大家好,我是1024小神,技术群 / 私活群 / 股票群 或 交朋友 都可以私信我。
如果你觉得本文有用,一键三连 (点赞、评论、关注),就是对我最大的支持~

比如你想快速将buffer.com/open 这个网站本地化访问,或者是想快速copy一个一模一样的网站出来,就可以使用这个教程来做,支持将整个网站copy,也支持只copy某些页面,最好是copy一个静态类型的网站,例如文档类等,如果是动态类型的网站,可能需要依赖接口来提供数据支撑才可以显示页面内容,这种就需要二次修改,这个也可以做,但是相对麻烦,如果你想copy一个动态网站,理论上你应该是想要他的网站样式,而不是他的数据,因为数据不太好本地化处理。
copy静态网站
使用的工具就是wget,非常牛逼,没有之一,使用方式和参数解释可以看这篇文章:juejin.cn/post/754290...
强烈不建议复制整个网站,因为这会非常慢,并且下载到的内容非常大:
如果我只想下载某个页面内容的html/css/js等文件
命令:
diff
wget -p -k -E https://example.com/page
参数解释:
-p (page-requisites)下载显示该页面所需的所有资源(CSS、JS、图片)。
-k (convert-links)把网页里的链接改成本地相对路径,这样离线打开不会跳外网。
-E (adjust-extension)自动给文件加 .html 后缀,保证浏览器能识别。如果我只想下载某个页面及其一级子页面内容的html/css/js等文件:
diff
wget -r -l 1 -p -k -E https://example.com/page
参数解释
-r (recursive)递归下载。
-l 1 (level=1)递归深度为 1如果只想下载某些页面及其页面内容:
perl
wget -p -k -E https://buffer.com/open https://buffer.com/metrics https://buffer.com/shareholders https://buffer.com/salaries https://buffer.com/about https://buffer.com/transparent-pricing https://buffer.com/timeoff https://buffer.com/metrics https://buffer.com/books https://buffer.com/resources/open/如果页面很多,可以写在文件里
比如把要下载的 URL 写到 urls.txt:
arduino
https://example.com/page1
https://example.com/page2
https://example.com/page3然后执行:
css
wget -p -k -E -i urls.txt如果支持某些页面,执行完后,会提示完成,就可以打开对应的文件夹里面的文件访问了:
使用浏览器打开html文件或者启动一个服务都可以:
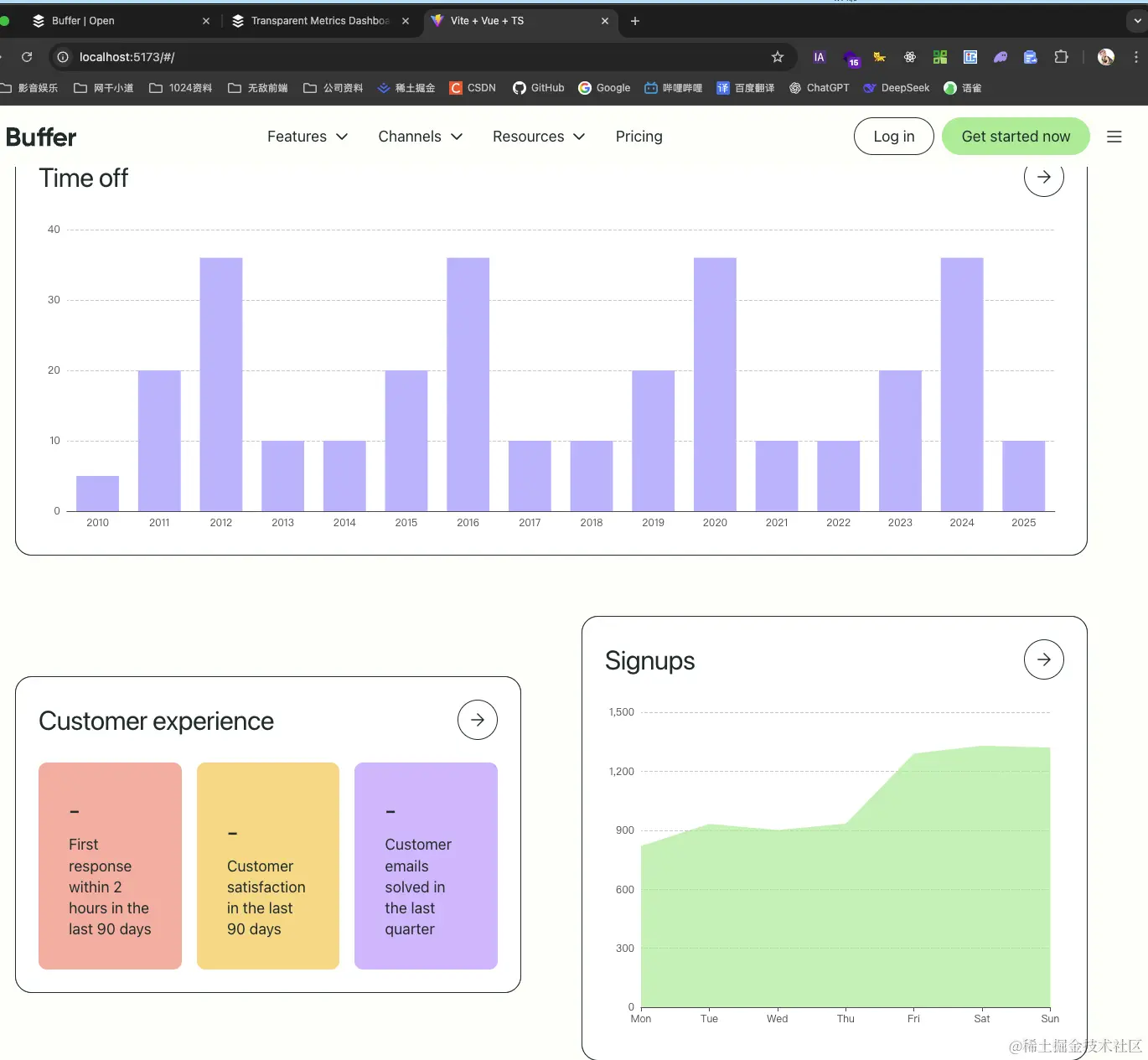
如果某些数据需要通过接口来获取并展示,比如图表这些,就需要二次处理了,你可以将下载到的html内容集成到vue/react项目中,当作模板,然后请求接口或自己的接口来实现数据获取,并通过echart来绘制图表内容,这过程中记得还要将css/js等依赖文件也配置到vue/react项目中,这样才不会出现样式错乱问题:
copy动态网站
如果你copy的网站是动态的,比如使用vue/react写的,那么不太推荐使用wget,你应该使用支持无头浏览器(Headless Browser)的工具 。这些工具会实际运行JavaScript,等待页面完全渲染后再下载内容。使用 puppeteer/playwright + 自定义脚本(专业推荐)
更推荐使用playwright,因为很方便:github.com/microsoft/p...
如果你有好的想法或需求,可以私信我,我这里有很多程序员朋友可以帮你实现你的想法。