前言
又是一年"金九银十"秋招季,大模型相关的技术岗位竞争也到了白热化阶段。为满足大家碎片化时间复习补充面试知识点的需求(泪目,思绪回到前两年自己面试的时候),笔者特开设 《大模型工程面试经典》 专栏,持续更新工作学习中遇到大模型技术与工程方面的面试题及其讲解。每个讲解都有一个必考题和相关热点问题组成,小伙伴们感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。
一、面试题:如何评估大模型微调和训练所需硬件成本
1.1 问题浅析
不同于纯粹的算法问题,这个问题考察的是对大模型工程落地的整体把控能力,需要快速、准确地评估一项微调任务所需的显卡容量和时间,直接体现了对大模型训练工程体系的理解深度。
1.2 标准回答
Dense类模型
Dense类模型指的是每次都会代入全部参数进行推理或者训练的模型,例如Qwen3-32B 模型就是一个拥有32*10=320亿参数的Dense模型。
全量微调
在Dense模型架构下,如果是做全量微调,每一步计算都会激活所有参数,此时硬件成本的评估逻辑相对直接。常见估计方法是根据 模型参数规模 * 精度位宽 来粗略估计显存需求。例如一个70B参数的Dense模型,若采用FP16格式进行存储,计算存储显存:
参数量:700 0000 0000每个参数所bit数:16bit1GB所占bit数:1GB=1024MB=1024 * 1024KB=1024 * 1024 * 1024 B = 1024 * 1024 * 1024 * 8 bit
计算公式: 参数量 ✖ 每个参数所占位数 ➗ 1GB所占bit数 ≈ 140GB
训练过程中梯度存储的显存与存储显存相同占用140G,优化器例如AdamW要为每个参数额外维护一阶动量和二阶动量等额外信息一般占用4倍显存,也就是约560G, 全量微调总共需要840G,再考虑激活值存储、显存碎片化以及分布式训练的冗余开销,实际需求往往在1TB显存左右。
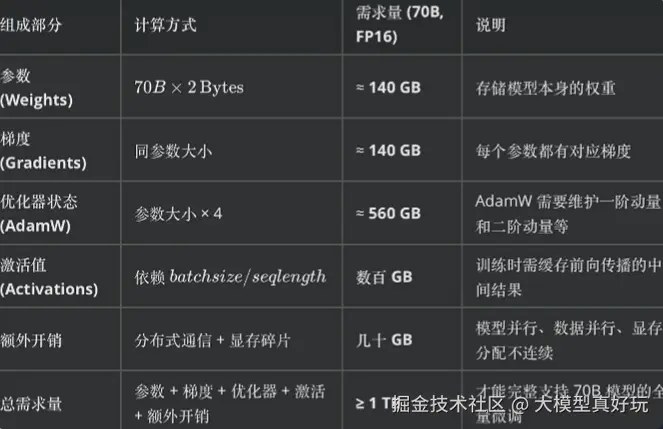
以上计算也可以整理为如下速算公式

如果换成参数更小的Dense模型,一般可以按照近似线性比例来计算显存需求。例如一个13B参数的模型,参数是70B模型的1/5左右,整体可能200GB显存以内就能完成全量微调。如果精度降低,比如采用8bit或4bit量化存储,显存占用会近似按照位宽缩减。以70B模型为例,FP16下参数是140GB,如果用8bit存储则需要约70GB,用4bit存储只有约35GB。不过量化模型梯度和优化器通常还是以FP16形式保存,因此总体显存缩减幅度有限。
Lora微调
如果采用Lora微调方法显存占用会显著降低。因为LORA只需要在部分矩阵中引入低秩适配器,训练时只更新新增的适配器参数,原始大模型参数保持冻结。例如对70B模型应用LORA,实际需要更新的参数量可能只有1%~2%, 因此显存需求往往控制在160G左右。
MoE模型微调
MoE(Mixture of Experts)是一种神经网络架构。其核心思想是"分而治之",将一个大模型拆分为多个功能不同的"专家"子网络(如前馈层)。对于每个输入,一个门控网络会动态选择并激活最相关的少数专家进行计算,再与共享参数的结果整合。这样能在显著增加模型总参数量的同时,保持计算量基本不变,实现了更高效的大模型训练与推理,例如Qwen3-235B-A22B 模型,激活参数为22B , 共享参数约为7.8B。
全量微调
MoE模型以Qwen3-235B-A22B为例,激活参数为22B,共享参数约为7.8B, 可以简单粗暴的将其等价为共享参数+激活参数等量的Dense模型,因此Qwen3-235B-A22B的微调显存等价于一个30B的Dense模型,也就是全量微调约需要500GB(当然实测用offload要比500多,可能到600左右,这里只是估计值)
Lora微调
高效Lora微调可能仅在不同专家中挑选适当数目的专家作微调,Qwen3-235B-A22B微调一般需要110GB显存即可。每个MoE模型的激活参数和共享参数量需要查阅官方说明文档来确定。
二、相关热点问题
2.1 MoE在企业环境中会遇到什么工程化难题?
答案: 除了专家路由均衡和高速互联依赖外,还会涉及跨卡通信优化、专家负载动态调度,以及需要考虑容错和监控机制等,这些都是工程化难点。
2.2 如果预算有限,如何优先分配硬件资源?
答案: 应先优先保障显存容量和带宽,以确保模型能正常加载和高效运行;其次是考虑显卡数量,对小模型而言,单卡大显存往往比多卡小显存效率更高,但是价格也更贵。
2.3 在评估硬件成本时,除了显卡还要考虑哪些隐形成本?
答案: 除了显卡还需要考虑电力与散热、机房空间、集群运维和人员那成本,以及分布式通信开销,这些隐性成本常被忽略却对整体预算影响显著。
三、总结
本期分享系统介绍了关于大模型训练和微调所需硬件成本的相关问题,总的来说硬件成本是大模型工程落地的必备能力。这类问题能让面试官快速感知你是否具备大模型的工程化能力以及是否有大模型工程化的实操经验。小伙伴们阅读后感兴趣可关注笔者掘金账号和专栏,更可关注笔者同名微信公众号: 大模型真好玩,免费分享学习工作中的知识点和资料。