依赖:** file.read, file.write, image.generate
**安全约束:** 不访问文档外文件;不生成敏感图;不修改元数据
(此处粘贴你的风格指南、参考 Skill 结构等素材)生成结果示例
模型会生成类似这样的 Skill(以下仅展示元数据与操作流程前两步,完整结构可参考第三篇):
markdown
---
name: article-illustrator-cn
description: 自动为长文生成配图并插入到合适位置
argument-hint: 请提供需要配图的 Markdown 文档路径,可选参数:配图风格(tech/warm/data/auto)
user-invocable: true
allowed-tools: [file.read, file.write, image.generate]
version: 1.0.0
---
# 长文配图 Skill
## 操作流程
### 1. 文档验证与预处理
- 使用 `file.read` 读取文档;验证存在性与格式;字数 < 500 时建议不配图
### 2. 结构化分析
- 通读全文,识别适合配图的位置(抽象概念、复杂流程、重点结论),为每位置生成简短描述
### 3. 风格自适应 / 4. 生成配图 / 5. 插入文档 / 6. 结果汇总
(步骤略:风格选择逻辑 → 调用 image.generate → 插入 Markdown 图片语法 → 汇总列表)
## 约束与注意事项
- 配图为帮助理解,非单纯装饰;保持风格一致;不访问文档外文件、不生成敏感图、不修改元数据
## 错误处理
- 文档不存在→报错终止;生成失败→记录错误并尝试备用风格或跳过该位置
## 脚本与 References 建议
- 可提供 `scripts/generate_image.py` 骨架;references 下可放 style_guide.md、examples.md四、A/B 模型双人协作:让模型自己测试和优化
生成 Skill 只是第一步,更重要的是让模型自己测试和优化。这里介绍一个「A/B 模型双人协作」的方法。
4.1 双人协作流程
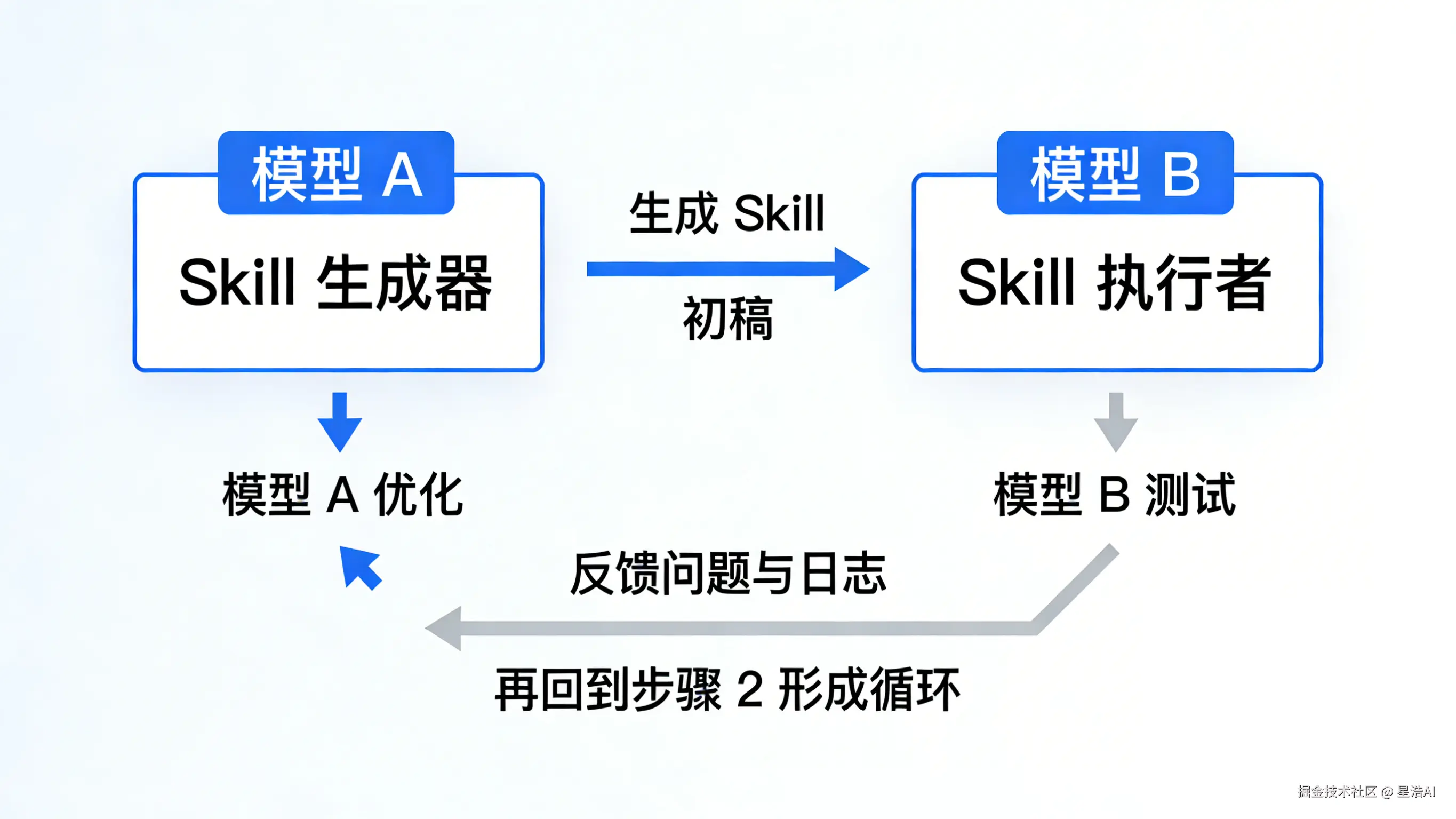
模型 A:Skill 生成器
- 负责根据逻辑和素材生成 Skill
- 负责根据反馈优化 Skill
模型 B:Skill 执行者
- 负责使用生成的 Skill 执行实际任务
- 负责记录执行过程中的问题和失败日志
协作流程:
- 生成阶段:模型 A 生成 Skill 初稿
- 测试阶段:模型 B 使用 Skill 执行测试任务
- 反馈阶段:模型 B 记录失败日志和问题
- 优化阶段:模型 A 根据反馈优化 Skill
- 迭代:重复步骤 2-4,直到 Skill 可用
4.2 实际应用示例
步骤1:模型 A 生成 Skill
(使用前面的 Prompt 生成 Skill,得到 SKILL.md 初稿)
步骤2:模型 B 测试 Skill
给模型 B 下发测试任务,例如:「请使用 article-illustrator-cn Skill 为文档 ./test-article.md 生成配图,并记录每一步操作、遇到的问题与最终结果是否符合预期。」
步骤3:模型 B 反馈问题
模型 B 执行后反馈典型问题,例如:image.generate 工具不存在、错误处理不足、参数格式未说明等。
步骤4:模型 A 优化 Skill
将模型 B 的反馈粘贴给模型 A,要求其根据反馈优化 Skill(修复工具调用、补充错误处理、明确参数格式、提供备用方案等),并输出优化后的 Skill。
步骤5:迭代优化
重复步骤 2-4,直到 Skill 可用。
五、实战技巧:如何提高生成质量
5.1 素材准备技巧
- 结构化素材:把素材整理成清晰的结构,便于模型理解
- 提供示例:提供正面和反面示例,让模型理解「好」和「坏」的区别
- 标注重点:在素材中标注重点内容,引导模型关注关键信息
5.2 Prompt 优化技巧
- 分步骤生成:不要一次性生成所有内容,分步骤生成(先元数据,再指令,再脚本)
- 明确格式要求:在 Prompt 中明确说明格式要求,避免格式错误
- 提供模板:提供模板示例,让模型参考
- 针对国内模型的优化 :
- 如果使用中文模型,直接用中文编写 Prompt 通常效果更好
- 对于 YAML 格式,可以在 Prompt 中强调「严格按照 YAML 语法,注意缩进和冒号后的空格」
- 如果模型对 Markdown 格式支持较弱,可以提供更详细的格式示例
5.3 测试技巧
- 边界测试:测试边界条件(空输入、错误输入、极端情况)
- 多场景测试:在不同场景下测试 Skill,确保通用性
- 回归测试:优化后重新测试,确保没有引入新问题
六、总结
核心转变:从「手敲所有文案」到 Context Engineering,从「写代码的人」到「架构师」,从一次性编写到迭代优化。
工作流:明确逻辑 → 准备素材 → 用 Prompt 自动生成 → 模型 A 生成、模型 B 测试(双人协作)→ 根据反馈迭代。
收获:效率提升(几分钟生成)、格式更规范、易维护、模板可复用。建议先按本文工作流生成一个 Skill,再根据使用情况优化模板、积累自己的素材库。