系统升级中如何实现数据平滑迁移?8 年 Java 开发:从业务崩溃到实战落地(附可复用代码)
作为一名摸爬滚打 8 年的 Java 开发,我踩过最痛的坑,莫过于系统升级时的 "数据迁移事故":
-
早期做电商系统 MySQL 5.6 升 8.0,全量迁移时没锁表,导致新旧库订单数据差了 100 多笔,用户投诉 "下单后查不到订单";
-
去年中台项目从单体库拆分为分库分表,增量数据没处理好,切换后新库缺失 3 小时的用户积分记录,半夜紧急回滚;
-
甚至有次异构迁移(MySQL→PostgreSQL),字段类型映射错了(MySQL datetime→PG timestamp),导致历史订单时间全变成 "1970-01-01"。
数据平滑迁移的核心,从来不是 "把数据从 A 搬到 B",而是 "不中断业务、不丢数据、可回滚"。今天不聊空洞的理论,只从实战角度,带你吃透从 "业务调研" 到 "代码落地" 的全流程,避开那些让我熬夜加班的坑。
一、先搞懂:什么场景需要数据迁移?迁移的核心痛点是什么?
别上来就写迁移脚本,八年开发的第一个经验:先明确 "为什么迁" 和 "迁什么" ,否则很容易做无用功。
1. 常见的迁移场景
| 迁移场景 | 业务背景示例 | 核心挑战 |
|---|---|---|
| 同构数据库升级 | MySQL 5.7→8.0、PostgreSQL 12→16 | 全量迁移效率、增量数据同步 |
| 异构数据库迁移 | MySQL→PostgreSQL、Oracle→ClickHouse | 字段类型映射、函数兼容性(如 MySQL NOW ()≠PG CURRENT_TIMESTAMP ()) |
| 分库分表改造 | 单体 MySQL→ShardingSphere 分库分表 | 数据分片规则设计、历史数据拆分、增量双写 |
| 存储引擎升级 | MySQL InnoDB→TiDB、Redis→Redis Cluster | 分布式事务一致性、数据分片后查询兼容 |
| 系统重构 / 中台化 | 旧单体系统→新中台(用户数据迁移) | 字段冗余 / 缺失处理、业务逻辑对齐 |
2. 迁移的 3 大核心痛点(也是 "平滑" 的关键)
- 业务不中断:不能为了迁移停服几小时(比如电商系统 24 小时运行);
- 数据一致性:迁移后新旧库数据必须完全一致(不能丢数据、不能多数据);
- 可回滚:一旦迁移出问题,能快速切回旧系统,避免故障扩大。
二、平滑迁移的通用流程:8 年实战总结的 "五步法"
不管什么场景,平滑迁移都离不开这 5 个步骤,少一步都可能出问题:
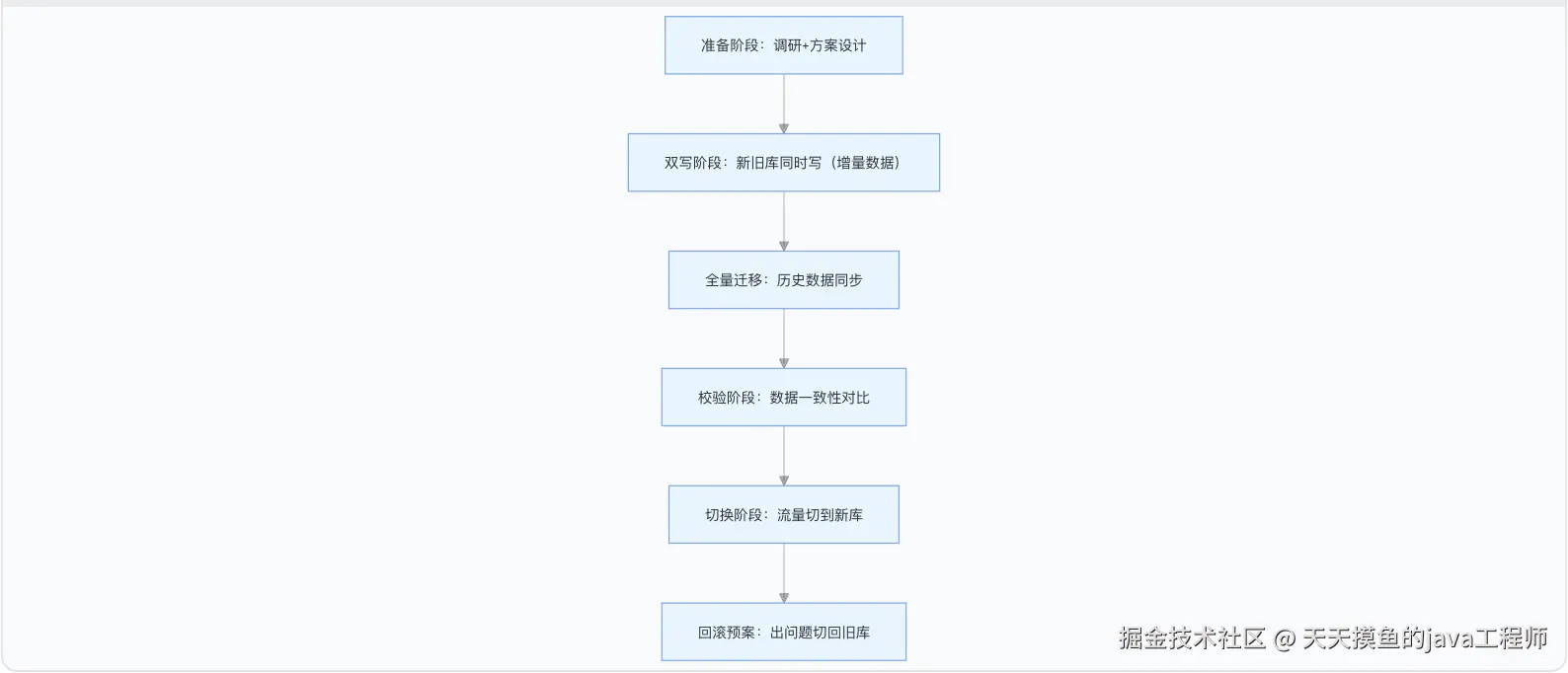
每个步骤都有 "必须做的事" 和 "不能踩的坑",下面逐个拆解。
三、分场景实战:从业务需求到代码落地
不同迁移场景的实现方案差异很大,这里重点讲 3 个最常见的场景,附核心代码。
场景 1:同构数据库平滑迁移(MySQL 5.7→8.0)
业务背景
电商订单系统升级 MySQL 版本,要求:
- 不影响白天下单(业务不中断);
- 迁移后订单数据 100% 一致;
- 支持 1 小时内回滚。
迁移方案:双写 + 全量迁移 + Canal 同步
核心代码实现
1. 第一步:双写实现(增量数据同步)
升级期间,新写的订单数据要同时写入旧库(MySQL 5.7)和新库(MySQL 8.0),用 Spring Boot 的PlatformTransactionManager管理双事务。
scss
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.TransactionStatus;
import org.springframework.transaction.support.DefaultTransactionDefinition;
@Service
public class OrderService {
// 旧库数据源事务管理器(MySQL 5.7)
@Autowired
private DataSourceTransactionManager oldTxManager;
// 新库数据源事务管理器(MySQL 8.0)
@Autowired
private DataSourceTransactionManager newTxManager;
// 旧库DAO
@Autowired
private OldOrderMapper oldOrderMapper;
// 新库DAO
@Autowired
private NewOrderMapper newOrderMapper;
/**
* 订单双写:同时写入旧库和新库
* 关键:双事务独立控制,一个失败则全部回滚
*/
public void createOrder(OrderDTO orderDTO) {
DefaultTransactionDefinition txDef = new DefaultTransactionDefinition();
// 旧库事务
TransactionStatus oldTx = oldTxManager.getTransaction(txDef);
// 新库事务
TransactionStatus newTx = newTxManager.getTransaction(txDef);
try {
// 1. 写入旧库(保持业务正常运行)
OldOrderDO oldOrder = OrderConverter.toOldDO(orderDTO);
oldOrderMapper.insert(oldOrder);
// 2. 写入新库(同步增量数据)
NewOrderDO newOrder = OrderConverter.toNewDO(orderDTO);
newOrderMapper.insert(newOrder);
// 双事务都提交
oldTxManager.commit(oldTx);
newTxManager.commit(newTx);
} catch (Exception e) {
// 任一失败,双事务都回滚
if (!oldTx.isCompleted()) {
oldTxManager.rollback(oldTx);
}
if (!newTx.isCompleted()) {
newTxManager.rollback(newTx);
}
log.error("订单双写失败,订单号:{}", orderDTO.getOrderNo(), e);
throw new BusinessException("下单失败,请重试");
}
}
}2. 第二步:全量迁移(历史订单数据)
用多线程分批读取旧库历史数据,避免单线程读取过大导致 OOM(比如迁移 1000 万条订单,每次读 1000 条)。
scss
@Component
public class OrderFullMigrationService {
// 批次大小:根据数据库性能调整(MySQL建议500-2000条/批)
private static final int BATCH_SIZE = 1000;
// 线程池:核心线程数=CPU核心数,避免压垮数据库
private final ExecutorService migrationPool = new ThreadPoolExecutor(
Runtime.getRuntime().availableProcessors(),
Runtime.getRuntime().availableProcessors() * 2,
60, TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100),
new ThreadPoolExecutor.CallerRunsPolicy() // 队列满了用主线程执行,避免任务丢失
);
@Autowired
private OldOrderMapper oldOrderMapper;
@Autowired
private NewOrderMapper newOrderMapper;
/**
* 全量迁移历史订单
* 逻辑:分页查询旧库→多线程写入新库→批次记录(便于断点续迁)
*/
public void migrateFullHistory() {
// 1. 查询旧库总条数
long totalCount = oldOrderMapper.countAll();
// 2. 计算总批次
long totalBatch = (totalCount + BATCH_SIZE - 1) / BATCH_SIZE;
log.info("历史订单总条数:{},总批次:{}", totalCount, totalBatch);
// 3. 多线程分批迁移
for (long batchNo = 1; batchNo <= totalBatch; batchNo++) {
long offset = (batchNo - 1) * BATCH_SIZE;
// 提交批次任务
migrationPool.submit(() -> {
try {
// 3.1 分页查询旧库数据(用limit offset,size,注意:offset过大时性能差,建议用ID范围查询)
// 优化方案:where id > lastId limit 1000(比offset更高效)
List<OldOrderDO> oldOrders = oldOrderMapper.selectByPage(offset, BATCH_SIZE);
if (CollectionUtils.isEmpty(oldOrders)) {
log.info("批次{}:无数据可迁移", batchNo);
return;
}
// 3.2 转换为新库DO
List<NewOrderDO> newOrders = oldOrders.stream()
.map(OrderConverter::toNewDO)
.collect(Collectors.toList());
// 3.3 批量写入新库
newOrderMapper.batchInsert(newOrders);
log.info("批次{}:迁移成功,条数:{}", batchNo, newOrders.size());
// 3.4 记录已迁移批次(存入Redis/数据库,便于断点续迁)
redisTemplate.opsForValue().set("order:migrate:batch", batchNo);
} catch (Exception e) {
log.error("批次{}:迁移失败", batchNo, e);
// 失败批次记录到异常表,后续手动处理
migrationFailMapper.insert(new MigrationFailDO(batchNo, "订单迁移失败", e.getMessage()));
}
});
}
// 4. 等待所有批次完成
migrationPool.shutdown();
try {
if (!migrationPool.awaitTermination(24, TimeUnit.HOURS)) {
log.error("全量迁移超时,强制关闭线程池");
migrationPool.shutdownNow();
}
} catch (InterruptedException e) {
migrationPool.shutdownNow();
Thread.currentThread().interrupt();
}
}
}3. 第三步:数据校验(确保一致性)
用 "总量对比 + 抽样 MD5" 的方式校验,避免全量 MD5 计算耗时过长。
scss
@Component
public class DataCheckService {
@Autowired
private OldOrderMapper oldOrderMapper;
@Autowired
private NewOrderMapper newOrderMapper;
/**
* 订单数据一致性校验
* @return 校验结果:true=一致,false=不一致
*/
public boolean checkOrderDataConsistency() {
// 1. 总量对比(快速判断是否有明显差异)
long oldTotal = oldOrderMapper.countAll();
long newTotal = newOrderMapper.countAll();
if (oldTotal != newTotal) {
log.error("订单总量不一致:旧库{},新库{}", oldTotal, newTotal);
return false;
}
// 2. 抽样MD5校验(随机抽1000条,对比字段MD5值)
List<Long> sampleOrderIds = oldOrderMapper.selectRandomOrderIds(1000);
for (Long orderId : sampleOrderIds) {
OldOrderDO oldOrder = oldOrderMapper.selectById(orderId);
NewOrderDO newOrder = newOrderMapper.selectById(orderId);
if (oldOrder == null && newOrder == null) {
continue;
}
if (oldOrder == null || newOrder == null) {
log.error("订单{}:旧库/新库存在空数据", orderId);
return false;
}
// 计算MD5(包含核心字段:orderNo、userId、amount、status等)
String oldMd5 = calculateMd5(oldOrder);
String newMd5 = calculateMd5(newOrder);
if (!oldMd5.equals(newMd5)) {
log.error("订单{}:MD5不一致,旧库{},新库{}", orderId, oldMd5, newMd5);
return false;
}
}
log.info("订单数据校验通过,总量一致,抽样MD5全部匹配");
return true;
}
/**
* 计算对象MD5(核心字段拼接后加密)
*/
private String calculateMd5(Object obj) {
try {
// 1. 获取核心字段(用反射或手动拼接,避免冗余字段影响MD5)
String content = "";
if (obj instanceof OldOrderDO) {
OldOrderDO order = (OldOrderDO) obj;
content = order.getOrderNo() + order.getUserId() + order.getAmount() + order.getStatus();
} else if (obj instanceof NewOrderDO) {
NewOrderDO order = (NewOrderDO) obj;
content = order.getOrderNo() + order.getUserId() + order.getAmount() + order.getStatus();
}
// 2. MD5加密
MessageDigest md5 = MessageDigest.getInstance("MD5");
byte[] bytes = md5.digest(content.getBytes(StandardCharsets.UTF_8));
// 3. 转换为16进制字符串
return DatatypeConverter.printHexBinary(bytes).toLowerCase();
} catch (Exception e) {
log.error("计算MD5失败", e);
throw new RuntimeException("数据校验失败");
}
}
}4. 第四步:流量切换(灰度→全量)
先切 10% 的流量到新库,观察 1 小时无问题再切 50%,最后全量,避免一次性切换导致故障。
kotlin
@Configuration
public class OrderDataSourceRouteConfig {
// 切换开关:0=全量旧库,1=10%新库,2=50%新库,3=全量新库(用Nacos配置中心动态调整)
@Value("${order.datasource.route.switch:0}")
private int routeSwitch;
/**
* 动态路由数据源:根据开关和用户ID哈希分配流量
*/
public DataSource routeDataSource(Long userId) {
// 全量旧库
if (routeSwitch == 0) {
return oldDataSource;
}
// 全量新库
if (routeSwitch == 3) {
return newDataSource;
}
// 灰度流量:根据用户ID哈希取模,确保同一用户流量稳定
int hash = Math.abs(userId.hashCode()) % 100;
// 10%新库:哈希0-9的用户走新库
if (routeSwitch == 1 && hash < 10) {
return newDataSource;
}
// 50%新库:哈希0-49的用户走新库
if (routeSwitch == 2 && hash < 50) {
return newDataSource;
}
// 其他情况走旧库
return oldDataSource;
}
}场景 2:异构数据库迁移(MySQL→PostgreSQL)
核心挑战
- 字段类型映射:MySQL
datetime→PGtimestamp with time zone、MySQLvarchar→PGtext; - 函数差异:MySQL
DATE_FORMAT()→PGTO_CHAR()、MySQLCONCAT()→PG||; - 自增主键:MySQL
auto_increment→PGserial/bigserial。
关键代码:字段转换器
typescript
public class OrderConverter {
/**
* MySQL DO → PostgreSQL DO(处理字段类型差异)
*/
public static PgOrderDO toPgDO(MySqlOrderDO mySqlOrder) {
PgOrderDO pgOrder = new PgOrderDO();
pgOrder.setId(mySqlOrder.getId());
pgOrder.setOrderNo(mySqlOrder.getOrderNo());
pgOrder.setUserId(mySqlOrder.getUserId());
// 1. datetime→timestamp with time zone(PG建议带时区)
pgOrder.setCreateTime(convertToPgTimestamp(mySqlOrder.getCreateTime()));
// 2. decimal(MySQL)→numeric(PG,精度保持一致)
pgOrder.setAmount(new BigDecimal(mySqlOrder.getAmount().toString()));
// 3. 枚举映射:MySQL tinyint(1=待支付,2=已支付)→PG varchar
pgOrder.setStatus(convertOrderStatus(mySqlOrder.getStatus()));
return pgOrder;
}
/**
* MySQL datetime → PG timestamp with time zone
*/
private static Timestamp convertToPgTimestamp(java.util.Date date) {
if (date == null) {
return null;
}
// PG的timestamp带时区,默认用UTC
return new Timestamp(date.getTime());
}
/**
* 订单状态映射(避免枚举值不兼容)
*/
private static String convertOrderStatus(Integer mySqlStatus) {
switch (mySqlStatus) {
case 1:
return "PENDING_PAY";
case 2:
return "PAID";
case 3:
return "CANCELED";
default:
throw new IllegalArgumentException("不支持的订单状态:" + mySqlStatus);
}
}
}工具推荐
用阿里的DataX做全量迁移(支持异构数据库),配置文件示例(mysql2pg.json):
json
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"username": "root",
"password": "123456",
"column": ["id", "order_no", "user_id", "amount", "status", "create_time"],
"connection": [
{
"table": ["order"],
"jdbcUrl": ["jdbc:mysql://192.168.1.100:3306/old_db?useSSL=false"]
}
],
"where": "create_time < '2024-01-01' " // 历史数据过滤
}
},
"writer": {
"name": "postgresqlwriter",
"parameter": {
"username": "postgres",
"password": "123456",
"column": ["id", "order_no", "user_id", "amount", "status", "create_time"],
"connection": [
{
"table": ["order"],
"jdbcUrl": "jdbc:postgresql://192.168.1.200:5432/new_db"
}
],
"preSql": ["TRUNCATE TABLE order"], // 迁移前清空表(仅测试用)
"batchSize": 1000
}
}
}
],
"setting": {
"speed": {
"channel": 5 // 并发通道数,根据数据库性能调整
}
}
}
}场景 3:分库分表迁移(单体→ShardingSphere)
核心挑战
- 分片规则设计(比如按
user_id%8分 8 个库); - 历史数据按分片规则拆分到对应分库;
- 增量数据双写时,需按分片规则路由到正确的分库。
关键代码:分片路由
ini
@Service
public class ShardingOrderService {
@Autowired
private ShardingOrderMapper shardingOrderMapper;
/**
* 分库分表双写:按user_id分片
*/
public void createShardingOrder(OrderDTO orderDTO) {
// 1. 计算分片键(按user_id%8分8个库)
int dbIndex = Math.abs(orderDTO.getUserId().hashCode()) % 8;
String dbName = "order_db_" + dbIndex;
log.info("订单{}:分片到数据库{}", orderDTO.getOrderNo(), dbName);
// 2. 转换为分库DO(携带分片键)
ShardingOrderDO shardingOrder = OrderConverter.toShardingDO(orderDTO);
// 3. 写入对应分库(ShardingSphere会自动路由,也可手动指定)
shardingOrderMapper.insert(shardingOrder);
}
/**
* 历史数据分片迁移:按user_id拆分到对应分库
*/
public void migrateToSharding() {
// 1. 按分片键范围查询旧库数据(比如user_id 0-100000到db_0)
for (int dbIndex = 0; dbIndex < 8; dbIndex++) {
long startUserId = dbIndex * 100000;
long endUserId = (dbIndex + 1) * 100000;
log.info("迁移分库{}:user_id范围{}~{}", dbIndex, startUserId, endUserId);
// 2. 分批查询旧库
long offset = 0;
while (true) {
List<OldOrderDO> oldOrders = oldOrderMapper.selectByUserIdRange(startUserId, endUserId, offset, BATCH_SIZE);
if (CollectionUtils.isEmpty(oldOrders)) {
break;
}
// 3. 写入对应分库
List<ShardingOrderDO> shardingOrders = oldOrders.stream()
.map(OrderConverter::toShardingDO)
.collect(Collectors.toList());
shardingOrderMapper.batchInsert(shardingOrders);
offset += BATCH_SIZE;
log.info("分库{}:迁移完成{}条", dbIndex, offset);
}
}
}
}四、八年开发的避坑指南:这些错别再犯!
- 坑 1:全量迁移没锁表,导致数据不一致
之前迁移时没锁旧库的写操作,全量迁移到一半,旧库又新增了订单,导致新库少了这部分数据。
解决方案:全量迁移时,对旧库表加 "读锁"(MySQL 用LOCK TABLES order READ),或选择业务低峰期(比如凌晨 2-4 点)迁移,迁移期间禁止写操作。 - 坑 2:双写时没处理事务,导致 "半成功"
早期双写用了单事务管理器,旧库写入成功但新库超时,结果事务回滚,旧库数据也丢了。
解决方案:用独立双事务(如场景 1 中的代码),两个库的事务单独控制,任一失败则全部回滚;或用 "最终一致性"(写旧库 + 发 MQ,消费 MQ 写入新库,失败重试)。 - 坑 3:忽略增量数据的 "延迟"
全量迁移完成后,直接切换流量,发现新库缺失 "全量迁移期间的增量数据"(比如全量迁了 2 小时,这 2 小时的新订单没同步)。
解决方案:先开启双写 / Canal 同步(提前 1 天开启),再做全量迁移,确保全量期间的增量数据已同步到新库。 - 坑 4:切换后没监控,出问题没发现
有次切换后,新库的索引没建全,订单查询接口耗时从 50ms 变成 500ms,用户投诉后才发现。
解决方案:切换后实时监控 "新库 QPS、响应时间、错误率",同时监控 "新旧库数据增量是否一致"(比如每小时对比一次新增订单数)。 - 坑 5:没做回滚预案,出问题只能硬扛
异构迁移时,PG 的字段长度设小了(MySQL varchar (255)→PG varchar (100)),导致部分订单号写入失败,又没回滚方案,只能半夜改 PG 字段长度。
解决方案:切换前必须做好回滚开关(如场景 1 中的routeSwitch),一旦出问题,1 分钟内切回旧库;同时备份旧库数据(迁移前用mysqldump全量备份)。
五、总结:平滑迁移的 3 个核心原则
八年开发实战下来,我发现数据平滑迁移的本质,不是 "技术多复杂",而是 "细节多周全":
-
数据一致性优先:不管用双写、Canal 还是 DataX,必须有校验环节(总量 + 抽样),确保迁移后数据 100% 一致;
-
业务不中断为前提:用双写、灰度切换避免停服,即使是低峰期迁移,也要确保迁移期间业务能正常运行;
-
可回滚是底线:永远不要假设 "迁移一定成功",必须提前做好回滚开关和数据备份,出问题能快速恢复。
最后送大家一句话:数据迁移不是 "一次性操作",而是 "持续验证的过程" ------ 从准备到切换,每一步都要留痕、可追溯,这样才能避免熬夜加班,平稳完成系统升级。