镜像队列:
镜像队列是RabbitMQ最经典的高可用方案 ,确保队列数据在多个节点间复制,实现真正的队列级高可用
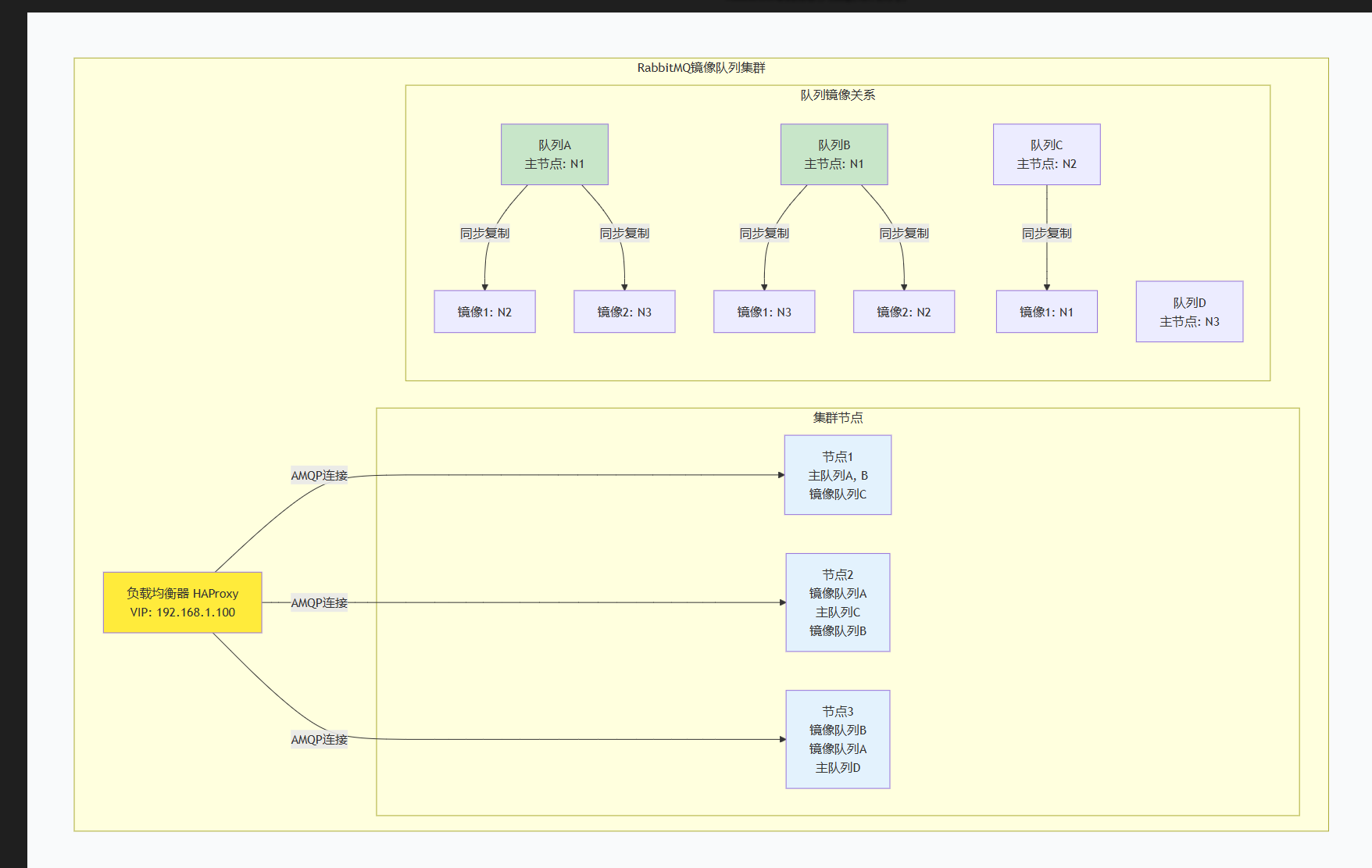
一、镜像队列核心原理
三种镜像模式对比
| 模式 | 配置示例 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| exactly (精确数量) | ha-mode: exactly ha-params: 3 |
控制精确的副本数 | 需要指定数字 | 明确需要N副本的场景 |
| all (所有节点) | ha-mode: all |
最大可用性 | 资源消耗大 | 小型集群,最高可用性要求 |
| nodes (指定节点) | ha-mode: nodes ha-params: ["rabbit@node1", "rabbit@node3"] |
灵活控制位置 | 配置复杂 | 特定节点有更强硬件 |
镜像队列的特性
-
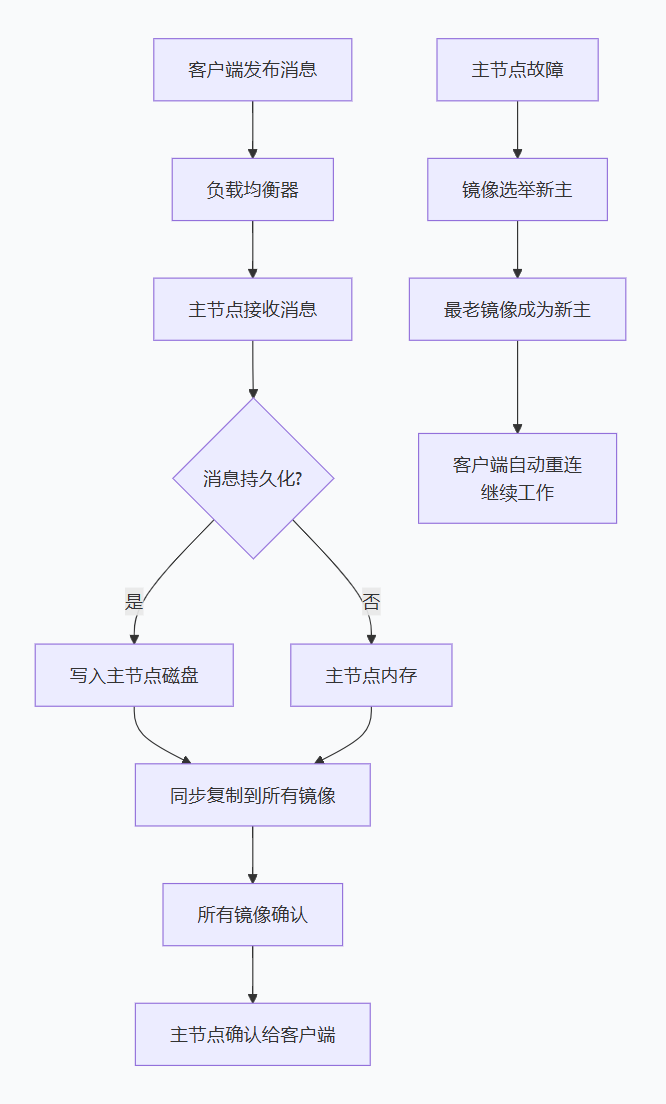
同步复制:消息写入主队列后,同步复制到所有镜像
-
自动故障转移:主节点故障时,最老的镜像自动成为新主节点
-
客户端透明:客户端无需感知镜像存在
-
选举机制:基于镜像加入时间选择新主节点
镜像队列工作流程
二、CentOS 7部署实战(3节点集群)
1. 环境规划与准备
节点规划表:
| 节点 | IP地址 | 主机名 | 角色 | 硬件建议 | 数据目录 |
|---|---|---|---|---|---|
| mq-node1 | 192.168.1.101 | mq-node1 | 磁盘节点 | 8-16GB RAM, 200GB SSD | /data/rabbitmq |
| mq-node2 | 192.168.1.102 | mq-node2 | 磁盘节点 | 8-16GB RAM, 200GB SSD | /data/rabbitmq |
| mq-node3 | 192.168.1.103 | mq-node3 | 磁盘节点 | 8-16GB RAM, 200GB SSD | /data/rabbitmq |
在所有节点执行:
#!/bin/bash
setup_rabbitmq_node.sh - 初始化每个节点
1. 设置主机名和hosts(以mq-node1为例)
NODE_NAME="mq-node1" # 每台机器修改此处
sudo hostnamectl set-hostname ${NODE_NAME}
编辑hosts文件
sudo tee -a /etc/hosts << EOF
192.168.1.101 mq-node1
192.168.1.102 mq-node2
192.168.1.103 mq-node3
EOF
2. 创建数据目录
sudo mkdir -p /data/rabbitmq
sudo chown -R rabbitmq:rabbitmq /data/rabbitmq
sudo chmod 755 /data/rabbitmq
3. 安装Erlang和RabbitMQ
添加RabbitMQ仓库
sudo tee /etc/yum.repos.d/rabbitmq.repo << 'EOF'
rabbitmq_erlang
name=rabbitmq_erlang
baseurl=https://packagecloud.io/rabbitmq/erlang/el/7/$basearch
repo_gpgcheck=1
gpgcheck=1
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/erlang/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
rabbitmq_server
name=rabbitmq_server
baseurl=https://packagecloud.io/rabbitmq/rabbitmq-server/el/7/$basearch
repo_gpgcheck=1
gpgcheck=0
enabled=1
gpgkey=https://packagecloud.io/rabbitmq/rabbitmq-server/gpgkey
sslverify=1
sslcacert=/etc/pki/tls/certs/ca-bundle.crt
EOF
安装
sudo yum install -y erlang-25.3.2.6-1.el7
sudo yum install -y rabbitmq-server-3.12.12-1.el7
4. 配置Erlang Cookie(关键步骤!)
先在mq-node1生成cookie,然后复制到其他节点
if "$NODE_NAME" = "mq-node1" ; then
生成随机cookie(仅在node1执行)
RANDOM_COOKIE=$(openssl rand -hex 32)
echo $RANDOM_COOKIE | sudo tee /var/lib/rabbitmq/.erlang.cookie
else
在其他节点,需要从mq-node1复制cookie值
echo "请从mq-node1复制.erlang.cookie内容到本节点"
echo "scp mq-node1:/var/lib/rabbitmq/.erlang.cookie /var/lib/rabbitmq/"
fi
设置cookie权限
sudo chown rabbitmq:rabbitmq /var/lib/rabbitmq/.erlang.cookie
sudo chmod 400 /var/lib/rabbitmq/.erlang.cookie
5. 防火墙配置
sudo firewall-cmd --permanent --add-port={4369,5672,15672,25672,35672-35682}/tcp
sudo firewall-cmd --reload
2. 基础集群搭建
步骤1:启动第一个节点(mq-node1)
mq-node1上执行
sudo systemctl start rabbitmq-server
sudo systemctl enable rabbitmq-server
启用管理插件
sudo rabbitmq-plugins enable rabbitmq_management rabbitmq_management_agent
创建管理用户
sudo rabbitmqctl add_user admin Admin@Secure123
sudo rabbitmqctl set_user_tags admin administrator
sudo rabbitmqctl set_permissions -p / admin ".*" ".*" ".*"
删除默认guest用户
sudo rabbitmqctl delete_user guest
步骤2:其他节点加入集群
在mq-node2上执行
sudo systemctl stop rabbitmq-server
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset # 注意:新节点可用,生产环境已有数据要小心!
sudo rabbitmqctl join_cluster rabbit@mq-node1
sudo rabbitmqctl start_app
sudo systemctl start rabbitmq-server
在mq-node3上执行(与mq-node2相同,修改主机名即可)
sudo systemctl stop rabbitmq-server
sudo rabbitmqctl stop_app
sudo rabbitmqctl reset
sudo rabbitmqctl join_cluster rabbit@mq-node1
sudo rabbitmqctl start_app
sudo systemctl start rabbitmq-server
步骤3:验证集群状态
在任何节点执行
sudo rabbitmqctl cluster_status
期望输出应显示三个节点都在running_nodes中
检查所有节点是否都是磁盘节点
sudo rabbitmqctl cluster_status | grep disc
3. 配置镜像队列策略
策略1:精确副本策略(推荐生产使用)
在任何节点执行,配置所有队列保持2个副本(1主1镜像)
sudo rabbitmqctl set_policy ha-two "^" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}' \
--apply-to queues
查看已设置的策略
sudo rabbitmqctl list_policies
策略2:节点指定策略
指定队列只在mq-node1和mq-node3上镜像
sudo rabbitmqctl set_policy ha-nodes "^important\." \
'{"ha-mode":"nodes","ha-params":"rabbit@mq-node1","rabbit@mq-node3","ha-sync-mode":"automatic"}' \
--apply-to queues
策略3:正则匹配策略
不同队列类型使用不同策略
高优先级队列:3副本
sudo rabbitmqctl set_policy ha-high "^high\." \
'{"ha-mode":"exactly","ha-params":3,"ha-sync-mode":"automatic"}' \
--apply-to queues
普通队列:2副本
sudo rabbitmqctl set_policy ha-normal "^normal\." \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic"}' \
--apply-to queues
低优先级队列:无镜像
sudo rabbitmqctl clear_policy ha-low "^low\."
4. 高级配置优化
创建优化配置文件:
sudo tee /etc/rabbitmq/rabbitmq.conf << 'EOF'
集群配置
cluster_formation.peer_discovery_backend = rabbit_peer_discovery_classic_config
cluster_formation.classic_config.nodes.1 = rabbit@mq-node1
cluster_formation.classic_config.nodes.2 = rabbit@mq-node2
cluster_formation.classic_config.nodes.3 = rabbit@mq-node3
内存和磁盘设置
vm_memory_high_watermark.relative = 0.7
vm_memory_high_watermark_paging_ratio = 0.5
disk_free_limit.absolute = 5GB
total_memory_available_override_value = 8GB
网络优化
tcp_listen_options.nodelay = true
tcp_listen_options.linger.on = true
tcp_listen_options.linger.timeout = 0
heartbeat = 60
frame_max = 131072
channel_max = 2047
镜像队列优化
ha_promote_on_shutdown = always
ha_promote_on_failure = always
queue_master_locator = min-masters
流控设置
collect_statistics_interval = 5000
management_db_cache_multiplier = 10
日志配置
log.dir = /var/log/rabbitmq
log.file.level = info
log.file.rotation.date = $D0
log.file.rotation.size = 10485760
EOF
重启所有节点使配置生效
sudo systemctl restart rabbitmq-server
5. HAProxy负载均衡配置
安装配置HAProxy:
# 在单独的负载均衡服务器或其中一个节点上安装
sudo yum install -y haproxy
配置HAProxy
sudo tee /etc/haproxy/haproxy.cfg << 'EOF'
global
log /dev/log local0
maxconn 5000
user haproxy
group haproxy
daemon
stats socket /var/run/haproxy.sock mode 660 level admin
tune.ssl.default-dh-param 2048
defaults
log global
mode tcp
option tcplog
option dontlognull
retries 3
timeout connect 5s
timeout client 50s
timeout server 50s
timeout check 10s
健康检查前端
frontend health_check
bind *:8888
mode http
monitor-uri /health
stats enable
stats uri /stats
stats realm HAProxy\ Statistics
stats auth admin:Admin123
RabbitMQ AMQP负载均衡
listen rabbitmq_cluster_amqp
bind *:5670
mode tcp
balance leastconn
option tcp-check
tcp-check connect port 5672 ssl
tcp-check send "PING\r\n"
tcp-check expect string "AMQP"
server mq-node1 192.168.1.101:5672 check inter 2s rise 2 fall 3 weight 1
server mq-node2 192.168.1.102:5672 check inter 2s rise 2 fall 3 weight 1
server mq-node3 192.168.1.103:5672 check inter 2s rise 2 fall 3 weight 1
RabbitMQ管理界面负载均衡
listen rabbitmq_cluster_http
bind *:15670
mode http
balance roundrobin
option httpchk GET /api/health/checks/alarms
server mq-node1 192.168.1.101:15672 check inter 5s rise 2 fall 3
server mq-node2 192.168.1.102:15672 check inter 5s rise 2 fall 3
server mq-node3 192.168.1.103:15672 check inter 5s rise 2 fall 3
EOF
启动HAProxy
sudo systemctl start haproxy
sudo systemctl enable haproxy
6. 客户端连接示例
Python客户端配置:
mirror_queue_client.py
import pika
import logging
import time
from retry import retry
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(name)
class RabbitMQMirrorClient:
def init(self):
HAProxy负载均衡地址
self.hosts = [
{'host': '192.168.1.100', 'port': 5670}, # HAProxy VIP
]
备用直连节点
self.backup_hosts = [
{'host': '192.168.1.101', 'port': 5672},
{'host': '192.168.1.102', 'port': 5672},
{'host': '192.168.1.103', 'port': 5672}
]
@retry(tries=3, delay=2, backoff=2)
def connect(self):
"""连接RabbitMQ集群"""
credentials = pika.PlainCredentials('app_user', 'AppPassword456!')
for host_info in self.hosts + self.backup_hosts:
try:
parameters = pika.ConnectionParameters(
host=host_info'host',
port=host_info'port',
credentials=credentials,
heartbeat=600,
blocked_connection_timeout=300,
connection_attempts=3,
retry_delay=3
)
connection = pika.BlockingConnection(parameters)
logger.info(f"成功连接到 {host_info'host'}:{host_info'port'}")
return connection
except Exception as e:
logger.warning(f"连接 {host_info'host'}:{host_info'port'} 失败: {e}")
continue
raise Exception("无法连接到任何RabbitMQ节点")
def create_mirrored_queue(self, queue_name):
"""创建镜像队列"""
connection = self.connect()
channel = connection.channel()
声明队列时设置镜像队列参数
channel.queue_declare(
queue=queue_name,
durable=True, # 持久化
arguments={
'x-ha-policy': 'all', # 镜像策略
'x-message-ttl': 3600000 # 消息TTL 1小时
}
)
logger.info(f"镜像队列 '{queue_name}' 创建成功")
return channel
def publish_message(self, queue_name, message):
"""发布消息到镜像队列"""
channel = self.create_mirrored_queue(queue_name)
channel.basic_publish(
exchange='',
routing_key=queue_name,
body=message,
properties=pika.BasicProperties(
delivery_mode=2, # 持久化消息
content_type='application/json'
)
)
logger.info(f"消息已发布到队列 '{queue_name}': {message:50}...")
channel.connection.close()
使用示例
if name == "main":
client = RabbitMQMirrorClient()
测试队列
test_queues = [
"order.payment.high",
"user.notification.normal",
"log.collection.low"
]
for queue in test_queues:
client.publish_message(queue, f'Test message for {queue}')
7. 监控与维护脚本
集群健康监控脚本:
#!/bin/bash
/usr/local/bin/monitor_mirror_cluster.sh
NODES=("mq-node1" "mq-node2" "mq-node3")
LOG_FILE="/var/log/rabbitmq_mirror_monitor.log"
ALERT_EMAIL="admin@example.com"
ALERT_THRESHOLD=1000 # 队列积压阈值
echo "=== 镜像队列集群监控报告 (date) ===" \| tee -a LOG_FILE
check_node_health() {
local node=$1
local status
检查服务状态
if ssh "$node" "systemctl is-active rabbitmq-server" | grep -q "active"; then
echo "✅ 节点 node: 服务运行正常" \| tee -a LOG_FILE
检查节点是否在集群中
if ssh "$node" "rabbitmqctl cluster_status 2>/dev/null" | grep -q "running_nodes"; then
echo " 集群状态: 正常" | tee -a $LOG_FILE
检查镜像队列状态
local mirror_status=(ssh "node" "rabbitmqctl list_queues name policy pid slave_pids 2>/dev/null | grep -v '^Listing'")
echo " 镜像队列状态:" | tee -a $LOG_FILE
echo "$mirror_status" | while read line; do
if -n "$line" ; then
echo " line" \| tee -a LOG_FILE
fi
done
检查积压消息
local backlog=(ssh "node" "rabbitmqctl list_queues name messages messages_ready 2>/dev/null | awk 'NR>1 {sum+=\$2} END {print sum}'")
if "$backlog" -gt "$ALERT_THRESHOLD" ; then
echo " ⚠️ 警告: 队列积压 backlog 条消息,超过阈值 ALERT_THRESHOLD" | tee -a $LOG_FILE
发送告警
echo "节点 node 队列积压 backlog 条消息" | mail -s "RabbitMQ告警" "$ALERT_EMAIL"
fi
else
echo " ❌ 集群状态: 异常" | tee -a $LOG_FILE
fi
检查磁盘空间
local disk_free=(ssh "node" "df -h /data/rabbitmq | awk 'NR==2 {print \$4}'")
echo " 磁盘空间: disk_free 可用" \| tee -a LOG_FILE
检查内存使用
local mem_usage=(ssh "node" "rabbitmqctl status 2>/dev/null | grep -A5 'memory' | grep 'used' | awk '{print \$2}'")
echo " 内存使用: mem_usage" \| tee -a LOG_FILE
else
echo "❌ 节点 node: 服务异常" \| tee -a LOG_FILE
echo "节点 node RabbitMQ服务停止" \| mail -s "RabbitMQ节点故障" "ALERT_EMAIL"
fi
echo "---" | tee -a $LOG_FILE
}
检查所有节点
for node in "${NODES@}"; do
check_node_health "$node"
done
检查镜像同步状态
echo "=== 镜像同步状态检查 ===" | tee -a $LOG_FILE
for node in "${NODES@}"; do
echo "检查节点 node 的同步状态:" \| tee -a LOG_FILE
ssh "node" "rabbitmqctl list_queues name messages messages_unacknowledged messages_ready 2\>/dev/null" \| tee -a LOG_FILE
echo "" | tee -a $LOG_FILE
done
镜像队列维护脚本:
#!/bin/bash
/usr/local/bin/maintain_mirror_queues.sh
1. 手动触发镜像同步
force_sync_queues() {
echo "强制同步所有队列..."
sudo rabbitmqctl list_queues name pid --quiet | while read queue_info; do
queue_name=(echo queue_info | awk '{print $1}')
echo "同步队列: $queue_name"
sudo rabbitmqctl sync_queue "$queue_name"
done
}
2. 重新平衡队列主节点
rebalance_masters() {
echo "重新平衡队列主节点..."
获取节点上的队列主节点分布
echo "当前主节点分布:"
sudo rabbitmqctl list_queues name pid --quiet | awk '{print $2}' | sort | uniq -c | sort -rn
设置队列主节点定位策略为最小主节点数
sudo rabbitmqctl set_policy queue-master-balance "^" \
'{"queue-master-locator":"min-masters"}' \
--apply-to queues
echo "已启用最小主节点数策略,新队列将自动平衡"
}
3. 检查并修复孤立镜像
check_orphaned_mirrors() {
echo "检查孤立镜像..."
获取所有队列的镜像信息
sudo rabbitmqctl list_queues name pid slave_pids --quiet | while read line; do
queue=(echo line | awk '{print $1}')
master=(echo line | awk '{print $2}')
slaves=(echo line | awk '{print $3}' | tr ',' '\n')
for slave in $slaves; do
检查镜像节点是否在集群中
if ! sudo rabbitmqctl cluster_status | grep -q "$slave"; then
echo "⚠️ 队列 'queue' 有孤立镜像在节点 slave"
echo " 建议: rabbitmqctl forget_cluster_node $slave"
fi
done
done
}
主菜单
echo "镜像队列维护工具"
echo "1. 强制同步所有队列"
echo "2. 重新平衡主节点"
echo "3. 检查孤立镜像"
echo "4. 查看队列统计"
read -p "请选择操作 (1-4): " choice
case $choice in
-
force_sync_queues ;;
-
rebalance_masters ;;
-
check_orphaned_mirrors ;;
-
sudo rabbitmqctl list_queues name messages messages_ready messages_unacknowledged consumers ;;
*) echo "无效选择" ;;
esac
8. 故障处理指南
常见故障处理表:
| 故障现象 | 可能原因 | 解决方案 |
|---|---|---|
| 镜像不同步 | 网络延迟、节点负载高 | 1. 检查网络连通性 2. 调整ha-sync-batch-size 3. 手动同步队列 |
| 主节点选举失败 | 节点间时间不同步 | 1. 配置NTP时间同步 2. 检查Erlang Cookie一致性 |
| 队列无法创建 | 磁盘空间不足 | 1. 清理磁盘空间 2. 调整disk_free_limit |
| 镜像节点丢失 | 节点宕机 | 1. 恢复宕机节点 2. 从集群移除故障节点 3. 重新加入集群 |
| 同步速度慢 | 大消息积压 | 1. 分批同步 2. 增加ha-sync-batch-size 3. 临时关闭同步 |
故障恢复命令示例:
1. 强制同步特定队列
sudo rabbitmqctl sync_queue "order.payment.high"
2. 从集群移除故障节点
sudo rabbitmqctl forget_cluster_node rabbit@故障节点名
3. 重新加入集群
sudo rabbitmqctl stop_app
sudo rabbitmqctl join_cluster rabbit@健康节点
sudo rabbitmqctl start_app
4. 修改同步批处理大小
sudo rabbitmqctl set_policy ha-sync "^" \
'{"ha-mode":"exactly","ha-params":2,"ha-sync-mode":"automatic","ha-sync-batch-size":500}' \
--apply-to queues
三、镜像队列性能优化建议
1. 硬件配置建议
小型集群 (3节点):
-
CPU: 4核以上
-
内存: 8-16GB
-
磁盘: SSD, 200GB以上
-
网络: 千兆以太网
中型集群 (5节点):
-
CPU: 8核以上
-
内存: 16-32GB
-
磁盘: NVMe SSD, 500GB以上
-
网络: 万兆以太网
大型集群 (7+节点):
-
考虑分片部署
-
使用仲裁队列替代全部镜像
2. 参数调优参考
在/etc/rabbitmq/rabbitmq.conf中添加:
同步优化
ha_sync_batch_size = 50000 # 增加同步批量大小
ha_sync_batch_timeout = 60000 # 同步超时时间(ms)
内存优化
vm_memory_high_watermark.absolute = 8GB
vm_memory_calculation_strategy = rss
网络优化
net_ticktime = 60
cluster_keepalive_interval = 10000
四、镜像队列 vs 仲裁队列选择指南
| 考量维度 | 镜像队列 | 仲裁队列 (Quorum) |
|---|---|---|
| 数据一致性 | 强一致 (同步复制) | 强一致 (Raft共识) |
| 性能开销 | 较高 (同步阻塞) | 中等 (日志复制) |
| 故障恢复 | 自动但可能阻塞 | 自动且快速 |
| 版本要求 | 所有版本 | RabbitMQ 3.8+ |
| 配置复杂度 | 简单 | 中等 |
| 适用场景 | 传统业务,需要兼容老客户端 | 新系统,要求自愈能力强 |
总结建议
镜像队列集群适合以下场景:
-
已经使用RabbitMQ,需要升级为高可用架构
-
业务连续性要求高,不能容忍队列单点故障
-
客户端兼容性重要,不能修改客户端代码
-
消息顺序性要求严格
部署完成后验证步骤:
-
停止主节点,验证队列自动故障转移
-
模拟网络分区,验证自动恢复
-
压力测试,验证同步性能
-
检查监控告警是否正常工作