梳理 hf_hub_download 和 snapshot_download 的区别、相同点,以及各自适合的场景。
1. 相同点
-
都来自
huggingface_hubpythonfrom huggingface_hub import hf_hub_download, snapshot_download -
都用于下载 Hugging Face Hub 上的模型或文件
- 都可以指定
repo_id(仓库名)、revision(分支/commit/tag)等参数。 - 都支持设置缓存目录
cache_dir。 - 都可以配合
proxies或国内镜像使用。
- 都可以指定
-
缓存机制相同
- 下载后的文件会缓存在
HF_HOME或指定cache_dir中。 - 如果文件已经存在缓存中,下次直接读取,无需重新下载。
- 下载后的文件会缓存在
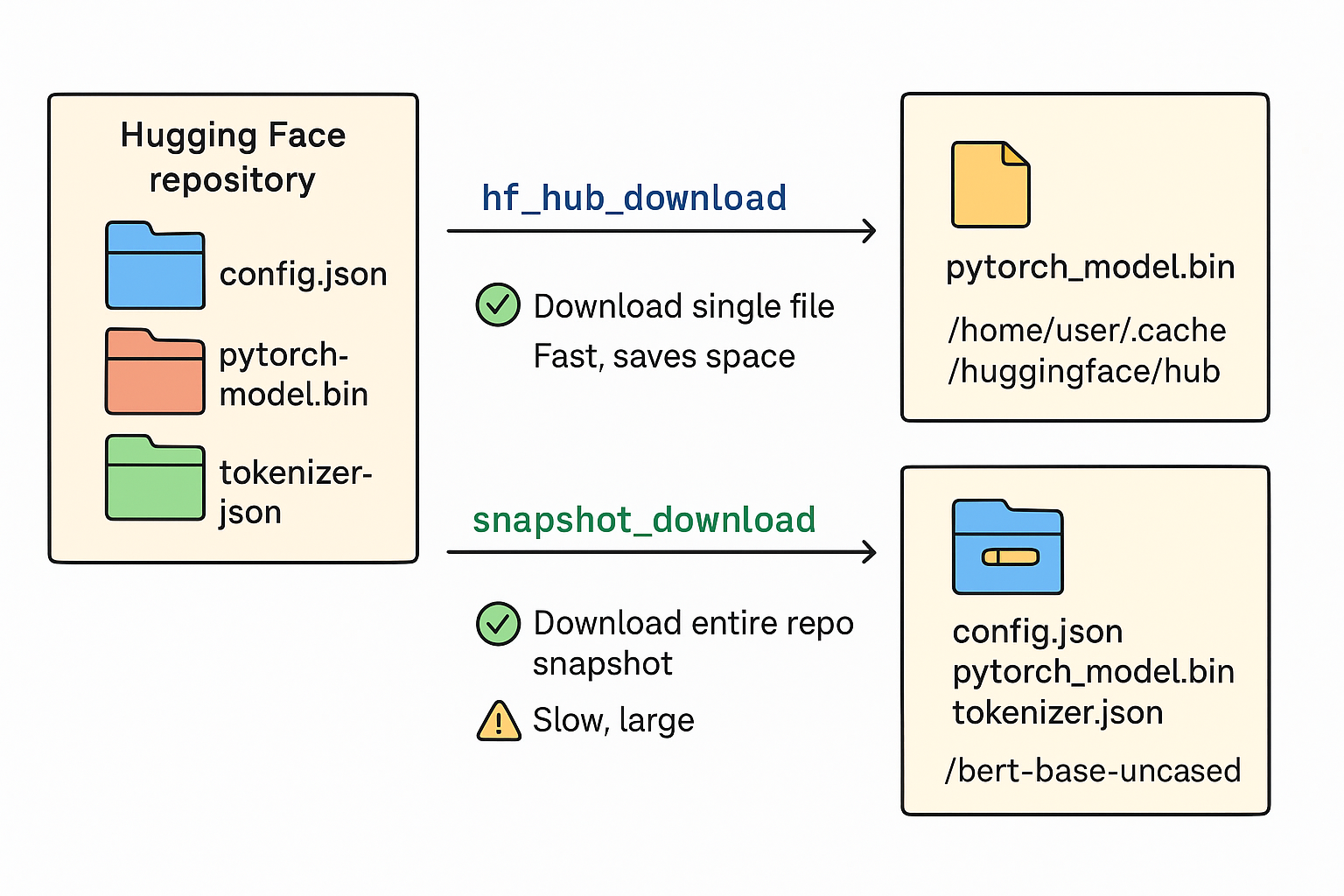
2. 不同点
| 特性 | hf_hub_download |
snapshot_download |
|---|---|---|
| 下载粒度 | 单个文件 | 仓库快照(整个模型目录) |
| 返回值 | 本地文件路径 | 仓库本地路径(目录) |
| 适合场景 | 只想下载仓库中的单个文件,比如 model.safetensors 或 config.json |
想获取整个仓库内容,包括多个文件、权重、tokenizer、配置等 |
| 使用方法 | python local_file = hf_hub_download(repo_id, filename) |
python local_dir = snapshot_download(repo_id) |
| 耗时 | 快(只下载一个文件) | 慢(下载整个仓库) |
| 存储空间 | 小 | 大 |
3. 场景示例
hf_hub_download
python
from huggingface_hub import hf_hub_download
# 下载单个模型权重文件
local_file = hf_hub_download(
repo_id="bert-base-uncased",
filename="pytorch_model.bin",
cache_dir="/home/user/.cache/huggingface/hub"
)✅ 场景:
- 只需要模型权重或 tokenizer 文件。
- 快速下载一个文件,不需要整个仓库。
- 适合自定义加载模型时使用(如
FastLanguageModel.from_pretrained(local_file))。
snapshot_download
python
from huggingface_hub import snapshot_download
# 下载整个仓库快照
local_dir = snapshot_download(
repo_id="bert-base-uncased",
cache_dir="/home/user/.cache/huggingface/hub"
)✅ 场景:
-
需要整个模型仓库,包括
config.json、tokenizer文件、权重文件等。 -
想离线完整使用模型,或者需要对多个文件进行统一管理。
-
适合加载 Transformers 模型时直接传目录:
pythonfrom transformers import AutoModel model = AutoModel.from_pretrained(local_dir)
4. 小结
- hf_hub_download → 下载单个文件,速度快,适合下载模型权重或配置文件。
- snapshot_download → 下载整个仓库,完整快照,适合一次性获取整个模型目录用于离线或批量操作。
5. example
使用国内镜像下载模型
python
import os
from huggingface_hub import snapshot_download
from unsloth.models import FastLanguageModel
# -------------------------------
# 1. 设置缓存目录和镜像
# -------------------------------
os.environ["HF_HOME"] ="/home/xjg/.cache/huggingface/hub" # 可自定义缓存路径
os.environ["HF_DATASETS_OFFLINE"] = "1" # 只从本地缓存读取数据集,不访问网络
os.environ["TRANSFORMERS_OFFLINE"] = "0" # "0" 表示在线模式;如果设置为 "1",transformers 会只从本地缓存加载模型
# 国内 Hugging Face 官方 CDN 镜像(无需代理)
HF_ENDPOINT = "https://hf-mirror.com/"
# -------------------------------
# 2. 下载模型到本地
# -------------------------------
model_name = "unsloth/DeepSeek-R1-Distill-Qwen-1.5B-unsloth-bnb-4bit"
filename = "model.safetensors"
# 使用 snapshot_download 下载整个模型目录
local_model_dir = snapshot_download(
repo_id=model_name,
cache_dir=os.environ["HF_HOME"],
use_auth_token=None, # 如果是私有模型,需要填入 token
endpoint=HF_ENDPOINT
)
print(f"模型下载到本地目录:{local_model_dir}")
# -------------------------------
# 3. 从本地加载模型和分词器
# -------------------------------
max_seq_length = 2048
dtype = "float16"
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=local_model_dir,
max_seq_length=max_seq_length,
dtype=dtype,
load_in_4bit=load_in_4bit
)
print("模型和分词器加载成功!")输出结果:
python
🦥 Unsloth: Will patch your computer to enable 2x faster free finetuning.
🦥 Unsloth Zoo will now patch everything to make training faster!
Fetching 8 files: 100%|███████████████████████████████████████████████████████████████| 8/8 [00:00<00:00, 56299.38it/s]
模型下载到本地目录:/home/xjg/.cache/huggingface/hub/models--unsloth--DeepSeek-R1-Distill-Qwen-1.5B-unsloth-bnb-4bit/snapshots/c93b549ceae3f8137b567af565c2b204b3045091
==((====))== Unsloth 2025.8.5: Fast Qwen2 patching. Transformers: 4.55.2.
\\ /| NVIDIA GeForce RTX 3060 Laptop GPU. Num GPUs = 1. Max memory: 5.799 GB. Platform: Linux.
O^O/ \_/ \ Torch: 2.7.1+cu126. CUDA: 8.6. CUDA Toolkit: 12.6. Triton: 3.3.1
\ / Bfloat16 = TRUE. FA [Xformers = 0.0.31.post1. FA2 = False]
"-____-" Free license: http://github.com/unslothai/unsloth
Unsloth: Fast downloading is enabled - ignore downloading bars which are red colored!
模型和分词器加载成功!