点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!"快的模型 + 深度思考模型 + 实时路由",持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月18日更新到: Java-100 深入浅出 MySQL事务隔离级别:读未提交、已提交、可重复读与串行化 MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解

章节内容
上节我们完成了:
- Spark 简单介绍
- Spark 的特点
- Spark 与 Hadoop MapReduce 框架对比
- Spark的系统架构
- Spark的部署模式

Spark简介
上节我们已经介绍过了,这里为了保持完整性,简单的再扩展介绍一下。 Spark(Apache Spark)是一个快速、通用的分布式数据处理框架,旨在以高效的方式进行大规模数据的处理和分析。它最初由加利福尼亚大学伯克利分校AMPLab开发,并在2010年开源。如今,Spark已经成为大数据处理领域的重要工具之一,广泛应用于许多行业。 Spark凭借其速度、通用性和易用性,成为大数据处理领域的一项关键技术。无论是处理批量数据还是实时数据,亦或是进行机器学习和图计算,Spark都提供了强大的支持。如果你在寻找一个高效的大数据处理框架,Spark无疑是一个值得考虑的选择。
核心特性
速度优势
- 内存计算引擎:Spark采用基于内存的分布式计算框架,通过在集群内存中缓存中间计算结果,显著减少磁盘I/O操作。典型场景下,迭代算法(如机器学习)性能提升尤为明显,相比Hadoop MapReduce可实现10-100倍的加速。
- 智能缓存机制:支持MEMORY_ONLY、MEMORY_AND_DISK等多种存储级别策略,当内存不足时自动将部分数据溢出到磁盘,例如在Spark SQL查询中,常用表可被持久化缓存以加速后续查询。
- 执行优化:通过DAG调度器将任务分解为有向无环图,配合Tungsten引擎的二进制内存管理,减少JVM对象开销。例如,在TPC-DS基准测试中,Spark 3.0比早期版本性能提升2倍以上。
通用计算平台
- 多语言支持:提供Java/Scala原生API(核心实现)、Python(PySpark)和R(SparkR)接口。如在Jupyter Notebook中可直接使用PySpark进行数据分析。
- 统一计算引擎 :
- 批处理:通过RDD/DataFrame处理PB级数据
- 流处理:Structured Streaming支持微批和持续处理模式
- 机器学习:MLlib库包含常见算法实现(如随机森林、K-means)
- 图计算:GraphX支持Pregel API,适用于社交网络分析等场景
- 生态系统集成:可与HDFS、Hive、Kafka等大数据组件无缝对接,例如通过Spark Streaming消费Kafka实时数据流。
开发者友好性
- 抽象层次 :
- 基础RDD API提供分布式集合操作(map/reduce/filter等)
- DataFrame API引入schema概念,支持SQL式操作
- 最新Dataset API结合类型安全与优化优势
- 交互式工具 :
- 自带spark-shell(Scala)和pyspark(Python)REPL环境
- 支持Zeppelin、Jupyter等笔记本工具
- Spark SQL CLI提供类Hive的查询体验
- 学习资源:保持与Hadoop相似的MapReduce编程范式,但提供更简洁的lambda表达式写法,例如WordCount示例代码量减少60%。
弹性扩展能力
- 集群部署 :
- 支持Standalone模式快速搭建测试集群
- 原生集成YARN,可复用Hadoop集群资源
- 通过K8s Operator实现容器化部署
- 资源调度 :
- 动态资源分配(DRA)根据负载自动调整executor数量
- 支持公平调度(Fair Scheduler)满足多租户需求
- 规模验证:实际生产环境中已验证可处理EB级数据,如在某互联网公司的推荐系统每天处理超过5PB的用户行为数据。
Spark的组件
Spark Core
作为Spark的核心基础模块,Spark Core提供了分布式计算的基本功能。它实现了以下关键机制:
- 内存管理:采用弹性分布式数据集(RDD)的内存缓存机制,通过内存计算显著提升计算速度
- 任务调度:基于DAG(有向无环图)的任务调度系统,支持任务依赖关系管理和优化执行
- 容错机制:通过RDD的Lineage(血统)信息实现数据恢复,无需数据复制即可保证容错
- 存储系统交互:支持HDFS、HBase、Cassandra等多种存储系统,提供统一的访问接口
典型应用场景:ETL处理、迭代算法(如PageRank)、交互式数据分析等
Spark SQL
结构化数据处理模块,主要功能包括:
- DataFrame API:提供类似R/Pandas的DataFrame抽象,支持结构化操作
- SQL支持:完整兼容ANSI SQL标准,支持常见SQL操作
- 数据源集成:
- 内置支持Parquet、JSON、JDBC等格式
- 通过Hive兼容层可访问Hive元数据和表数据
- 支持自定义数据源扩展
- 优化器:基于Catalyst的查询优化器,自动优化执行计划
应用示例:数据仓库分析、报表生成、交互式查询等
Spark Streaming
实时流处理解决方案,特点包括:
- 微批处理架构:将流数据划分为小批次(如2秒)进行处理
- 精确一次语义:保证每个记录只被处理一次
- 窗口操作:支持滑动窗口、统计窗口等时间窗口操作
- 与批处理集成:可与Spark SQL、MLlib等无缝结合
典型应用场景:实时监控、日志分析、实时推荐系统等
MLlib
分布式机器学习库,主要提供:
- 算法实现:
- 分类:逻辑回归、决策树、随机森林等
- 回归:线性回归、保序回归等
- 聚类:K-means、LDA等
- 协同过滤:ALS(交替最小二乘)
- 工具链:
- 特征工程:TF-IDF、Word2Vec、标准化等
- 流水线:提供类似scikit-learn的Pipeline API
- 模型评估:交叉验证、多种评估指标
- 模型持久化:支持模型保存和加载
应用场景:用户画像、推荐系统、风险预测等
GraphX
图计算框架,主要功能:
- 图抽象:提供属性图(带属性的顶点和边)表示
- 图操作:
- 基础操作:子图筛选、顶点/边映射等
- 图算法:PageRank、连通组件、三角形计数等
- 图并行计算:基于Pregel API实现大规模图计算
- 与RDD互操作:可与普通RDD相互转换
典型应用:社交网络分析、交通网络分析、推荐系统等
使用场景
Spark广泛应用于各种需要大规模数据处理的场景,包括但不限于:
- 批处理:处理大量历史数据,如日志分析、ETL操作。
- 流处理:实时数据分析和处理,如网络监控、实时推荐系统。
- 机器学习:大规模数据上的机器学习任务,如推荐系统、文本分类。
- 交互式查询:通过Spark SQL对大数据集进行快速查询和分析。
- 图计算:处理社交网络、推荐系统中的复杂图结构数据。
下载文件
我们到官方地址下载:
shell
https://archive.apache.org/dist/spark/页面如下,为了保证稳定和学习的方便,我用了比较老的版本:2.4.5  我们选择:without-hadoop-scala 这种版本,可以不用安装配置 Scala:
我们选择:without-hadoop-scala 这种版本,可以不用安装配置 Scala:
shell
https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop-scala-2.12.tgz
解压配置
我们可以使用 wget 或者其他工具来完成文件的下载,我这里是传到服务器上:
shell
cd /opt/software/
wget https://archive.apache.org/dist/spark/spark-2.4.5/spark-2.4.5-bin-without-hadoop-scala-2.12.tgz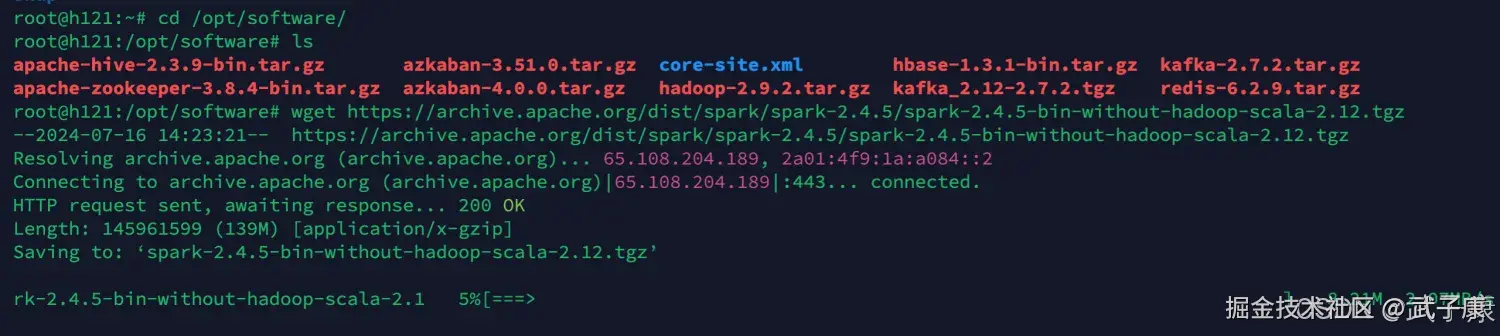 下载完成后,我们进行解压并移动到指定位置:
下载完成后,我们进行解压并移动到指定位置:
shell
cd /opt/software/
tar zxvf spark-2.4.5-bin-without-hadoop-scala-2.12.tgz 移动目录到servers下(之前的规范):
移动目录到servers下(之前的规范):
shell
mv spark-2.4.5-bin-without-hadoop-scala-2.12 ../servers
环境变量
shell
vim /etc/profile
# spark
export SPARK_HOME=/opt/servers/spark-2.4.5-bin-without-hadoop-scala-2.12
export PATH=$PATH:$SPARK_HOME/bin配置完的结果,记得刷新环境变量 
修改配置
shell
cd $SPARK_HOME/confslaves
shell
mv slaves.template slaves
vim slaves
# 集群地址
h121.wzk.icu
h122.wzk.icu
h123.wzk.icu配置完的样子大概如下: 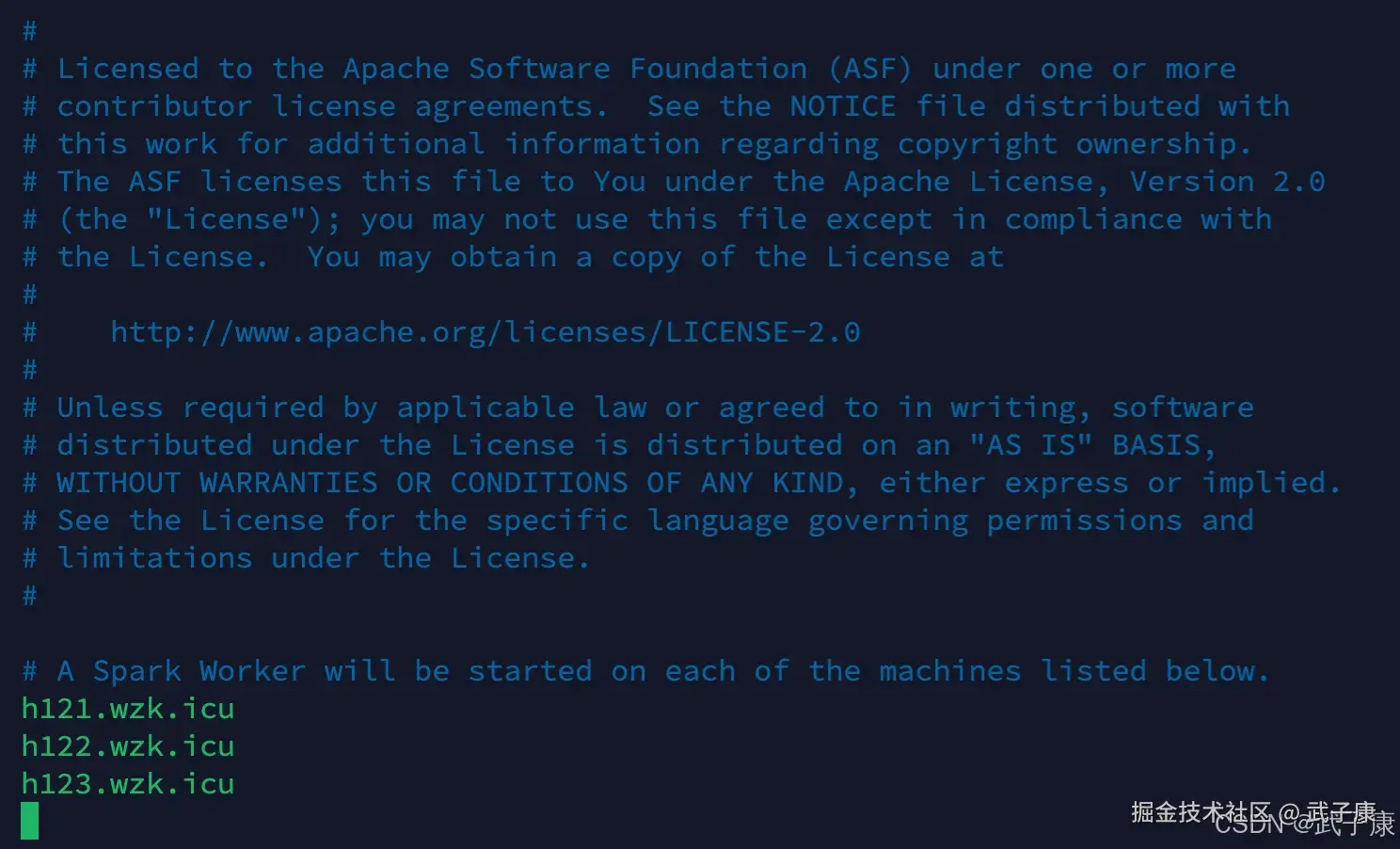
spark-defaults
shell
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
# 修改配置的信息
spark.master spark://h121.wzk.icu:7077
spark.eventLog.enabled true
spark.eventLog.dir hdfs://h121.wzk.icu:9000/spark-eventLog
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.driver.memory 512m配置完的结果如下图: 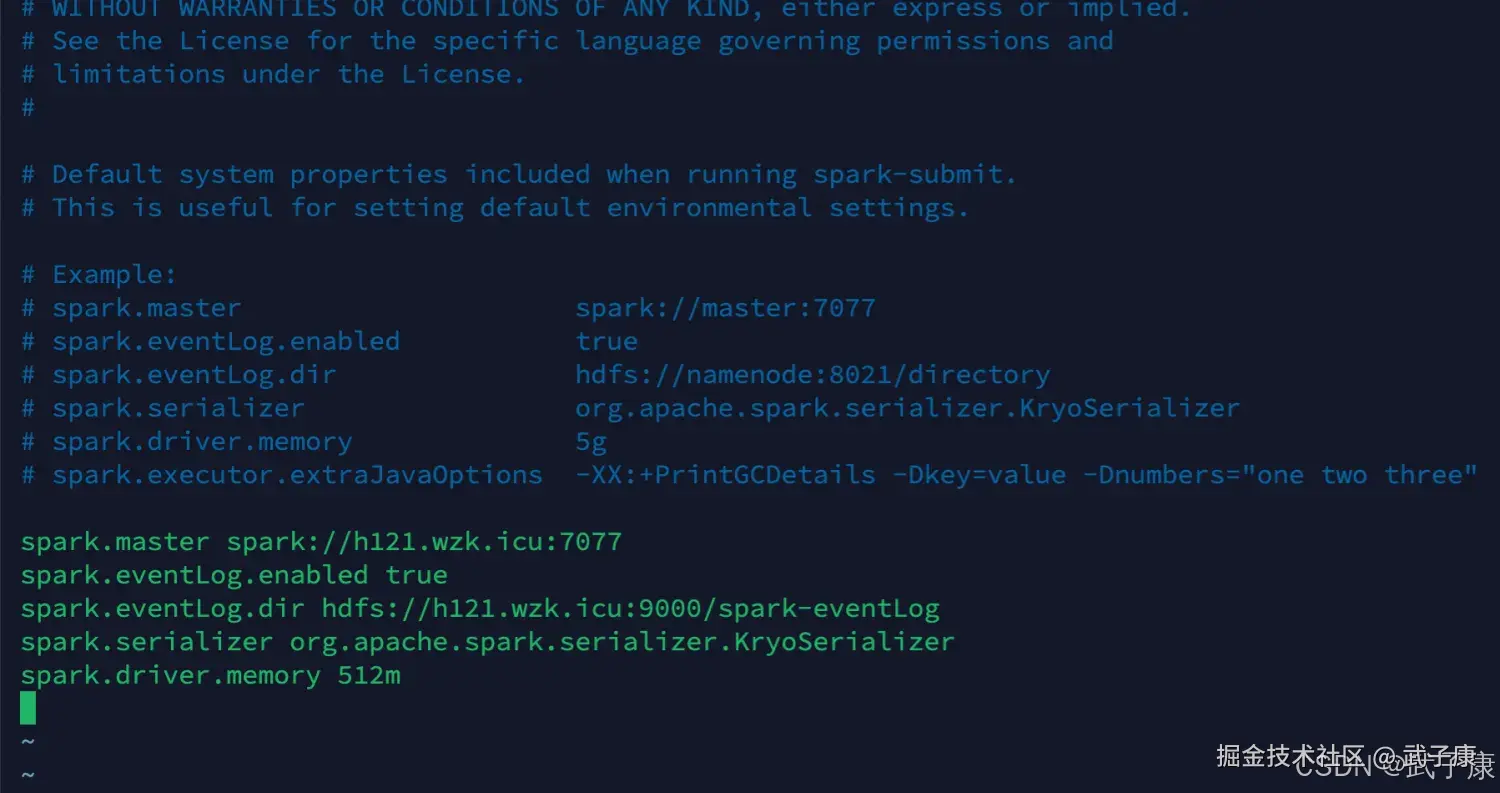
创建HDFS目录
shell
hdfs dfs -mkdir /spark-eventLogspark-env
shell
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
# 修改如下的配置内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/opt/servers/hadoop-2.9.2
export HADOOP_CONF_DIR==/opt/servers/hadoop-2.9.2/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/opt/servers/hadoop-2.9.2/bin/hadoop classpath)
export SPARK_MASTER_HOST=h121.wzk.icu
export SPARK_MASTER_PORT=7077配置完成截图如下: 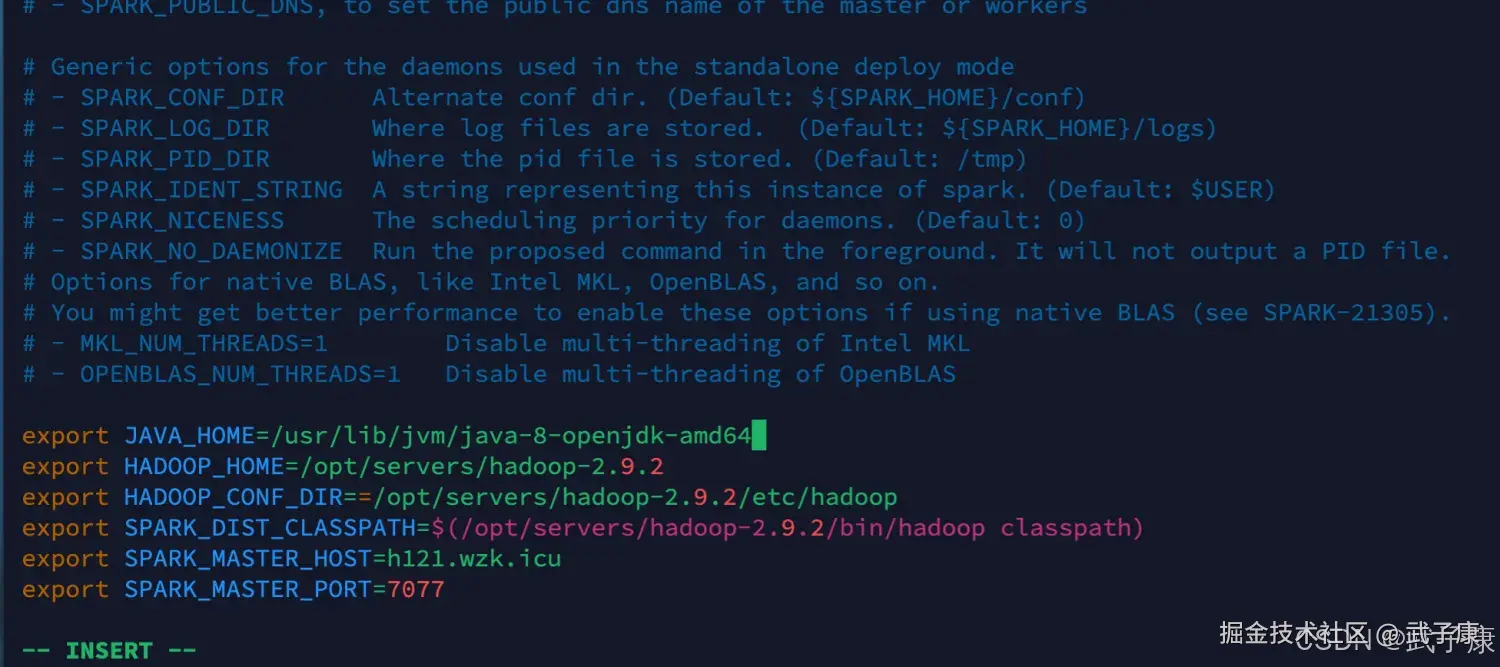
分发软件
传输文件
使用我们之前编写的 rsync-script 工具。当然你也可以每台都配置一次也行,只要保证环境一致即可。 (之前Hadoop等都使用过,如果你没有,你可以用复制或者别的方式)
shell
rsync-script /opt/servers/spark-2.4.5-bin-without-hadoop-scala-2.12过程会很漫长,请耐心等待:  文件传输分发完毕:
文件传输分发完毕: 
环境变量
每天机器都需要配置环境变量!!!
shell
/etc/profileh122 服务器

h123 服务器