背景
Docker是一个开源的应用容器引擎,用于开发、交付和运行应用程序。它允许开发者将应用程序及其所有依赖(如库、配置文件等)打包到一个轻量级、可移植的容器中。这些容器可以在任何支持 Docker 的环境中以相同的方式运行,从而解决了传统部署中环境差异导致的问题。
Docker基本原理
虚拟化技术
为什么需要进行虚拟化?
虚拟化技术诞生之初解决的痛点是资源复用 + 多租户隔离 ,在早期,计算机资源非常昂贵,单用户批处理的任务在计算机中资源的使用率不足10%,为了让昂贵且稀缺 的硬件能被多个科研项目或企业部门共享,开始用软件把一台物理机划分成多台彼此隔离的虚拟机 ,从而解决了两个问题 。
- 提高 CPU、内存等资源的利用率
- 让不同用户的操作系统在同一硬件上并行运行而不互相干扰
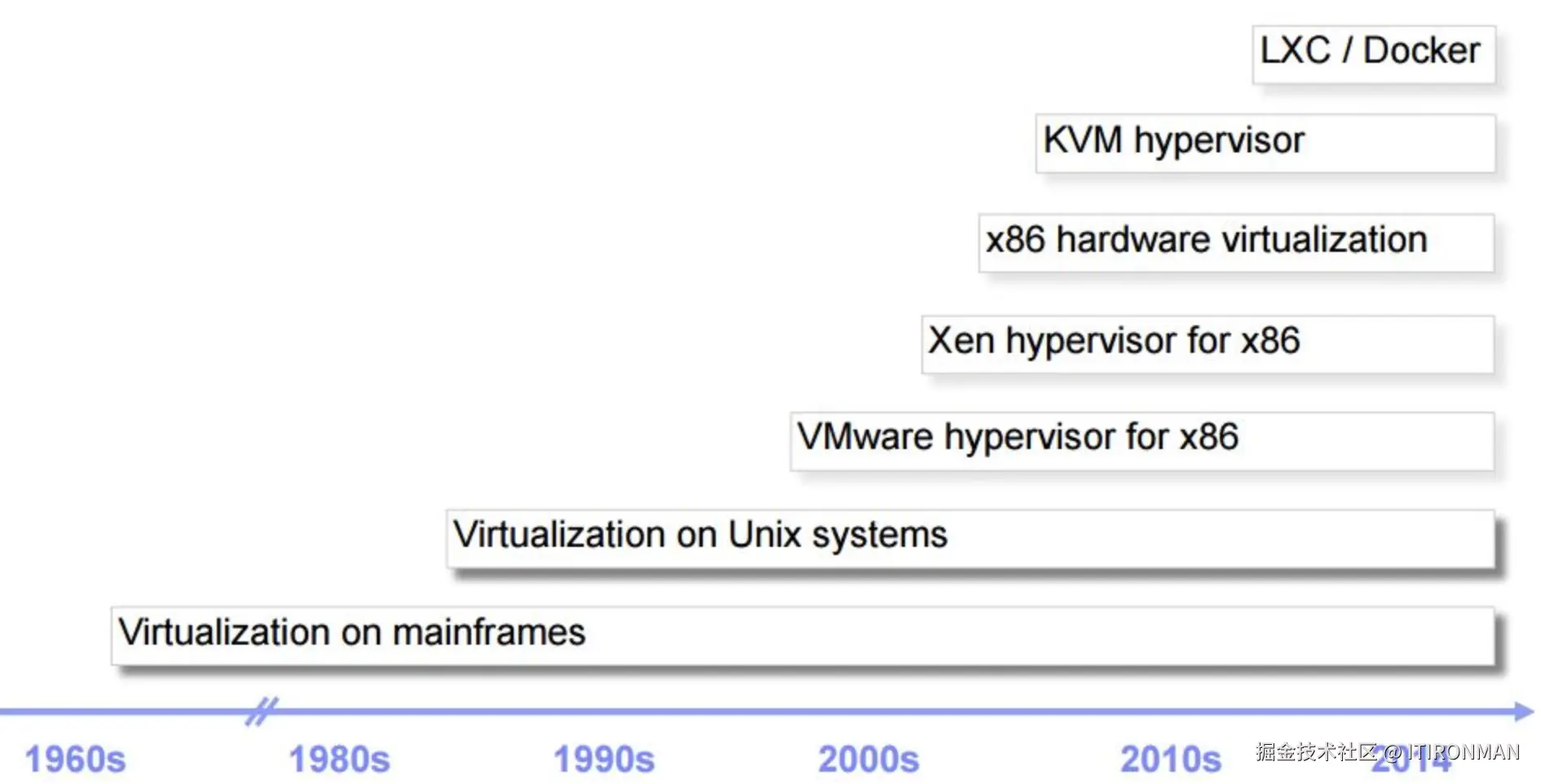
有几种虚拟化技术?
虚拟化技术是一种将计算机物理实体(如服务器、存储设备、网络设备)通过软件技术划分为多个虚拟实体的技术。其原理在于引入一个虚拟化层(虚拟机监控器VMM),将物理硬件与操作系统进行分离,使VMM能够拦截和重定向操作系统对硬件的访问请求,从而实现对物理硬件的共享、抽象和模拟。
- 计算机层次划分
一台计算机,从上层到下层,可以按照下面的方式进行划分:应用程序层、操作系统层、物理硬件层。
暂时无法在飞书文档外展示此内容
- I型虚拟化
VMM意为Virtual Machine Monitor ,虚拟机监控程序,或称为:HyperVisor。
I型虚拟化典型的特点:VMM直接在硬件上面,构建出多个隔离的操作系统环境,如VMware ESXi、Huawei FusionCompute、VMware 5.5 及以后版本、Xen 3.0 及以后版本、Virtual PC 2005、KVM。
- 需要硬件支持
- VMM 作为主操作系统
- 运行效率高
适用场景:数据中心、大规模虚拟化、高性能。
暂时无法在飞书文档外展示此内容
- II型虚拟化
依赖于宿主操作系统,在其上构建出多个隔离的操作系统环境,如VMware 5.5 以前版本、Xen 3.0 以前版、Virtual PC 2004。
- VMM 作为应用程序运行在主操作系统环境内
- 运行效率一般较类型 I 低
适用场景:个人用户、开发者、测试人员。
暂时无法在飞书文档外展示此内容
- KVM(Kernel-based Virtual Machin)虚拟化
KVM 是 Linux 内核中的一个虚拟化模块(Kernel Module,加载后把 Linux 内核变成一个 Hypervisor)。
由 QEMU + KVM 组合提供完整虚拟化:
- KVM 负责利用硬件(Intel VT-x / AMD-V)指令,把 CPU/内存虚拟化出来。
- QEMU 负责 I/O 设备的仿真。
KVM 把 Linux 本身变成了一个 Type-1 Hypervisor,这里的KVM并不属于操作系统,而是运行在硬件之上。
暂时无法在飞书文档外展示此内容
- LXC(Linux Containers,操作系统虚拟化-容器-系统级)
LXC是一种基于Linux内核的用户空间容器化技术。它通过利用Linux内核的命名空间、控制组(Cgroup)和文件系统隔离等特性,实现了轻量级的虚拟化。LXC容器可以在宿主机上运行一个或多个独立的Linux系统,每个容器有自己独立的进程空间、网络空间和文件系统。
暂时无法在飞书文档外展示此内容
-
Docker(操作系统虚拟化-容器-应用级)
-
Docker 属于 操作系统层虚拟化(OS-level Virtualization) ,最初基于LXC,依赖于 Linux 内核的几项关键技术namespace、Cgroups和UnionFS。
Namespaces(命名空间):进程、网络、挂载点、用户/用户组隔离。
cgroups(Control Groups):CPU、内存、设备、IO等资源的限制。
UnionFS / OverlayFS(联合文件系统,写时复制 CoW):把镜像层 + 容器可写层合并成 rootfs,读写高效,启动只需挂载而非安装 OS。
- 暂时无法在飞书文档外展示此内容
- COW(写时复制)
-
COW的目的是什么(Docker镜像为何要分层)?
- 镜像层可读:镜像层是可读的,对于信息的读取,共享的是同一份镜像,多个容器可以共享同一个镜像层(只读层不需要重复拷贝)。
- 容器层可写:启动容器的时候,一个新的可写层加载到镜像顶部,这一层称之为容器层,容器层以下称之为镜像层。
好处:
- 节省存储空间:访问镜像层无需全部复制,直接共享
- 提高启动速度:容器创建时不需要复制整个镜像 → 只需挂载镜像层 + 新建一个空的可写层
- 可复用、可回滚:重复利用+删除回滚
-
Docker网络
| 网络模式 | 配置 | 说明 |
|---|---|---|
| None | -net=none | 容器有独立的network namespace 但并没有对其进行任务网络设置,如分配veth pair 和网桥连接,配置IP等 |
| Container | -net=container:name | 容器和另一个容器共享network namespace,kubernetes 就是多个容器共享一个 network namespace |
| Host | -net=host | 容器和宿主机共享 network namespace |
| Bridge | -net=bridge | 默认模式 |
下面将结合真实的网络环境给大家讲一下虚拟机常用的几种网络模式具体含义还有网络是如何通讯的。
-
网络传输
-
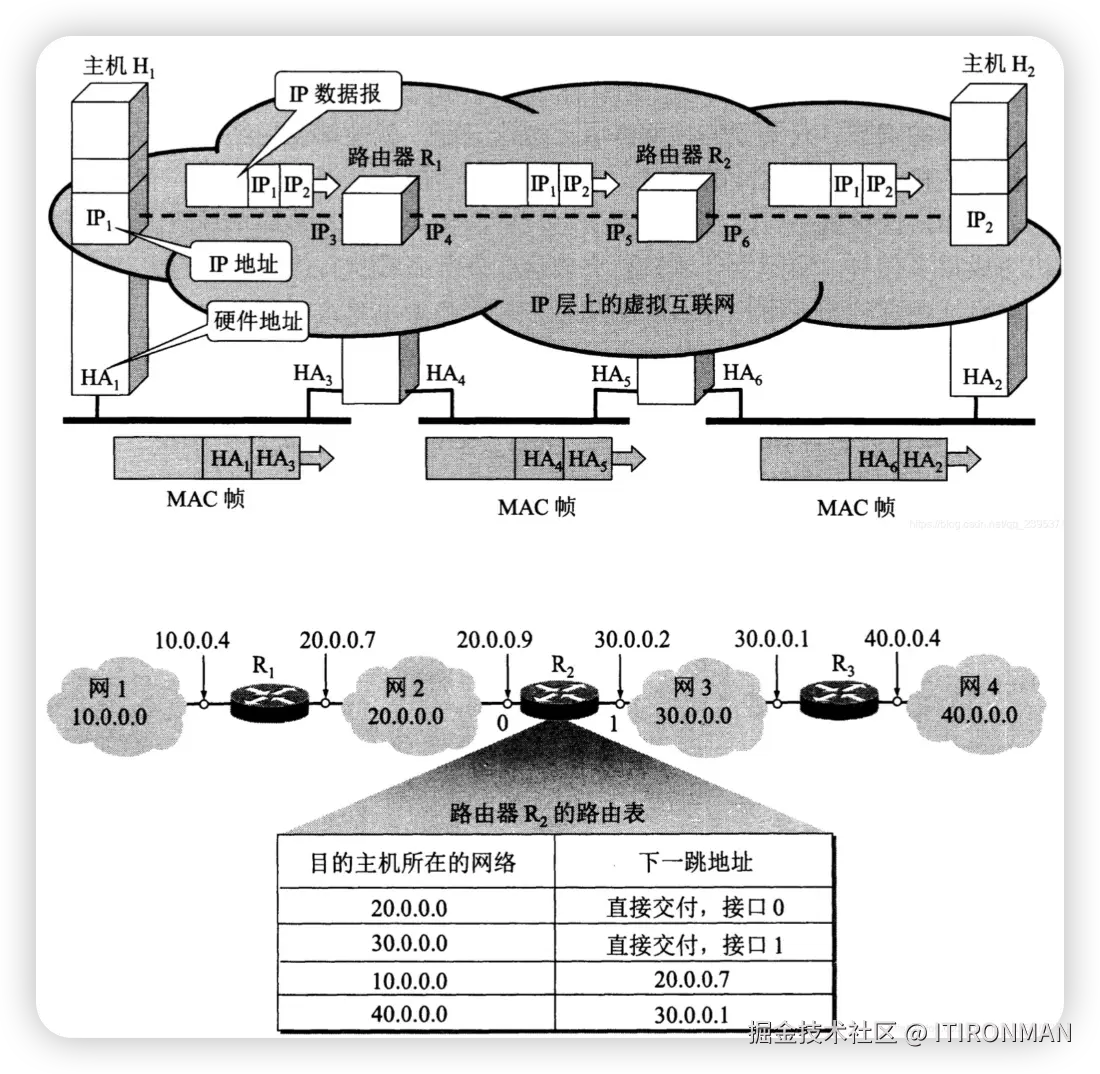
要想真正的理解网络传输,必须知道IP是如何进行寻址的,这里面涉及到IP寻址+路由选择。
-
-
情景1:同网络寻址
-
暂时无法在飞书文档外展示此内容
-
列出寻址场景
主机 IP地址 子网掩码 默认网关 同事A 192.168.1.10 255.255.255.0 192.168.1.1 同事B 192.168.1.20 255.255.255.0 192.168.1.1 -
寻址流程
- step1:判断同事A与同事B是否在同一个网络
-
网络号 = IP地址 & 子网掩码
同事A网络号:192.168.1.10 & 255.255.255.0 → 192.168.1.0
同事B网络号:192.168.1.20 & 255.255.255.0 → 192.168.1.0
同一网络号 → 局域网内直连,不经过网关。
- step2:查询目标MAC地址
-
(1)同事A的电脑通过arp命令查询同事B的IP地址,看看是否能找到其MAC地址,类似如下,假如可以查到mac地址,就可以直接发出信息

(2)假如查不到,就需要同事A的电脑发送ARP广播(谁的IP是1.20啊,把你的MAC地址发我)

(3)通过上述两种情况,查到B的MAC地址或B收到广播直接把MAC地址给了A,就可以直接通讯,具体流程大致如下
-
构造IP数据包和以太网帧
以太网帧头部:
目标MAC: BB-BB-BB-BB-BB-BB
源MAC: AA-AA-AA-AA-AA-AA
类型: IPv4 (0x0800)
数据部分:
IP头部(192.168.1.10 → 192.168.1.20)
TCP/UDP/ICMP 数据 -
发送到LAN网络,交换机根据MAC地址表直接找到同事B的电脑和端口,把这个数据包发过去 3. 同事B在端口处收到数据包,开始解包,从物理层、以太网帧层一直到TCP/IP层逐步解析,拿到数据
(4)此时,同事A和同事B完成了一次通信,同事A和同事B的地址路由表均会新增一条ARP信息,下次通讯就不需要广播
-
-
-
情景2:跨网络寻址
-
暂时无法在飞书文档外展示此内容
-
列出寻址场景
主机 IP地址 子网掩码 默认网关 同事A 192.168.96.47 255.255.248.0 192.168.103.254 同事B 220.181.111.232 未知 未知 -
寻址流程
- step1:判断同事A与同事B是否在同一个网络
-
网络号 = IP地址 & 子网掩码
同事A网络号:192.168.96.47 & 255.255.248.0 → 192.168.96.0 /21
yaml同事A: IP: 11000000 10101000 01100000 00101111 (192.168.96.47) Mask:11111111 11111111 11111000 00000000 (255.255.248.0) --- 按位与: 11000000 10101000 01100000 00000000 --- 转为十进制: 11000000 → 192 10101000 → 168 01100000 → 96 00000000 → 0同事B网络号:220.181.111.232 & 255.255.248.0 → 220.181.104.0 /21
网络号不相等 → 无法直接通讯,同事A需要把数据帧发给网关(路由器),让路由器去寻找同事B到底在哪。
- step2:路由寻址
-
同事A把数据包发送给路由器(192.168.103.254),然后路由器会查询自己的路由表,看看这个地址在哪个网络,如果它找不到,就会把这个地址继续发送给下一跳,继续寻址,如此反复。
arduino192.168.103.254 / 21 dev eth0 220.181.114.0 / 21 dev eth1 default via 220.181.104.0 dev eth1匹配流程:
- 目标 IP =
220.181.111.232 - 不匹配 192.168.103.254/21
- 不匹配 220.181.114.0 /21
- 命中
default(0.0.0.0/0),下一跳 =220.181.104.0
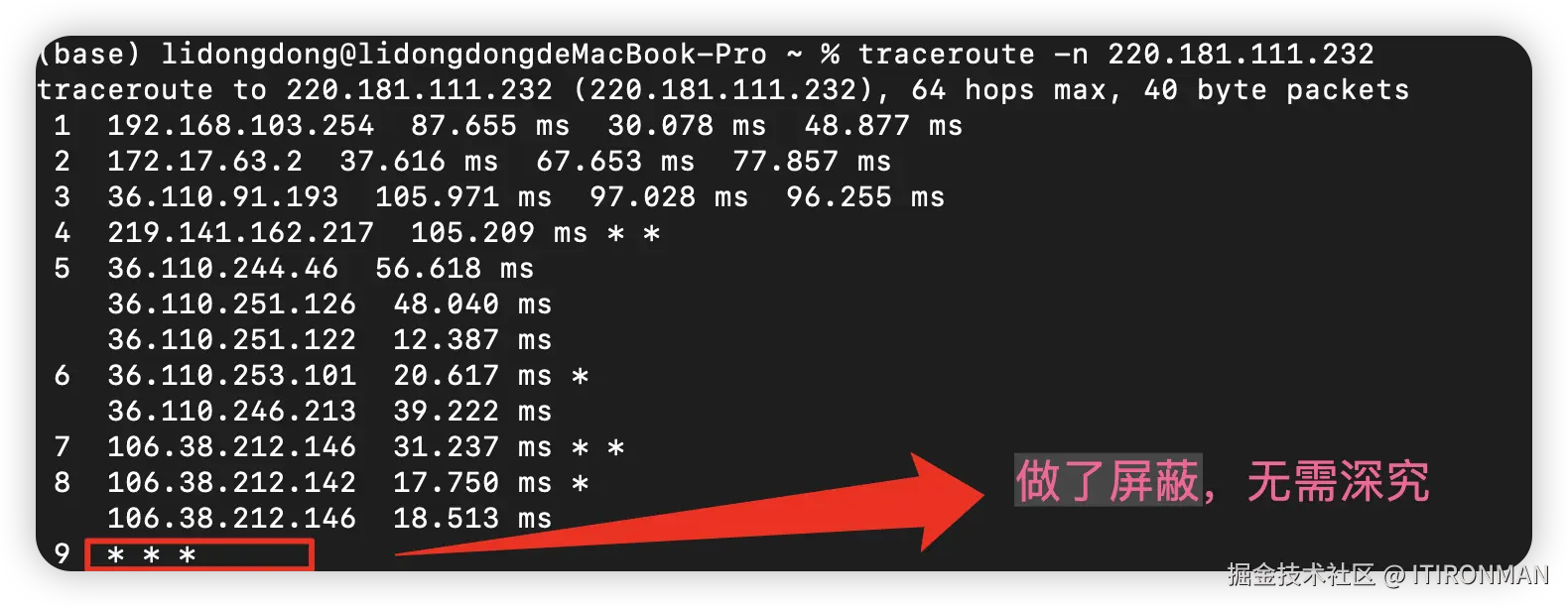
注意:
通过上述命令,可以查看ip的寻址流程,比如第一个就是192.168.103.254 ,第二个就是172.17.63.2,如此反复,直到找到目标地址。
64 hops max表示,如果经历64跳仍找不到,就会丢弃,一般情况下,绝大多数地址30跳就可以找到。
- 目标 IP =
- step3:查询目标MAC地址
-
通过多次路由后找到地址,完成寻址流程,后续通讯就可以在同事A与同事B经过的路由器中都增加了一条路由信息,再次通信就变得容易,后续流程同情景1。
-
下面,挑Docker两个最常见的网络模式Host 和Bridge, 讲一下其原理 。
- Host
容器1 与容器2 共享宿主机IP 和端口的网络,两个容器端口必须不一致。
暂时无法在飞书文档外展示此内容
容器不再有独立的 network namespace。
它直接共享宿主机的 network namespace。
容器里看到的
eth0、lo、IP 地址、路由表 → 全部和宿主机一模一样。
css
docker run -d --name hello-api-3 --network host crccheck/hello-world 
- Bridge
Bridge模式是相对而言较为复杂的一种模式,但是其原理并不复杂,并且很常用。
Docker 内部通信:在linux系统中,严重依赖 iptables 的 NAT 规则
arduino
docker run -d --name hello-api-1 -p 8080:8080 crccheck/hello-world
docker run -d --name hello-api-2 -p 8080:9090 crccheck/hello-world
css
docker inspect hello-api-1 | jq -r '.[0].NetworkSettings.Networks[].IPAddress'
docker inspect hello-api-2 | jq -r '.[0].NetworkSettings.Networks[].IPAddress'
ini
docker network inspect bridge --format='{{(index .IPAM.Config 0).Gateway}}'
sql
ip addr show docker0


暂时无法在飞书文档外展示此内容
在Bridge模式下,容器1和容器2相当于在同一个网络里面,它们通信不需要经过路由,可以直接通信,而宿主机或宿主机外部的信息进来是默认要经过docker0的。

Docker镜像
Docker 镜像是一个只读的文件系统层,可以在宿主机上看到这些层。
linux可以直接进入目录查看:/var/lib/docker/overlay2/
暂时无法在飞书文档外展示此内容
镜像层的数据往往保存在主机上的一个文件,每一层的指针会指向下一层。
bash
/var/lib/docker/graph/e809f156dc985.../jsone809f156dc985...就是这层镜像的id,一个容器的元数据是被分成了很多文件,但或多或少能够在/var/lib/docker/containers/目录下找到,就是一个可读层的id。这个目录下的文件大多是运行时的数据,比如说网络,日志等等。
Docker容器
一个运行态容器(running container)被定义为一个可读写的统一文件系统加上隔离的进程空间和包含其中的进程。
暂时无法在飞书文档外展示此内容
根据上面的图可以看到,容器层创建了一个可读的读写层文件系统,你可以先创建一个运行的容器,然后在运行的容器里面创建一个文件:hello.txt,然后停掉容器,进入宿主机的文件系统,就可以找到这个创建的文件。
Docker核心技术
几个核心问题
- 先有进程还是先有容器?
- docker有自己的操作系统吗?
- docker里面的进程和宿主机的进程有区别吗?
namespace
Linux Namespace (命名空间) 是 Linux 内核提供的一项功能,用于隔离和虚拟化系统资源。它允许我们创建一种"盒子",在这个盒子里的进程看到的系统资源(如进程ID、网络、主机名等)与盒子外的进程看到的是隔离的。这正是容器技术实现隔离的基石。
- 系统可以为进程分配不同的 Namespace。
- 保证不同的 Namespace 资源独立分配、进程彼此隔离,即不同的Namespace 下的进程互不干扰 。
arduino
struct task_struct {
...
/* namespaces */
struct nsproxy *nsproxy;
...
}
arduino
struct nsproxy {
atomic_t count;
struct uts_namespace *uts_ns;
struct ipc_namespace *ipc_ns;
struct mnt_namespace *mnt_ns;
struct pid_namespace *pid_ns_for_children;
struct net *net_ns;
}-
创建流程
- clone
csharp# 在创建新进程的系统调用时,可以通过 flags 参数指定需要新建的 Namespace 类型 // CLONE_NEWCGROUP / CLONE_NEWIPC / CLONE_NEWNET / CLONE_NEWNS /CLONE_NEWPID /CLONE_NEWUSER / CLONE_NEWUTS int clone(int (*fn)(void *), void *child_stack, int flags, void *arg)- setns
csharp# 该系统调用可以让调用进程加入某个已经存在的 Namespace 中 int setns(int fd, int nstype)- unshare
csharp# 该系统调用可以将调用进程移动到新的 Namespace 下 int unshare(int flags) -
隔离类型
java
PID Namespace (进程隔离) :
容器内的进程拥有独立的进程ID空间。容器里的第一个进程(通常是应用的入口程序)的 PID 是 1,它扮演着 init 进程的角色。容器内的进程看不到宿主机上的进程。
Net Namespace (网络隔离) :
每个容器都有自己独立的网络栈,包括网络接口(如 eth0)、IP 地址、路由表、端口号等。这使得我们可以在同一台宿主机上运行多个监听 80 端口的 Web 服务器容器。
Mnt Namespace (挂载点隔离) :
容器拥有独立的文件系统挂载点。容器启动时看到的文件系统是基于镜像构建的,它看不到宿主机的文件系统(除非通过 volume 挂载)。
UTS Namespace (主机名和域名隔离) :
每个容器可以有自己独立的主机名(hostname)和域名(domain name),这让容器在网络上看起来像一台独立的主机。
IPC Namespace (进程间通信隔离) :
容器内的进程间通信(IPC)资源,如信号量、消息队列、共享内存等,是与宿主机和其他容器隔离的。
User Namespace (用户和用户组隔离) :
允许在容器内创建一个非 root 用户,并将其映射到宿主机上的一个普通用户。这样,即使在容器内拥有 root 权限,其在宿主机上对应的也只是一个低权限用户,大大增强了安全性。- 常用操作
sql
[AIHPC集群 dongdong.li01@msxf-hpc-2-142-ai ~]$ lsns -t net
NS TYPE NPROCS PID USER NETNSID NSFS COMMAND
4026531840 net 12 13305 dongdong.li01 unassigned /run/docker/netns/default /bin/sh -l
[AIHPC集群 dongdong.li01@msxf-hpc-2-142-ai ~]$ lsns -t pid
NS TYPE NPROCS PID USER COMMAND
4026531836 pid 12 13305 dongdong.li01 /bin/sh -l- Docker run发生了什么
- 你运行
docker run ...。 - Docker Daemon 接收到请求。
- Docker Daemon 调用
clone()系统调用,并传入上述一组或多组CLONE_NEW*标志位。 - Linux 内核创建一个新进程,并为这个进程创建一套全新的、隔离的 Namespace。
- 这个新进程就是容器里的第一个进程(PID 1)。
- 接着,Docker 会为这个 Namespace 配置网络(创建 veth pair)、挂载文件系统(基于镜像)、设置 cgroups 资源限制等,最终启动容器内的应用程序。
Cgroups
Control Groups(cgroups) :Linux 内核特性,用来对一组进程进行 资源计量、限制、隔离。
提供了层次化的分组机制:你可以把某些进程放到一个"控制组",并对这个组设置:
- CPU(限速/份额/绑核)
- Memory(最大内存、swap、OOM 行为)
- Block I/O(磁盘带宽/IOPS)
- PIDs(最多能启动多少进程)
- Hugepages、网络流量、device 权限 等
Docker(和 containerd/runc)正是通过把容器进程放进特定 cgroup 并写配置文件的方式,来保证容器之间互不抢占资源。
-
实现
- 进程数据结构
arduinostruct task_struct { #ifdef CONFIG_CGROUPS struct css_set __rcu *cgroups; struct list_head cg_list; #endif }- 限制cpu
bash# 创建一个 cgroup 目录 sudo mkdir -p /sys/fs/cgroup/cpu/mygroup # 限制 CPU 时间份额(默认 1024,表示 100%) echo 512 | sudo tee /sys/fs/cgroup/cpu/mygroup/cpu.shares # 启动一个进程(比如 stress 工具压 CPU),然后把 PID 加入 cgroup stress --cpu 2 & # 假设 PID=12345 echo 12345 | sudo tee /sys/fs/cgroup/cpu/mygroup/tasks- 限制内存
bashsudo mkdir -p /sys/fs/cgroup/memory/mygroup # 设置内存限制 100MB echo $((100*1024*1024)) | sudo tee /sys/fs/cgroup/memory/mygroup/memory.limit_in_bytes # 启动进程并加入 cgroup stress --vm 1 --vm-bytes 200M --vm-hang 0 & # PID=12346 echo 12346 | sudo tee /sys/fs/cgroup/memory/mygroup/tasks
Union FS

Union FS (Union File System)
- 一种能把多个不同目录层合并成一个统一挂载点的文件系统。
- 上层文件会覆盖下层同名文件(优先级),实现 分层叠加。
- 可以只读或读写叠加 → 写时复制(Copy-on-Write, CoW) :修改文件时,并不是直接修改下层只读层,而是拷贝到上层可写层再修改。
核心目标:让容器能基于不可变镜像层运行,并且拥有一个隔离的可写层。
-
linux文件系统
- Bootfs(boot file system)
Bootloader - 引导加载 kernel, Kernel - 当 kernel 被加载到内存中后 umount(卸载) bootfs。- rootfs (root file system)
bash/dev,/proc,/bin,/etc 等标准目录和文件。 对于不同的 linux 发行版, bootfs 基本是一致的,但 rootfs 会有差别。 -
启动
-
Linux
- 在启动后,首先将 rootfs 设置为 readonly, 进行一系列检查, 然后将其切换为 "readwrite"供用户使用。
-
Docker 启动
- 初始化时也是将 rootfs 以 readonly 方式加载并检查,然而接下来利用 union mount 的方式将一个readwrite 文件系统挂载在 readonly 的 rootfs 之上;
- 并且允许再次将下层的 FS(file system) 设定为 readonly 并且向上叠加。
- 这样一组 readonly 和一个 writeable 的结构构成一个 container 的运行时态, 每一个 FS 被称作一个 FS层。
-
-
OverlayFS
OverlayFS 是一种与 AUFS 类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的 Overlay 和 更新更稳定的 overlay2。
Overlay 只有两层:upper 层和 lower 层,Lower 层代表镜像层,upper 层代表容器可写层。
upper和lower会一起合并成一个合并层,就是mount指定两个层级,最后会被合并成一个目录。
暂时无法在飞书文档外展示此内容
shell
# mkdir upper lower merged work
# echo "from lower" > lower/in_lower.txt
# echo "from upper" > upper/in_upper.txt
# echo "from lower" > lower/in_both.txt
# echo "from upper" > upper/in_both.txt
# sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
# cd merged/
# ls
in_both.txt in_lower.txt in_upper.txt
# 当有同名文件的时候以上层为主
# cat in_both.txt
from upper
bash
# % docker inspect c998aab42872
"GraphDriver": {
"Data": {
"ID": "c998aab4287227ded8fff81d6f0c84f4ae8b63ea22cd3e46265f2e4bef9ea294",
"LowerDir": "/var/lib/docker/overlay2/cc47c5a4d87208c19718fdaa117a0d3232f89c5ec17442993d132a00523a99ef-init/diff:/var/lib/docker/overlay2/2195c1475b5692e9a2512f38d1f2d68b695556e8e72d48bea16266698eca487b/diff:/var/lib/docker/overlay2/2d8a5b8bcb04469359bfb9595d255882715a79bbc3035df77374e36d6067f52e/diff",
"MergedDir": "/var/lib/docker/overlay2/cc47c5a4d87208c19718fdaa117a0d3232f89c5ec17442993d132a00523a99ef/merged",
"UpperDir": "/var/lib/docker/overlay2/cc47c5a4d87208c19718fdaa117a0d3232f89c5ec17442993d132a00523a99ef/diff",
"WorkDir": "/var/lib/docker/overlay2/cc47c5a4d87208c19718fdaa117a0d3232f89c5ec17442993d132a00523a99ef/work"
},
"Name": "overlay2"
}几个核心问题的答案
- 先有进程还是先有容器?先有进程,只是进程被隔离了,创建进程同时创建各种隔离环境。
- docker有自己的操作系统吗?没有,共享宿主机内核。
- docker里面的进程和宿主机的进程有区别吗?本质上没区别,属于不同用户空间而已
Docker技巧及问题
Docker 中有一些常见的问题是很多人容易遇到的,本节将讲一下docker常见问题及基本技巧。
几个核心问题
- 宿主机目录和容器目录权限有区别吗,谁会影响谁?
- 宿主机用户和容器用户一致吗,是不是容器的用户在宿主机也存在?
目录权限问题
Docker中常见的一类问题是权限问题,最常见的是目录权限,尤其是通过-v进行目录挂载时候的权限。
docker -v命令究竟干了什么?
使用 docker run -v /host/path:/container/path ... 命令时,Docker 在底层其实是利用了 Linux 内核的 mount 系统调用,具体来说是 bind mount (绑定挂载) 。
挂载流程:
-
解析命令:Docker 客户端将命令发送给 Docker 守护进程 (Docker Daemon)。
-
准备容器环境 :Docker 守护进程开始创建容器,这包括创建一系列隔离的命名空间(Namespace),其中最重要的就是 挂载命名空间 (Mount Namespace) 。每个容器都有自己独立的文件系统视图。
-
执行挂载 :在容器的主进程(即
CMD或ENTRYPOINT)启动之前,拥有宿主机 root 权限的 Docker 守护进程会执行一个类似下面的操作:- ```
- mount --bind /host/path /path/to/container/rootfs/container/path
- ```
-
完成挂载 :执行后,在容器的挂载命名空间看来,
/container/path这个目录的内容就是 宿主机/host/path目录的内容。它们不是文件的拷贝,而是像一个"传送门"或"快捷方式"。任何一方对文件的读、写、修改、删除操作,都会实时地、直接地反映在另一方。
- 使用绝对路径+设置好宿主机权限
推荐使用绝对路径、预先创建并设置好宿主目录权限(宿主机目录权限很重要!!! )
例子:
shell# mkdir -p docker-vlm # cd docker-vlm # touch test.txt # cd .. # chmod -R 444 docker-vlm #ls -al |grep docker dr--r--r-- 3 lidongdong staff 96 8 27 18 : 37 docker-vlm
shell# docker run -d --name hello-api-4 -v /Users/lidongdong/docker-vlm:/docker-vlm --network host crccheck/hello-world # docker exec -it hello-api-4 /bin/sh # ls -al |grep docker* dr--r--r-- 3 root root 96 Aug 27 10 : 37 docker-vlm
目录权限注意⚠️
- 宿主机的权限会挂载到容器里面,所以挂载宿主机目录要非常小心 ,不然很容易出现权限不足!
-
目录权限谁权力大
-
假如,我修改上面docker-vlm的权限,容器内和宿主机修改,谁权力大?
-
情况一:先修改宿主机权限
-
shell
# chmod -R 755 docker-vlm #ls -al |grep docker* drwxr-xr-x 3 lidongdong staff 96 8 27 18 : 37 docker-vlmshell# ls -al|grep docker* drwxr-xr-x 3 root root 96 Aug 27 10 : 37 docker-vlm -
- 直接修改宿主机目录权限,被挂载的容器目录权限跟着变了,并且是马上变,都不需要重启!
- 这里隐藏了一个非常危险的信号 :某个超级管理如果突然修改了宿主机上docker挂载的目录权限,你的docker很有可能毫无征兆的服务挂了!
-
情况二:先修改容器权限
bash# chmod -R 444 docker-vlm chmod: docker-vlm: Permission denied-
- 宿主机上建立的目录,容器直接无法修改其权限
- 情况三:容器内建立一个文件
-
宿主机先修改权限:chmod -R 777 docker-vlm
shell# cd docker-vlm/ # touch hello.txt # ls -al -rw-r--r-- 1 root root 0 Aug 27 11 : 10 hello.txtshell# ls -al -rw-r--r-- 1 lidongdong staff 0 8 27 19 : 10 hello.txt-
- 容器内建立的文件会即时映射到宿主机上,且权限与容器内一致,容器内修改权限,宿主机同步变化
- 情况四:宿主机修改容器中建立的文件权限
shell# chmod 444 hello.txt # ls -al -r--r--r-- 1 lidongdong staff 0 Aug 27 11 : 10 hello.txtshell# ls -al -r--r--r-- 1 root root 0 8 27 19 : 10 hello.txt- 总结:
- 从上面的结果看来,宿主机对于目录权限的修改是非常大的,大于容器 ,所以再进行docker -v目录映射的时候一定要非常小心,不然会因为宿主机目录的限制导致容器出现各种各样的权限问题!
- 建议:
-
- 使用绝对路径,避免出现目录映射错误
- 尽量避免随意进行宿主机目录映射,如果要映射,一定要控制好权限
-
用户权限问题
用户权限问题是容器和宿主机权限的问题,然而linux系统并不关心用户名,它只认识UID和GID。
此部分不同系统:macos、linux和windows可能有细微区别,建议大家使用权限更高的linux多做尝试!
前面讲到,宿主机上建立目录后,容器内的权限是受影响的,一个重要的原因就是宿主机和容器内的UID和GID是不一致的,也是不确定的,假如直接把宿主机的UID和GID映射给容器,会发生什么。
- 用户挂载
shell
# 使用 -u 标志,将当前宿主机用户的 UID 和 GID 传递给容器
# docker run -d --name hello-api-5 -v /Users/lidongdong/docker-vlm:/docker-vlm -u "$(id -u):$(id -g)" --network host crccheck/hello-world
shell
# ls -al|grep docker
drwxrwxrwx@ 4 lidongdong staff 128 8 27 19 : 10 docker-vlm
ruby
# docker exec -it hello-api-5 /bin/sh
# ls -al|grep docker*
dr--r--r-- 4 501 20 128 Aug 27 11 : 10 docker-vlm
# whoami
whoami: unknown uid 501
# cat /etc/passwd
root:x:0:0:root:/root:/bin/sh
daemon:x:1:1:daemon:/usr/sbin:/bin/false
bin:x:2:2:bin:/bin:/bin/false
sys:x:3:3:sys:/dev:/bin/false
sync:x:4:100:sync:/bin:/bin/sync
mail:x:8:8:mail:/var/spool/mail:/bin/false
www-data:x:33:33:www-data:/var/www:/bin/false
operator:x:37:37:Operator:/var:/bin/false
nobody:x:65534:65534:nobody:/home:/bin/false注意⚠️
- 直接映射用户UID和GID只是把号码映射进去了,但是容器内不知道这个用户是谁,只显示ID号,passwd里面也没有它
shell
# docker run -d --name hello-api-5 -v /Users/lidongdong/docker-vlm:/docker-vlm -v /etc/passwd:/etc/passwd -u "$(id -u):$(id -g)" --network host crccheck/hello-world
#ls -al|grep docker*
dr--r--r-- 4 501 20 128 Aug 27 12:33 docker-vlm注意⚠️
- macos系统即便是映射进去,还是没有把用户解析出来,此处可以使用linux系统试一试(自行尝试)!
网络通信问题
前面已经讲到了docker中的网络,基本上对于docker网络通信有了一定深度认识,这里讲一个非常难发现、难复现,但是破坏力极强的bug!
假设:同事A在公司内部的docker内部的网络访问同事B(容器1)在公司外部的一个网络,而这两个网络的内网地址网络号均为172.17.0.1。
暂时无法在飞书文档外展示此内容
第一步:容器内进行路由决策
- 容器1的操作系统内核需要决定如何发送这个数据包。
- 它会查看自己的路由表。一个简化的路由表如下:
sql# 在容器1内部执行 route -n Kernel IP routing table Destination Gateway Genmask Flags Metric Ref Use Iface 0.0.0.0 172.17.0.1 0.0.0.0 UG 0 0 0 eth0 172.17.0.0 0.0.0.0 255.255.0.0 U 0 0 0 eth0
- 内核拿到目标IP
172.17.0.9,会用它去匹配路由表。- 它首先匹配到第二条规则
172.17.0.0/16(Genmask 255.255.0.0)。这条规则告诉内核:目标172.17.0.9就在我的本地网络中(同一个广播域) 。- 关键错误点 :由于目标IP在本地网段内,内核不会 将数据包发送给默认网关
172.17.0.1。它认为可以直接通过二层(数据链路层)通信找到对方。第二步:ARP 地址解析
- 为了在二层网络上发送数据,容器1需要知道
172.17.0.9这个IP地址对应的MAC地址。- 于是,容器1会通过它的虚拟网卡
veth0发出一个 ARP 请求 ,广播到它所连接的docker0网桥上。ARP请求的内容是:"谁是172.17.0.9?请告诉我你的MAC地址。 "第三步:ARP 请求失败
这个ARP请求会在
docker0网桥所连接的所有设备中传播。这些设备包括:
- 宿主机上的
docker0接口 (172.17.0.1)- 容器1的
veth0对端- 容器2的
veth1对端然而,真正的"同事B" (
172.17.0.9) 是一台外部物理机或虚拟机 ,他并没有连接 在这个虚拟的docker0网桥上。因此,
docker0网络中的任何设备都不会响应这个ARP请求。容器1在等待一段时间后,收不到ARP应答,ARP解析失败。
第四步:通信失败
- 由于无法解析出目标IP的MAC地址,容器1的内核无法构建完整的数据链路层帧。
- 操作系统向发起请求的应用程序(如
curl)返回一个错误,通常是 "Host Unreachable" (主机不可达) 或连接超时。
核心命令
-
ADD 与 COPY
-
COPY只做一件事:复制 。而ADD会根据源的类型决定是复制 、下载 还是解压。
目的 COPY ADD 推荐用法 场景1:复制本地 ✅ ✅ 强烈推荐 COPY场景2:下载远程文件 ❌ ✅ 用 RUN curl/wget(ADD功能较复杂,不好排错)场景3:解压本地压缩包 ❌ ✅ 可以使用 ADD,这是它的主要优势场景,唯一推荐场景- COPY的坑(此部分可能会因docker版本有差别,请自行尝试! )
-
请你区分:
COPY hello /opt、COPY hello /opt/、COPY hello/ /opt/有何区别。
-
一个口诀:
- 目标要当目录用,就加
/(一定对) - 复制目录:
- 要内容 ⇒
hello/ - 要目录本体 ⇒
hello
| 写法 | 基镜像情况 | hello 是文件 | hello 是目录 |
|---|---|---|---|
| COPY hello /opt | /opt 已存在(目录) | /opt/hello | /opt/hello/... |
| /opt 不存在 | 生成文件 /opt(危险) | 生成目录 /opt,把 hello 的内容直接放进去(没有 hello 这一层) | |
| COPY hello /opt/ | /opt 已存在或不存在 | 始终 /opt/hello | 始终 /opt/hello/...(会多一层 hello) |
| COPY hello/ /opt/ | /opt 已存在或不存在 | ❌ 报错(因为 hello/ 只能是目录) | /opt/...(直接平铺内容,没有 hello 这一层) |
COPY hello /opt ⇒ 语义不确定,可能是文件也可能是目录,容易踩坑
COPY hello /opt/ ⇒ 稳妥,始终复制到目录中,多一层 hello
COPY hello/ /opt/ ⇒ 稳妥,复制目录内容 ,没有额外的 hello 这层
-
Docker Inspect
-
docker inspect用来查看 Docker 对象的详细信息(JSON 格式)。支持的对象:容器(container)、镜像(image)、网络(network)、卷(volume)、节点(swarm node)等。
输出内容非常详细,包括配置参数、运行状态、网络信息、挂载卷、环境变量、元数据等。
- 用法
-
这个命令输出的JSON非常长,一定要过滤使用,下面介绍几个高频小命令。
-
| 用途 | 命令 |
|---|---|
| 查看容器 IP | docker inspect -f '{{range .NetworkSettings.Networks}}{{.IPAddress}}{{end}}' my-container |
| 查看容器挂载卷 | docker inspect -f '{{range .Mounts}}{{.Source}} -> {{.Destination}}{{println}}{{end}}' my-container |
| 查看容器启动命令 | docker inspect -f '{{.Path}} {{.Args}}' my-container |
| 查看镜像 Entrypoint + Cmd | docker inspect -f '{{.Config.Entrypoint}} {{.Config.Cmd}}' my-image |
| 查看容器环境变量 | docker inspect -f '{{range .Config.Env}}{{println .}}{{end}}' my-container |