Java 集合框架(Java Collections Framework)是 Java 中用于存储和操作一组对象的统一架构,它提供了多种数据结构和算法,简化了数据处理操作。
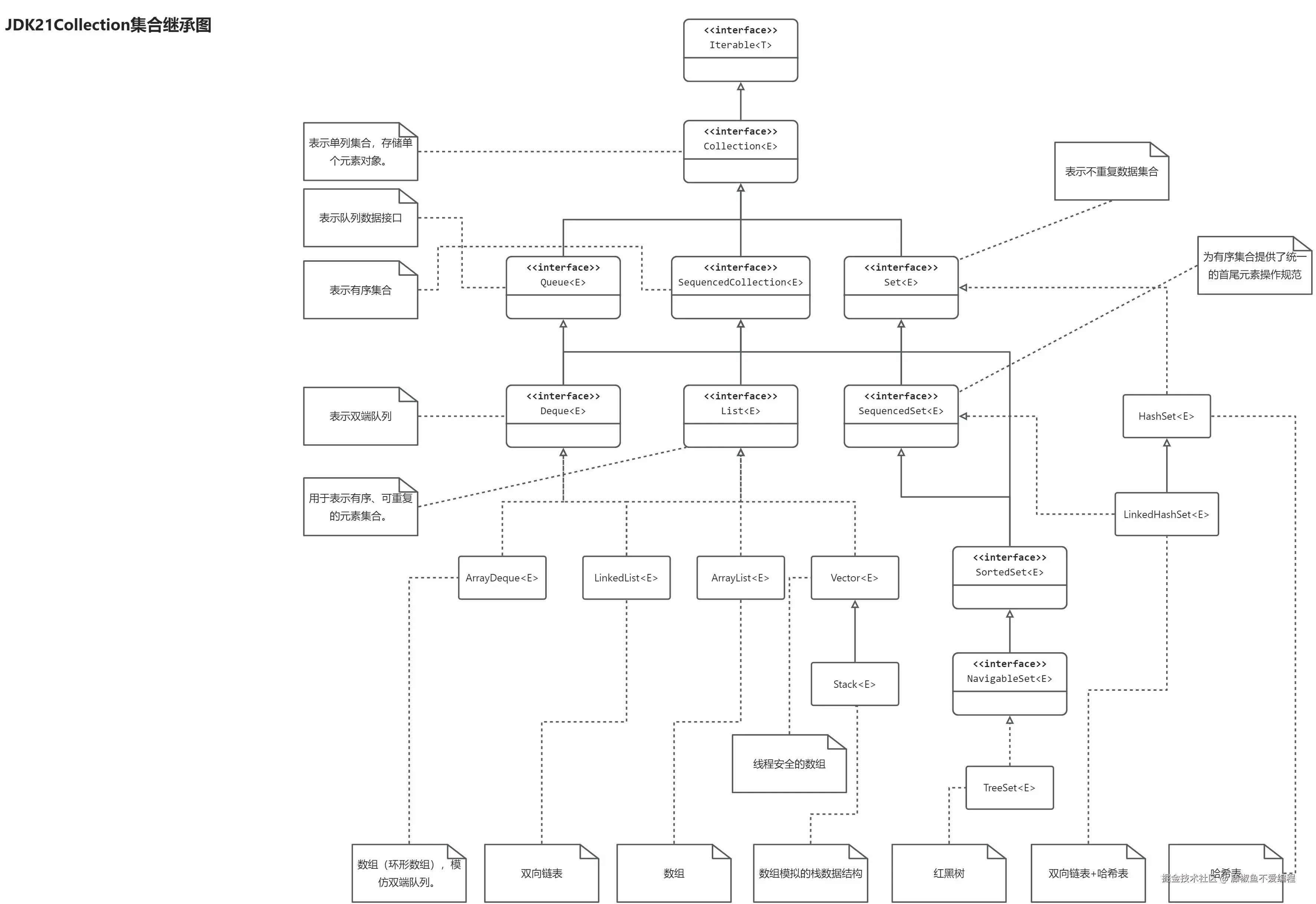
集合框架整体结构
Java 集合框架主要分为两大体系:
Collection接口:存储单个元素的集合(如列表、集合、队列)。
Map接口:存储键值对(key-value)的集合。

Collection 体系核心组件
Java Collection 体系是处理单个元素集合的核心框架,其核心组件围绕Collection接口展开,包含多个子接口及具体实现类。
Collection接口:所有单元素集合的根
Collection是所有单元素集合的根接口,定义了集合操作的通用规范,主要方法包括:
- 添加元素 :
add(E e)(添加成功返回true)、addAll(Collection<? extends E> c)(添加另一个集合的所有元素); - 删除元素 :
remove(Object o)(删除指定元素)、removeAll(Collection<?> c)(删除两个集合的交集元素)、clear()(清空集合); - 查询与判断 :
size()(元素数量)、isEmpty()(是否为空)、contains(Object o)(是否包含指定元素)、containsAll(Collection<?> c)(是否包含另一个集合的所有元素); - 遍历与转换 :
iterator()(返回迭代器)、stream()(返回流对象,支持函数式操作)、toArray()(转换为数组)。
Collection接口本身不直接实例化,而是通过子接口(List、Set、Queue等)的实现类使用。
List 接口:有序可重复集合
List 继承自 Collection,特点是元素有序(插入顺序)、可重复、支持索引访问。
核心扩展方法
- 索引操作:
E get(int index)、E set(int index, E e)、void add(int index, E e)、E remove(int index) - 查找位置:
int indexOf(Object o)、int lastIndexOf(Object o) - 子列表:
List<E> subList(int fromIndex, int toIndex)(返回原集合的视图,修改会影响原集合)
主要实现类及示例
ArrayList:基于动态数组的实现
特性:随机访问快(O (1)),中间插入 / 删除慢(O (n)),初始容量 10,扩容时默认增长 50%(JDK21 优化了扩容策略)。
示例:
java
import java.util.ArrayList;
import java.util.List;
public class ArrayListDemo {
public static void main(String[] args) {
// 创建ArrayList
List<String> fruits = new ArrayList<>();
// 添加元素
fruits.add("Apple");
fruits.add("Banana");
fruits.add(1, "Orange"); // 插入到索引1位置
// 访问元素
System.out.println(fruits.get(0)); // 输出:Apple
// 遍历元素
for (String fruit : fruits) {
System.out.println(fruit);
}
// 修改元素
fruits.set(2, "Grape");
// 删除元素
fruits.remove(0);
// 子列表(视图)
List<String> subList = fruits.subList(0, 2);
System.out.println(subList); // 输出:[Orange, Grape]
}
}LinkedList:基于双向链表的实现
特性:中间插入 / 删除快(O (1)),随机访问慢(O (n)),同时实现了 Queue 接口,可作为队列 / 栈使用。
示例:
java
import java.util.LinkedList;
import java.util.Queue;
public class LinkedListDemo {
public static void main(String[] args) {
// 作为List使用
LinkedList<String> list = new LinkedList<>();
list.add("A");
list.add("B");
list.addFirst("Head"); // 头部插入
list.addLast("Tail"); // 尾部插入
// 作为队列使用(FIFO)
Queue<String> queue = new LinkedList<>();
queue.offer("Task1"); // 入队
queue.offer("Task2");
System.out.println(queue.poll()); // 出队:Task1
// 作为栈使用(LIFO)
LinkedList<String> stack = new LinkedList<>();
stack.push("Item1"); // 入栈
stack.push("Item2");
System.out.println(stack.pop()); // 出栈:Item2
}
}Set 接口:无序不可重复集合
Set 继承自 Collection,特点是元素无序(除非有序实现)、不可重复(通过 equals() 和 hashCode() 判断唯一性)。
核心方法
与 Collection 一致(无索引相关方法),关键是元素必须正确重写 hashCode() 和 equals()。
主要实现类及示例
HashSet:基于 HashMap 的无序去重集合
特性 :查询 / 插入 / 删除效率高(O (1)),元素无序,依赖 hashCode() 和equals()去重。
示例:
java
import java.util.HashSet;
import java.util.Set;
public class HashSetDemo {
static class User {
String name;
int age;
User(String name, int age) {
this.name = name;
this.age = age;
}
// 必须重写hashCode和equals才能正确去重
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return age == user.age && name.equals(user.name);
}
@Override
public int hashCode() {
return 31 * name.hashCode() + age;
}
}
public static void main(String[] args) {
Set<User> users = new HashSet<>();
users.add(new User("Alice", 20));
users.add(new User("Bob", 25));
users.add(new User("Alice", 20)); // 重复元素,不会被添加
System.out.println(users.size()); // 输出:2
}
}LinkedHashSet:保留插入顺序的 Set
特性 :继承 HashSet,通过链表维护插入顺序,迭代效率高于 HashSet。
示例:
java
import java.util.LinkedHashSet;
import java.util.Set;
public class LinkedHashSetDemo {
public static void main(String[] args) {
Set<String> orderedSet = new LinkedHashSet<>();
orderedSet.add("B");
orderedSet.add("A");
orderedSet.add("C");
// 遍历顺序与插入顺序一致
for (String s : orderedSet) {
System.out.println(s); // 输出:B、A、C
}
}
}TreeSet:支持排序的 Set
特性:基于红黑树实现,元素按自然排序(Comparable)或定制排序(Comparator),支持范围查询。
示例:
java
import java.util.Comparator;
import java.util.Set;
import java.util.TreeSet;
public class TreeSetDemo {
public static void main(String[] args) {
// 自然排序(String实现了Comparable)
Set<String> naturalSet = new TreeSet<>();
naturalSet.add("B");
naturalSet.add("A");
System.out.println(naturalSet); // 输出:[A, B]
// 定制排序(按长度倒序)
Set<String> customSet = new TreeSet<>(Comparator.comparingInt(String::length).reversed());
customSet.add("Apple");
customSet.add("Banana");
customSet.add("Grape");
System.out.println(customSet); // 输出:[Banana, Apple, Grape]
}
}Queue 接口:队列(先进先出)
Queue 继承自 Collection,遵循 "先进先出(FIFO)" 原则,支持队列特有操作。
核心方法(区分失败处理方式)
| 操作 | 抛出异常 | 返回特殊值(推荐) |
|---|---|---|
| 插入 | add(E e) |
offer(E e) |
| 移除 | remove() |
poll() |
| 查看 | element() |
peek() |
主要实现类
ArrayDeque:双端队列(高效队列 / 栈)
特性 :基于动态数组,支持两端插入 / 删除,性能优于 LinkedList。
示例:
java
import java.util.ArrayDeque;
import java.util.Deque;
public class ArrayDequeDemo {
public static void main(String[] args) {
Deque<String> deque = new ArrayDeque<>();
// 作为队列(FIFO)
deque.offerLast("First"); // 尾部入队
deque.offerLast("Second");
System.out.println(deque.pollFirst()); // 头部出队:First
// 作为栈(LIFO)
deque.push("Top"); // 头部入栈
deque.push("NewTop");
System.out.println(deque.pop()); // 头部出栈:NewTop
}
}PriorityQueue:优先级队列
特性:基于小顶堆,元素按优先级出队(非 FIFO),默认自然排序。
示例:
java
import java.util.PriorityQueue;
import java.util.Queue;
public class PriorityQueueDemo {
public static void main(String[] args) {
Queue<Integer> pq = new PriorityQueue<>(); // 默认小顶堆
pq.offer(3);
pq.offer(1);
pq.offer(2);
// 每次出队最小元素
while (!pq.isEmpty()) {
System.out.println(pq.poll()); // 输出:1、2、3
}
}
}ConcurrentLinkedQueue:并发安全队列
特性:无锁实现(CAS 操作),适合高并发场景,JDK21 对虚拟线程优化。
示例:
java
import java.util.Queue;
import java.util.concurrent.ConcurrentLinkedQueue;
public class ConcurrentQueueDemo {
public static void main(String[] args) throws InterruptedException {
Queue<String> queue = new ConcurrentLinkedQueue<>();
// 生产者线程
new Thread(() -> {
for (int i = 0; i < 1000; i++) {
queue.offer("Task" + i);
}
}).start();
// 消费者线程
new Thread(() -> {
while (true) {
String task = queue.poll();
if (task != null) {
System.out.println("处理:" + task);
}
}
}).start();
Thread.sleep(1000);
}
}最佳实践
- 选择合适的实现类:
- 读多写少、需索引访问 →
ArrayList - 频繁增删、无需索引 →
LinkedList(或ArrayDeque双端操作) - 去重且无序 →
HashSet - 去重且需顺序 →
LinkedHashSet(插入顺序)或TreeSet(排序) - 队列操作 →
ArrayDeque(高效)或ConcurrentLinkedQueue(并发)
- 读多写少、需索引访问 →
- 重写
**hashCode()**和**equals()**:- 自定义对象作为
Set元素或Map key时,必须同时重写这两个方法,确保逻辑一致。
- 自定义对象作为
- 避免使用古老类:
- 弃用
Vector(线程安全但低效),改用Collections.synchronizedList(new ArrayList<>())或CopyOnWriteArrayList。
- 弃用
- 不可变集合优先:
- 对不需要修改的集合,使用
List.of()、Set.of()创建不可变集合,避免意外修改,提升安全性。
- 对不需要修改的集合,使用
Map 体系核心组件
Java 的Map体系是用于存储键值对(key-value)数据的核心框架,与Collection体系并列但独立(Map不继承Collection)。
Map 接口:键值对集合的根
Map接口定义了键值对集合的通用操作,核心特点是:
- 键(key)唯一:重复插入相同 key 会覆盖旧值
- 值(value)可重复:不同 key 可关联相同 value
**key**** 和**value**均可为****null**(具体实现类可能限制,如TreeMap不允许null key)。
核心方法分类:
| 方法分类 | 核心方法 |
|---|---|
| 添加 / 修改 | V put(K key, V value)(添加或覆盖)、void putAll(Map<? extends K, ? extends V> m) |
| 删除 | V remove(Object key)(删除 key 对应的键值对)、void clear()(清空) |
| 查询 | V get(Object key)(获取 value)、boolean containsKey(Object key)、boolean containsValue(Object value) |
| 视图获取 | Set<K> keySet()(所有 key 的 Set 视图)、Collection<V> values()(所有 value 的 Collection 视图)、Set<Map.Entry<K, V>> entrySet()(所有键值对的 Set 视图) |
| 其他 | int size()、boolean isEmpty() |
注意 :Map.Entry是Map的内部接口,代表一个键值对,提供getKey()、getValue()、setValue(V value)方法。
Map 主要实现类及示例
HashMap:基于哈希表的高效实现(最常用)
底层结构 :JDK8 + 采用 "数组 + 链表 + 红黑树" 混合结构:
- 数组(哈希桶):存储链表 / 红黑树的头节点;
- 链表:哈希冲突时存储相同哈希值的元素;
- 红黑树:当链表长度超过 8 且数组容量≥64 时,链表转为红黑树(优化查询效率)。
特性:
- 线程不安全,效率高;
key允许null(仅一个),value允许null;- 插入 / 查询 / 删除平均时间复杂度 O (1);
- 无序(存储顺序与插入顺序无关)。.
JDK21 优化:优化了红黑树转换逻辑,减少内存占用,提升哈希冲突处理效率。
示例:
java
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class HashMapDemo {
public static void main(String[] args) {
// 创建HashMap
Map<String, Integer> scoreMap = new HashMap<>();
// 添加键值对
scoreMap.put("Alice", 90);
scoreMap.put("Bob", 85);
scoreMap.put("Alice", 95); // 覆盖原有值
// 获取值
System.out.println(scoreMap.get("Bob")); // 输出:85
// 判断是否包含key/value
System.out.println(scoreMap.containsKey("Alice")); // true
System.out.println(scoreMap.containsValue(95)); // true
// 遍历方式1:遍历keySet
Set<String> keys = scoreMap.keySet();
for (String key : keys) {
System.out.println(key + ": " + scoreMap.get(key));
}
// 遍历方式2:遍历entrySet(推荐,效率更高)
for (Map.Entry<String, Integer> entry : scoreMap.entrySet()) {
System.out.println(entry.getKey() + ": " + entry.getValue());
}
// 删除元素
scoreMap.remove("Bob");
System.out.println(scoreMap.size()); // 输出:1
}
}LinkedHashMap:保留插入 / 访问顺序的 Map
特性:
- 继承
HashMap,底层额外维护一条双向链表,记录键值对的顺序; - 支持两种顺序 :
- 插入顺序(默认):按键值对插入的先后排序;
- 访问顺序(
accessOrder=true):访问(get/put)元素后,该元素移至链表尾部(适合实现LRU缓存);
- 性能略低于
**HashMap**(维护链表的额外开销)。
示例:
java
import java.util.LinkedHashMap;
import java.util.Map;
public class LinkedHashMapDemo {
public static void main(String[] args) {
// 1. 插入顺序(默认)
Map<String, String> insertOrderMap = new LinkedHashMap<>();
insertOrderMap.put("b", "B");
insertOrderMap.put("a", "A");
insertOrderMap.put("c", "C");
System.out.println(insertOrderMap.keySet()); // 输出:[b, a, c](插入顺序)
// 2. 访问顺序(accessOrder=true)
Map<String, String> accessOrderMap = new LinkedHashMap<>(16, 0.75f, true);
accessOrderMap.put("1", "One");
accessOrderMap.put("2", "Two");
accessOrderMap.put("3", "Three");
accessOrderMap.get("2"); // 访问"2",移至尾部
System.out.println(accessOrderMap.keySet()); // 输出:[1, 3, 2](访问后顺序变化)
}
}LRU 缓存简易实现(基于访问顺序):
java
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K, V> extends LinkedHashMap<K, V> {
private final int maxSize;
public LRUCache(int maxSize) {
super(16, 0.75f, true); // accessOrder=true
this.maxSize = maxSize;
}
// 当元素数量超过maxSize时,自动删除最久未访问的元素
@Override
protected boolean removeEldestEntry(Map.Entry<K, V> eldest) {
return size() > maxSize;
}
public static void main(String[] args) {
LRUCache<String, String> cache = new LRUCache<>(2);
cache.put("a", "A");
cache.put("b", "B");
cache.get("a"); // 访问"a"
cache.put("c", "C"); // 超过容量,删除最久未访问的"b"
System.out.println(cache.keySet()); // 输出:[a, c]
}
}TreeMap:支持排序的 Map
底层结构:基于红黑树(自平衡二叉查找树)实现,键值对按 key 排序。
特性:
- 线程不安全;
key必须可比较:要么实现Comparable接口(自然排序),要么通过Comparator指定排序规则;key不允许null(排序时会抛NullPointerException);- 插入 / 查询 / 删除时间复杂度 O (log n);
- 支持范围查询(如
subMap()、headMap()、tailMap())。
示例:
java
import java.util.Comparator;
import java.util.Map;
import java.util.TreeMap;
public class TreeMapDemo {
public static void main(String[] args) {
// 1. 自然排序(String实现了Comparable)
Map<String, Integer> naturalMap = new TreeMap<>();
naturalMap.put("b", 2);
naturalMap.put("a", 1);
naturalMap.put("c", 3);
System.out.println(naturalMap.keySet()); // 输出:[a, b, c](自然排序)
// 2. 定制排序(按key长度倒序)
Map<String, Integer> customMap = new TreeMap<>(
Comparator.comparingInt(String::length).reversed()
);
customMap.put("apple", 5);
customMap.put("banana", 6);
customMap.put("grape", 5);
System.out.println(customMap.keySet()); // 输出:[banana, apple, grape]
// 3. 范围查询
Map<String, Integer> rangeMap = new TreeMap<>();
rangeMap.put("a", 1);
rangeMap.put("b", 2);
rangeMap.put("c", 3);
rangeMap.put("d", 4);
// 获取key >= "b" 且 < "d" 的子Map
Map<String, Integer> subMap = rangeMap.subMap("b", "d");
System.out.println(subMap); // 输出:{b=2, c=3}
}
}ConcurrentHashMap:线程安全的高效 Map
特性:
- 线程安全,适合高并发场景;
JDK8 +摒弃了JDK7的分段锁,采用 "CAS+ synchronized" 实现细粒度锁,减少锁竞争;- 支持并发读写,读操作无锁(弱一致性);
key和value不允许null(避免与get方法返回null的歧义);
JDK21 优化:适配虚拟线程,减少大量线程并发时的性能损耗。
示例:
java
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapDemo {
public static void main(String[] args) throws InterruptedException {
Map<String, Integer> concurrentMap = new ConcurrentHashMap<>();
// 多线程并发写入
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
concurrentMap.put(Thread.currentThread().getName() + i, i);
}
};
Thread t1 = new Thread(task);
Thread t2 = new Thread(task);
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println("总元素数:" + concurrentMap.size()); // 输出:2000(无并发问题)
}
}其他实现类
Hashtable:古老的线程安全实现,方法全加synchronized(性能差),已被ConcurrentHashMap替代;EnumMap:key为枚举类型的专用Map,底层基于数组,效率极高,适合枚举键场景;WeakHashMap:key为弱引用,当key不再被外部强引用时,会被GC回收,适合缓存场景(如临时数据缓存)。
Map 体系最佳实践
- 选择合适的实现类 :
- 通用场景(无序、高效)→
HashMap; - 需要顺序(插入 / 访问)→
LinkedHashMap; - 需要排序或范围查询 →
TreeMap; - 高并发场景 →
ConcurrentHashMap; - 枚举 key →
EnumMap。
- 通用场景(无序、高效)→
- 正确重写
**hashCode()**和**equals()**:- 当自定义对象作为 key 时,必须同时重写这两个方法,确保:
- 相等的对象必须有相等的哈希码;
- 哈希码相等的对象不一定相等(减少冲突)。
- 当自定义对象作为 key 时,必须同时重写这两个方法,确保:
- 遍历方式选择:
- 优先使用
entrySet()遍历(一次获取key和value,效率高于keySet()+get()); - 如需只遍历
value,使用values()视图。
- 优先使用
- 初始容量与负载因子 :
HashMap默认初始容量 16,负载因子 0.75(当元素数超过容量 × 负载因子时扩容);- 预估数据量时,可指定初始容量(如
new HashMap<>(1000)),减少扩容次数。
- 避免使用
**null key/value**(特定场景除外) :ConcurrentHashMap和TreeMap不允许null key/value;HashMap允许,但可能导致逻辑错误(如get(null)无法区分key不存在还是value 为null)。
- 不可变
**Map**优先:- JDK9 + 提供
Map.of()、Map.ofEntries()创建不可变Map,线程安全且性能好:
- JDK9 + 提供
java
Map<String, Integer> immutableMap = Map.of("a", 1, "b", 2);